OO第三单元总结——基于JML规格的设计
OO第三单元总结——基于JML规格的设计
第一次作业
UML类图:
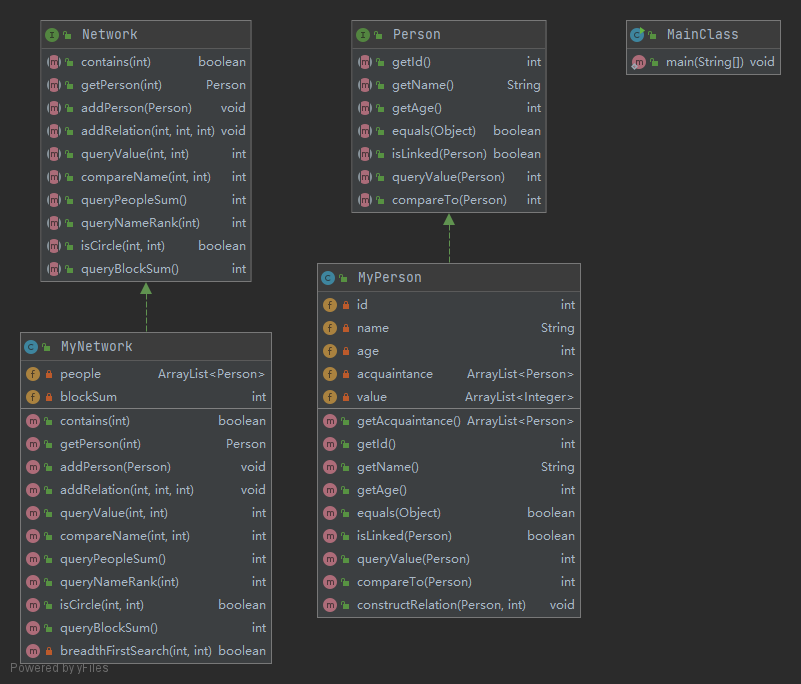
类复杂度:

方法复杂度:
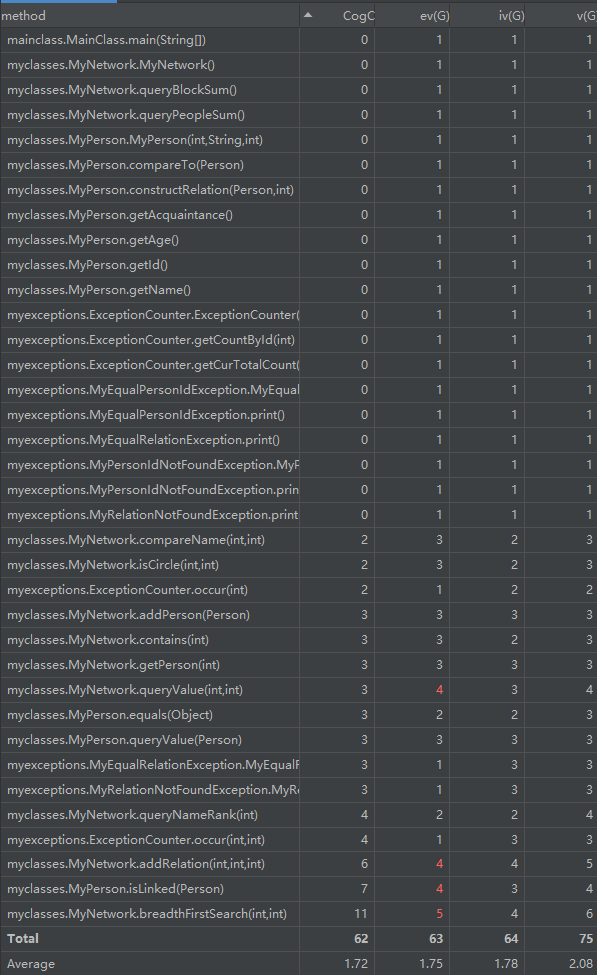
复杂度分析:
从类的角度来看,无疑是MyNetwork类的复杂度最高。
从方法的角度看,我自行设计的广度优先搜索遍历图的方法复杂度最高,然后譬如MyPerson类下的isLinked方法,由于采用了遍历的方式实现,复杂度也较高。
关键设计策略
本次作业规格较为简单,因此我直接采用了ArrayList来实现所有规格中要求以列表形式存在的数据。
对于JML需求中的方法,也基本采用了需求中的描述去实现。这就导致了潜在的性能问题。
测试情况
本次课下测试较少,只是确认了一下基本的样例输出正确。
在线上测试中,公测无bug,互测被找出了存在的性能问题。主要测试点为连续多个qbs指令导致CPU超时。
原因分析:
我的queryBlockSum原本实现如下:
public int queryBlockSum() {
int sum = 0;
int flag;
boolean res = false;
for (int i = 0; i < people.size(); i++) {
flag = 1;
for (int j = 0; j < i; j++) {
try {
res = isCircle(people.get(i).getId(), people.get(j).getId());
} catch (PersonIdNotFoundException e) {
e.print();
