面试突击
1、如果线上机器突然宕机,线程池的阻塞队列中的请求怎么办?
导致队列中积压的任务会丢失
解决 : 提交任务之前先在数据库里插入这个任务的信息,并标以状态比如 : 未提交、已提交、已完成。待机器重启后,使用一个后台线程扫描表中已提交和未提交的数据,进行重新提交
2、谈谈你对Java内存模型的理解
每条线程有自己的工作内存,工作内存中保存了被该线程使用的变量的主内存副本。线程不可以直接操作主内存,不同线程不可以访问对方工作内存中的变量,线程间变量的传递都是通过主内存来完成。
将一个int a = 0 改为 1的流程包括:
- 从主内存中read到 a= 0
- 将a = 0 load到工作内存中
- 线程use工作内存中的a = 0将a设置为1
- 将a = 1 assign到工作内存中
- 工作内存将a =1 通过store、write进主内存
3、Java内存模型中的原子性、可见性、有序性?
- 原子性:操作不可拆分,同一时刻只有一个线程可以进行操作。
- 可见性:一个线程中某个变量的修改能马上被其他线程知晓
- 有序性:jvm虚拟机为了性能优化在单线程不影响结果的情况下会进行指令重排,有序性就是禁止指令重排
4、volatile工作原理?如何保证可见性?原子性为什么不能保证?
回答顺序:内存模型 ==》 原子性、可见性、有序性 ==》volatile
- volatile 和 原子性 : 不能保证,多线程会存在问题
- volatile 和 可见性 :可以保证,一个被volatile修饰的变量修改之后马上会写入主内存,并且让其他线程中改变量的缓存失效。那么其他线程要读取的时候就必须要去主内存中读取
- volatile 和有序性 :
5、happens-before/内存屏障是什么?
6、spring中bean是线程安全的吗?
思路 :先描述一下spring中的作用域
spring的作用域有五种 :singleton、prototype、request、session、global-session
默认的作用域是singlton,如果在某个实例中存在实例变量,那么多线程调用的时候就会出现线程不安全的情况。
7、spring事务的实现原理是什么?说一下事务传播机制?
事务的原理就是如果你加了一个@Transactional注解,此时spring就会使用AOP思想,对你的这个方法在执行之前,先去开启事务,执行完毕之后,根据你方法是否报错来判断是否执行回滚操作。
- propagation_required : 默认,如果没有事务就新建一个事务,如果有事务存在就加入
- propagation_supports : 如果有事务就加入事务,如果没有事务就以非事务方式运行
- propagation_mandatory:使用当前事务,如果没有事务就报错
- propagation_required_new : 新建事务,如果存在事务就将当前事务挂起
- propagation_not_supported:以非事务方式运行,如果当前存在事务,就将事务挂起
- propagation_never : 以非事务方式运行,如果存在就抛出异常
- propagation_nested : 外层事务如果回滚,内层事务回滚。但是内层事务如果回滚,仅仅回滚自己的代码
8、spring bean的生命周期
- 实例化bean :
- 属性填充:实例化后的对象被封装在BeanWrapper中,spring根据BeanDefinition中的信息以及通过BeanWrapper提供的设置属性的接口完成依赖注入
- 处理Aware接口:Spring接口会检测该对象是否实现了xxxAware接口,并将相关的xxxAware实例注入给Bean:
- 如果实现了BeanNameAware接口,会调用他的setBeanName(String beanId)方法
- 如果实现了BeanFactoryAware接口,会调用setBeanFactory()方法,传递的就是工厂本身
- 如果实现了BeanClassLoaderAware接口,会调用setBeanClassLoader方法
- BeanPostProcessor : bean自定义的一些前置处理,applyBeanPostProcessorsBeforeInitialization
- PropertiesSet 和 init-method方法的调用
- BeanPostProcessor :bean自定义的一些后置处理,applyBeanPostProcessorsAfterInitialization
9、spring涉及的设计模式?
