Python Programming
Topic 1 目录
- Python 简介
- Python 输入/输出
- 变量、常量与注释
- 数据类型与类型转换
- 字符串与字符串操作
- 条件执行(if / elif / else / match-case)
- 循环结构(while / for)
- 关键控制语句:break、continue、pass
- 整体总结
1️⃣ Python 简介
Python 是一种简单易学、广泛用于 AI/ML 的语言 。
Python 特点:
- 语法简单,接近英文
- 拥有大量 AI/数据科学相关库
- 跨平台
- 社区庞大
- AI/DS 领域多数开发都用 Python
两种版本:
- Python 2(已过时)
- Python 3.x(必须使用此版本)
2️⃣ Python 输入 / 输出(I/O)
✔ 输出(print 函数)
示例:
print("Hello world")
功能:将字符串输出到屏幕上 。
解释:
- print() 是函数,用于显示内容。
- 输入后直接执行。
✔ 输入(input 函数)
示例:
name = input("What is your name? ")
print("Hello " + name)
解释:
input()接收用户输入,返回值是字符串类型。- 输入的值存入变量
name。 - print 再输出拼接后的结果。
3️⃣ 变量、常量、注释
✔ 变量(Variables)
变量是用于存储数据的容器。Python 不需要提前声明类型。
示例:
a = "Hello World!"
b = 2 + 3
解释:
- a 自动变成字符串变量。
- b 自动变成整数变量。
- Python 的变量类型会随着赋值改变。
再次示例:
a = 7
a = "hello again"
解释:
变量类型可以随时改变(int → str)。
✔ 变量命名规则
变量名必须:
- 以字母或
_开头 - 不能以数字开头
- 只能包含字母、数字和
_ - 区分大小写
示例:
myName = "Nick" # CamelCase
my_name = "Nick" # snake_case
✔ 常量(Constants)
常量示例:
PI = 3.14159
MAX_MARK = 100
FILE_NAME = "test1.csv"
特点:
- 约定俗成:全部大写+下划线
- 用于“不会改变”的值。
✔ 注释(Comments)
单行注释:
# this is a comment
多行注释:
# This is line 1
# This is line 2
# This is line 3
✔ 多行字符串(docstring),不是注释!:
def add(a, b):
"""
This function adds two numbers.
a + b
"""
return a + b
1.Docstring 是一个 字符串字面量(string literal),通常放在:
-
函数定义里
-
类定义里
-
模块(文件)开头
2.这个字符串会被 Python解释器保留,不会被当作注释丢弃。
它可以通过:print(add.__doc__)被访问,是正式的文档内容。
3.用途:暂时禁用代码、做说明文档
4️⃣ Python 数据类型(Data Types)
常见内置数据类型:
- str:字符串
- int, float:数字
- bool:True / False
- list, tuple, set, range:序列
- dict:字典(键值对)
示例:
string x = "apple"
float x = 3.14
bool x = True
list x = ["apple", "banana"]
tuple x = ("apple", "banana")
set x = {"apple", "banana"}
range x = range(6)
dict x = {"name": "John", "age": 36}
1️⃣ list(列表)
✔ 有序
✔ 可变(可以修改元素)
✔ 允许重复元素
✔ 用 [] 表示
示例:
a = [1, 2, 3, 2]
a[0] = 10
print(a) # [10, 2, 3, 2]
2️⃣ tuple(元组)
✔ 有序
✔ 不可变(不能修改、删除元素)
✔ 允许重复元素
✔ 用 () 表示
示例:
t = (1, 2, 3, 2)
print(t[0]) # 1
# t[0] = 10 # ❌ 会报错:tuple 不可变
用途:适合存储不希望被修改的数据,如坐标、常量等。
3️⃣ set(集合)
✔ 无序(不能通过索引访问)
✔ 可变
✔ 不允许重复元素
✔ 用 {} 表示,但空集合用 set()
示例:
s = {1, 2, 3, 3}
print(s) # {1, 2, 3}(自动去重)
s.add(4)
print(s) # {1, 2, 3, 4}
用途:去重、做交集/并集等数学运算。
4️⃣ range(范围序列)
✔ 有序
✔ 不可变
✔ 主要用于生成整数序列,常用于循环
✔ 不真正生成所有数字,只在需要时才生成(高效)
