Language Models as Knowledge Embeddings
1. Abstract
知识嵌入(KE)通过将实体和关系嵌入到连续向量空间中来表示知识图(KG),现有的方法主要是基于结构或基于描述的。
基于结构的方法学习保持KGs固有结构的表示。在结构信息有限的现实世界中,它们不能很好地代表大量的长尾实体。
基于描述的方法利用文本信息和语言模型。在这个方向上,先前的方法几乎没有优于基于结构的方法,并且存在诸如昂贵的负采样和限制性描述需求等问题。
在本文中,我们提出了LMKE,它采用语言模型来推导知识嵌入,旨在丰富长尾实体的表示,并解决基于先验描述的方法的问题。我们将基于描述的KE学习与对比学习框架结合起来,以提高训练和评估的效率。实验结果表明,LMKE在链路预测和三重分类的KE基准上取得了最先进的性能,尤其是对于长尾实体。
2. Introduction
基于结构的方法:
如TransE和RotatE,被训练来保持KGs的固有结构。这些方法不能很好地表示长尾实体,因为它们仅依赖于KGs的结构,因此有利于富含结构信息的实体(即与大量实体链接)
- 缺点:现实世界中的KGs被广泛观察到具有右偏度分布,即实体的度近似遵循幂律分布,形成长尾。例如,在WN18RR上,14.1%的实体具有度1,60.7%的实体具有不超过3个邻居。因此,它们的嵌入受到结构连通性的限制。图1中所示的基于结构的方法在长尾实体上的性能下降证明了这个问题,这表明它们的嵌入是不符合要求的
基于描述的方法:
基于描述的KE方法通过用语言模型对KGs中的实体的描述进行编码来表示它们,例如DKRL和KEPLER。文本描述为许多语义相关任务提供了丰富的信息,这为学习长尾实体的信息表示提供了机会。在极端情况下,对现有KG来说是新颖的新兴实体仍然可以用其文本信息很好地表示。此功能被以前的方法称为“inductive (zero-shot) setting”。此外,KGs中大量缺失的知识可以被实体描述中包含的丰富的文本信息所覆盖,也可以通过预先训练的语言模式来学习PLM,因为当前的文本语料库在规模上超过了KGs,并且包含了更多的信息。
- 缺点:现有的基于描述的方法几乎不能优于基于结构的方法,并且存在以下问题:
1.昂贵的阴性采样。虽然负采样对KE学习至关重要,但由于语言模型的编码开销,现有的基于描述的方法只允许具有有限的负采样。
2.限制性描述需求。现有方法通常需要对KG中的所有实体进行描述,并丢弃没有描述或描述简短的实体。尽管精细的基准可以满足这一需求,但现实世界中的KGs很难包含对所有实体的描述。
在本文中,我们提出了LMKE,它采用语言模型来推导知识嵌入,旨在增强长尾实体的表示,并解决基于先前描述的KEs中的上述问题。LMKE利用基于描述的方法的归纳能力来丰富长尾实体的表示。在LMKE中,实体和关系被视为特殊的令牌,其输出嵌入被置于相关实体、关系及其文本信息中并从中学习,因此LMKE也适用于没有描述的实体。进一步提出了一种对比学习框架,其中小批量内的实体嵌入作为彼此的负样本,以避免编码负样本的额外成本。总之,我们的贡献如下:
1.我们识别了基于结构的KEs在表示长尾实体时的问题,并推广了基于描述的KEs的归纳能力来解决这个问题。据我们所知,我们是第一个提出利用文本信息和语言模型来丰富长尾实体表示的人。
2.我们提出了一种新的方法LMKE,该方法解决了现有基于描述的方法的两个不足,即昂贵的负采样和限制性的描述需求。我们也是第一个将基于描述的KE学习表述为对比学习问题的人。
3.我们在广泛使用的KE基准上进行了大量实验,结果表明LMKE在链路预测和三重分类方面都达到了最先进的性能,显著超过了现有的基于结构和基于描述的方法,尤其是对于长尾实体。
3. Related Work
Structure-Based Knowledge Embeddings.
