戴焕曾---第二次作业
| 这个作业属于哪个课程 | 至诚软工实践F班 |
|---|---|
| 这个作业要求在哪里 | 第二次作业:个人编程 |
| 这个作业的目标 | 学习并争取掌握抓包技术 |
| Github 地址 | https://github.com/TnTdhz/212106706Lesson2 |
1.必做题:朴朴商品信息获取
-
解题思考
这次作业的主要考察内容是抓取页面内容,我以前没做过抓包,对于整体的知识了解也甚少。
1. 首先我考虑的是先了解我们抓取的究竟为何物,是整个页面的源代码还是像存放在数据库里的数据?后经过请教班级里了解的同学,才知道原来这道题需要处理的是JSON数据格式的数据,通过百度,我了解到更多关于JSON的相关知识,其中最重要的是他的书写格式:名称/值对。
1. 了解了我们需要处理的数据后,接下来考虑如何获取,通过助教们提供的资料,我知道了大概的方法,使用Fildder对http请求抓取,然后对抓取到的信息进行筛选,其中需要用到的就是RAW和JSON,在Filder点击之后,可以很直观的看到这两个数据,RAW中的数据是我们要访问网站的网址和一些请求属性,JSON已经通过可视化图来帮助我们辨别是否抓取的是正确的网站。
-
解题准备
在语言方面上,老师说不限制语言,由于我目前只学过Java,所以我决定用Java语言来完成这一次作业。抓取的朴朴网页用微信的PC端的小程序打开,并借助一些在线工具来完成此次作业。
软件:IDEA、微信PC端、Filder、Edge
-
解题过程
-
第一步,首先,我在使用Filder尝试第一次抓取时,一打开软件就会断开校园网,后来仔细阅读课件的PPT后才知道,原来Filder的代理会把校园网给挤掉,因为校园网也是代理。后来,我用自己手机开热点,才成功,并找到了自己想要抓取的网页的信息,通过JSON看到它对应的KEY和值。
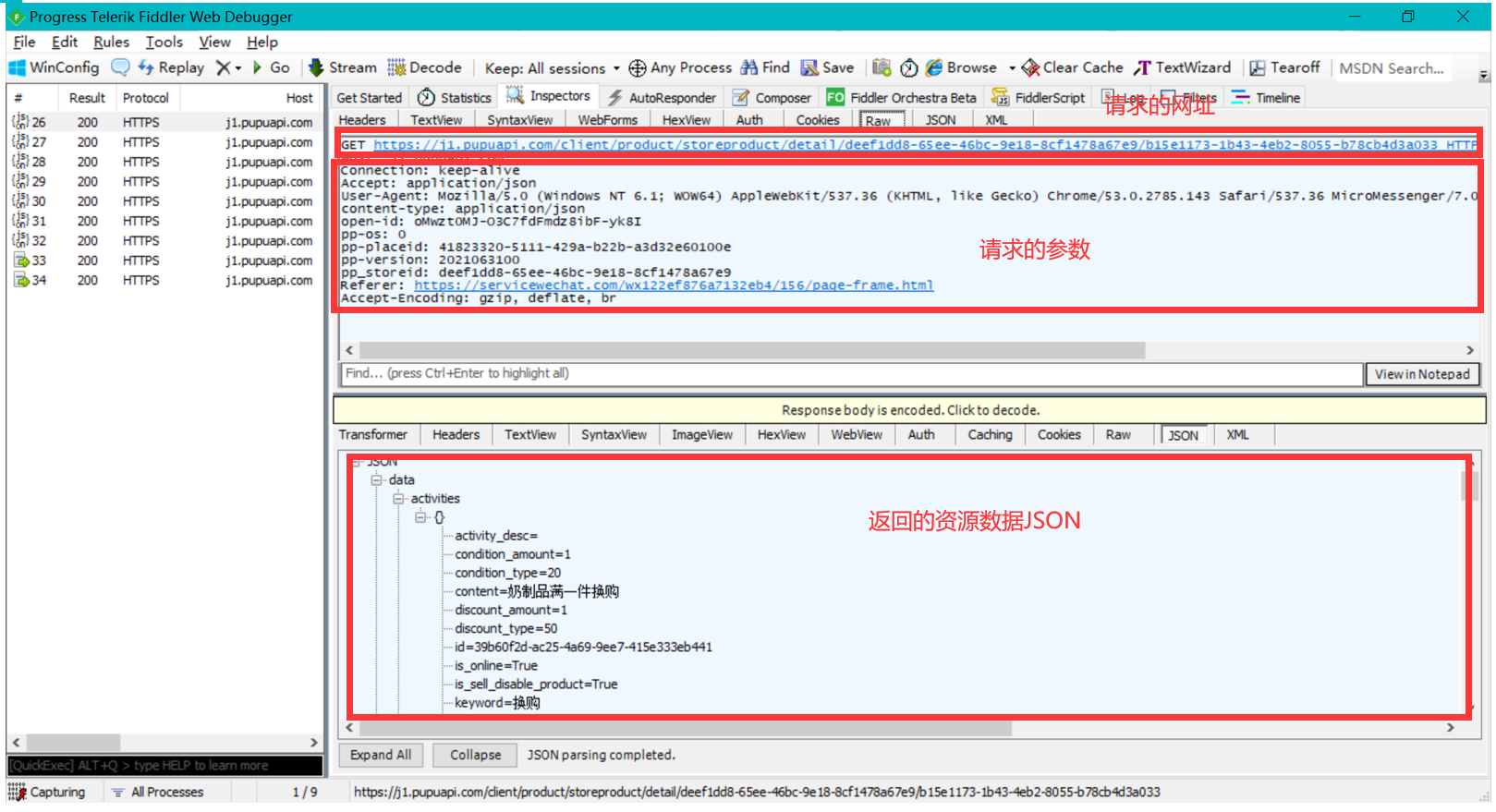
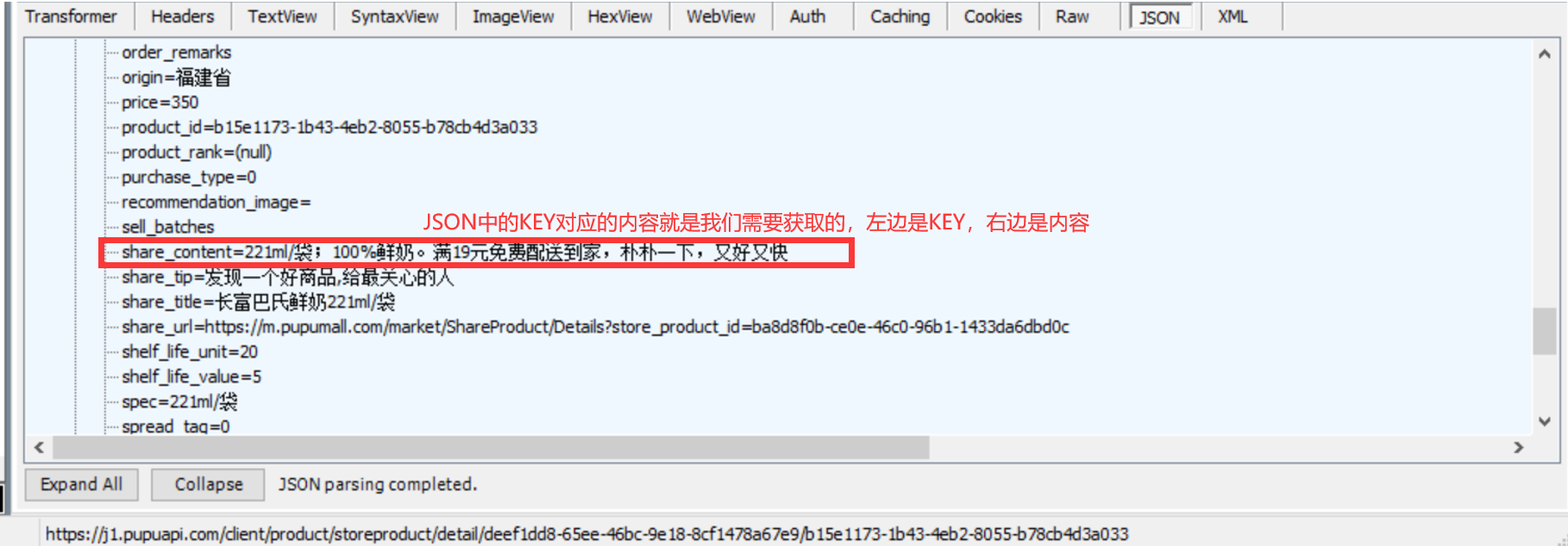
-
第二步,接下来开始在Java里面写代码,通过百度了解到Java有提供专门向指定URL发送GET方法的请求的方法,写出Java代码之后,我先将获取到的远程资源的响应结果在控制台输出,更详细的代码与说明在后文有上传。
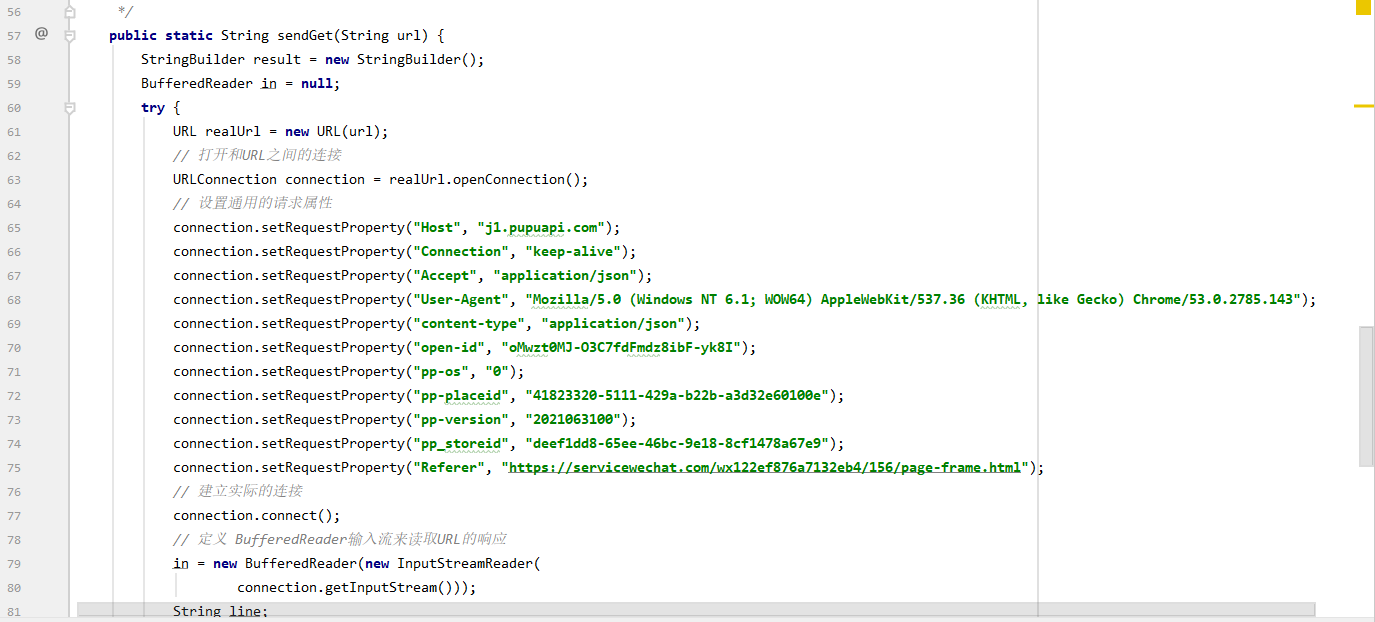

-
第三步,原本的方法是打算用正则表达匹配出我想要的内容,后来经过反复思考,发现若使用正则表达式来匹配,那么会遇到如下几个问题:
1.按照KEY来匹配的话,JSON中相同名字的KEY可能不止一个。
2.在JSON数据里也有可能包含原本不是这个含义的相同字符的数据,那么匹配出来也可能导致错误。
最后才通过百度得知如何将返回的数据进行处理,由于返回的是JSON数据,Java需要借助第三方类库,在导入依赖包后,就可以使用JSONObject新建一个JSON对象了,通过JSONSerializer.toJSON()方法可以将获取到的字符串转换为JSON对象,再使用getJSONObject()方法能获取JSON中的KEY对应的JSON对象;更详细的代码与说明在后文有上传。

最后通过getString()方法就可以提取JSON对象中KEy对应的值;

-
解题答案与代码
-
Commit截图
-
成果展示
-
代码展示
点击查看代码
import net.sf.json.JSONObject;
import net.sf.json.JSONSerializer;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.net.URL;
import java.net.URLConnection;
import java.time.LocalDateTime;
public class Test {
/**
*主方法
* @param args
*/
public static void main(String[] args) throws InterruptedException {
for(int i=1;i<10;i++) {
//实例化一个LocalDate来获取现在的时间
LocalDateTime now=LocalDateTime.now();
String url = "https://j1.pupuapi.com/client/product/storeproduct/detail/deef1dd8-65ee-46bc-9e18-8cf1478a67e9/b15e1173-1b43-4eb2-8055-b78cb4d3a033 ";
String value = sendGet(url);
//分析json的格式,得到一个json对象
JSONObject json = (JSONObject) JSONSerializer.toJSON(value);
JSONObject data = json.getJSONObject("data");
//若JSON数据包含数组,可以解析来获取一个JSOn数组
// JSONArray array = data.getJSONArray("products");
