
JVM
课程:JVM-黑马(B站资源)
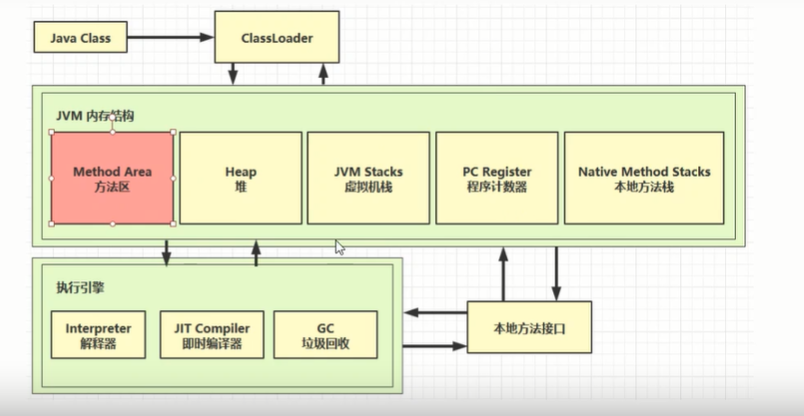
JVM内存结构;

结构细化:
1. JVM的执行过程
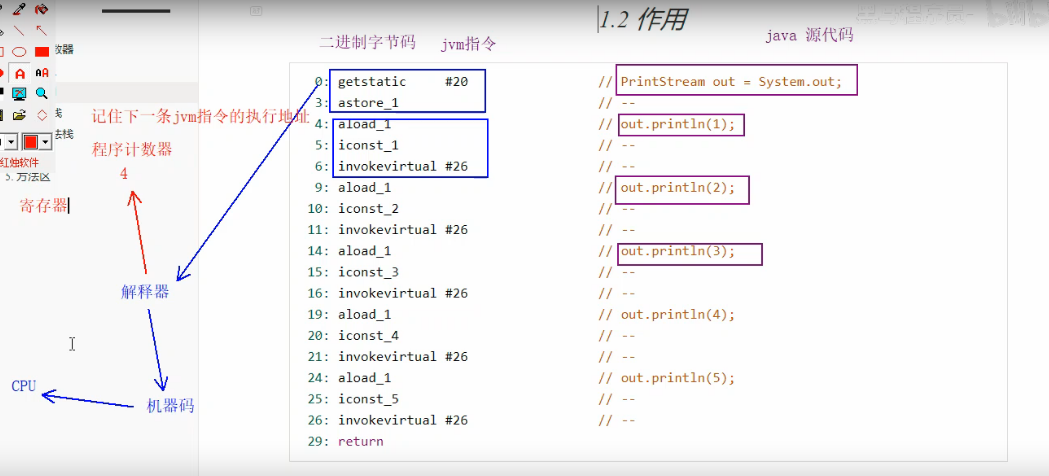
Java 源代码经过jvm编译成class二进制字节码文件后(会生成对应的jvm指令),经过解释器,把jvm指令翻译成机器码,最后交给CPU执行。
该过程涉及程序计数器,
程序计数器的作用:
记住下一条jvm指令的执行地址,即当解释器把第一条指令翻译成机器码之后,会到计数器中找下一条要被翻译的指令。程序计数器在物理上是由寄存器实现的
程序计数器的特点:
1. 线程私有的 : 当多线程时,线程1抢占cpu时间片,代码执行到地址为10的时候,此时线程2抢占了CPU时间片,线程1进入等待状态, 当线程1再次抢占到CPU时间片之后,会找到程序计数器,看下一条要执行的指令是哪一个
2. 不会存在内存溢出
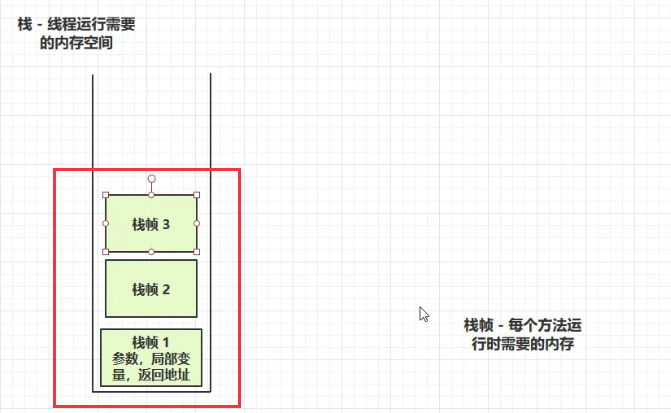
2. 虚拟机栈
- 虚拟机栈定义:每个线程运行时需要的内存空间。
- 每个栈由多个栈帧组成,对应着每次方法调用时所需要的的内存。
- 每个线程只能有一个活动栈帧,对应着当前正在执行的那个方法。
栈帧:每个方法运行时需要的内存。(该内存用于:参数、局部变量等), 多个栈针的情况:方法1调用了方法2,方法2调用了方法3
虚拟机栈:与程序计数器、本地方法栈都是属于线程私有的JVM内存区域。虚拟机栈的生命周期是和线程相同的,是在JVM运行时创建的,在线程中,方法在执行的过程创建一个栈帧。主要用于存放局部变量表、操作栈、动态链接、方法出口等信息
3.问题
1. 垃圾回收是否涉及栈内存? -- 不涉及
因为栈内存是一次次的方法调用产生的栈帧内存,而栈帧内存在每一次方法调用结束后都会自动弹出栈,自动回收掉。所以不需要垃圾回收参与,垃圾回收回收的是堆内存中的无用对象。
2. 栈内存分配越大越好吗?
栈内存可以在JVM运行时通过调整参数来指定大小。示例:- Xss Size : - Xss 1024k 即指定的内存大小为1M。 WIndows系统的JVM内存大小是继续物理内存
不是将栈内存分配的越大越好,由于物理内存是一定的,假设为物理内存为500M, 如果一个指定线程的运行时需要的栈内存为1M,一共可以运行500个线程, 如果线程运行需要的栈内存调整未2M,则最多可以运
行250个线程
3. 方法内的局部变量是否线程安全?
这个要看这个变量是对每个线程是共享的还是私有的,线程私有的不会有线程安全问题。 如果把变量改成static,两个线程都会读取,此时不安全
public class Test7 {
//static int x = 0;
static void get() {
int x = 0;
for (int i = 0;i<= 100;i++) {
x++;
}
}
}4.栈内存溢出 java.lang.StackOverflowError
情况:
- 栈帧过多导致栈内存溢出;
场景:1. 方法的递归调用,没有结束条件 ; Java对象转Json时,两个类之间的循环引用问题导致Json解析时会出现栈内存溢出,解决方案:在Json转换时打破这种循环引用,使用一个@JsonIgnore注解
- 栈帧过大导致栈内存溢出
场景:这种情况很少出现

5. 线程运行诊断
案例1:CPU占用过多
定位
- 用top定位哪个进程对cpu的占用过高
- ps H -eo pid,tid,%cpu | grep 进程id (用ps命令进一步定位是哪个线程引起的cpu占用过高)