根据评分函数,这些方法进一步分为 translation-based models 以及 semantic-matching models。
基于translation的模型采用基于距离的评分函数,该函数通过特定于关系的translation后实体嵌入h和t之间的距离来衡量三元组(h,r,t)的合理性。最具代表性的是TransE。它将实体和关系嵌入到维数为d的共享向量空间中,如h,r,t∈Rd。它的损失函数定义为‖h+r−t‖,以便在平移r后使h接近t。TransH提出将实体嵌入h和t投影到关系特定超平面,TransR进一步提出了到关系特定空间的投影。RotateE将一个关系定义为复向量空间中从实体h到实体t的旋转,因此它们的嵌入h,r,t∈Cd预计满足h⊙r≈t,其中⊙代表元素乘积。
基于semantic-matching的模型采用基于相似性的评分函数,通过匹配h,r,t的潜在语义来测量三元组(h,r、t)的合理性。RESCAL将关系r表示为矩阵Mr,并使用双线性函数h⊤ Mr t对(h,r,t)进行评分。DistMult为了简洁和高效,将Mr设为对角线。CoKE采用Transformer来推导上下文嵌入,其中三元组或关系路径用作输入令牌序列。
Description-based Knowledge Embeddings.
近年来,基于描述的KE方法由于文本信息的重要性和在NLP中的发展而越来越受到关注。DKRL首先引入实体的描述,并通过卷积神经网络对其进行编码,用于基于描述的嵌入。KEPLER使用PLM作为编码器来推导基于描述的嵌入,并以KE和PLM为目标进行训练。Pretrain KGE提出了一种基于描述的通用KE框架,该框架使用基于描述的嵌入初始化另一个可学习的KE,并在微调PLM后为了效率而丢弃PLM。KGBERT将h、r、t的描述作为PLM的输入序列连接起来,并通过序列嵌入对三元组进行评分。StAR因此将三元组划分为两个不对称部分,在这两个部分之间进行语义匹配。
4. Methods
在本节中,我们将介绍LMKE及其变体。我们首先提供了语言模型的背景(第3.1节)。然后,我们详细说明了LMKE如何采用语言模型来推导知识嵌入(第3.2节),以及它在训练中的零成本负采样和评估中的有效链接预测的对比变体(第3.3节)。
4.1 Language Models
预训练语言模型在NLP中越来越普遍。他们已经在大型语料库上进行了预训练,以存储大量的一般知识。例如,BERT[Devlin等人,2018]是一种经过预训练以预测随机屏蔽令牌的Transformer编码器。之后,PLM可以容易地用于在具有微调的各种下游任务中实现优异的性能。为了更好地理解这种优秀,提出了知识探究[Petroni et al,2019],用掩蔽完形填空来质疑PLM。这方面的研究表明,PLM包含丰富的事实知识,具有作为知识库的潜力。有趣的是,PLM也被证明能够学习满足一跳规则的关系,如等价、对称、反转和蕴涵[Casner et al,2020],这也是知识嵌入的需求。
4.2 LMKE
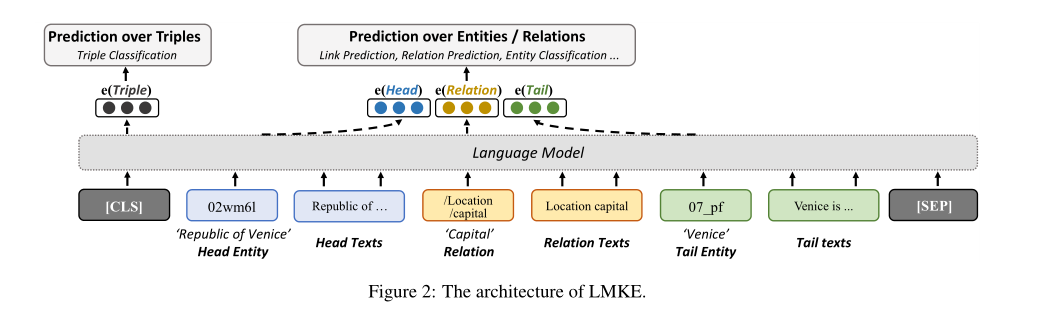

