
python3 爬虫教学之爬取链家二手房(最下面源码) //以更新源码
前言
作为一只小白,刚进入Python爬虫领域,今天尝试一下爬取链家的二手房,之前已经爬取了房天下的了,看看链家有什么不同,马上开始。
一、分析观察爬取网站结构
这里以广州链家二手房为例:http://gz.lianjia.com/ershoufang/
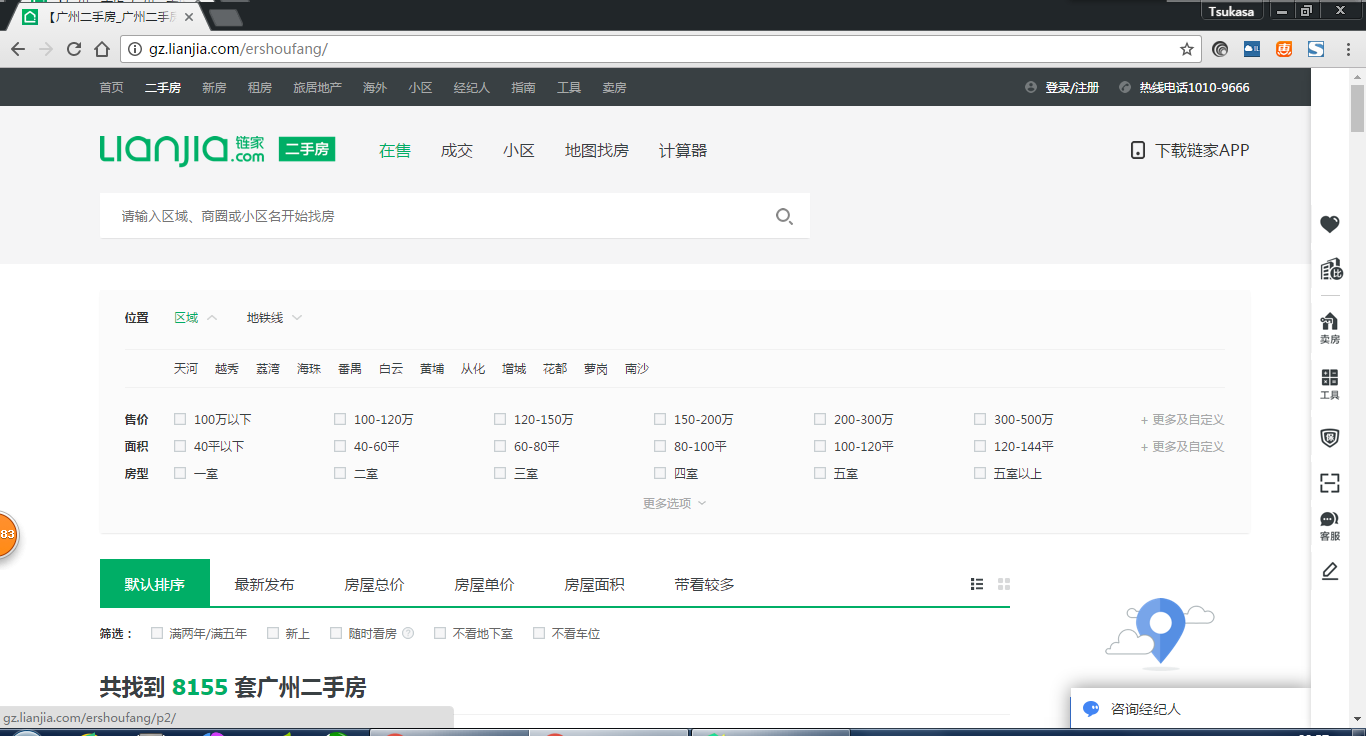
这是第一页,我们看看第二页的url会有什么变化 发现多出来一个/g2,第三页/pg3,那么原始的是不是就是增加/pg1呢,我们测试一下http://gz.lianjia.com/ershoufang/pg1/ == http://gz.lianjia.com/ershoufang/那么问题不大,我们继续分析。
发现多出来一个/g2,第三页/pg3,那么原始的是不是就是增加/pg1呢,我们测试一下http://gz.lianjia.com/ershoufang/pg1/ == http://gz.lianjia.com/ershoufang/那么问题不大,我们继续分析。

这些就是我们想得到的二手房资讯,但是这个是有链接可以点进去的,我们看看:
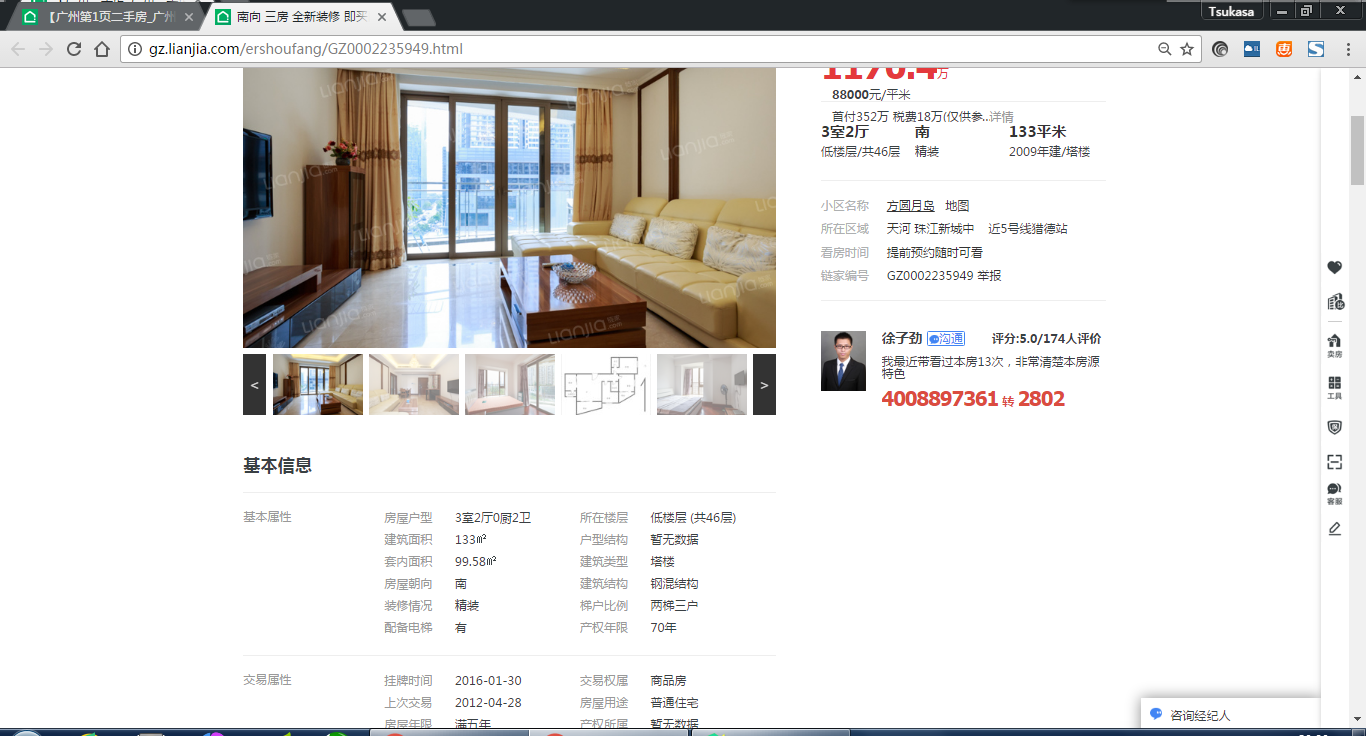