}
if (res) {
flag = 0;
break;
}
}
sum += flag;
}
return sum;
}
注意到isCircle内通过调用广度优先搜索来确定两个节点是否连通,再加上这里是一个两层循环,导致qbs的性能消耗极大,最终超时。
解决方案:
注意到图的性质有:
- 每次添加一个孤立节点,连通分量数+1;
- 两个已连通的节点间加边,不改变连通分量数;
- 两个不连通的节点间加边,连通分量数-1。
因此,考虑设置一个全局的blockSum变量,初值为0,在addPerson和addRelation里分别对其进行修改,这样在qbs的时候直接返回它的值即可。这导致每次插入关系时的时间复杂度变为O(n),但是qbs的时间复杂度降为O(1)。考虑到插入关系次数较少,且复杂度随图的规模增长而增长,这样的优化效果是显著的。
第二次作业
UML类图:
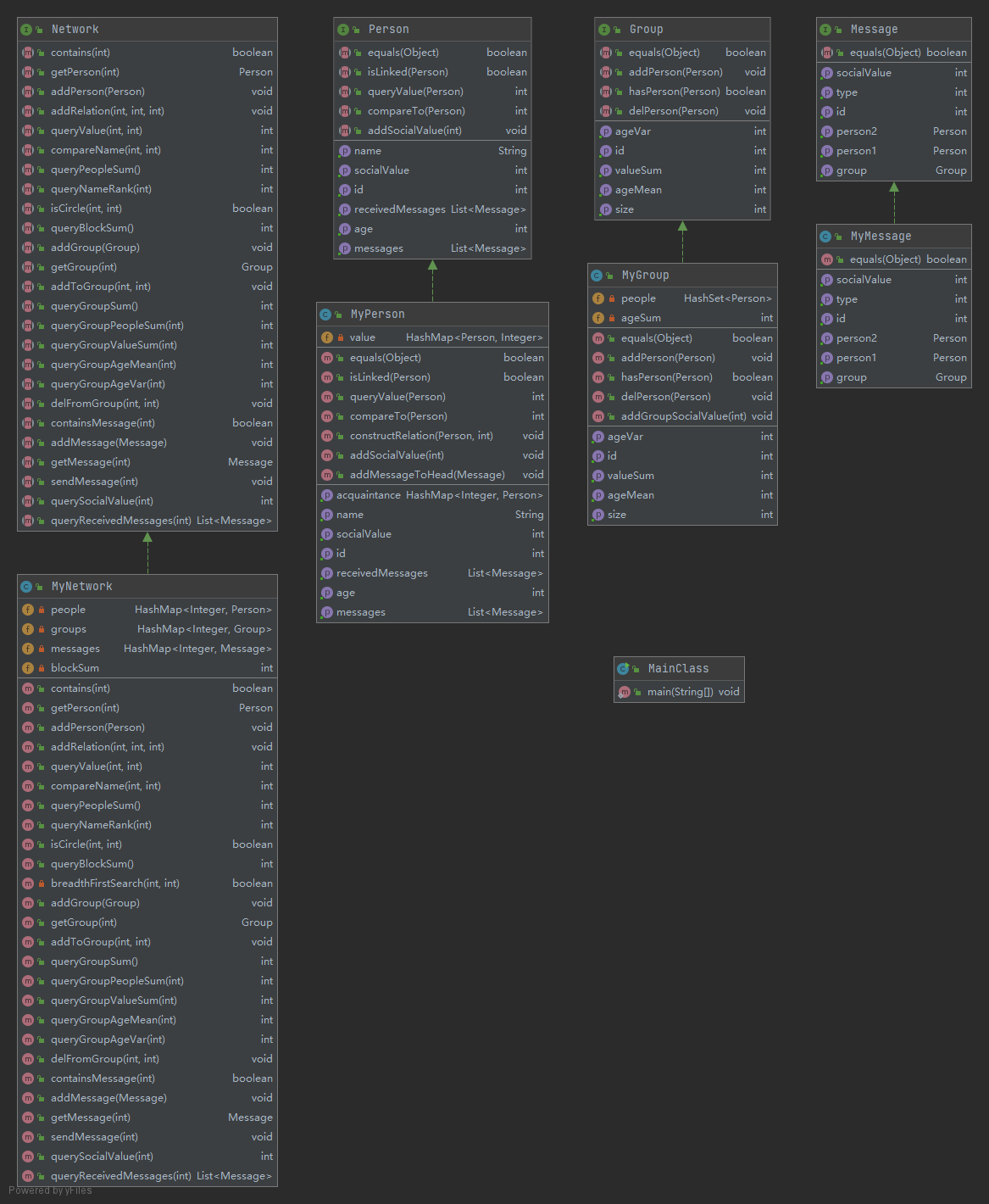
类复杂度:

方法复杂度(仅截取最复杂的一部分):
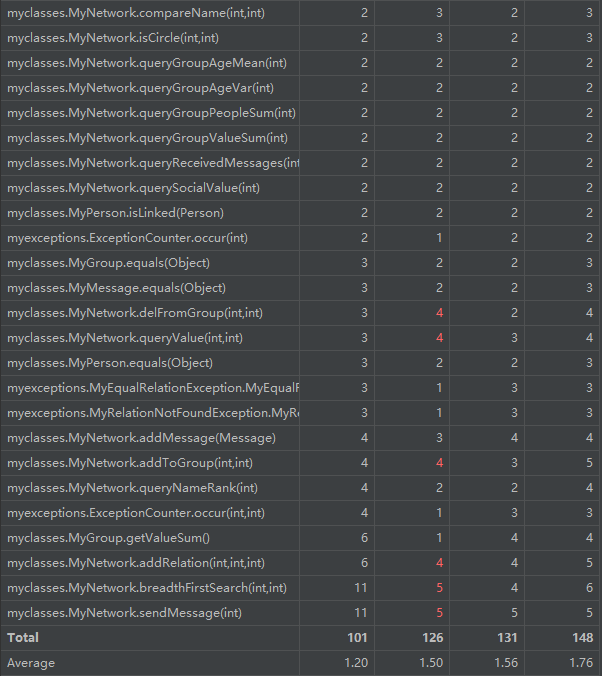
复杂度分析:
从类的角度来看,仍然是MyNetwork类的复杂度最高。
从方法的角度看,添加关系、BFS、发送消息等复杂度较高。
关键设计策略
本次作业在吸取上次作业性能问题的教训后,换用了新的数据结构。
- 考虑到不需要索引,
MyGroup类用来装Person的容器使用了HashSet; - 由于需要建立
id与具体的人和消息的关系,MyPerson类的邻接表、权重表采用了HashMap,MyNetWork类内容器也是如此。 - 对于有强制的顺序要求的,如
MyPerson类中的消息列表,采用LinkedList,以方便插入删除操作。
