
python识别html主要文本框
在抓取网页的时候只想抓取主要的文本框,例如 csdn 中的主要文本框为下图红色框:
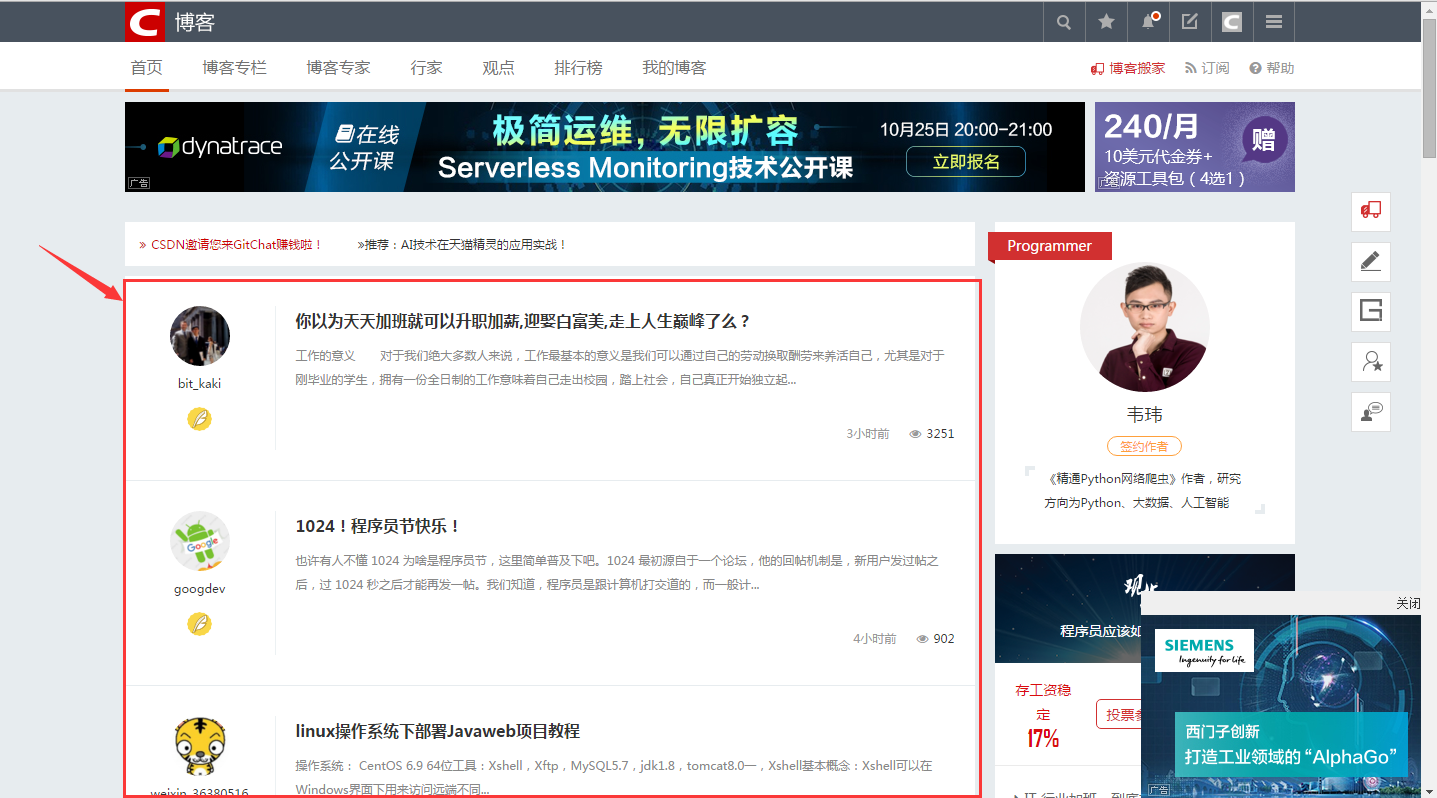
抓取的思想是,利用 bs4 查找所有的 div,用正则筛选出每个 div 里面的中文,找到中文字数最多的 div 就是属于正文的 div 了。定义一个抓取的头部抓取网页内容:
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.106 Safari/537.36',
'Host': 'blog.csdn.net'}
session = requests.session()
def getHtmlByRequests(url):
headers.update(
dict(Referer=url, Accept="*/*", Connection="keep-alive"))
htmlContent = session.get(url=url, headers=headers).content
return htmlContent.decode("utf-8", "ignore")
识别每个 div 中文字的正则:
import re
# 统计中文字数
def countContent(string):
pattern = re.compile(u'[\u1100-\uFFFD]+?')
content = pattern.findall(string)
return content
遍历每一个 div ,利用正则判断里面中文的字数长度,找到长度最长的 div :
# 分析页面信息
def analyzeHtml(html):
# 初始化网页
soup = BeautifulSoup(html, "html.parser")
part = soup.select('div')
match = ""
for paragraph in part:
content = countContent(str(paragraph))
if len(content) > len(match):
match = str(paragraph)
return match
得到主要的 div 后,提取里面的文字出来:
def main():
url = "http://blog.csdn.net/"
html = getHtmlByRequests(url)
mainContent = analyzeHtml(html)
soup = BeautifulSoup(mainContent, "html.parser")
print(soup.select('div')[0].text)
完整的代码如下:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup
import requests
import re
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/47.0.2526.106 Safari/537.36',
'Host': 'blog.csdn.net'}
session = requests.session()
def getHtmlByRequests(url):
headers.update(
dict(Referer=url, Accept="*/*", Connection="keep-alive"))
htmlContent = session.get(url=url, headers=headers).content
return htmlContent.decode("utf-8", "ignore")
# 统计中文字数
def countContent(string):
pattern = re.compile(u'[\u1100-\uFFFD]+?')
content = pattern.findall(string)
return content
# 分析页面信息
def analyzeHtml(html):
# 初始化网页
soup = BeautifulSoup(html, "html.parser")
part = soup.select('div')
match = ""
for paragraph in part:
content = countContent(str(paragraph))
if len(content) > len(match):
match = str(paragraph)
return match
def main():
url = "http://blog.csdn.net/"
html = getHtmlByRequests(url)
mainContent = analyzeHtml(html)
soup = BeautifulSoup(mainContent, "html.parser")
print(soup.select('div')[0].text)
if __name__ == '__main__':
main()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号