

github链接:https://github.com/Tomgao4116/3123004304
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/gdgy/Class12Grade23ComputerScience |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/gdgy/Class12Grade23ComputerScience/homework/13468 |
| 这个作业的目标 | 实现一个论文查重程序,规范软件开发流程,熟悉Github进行源代码管理和学习软件测试 |
一,PSP表格:
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 10 | 10 |
| Estimate | 估计这个任务需要多少时间 | 200 | 300 |
| Development | 开发 | 10 | 10 |
| Analysis | 需求分析 (包括学习新技术) | 20 | 20 |
| Design Spec | 生成设计文档 | 10 | 5 |
| Design Review | 设计复审 | 20 | 40 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 60 | 40 |
| Design | 具体设计 | 20 | 70 |
| Coding | 具体编码 | 100 | 100 |
| Code Review | 代码复审 | 50 | 50 |
| Test | 测试(自我测试,修改代码,提交修改) | 60 | 60 |
| Reporting | 报告 | 40 | 120 |
| Test Report | 测试报告 | 30 | 60 |
| Size Measurement | 计算工作量 | 40 | 80 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 40 | 30 |
| 合计 | 810 | 995 |
二,计算模块接口的设计与实现过程:
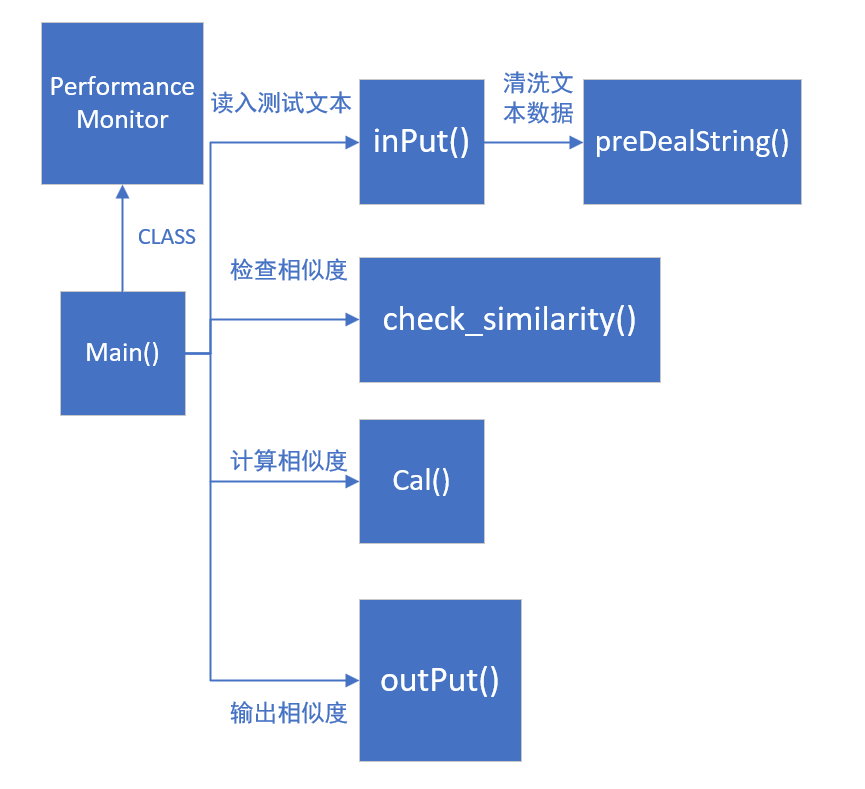
本次任务的核心是设计一个论文查重算法,实现该算法程序的核心函数模块与调用关系如下:
1:核心模块函数
| 模块名称 | 函数名称 | 函数功能 |
|---|---|---|
| 主函数 | main() | 主函数,作为核心模块调用其他函数 |
| 数据结构初始化 | initMap() | 对map进行初始化,为中文标点符号打上标记,方便后续判断去重 |
| 文本输入 | inPut() | 从指定路径文件中读入对应的数据 |
| 答案输出 | outPut() | 把答案输出到指定路径的文件上 |
| 文本预处理 | preDealString() | 对读入的文件数据进行预处理,通过哈希与离散化清洗数据 |
