
07 2024 档案
摘要: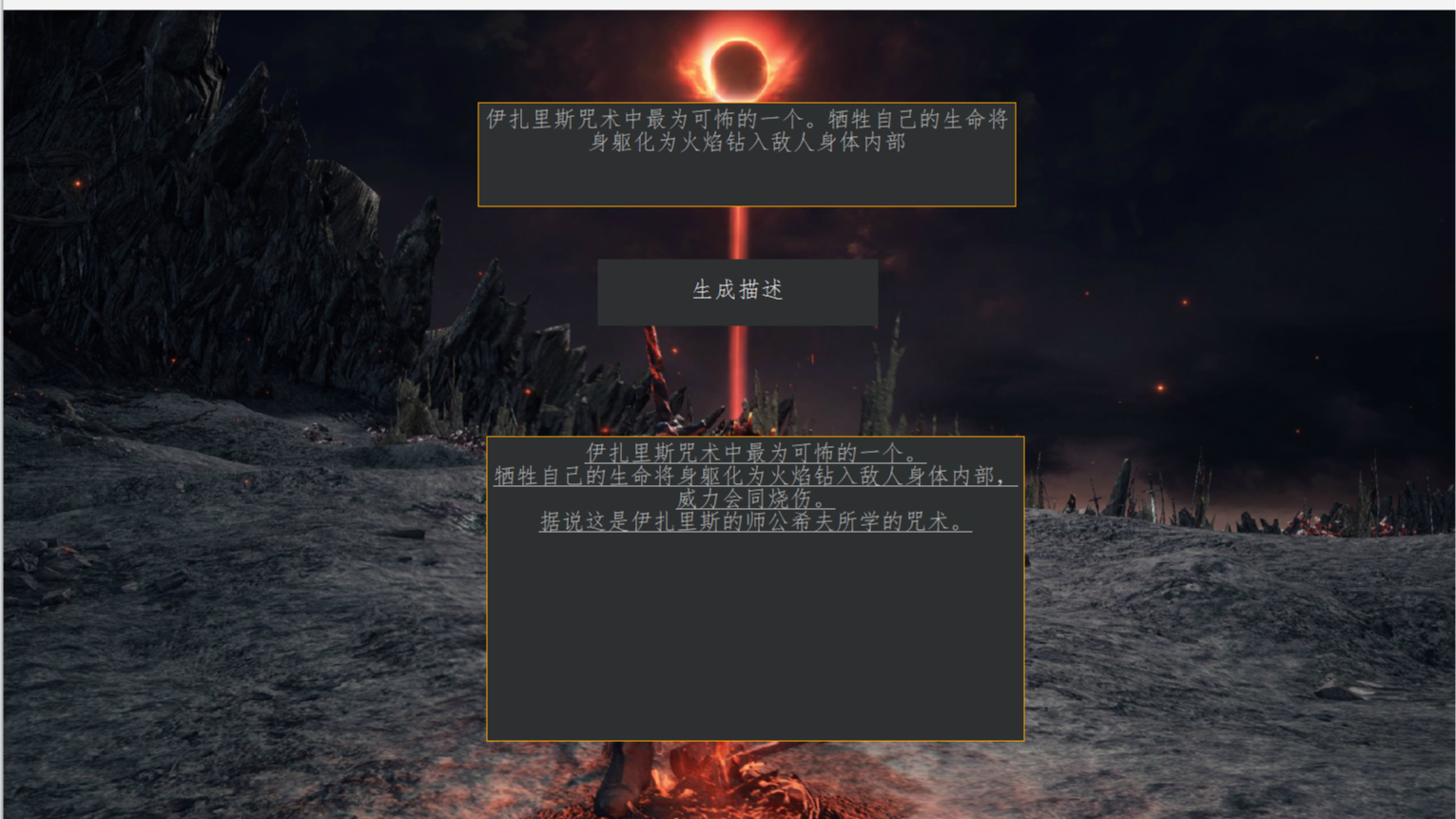 我在之前的文章中使用HuggingFace的Transformers库训练了一个可以根据上文生成下文的黑暗之魂物品描述的模型。现在,我将尝试将其部署到dot NET项目中。
阅读全文
我在之前的文章中使用HuggingFace的Transformers库训练了一个可以根据上文生成下文的黑暗之魂物品描述的模型。现在,我将尝试将其部署到dot NET项目中。
阅读全文
我在之前的文章中使用HuggingFace的Transformers库训练了一个可以根据上文生成下文的黑暗之魂物品描述的模型。现在,我将尝试将其部署到dot NET项目中。
阅读全文
摘要:这里探讨数据集中Promo2对于每家店铺销售额的影响。其中,Promo2是一个基于优惠券的邮寄活动,发送给参与商店的顾客。每封信里都有几张优惠券,大部分是所有产品的一般折扣,有效期为三个月。所以在这些优惠券到期之前,我们会给客户发新一轮的邮件。
阅读全文
摘要:这个此在线零售数据集包含2009年12月1日至2011年12月9日期间的在线零售的所有交易。该公司主要销售独特的各种场合礼品。这家公司的许多客户都是批发商。本文将通过pyspark对数据进行导入与预处理,进行可视化分析并使用RFM、生存分析与BG-NBD模型进行对购买客户的各项分析。
阅读全文
摘要:CLV(Customer Lifetime Value)指的是客户生命周期价值,用以衡量客户在一段时间内对企业有多大的价值。企业对每个用户的流失与否、在未来时间是否会再次购买,还会再购买多少次才会流失等问题感兴趣,本文中的BG/NBD模型就是用来解决这样一系列问题的。
阅读全文
摘要:零售商期望能够利用过去的零售数据在自己的行业中进行探索,并为客户提供有关商品集的建议,这样就能提高客户参与度、改善客户体验并识别客户行为。本文将通过pyspark对数据进行导入与预处理,进行可视化分析并使用spark自带的机器学习库做关联规则学习,挖掘不同商品之间是否存在关联关系。
阅读全文
摘要: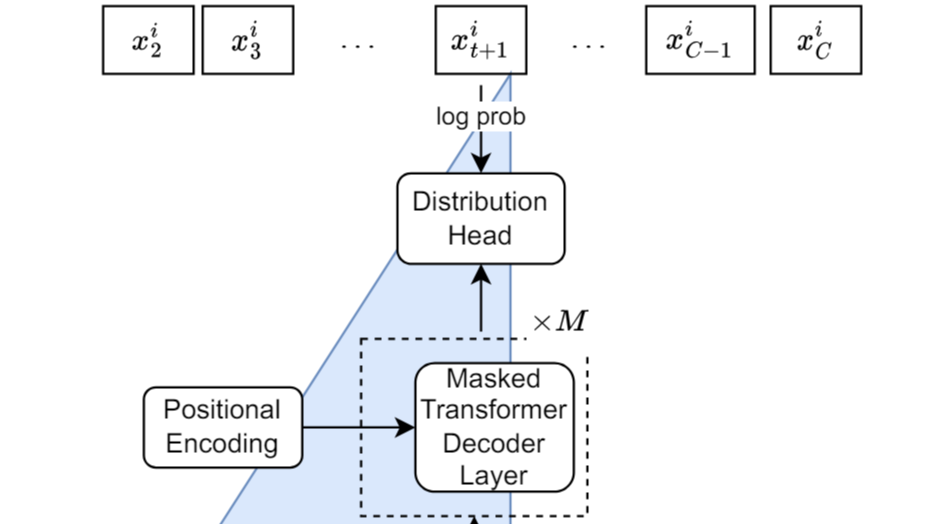 这是一个借鉴了Llama模型结构的单变量概率时间预测模型,使用了海量的数据集进行预训练,用户可以根据实际的任务进行模型微调或者直接进行零样本推理。模型从六个领域搜集了27个时序数据,根据不同的频数分为了7965个数据集进行预训练,之后又从其他数据集上进行零样本学习以及微调,使用CRPS评估的结果如图所示,Lag-Llama微调后的平均结果更好,仅2.786左右。
阅读全文