示例:
r = range(1, 6)
print(list(r)) # [1, 2, 3, 4, 5]
5️⃣ dict(字典)
✔ key-value(键值对)结构
✔ 无序(Python 3.7+ 按插入顺序显示,但逻辑上不保证排序)
✔ 键不可重复
✔ 键必须是可哈希的(不可变类型)
✔ 用 {key: value} 表示
示例:
d = {"name": "Tom", "age": 18}
print(d["name"]) # Tom
d["age"] = 20
print(d) # {'name': 'Tom', 'age': 20}
用途:适合做映射关系,例如存储学生信息、配置文件等。
区别总结图
| 类型 | 有序 | 可变 | 可重复 | 索引访问 | 典型用途 |
|---|---|---|---|---|---|
| list | ✔ | ✔ | ✔ | ✔ | 普通序列 |
| tuple | ✔ | ✘ | ✔ | ✔ | 固定数据 |
| set | ✘ | ✔ | ✘(自动去重) | ✘ | 去重、集合运算 |
| range | ✔ | ✘ | ✔ | ✔ | 生成整数序列 |
| dict | 无序(按插入顺序显示) | ✔ | key 不可重复 | 用键访问 | 映射关系 |
✔ 类型转换(Casting)
示例:
a = int(7.1) # 7
b = str(7) # "7"
c = float(7) # 7.0
d = list(("apple", "banana"))
检查变量类型:
print(type(a))
print(type(b))
✔ input() 类型转换
因为 input 默认返回字符串,因此需要转换:
x = float(input("Key in first number"))
y = float(input("Key in second number"))
print(x + y)
解释:
- 这是数字加法,不是字符串拼接。
✔ 原地操作(In-place Operation)
示例:
x = 1
x = x + 1 # 常见写法
x += 1 # 原地操作,等价
其他示例:
*=/=%=**=(次方)
5️⃣ 字符串(String)
✔ 字符串是字符序列(可索引)
示例:
text = "Hello World!"
print(text[0]) # 输出 "H"
print(text[2]) # 输出 "l"
print(text[2:5]) # "llo"
print(text[:5]) # "Hello"
print(text[:6]) # "Hello "
print(text[1:]) # "ello World!"
print(text[:-1]) # '!'(负索引 = 从右往左)
解释:Python 字符串支持切片(slice)。
代码逐行解释 + 额外示例
text = "Hello World!"
字符串的下标如下(非常重要):
H e l l o W o r l d !
0 1 2 3 4 5 6 7 8 9 10 11
text[2] —— 取单个字符
print(text[2]) # 输出 "l"
解释:
text[2] 取得 下标为 2 的字符,也就是第三个字符 'l'。
text[2:5] —— 切片,从索引 2 到 4
print(text[2:5]) # "llo"
解释:
text[2:5] 取 index 2 到 4(不包含 5),对应:
2:l 3:l 4:o
text[:5] —— 从头到 index 4
print(text[:5]) # "Hello"
解释:
text[:5] 等同于 text[0:5]
取 0~4 → "Hello"
text[:6] —— 从头到 index 5(包含空格!)
print(text[:6]) # "Hello "
解释:
index 5 的字符是空格 " "
所以结果是 "Hello "(末尾多了空格)
text[1:] —— 从 index 1 到结尾
print(text[1:]) # "ello World!"
解释:
text[1:] 等同于 text[1 : len(text)]
取从索引 1 开始直到结束。
切片完整格式:
string[start : stop : step]
它用于在字符串(或列表、元组等序列)中截取一部分内容。
规则:
- start 包含
- stop 不包含
- 省略 start → 从头开始
- 省略 stop → 到尾结束
- step 是步长(可省略):表示每次移动多少个位置
切片规则详细解释
1. start 包含
start是起始位置(索引)- 包含这个位置
例如:
text = "abcdef"
print(text[2:]) # 从 index=2 开始
输出:
cdef
因为 index 2 的字符 'c' 被包含。
2. stop 不包含
stop是结束位置(索引)- 不包含 stop 本身
例如:
text = "abcdef"
print(text[1:4]) # index 1 到 3
输出:
bcd
注意:4 对应的是 'e',不包含!