| LCS计算 | check_similarity() | 对处理好的数据求解LCS,求解两文本之间相似度 |
| 相似度计算 | cal() | 根据LCS计算文本相似度 |
2:模块调用关系
3:核心模块实现过程
1:文本数据清洗:
点击查看代码
//对读入的文件数据进行预处理:去除标点符号+空格,只保留汉字,利用Hash加密后:进行离散化处理;
void preDealString(string x,ll op){
for(int i=0;i<x.size();){
if((x[i]&0xF0) == 0xE0){
string v=x.substr(i,3);
ull hash=v[0]*p*p+v[1]*p+v[2];
if(vis[hash]){
i+=3;
continue;
}
if(!mp[hash]){
cnt++;
mp[hash]=cnt;
}
if(op==1){
sum1++;
a.push_back(mp[hash]);
}else{
sum2++;
b.push_back(mp[hash]);
}
i+=3;
}else{
i++;
}
}
}
2:求解LCS:
点击查看代码
//利用DP:LCS求出二者的相似度:
ll check_similarity() {
ll len1 = a.size(),len2=b.size();
for(ll i = 1; i <= len1; i++) {
for(ll j = 1; j <= len2; j++) {
ll v=(i%2);
if(a[i-1] == b[j-1])
dp[v][j] = max(dp[v][j], dp[v^1][j-1] + 1);
else
dp[v][j] = max(dp[v][j], max(dp[v^1][j], dp[v][j-1]));
}
}
return dp[len1%2][len2];
}
3:计算文本相似度:
点击查看代码
//计算两篇论文相似度:
db cal(ll s1,ll v1){
db x1=s1,y1=v1;
if(x1==0)return 0;
return y1/x1;
}
三,算法设计分析
1:算法设计核心流程:
1:从指定路径的文件中读取数据文本
2:把读入原始文本与测试文本进行清洗,去除无意义的空格与标点符号,把汉字进行哈希处理,并将其离散化后装入对应数组中
3:对装入对应数组的数据求解LCS,根据求出的结果计算文本相似度
(文本相似度=LCS长度/原始文本长度)
4:将测试结果输出到对应输出文件中保存
2:算法核心实现:
1:对汉字进行哈希离散化处理:
把单个汉字抽取出,设计哈希函数:hash= app+b*p+c 先进行哈希,将汉字对应的哈希值存入map记录下来,给每个不同的汉字赋予一个对应的hash值与离散化后的值作为标签cnt,如果之后遍历map中查找到该汉字记录,其离散化后的值就为其mapHash中存储的值,否则cnt++为其赋予一个新的标签.