- jstack 进程id
- 可以根据线程id 找到有问题的线程,进一步定位到问题代码的源码行号
案例2:程序运行很长时间没有结果
线程死锁
6. 本地方法栈
本地方法:Native Method : 不是有Java编写的方法,是由C或C++编写的, 本地方法运行时所需要的的内存空间叫做本地方法栈
常见的本地方法:Object类中的 hashcode()、clone()、wait()、notify()等方法都是Native修饰的方法
public final native void notify();7、Heap 堆
通过 new 关键字,创建对象都会使用堆内存
特点
- 它是线程共享的,堆中对象都需要考虑线程安全的问题
- 有垃圾回收机制
8、堆内存溢出 OutOfMemoryError
堆内存中的垃圾回收机制是在对象不再被使用的情况下才会进行回收。
调整堆内存参数:-Xmx1024m
堆内存诊断:
1. jps 工具
查看当前系统中有哪些 java 进程
2. jmap 工具
查看堆内存占用情况 jmap - heap 进程id
3. jconsole 工具(jdk目录下bin目录下 jconsole.exe)
图形界面的,多功能的监测工具,可以连续监测
9、方法区组成
jdk1.6 JVM方法区的实现使用的是永久代PermGen,占用堆内存空间。永久代理存储的是 class类信息、ClassLoader类加载器、运行时常量池,jdk1.6 运行时常量池包含StringTable
jkd1.8 JMV方法区的实现使用的是元空间MetaSpace,占用机器的物理内存。元空间也存储的是 class类信息、ClassLoader类加载器、运行时常量池. jdk1.8中StringTable位于堆中,而不是常量池中
1.永久代(在JVM中):JDK8版本之前的实现,永久代,顾名思义是永久存在,不进行垃圾回收,数据一直在里面,但是永久代存在一个问题,也就是说永久代的内存大小是给定的,也就是MaxPermSize,你不知道应
该设置为多大,如果使用默认值(非常大)的话,可能会发生OOM(OutOfMemory)内存溢出的问题,于是JDK8之后就设计出了元空间来解决此问题,把永久代从堆空间中移除
2.元空间(在本地内存):元空间是位于本地内存的一块区域,也就是说你能存放多少类的数据,不取决于MaxPermSize,而是由系统内存大小来决定,只要内存足够大,就不会发生OOM问题
10、方法区的内存溢出
1.8 以前会导致永久代内存溢出
1.8 之后会导致元空间内存溢出
场景
mybatis
* 演示永久代内存溢出 java.lang.OutOfMemoryError: PermGen space
* -XX:MaxPermSize=8m
* 演示元空间内存溢出 java.lang.OutOfMemoryError: Metaspace
* -XX:MaxMetaspaceSize=8m
11、方法区的组成部分:常量池
二进制字节码文件主要组成: 类基本信息,常量池Constant pool(里面都是一些地址),类方法定义,包含了虚拟机指令
示例:
package cn.itcast.jvm.t5;
// 二进制字节码大致由3部分组成:(类基本信息,常量池,类方法定义,包含了虚拟机指令)
public class HelloWorld {
public static void main(String[] args) {
System.out.println("hello world");
}
}
