
K-means聚类算法
K-means算法是硬聚类算法,是典型的基于原型的目标函数聚类方法的代表,它是数据点到原型的某种距离作为优化的目标函数,利用函数求极值的方法得到迭代运算的调整规则。K-means算法以 欧式距离 作为相似度测度,它是求对应某一初始聚类中心向量V最优分类,使得评价指标J最小。算法采用 误差平方和 准则函数作为聚类准则函数。K-means 百度百科
K-means聚类算法的实质简单来说就是 两点间的距离 ,计算步骤为:
第一步--获取坐标点
本文随机生成26个字母在 0-100 的坐标点:
{'V': {'y': 81, 'x': 61}, 'H': {'y': 19, 'x': 37}, 'X': {'y': 93, 'x': 66}, 'S': {'y': 81, 'x': 89}, 'E': {'y': 23, 'x': 39}, 'T': {'y': 81, 'x': 70}, 'Q': {'y': 87, 'x': 96}, 'K': {'y': 39, 'x': 37}, 'A': {'y': 14, 'x': 7}, 'B': {'y': 6, 'x': 17}, 'I': {'y': 15, 'x': 32}, 'W': {'y': 83, 'x': 78}, 'J': {'y': 20, 'x': 21}, 'R': {'y': 81, 'x': 74}, 'Y': {'y': 89, 'x': 65}, 'M': {'y': 1, 'x': 24}, 'Z': {'y': 62, 'x': 78}, 'D': {'y': 0, 'x': 0}, 'U': {'y': 65, 'x': 98}, 'O': {'y': 73, 'x': 75}, 'C': {'y': 8, 'x': 20}, 'F': {'y': 36, 'x': 38}, 'L': {'y': 38, 'x': 12}, 'G': {'y': 34, 'x': 10}, 'P': {'y': 69, 'x': 90}}
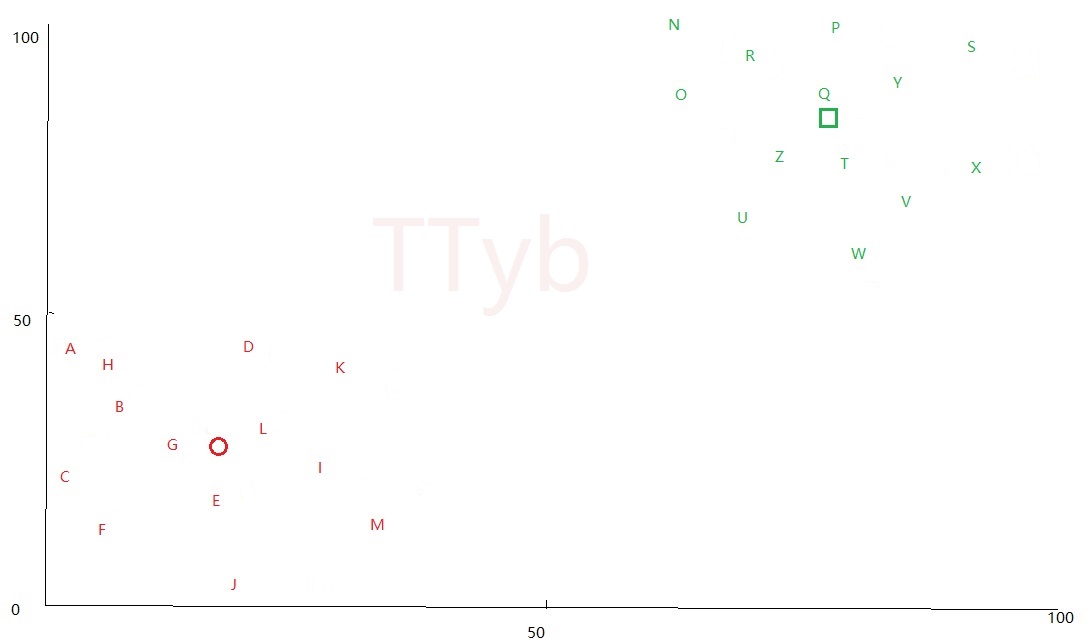
刻画在坐标图上为:

第二步--生成质点
质点也就是上图中 分簇的中心点 ,质点的个数也就是 K值 ,K=2则代表有两个分簇,也就是说有两个分簇的质点,K=3则代表有三个分簇,也就是说有三个分簇的质点。
但是最开始并不知道中心点的坐标,因此最开始生成质点的方式有两种:
- 以某两个字母的坐标点作为质点,这两个字母是随机选择的
- 在0-100内随机生成两个坐标点作为质点

上图中是以方法二得到的两个质点,分别是 红色的圆 和 绿色的框
第三步--第一次分簇
分簇需要计算两个间的距离,利用欧几里得距离可以求得:
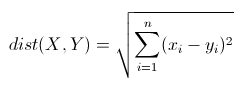
在上图中,假设一个坐标点 A点 , A点 和 红色的圆 的距离小于 A点 和 绿色的框 的距离,那么认为A点属于 红色的圆 的分簇;同理,M点 和 红色的圆 的距离大于 M点 和 绿色的框 的距离,那么认为M点属于 绿色的框 的分簇,第一次分簇得到的图形如下:
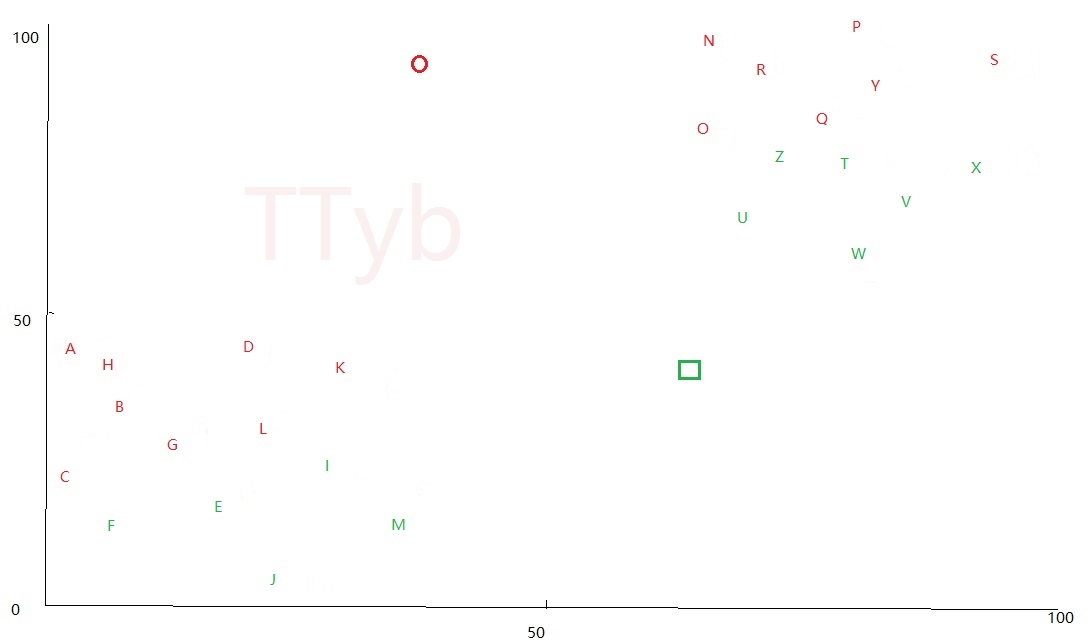
第四步--更新质点
从上图看出分簇很不合理,原因是最开始的质点是 随机 生成的,这里需要更新质点,更新的办法 简单粗暴 :