换用HashSet和HashMap可以大大降低查询的时间复杂度。
测试情况
本次课下测试较少,只是确认了一下基本的样例输出正确。
在线上测试中,公测无bug,互测被找出了存在的性能问题。主要测试点为连续多个qgvs指令导致CPU超时。
原因分析:
我的getValueSum原本实现如下:
public int getValueSum() {
int result = 0;
for (Person p : people) {
for (Person q : people) {
if (p.isLinked(q)) {
result += p.queryValue(q);
}
}
}
return result;
}
最大的问题在于,在对邻接关系求和时,没有从邻接表中查找,而是从所有人中查找。这大大地增加了查找的范围。
解决方案:
public int getValueSum() {
int result = 0;
for (Person p : people) {
for (Person q : ((MyPerson) p).getAcquaintance().values()) {
if (hasPerson(q)) {
result += p.queryValue(q);
}
}
}
return result;
}
将从所有人中查找改为从邻接表中查找即可。
第三次作业
UML类图:
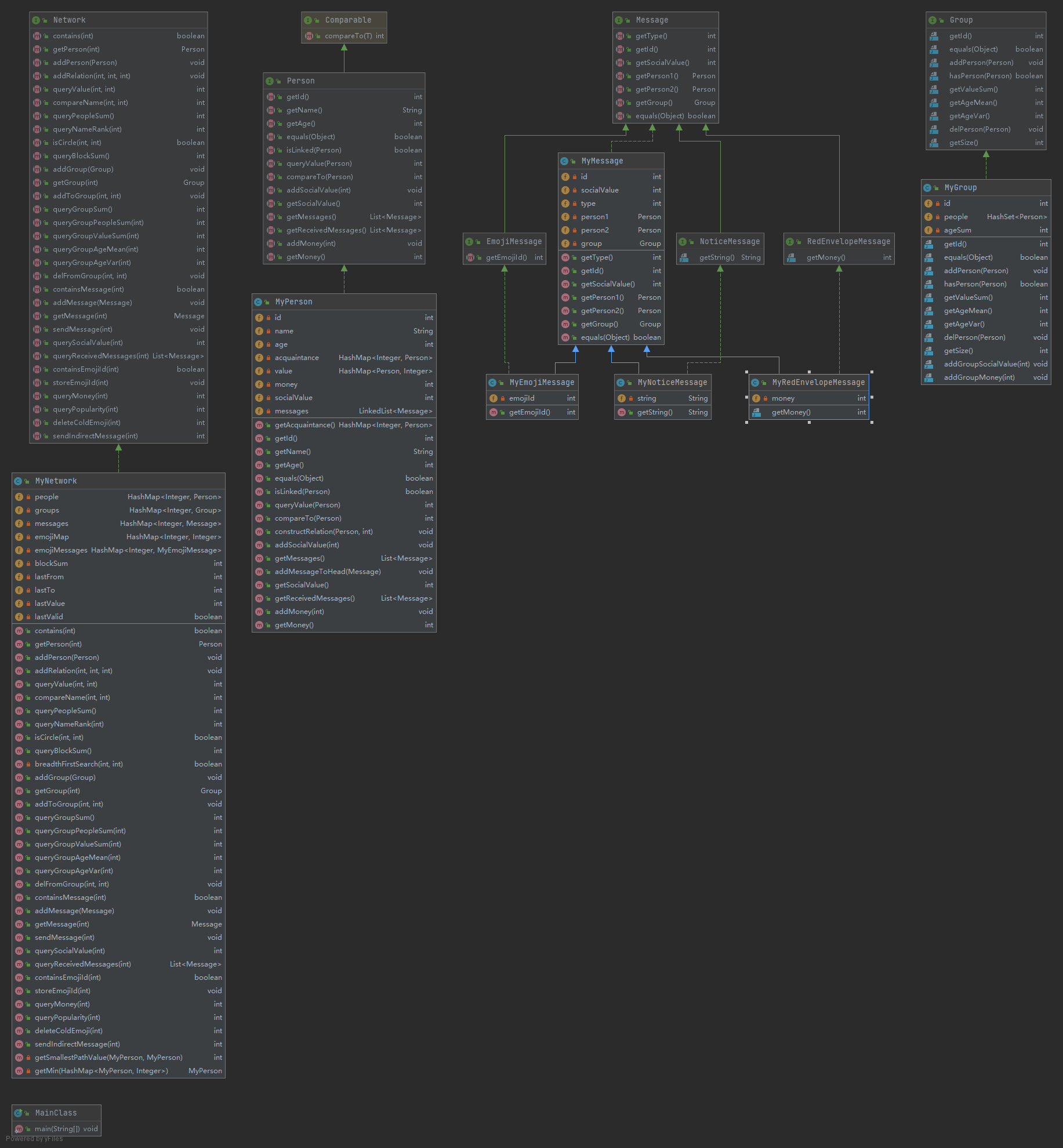
类复杂度:
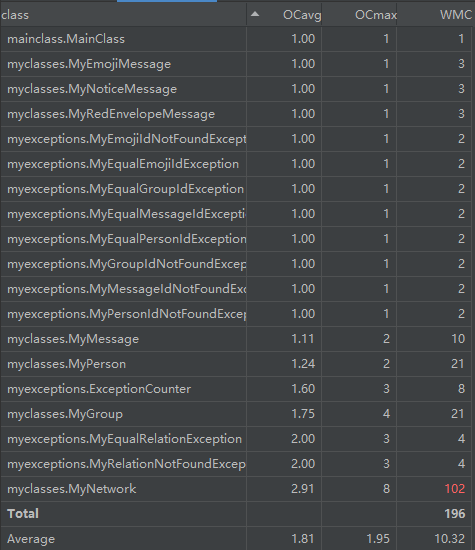
方法复杂度(仅截取最复杂的一部分):
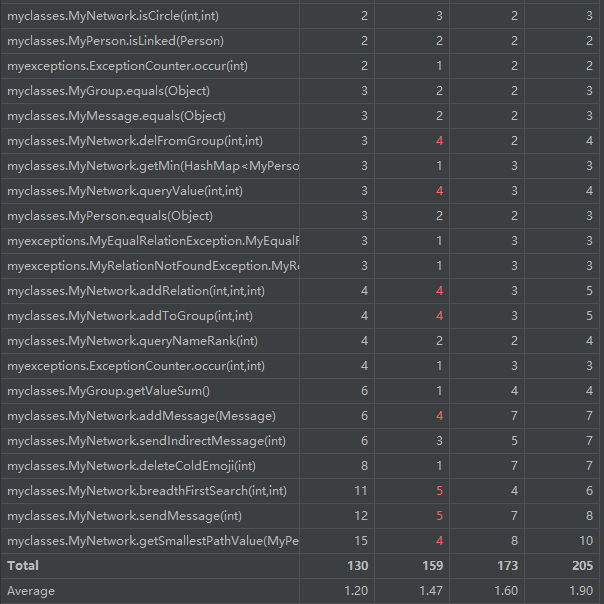