里面的二手房资讯更加全面,那我是想得到这个网页里面的资讯了。
二、编写爬虫
1.得到url
我们先可以得到全部详细的链接,这里有100页,那么我们可以http://gz.lianjia.com/ershoufang/pg1/.../pg2.../pg3.../pg100 先生成全部url,再从这些url得到每一页里面详细的url,再从详细的url分析html得到我想要的资讯。

2.分析 htmlhttp://gz.lianjia.com/ershoufang/pg1/
先打开chrom自带的开发者工具分析里面的network ,把preserve log
,把preserve log 勾上,清空
勾上,清空 ,然后我们刷新一下网页。
,然后我们刷新一下网页。

发现get:http://gz.lianjia.com/ershoufang/pg1/请求到的html
那么我们就可以开始生成全部url先了:
def generate_allurl(user_in_nub):
url = 'http://gz.lianjia.com/ershoufang/pg{}/'
for url_next in range(1,int(user_in_nub)):
yield url.format(url_next)
def main():
user_in_nub = input('输入生成页数:')
for i in generate_allurl(user_in_nub):
print(i)
if __name__ == '__main__':
main()
运行结果: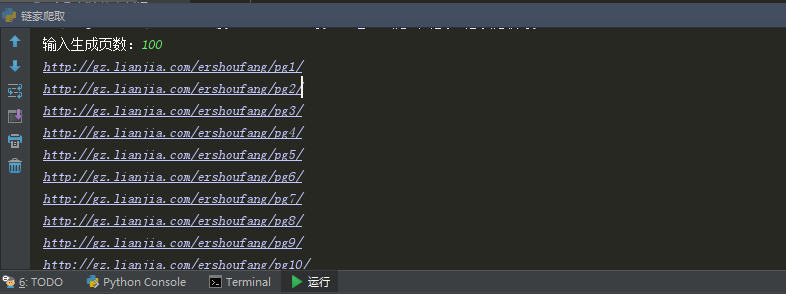
这样我们就生成了100页的url
然后我们就要分析这些url里面的详细每一页的url:
先分析网页结构,
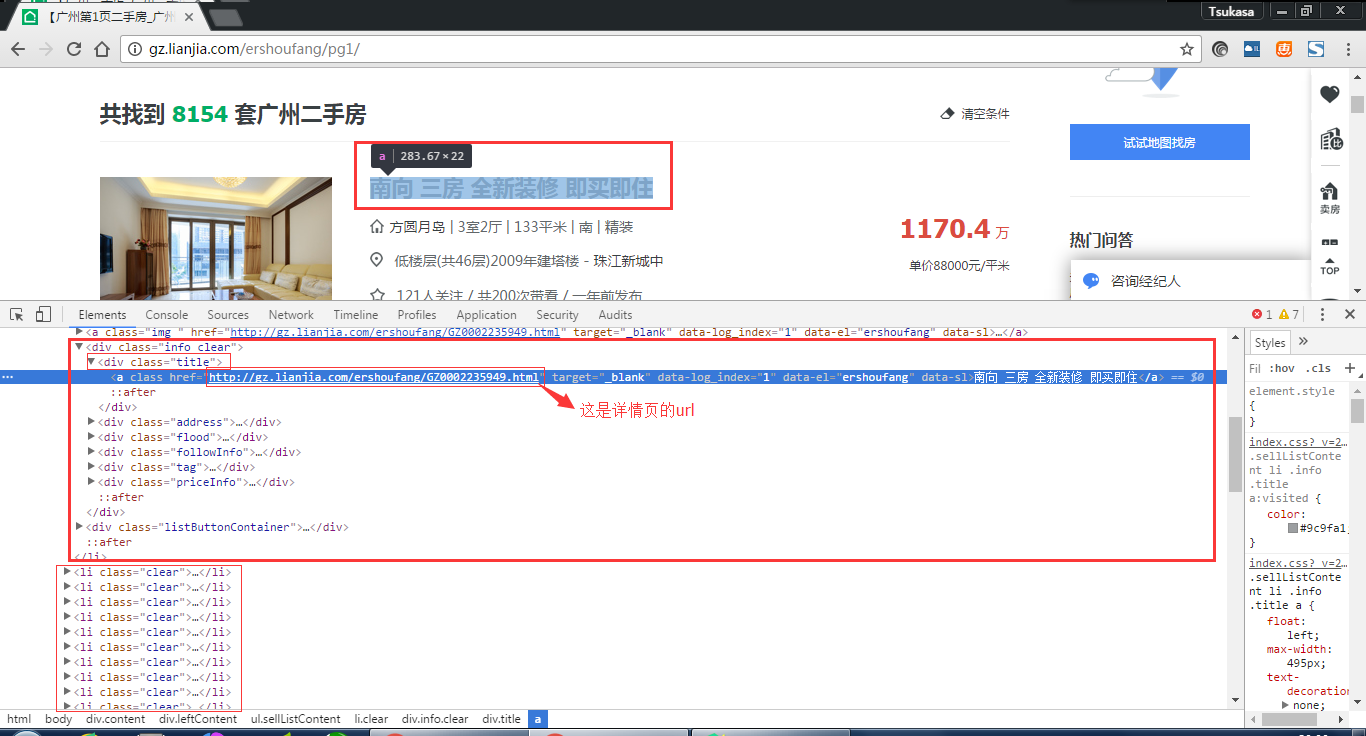
发现我们要的url是再class为title里面的a标签,我们可以使用request来获取html,用正则表达法来分析获取详情页url:
import requests
import re
def一个方法,把得到的generate_allurl传进来再打印一下看看
def get_allurl(generate_allurl):
get_url = requests.get(generate_allurl,)
if get_url.status_code == 200:
re_set = re.compile('<li.*?class="clear">.*?<a.*?class="img.*?".*?href="(.*?)"')