// JSONObject yumo = array.getJSONObject(1);
//通过查找Key来获取相应的数值
String name = data.getString("name");
String price = data.getString("market_price");
double realprice = Double.parseDouble(price) / 100;
String guige = data.getString("spec");
String custom_tag_text = data.getString("share_content");
//控制台展示效果
if(i==1) {
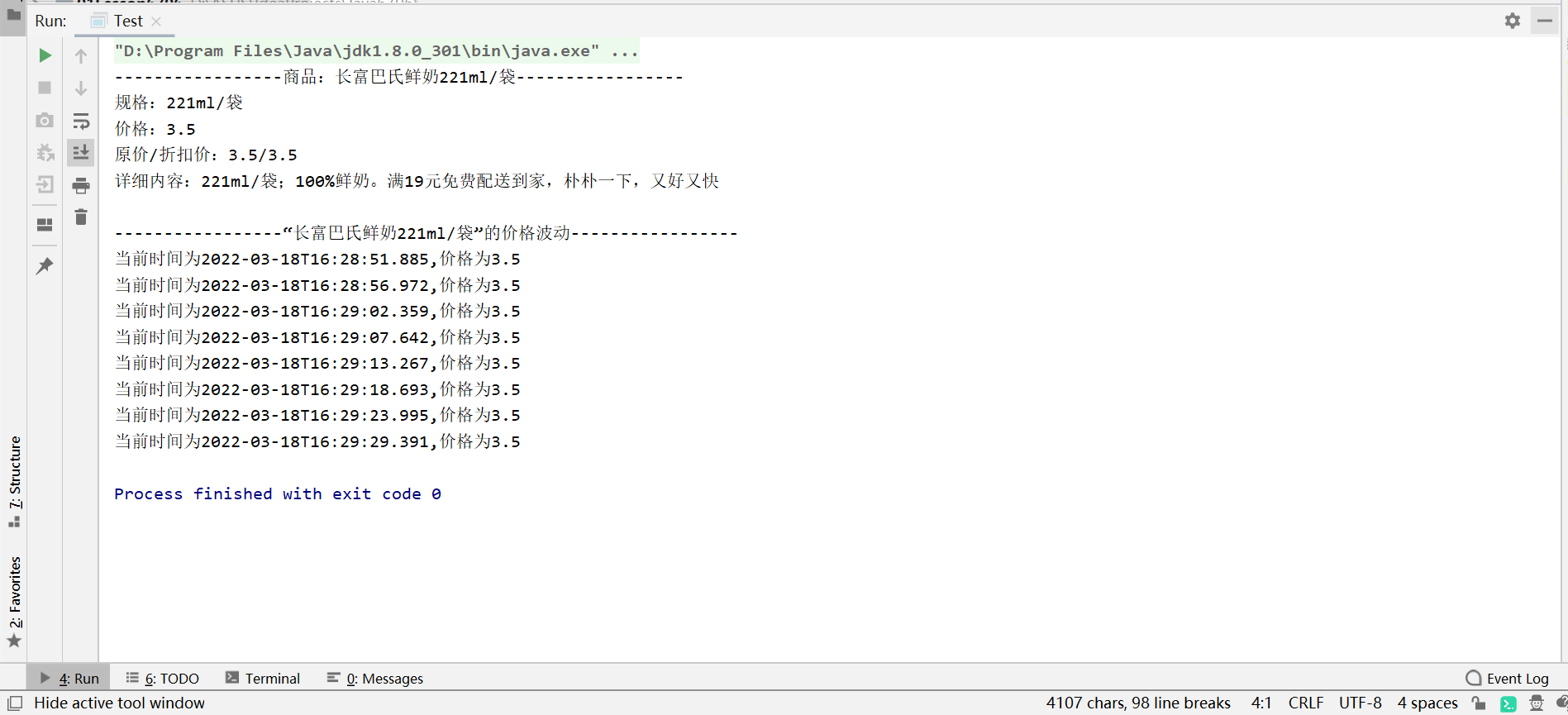
System.out.println("-----------------商品:" + name + "-----------------");
System.out.println("规格:" + guige);
System.out.println("价格:" + realprice);
System.out.println("原价/折扣价:" + realprice + "/" + realprice);
System.out.println("详细内容:" + custom_tag_text);
System.out.println();
System.out.println("-----------------“" + name + "”的价格波动-----------------");
}else{
//通过设置延时5秒来获取不同时间的商品价格
Thread.sleep(5000);
System.out.println("当前时间为"+now+",价格为"+realprice);
}
}
}
/**
* 调用GET接口访问朴朴的网站
* @param url 链接网址
* @return 获取的JSON
*/
public static String sendGet(String url) {
StringBuilder result = new StringBuilder();
BufferedReader in = null;
try {
URL realUrl = new URL(url);
// 打开和URL之间的连接
URLConnection connection = realUrl.openConnection();
// 设置通用的请求属性