(汉字通过UTF-8编码读入存入字符串中,字符串中连续三个位置a,b,c对应一个汉字, p=1313131)
2:求解LCS最长公共子序列:
考虑设计dp状态:dp[i][j]:表示考虑a的前i个位置与B的前j个位置的最长公共子序列
dp状态转移方程:
- dp[i][j]=max(dp[i][j],dp[i-1][j-1]+1) [a[i-1]==b[j-1]]
- dp[i][j]=max(dp[i][j],dp[i-1][j],dp[i][j-1]) [a[i-1]!=b[j-1]]
3:算法独道之处:
- 应用性强:支持对所有文本字符的清洗处理,包括中文字符,英文字符,数字字符等
- 无依赖:纯 JDK 实现,无需第三方库,便于部署
- 可靠性高,算法通过先哈希与离散化的方式预处理所有数据,设计的哈希函数强度高,能够在字符数目大的情况正常运行 (n<=10^7)
4:算法复杂度分析:
- 时间复杂度:O(n^2) for循环最内层最耗时语句为dp的状态转移方程
- 空间复杂度:O(n)
四,计算模块接口性能改进
1. 性能分析:
2. 空间优化:
空间复杂度:O(n) 如果不使用滚动数组优化处理复杂度可达O(n^2),通过滚动数组优化复杂度可降至O(n)
滚动数组优化方式:
原转移方程:需要n^2的空间:
点击查看代码
for(ll i = 1; i <= len1; i++) {
for(ll j = 1; j <= len2; j++) {
ll v=(i%2);
if(a[i-1] == b[j-1])
dp[v][j] = max(dp[v][j], dp[v^1][j-1] + 1);
else
dp[v][j] = max(dp[v][j], max(dp[v^1][j], dp[v][j-1]));
}
}
return dp[len1%2][len2];
点击查看代码
for(ll i = 1; i <= len1; i++) {
for(ll j = 1; j <= len2; j++) {
ll v=(i%2);
if(a[i-1] == b[j-1])
dp[i][j] = max(dp[i][j], dp[i-1][j-1] + 1);
else
dp[i][j] = max(dp[i][j], max(dp[i-1][j], dp[i][j-1]));