//在idea中使用Terminal进行查询,先javac HelloWorld.java得到HelloWorld.class ,在 javap -v HelloWorld.class
里面包含:
Constant pool:
#1 = Methodref #6.#15 // java/lang/Object."<init>":()V
#2 = Fieldref #16.#17 // java/lang/System.out:Ljava/io/PrintStream;
#3 = String #18 // hello world
#4 = Methodref #19.#20 // java/io/PrintStream.println:(Ljava/lang/String;)V
#5 = Class #21 // cn/itcast/jvm/t5/HelloWorld
#6 = Class #22 // java/lang/Object
#7 = Utf8 <init>
#8 = Utf8 ()V
方法:
1. 构造方法
public cn.itcast.jvm.t5.HelloWorld();
2. main方法, 方法中包含
public static void main(java.lang.String[]);
//虚拟机指令:
0: getstatic #2 // Field java/lang/System.out:Ljava/io/PrintStream; getstatic:获取一个静态变量
3: ldc #3 // String hello world ldc:加载一个参数
5: invokevirtual #4 // Method java/io/PrintStream.println:(Ljava/lang/String;)V invok :执行一次虚方法调用
8: return
// 这里面的#2 #3 等对应Constant pool常量池中的#2 #312、运行时常量池
常量池,就是一张表,虚拟机指令根据这张常量表找到要执行的类名、方法名、参数类型、字面量等信息
运行时常量池,常量池是 *.class 文件中的,当该类被加载,它的常量池信息就会放入运行时常量池,并把里面的符号地址变为真实地址
13、运行时常量池的组成部分StringTable
package cn.itcast.jvm.t1.stringtable;
// StringTable [ "a", "b" ,"ab" ] hashtable 结构,不能扩容
public class Demo1_22 {
public static void main(String[] args) {
// 常量池中的信息,都会被加载到运行时常量池中, 这时 a b ab 信息都是运行时常量池中的符号,还没有变为 java 字符串对象
// 等到程序执行到具体引导到这个代码时,才会变为a的字符串对象,同时,准备好一块空间StringTable,查看table中是否有a对象
// 如果没有,则将a放入table串池中,如果有,不添加 。 所以可以理解为懒加载 。 串池是一个hashtable结构,不能扩容
// ldc #2 会把 a 符号变为 "a" 字符串对象
// ldc #3 会把 b 符号变为 "b" 字符串对象
// ldc #4 会把 ab 符号变为 "ab" 字符串对象
String s1 = "a";
String s2 = "b";
String s3 = "ab";
// new StringBuilder().append("a").append("b").toString() new String("ab")