复杂度分析:
从类的角度来看,由于接口的限制,MyNetwork类的复杂度最高。
从方法的角度看,删除冷表情、BFS、发送消息、求最短路径等复杂度较高。
关键设计策略
本次作业在吸取上次作业性能问题的教训后,换用了新的数据结构。
- 考虑到不需要索引,
MyGroup类用来装Person的容器使用了HashSet; - 由于需要建立
id与具体的人和消息的关系,MyPerson类的邻接表、权重表采用了HashMap,MyNetWork类内容器也是如此。 - 对于有强制的顺序要求的,如
MyPerson类中的消息列表,采用LinkedList,以方便插入删除操作。
换用HashSet和HashMap可以大大降低查询的时间复杂度。
测试情况
本次课下测试较少,只是确认了一下基本的样例输出正确。
在线上测试中,公测找到了一个问题,互测没有出问题。主要问题在于删除了不该删除的消息,导致后面的消息出错。
原因分析:
为加速deleteColdEmoji,避免其每次都需要从所有消息中查找表情类消息,我建立了一个emojiMessages容器,专门将表情类消息再在此存储一次,这样deleteColdEmoji就只需要在emojiMessages里遍历删除即可。
但是,漏了一点在于,发送消息后要删除该消息,但是我遗漏了emojiMessages里的消息,没有把里面相应消息一并删除,导致该表情类消息已经发送,其id被下一条新消息使用,此时进行一次deleteColdEmoji,就按照id把不该删的消息删除了,进而出错。
解决方案:
在两个发送消息方法内补上了对emojiMessages内消息的处理。
容器选择与使用经验
数据需要而且可以建立索引时,考虑使用HashMap来作为容器,可以显著降低查询、修改的时间复杂度。