1. 得到所有红色字母的横、纵坐标
2. 分别计算横、纵坐标的平均值,平均值即为新的红色质点坐标
3. 绿色字母同理
新的质点可能偏移到下列位置:
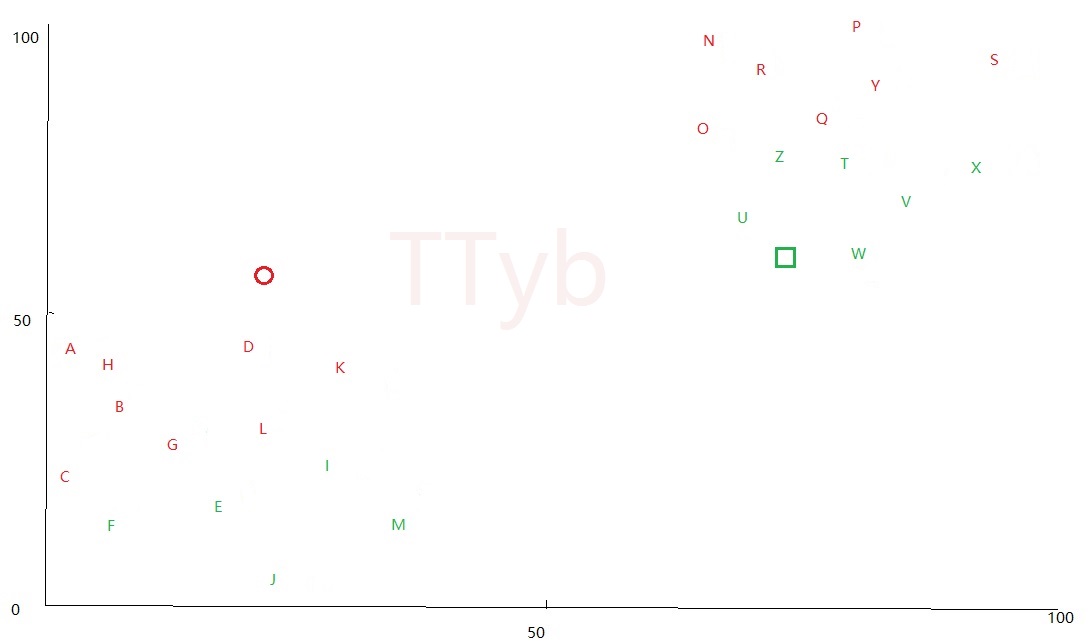
第五步--再次分簇
分簇的方法和 第三步 一样,可以得到如下形势:
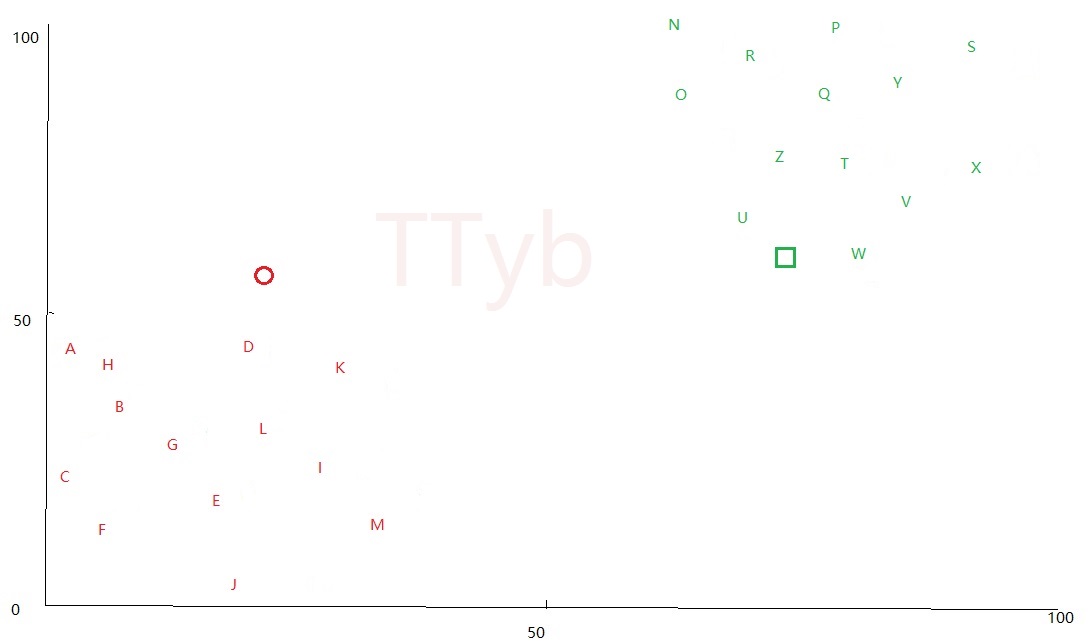
第六步--再次更新质点
由于本文只是举例,虽然看起来分簇已经很完美了,但是质点并非处于簇的中心,这里还不算分簇完成,完成的标志是:
更新质点时,更新前和更新后的质点偏移很小,或者偏移值固定不变
为什么 偏移值固定不变 也是完成的标志?原因在 第四步 的平均大法上面,这个在作者写代码时发现的,读者需要自己去实践
根据这个完成的标志,最终的 质点位置 和 分簇图 为:
第一步--获取坐标点
python随机生成 0-100 的坐标点,为了计算方便,将部分横坐标设定在 (0, 40) ,将部分纵坐标设定在 (60, 100)
# 生成坐标字典
def buildclusters():
clusters = {}
keys = [chr(i) for i in range(ord('A'), ord('Z') + 1)]
# ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z']
# 生成小数坐标
for i in range(0, int(len(keys) / 2)):
temp = {}
x = random.randint(0, 40)
y = random.randint(0, 40)
temp["x"] = x
temp["y"] = y
clusters[keys[i]] = temp
# 生成大数坐标
for i in range(int(len(keys) / 2), int(len(keys))):
temp = {}
x = random.randint(60, 100)
y = random.randint(60, 100)
temp["x"] = x
temp["y"] = y
clusters[keys[i]] = temp
return clusters
返回结果为:
# {'V': {'y': 81, 'x': 61}, 'H': {'y': 19, 'x': 37}, 'X': {'y': 93, 'x': 66}, 'S': {'y': 81, 'x': 89}, 'E': {'y': 23, 'x': 39}, 'T': {'y': 81, 'x': 70}, 'Q': {'y': 87, 'x': 96}, 'K': {'y': 39, 'x': 37}, 'A': {'y': 14, 'x': 7}, 'B': {'y': 6, 'x': 17}, 'I': {'y': 15, 'x': 32}, 'W': {'y': 83, 'x': 78}, 'J': {'y': 20, 'x': 21}, 'R': {'y': 81, 'x': 74}, 'Y': {'y': 89, 'x': 65}, 'M': {'y': 1, 'x': 24}, 'Z': {'y': 62, 'x': 78}, 'D': {'y': 0, 'x': 0}, 'U': {'y': 65, 'x': 98}, 'O': {'y': 73, 'x': 75}, 'C': {'y': 8, 'x': 20}, 'F': {'y': 36, 'x': 38}, 'L': {'y': 38, 'x': 12}, 'G': {'y': 34, 'x': 10}, 'P': {'y': 69, 'x': 90}}
第二步--生成质点
