1. 在enocder_output上计算注意力权重
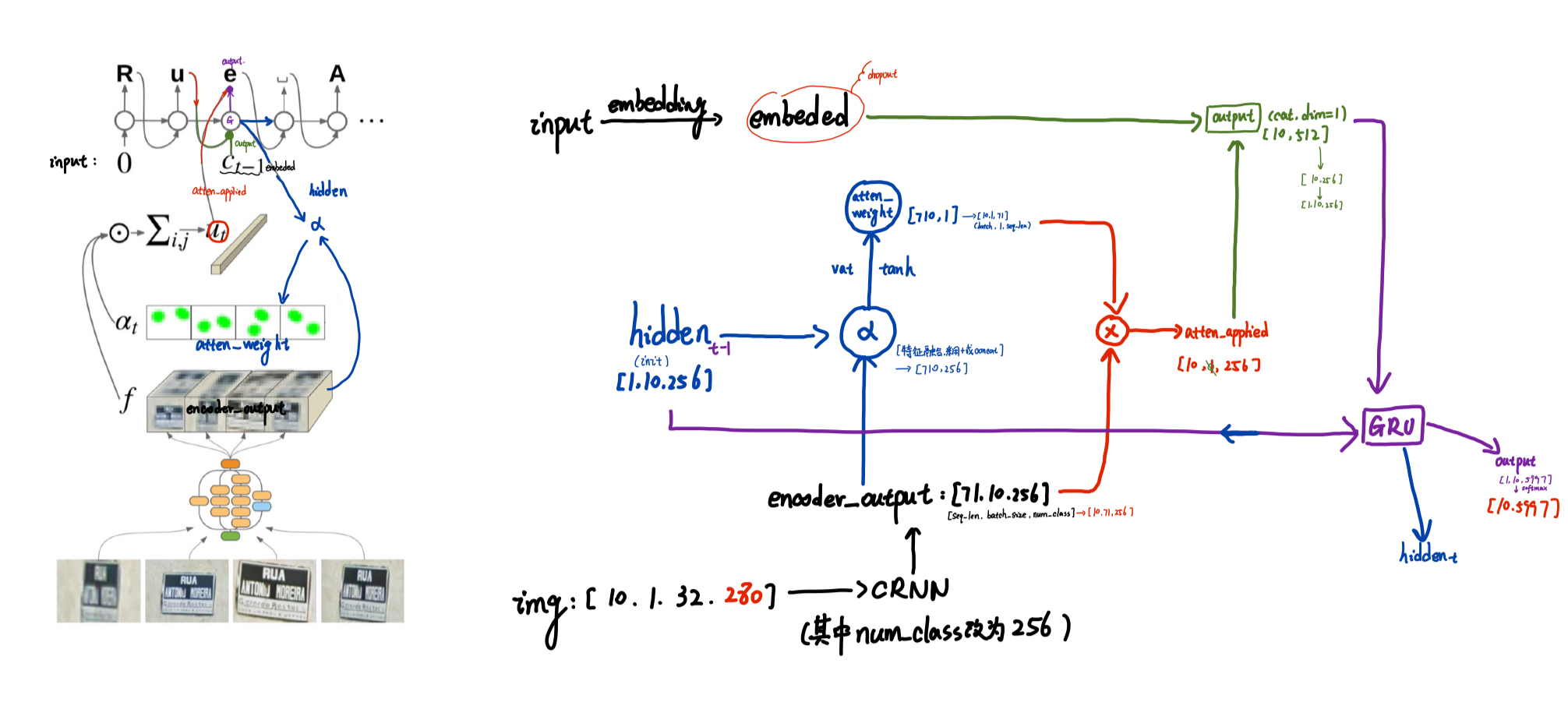
class AttentiondecoderV2(nn.Module):
"""
采用seq2seq
"""
def __init__(self,hidden_size,output_size,dropout_p=0.1):
super(AttentiondecoderV2, self).__init__()
self.hidden_size=hidden_size
self.output_size=output_size
self.dropout_p=dropout_p
self.embedding=nn.Embedding(self.output_size,self.hidden_size)
self.attn_combine=nn.Linear(self.hidden_size*2,self.hidden_size)
self.dropout=nn.Dropout(self.dropout_p)
self.gru=nn.GRU(self.hidden_size,self.hidden_size)
self.out=nn.Linear(self.hidden_size,self.output_size)
#test
self.vat=nn.Linear(hidden_size,1)
def forward(self,input,hidden,encoder_outputs):
"""
:param input:
:param hidden:
:param encoder_outputs: [seq_len,batch_size,num_class]
:return:
"""
#前一次的输入进行词嵌入,每个batch一个词输(数字)入进来
#[10]->[10, 256]
embeded=self.embedding(input)
embeded=self.dropout(embeded)
#test [71,10,256] batch_size
batch_size=encoder_outputs.shape[1]
alpha=hidden+encoder_outputs #特征融合 +
#aplha:[710,256]
alpha=alpha.view(-1,alpha.shape[-1])
#atten_weight:[710,256]*[256,1]->[710,1]
atten_weights=self.vat(torch.tanh(alpha))
#[710,1]
atten_weights=atten_weights.view(-1,1,batch_size).permute(2,1,0)
#[71,1,10]->[10,1,71] [batch_size,1,seq_len]
atten_weights=F.softmax(atten_weights,dim=2)
#atten_weights:[batch_size,1,71]
#[10,1,71]和[1,71,256]——>[10,1,256]
attn_applied=torch.matmul(atten_weights,encoder_outputs.permute(1,0,2))
#[10,256]+[10,256]——>[10,512]
output=torch.cat((embeded,attn_applied.squeeze(1)),1)
#[10,512]——>[10,256]——>[1,10,256]
output=self.attn_combine(output).unsqueeze(0)
output=F.relu(output)
#[1,10,256],[1,10,256]
output,hidden=self.gru(output,hidden)
#[10,hiden_size] ——> [10,output_size]
output=F.log_softmax(self.out(output[0]),dim=1)
return output,hidden,atten_weights