//初始化一个StringBuilder,调用appened方法,最后转成toString, 再new String()对象将参数放进去
//所以s4是位于堆内存中的
String s4 = s1 + s2;
String s5 = "a" + "b"; //ab 执行到这里的时候,s3的ab已经在串池中了 。 这是javac在编译期间的优化
System.out.println(s3 == s4); //false
System.out.println(s3 == s5); //true
}
}14、StringTable 特性
- 常量池中的字符串仅是符号,第一次用到时才变为对象
- 利用串池的机制,来避免重复创建字符串对象
- 字符串变量拼接的原理是 StringBuilder (1.8)
- 字符串常量拼接的原理是编译期优化
- 可以使用 intern 方法,主动将串池中还没有的字符串对象放入串池
1.8 将这个字符串对象尝试放入串池,如果有则并不会放入,如果没有则放入串池, 会把串池中的对象返回
1.6 将这个字符串对象尝试放入串池,如果有则并不会放入,如果没有会把此对象复制一份,放入串池, 会把串池中的对象返回
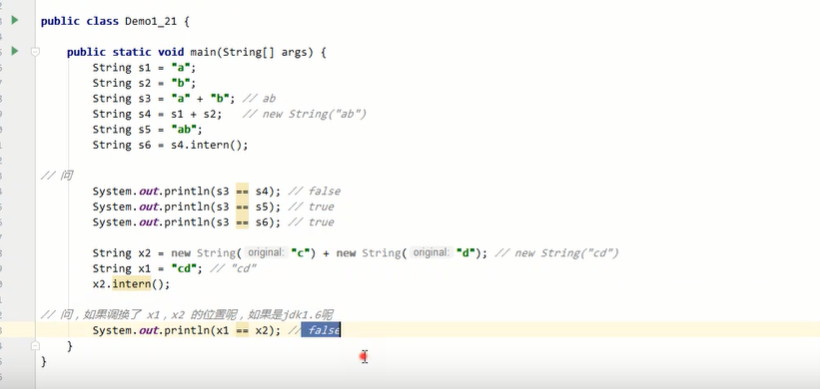
//该规则是针对jdk1.7(包含)之后才适用
package cn.itcast.jvm.t1.stringtable;
// StringTable [ "a", "b" ,"ab" ] hashtable 结构,不能扩容
public class Demo1_22 {
// 常量池中的信息,都会被加载到运行时常量池中, 这时 a b ab 都是常量池中的符号,还没有变为 java 字符串对象
// ldc #2 会把 a 符号变为 "a" 字符串对象
// ldc #3 会把 b 符号变为 "b" 字符串对象
// ldc #4 会把 ab 符号变为 "ab" 字符串对象
public static void main(String[] args) {
//情况1:先于aa.intern() 执行String bb = "ab";
//String bb = "ab";
String aa = new String("a")+new String("b");
String x = aa.intern();
String bb = "ab";
//情况2:后于aa.intern() 执行String bb = "ab";
//情况1时:在执行aa.intern()时,此时常量池中已经有[ab],所以不再往常量池中放入,但此时的引用x指向的是常量池中的bb,所以bb = x 返回true
// System.out.println(aa == x); //flase aa是对内存中的对象
// System.out.println(bb == x); //true
//情况2时:在执行aa.intern()时,此时常量池还没有[ab],所以要往常量池中放入,所以bb = x 返回true
System.out.println(aa == x); //true 当jdk为1.7之后时,为true; 但jdk1.6的时候,是把对堆中的ab进行复制了一份,放入了常量池,所以与bb定义的ab不是同一个,返回false
System.out.println(bb == x); //true
}
}测试:
15、StringTable 的位置
jdk1.6 :StringTable是位于永久代的常量池中,即1.6串池(StringTable)占用的是永久代内存, 永久代内存溢出:PermGen space