connection.setRequestProperty("Host", "j1.pupuapi.com");
connection.setRequestProperty("Connection", "keep-alive");
connection.setRequestProperty("Accept", "application/json");
connection.setRequestProperty("User-Agent", "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143");
connection.setRequestProperty("content-type", "application/json");
connection.setRequestProperty("open-id", "oMwzt0MJ-O3C7fdFmdz8ibF-yk8I");
connection.setRequestProperty("pp-os", "0");
connection.setRequestProperty("pp-placeid", "41823320-5111-429a-b22b-a3d32e60100e");
connection.setRequestProperty("pp-version", "2021063100");
connection.setRequestProperty("pp_storeid", "deef1dd8-65ee-46bc-9e18-8cf1478a67e9");
connection.setRequestProperty("Referer", "https://servicewechat.com/wx122ef876a7132eb4/156/page-frame.html");
// 建立实际的连接
connection.connect();
// 定义 BufferedReader输入流来读取URL的响应
in = new BufferedReader(new InputStreamReader(
connection.getInputStream()));
String line;
while ((line = in.readLine()) != null) {
result.append(line);
}
} catch (Exception e) {
System.out.println("发送GET请求出现异常!" + e);
e.printStackTrace();
}
// 使用finally块来关闭输入流
finally {
try {
if (in != null) {
in.close();
}
} catch (Exception e2) {
e2.printStackTrace();
}
}
return result.toString();
}
}
-
优化改进
这次作业在方法上的优化改进暂时没有思绪,但是程序已经优化改进过代码的规范以及模块化。
2.选做题:知乎收藏夹信息获取
-
解题思考
经过第一个抓取朴朴的作业,我觉得这次的作业应该原理上相同,过程中应该不会那么困难,但在我第一次尝试抓取的时候,发现在收藏夹的页面并没办法通过JSON数据来获取想要的信息,因此我需要从另外的途径来获取想要的信息。 -
解题准备
在语言方面上,老师说不限制语言,由于我目前只学过Java,所以我决定用Java语言来完成这一次作业。抓取的朴朴网页用微信的PC端的小程序打开,并借助一些在线工具来完成此次作业。
软件:IDEA、Filder、Edge -
解题过程
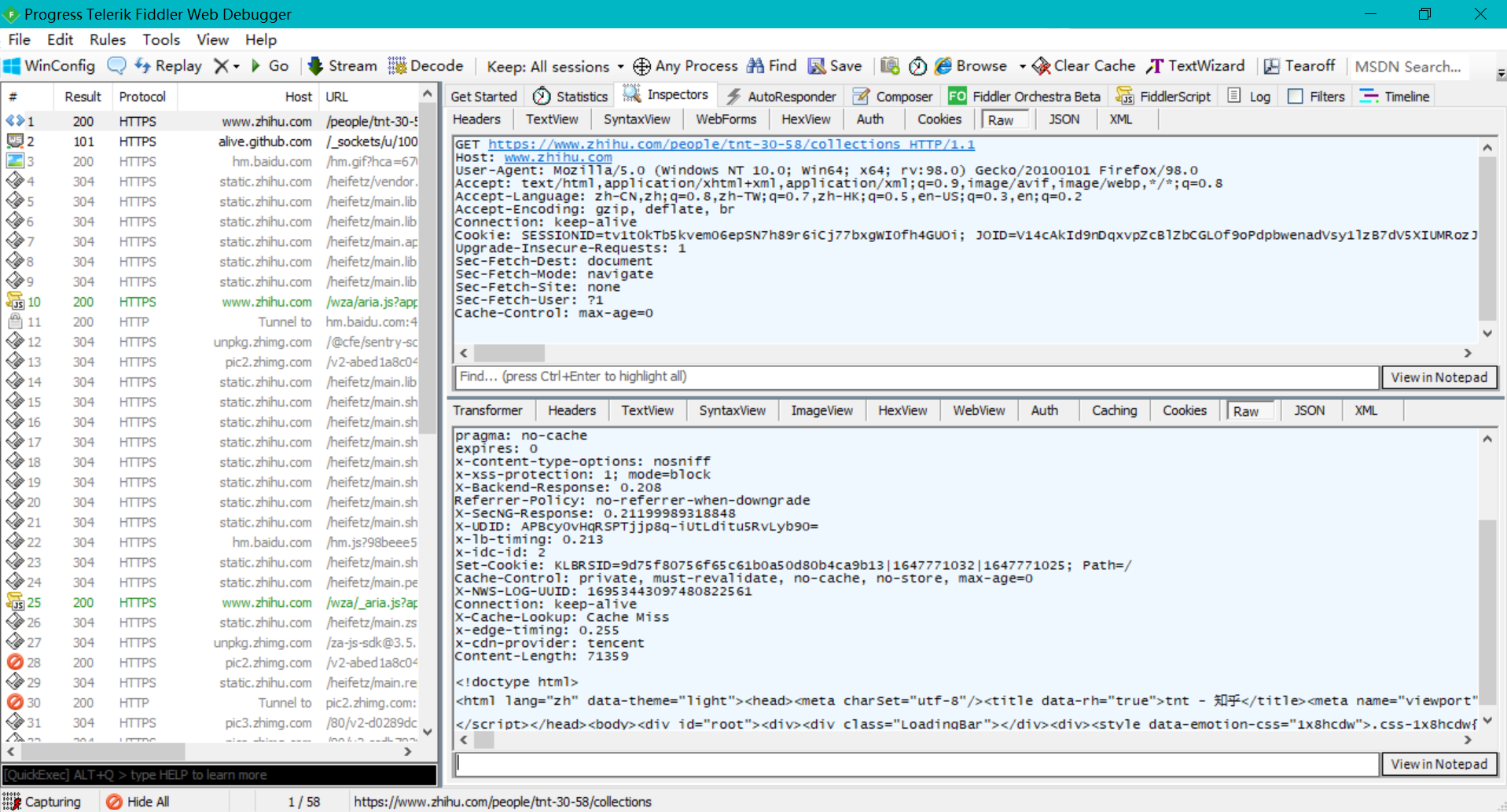
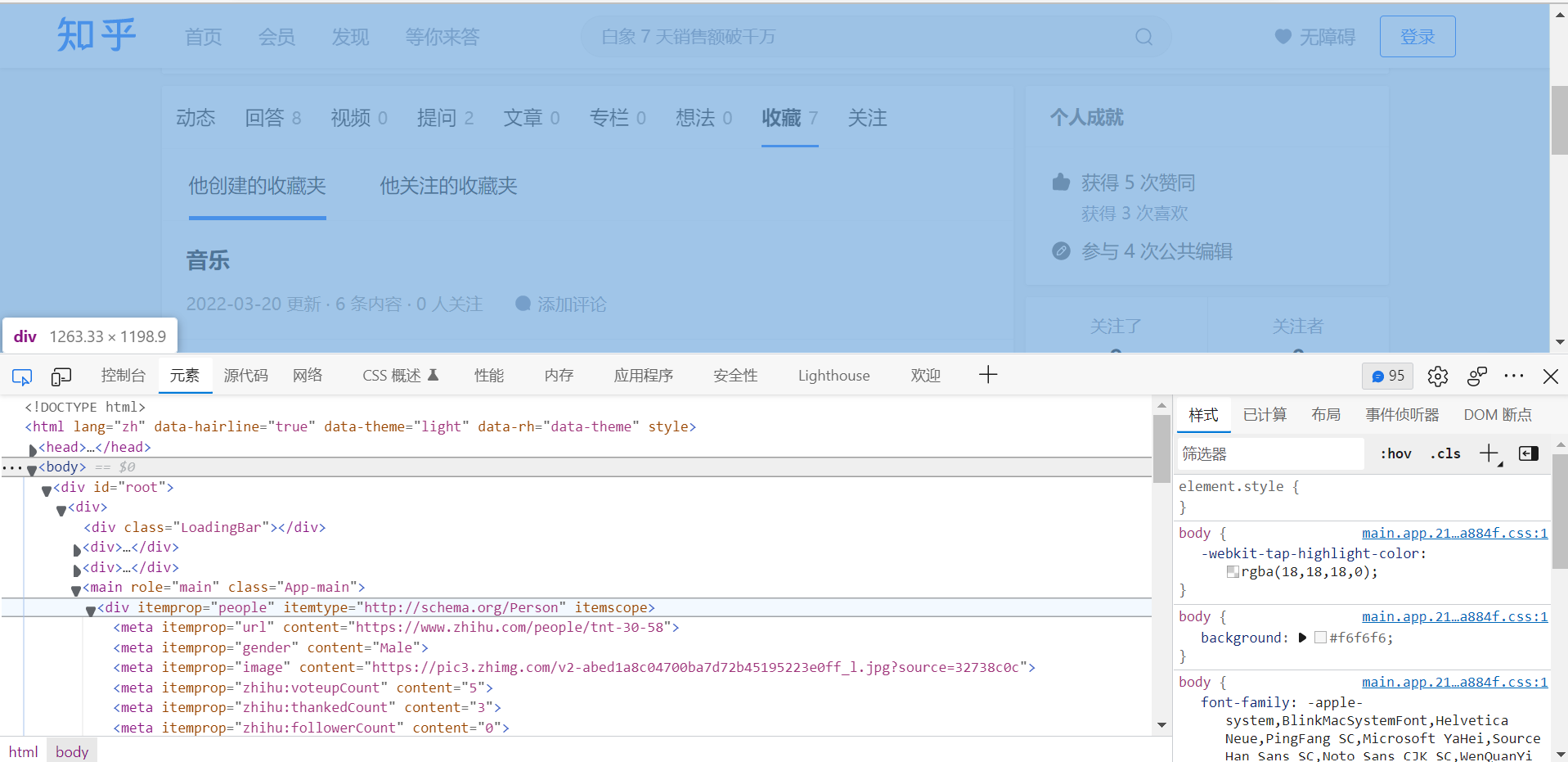
- 第一步,首先还是使用Fiddler抓取知乎的收藏夹页面,经过我的寻找,才知道我们需要得到的信息放在知乎收藏夹页面的Html代码当中,同时我在浏览器按F12观察页面,观察到想获取的信息的确是在Html代码中,在Fiddler通i过进一步搜索获取的html内容进一步验证了这是对的。
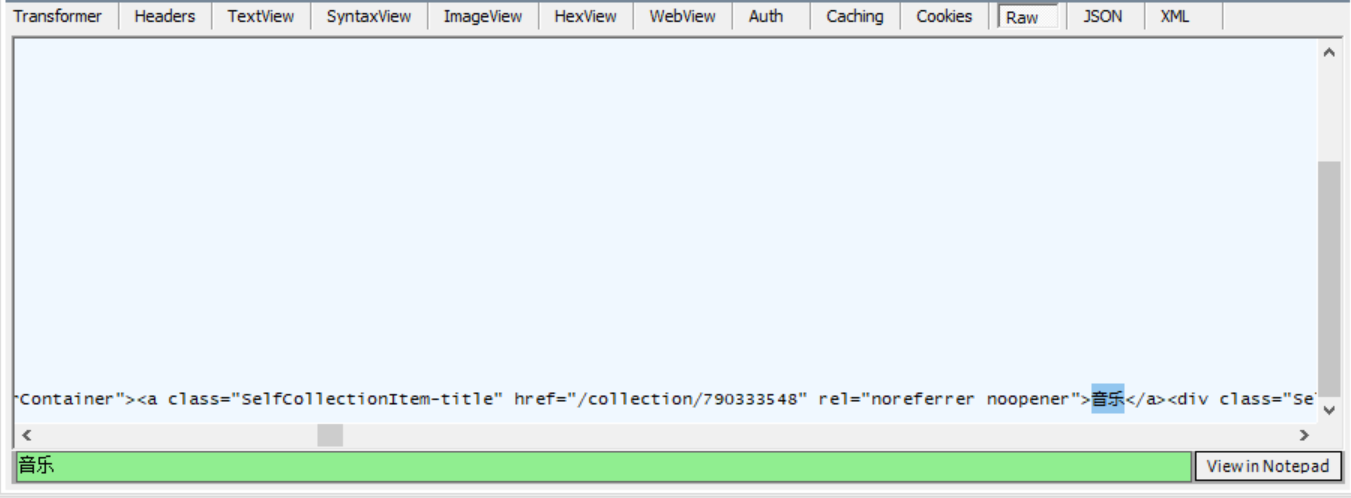
-
第二步,既然此次获取的知乎收藏夹信息是在Html里,那么Java的程序也应该有所改变,因为获取的不是JSON数据。通过百度了解到,Java要通过接口访问数据,获取的内容是个标准的html格式,使用jsoup的方式获取页面元素值。要使用jsoup的方法需要去导入第三方的包。导入后,就可以通过Jsoup.parse()来解析访问链接获取标准的的Htnl字符串,再通过getElementsByClass()方法根据类名获取元素,getElementsByClass()方法返回的是Elements类型,里面存放了提取的所有元素,。在单个Element中有text()方法和attr()方法,text()是获取元素的内容,attr()是获取属性。更详细的代码与说明在后文有上传。


-
