使用代理绕过网站的反爬机制
最近在尝试收集一些网络指标的数据, 所以, 我又开始做爬虫了。 :)
我们在做爬虫的过程中经常会遇到这样的情况,最初爬虫正常运行,正常抓取数据,一切看起来都是那么的美好,然而一杯茶的功夫可能就会出现错误,比如 403 Forbidden,这时候打开网页一看,可能会看到 “您的 IP 访问频率太高” 这样的提示,或者跳出一个验证码让我们输入,输入之后才可能解封,但是输入之后过一会儿就又这样了。
出现这样的现象的原因是网站采取了一些反爬虫的措施,比如服务器会检测某个 IP 在单位时间内的请求次数,如果超过了这个阈值,那么会直接拒绝服务,返回一些错误信息,这种情况可以称之为封 IP,于是乎就成功把我们的爬虫禁掉了。
既然服务器检测的是某个 IP 单位时间的请求次数,那么我们借助某种方式来伪装我们的 IP,让服务器识别不出是由我们本机发起的请求,不就可以成功防止封 IP 了吗?
所以这时候代理就派上用场了。本章会详细介绍代理的基本知识及各种代理的使用方式,包括代理的设置、代理池的维护、付费代理的使用、ADSL 拨号代理的搭建方法等内容,以帮助爬虫脱离封 IP 的 “苦海”。
获取代理
在做测试之前, 我们需要先获取一个可用代理。搜索引擎搜索 “代理” 关键字,就可以看到许多代理服务网站,网站上会有很多免费代理, 大部分免费的代理都不好用, 我也想过从一些发布免费代理的网页上采集代理的地址, 哎, 就这事, 就花了两天时间, 很多时候, 采集来的代理基本上没法用, 采集了几百个, 最后自检的时候, 就剩下不到20个alive的。
后来找到一个付费的代理, 当然付费代理就好用很多, 常用的付费代理, 我就不一一介绍了, 由于我是采集海外的资源, 所以根据一些论坛的推荐, 找到了 这家, 我也顺便发个aff, 介意勿点。
为什么推荐这个, 是因为这家让我意外的发现他们家的免费代理也很好用, 不尽快, 还能保证很高的可用性。 来看看这个免费的offer, 0元购
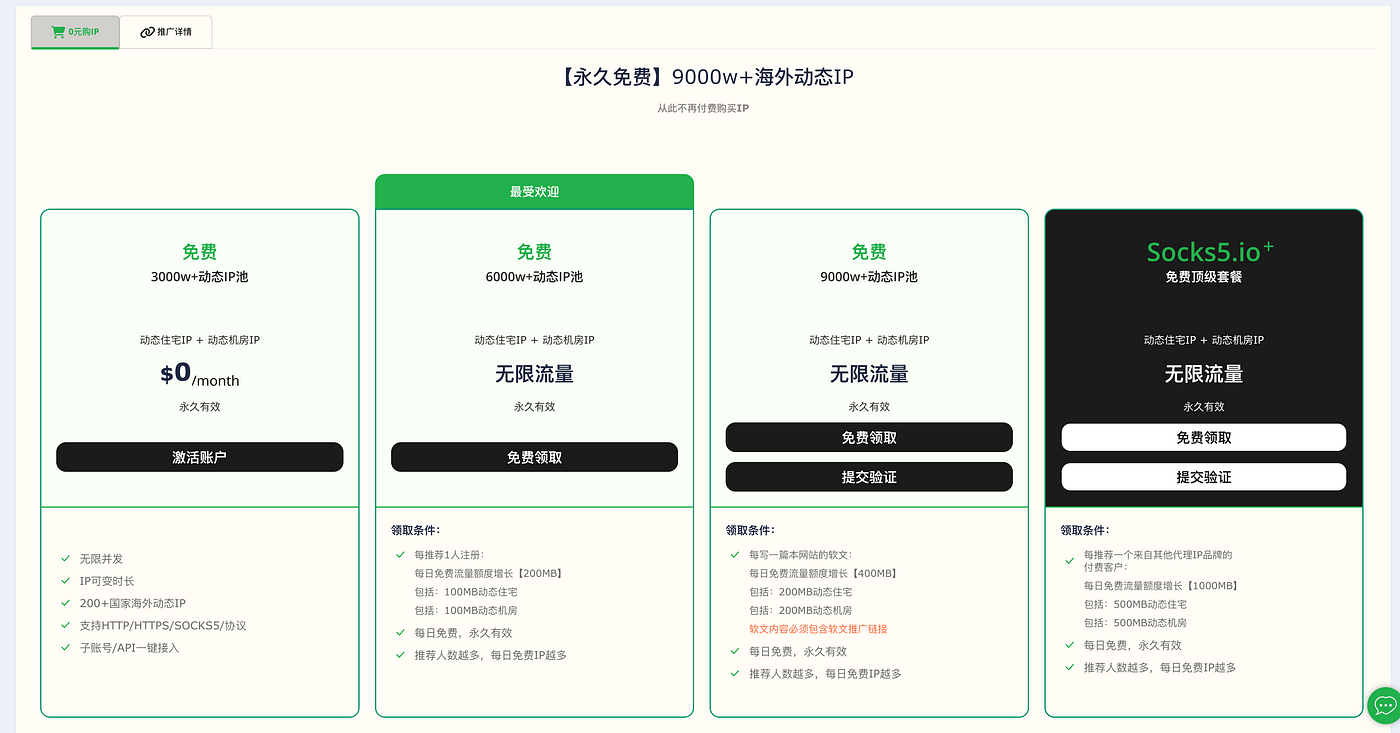
看到没, 说实话, 我现在在做的事情, 包括这篇文章, 就是为了拿到第三个offer。 Anyway, 我们先注册一个账号, 可以先免费使用部分代理, 然后我们使用代理池来确保我们的python 爬虫, 可以批量的添加代理, 或者随机选择代理。
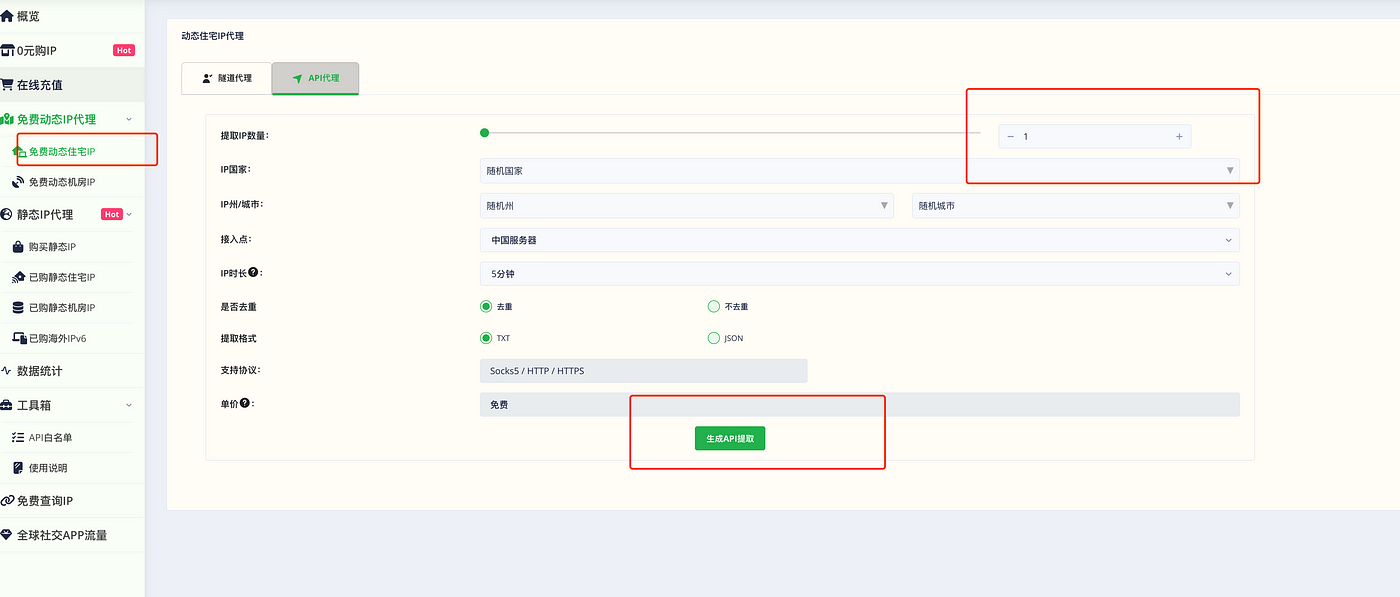
我们先选择免费动态ip代理, 然后可以提取最多100个ip, 剩下就生成API 提取就可以了。 比忘记把你自己的公网地址放到白名单里。 然后生成的url可以直接用浏览器打开, 就可以看到是这样格式的代理地址列表
随便测试一个都可以用。
使用 requests 来随机选择代理访问
对于 requests 来说,代理设置更加简单,我们只需要传入 proxies 参数即可。
还是以上例中的代理为例,我们来看下 requests 的代理的设置:
import requests proxy = '127.0.0.1:9743' proxies = { 'http': 'http://' + proxy, 'https': 'https://' + proxy, } try: response = requests.get('http://httpbin.org/get', proxies=proxies) print(response.text) except requests.exceptions.ConnectionError as e: print('Error', e.args)
那么结合我们可以每隔一段时间更新一下代理的话, 那么我们可以这样写:
proxies = [] current_proxy = 0 token = 'xxxxxx' #生成api里的token字段 def get_proxy(): global proxies url = 'http://api.socks5.io/user_get_ip_list?token={token}&type=dc&qty=100&country=&time=5&format=txt&filter=1' r = requests.get(url) if r.status_code == 200: proxies = r.text.split('\n') else: print('error in get_proxy')
# 每次获取一个代理
def get_one_proxy(): if len(proxies) == 0: get_proxy() global current_proxy p = proxies[current_proxy] if current_proxy == len(proxies) - 1: current_proxy = 0 if p is not None and p.strip() != '': current_proxy += 1 return p else: return get_one_proxy() def test_proxy(): url = 'https://baidu.com' headers = { 'User-Agent': 'customized ua -- 1.0', 'X-Requested-With': 'XMLHttpRequest', } try: p = get_one_proxy() r = requests.get(url, headers=headers, timeout=5, proxies={'http': f'http://{p}'}) if r.status_code == 200: # process html data from r.text with open(filename, 'w') as f: f.write(r.text) retry = 0 return r.text else: print(f'Error: {r.status_code}') retry = 0 return ''
这样就可以每次更换一个代理的地址来爬网页了。