对于要灵活修改、插入、删除、插入到指定位置的情况,使用链表LinkedList会更方便。
对于潜在的时间复杂度较高的操作,或是可能使用频率较高的(包括测试时经常被高强度使用的)方法,考虑优化该方法内的数据结构,尽量采用如上所述的复杂度较低的数据结构,而非类似ArrayList这样不便于查找、修改的数据结构。
在我的第三次作业中,考虑到Emoji的id唯一性,我采用了一个HashMap建立从id到表情热度的方法,而非规格中要求的两个List,这样可以节省下查找两个List的时间,同样也可以简化后续程序设计。实际上,规格中很多地方采用\forall、\exist这类的表述,只是为了表明其中存在或不存在某个元素,不能机械地照抄规格,进行简单的遍历。规格给出的是理论上能够完成的计算方法,实际上为了应对多变的使用环境,需要具体结合应用场景更改实现方式。
性能问题总结
本单元作业中较可能出现性能问题的方法有:
MyNetWork类:
isCircle:
通过广度优先搜索来确定两个点是否处于同一连通分量内。
没出问题的原因大概是测试数据没有过多调用这个接口。
queryBlockSum:
查询连通分量数。
通过在添加节点和边时实时修改连通分量数而达成O(1)复杂度。
queryGroupValueSum:
组内所有人际关系权重求和。
超时原因是MyGroup的getValueSum照抄了规格的实现,而非从邻接表去找。
deleteColdEmoji:
删除冷门表情及消息。
单独使用了一个表情消息列表以避免从所有消息里遍历查找。
sendIndirectMessage:
在同一连通分量内发消息。