第三步,在进去到每个收藏夹后,要提取的信息还是一样在JSON数据里,那么与朴朴作业的提取方法一样,将返回的JSON数据进行处理,由于返回的是JSON数据,Java需要借助第三方类库,在导入依赖包后,就可以使用JSONObject新建一个JSON对象了,通过JSONSerializer.toJSON()方法可以将获取到的字符串转换为JSON对象,再使用getJSONObject()方法能获取JSON中的KEY对应的JSON对象。更详细的代码与说明在后文有上传。


-
解题答案与代码
-
Commit截图
-
成果展示
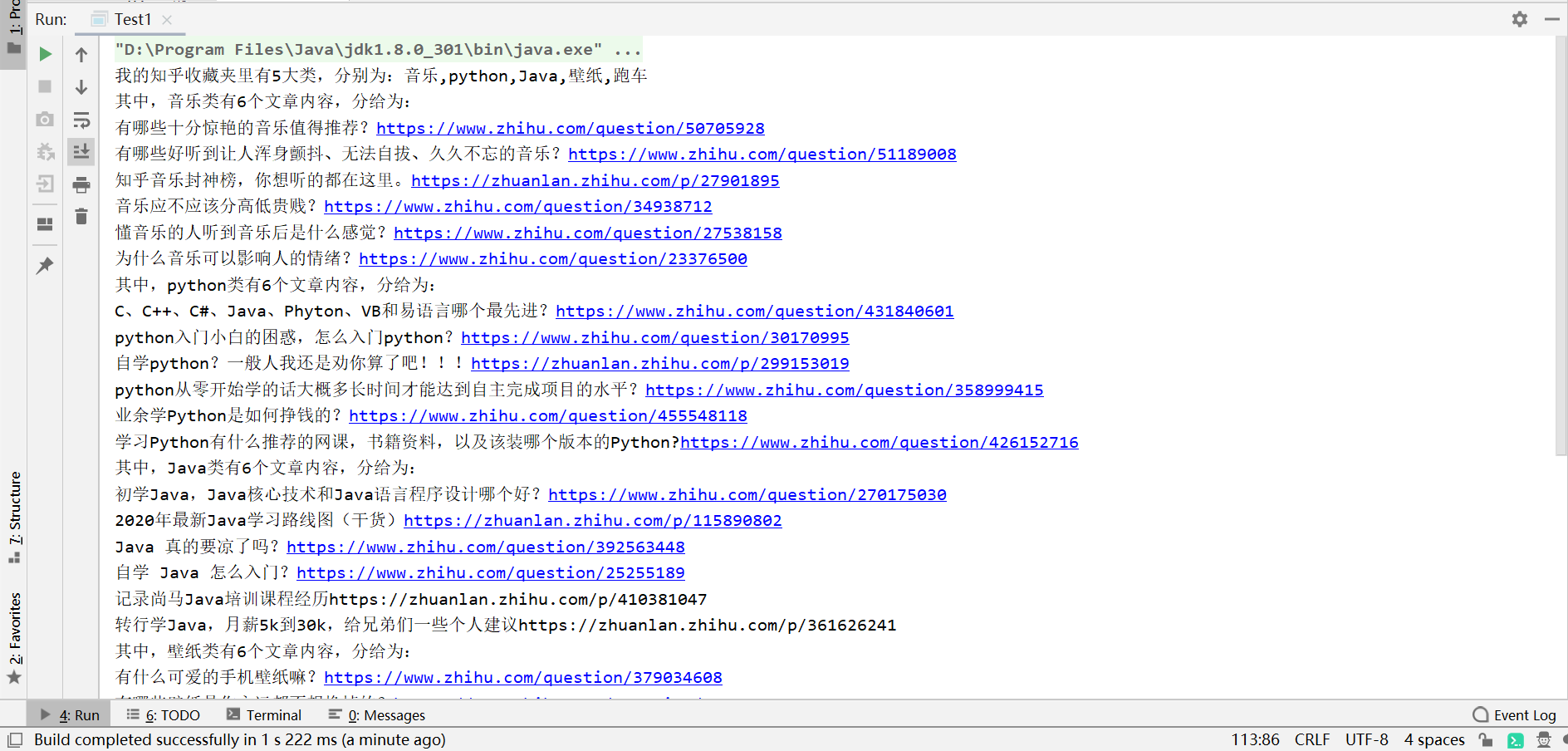
-
代码展示
getHtml()
点击查看代码
public static String getHtml(String url) {
StringBuilder result = new StringBuilder();
BufferedReader in = null;
try {
URL realUrl = new URL(url);
// 打开和URL之间的连接
URLConnection connection = realUrl.openConnection();
HttpURLConnection httpURLConnection = (HttpURLConnection) realUrl.openConnection();
// 建立实际的连接
httpURLConnection.connect();
// 定义 BufferedReader输入流来读取URL的响应
in = new BufferedReader(new InputStreamReader(
connection.getInputStream()));
String line;
while ((line = in.readLine()) != null) {
result.append(line);
}
} catch (Exception e) {
System.out.println("发送GET请求出现异常!" + e);
e.printStackTrace();
}
// 使用finally块来关闭输入流
finally {
try {
if (in != null) {
in.close();
}
} catch (Exception e2) {
e2.printStackTrace();
}
}
//将获取的Html数据保存在本地上
try (FileOutputStream fos = new FileOutputStream("E:\\Html.txt")) {
fos.write(result.toString().getBytes());