3. 省略 start → 从头开始
text[:5]
等同于:
text[0:5]
示例:
text = "abcdef"
print(text[:3]) # 从头到 index=2
输出:
abc
4. 省略 stop → 到尾结束
text[2:]
等同于:
text[2 : len(text)]
示例:
text = "abcdef"
print(text[3:]) # 从 index=3 到结尾
输出:
def
5. 步长(step):每次移动多少个位置。
默认步长是 1:
text = "abcdef"
print(text[0:5:1])
输出:
abcde
每隔一个取一个,每次移动2步
text = "abcdef"
print(text[::2])
输出:
ace
反向切片(步长为 -1,从字符串最后倒着移动1位)
text = "abcdef"
print(text[::-1])
输出:
fedcba
总结:
切片就是:
从 start 开始取,到 stop 前一个位置结束,按 step 的间隔取。
✔ 常用字符串方法
示例:
text = "Hello World!"
print(len(text)) # 1. 字符串长度
print(text.upper()) # 2. 全大写
print(text.lower()) # 3. 全小写
print(text.isupper()) # 4. 是否全大写
print(text.islower()) # 5. 是否全小写
print(text.find("Wo")) # 6. 查找子串
运行输出:
12
HELLO WORLD!
hello world!
False
False
6
1) len(text) → 12
-
含义:返回字符串中字符的数量(长度)。
-
为什么是 12:
"Hello World!"的每个字符都计入,包括空格和感叹号。H e l l o _ W o r l d ! 0 1 2 3 4 5 6 7 8 9 10 11 → 共 12 个字符 -
备注:对于 Unicode 字符(比如某些表情或组合字符),计数规则更复杂,但对常见 ASCII 字符如上是按字符计数。
2) text.upper() → "HELLO WORLD!"
- 含义:返回一个新字符串,把原字符串中所有可转换为大写的字母都变为大写。
- 重要:不修改原字符串(字符串是不可变的),而是返回一个新的值。
- 举例:
"Hello".upper()→"HELLO";非字母(空格、标点)保持不变。
3) text.lower() → "hello world!"
- 含义:返回一个新字符串,把所有可转换为小写的字母变为小写。
- 同样不会修改
text本身。
4) text.isupper() → False
-
含义:判断字符串中的字母是否都是大写(并且至少含有一个字母)。
-
为何是
False:因为"Hello World!"既有大写H、W,也有小写ello、orld,不是全部大写,所以返回False。 -
额外说明:
isupper()只关注字母字符;数字、空格、标点不会被视为“字母”。- 例如
"HELLO!" .isupper()会返回True(标点不影响结果),但"123".isupper()返回False(没有字母)。
5) text.islower() → False
- 含义:判断字符串中的字母是否都是小写(并且至少含有一个字母)。
- 为何是
False:因为字符串中存在大写字母H和W,因此不是全部小写。 - 同理:
"hello!" .islower()会返回True。
6) text.find("Wo") → 6
-
含义:在字符串中查找子串
"Wo",返回第一次出现的起始索引;找不到则返回-1。 -
为什么是
6:按零起点索引,W在位置 6(见上面的索引表),所以"Wo"的起始位置是 6。 -
例子:
text.find("world")→-1(区分大小写,“World” 与 “world” 不同)text.find("World")→6
-
备注:
str.index("Wo")与find类似,但找不到会抛出ValueError,而非返回 -1。
小结(常见误解)
upper()/lower()返回新字符串,不会改变原变量text。如果你想永久改变,需要text = text.upper()。isupper()/islower()需要字符串中至少有一个字母字符,否则返回False。find()是 区分大小写 的查找。
✔ 去除空白:strip()
a = " Hello World "
print(a.strip()) # "Hello World"
✔ format() 格式化字符串
age = 22
txt = "My name is Chen, and I am {}"
print(txt.format(age))
解释:
txt是一个包含占位符{}的字符串。txt.format(age)会将age变量的值(这里是 22)替换掉{},从而生成完整的字符串My name is Chen, and I am 22并打印出来。
可以有多个占位符,并用多个参数替换它们。举个例子:
txt = "My name is {} and I am {} years old."
name = "Alice"
age = 30
print(txt.format(name, age))
输出:
My name is Alice and I am 30 years old.
