机器学习—降维-特征选择6-2(包装法)
使用包装法对糖尿病数据集降维(递归特征消除法)
主要步骤流程:
- 1. 导入包
- 2. 导入数据集
- 3. 数据预处理
- 3.1 检测缺失值
- 3.2 生成自变量和因变量
- 3.3 拆分训练集和测试集
- 3.4 特征缩放
- 4. 使用递归特征消除法降维
- 5. 得到降维后的自变量
1. 导入包
In [2]:
# 导入包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
2. 导入数据集
In [3]:
# 导入数据集
dataset = pd.read_csv('pima-indians-diabetes.csv')
dataset
Out[3]:
3. 数据预处理
3.1 检测缺失值
In [4]:
# 检测缺失值
null_df = dataset.isnull().sum()
null_df
Out[4]:
3.2 生成自变量和因变量
In [5]:
# 生成自变量和因变量
X = dataset.iloc[:,0:8].values
y = dataset.iloc[:,8].values
3.3 拆分训练集和测试集
In [6]:
# 拆分训练集和测试集
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 1)
print(X_train.shape)
print(X_test.shape)
print(y_train.shape)
print(y_test.shape)
3.4 特征缩放
In [7]:
# 特征缩放
from sklearn.preprocessing import StandardScaler
sc_X = StandardScaler()
X_train = sc_X.fit_transform(X_train)
X_test = sc_X.transform(X_test)
4. 使用递归特征消除法降维
In [8]:
# 建立逻辑回归模型
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
In [9]:
# 递归特征消除法
from sklearn.feature_selection import RFECV
rfecv = RFECV(estimator = model, min_features_to_select = 1, cv=5, verbose=1, step=1, scoring='accuracy')
rfecv = rfecv.fit(X_train, y_train)
In [10]:
# 打印降维后的重要信息
print("应该选择的字段个数:%d" % rfecv.n_features_)
In [11]:
print("选择的字段索引是:%s" % rfecv.support_)
In [12]:
print("字段排名是:%s" % rfecv.ranking_)
In [13]:
# 画出字段个数 VS 交叉验证分数
plt.figure()
plt.xlabel("Number of Features")
plt.ylabel("Accuracy")
plt.plot(range(1, len(rfecv.grid_scores_) + 1), rfecv.grid_scores_)
plt.show()
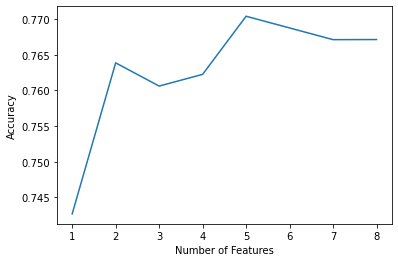
In [14]:
rfecv.grid_scores_
Out[14]:
5. 得到降维后的自变量
In [15]:
# 得到降维后的自变量
features1 = rfecv.transform(X)
features1
Out[15]:
In [16]:
# 得到降维后的自变量(验证)
features1 = X[:, [0,1,2,5,6]]
print(features1)
结论:
features1 存储着降维后的自变量

 浙公网安备 33010602011771号
浙公网安备 33010602011771号