} catch (IOException e) {
e.printStackTrace();
}
return result.toString();
}
点击查看代码
public static String getJson(String url, int n) {
StringBuilder result = new StringBuilder();
BufferedReader in = null;
try {
URL realUrl = new URL(url);
// 打开和URL之间的连接
URLConnection connection = realUrl.openConnection();
// 建立实际的连接
connection.connect();
// 定义 BufferedReader输入流来读取URL的响应
in = new BufferedReader(new InputStreamReader(
connection.getInputStream()));
String line;
while ((line = in.readLine()) != null) {
result.append(line);
}
} catch (Exception e) {
System.out.println("发送GET请求出现异常!" + e);
e.printStackTrace();
}
// 使用finally块来关闭输入流
finally {
try {
if (in != null) {
in.close();
}
} catch (Exception e2) {
e2.printStackTrace();
}
}
//将获取的JSON数据保存在本地上
n++;
try (FileOutputStream fos = new FileOutputStream("E:\\Json" + n + ".txt")) {
fos.write(result.toString().getBytes());
} catch (IOException e) {
e.printStackTrace();
}
return result.toString();
}
点击查看代码
public static void showJson(Elements elements, String value, int n) {
//分析JSON的格式,得到一个JSON对象
JSONObject json = (JSONObject) JSONSerializer.toJSON(value);
