OO第一单元总结——表达式求导
第一次作业
UML类图
复杂度分析

结构分析
本次作业中,除了主类MainClass外,我设计了三个类:
-
Reader:用于从输入中读出表达式; -
VarFactor:多项式中的一个项,包括其系数coe和指数pow; -
Polynormial:多项式,实际上是前面VarFactor的一个封装了的容器。
其中,求导接口放在了Polynormial里,具体做法是逐项从容器中提取并求导后,放入一个新的容器,最终返回的新容器是求导完成的多项式。
从UML图可见,我的第一次作业整体上体现出了一些面向对象的设计思路,单独创建了一个Reader对象用于读取式子,并在读取的时候创建多项式Polynormial的实例,由于在Polynormial内采用了HashMap容器来容纳每一项,我合并同类项的优化过程在向Polynormial内添加类的addFactor()方法内就完成了。
整体复杂度来说,其余方法都问题不大,只有VarFactor中的toString()方法复杂度较高,主要是此处使用了一个11分支的if-else if-else选择语句,把各种可能的输出情况都考虑了一遍,导致复杂度上升。
优缺点分析
优点
组织方式简单,用HashMap来装每一项,以指数为key,易于合并同类项。
缺点
正则表达式法读取在表达式复杂度加大后不再适用;
多项式的组织方式不适用于后续存在嵌套的表达式。
总而言之,本次设计的可扩展性较差,直接导致了第二次作业的重写。
测试
自测和互测均采用随机生成正则表达式,并通过sympy的检查相等性的方式测试。由于第一次作业输入较为简单,强测和互测均未被找出bug。
感受
第一次作业较为简单,强行用正则表达式全程匹配、开始时直接强行去除所有空白符等方法是可以处理的,因此较为简单就可以完成本次作业,且在正确性和性能上都拿到很好的结果。
第二次作业
我的第二次作业代码中,从第一次作业复用的全部代码如下:
public class MainClass {
public static void main(String[] args) {
}
}
除以上四句外,其余代码均为第二次作业的全新代码。
也就是说,第二次作业相较于第一次作业,进行了一次完完全全的重写。
因此,相应的类图与第一次作业有很大的区别。
UML类图

结构分析
本次作业中,除了主类MainClass外,我设计了一个接口、8个类:
接口:
Derivable:可导函数的接口,要求实现求导方法diff()和输出方法toString()。
类:
-
Constant:常数项,实现了Derivable接口; -
PowFunc:幂函数项,实现了Derivable接口; -
TriFunc:三角函数项,实现了Derivable接口; -
Plus:用加法将两项组合起来,实现了Derivable接口; -
Mult:用乘法将两项组合起来,实现了Derivable接口; -
Composite:将两项中前一项的x替换为后一项,即两项的复合,实现了Derivable接口;以上六个类为组成多项式的基本类。