jkd1.7开始,StringTable 转移到了堆中。即1.8串池(StringTable)占用的是堆空间内存 , 对内存溢出:head space

16.StringTable的垃圾回收
StringTable内部也是会发生垃圾回收的即方法区中的字符串也会发生垃圾回收。
17.StringTable的垃圾回收
StringTable底层实现是HashTable ,HashTable,是数组+链表实现的,数组的个数称为 桶
1. 通过 -XX:StringTableSize=桶个数调整
StringTable 是靠我们的 HashTable 来实现的。即,当我们的空间足够大的时候,我们的数据就会比较分散,查询的效率也会因此降低,反之,当我们的空间比较小的时候,我们的数据就会比较集中,查询的
效率也会因此提高。当然了,StringTable 的空间大小并不是越小越好,太小了,一直进行垃圾回收,导致经常要删除老数据,添加新数据等问题也很难受。要是那些个老数据刚删掉没多久就要用到了呢。
总结:如果程序涉及到的字符串足够多的话,那么可以适当调大 StringTable 的桶的大小,优化性能。
2.考虑是否将字符串对象入池
可以通过intern方法减少重复入池,保证相同的地址在StringTable中只存储一份(如果应用点含有大量的字符串,同时字符串有很多是重复的,这时可以考虑调用intern()方法(String对象的方法)将字符串入池,可以去重,从而减少字符串个数,节约堆内存空间的占用。因为JDK1.8中StringTable是位于堆内存当中,所以较少字符串在StringTable的个数,直接减少了堆内存的占用)
18、直接内存 direct memary
不属于java虚拟机内存,属于操作系统内存。
特点:
(1)NIO操作,用于数据缓冲区。
(2)读写效率相对于普通的IO明显提高。
(3)不受JVM内存回收管理。:直接内存也会存在内存溢出,但不是JVM的垃圾回收管理的。
文件普通IO操作的底层运行原理,如果所示:
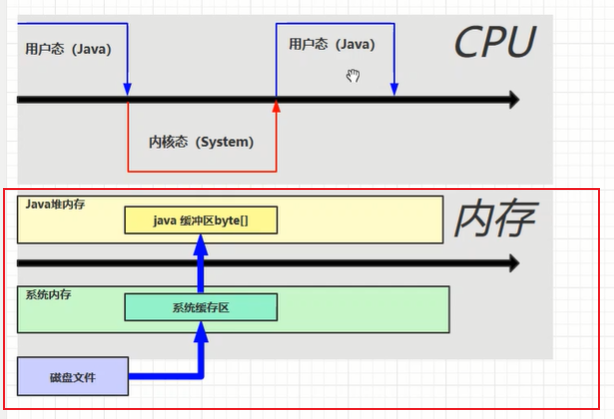
Java代码中,在读取一个文件时,CPU的状态会先从用户态转成内核态,转化成内核态之后会有CPU的函数去真正读取磁盘中的文件,然后在系统内存中开辟一个系统缓冲区,由于java代码是不能在系统缓冲区运行的,此时虚拟机堆内存会开辟一个java缓冲区,对应java中new byte,将系统缓冲区的数据间接的复制到java缓冲区,然后在进行文件的写入操作。反腐进行读写。
使用了direct buffer之后,操作的底层运行原理,如果所示:

首先需要会调用ByteBuffer.allocatedirect(_100Mb) :这个方法调用之后会在操作系统中分配一块内存,叫做直接内存(direct memary),这个直接内存,可以在任务管理器中查看,直接内存java代码可以直接
访问,不需要再次从系统内存将文件信息复制到java内存中。
19.直接内存的释放原理
通过ByteBuffer.allocatedirect(_100Mb)产生的直接内存,该内存的回收不受JVM垃圾回收管理,是JDK底层的一个Unsafe对象来管理的,分配内存是调用Unsafe.allocateMemary(100M) , 释放内存调用的是
Unsafe.freeMemary()方法。所以不是JVM的垃圾回收管理。JVM的垃圾回收中针对java内存。
java的内存回收是自动的,而直接内存的回收必须主动调用Unsafe.freeMemary()方法。
ByteBuffer.allocatedirect(_100Mb) 这个方法如何与Unsafe对象进行关联的?