re_get = re.findall(re_set,get_url.text)
print(re_get)
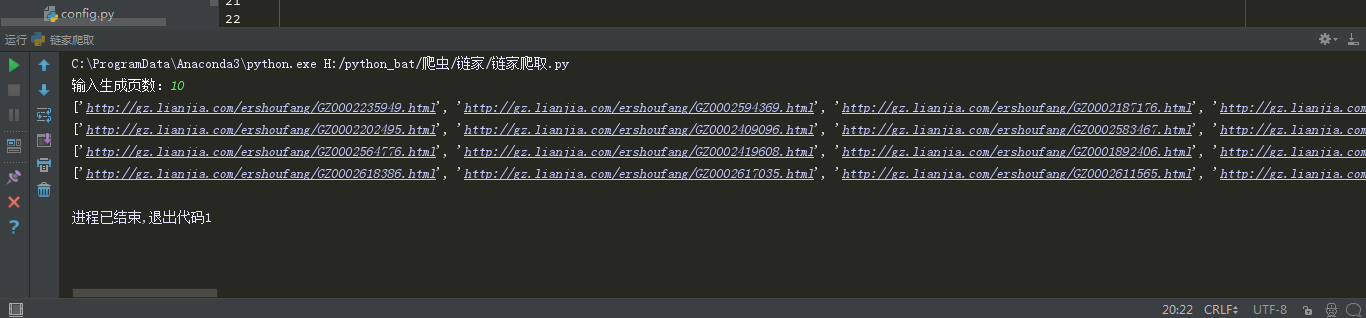
正常获取详细页的链接
下一步我们就要分析这些详细页连接以获取里面的资讯, 使用自带开发者工具点击这个箭头可以选择网页元素:
使用自带开发者工具点击这个箭头可以选择网页元素:

发现资讯在一个class为main里面,可以用BeautifulSoup模块里面的方法得到:
from bs4 import BeautifulSoup
定义一个方法来把详情url链接传进来分析:
def open_url(re_get):
res = requests.get(re_get)
if res.status_code == 200:
info = {}
soup = BeautifulSoup(res.text,'lxml')
info['标题'] = soup.select('.main')[0].text
info['总价'] = soup.select('.total')[0].text + '万'
info['每平方售价'] = soup.select('.unitPriceValue')[0].text
return info
这里把requests.get对象传给res,然后把这个变量传给BeautifulSoup,用lxml解析器解析,再把结果传给soup,然后就可以soup.select方法来筛选,因为上面标题在,main下:
soup.select('.main'),因为这里是一个class,所以前面要加.,如果筛选的是id,则加#。
得到如下结果:

是一个list,所以我们要加[ 0 ]取出,然后可以运用方法 .text得到文本。
def open_url(re_get):
res = requests.get(re_get)
if res.status_code == 200:
soup = BeautifulSoup(res.text,'lxml')
title = soup.select('.main')[0].text
print(title)
得到结果

然后还可以添加到字典,return返回字典:
def open_url(re_get):
res = requests.get(re_get)
if res.status_code == 200:
info = {}
soup = BeautifulSoup(res.text,'lxml')
info['标题'] = soup.select('.main')[0].text
info['总价'] = soup.select('.total')[0].text + '万'
info['每平方售价'] = soup.select('.unitPriceValue')[0].text
return info
得到结果:
还可以储存到xlsx文档里面:
def pandas_to_xlsx(info):
pd_look = pd.DataFrame(info)
pd_look.to_excel('链家二手房.xlsx',sheet_name='链家二手房')
ok基本完成,可能有没有说清楚的,留言我继续更新
1 #!/usr/bin/env python3 2 # -*- coding: utf-8 -*- 3 # Author;Tsukasa 4 5 import json 6 from multiprocessing import Pool 7 import requests 8 from bs4 import BeautifulSoup 9 import re 10 import pandas as pd 11 import pymongo 12 13 14 def generate_allurl(user_in_nub, user_in_city): # 生成url 15 url = 'http://' + user_in_city + '.lianjia.com/ershoufang/pg{}/' 16 for url_next in range(1, int(user_in_nub)): 17 yield url.format(url_next) 18 19 20 def get_allurl(generate_allurl): # 分析url解析出每一页的详细url 21 get_url = requests.get(generate_allurl, 'lxml') 22 if get_url.status_code == 200: 23 re_set = re.compile('<li.*?class="clear">.*?<a.*?class="img.*?".*?href="(.*?)"') 