- 工厂:
- 单例:
- 代理:
10、索引
b-树
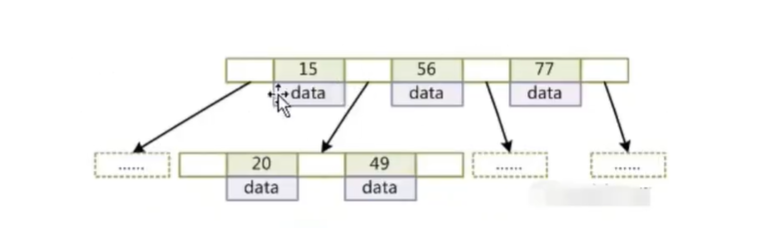
B+树
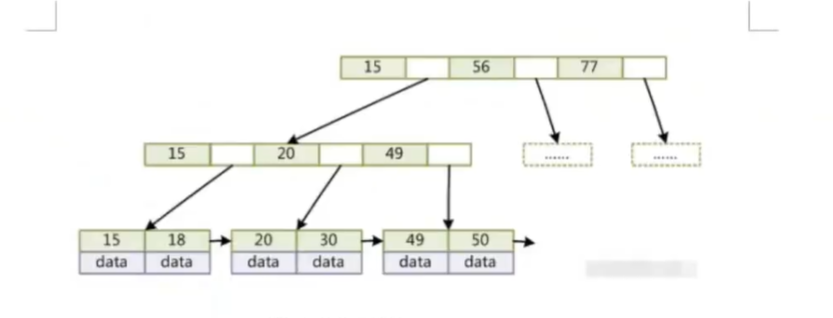
- myisam叶子节点不存数据,存的是物理地址,然后根据物理地址到数据文件中去查找到对应的数据。
- innodb 默认会根据主键建立索引,称为聚簇索引。innodb的数据文件本身就是索引文件,聚簇索引的叶子节点存储了真实的数据,如果对非主键建立索引,其叶子节点存储的是主键的值,然后根据主键再查询到对应的数据,该操作称之为回表。
- 索引的原则 : 全值匹配、最左匹配原则、慎用like 百分号在右边、范围查找只有范围查找字段可用索引、不要使用函数修改列
11、mysql事务
ACID ---- 事务的隔离级别
- atomic :原子性,一堆sql要么一起成功要么一起失败
- consistency :一致性,针对数据一致性来说的。就是一组SQL执行之前是正确的,执行之后数据也必须是准确的。
- isolation : 隔离性,多个事务跑的时候不能互相干扰
- durability : 持久性,事务成功后, 对数据的修改必须永久生效。
事务隔离级别:
- 读未提交 read uncommited :A线程可以读取到B线程未提交的数据,这个叫做脏读
- 读已提交 read commited : A线程跑的时候,先查询一个值为1,这时候B将这条记录改为2,并提交了事务,此时A再次查询该条记录的时候就发现变为2,这个问题叫做不可重复读
- 可重复读 read repeatable :A线程在运行过程中,对于某个数据的值,无论读多少次都不会改变,哪怕B线程修改了该值并提交了事务。
- 串行化 : 不可重复读和可重复读都存在幻读的问题,假设表中只有一条数据,事务A查询全表查询一条数据,这时候事务B插入一条记录,事务A再次查询出现了两条。如果要解决幻读,就需要使用串行化隔离级别的事务,将多个事务串行起来,不允许多个事务并发操作
MVCC :多版本并发控制
- innodb在存储的时候,会在每行数据的最后加两个隐藏列,创建时间和失效时间,保存的值都是事务的id,innodb事务开始的时候都会被分配到一个事务id,依次递增
- 一个事务在查询的时候,innodb只会查询创建时间事务id<当前事务id,并且失效时间 > 当前事务的id的数据
- 当执行update操作的时候,innodb实际上将原有列的失效时间覆盖,然后新增一条创建时间为当前事务id的数据
- update操作表里肯定还是一条数据,那么事务是怎么查到之前的版本的呢?更新的时候都会在undo.log中记录一条对应版本回滚记录,然后我们只要根据当前事务id对当前值进行回滚操作,就可以看到我们应该看到的数据了。
12、数据库锁有哪些类型?锁是如何实现的?行级锁有哪两种?一定会锁定指定的行吗?为什么?悲观锁?乐观锁?使用场景是什么?mysql死锁原理以及如何解决?
- mysql锁类型一般就是表锁,行锁和页锁
- 表锁 : 意向共享锁:就是加共享锁的时候,必须先加这个共享表锁;还有一个意向排他锁,就是给某行加排他锁的时候,必须先给表加排他锁。这个表锁是引擎自动加的
- innodb行锁有共享锁(S)和排他锁(X)两种,多个事务可以加共享锁读同一行数据,但是别的事务不能写。排他锁就是一个事务可以写,别的事务只能读不能写。
- innodb在insert、delete、update的时候会自动给那一行加排他锁
- innodb不会自己主动加共享锁 ,必须自己手动加: select * from table where id = 5 lock in share mode
- 手动加排他锁 : select * from table where id = 5 for update;
悲观锁和乐观锁
- 悲观锁:总是害怕拿不到锁,总是先加锁
- 乐观锁:先查出来一条数据,修改的时候查看数据库是不是还是那个版本,如果还是那个版本就修改。不然就重新查出来再修改
死锁:
场景:
- 事务A : select * from table where id = 1 for update;
- 事务B : select * from table where id = 2 for update;
- 事务A : select * from table where id = 2 for update;
- 事务B : select * from table where id = 1 for update;
持有对方的锁,gg
解决方案 : 找下dba查一下死锁的日志
13、mysql优化
explain select * from table;
- table : 哪个表
- type(重要):
- all:全表扫描
- const : 读常量,最多一条记录匹配
- eq_ref : 走主键,一般最多一条记录匹配
- index :扫描全部索引
- range : 扫描部分索引
- possiable_keys : 显示可能使用的索引
- key : 实际使用的所以
- key_len : 使用索引的长度
- ref :联合索引的哪一列被用
- rows : 一共扫描和返回了多少行
- extra :
- using filesort :需要额外排序
- using temporary :构建了临时表,比如排序的时候。 using temporary常见于group by会出现,这种情况是最不能忍受的。因为创建临时表会需要消耗很大的时间,也是导致sql变慢的主要原因
- using where :就是根据索引出来的数据再次根据where来过滤结果
14、什么情况下会进入老年代?
- 熬过默认的15次垃圾回收
- 垃圾回收的时候s区放不下就进入老年代
- 大对象进入老年代

 浙公网安备 33010602011771号
浙公网安备 33010602011771号