}
}
return dp[len1][len2];
3. 时间优化:
| 核心模块功能 | 对应函数 | 耗时占比 |
|---|---|---|
| 文本读入 | inPut() | 12% |
| 文本清洗 | preDealString() | 12% |
| 求解LCS | check_similarity | 75% |
| 计算结果 | cal() | 1% |
根据表格分析:程序消耗最大的函数即为求解LCS的check_Similarity()
代码:
点击查看代码
//利用DP:LCS求出二者的相似度:
ll check_similarity() {
ll len1 = a.size(),len2=b.size();
for(ll i = 1; i <= len1; i++) {
for(ll j = 1; j <= len2; j++) {
ll v=(i%2);
if(a[i-1] == b[j-1])
dp[v][j] = max(dp[v][j], dp[v^1][j-1] + 1);
else
dp[v][j] = max(dp[v][j], max(dp[v^1][j], dp[v][j-1]));
}
}
return dp[len1%2][len2];
}
原因:需要遍历两个文本之间所有字符串并同时枚举每一个位置
优化方法:
- 通过把unordered_map修改为map,降低常数大小,提高运行效率
点击查看代码
map<ull,ll> mp;
map<ull,ll> vis;
- 关停同步输入输出流:减少因为数据读入产生的耗时
点击查看代码
ios::sync_with_stdio(false);cin.tie(0);cout.tie(0);
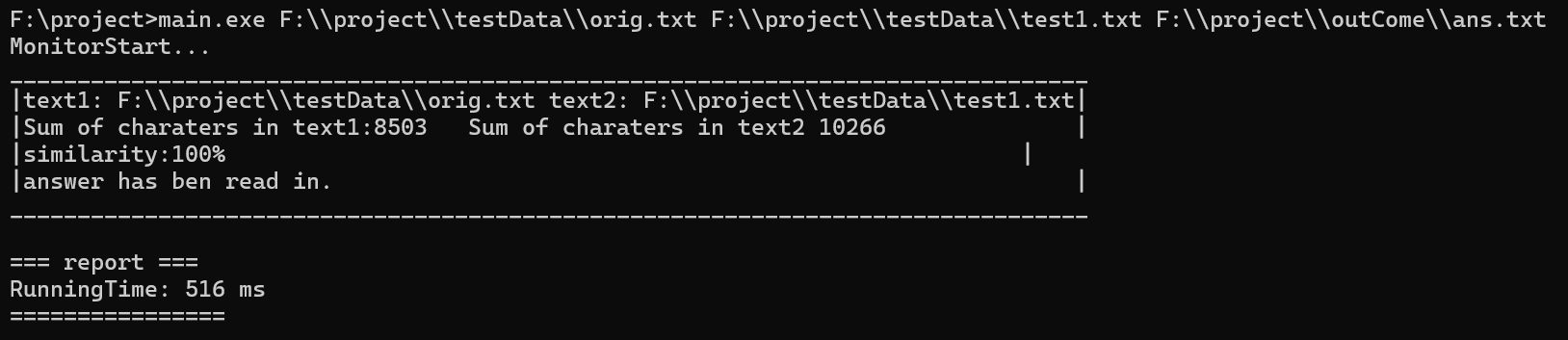
进行优化之后运行测试结果:
通过优化提升,运行
五 ,模块单元测试情况
1:测试数据构造思路:
·边界测试:针对空文本、极端参数、边界值(如全 0 哈希)设计测试样例
·等价类划分:将输入分为有效输入、无效输入、边界输入等等价类
·场景覆盖:覆盖正常处理、异常处理、边界条件等场景
2:测试数据组成:
- 部分匹配:构造有部分重叠内容的中文字符串(如L"中国上海北京"和L"上海北京广州"),测试部分匹配时的最长公共子序列长度计算。