这种格式化方法在处理动态文本和输出时非常有用,能让字符串的生成更具可读性和灵活性。
✔ 反斜杠 \(转义字符)
示例:
txt = 'It\'s alright.\n'
print(txt)
换行:\n
转义单引号:\'
6️⃣ 条件执行(Conditional Execution)
✔ if 语句
示例:
a = 38
b = 24
if a > b:
print("a is greater than b")
布尔表达式:>、<、==、!= 等。
✔ if – elif – else
if a > b:
print("a > b")
elif a == b:
print("a == b")
else:
print("a < b")
也可以使用逻辑 and:
if a > b and c > a:
print("Both conditions are True")
✔ match-case(Python 3.10 起支持)
character = input()
match character:
case 'A':
print("character is A")
case 'B':
print("character is B")
用途:对比多种情况,比 if-elif 更整洁。
7️⃣ 循环(Loops)
✔ while 循环
i = 1
while i < 6:
print(i)
i = i + 1
解释:满足条件时重复执行。
✔ 无限循环 + break
i = 1
while True:
print(i)
if i == 3:
break
i += 1
print("done")
解释:
while True永远循环break跳出循环
✔ continue 跳过当前循环
i = 0
while i < 6:
i += 1
if i == 3:
continue
print(i)
输出:1,2,4,5,6(跳过3)
✔ for 循环(遍历序列)
range()的作用- 每个示例输出什么
- 内部原理
range() 的基本功能
range() 是 Python 中用来生成一个 整数序列 的函数,常用于 for 循环。
常见的三种用法:
| 写法 | 含义 |
|---|---|
range(stop) |
从 0 开始,到 stop-1 |
range(start, stop) |
从 start 开始,到 stop-1 |
range(start, stop, step) |
从 start 开始,到 stop-1,按 step 递增/递减 |
1) 最基本版本:range(10)
for x in range(10):
print(x)
含义
生成从 0 到 9 的数字:
0, 1, 2, 3, 4, 5, 6, 7, 8, 9
输出
0
1
2
3
4
5
6
7
8
9
2) 带起始值:range(3, 10)
for x in range(3, 10):
print(x)
含义
从 3 开始 到 9 结束(不包含 10)
输出
3
4
5
6
7
8
9
3) 带起始 + 步长:range(2, 30, 3)
for x in range(2, 30, 3):
print(x)
含义
从 2 开始到 29(不含 30)
每次 加 3
生成的序列
2、5、8、11、14、17、20、23、26、29
输出
2
5
8
11
14
17
20
23
26
29
遍历字符串(不用 range)
for x in "apple":
print(x)
含义
逐个遍历字符串的每个字符:
输出
a
p
p
l
e
原理
字符串本质上是一个可迭代对象(Iterable),
for 可以直接一个一个取出字符,无需 range。
总结
| 写法 | 功能 |
|---|---|
range(10) |
0~9 |
range(3, 10) |
3~9 |
range(2, 30, 3) |
2, 5, 8, 11, ... |
for x in "apple" |
逐字符遍历 |
PDF上原例:
range 版本:
for x in range(10):
print(x)
带起始与步长:
for x in range(3, 10):
print(x)
for x in range(2, 30, 3):
print(x)
遍历字符串:
for x in "apple":
print(x)
✔ 使用占位变量 _
在 Python 中,_ 常常用作一个占位符变量,特别是当你不打算使用这个变量时。在循环或其他结构中,如果你不需要循环变量的值,可以使用 _ 来代替它。这不仅清晰地表达了你不打算使用该变量,还能避免产生不必要的命名警告。
for _ in range(3):
print("Hello World!")