-
DerivableFactory:可导函数工厂,用于制造一个符合要求的可导函数; -
Read:用于从输入中读出表达式;
由于进行了完全重写,第二次作业结构与第一次有较大不同。大体上仍采用一个单独的Read类进行表达式的读入,但是放弃了正则表达式匹配,而采取了递归下降的方法,这可以从Read的方法列表中看出。然后,表达式不再作为一个单独的类,而是将其划分为三个基本函数(常数Constant、幂函数PowFunc、三角函数TriFunc)和三种运算方式(加Plus、乘Mult、复合Composite)的结合体。这六大基本类型均作为可导函数Derivable接口的实现。大部分Read中创建函数的操作也不再由直接new完成,而是采用工厂模式,交给一个制造可导函数的工厂DerivableFactory去处理。此时,一些优化如加零、乘零、乘一、常数相加等就在工厂内完成。
优缺点分析
优点
- 采用统一的接口,将不同种类的项纳入统一管理;
- 工厂模式提高了灵活性;
- 树状结构使得表达式求导成为简单的二叉树递归中序遍历过程。
缺点
- 树状结构不利于后续优化,事实上本次作业基本放弃了高级别的优化。
复杂度分析

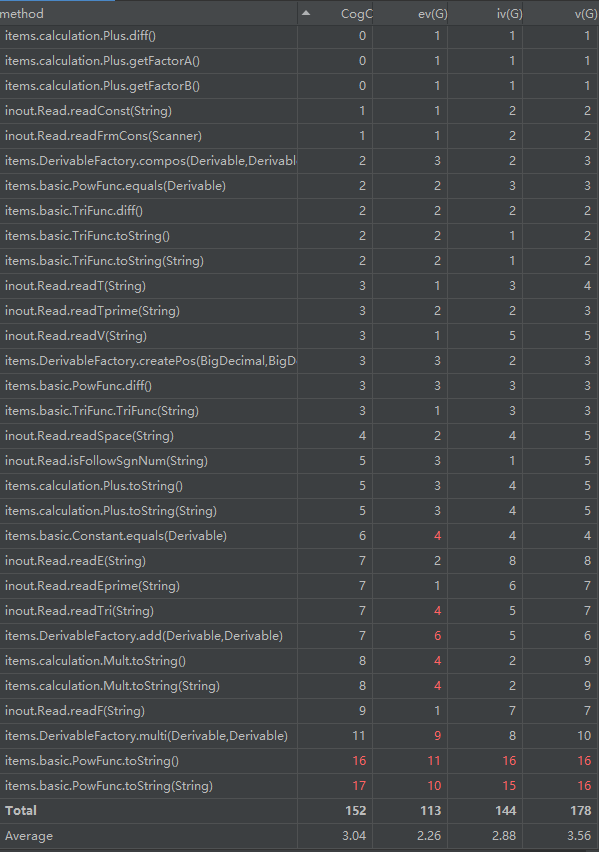
方法复杂度中可以看出,整体复杂度不高,但是幂函数的toString()方法复杂度仍然飘红,因为里面也采用了大量if-else if-else特判来简化输出。
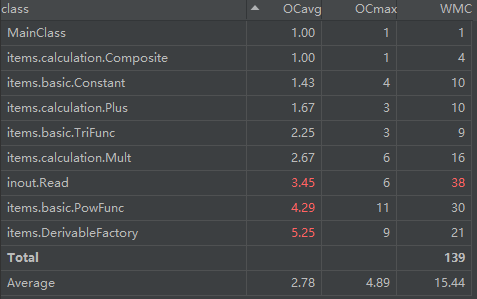
耦合度方面,可以看到Read、DerivableFactory由于要协调各类产生表达式,其耦合度较高是正常的,但是PowFunc的耦合度也较高,推测仍是因为其两个输出方法较为复杂,特判较多导致的。
测试
本次我重写了自动评测,不再采取随机生成正则表达式的方法,而是参照文法和递归下降写了生成表达式的评测机进行随机评测。经过随机评测后,我在强测处没有被找出bug,但是互测时有一处出现了由于幂函数输出优化导致丢失乘号的格式错误。
感受
第二次作业由于加入括号和三角函数,我意识到简单的暴力正则表达式匹配无法再处理这样的要求,只能全部重写,用递归下降法处理。在重写后,我发现简单地从输出层面上去优化不能起到很大作用,因此尝试在建立表达式时就进行优化,为此引入了工厂模式,也感受到工厂模式在这方面的强大。
这次作业在学习递归下降法之后实际写起来不难,花了一天时间也就重写完了。虽然这次在bug方面没有太大的问题,而且还给第三次作业预留了三角函数嵌套的接口,但是也就是预留的这个接口的问题,给我第三次作业带来了严重的bug。
第三次作业
UML类图

结构分析
第三次作业与第二次作业结构基本相同,除了给工厂增加了一些功能以支持更多的优化需求,因此具体的类设计不再列举。
优缺点分析
与第二次作业大致相同。补充如下:
优点
- 递归下降使得错误检测变得十分便利,且所有输入集中在一个
Read类使得增加该功能不需要考虑对别的功能的影响。
缺点
- 不利于高级优化。