这是一个借鉴了Llama模型结构的单变量概率时间预测模型,使用了海量的数据集进行预训练,用户可以根据实际的任务进行模型微调或者直接进行零样本推理。模型从六个领域搜集了27个时序数据,根据不同的频数分为了7965个数据集进行预训练,之后又从其他数据集上进行零样本学习以及微调,使用CRPS评估的结果如图所示,Lag-Llama微调后的平均结果更好,仅2.786左右。
阅读全文
这是一个借鉴了Llama模型结构的单变量概率时间预测模型,使用了海量的数据集进行预训练,用户可以根据实际的任务进行模型微调或者直接进行零样本推理。模型从六个领域搜集了27个时序数据,根据不同的频数分为了7965个数据集进行预训练,之后又从其他数据集上进行零样本学习以及微调,使用CRPS评估的结果如图所示,Lag-Llama微调后的平均结果更好,仅2.786左右。
阅读全文
摘要: 项目地址:https://github.com/thornbsj/DS_PAIR
游戏“黑暗之魂”系列中一直以其隐晦的剧情以及其“碎片化叙事”著称。除去一般游戏中采用的环境叙事以及NPC的语言叙事外,还会将部分剧情背景通过物品描述的形式糅合进游戏中。通过“魂式文风”的物品描述来推测背景故事也是玩家们乐此不疲的一件事。本文就希望能够借助于预训练好的语言模型,输入物品描述,让模型输出一个相关的背景故事。
阅读全文
项目地址:https://github.com/thornbsj/DS_PAIR
游戏“黑暗之魂”系列中一直以其隐晦的剧情以及其“碎片化叙事”著称。除去一般游戏中采用的环境叙事以及NPC的语言叙事外,还会将部分剧情背景通过物品描述的形式糅合进游戏中。通过“魂式文风”的物品描述来推测背景故事也是玩家们乐此不疲的一件事。本文就希望能够借助于预训练好的语言模型,输入物品描述,让模型输出一个相关的背景故事。
阅读全文
项目地址:https://github.com/thornbsj/DS_PAIR
游戏“黑暗之魂”系列中一直以其隐晦的剧情以及其“碎片化叙事”著称。除去一般游戏中采用的环境叙事以及NPC的语言叙事外,还会将部分剧情背景通过物品描述的形式糅合进游戏中。通过“魂式文风”的物品描述来推测背景故事也是玩家们乐此不疲的一件事。本文就希望能够借助于预训练好的语言模型,输入物品描述,让模型输出一个相关的背景故事。
阅读全文
摘要:通常真是数据集中很少回包含“对于预测完全没有帮助的高斯噪声特征”,但是以往在评估特征选择算法时,会手动造数据并包含由高斯分布生成的“纯噪音特征”,不仅和事实大相径庭,而且这也使得特征选择算法的任务变得比真实情况更加“简单”了;所以作者基于真实数据集构造特征选择的评估基准,并加入了随机噪音特征、损坏特征和作为特征工程原型的二阶特征(有可能是冗余特征),通过对特征选择后的数据下游模型(MLP和FT-Transformer)效能评估来评估特征选择的效果。
