Scrapy框架
Scrapy框架
MarkText不能设置中文orz,有点麻
框架理解

他总共有五个部件吧,Scrapy Engine是核心部件,负责进行数据的处理并把数据分派给其他部件以及触发事件,如翻页,点击等,Scheduler负责存取要爬取的url,Downloader就是下载网页上的数据,Spider就是根据用户写的response获得用户需要的数据item,Item Pipeline就是负责把数据存入用户要存的地方,如Mysql,Redis等。
另外Spider和Downloader各自有一个中间部件是用户自定义的来扩展scrapy功能。
工作原理
1.Scrapy Engine先打开一个网站,并找到解析网页对应的spider请求第一个要爬取的url
2.请求到的url通过Scrapy Engine发送到Scheduler中通过Request调度
3.Scrapy Engine向Scheduler请求url
4.请求到的url发送到Downloader,Downloader下载好数据并通过Downloader中间件(含Response)传回ScrapyEngine
5.ScrapyEngine通过Spider中间件把数据和response传给spiders
6.Spiders处理response,并把处理好的Item和新的Request传给ScrapyEngine
7.ScrapyEngine将Item传给Item Pipeline,Requests给Scheduler
8.回到2,重复至没有新的Request
项目流程
scrapy startproject/genspider/crawl
生成文件分析
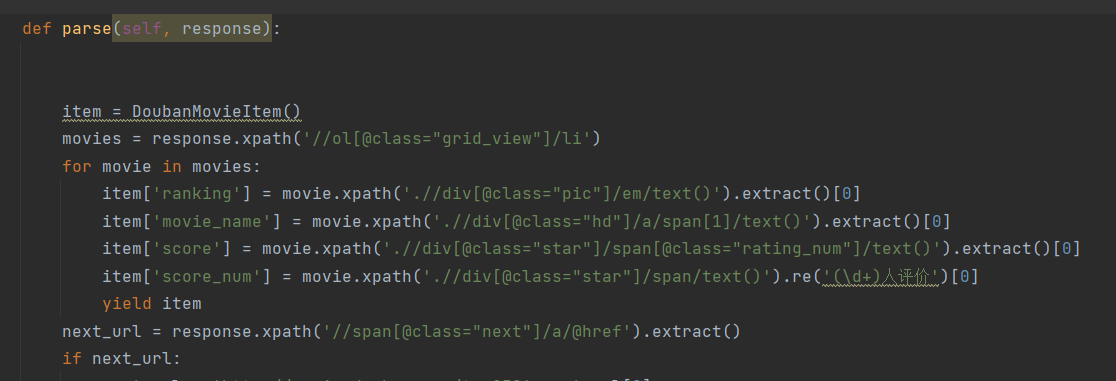
生成的爬虫py都在spiders文件夹下,parse方法是用来获取Item的,需要重写。setting.py是配置文件,可以看到有很多被注释的东西,user_Agent头等可以在这里添加。
LU3.png)

Xpath
用了XpathHelper边看边学吧,最简单的几个要会就是了
/表示子节点
//表示跳级节点
然后就是输入标签头如div、span等进行查询,[@**]来查询属性,**表示class,href等属性,text()表示查询某个特定名称里的文本,contains()表示查询某个包含特定名称的数据
实战
就是实现了一个豆瓣top250电影的爬取,但是还有很多没学吧,items.py,middlewares.py,piplines.py都没改,毕竟最终项目的时候是要用到redis这种分布式数据库的

 浙公网安备 33010602011771号
浙公网安备 33010602011771号