复杂度分析
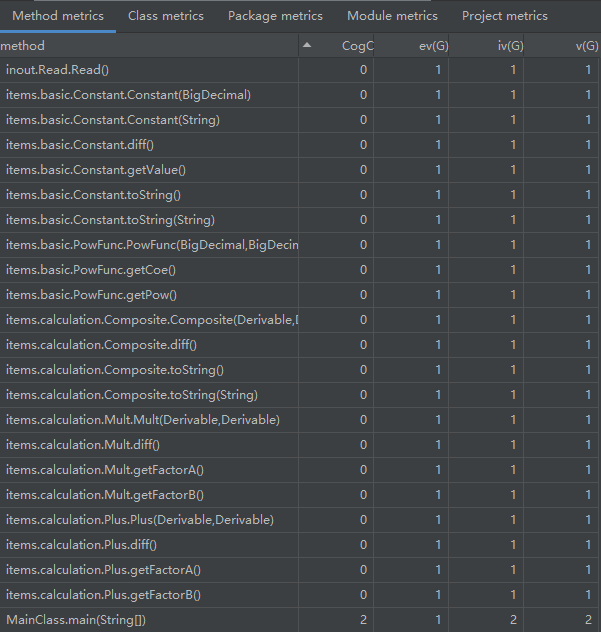
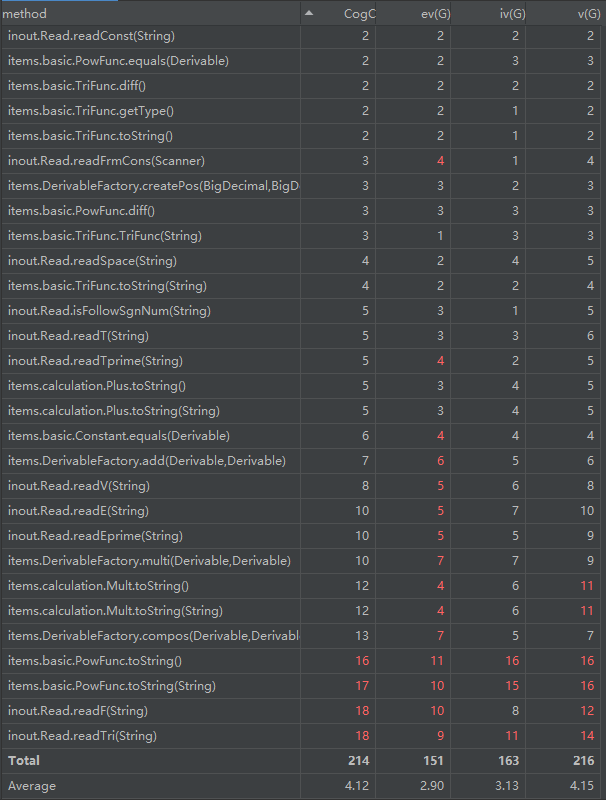
由于三角函数内嵌套和三角函数指数的引入,Read类下的几个读取方法的复杂度有所上升。整体复杂度尚可。
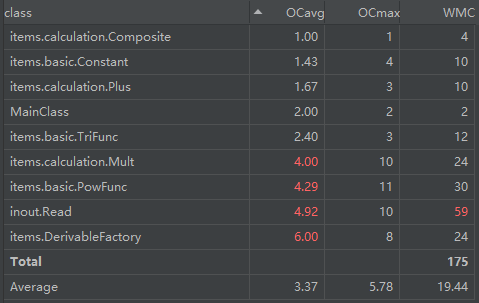
与第二次作业比起来,乘、读取和工厂类的复杂度有所上升,也是前述的新功能引入所导致的结果。
测试
第三次作业的主要问题在于测试。在对第二次作业的评测机进行修改后,直接应用于本次作业的测试,保证了本次作业求导的正确性。因此,在正确性方面,强测和互测都没有找出bug。
但是,评测机只能生成正确的样例,对于错误样例的测试有缺失,这导致我没有测出诸如sin(+ 4)这样的错误,在强测中有两处WRONG FORMAT没有检测到。强测结果公布后,通过检查,我发现问题出在第二次作业预留的接口上。第二次作业并没有直接读取sin(x)或cos(x),而是会在括号中寻找表达式——此处出现了问题,在括号中寻找的应该是因子而非表达式,此处递归下降进入的模块错误,导致三角函数内部嵌套不能识别错误格式。
修改了本处错误(一个字母),强测的两处bug就修复了。这也提示我测试需要尽量覆盖所有可能,不能简单地把程序丢给评测机就了事。
——当然互测的时候随机生成样例的自动评测机还是很管用的。
总结+感想
第一次作业拿到手就直接开始写,基本没有考虑后续迭代开发需求,也没有学习相应的知识,导致强行拿正则表达式凑了一个程序出来。由于此次作业难度较低,也就这么混过去了。但是这样的写法在第二、三次作业就不行了,因此第二次作业完全重写了一遍,且学习了递归下降法,才发现用这样的方法可以这么简单地完成读取工作。
第二次给第三次留下了迭代开发的接口,大大减轻了第三次作业需要修改的工作量。因此,相比起第二次的重写,第三次基本就是在几处检测格式的地方加上抛出WRONG FORMAT的功能就完成了。
大概的启示就是拿到一个工作,需要认真评估完成工作的方法,考虑后续迭代需求,设计一个合理的、易于维护的架构,同时不要拒绝新技术,积极学习,新技术有时可以起到事半功倍的效果,如这次的递归下降相对于原来的正则表达式匹配。
从刚开学的一周速成Java到第一次作业从零写一个表达式求导程序,在这过程中,讨论区、班级群的同学们给了我很大帮助,让我从完全没有Java和OO基础锻炼到现在已经能基本使用OOP的方法写一个简单的小程序了。经过权衡,我放弃了极限优化性能分,只保证正确性,在性能上优化也就仅限于简单地处理了同类项、常数项等,有很多想法没有写进程序,当然也就没有像有些同学每天熬夜到两三点,整体而言第一个月的OO历程还算友好。当然教训就是不要太过于偷懒导致测试不充分。
在此也要感谢所有在讨论区、课程群、班级群、研讨课给我帮助的同学们,很多合理的设计、新颖的想法也是从他们身上学到的。诸君加油!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号