24 re_get = re.findall(re_set, get_url.text) 25 return re_get 26 27 28 def open_url(re_get): # 分析详细url获取所需信息 29 res = requests.get(re_get) 30 if res.status_code == 200: 31 info = {} 32 soup = BeautifulSoup(res.text, 'lxml') 33 info['标题'] = soup.select('.main')[0].text 34 info['总价'] = soup.select('.total')[0].text + '万' 35 info['每平方售价'] = soup.select('.unitPriceValue')[0].text 36 info['参考总价'] = soup.select('.taxtext')[0].text 37 info['建造时间'] = soup.select('.subInfo')[2].text 38 info['小区名称'] = soup.select('.info')[0].text 39 info['所在区域'] = soup.select('.info a')[0].text + ':' + soup.select('.info a')[1].text 40 info['链家编号'] = str(re_get)[33:].rsplit('.html')[0] 41 for i in soup.select('.base li'): 42 i = str(i) 43 if '</span>' in i or len(i) > 0: 44 key, value = (i.split('</span>')) 45 info[key[24:]] = value.rsplit('</li>')[0] 46 for i in soup.select('.transaction li'): 47 i = str(i) 48 if '</span>' in i and len(i) > 0 and '抵押信息' not in i: 49 key, value = (i.split('</span>')) 50 info[key[24:]] = value.rsplit('</li>')[0] 51 print(info) 52 return info 53 54 55 def update_to_MongoDB(one_page): # update储存到MongoDB 56 if db[Mongo_TABLE].update({'链家编号': one_page['链家编号']}, {'$set': one_page}, True): #去重复 57 print('储存MongoDB 成功!') 58 return True 59 return False 60 61 62 def pandas_to_xlsx(info): # 储存到xlsx 63 pd_look = pd.DataFrame(info) 64 pd_look.to_excel('链家二手房.xlsx', sheet_name='链家二手房') 65 66 67 def writer_to_text(list): # 储存到text 68 with open('链家二手房.text', 'a', encoding='utf-8')as f: 69 f.write(json.dumps(list, ensure_ascii=False) + '\n') 70 f.close() 71 72 73 def main(url): 74 75 writer_to_text(open_url(url)) #储存到text文件 76 # update_to_MongoDB(list) #储存到Mongodb 77 78 79 if __name__ == '__main__': 80 user_in_city = input('输入爬取城市:') 81 user_in_nub = input('输入爬取页数:') 82 83 Mongo_Url = 'localhost' 84 Mongo_DB = 'Lianjia' 85 Mongo_TABLE = 'Lianjia' + '\n' + str('zs') 86 client = pymongo.MongoClient(Mongo_Url) 87 db = client[Mongo_DB] 88 pool = Pool() 89 for i in generate_allurl('2', 'zs'): 90 pool.map(main, [url for url in get_allurl(i)])
源码地址:https://gist.github.com/Tsukasa007/660fce644b7dd33afc57998fdc6c376a

 浙公网安备 33010602011771号
浙公网安备 33010602011771号