阅读全文
摘要: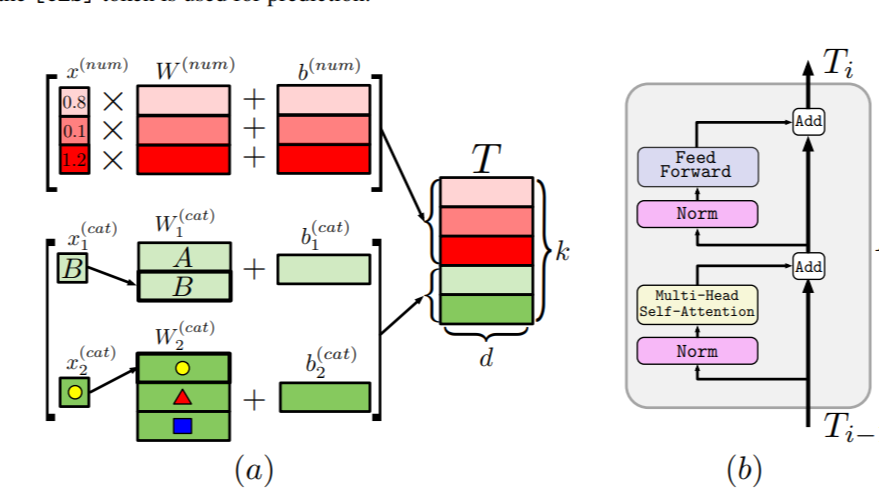 现有的关于表格数据做深度学习的模型层出不穷,但是作者认为,由于在真实使用模型时有着不同的基准以及实验场合,这些提出的模型没有被很好地比较。因此,论文作者在论文中对各类模型进行了综述,并且自身提出了一个对Transformer作简单改进的模型:FT-Transformer,最终将ResNet-like类模型、Transformer-like类模型以及其他MLP模型在不同的数据集上训练、对比效果,最终确定了一个较好的衡量针对表格数据的深度学习模型的标准(bennchmark)。
阅读全文
现有的关于表格数据做深度学习的模型层出不穷,但是作者认为,由于在真实使用模型时有着不同的基准以及实验场合,这些提出的模型没有被很好地比较。因此,论文作者在论文中对各类模型进行了综述,并且自身提出了一个对Transformer作简单改进的模型:FT-Transformer,最终将ResNet-like类模型、Transformer-like类模型以及其他MLP模型在不同的数据集上训练、对比效果,最终确定了一个较好的衡量针对表格数据的深度学习模型的标准(bennchmark)。
阅读全文
现有的关于表格数据做深度学习的模型层出不穷,但是作者认为,由于在真实使用模型时有着不同的基准以及实验场合,这些提出的模型没有被很好地比较。因此,论文作者在论文中对各类模型进行了综述,并且自身提出了一个对Transformer作简单改进的模型:FT-Transformer,最终将ResNet-like类模型、Transformer-like类模型以及其他MLP模型在不同的数据集上训练、对比效果,最终确定了一个较好的衡量针对表格数据的深度学习模型的标准(bennchmark)。
阅读全文
摘要: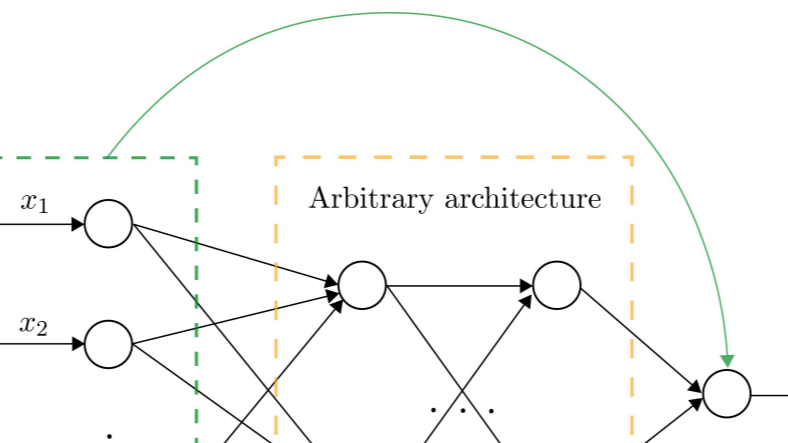 论文提出了一个在神经网络中能够做特征提取的结构:LassoNet,其核心思想,是使用一个“Skip层”的结构来控制要进入后面隐层的特征数量,从而实现特征的稀疏化。尽管原理看上去很简单,但是针对其进行反向传播的优化算法(Warm Start和Hier-Prox算法),实际上有着相当的数学最优化原理。这篇论文实际上结合了原本线性模型种的L1正则化与ResNet的思路,可以说有着借鉴价值。
阅读全文