在allocatedirect()方法中new了一个DirectByteBuffer, 在DirectByteBuffer的构造方法中就使用了Unsafe对象。
直接内存的分配和回收总结:
直接内存是使用了Unsafe对象完成直接内存的分配与回收,并且需要主动调用Unsafe的freeMemary()方法来进行直接内存的回收。
ByteBuffer的实现类内部,使用了Cleaner来监测ByteBuffer对象,一旦ByteBuffer对象被垃圾回收(System.gc()),那么就会有ReferenceHandler线程通过Cleaner的clean方法调用freeMemary方法来释放
直接内存。

ByteBuffer对象被垃圾回收之后,就会调用freeMemary()方法来释放直接内存。 在开发中可能存在一个问题,就是在JVM优化时,经常会加一个参数, -XX:+DisableExplictGC 这个虚拟机参数,就是禁
用显式的垃圾回收,就是让代码中的System.GC( ) 方法失效。为什么要禁用显式的垃圾回收呢,因为System.GC( ) 方法执行时,不仅要回收新生代,还要回收老年代,会造成程序暂停的时间比较长。
当禁用显式的垃圾回收之后,代码中调用的System.GC( ) 就不会执行了,进而不会触发java中的垃圾回收,所以ByteBuffer 对象不会被回收掉。也不会调用Unsafe的freeMemary()方法,所以此时直接内存无
法回收。 针对该情况的解决方案:可以使用Unsafe对象直接调用freeMemary()方法释放直接内存。
20. JVM的垃圾回收机制
垃圾回收发生在哪些区域? ——》 堆(回收对象)、方法区(不用的常量、类)
1. 如何判断一个对象可以进行回收?
共有两种算法:
(1)引用计数法:如果一个对象被引用,那么就+1,如果一个变量不在引用他了,那么就计数-1,当为0的时候,默认为可以进行回收了。(但是该算法存在一个问题:A引用B,然后B又引用A,A和B都没有被其
他对象或变量引用,但此时这两个对象的引用计数不等于0,所以不能进行回收。)
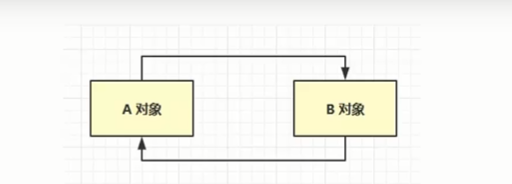
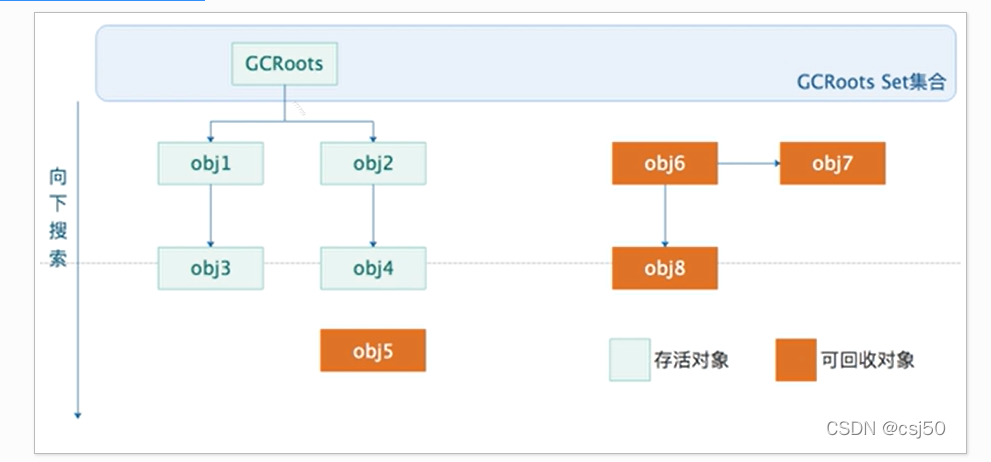
(2)可达性分析算法:首先要确定根对象(可定不能当做垃圾被回收的对象),在垃圾回收之前会先扫描一下堆内存中的对象,确认对象是不是被根对象直接或间接的引用,如果被引用了,那么就不能被回收。
JVM中事采用了该算法进行垃圾回收的。
参数文档:垃圾回收算法
2. 哪些对象可以作为GC Roots对象?