通过这种方式,我们将实体、关系及其描述的词嵌入到共享向量空间中。一个实体(或关系)的嵌入不仅在其自身的文本信息中,而且在三元组的其他两个组成部分及其文本信息中被情境化并从中学习。因此,长尾实体可以用它们的描述很好地表示,没有描述的实体也可以从相关实体的描述中学习表示。[CLS]的输出嵌入聚合了整个序列的信息,因此我们将其视为整个三元组的嵌入u。为了对三元组的合理性p(u)进行评分,LMKE将u输入到类似KG-BERT的线性层中

两个基准任务
KE的主要应用是预测缺失链接和对可能的三元组进行分类,即链接预测[Bolds等人,2013]和三元组分类[Socher等人,2013]。三重分类是一种判断三重u是否为真的二元分类任务,可以直接用p(u)来执行。链接预测是预测损坏的三元组(?,r,t)或(h,r,?)中缺失的实体,其中?表示为了预测而移除的实体。在这项任务中,模型需要通过用KG中的每个实体替换其头部或尾部实体来破坏三元组,对替换的三元组进行评分,并按得分的降序对实体进行排名。

4.3 Contrastive KE Learning
为了使用语言模型进行有效的链接预测,一种解决方案是对三元组进行部分编码。掩模实体模型(MEM-KGC)[CChoi等人,2021]用mask q替换移除的实体及其描述,并通过将其输出嵌入q馈送到线性层中来预测缺失的实体。它可以被视为LMKE的一种掩蔽变体,以利用文本信息换取时间复杂性。由于只编码了一个掩码不完全三元组,因此复杂性降低。然而,它丢弃了要预测的目标实体的文本信息,从而损害了文本信息的效用。
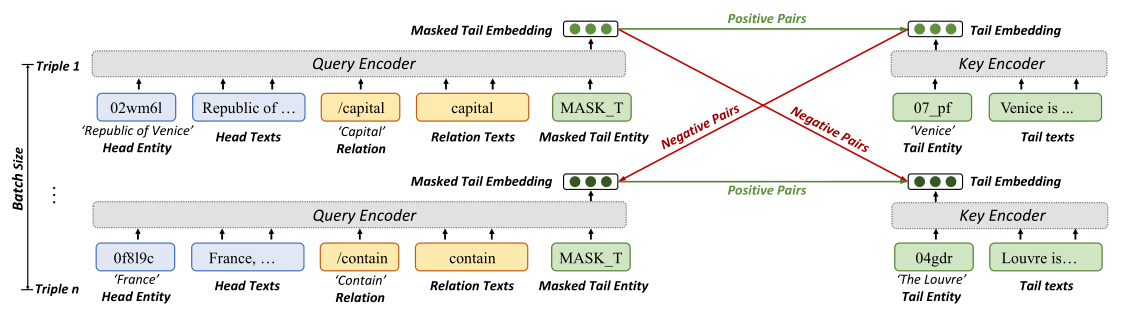
我们提出了一个对比学习框架,以更好地利用基于描述的KEs进行链接预测,其中给定的实体关系对和目标实体用作对比学习中要匹配的q和k。
对比LMKE(C-LMKE)是该框架下的LMKE变体,它用目标实体描述的编码取代了学习的实体表示(We的行)。它的特点是在小批量内进行对比匹配,这允许在不损失信息利用的情况下进行有效的链接预测,同时避免了编码负样本的额外成本。 The candidate keys of a query are defined as keys of the queries in the batch.查询的候选关键字被定义为批处理中查询的关键字。表1分析了C-LMKE的时间复杂度。
这种做法解决了昂贵的负采样问题,并允许基于描述的KEs从更多的负采样中学习。虽然负样本对KE学习至关重要,但由于语言模型的成本,大多数现有的基于描述的方法允许每个正样本只有几个(通常在1到5之间)。C-LMKE目前将负采样大小与批量大小绑定,通过我们的对比框架,可以进一步引入对比学习中的现有方法,如记忆库,以实现更多改进。
我们通过双层MLP(多层感知器)将编码query q与编码key k匹配,而不是对比学习中通常采用的余弦相似性,因为可能存在多个匹配 query 的 key。如果k1和k2都匹配q,并且我们使(q,k1)和(q,k2)之间的相似性最大化,则(k1,k2)也将被强制为相似,这是不希望的。因此,q与k匹配的概率为:

由于对于不是一对一的关系,通常有多个正确的实体用于损坏的三元组,因此我们采用二进制交叉熵来判断每个实体是否是正确的密钥(多标签分类),而不是多类交叉熵来找到最有可能的实体。考虑到大多数key是负的,我们分别对正的和负的损失进行平均,并将其相加。因此,将查询q与密钥K匹配的损失公式化为L(q,K)=−∑K+∈K+wq,K+log(p(q,K+))−∑K-∈K−wq,K−log(1−p(q、K−)),其中K+、K−分别表示正密钥和负密钥,K=K+ŞK−。我们采用自对抗负采样[Sun et al,2019]进行有效的KE学习,其计算权重为wq,k+=1Ük+Ü和wq,k−=exp(p(q,k))∑k∈k−exp(p(q,k))。在这种情况下,假阳性样本的损失被放大,而真阴性样本的损失则被减少。如图所示

5. Experiment
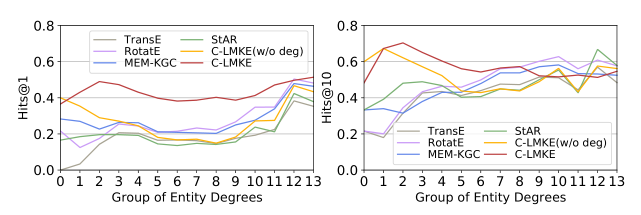
为了显示我们的方法在长尾实体上的有效性,我们根据度的对数对实体进行分组,为每组收集相关的三元组,并研究不同方法在不同组上的平均链路预测性能。如果h或t在群i中,则三元组(h,r,t)与群i相关。分组规则与图1中相同。图4中FB15k-237的结果表明,基于描述的方法显著优于基于0、1和2组长尾实体(阶数低于4)的结构方法,并且我们的C-LMKE显著优于其他基于描述的算法。具有或不具有学位信息的C-LMKE结果之间的比较表明,引入度信息通常可以提高其在不是长尾实体上的性能。然而,在流行的实体上,基于结构的方法通常表现得更好。尽管StAR也是基于描述的模型,但它达到了最佳效果Hits@10在第12组和第13组上,因为它是用遵循基于结构的方法的附加目标进行训练的。
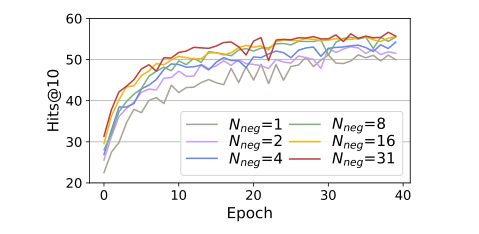
负采样大小的重要性我们研究了具有不同负采样大小Nneg的C-LMKE的性能,以证明其重要性。我们将批处理大小设置为32,并通过仅使用批处理中其他三元组的几个编码目标实体作为负密钥来限制每个三元组的Nneg。我们报告Hits@10C-LMKE与BERTtiny在FB15k-237上的40个时期。结果如图所示。5表明更大的Nneg持续地带来更好的性能直到收敛。当Nneg低于8岁时,增加Nneg可以大大加速训练,并提高最终表现。然而,现有的基于描述的方法通常将Nneg设置为仅1或5,这限制了它们的性能。
6. Conclusion
在本文中,我们提出了LMKE,这是一种采用语言模型作为知识嵌入的有效方法。
由于基于结构的KEs无法很好地表示长尾实体,LMKE利用文本描述,并学习实体和关系在与单词标记相同的空间中的嵌入。它解决了基于先验描述的方法的限制性需求。进一步提出了一种对比学习框架,该框架允许零成本负采样,并显著降低训练和评估中的时间复杂性。大量实验的结果表明,我们的方法在各种基准测试上实现了最先进的性能,尤其是对于长尾实体。
未来,我们计划探索更先进的对比学习方法在基于描述的KEs中的有效性。我们还感兴趣的是语言模型在KGs中建模组成模式的能力。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号