#output:[10,13]
#hidden:[1,10,256]
#aten_weights:[10,1,71]
def initHidden(self,batch_size):
#初始化hidden的张量[1,10,256]
result=Variable(torch.zeros(1,batch_size,self.hidden_size))
return result
class decoderV2(nn.Module):
"""
decoder from image features
"""
def __init__(self,nh=256,nclass=13,dropout_p=0.1):
super(decoderV2, self).__init__()
self.hidden_size=nh
self.decoder=AttentiondecoderV2(nh,nclass,dropout_p)
def forward(self,input,hidden,encoder_outputs):
return self.decoder(input,hidden,encoder_outputs)
def initHidden(self,batch_size):
#初始化hidden的张量[1,10,256]
result=Variable(torch.zeros(1,batch_size,self.hidden_size))
return result
2. 在embeded上计算注意力权重
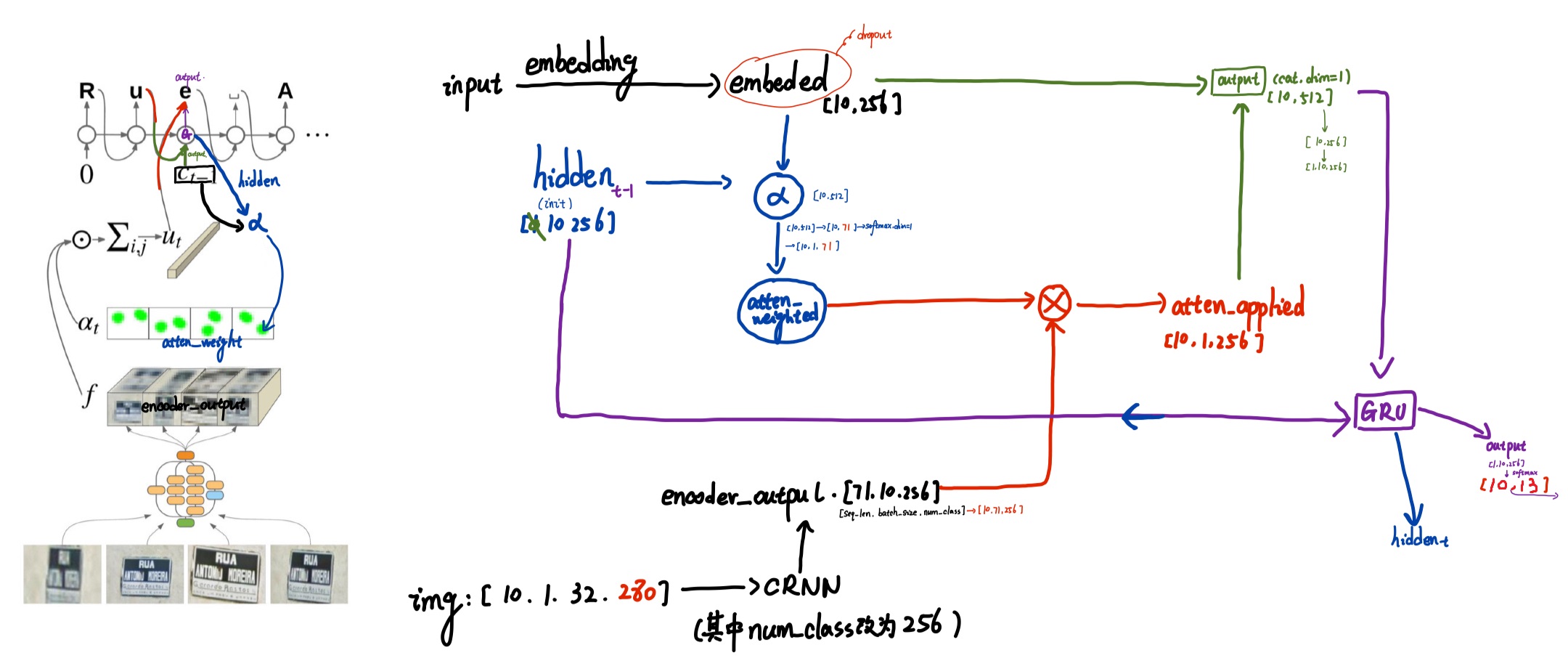
class Attentiondecoder(nn.Module):
"""
采用attention注意力机制,进行解码
"""
def __init__(self,hidden_size,output_size,dropout_p=0.1,max_length=71):
super(Attentiondecoder, self).__init__()
self.hidden_size=hidden_size
self.output_size=output_size
self.dropout_p=dropout_p
self.max_length=max_length
self.embedding=nn.Embedding(self.output_size,self.hidden_size)
#[13,256]
#nn.Embedding(num_embeddings,embedding_dim)
#第一个参数:词典中一共有多少个词
#第二个参数:每个词用一个多少维度的词向量来描述它
"""input = [[1, 2, 3],[2, 3, 4]]
input=torch.LongTensor(input)
print(input.size())
embeded=nn.Embedding(5,512)
#词表的大小必须比最大值大,要可以完全映射
x=embeded(input)
print(x.size())
torch.Size([2, 3])
torch.Size([2, 3, 512])"""
self.attn=nn.Linear(self.hidden_size*2,self.max_length)
self.attn_combine=nn.Linear(self.hidden_size*2,self.hidden_size)
self.dropout=nn.Dropout(self.dropout_p)
self.gru=nn.GRU(self.hidden_size,self.hidden_size)
self.out=nn.Linear(self.hidden_size,self.output_size)
def forward(self,input,hidden,encoder_outputs):
#[10]
embedded=self.embedding(input)
embedded=self.dropout(embedded)
#hidden[0]: [10,256]与embeded:[10,256]——>[10,512]——>[10,71]