- 虚拟机栈(栈帧中的本地变量表)中引用的对象
- 方法区中类静态属性引用的对象
- 方法区中常量引用的对象
- 本地方法栈中JNI(即 Native方法)引用的对象
详细有:System Class : 系统类(Object/HashMap) 、 线程锁定的对象
21、Java虚拟机中的4种引用
参考文档:java中的4种引用
1. 强引用:大部分都是强引用,被强引用的对象不能被垃圾回收,只有强引用都断开时,该对象才可能被回收。
2. 软引用:凡是被软引用或弱引用引用的对象(不被强引用)时,在垃圾回收时,回收完了发现内存还是不够,这时只被软引用引用的对象就会被回收(前提是内存不够)。
3. 弱引用:被弱引用引用的对象,没有强引用引用他的时候,只要发生了垃圾回收,弱引用引用的对象都会被回收。不管此时内存是否足够。
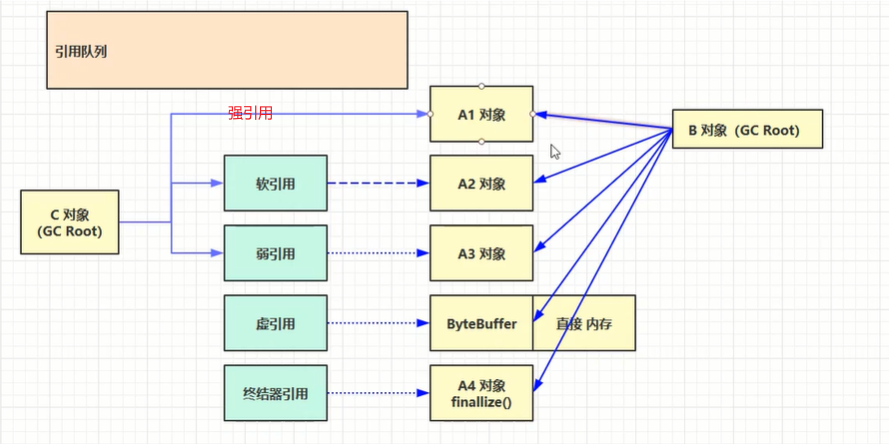
4. 虚引用:虚引用与软、弱引用的区别就是软、弱引用既可以配合引用队列使用,又可以不配合引用队列使用。 但虚引用和终结器引用必须配合引用队列使用。
原因:在创建ByteBuffer对象时就会创建一个叫Cleaner的虚引用对象,ByteBuffer会分配一块直接内存,并且把直接内存的地址传递给Cleaner虚引用对象。在ByteBuffer不再被强引用对象引用时,ByteBuffer会
被垃圾回收掉。但是由ByteBuffer分配的直接内存此时不会被释放掉,这时就需要引用队列参与,在ByteBuffer被回收时,虚引用对象Cleaner就会被放到引用队列中,有个叫ReferenceHandler的线程会定期扫描
引用队列,看引用队列中有没有新入队的虚引用对象Cleaner,如果有,则调用Cleaner的clean()方法,该方法根据前面记录的内存地址,然后调用Unsafe对象的freeMemary()方法,来释放直接内存,避免由直接
内存造成的内存泄漏。
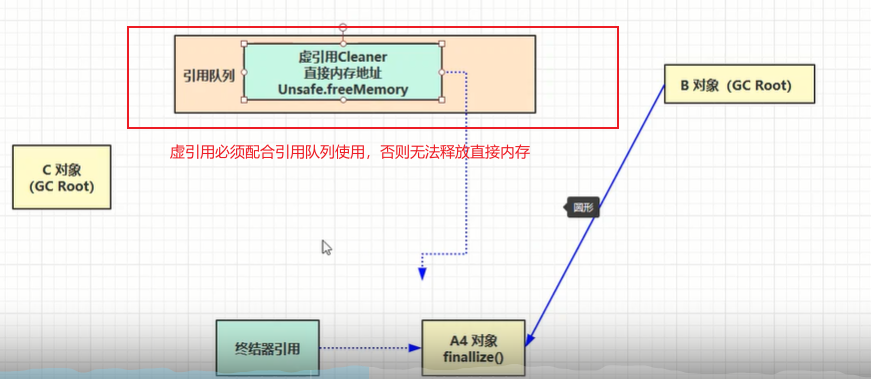
5. 终结器引用:他用于实现对象的finalize方法,finalize是Object类的方法,任何对象都继承Object,当一个对象重写finalize方法时,重写的目的就是让这个对象被垃圾回收掉,当对象没有被强引用对象引用时,