论文提出了一个在神经网络中能够做特征提取的结构:LassoNet,其核心思想,是使用一个“Skip层”的结构来控制要进入后面隐层的特征数量,从而实现特征的稀疏化。尽管原理看上去很简单,但是针对其进行反向传播的优化算法(Warm Start和Hier-Prox算法),实际上有着相当的数学最优化原理。这篇论文实际上结合了原本线性模型种的L1正则化与ResNet的思路,可以说有着借鉴价值。
阅读全文
论文提出了一个在神经网络中能够做特征提取的结构:LassoNet,其核心思想,是使用一个“Skip层”的结构来控制要进入后面隐层的特征数量,从而实现特征的稀疏化。尽管原理看上去很简单,但是针对其进行反向传播的优化算法(Warm Start和Hier-Prox算法),实际上有着相当的数学最优化原理。这篇论文实际上结合了原本线性模型种的L1正则化与ResNet的思路,可以说有着借鉴价值。
阅读全文
摘要: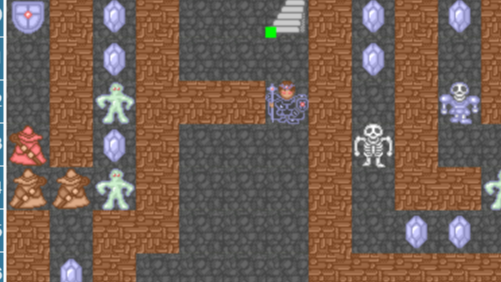 魔塔是一款经典的策略益智游戏,自问世以来一直受部分玩家的追捧,各个魔塔爱好者不仅将这个玩法作为基准推陈出新造出了一系列的同人创作并发展出了自己的游戏社区,而且其内里蕴含的算法与策略也被诸多玩家开发利用。今天笔者就用算法来介绍一下魔塔社区中发现的“全蓝宝石转化理论”。
阅读全文
魔塔是一款经典的策略益智游戏,自问世以来一直受部分玩家的追捧,各个魔塔爱好者不仅将这个玩法作为基准推陈出新造出了一系列的同人创作并发展出了自己的游戏社区,而且其内里蕴含的算法与策略也被诸多玩家开发利用。今天笔者就用算法来介绍一下魔塔社区中发现的“全蓝宝石转化理论”。
阅读全文
魔塔是一款经典的策略益智游戏,自问世以来一直受部分玩家的追捧,各个魔塔爱好者不仅将这个玩法作为基准推陈出新造出了一系列的同人创作并发展出了自己的游戏社区,而且其内里蕴含的算法与策略也被诸多玩家开发利用。今天笔者就用算法来介绍一下魔塔社区中发现的“全蓝宝石转化理论”。
阅读全文
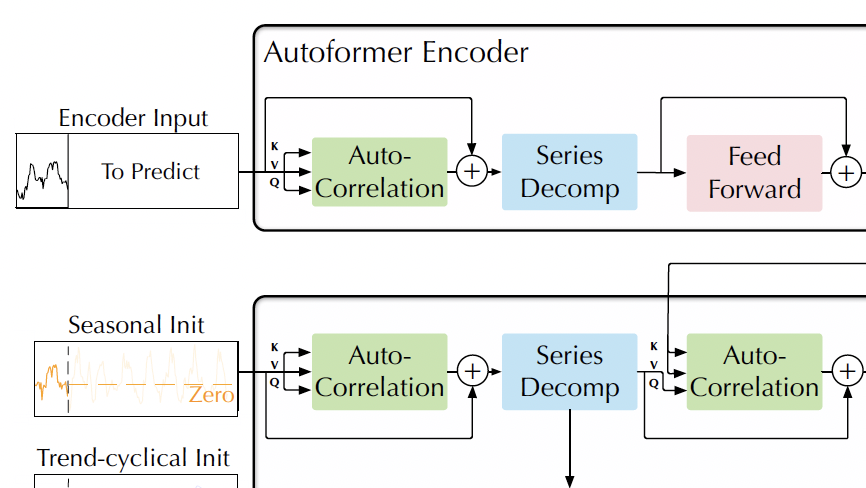
摘要:反思了为什么Transformer模型在时间序列预测的问题上没有传统的线性模型效果好。文章作者认为,Transformer并非不适合于时间序列预测任务,而是以往的研究者没有“正确使用”Transformer。在没有大改Transformer模型的情况下,通过将输入Embedding的进行转置,使得自注意力层与前向层所提取的特征进行了互换,经过试验发现无论是预测效果还是模型可解释性都大大提高了,论文具有一定指导意义,这个转置的技巧也可以用在以往的模型之中。
阅读全文
