模块化函数(4) dataset
1. 整理数据集
将 [image] 和 [label]分开,其中image是gray格式图片矩阵,label是str

class listDataset(Dataset):
def __init__(self,list_file=None,transform=None,target_transform=None):
self.list_file=list_file
with open(list_file) as fp:
self.lines=fp.readlines()
self.nSamples=len(self.lines)
self.transform=transform
self.target_transform=target_transform
def __len__(self):
return self.nSamples
def __getitem__(self, index):
assert index <= len(self),'index range error'
line_splits=self.lines[index].strip().split(' ')
imgpath=line_splits[0]
label=line_splits[1].decode('utf-8')
try:
img=Image.open(imgpath).convert('L')
except IOError:
print('Corrupted image for %d' % index)
if self.transform is not None:
img=self.transform(img)
if self.target_transform is not None:
label=self.target_transform(label)
return (img,label)
2. 图片大小并归一化
class resizeNormalize(object):
def __init__(self,size,interpolation=Image.BILINEAR):
self.size=size
self.interpolation=interpolation
self.toTensor=transforms.ToTensor()
def __call__(self, img):
img=img.resize(self.size,self.interpolation)
img=self.toTensor(img)
img.sub_(0.5).div_(0.5)
return img
先判断是否需要keep_ratio,如果需要,就取最大ratio并应用在imageH和imagW上做出大小调整,并归一化
class alignCollate(object):
def __init__(self,imgH=32,imgW=100,keep_ratio=False,min_ratio=1):
self.imgH=imgH
self.imgW=imgW
self.keep_ratio=keep_ratio
self.min_ratio=min_ratio
def __call__(self, batch):
images,labels=zip(*batch)
imgH=self.imgH
imgW=self.imgW
if self.keep_ratio:
ratios=[]
for image in images:
w,h=image.size
ratios.append(w/float(h))
ratios.sort()
max_ratio=ratios[-1]
imgW=int(np.floor(max_ratio*imgH))
imgW=max(imgH*self.min_ratio,imgW)
transforms=resizeNormalize((imgW,imgH))
images=[transforms(image) for image in images]
images=torch.cat([t.unsqueeze(0) for t in images],0)
#cat中使用[]不容易出错,使用()容易出错
return images,labels
3. 随机连续取样
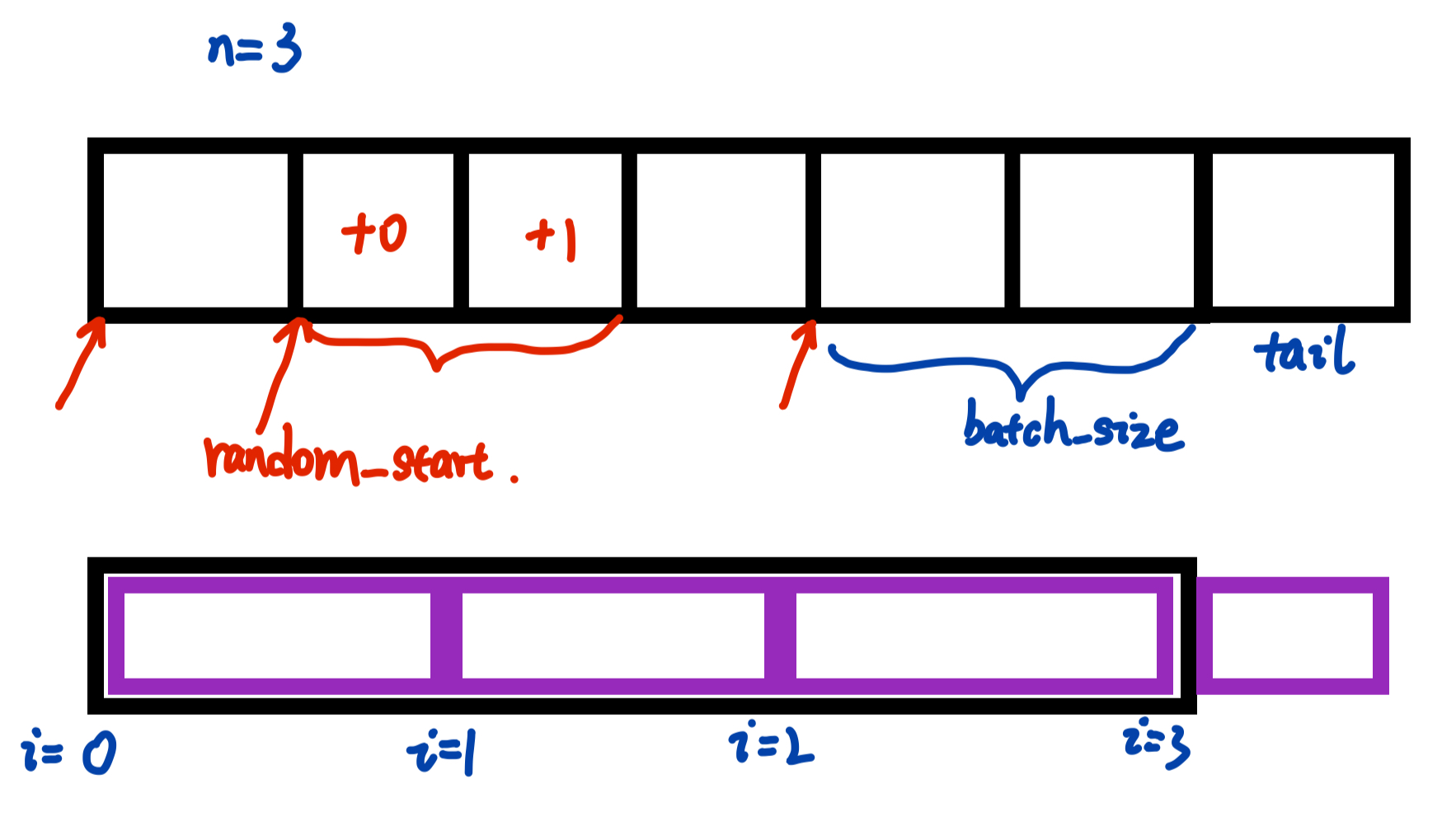
class randomSequentialSampler(sampler.Sampler):
def __init__(self,data_source,batch_size):
self.num_samples=len(data_source)
self.batch_size=batch_size
def __iter__(self):
n_batch=len(self)//self.batch_size
tail=len(self)%self.batch_size
index=torch.LongTensor(len(self)).fill_(0)
for i in range(n_batch):
random_start=random.randint(0,len(self)-self.batch_size)
batch_index=random_start+torch.arange(0,self.batch_size)
index[i*self.batch_size:(i+1)*self.batch_size]=batch_index
if tail:
random_start=random.randint(0,len(self)-self.batch_size)
tail_index=random_start+torch.arange(0,tail)
index[(i+1)*self.batch_size:]=tail_index
return iter(index)
def __len__(self):
return self.num_samples


 浙公网安备 33010602011771号
浙公网安备 33010602011771号