jvm在第一次垃圾回收时,会创建该对象的终结器引用,同时该终结器引用会被加入到引用队列,注意在将终结器加入引用队列时,这个对象还没有被垃圾回收掉,此时有一个优先级很低的线程FinalizeHandler定
期来扫描是不是有新加入的终结器引用,如果有,会根据这个引用找到对应的还未回收的对象,并且调用这个对象的finalize方法,等调用完finalize方法之后,这个对象占用的内存就被释放。
注意:jvm对该对象第一次进行回收时,不会被立刻回收,而是将该对象的终结器引用放入引用队列,等待优先级较低的线程FinalizeHandler来处理,根据该终结器引用找到要被回收的对象,然后调用该对象
的finalize方法,等调用完了之后,该对象才会被回收。
综上所述,不推荐使用finalize方法来释放资源,第一次垃圾回收时,还不能被回收,只是将该对象的终结器引用加入了引用队列,同时,处理入队引用队列的线程的优先级很低,即该线程被被执行的机会很
少,进而可能会造成被回收对象的finalize方法迟迟不被调用,这个对象占用的内存也迟迟得不到释放。

22.垃圾回收的算法
共3种: (1)标记清除; (2)标记整理; (3)复制
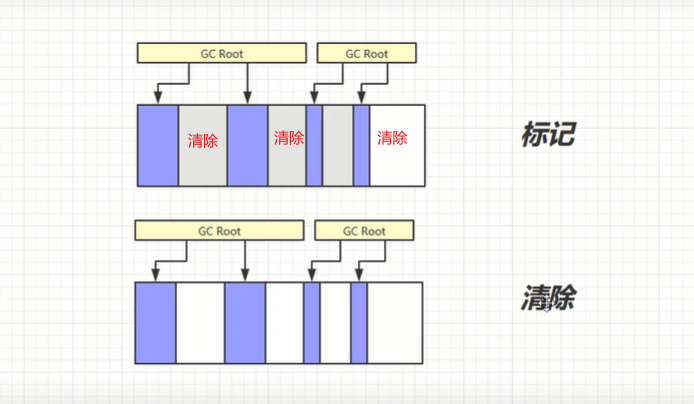
1. 标记清除:
(1)标记阶段:先标记出所有需要回收的对象;
(2)清除阶段:统一回收所有未被标记的对象;清除不是将部分内存字节清零,而是记录该内存的开始、结束地址,当下一次分配新的对象时,会找记录的地址,如果空间足够,则直接将该对象放入,覆盖之前的
对象。
标记清除算法的优缺点:
优点:速度快,在清除时只记录内存的起、止地址;
缺点:会产生内存碎片,即下一对象要放入时,要先看看被标记清除的内存的大小空间是否足够,存在一种情况,新对象较大,被标记清除的空间大小不够,就会接着找下一个被清除的内存,下一个也不够,
由于之前被标记清除的内存可能会有很多不连续的,但加起来的空间是足够容纳该对象的,所以就产生了非必要的内存碎片。
2. 标记整理:
(1)标记阶段:同上
(2)整理阶段:与标记清除不同的是,在标记完之后,会将被标记的待清理的不连续的内存合并到一起,这样减少内存碎片
标记整理的优缺点:
优点:减少内存碎片;
缺点:相对于标记清除算法效率降低,因为涉及到了未被清除对象内存地址的改变。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号