摘要:这是Kaggle上的一个分类任务竞赛,给出的数据集没有明确的业务背景,但是只包含分类数据,包括:二分类数据,低分类数与高分类数的类别特征,低分类数与高分类数的顺序特征,以及(潜在包含)的周期特征。
选手们需要根据600K条数据预测400K条测试集的二分类可能性。
阅读全文
摘要:在rossmann-store-sales竞赛中,有着众多的离散型的特征难以处理,以最为典型店铺号为例,数据集中包含了1115家店铺类型的店铺历史信息数据。对于建模是一个十分重要的信息。但是,对于这样一个有着1115个类别的特征而言,不能使用传统的热编码或者哑变量来进行预处理:因为这样不仅会使得特征具有严重的稀疏性,而且1115个哑变量/热编码也会造成维度灾难,会严重影响模型的效果。而如果将1115个商店分别拎出来进行建模,那么不仅每家单店的数据量过少,仅983条,且没有同类型店铺的相关先验信息,并造成了很多特征不再可用。所以对于这样的多分类离散特征算是这个竞赛的痛点之一,而在之前的很多机器学习模型中,也有类似对于这类多类型离散特征变量的处理。
阅读全文
摘要:Prophet是Facebook公司开源的一款时间序列预测模型接口,可用R语言或python进行相关时间预测操作,本文将会从它的代码上对其进行模型拟合以及预测的过程进行一个梳理,并使用python中的pymc包进行Stan文件中贝叶斯建模的复现。
阅读全文
摘要:之前复现的机器学习中,大多数都是按照频率派的思路进行点估计。以线性回归举例,按照频率派的思想,就是将估计值的误差平方和作为损失函数,找到能够使得它最小的权重矩阵W,也就是我们常看到的最小二乘法。
而到了贝叶斯派的眼中,原本应该是一个作为“估计值”的W矩阵,本身也是一个符合某一变量的随机变量。目标就是求W矩阵的分布。
阅读全文
摘要:和其他深度学习任务(图像以及自然语言处理)不同,尽管时间序列是连续记录的,然而每个时间点只记录了一些标量,语义信息不足,所以研究都集中在数据的时间变化上(temporal variation)。然而现实的时间序列数据,通常都是由各个有着不同周期的不同因素耦合在一起的,增加了建模难度。并且,时间点本身不仅受到本身缩在周期影响,相邻周期也会对这一周期的时间点产生影响。文中将这2种影响时间序列的变化分别称之为“期内变化”(intraperiod-variation)和“期间变化”(interperiod-variation)。为了将这2种变化区分开来,文中将一维的时间序列数据转换为了二维空间数据。
阅读全文
摘要:本次根据第一名给出的pdf策略进行了特征提取与建模操作;在此期间使用了Prophet作趋势项与季节因素的提取操作,Null Importance作特征筛选,Optuna对模型参数进行贝叶斯优化选取。