//若JSON数据包含数组,可以解析来获取一个JSON数组
JSONArray array = json.getJSONArray("data");
System.out.println("其中," + elements.get(n).text() + "类有" + array.size() + "个文章内容,分给为:");
for (int num = 0; num < array.size(); num++) {
//再对JSON数组进行解析得到新的JSON对象
JSONObject jsonValue = array.getJSONObject(num);
JSONObject jsonContent = jsonValue.getJSONObject("content");
if (jsonContent.getString("title").length() > 1) {
System.out.println(jsonContent.getString("title") + jsonContent.getString("url"));
} else {
JSONObject jsonQuestion = jsonContent.getJSONObject("question");
System.out.println(jsonQuestion.getString("title") + jsonQuestion.getString("url"));
}
}
}
点击查看代码
public static void showHtml(Elements elements) {
System.out.print("我的知乎收藏夹里有" + elements.size() + "大类,分别为:");
int i = 0;
//遍历存放的元素,提取出标签的内容并展示在控制台
for (Element element : elements) {
if (i == 0) {
//输出的是标签的文本
System.out.print(element.text());
i = 1;
} else {
System.out.print("," + element.text());
}
}
System.out.println();
}
-
优化改进
在后续了解Jsoup后了解到,Jsoup可以从URL直接加载HTML文档,使用 Jsoup.connect(String url)方法,这样就不需要再创建额外的链接来获取Html文档,由于时间问题无法在提交的作业中体现更改,后续我会自己尝试改进一下。