使用了Dijkstra算法求带权最短路径。由于使用基于BFS的isCircle,没有超时的原因大约还是数据不够强。
另外,考虑到sim可能频繁使用,设置了一个“缓存区”,每次存储上一次的最短路径权值,如果关系没有更新,且重复查询,则不再执行最短路径算法,而是直接返回上次求好的值。
MyGroup类:
getAgeMean:
求平均数。
在全局存储当前求和情况,每次求平均数就只需要计算一次除法。
getAgeVar:
求方差。
先把平均数求好,避免每计算一个元素都要调用一次求平均数。
MyPerson类:
isLinked:
查询该人是否与当前人有联系。
由于邻接表使用了HashMap,此处查询为O(1)复杂度。
架构设计总结
本单元作业的架构基本已经由JML规格给定,个人设计的部分主要在于对各种操作的优化。其中,对于两个节点是否在同一连通分量下,我采用了BFS进行遍历搜索;查找两个节点之间的最短路径,使用了Dijkstra算法。整体而言,没有做太多的优化。
心得体会
本单元整体而言较为轻松,每次作业发布基本可以一个晚上写完,不像前面表达式求导和电梯需要花很多精力。但是,在三次作业的迭代中,从第一次的照抄规格到第三次选用新的容器和算法,以及参考别的同学展示的设计,我了解到设计规格和具体实现之间并不是紧密绑定的,具体实现应该考虑应用场景,具体问题具体分析地去设计架构,这样对于程序员,可以让编码更简便,代码可读性更强;对于用户可以在保证功能实现的情况下追求性能的优越性。
但是JML这样严格的规格带来的问题就是冗长、规格自身可读性差,需要花很长时间才能理解,而且很长的一段规格描述用自然语言大概就是一两句话,这也就是实现严谨所需的代价。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号