阅读全文
摘要:我们想要优化的目标是:找到一组最佳的超参X(注意此处的X不是数据集中的自变量),能够使得训练出来的模型的损失值Y(Y也不是因变量)最小。与正常的机器学习不同,这里的Y(损失值)与X(超参)本身的关系更为复杂,因为模型的结构本身是按照优化函数:f(自变量)来设计的,当我们将超参作为随机变量来看待时,这个函数便不一定是凸函数,不一定关于一、二阶可微,传统的梯度下降法不再适用,损失函数如同“黑箱”一般,难以优化。
为此,SMBO算法建立,以此在计算机上对模型使用贝叶斯优化。
阅读全文
摘要: 参考了Konstantin的特征处理,使用了XGBoost,lightGBM,CatBoost以及Blending策略对M5数据集中的德克萨斯州家居类产品作了预测。得到了可以接受的一个结果。
阅读全文
参考了Konstantin的特征处理,使用了XGBoost,lightGBM,CatBoost以及Blending策略对M5数据集中的德克萨斯州家居类产品作了预测。得到了可以接受的一个结果。
阅读全文
参考了Konstantin的特征处理,使用了XGBoost,lightGBM,CatBoost以及Blending策略对M5数据集中的德克萨斯州家居类产品作了预测。得到了可以接受的一个结果。
阅读全文
 源代码的浅读,而非复现。
源代码的浅读,而非复现。
摘要:根据模型的数学原理进行简单的代码自我复现以及使用测试,仅作自我学习用。模型原理此处不作过多赘述。
如文中或代码有错误或是不足之处,还望能不吝指正。
阅读全文
摘要:根据模型的数学原理进行简单的代码自我复现以及使用测试,仅作自我学习用。模型原理此处不作过多赘述。
如文中或代码有错误或是不足之处,还望能不吝指正。
阅读全文
摘要:根据模型的数学原理进行简单的代码自我复现以及使用测试,仅作自我学习用。模型原理此处不作过多赘述,仅罗列自己将要使用到的部分公式。
如文中或代码有错误或是不足之处,还望能不吝指正。
阅读全文
摘要:根据模型的数学原理进行简单的代码自我复现以及使用测试,仅作自我学习用。模型原理此处不作过多赘述,仅罗列自己将要使用到的部分公式。
如文中或代码有错误或是不足之处,还望能不吝指正。
阅读全文
摘要:根据模型的数学原理进行简单的代码自我复现以及使用测试,仅作自我学习用。模型原理此处不作过多赘述,仅罗列自己将要使用到的部分公式。
阅读全文
摘要:根据模型的数学原理进行简单的代码自我复现以及使用测试,仅作自我学习用。模型原理此处不作过多赘述,仅罗列自己将要使用到的部分公式。
阅读全文
