
链家二手房楼盘爬虫
前言
想看下最近房价是否能入手,抓取链家 二手房 、 新房 的信息,发现广州有些精装修 88平米 的 3房2厅 首付只要 29 万!平均 1.1万/平:

查看请求信息
本次用的是火狐浏览器32.0配合 firebug 和 httpfox 使用,基于 python3 环境,前期步骤:
- 首先打开
firefox浏览器,清除网页所有的历史纪录,这是为了防止以前的Cookie影响服务器返回的数据。F12打开firebug,进入链家手机端首页https://m.lianjia.com,点击 网络 -> 头信息 ,查看请求的头部信息。

发现请求头信息如下,这个是后面要模拟的:
Host: m.lianjia.com
User-Agent: Mozilla/5.0 (Windows NT 6.3; WOW64; rv:32.0) Gecko/20100101 Firefox/32.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: zh-cn,zh;q=0.8,en-us;q=0.5,en;q=0.3
Accept-Encoding: gzip, deflate
Connection: keep-alive
查看导航链接
点击 firebug 的查看元素箭头,选中导航查看元素:

发现导航的主要是在 class=inner post_ulog 的超链接元素 a 里面,这里用 BeautifulSoup 抓取名称和 href 就好,最后组成一个字典:
# 获取引导频道
def getChannel(html):
channelDict = {}
soup = BeautifulSoup(html, "html.parser")
channels = soup.find_all("a", attrs={"class": "inner post_ulog"})
for channel in channels:
list_tmp = channel.find_all("div", attrs={"class": "name"})
channelName = list_tmp[0].get_text()
channelHref = channel.get('href')
channelDict[channelName] = channelHref
return channelDict
结果如下:
{'海外': '/i/', '卖房': '/bj/yezhu/', '新房': '/bj/loupan/fang/', '找小区': '/bj/xiaoqu/', '查成交': '/bj/chengjiao/', '租房': '/chuzu/bj/zufang/', '二手房': '/bj/ershoufang/index/', '写字楼': 'https://shang.lianjia.com/bj/'}
获取城市编码
点击页面低于按钮,获取城市编码:
发现城市的编码主要在 class=block city_block 的 div 里面,如下抓取所有就好,这里需要的是广州,广州的城市编码是 gz :
# 获取城市对应的缩写
def getCity(html):
cityDict = {}
soup = BeautifulSoup(html, "html.parser")
citys = soup.find_all("div", attrs={"class": "city_block"})
for city in citys:
list_tmp = city.find_all('a')
for a in list_tmp:
cityHref = a.get('href')
cityName = a.get_text()
cityDict[cityName] = cityHref
return cityDict
结果如下:
{'文昌': '/wc/', '大理': '/dali/', '威海': '/weihai/', '达州': '/dazhou/', '中山': '/zs/', '佛山': '/fs/', '呼和浩特': '/hhht/', '合肥': '/hf/', '南昌': '/nc/', '昆明': '/km/', '定安': '/da/', '宜昌': '/yichang/', '襄阳': '/xy/', '嘉兴': '/jx/', '厦门': '/xm/', '青岛': '/qd/', '株洲': '/zhuzhou/', '西安': '/xa/', '泉州': '/quanzhou/', '济南': '/jn/', '澄迈': '/cm/', '潍坊': '/wf/', '保定': '/bd/', '绵阳': '/mianyang/', '重庆': '/cq/', '儋州': '/dz/', '南充': '/nanchong/', '南京': '/nj/', '北京': '/bj/', '杭州': '/hz/', '滁州': '/cz/', '咸宁': '/xn/', '琼海': '/qh/', '洛阳': '/luoyang/', '绍兴': '/sx/', '廊坊': '/lf/', '惠州': '/hui/', '南通': '/nt/', '上饶': '/sr/', '湛江': '/zhanjiang/', '秦皇岛': '/qhd/', '黄石': '/huangshi/', '武汉': '/wh/', '天津': '/tj/', '哈尔滨': '/hrb/', '黄冈': '/hg/', '龙岩': '/ly/', '长春': '/cc/', '珠海': '/zh/', '邢台': '/xt/', '三亚': '/san/', '北海': '/bh/', '太原': '/ty/', '德阳': '/dy/', '万宁': '/wn/', '承德': '/chengde/', '五指山': '/wzs/', '陵水': '/ls/', '成都': '/cd/', '深圳': '/sz/', '咸阳': '/xianyang/', '烟台': '/yt/', '东莞': '/dg/', '清远': '/qy/', '西双版纳': '/xsbn/', '郑州': '/zz/', '淮安': '/ha/', '漳州': '/zhangzhou/', '常德': '/changde/', '邯郸': '/hd/', '上海': '/sh/', '开封': '/kf/', '苏州': '/su/', '衡水': '/hs/', '无锡': '/wx/', '广州': '/gz/', '银川': '/yinchuan/', '徐州': '/xz/', '大连': '/dl/', '海口': '/hk/', '晋中': '/jz/', '福州': '/fz/', '新乡': '/xinxiang/', '沈阳': '/sy/', '琼中': '/qz/', '乐东': '/ld/', '淄博': '/zb/', '眉山': '/ms/', '宁波': '/nb/', '张家口': '/zjk/', '保亭': '/bt/', '长沙': '/cs/', '临高': '/lg/', '石家庄': '/sjz/', '许昌': '/xc/', '镇江': '/zj/', '乐山': '/leshan/', '贵阳': '/gy/'}
模拟请求二手房
点击二手房链接进入二手房列表页面,发现列表页面的 url 是 https://m.lianjia.com/bj/ershoufang/index/ ,把网页往下拉进行翻页,发现下一页的 url 构造为:

只是在原来的网址后面添加了页码 pg1 ,但是在 httpfox 里面惊奇的发现了一段 json:

- 对于爬虫的各位作者有个忠告:能抓取json就抓取json!*
json是一个API接口,相比于网页来说更新频率低,网页架构很容易换掉,但是API接口一般不会换掉,且换掉后维护的成本比网页低。试想,接口只是一个dict,如果更新只要在代码里面改key就好了;而网页更新后,需要改的是bs4里面的元素,对于以后开发过多的爬虫来说,维护特别麻烦!
所以对于这里肯定是抓取 json,查看头部:
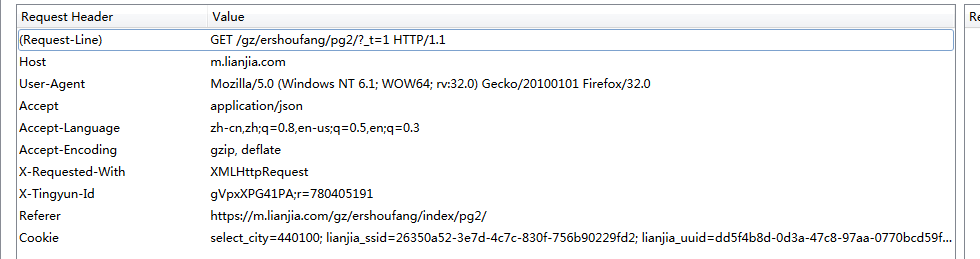
头部需要携带 cookie !
所以这里需要携带 cookie。而 requests 本身就有抓取携带 cookie 的写法。那么作者就在从获取导航链接、城市编码都获取更新 cookie。而在每一次 requests 请求的时候,返回 cookie 的代码为:
session.get(url, headers=headers)
html_set_cookie = requests.utils.dict_from_cookiejar(session.cookies)
那么在导航链接、城市编码的时候,不仅仅返回网页的 html ,还多返回一个 cookie :
print("构建城市编码url")
url_get_city = url_ori + "/city/"
print("获取城市编码", ":", url_get_city)
html_set_cookie, html_city = getHtml(url_get_city)
cityDict = getCity(html_city)
url_city = url_ori + cityDict[city]
print("访问获取导航", ":", url_city)
html_set_cookie, html_city_content = getHtml(url_city, _cookie=html_set_cookie)
然后在请求头携带 cookie :
# 解析网页
def getHtml(url, _cookie=None):
html_bytes = session.get(url, headers=headers, cookies=_cookie)
html_set_cookie = requests.utils.dict_from_cookiejar(session.cookies)
return html_set_cookie, html_bytes.content.decode("utf-8", "ignore")
这里也模拟请求头携带 cookie 后抓取下来的 json 为:
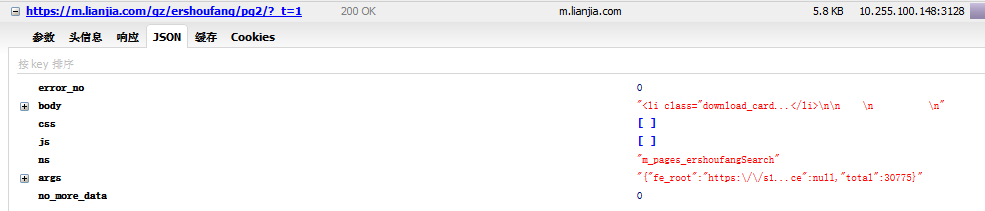
而主要的信息在 body 里面,直接解析 html 变成 dict ,提取 body 出来:
html_bytes = session.get(url_detail, headers=headerJson, cookies=html_set_cookie)
html_detail = html_bytes.content.decode("utf-8", "ignore")
detailJson = json.loads(html_detail)
发现信息都在 class=item_list 里面,直接用 bs4 抓取即可。可以抓取到的信息为:标题、标签、房子构造、面积、总价、单价、房屋朝向、详情页 url 等:

获取信息的部分代码为:
# 获取二手房的详细信息
def getInfoErshoufang(html):
detailArr = []
soup = BeautifulSoup(html, "html.parser")
detailInfo = soup.find_all("div", attrs={"class": "item_list"})
detailUrl = soup.find_all("a", attrs={"class": "a_mask"})
details = zip(detailInfo, detailUrl)
for info_url in details:
info = info_url[0]
detailDict = {}
# 获取标题
title_tmp = info.find_all("div", attrs={"class": "item_main"})
detail_title = title_tmp[0].get_text()
# 获取房屋大小
size_tmp = info.find_all("div", attrs={"class": "item_other"})
detail_size = size_tmp[0].get_text()
# 获取价格单价
price_total_tmp = info.find_all("span", attrs={"class": "price_total"})
detail_price_total = price_total_tmp[0].get_text()
try:
unit_price_tmp = info.find_all("span", attrs={"class": "unit_price"})
detail_unit_price = unit_price_tmp[0].get_text()
except:
detail_unit_price = "88888888元/平"
# 获取标签
tag_tmp = info.find_all("div", attrs={"class": "tag_box"})
detail_tag = tag_tmp[0].get_text()
# 获取详情页
url_a = info_url[1]
封装代码
为了让代码更加的和谐,这里对代码进行了封装,包括如下几个方面:
- 选择城市
- 选择查看二手房、新房等
- 详情页抓取页数
- 计算首付
- 按照首付升序排列
目前只写那么多了,毕竟博文只教方法给读者,更多抓取的信息需要各位读者根据自己的需求添加
下载源码
作者已经将源码放到 github 上面了,包括 3 个 py 文件:
- lianjia.py ,跳转页面到详情页的代码,为主代码
- GetDetail.py,抓取详情页翻页的代码
- GetInfo.py,提取详情页里面信息的代码
源代码地址为:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号