这里是 随机选取某两个点 作为初始的质点:
# 生成k个簇的质点/这里是以某个点为质点
def buildcluster(K):
centroids = {}
dic = buildclusters()
keys = []
for temp in dic.keys():
keys.append(temp)
for i in range(K):
rand = random.randint(0, len(keys) - 1)
name = "P" + str(i + 1)
centroids[name] = dic[keys[rand]]
# {'P1': {'y': 81, 'x': 79}, 'P2': {'y': 18, 'x': 5}}
return centroids
第三步--第一次分簇
需要欧几里得距离公式:
# 两点间的距离公式/欧式距离
def distance(x1, x2, y1, y2):
distan = ((x1 - x2) ** 2 + (y1 - y2) ** 2) ** 0.5
return distan
分簇的代码为:
# 分簇/簇点距离哪个质心最近就属于哪个质心的
def splitcluster(centroids, clusters, K):
# 分好的簇
newclusters = {}
# 新的质点
newcentroids = {}
# 分簇
# 26个点距离哪个质点的距离小
for key_clu in clusters.keys():
distan = {}
for key_cen in centroids.keys():
distan[key_cen] = distance(centroids[key_cen]["x"], clusters[key_clu]["x"], centroids[key_cen]["y"],
clusters[key_clu]["y"])
# 最小值的键值
name = "cluster" + minkey(distan).replace("P", "")
# 构造新字典
temp1 = clusters[key_clu]
try:
newclusters[name][key_clu] = temp1
except:
temp2 = {}
temp2[key_clu] = temp1
newclusters[name] = temp2
return newclusters
得到的结果为:
# {'cluster2': {'J': {'x': 0, 'y': 36}, 'V': {'x': 72, 'y': 98}, 'N': {'x': 82, 'y': 71}, 'P': {'x': 82, 'y': 73}, 'Q': {'x': 93, 'y': 81}, 'X': {'x': 68, 'y': 89}, 'R': {'x': 65, 'y': 60}, 'Z': {'x': 74, 'y': 89}, 'S': {'x': 99, 'y': 99}, 'D': {'x': 20, 'y': 40}, 'O': {'x': 72, 'y': 66}, 'W': {'x': 89, 'y': 82}}, 'cluster1': {'A': {'x': 37, 'y': 1}, 'E': {'x': 16, 'y': 4}, 'M': {'x': 18, 'y': 2}, 'I': {'x': 3, 'y': 11}, 'H': {'x': 2, 'y': 2}, 'L': {'x': 39, 'y': 27}, 'T': {'x': 97, 'y': 60}, 'U': {'x': 98, 'y': 72}, 'K': {'x': 21, 'y': 10}, 'C': {'x': 1, 'y': 16}, 'G': {'x': 31, 'y': 19}, 'B': {'x': 5, 'y': 22}, 'Y': {'x': 76, 'y': 62}, 'F': {'x': 11, 'y': 1}}}
第四步--更新质点
平均大法无敌:
# 根据簇的坐标得到新的质点
def getnewcentroids(dict):
centroids = {}
x = 0
y = 0
for key in dict.keys():
x += dict[key]["x"]
y += dict[key]["y"]
centroids["x"] = x / len(dict)
centroids["y"] = y / len(dict)
return centroids
更新质点:
# 更新质点
i = 0
for key in newclusters.keys():
tempdict = getnewcentroids(newclusters[key])
name = "P" + str(i + 1)
newcentroids[name] = tempdict
i += 1
第五、六步--再次分簇、更新质点
得到质点的差值:
# 得到质点差值
def centroidsoffset(centroids, newcentroids):
sum = 0
for key in centroids.keys():
sum += distance(centroids[key]["x"], newcentroids[key]["x"], centroids[key]["y"], newcentroids[key]["y"])
return sum
本文以如果质点差值不变,那么就算是最终的质点了:
while True:
newclusters, newcentroids, newdifference = splitcluster(newcentroids, clusters, K)
if tempdiff == newdifference:
print(newclusters)
print(newcentroids)
print(newdifference)
break
else:
tempdiff = newdifference
splitcluster(newcentroids, clusters, K)
源码在我的博客上面:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号