在上面的代码中,_ 表示循环变量在这次循环中不会被使用,只是单纯地重复执行 print("Hello World!") 三次。
8️⃣ pass 语句
pass 是一个占位语句,它用于在代码块中暂时不执行任何操作,通常用于占位或者作为未完成代码的占位符。当你需要写一个语法上有效的代码块,但又不想在某个阶段实际执行任何操作时,pass 就非常有用了。
for x in [0, 1, 2]:
pass
在上面的代码中,pass 语句表示这个 for 循环没有实际的操作,只是占据了位置。这种情况可能出现在你编写代码时,暂时还没有想好具体的逻辑,或者需要保持代码结构完整,但不执行任何操作。
总结:
_用于表示你不关心的变量。pass用于占位,表示目前没有实现的代码块。
解释含义
1. for x in [0, 1, 2]:
让变量 x 依次取列表中的每一个值:
- 第一轮:
x = 0 - 第二轮:
x = 1 - 第三轮:
x = 2
Python 会循环 3 次。
2. pass
pass 表示“什么也不做”。
它是一个 占位语句,通常在需要写语法结构(循环、函数、if等)但暂时不想写具体逻辑时使用。
例如:
- 代码还没写好
- 需要一个空的循环结构
- 需要空函数、空类等
所以整段代码的意思:
👉 “循环遍历 [0, 1, 2],但每次循环都不做任何事情。”
也就是说,这段代码运行时 没有任何输出,也不产生任何效果。
简单示例展示 pass 的用途
空循环(等于啥都不做)
for i in range(5):
pass
空函数
def todo():
pass
空类
class MyClass:
pass
这些都合法,因为 pass 让 Python 语法结构保持完整。
9️⃣ 第 1 章总结要点:
- 基本输入输出
- 变量
- 数据类型
- 条件执行:if / while / for
- break、continue、pass
Topic 2 目录
- Python 内建数据结构概览
- List(列表)
- 列表特性
- 创建方法、访问方式、修改方式
- 添加、插入、删除、排序、遍历
- 方法总表
- 例子逐行解释 - Tuple(元组)
- 特性、创建、访问
- 不可变性质、如何绕开不可变
- 常用方法
- 例子解释 - Dictionary(字典)
- 特性、键值对访问
- keys, values, items
- 修改、增加、删除
- 嵌套字典
- 字典推导式
- 例子解释 - Set(集合)
- 特性、唯一性、无序性
- 添加、合并、更新
- 集合的数学操作(并、交、差)
- 例子解释 - 四种数据结构总结对比
1️⃣ Python 内建数据结构概览
Python 提供四种常用数据结构,用来存储多个数据元素:
| 数据结构 | 符号 | 是否有序 | 是否可修改 | 是否可重复 | 特点 |
|---|---|---|---|---|---|
| List | [] |
✔ 有序 | ✔ 可修改 | ✔ 可重复 | 使用最广,灵活 |
| Tuple | () |
✔ 有序 | ✘ 不可修改 | ✔ 可重复 | 安全、快速 |
| Dictionary | {key:value} |
✔(3.7 后有序) | ✔ 可修改 | ✘ 键不可重复 | 键值对存储 |
| Set | {} |
✘ 无序 | ✔ 可修改 | ✘ 不可重复 | 自动去重、集合操作 |
2️⃣ List(列表)
✔ 列表特性
- 使用
[]创建 - 可以包含不同类型的元素
- 有序(保持插入顺序)
- 可修改:增删改都可以
- 可以有重复元素
➤ 列表的创建
fruits = ["apple", "banana", "cherry", "durian"]
mixed = ["apple", 2, "cherry"]
分析:
fruits是字符串列表mixed是混合类型列表(Python 允许)
代码举例
import random # 导入 random 模块,用于生成随机数字
loc = [' '] * 9 # 建立一个长度为 9 的列表表示棋盘,初始全部为空格
def AI_turn(): # 定义 AI 落子(回合)函数
while True: # 使用无限循环,直到 AI 成功找到一个空位
choice = random.randint(1, 9) # 随机生成一个 1~9 的位置(AI 随机落子)
if loc[choice] == ' ': # 如果该位置是空的(没有被占用)
loc[choice] = 'o' # 将 AI 的棋子 'o' 放到该位置
break # 成功落子后跳出循环,结束 AI 行动
loc = [' '] * 9 是 Python 列表(list)的重复语法。
它的作用是创建一个含有 9 个空格字符串 ' ' 的列表:
[' ', ' ', ' ', ' ', ' ', ' ', ' ', ' ', ' ']
也就是把列表 [' '] 重复 9 次。
语法解释:列表乘法(List Multiplication)
在 Python 中:
list * n
表示把这个列表重复 n 次,然后拼接成一个新的列表。
例如:
[1] * 4 -> [1, 1, 1, 1]
['A'] * 3 -> ['A', 'A', 'A']
[' '] * 9 -> [' ', ' ', ' ', ' ', ' ', ' ', ' ', ' ', ' ']
为什么用它来初始化棋盘?