摘要:根据模型的数学原理进行简单的代码自我复现以及使用测试,仅作自我学习用。模型原理此处不作过多赘述,仅罗列自己将要使用到的部分公式。
阅读全文
摘要: 根据模型的数学原理进行简单的代码自我复现以及使用测试,仅作自我学习用。模型原理此处不作过多赘述,仅罗列自己将要使用到的部分公式。
阅读全文
根据模型的数学原理进行简单的代码自我复现以及使用测试,仅作自我学习用。模型原理此处不作过多赘述,仅罗列自己将要使用到的部分公式。
阅读全文
根据模型的数学原理进行简单的代码自我复现以及使用测试,仅作自我学习用。模型原理此处不作过多赘述,仅罗列自己将要使用到的部分公式。
阅读全文
摘要: 根据模型的数学原理进行简单的代码自我复现以及使用测试,仅作自我学习用。模型原理此处不作过多赘述,仅罗列自己将要使用到的部分公式。
如文中或代码有错误或是不足之处,还望能不吝指正。
阅读全文
根据模型的数学原理进行简单的代码自我复现以及使用测试,仅作自我学习用。模型原理此处不作过多赘述,仅罗列自己将要使用到的部分公式。
如文中或代码有错误或是不足之处,还望能不吝指正。
阅读全文
根据模型的数学原理进行简单的代码自我复现以及使用测试,仅作自我学习用。模型原理此处不作过多赘述,仅罗列自己将要使用到的部分公式。
如文中或代码有错误或是不足之处,还望能不吝指正。
阅读全文
摘要: 根据模型的数学原理进行简单的代码自我复现以及使用测试,仅作自我学习用。模型原理此处不作过多赘述,仅罗列自己将要使用到的部分公式。代码框架部分参照了以下视频中的内容。
阅读全文
根据模型的数学原理进行简单的代码自我复现以及使用测试,仅作自我学习用。模型原理此处不作过多赘述,仅罗列自己将要使用到的部分公式。代码框架部分参照了以下视频中的内容。
阅读全文
根据模型的数学原理进行简单的代码自我复现以及使用测试,仅作自我学习用。模型原理此处不作过多赘述,仅罗列自己将要使用到的部分公式。代码框架部分参照了以下视频中的内容。
阅读全文
摘要: 根据模型的数学原理进行简单的代码自我复现以及使用测试,仅作自我学习用。模型原理此处不作过多赘述,仅罗列自己将要使用到的部分公式。代码框架部分参照了以下视频中的内容。
阅读全文
根据模型的数学原理进行简单的代码自我复现以及使用测试,仅作自我学习用。模型原理此处不作过多赘述,仅罗列自己将要使用到的部分公式。代码框架部分参照了以下视频中的内容。
阅读全文
根据模型的数学原理进行简单的代码自我复现以及使用测试,仅作自我学习用。模型原理此处不作过多赘述,仅罗列自己将要使用到的部分公式。代码框架部分参照了以下视频中的内容。
阅读全文
 浙公网安备 33010602011771号
浙公网安备 33010602011771号