创建运行Scrapy项目
1.创建Scrapy项目
scrapy startproject 项目名称
例:
scrapy startproject myScrapyProject
scrapy项目目录结构
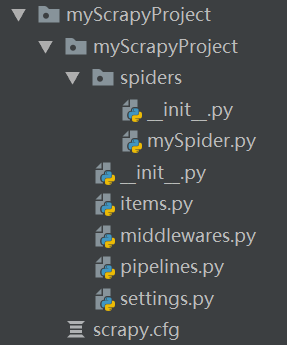
- myScrapyProject
- myScrapyProject
- spiders
- _init_.py
- 自定义的爬虫文件.py
- _init_.py
- items.py --->定义数据结构,是一个继承自scrapy.Item的类
- middewares.py --->中间件(代理)
- pipelines.py --->管道文件,里面只有一个类,用于处理下载数据的后续处理,默认是300优先级,值越小越优先
- setting.py --->配置文件
- spiders
- scrapy.cfg
- myScrapyProject
2.创建爬虫文件
在爬虫项目目录下执行
scrapy genspider 爬虫名字 网页的域名
例:
scrapy genspider mySpider www.xxx.com
爬虫文件
class MyspiderSpider(scrapy.Spider):
name = 'mySpider' #运行爬虫文件时使用的名字,必须与爬虫文件名字一致
allowed_domains = ['www.xxx.com'] #爬虫允许的域名,在爬取的时候,如果不是此域名之下的url会被过滤掉
start_urls = ['http://www.xxx.com/'] #声明了爬虫的起始地址,可以写多个url,一般是一个
def parse(self, response): #解析数据的回调函数
response.text #响应的是字符串
response.body #响应的是二进制文件
response.xpath() #xpath方法的返回值类型是selector列表
extract() #提取的是selector对象的是data
extract_first() #提取的是selector列表中的第一个数据
3.运行爬虫文件
scrapy crawl 爬虫名称
例:
scrapy crawl mySpider

 浙公网安备 33010602011771号
浙公网安备 33010602011771号