因为井字棋有 9 个位置,需要一个长度为 9 的空格列表来表示:
loc[0]= 位置 1loc[1]= 位置 2- …
loc[8]= 位置 9
每个位置初始为空 ' ',表示“没有下棋子”。
总结 AI_turn() 的核心逻辑
- AI 随机选择一个格子(1 到 9)。
loc = [' '] * 9是用列表重复语法创建一个含 9 个空格的列表,表示 9 个空的棋盘格。 - 检查该格子是否为空。
- 如果为空 → 在此位置放入 AI 的棋子
'o'。 - 如果不为空 → 继续循环,再随机选一个位置。
- 一旦成功落子 →
break结束函数。
➤ 列表访问(索引)
fruits = ["apple", "banana", "cherry", "durian"]
print(fruits[0]) # apple
print(fruits[1]) # banana
print(fruits[-1]) # durian(倒数第一)
print(fruits[1:3]) # ["banana", "cherry"]
print(fruits) # ['apple', 'banana', 'cherry', 'durian']
print(fruits[:]) # ['apple', 'banana', 'cherry', 'durian']
print(fruits[]) # 报错
解释:
fruits[1]:第二个元素fruits[-1]:最后一个元素fruits[1:3]:切片,从 1 到 2(不含 3)
如果想打印列表的所有内容,但不要方括号 [],有几种常用方法:
1. 用 join()(最常用、最优雅)
join() 要求列表中是 字符串,刚好你的水果都是字符串。
fruits = ["apple", "banana", "cherry", "durian"]
print(" ".join(fruits))
输出:
apple banana cherry durian
如果想用逗号:
print(", ".join(fruits))
输出:
apple, banana, cherry, durian
2. 用 print(*fruits)(最简单的方法)
print(*列表) 会自动把列表拆开来打印,不带括号、不带逗号。
print(*fruits)
输出:
apple banana cherry durian
你可以换分隔符:
print(*fruits, sep=", ")
输出:
apple, banana, cherry, durian
3. 循环打印
for f in fruits:
print(f)
输出(每行一个):
apple
banana
cherry
durian
➤ 检查元素是否存在
if "cherry" in fruits:
print("'cherry' is in the fruits list")
➤ 添加与插入
fruits.append("orange") # 末尾添加
fruits.insert(1, "pineapple") # 在位置 1 插入
第一行:创建列表
fruits = ["apple", "banana", "cherry", "durian"]
含义:
创建一个名为 fruits 的列表,里面有 4 个字符串:
["apple", "banana", "cherry", "durian"]
第二行:fruits.append("orange")
fruits.append("orange")
含义:
append() 会 把元素添加到列表的最末尾。
执行后,列表变为:
["apple", "banana", "cherry", "durian", "orange"]
特点:
append()只能添加一个元素- 永远添加到最后
第三行:fruits.insert(1, "pineapple")
fruits.insert(1, "pineapple")
含义:
insert(索引, 元素) → 把 "pineapple" 插入到 索引 1(第二个位置)。
执行所有代码后 fruits列表等于:
['apple', 'pineapple', 'banana', 'cherry', 'durian', 'orange']
原来索引 1 的 "banana" 会自动往后移动。
➤ 修改元素
fruits[1] = "orange" # 替换一个
fruits[1:3] = ["pineapple", "orange"] # 替换两个
fruits[1:2] = ["mango", "peach"] # 用两个替换一个
1. fruits[1] = "orange" —— 替换一个元素
fruits = ["apple", "banana", "cherry", "durian"]
fruits[1] = "orange"
含义:
- 访问索引
1(即第二个元素"banana") - 用
"orange"替换它
修改后:
["apple", "orange", "cherry", "durian"]
2. fruits[1:3] = ["pineapple", "orange"] —— 替换两个元素
fruits = ["apple", "banana", "cherry", "durian"]
fruits[1:3] = ["pineapple", "orange"]
含义:
- 切片
1:3→ 包含索引 1 和 2,即:
["banana", "cherry"] - 用
["pineapple", "orange"]替换这两个
修改后:
["apple", "pineapple", "orange", "durian"]
✔ 左右数量相同;
✔ 列表长度不变。
3. fruits[1:2] = ["mango", "peach"] —— 用多个替换一个
fruits = ["apple", "banana", "cherry", "durian"]
fruits[1:2] = ["mango", "peach"]
含义:
- 切片
1:2→ 只包含索引 1(即"banana") - 用两个元素
["mango", "peach"]替换它
修改后:
["apple", "mango", "peach", "cherry", "durian"]
✔ 用 2 个替换 1 个
✔ 列表长度增加 1
✔ 切片赋值可以改变列表长度!