alpha=torch.cat((embedded,hidden[0]),1)
atten_weights=F.softmax(self.attn(alpha),dim=1)
#[10,1,71]*[10,71,256]——>[10,1,256]
atten_applyed=torch.matmul(atten_weights.unsqueeze(1),encoder_outputs.permute(1,0,2))
#[10,256],[10,256]——>[10,512]
output=torch.cat((embedded,atten_applyed.squeeze(1)),1)
#[1,10,256]
output=self.attn_combine(output).unsqueeze(0)
output=F.relu(output)
output,hidden=self.gru(output,hidden)
#关于GRU
#GRU(input_size,hidden_size)
#input:(seq_len,batch,input_size)
#h0: (num_layers*num_directions:1*1,batch,hidden_size)
#output:(seq_len,batch,num_directions*hidden_size:256)
#h_n: (num_layers*num_directions:1*1,batch,hidden_size)
#[10,256]——>[10,13(num_class)]
output=F.log_softmax(self.out(output[0]),dim=1)
#use log_softmax for nllloss
return output,hidden,atten_weights
#output:[10,13]
#hidden:[1,10,]
def initHidden(self,batch_size):
result=Variable(torch.zeros(1,batch_size,self.hidden_size))
return result
class decoder(nn.Module):
"""
decode for image features
"""
def __init__(self,nh=256,nclass=13,dropout_p=0.1,max_length=71):
super(decoder, self).__init__()
self.hidden_size=nh
self.decoder=Attentiondecoder(nh,nclass,dropout_p,max_length)
def forward(self,input,hidden,encoder_outputs):
return self.decoder(input,hidden,encoder_outputs)
def initHidden(self,batch_size):
result=Variable(torch.zeros(1,batch_size,self.hidden_size))
return result
测试函数
if __name__=='__main__':
#[10]
input=torch.LongTensor([1,1,2,1,3,1,2,4,1,7])
net=decoderV2()
encoder_output=torch.randn(71,10,256)
decoder_hidden=net.initHidden(10)
output, hidden, atten_weights=net(input,decoder_hidden,encoder_output)
print(output.shape,hidden.shape,atten_weights.shape)
#torch.Size([10, 13])
#torch.Size([1, 10, 256])
#torch.Size([10, 1, 71])"""


 浙公网安备 33010602011771号
浙公网安备 33010602011771号