- 完全不匹配:构造无任何重叠内容的中文字符串(如L"苹果香蕉"和L"西瓜橙子"),验证此时最长公共子序列长度为 0。
- 空字符串场景:分别构造一个字符串为空、另一个不为空以及两个都为空的情况,测试边界条件下的函数行为。
| 原始文本 | 测试文本 |
|---|---|
| orig.txt | test1.txt |
| test2.txt | |
| test3.txt | |
| test4.txt | |
| test5.txt |
| 原始文本 | 测试文本 |
|---|---|
| orig2.txt | test6.txt |
| 原始文本 | 测试文本 |
|---|---|
| orig3.txt | test7.txt |
| test8.txt | |
| test9.txt | |
| test10.txt |
3:部分测试结果展示:
所有测试数据均已上传至github仓库
test1,test2原始文本为orig.txt,测试数据对应原有orig_0.8_add.txt与orig_dis_1.txt文件
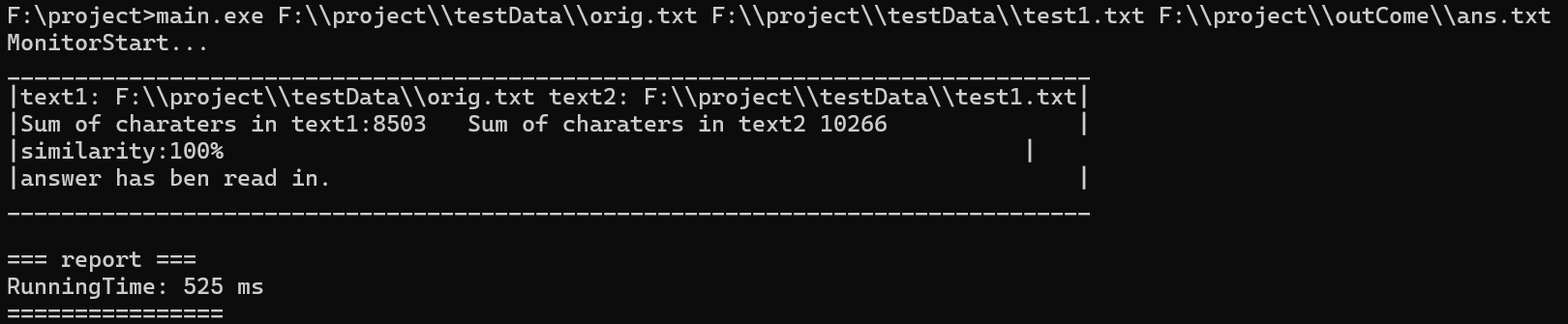
test1:
预期结果:85-95%
test2:
预期结果:75-80%
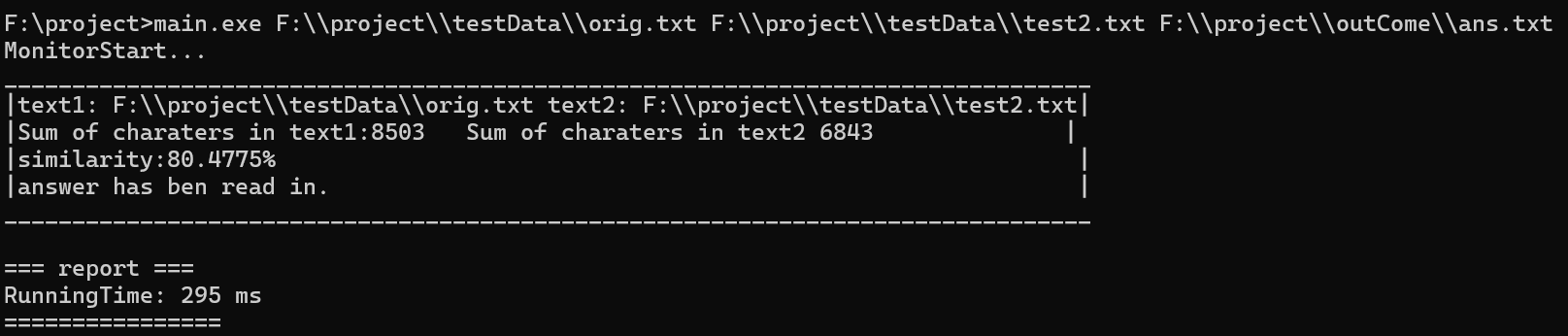
test6:
原始文本:今天天气晴朗,适合户外运动。
测试文本:
预期结果:90-100%
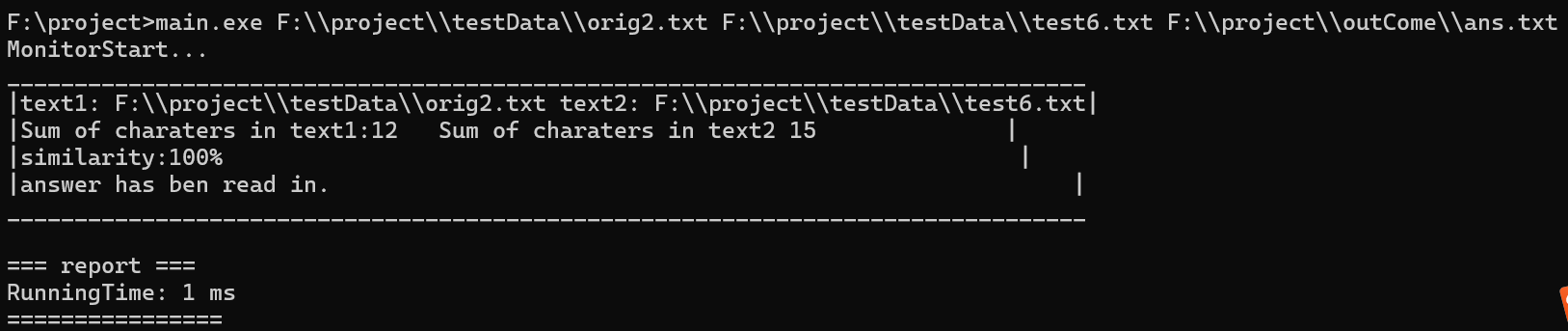
test9:
原始文本:深度学习需要大量计算资源
测试文本:(空字符串)
预期结果:0%
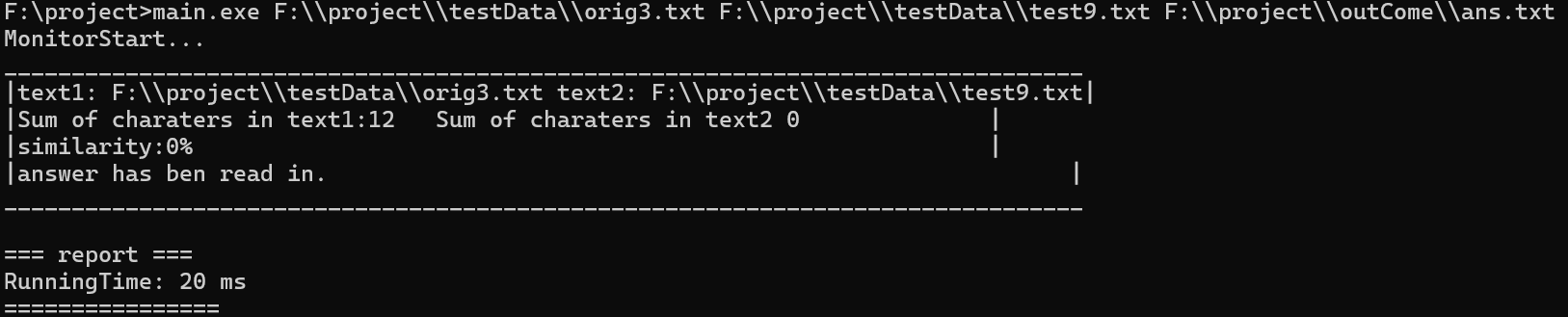
test10:
原始文本:
深度学习需要大量计算资源
测试文本:
wefqwfcjfcqwpocmwermooeoxrcwiwqxwcojiwox qweqfqw qwefwefqf 全微分轻微发热qwfgew
wfgreer reerg wtpgw rogjiowjg tc n to rtiorthrthrhtyj[]ty[];][yu;];t[y]mrtynep45g45bwt brwh
预期结果:0%
4:结论:测试结果符合预期,全部通过:
六,程序异常处理
1. 文件路径转换异常处理
设计目标:main函数传入路径参数错误时能够及时捕获该错误,提示用户路径转换存在问题,避免因路径问题导致后续文件操作(如打开、读取、写入文件)出现错误。
测试代码:
点击查看代码
// 检查命令行参数
if(argc != 4){
cout<< "formal: " << argv[0] << " <originRoad> <copyRoad> <outPutRoad>" << endl;
return 1;
}
2.文件打开异常处理
设计目标:在inPut函数与outPut函数打开文件时,若返回错误码非 0,能够及时告知用户无法打开文件,方便用户排查文件是否存在、文件权限等问题。
测试代码:
点击查看代码
ifstream file1,file2;
file1.open(s1);
file2.open(s2);
if(!file1.is_open()||!file2.is_open()) {
cout << "Can not open the file!" << endl;
return 1;
}
3:计算异常情况处理:
设计目标:当给予比对的文本有出现空字符串的时候,不相似度应返回0,防止程序运行出现RunTime Error的错误
测试代码:
点击查看代码
db cal(ll s1,ll v1){
db x1=s1,y1=v1;
if(x1==0)return 0;
return y1/x1;
}
七,项目总结与思考
1:结论:
- 设计要求:能按要求完成所有功能,命令行参数读入路径,检查文本相似度,并将结果存储到文件中
- 正确性:单元测试考虑绝大多数情况,测试样例正确性100%;
- 性能优化:经过输入输出读入等优化,程序运行提速约40-50ms;内存通过滚动数组占用内存进一步减少;
2:进一步改进的空间:
- 可读性可以增强:在 README 里加 阈值示例(相似度 ≥0.8 视为重复)和几条真实样例;
- 语义可以变得更稳:加入同义词/常见替换的小表(如“星期/周”),减少表面改写带来的相似度波动。
- 可以去除重复无用的语义:对于“的了吗么呢”等助词与语气副词,在文本相似度查询中无关紧要,咋文本清洗中可以考虑降低权重或者清除滤过

 浙公网安备 33010602011771号
浙公网安备 33010602011771号