总结对比
| 代码 | 修改方式 | 列表长度变化 |
|---|---|---|
fruits[1] = "orange" |
替换单个元素 | 不变 |
fruits[1:3] = ["pineapple", "orange"] |
两个替换两个 | 不变 |
fruits[1:2] = ["mango", "peach"] |
两个替换一个 | 增加 |
列表排序(sort)
-
数字:从小到大
-
字符串:按字典序(Unicode),从a到z。先比第 1 个字符,相同再比第 2 个,不同字母按 Unicode 编码比较
-
大写字母优先级高于小写字母(因为 ASCII 值小)
-
不同类型无法比较
从 A → Z 排序(默认)
会按照字母顺序排序。
例子:
fruits = ["banana", "apple", "durian", "cherry"]
fruits.sort()
print(fruits)
输出:
['apple', 'banana', 'cherry', 'durian']
反向排序(Z → A)
fruits.sort(reverse=True)
输出:
['durian', 'cherry', 'banana', 'apple']
按 key 排序(高级功能)
例如按字符串长度排序:
fruits.sort(key=len)
输出:
['apple', 'banana', 'cherry', 'durian'] # 按长度从短到长
反向:
fruits.sort(key=len, reverse=True)
sort() 会修改原列表!
如果你想保留原列表,用 sorted():
new_list = sorted(fruits)
没错,你说的完全正确!👍
list.sort() vs sorted() 的区别
1)list.sort()
- 原地排序(in place)
- 会修改原列表
- 返回值是 None
例子:
fruits = ["banana", "apple", "cherry"]
new_list = fruits.sort()
print(fruits) # ['apple', 'banana', 'cherry']
print(new_list) # None
2)sorted(iterable)
- 不会修改原列表
- 返回一个 新的排序列表
例子:
fruits = ["banana", "apple", "cherry"]
new_list = sorted(fruits)
print(fruits) # ['banana', 'apple', 'cherry']
print(new_list) # ['apple', 'banana', 'cherry']
列表合并 extend
extend 的作用
把 local_fruits 的所有元素展开后加入到 fruits 末尾。
例:
fruits = ["apple", "banana"]
local_fruits = ["cherry", "durian"]
fruits.extend(local_fruits)
print(fruits)
输出:
['apple', 'banana', 'cherry', 'durian']
extend() 会修改原列表。
extend vs append 的区别(最重要)
a.append(b) # 把整个 b 当作一个元素加入
a.extend(b) # 把 b 的元素展开加入
例:
a = [1, 2]
b = [3, 4]
a.append(b)
print(a)
输出:
[1, 2, [3, 4]]
再看 extend:
a = [1, 2]
a.extend([3, 4])
print(a)
输出:
[1, 2, 3, 4]
其他合并写法(你可以选择)
fruits = fruits + local_fruits # 返回一个新列表
fruits += local_fruits # 就地扩展(类似 extend)
remove / pop 删除元素
原例:
fruits.remove("cherry") # 按值删
fruits.pop(2) # 按索引删除
remove(value)删除
删除第一个匹配的值
fruits.remove("banana")
如果有多个相同的值,只删第一个。
remove 删除不存在的值会报错
fruits.remove("watermelon")
会报:
ValueError: list.remove(x): x not in list
pop(index)删除
根据索引删除并返回删除的元素
deleted = fruits.pop(2)
print("删除了:", deleted)
输出:
删除了: cherry
不写 index → 默认删除最后一个
fruits.pop()
pop 超出索引会报错
fruits.pop(100)
错误:
IndexError: pop index out of range
pop 会返回删除的值
1️. 取出并处理某个元素
从列表中“拿出来”某个元素并立即处理,而不是仅仅删除。
numbers = [10, 20, 30, 40]
removed = numbers.pop(2)
print(removed) # 30
print(numbers) # [10, 20, 40]
用处:
- 想得到被删除的东西
- 想要对它做进一步计算
2. 实现“栈(stack)”的数据结构
栈是后进先出(LIFO)结构,pop() 可用来取出栈顶元素。
stack = [1, 2, 3]
item = stack.pop() # 默认 pop(-1)
print(item) # 3
print(stack) # [1, 2]
如果没有“返回值”,就不能获取被弹出的元素做逻辑处理。
3️. 从列表移动元素到另一个列表
你想把值从一个列表取出来放到另一个列表:
source = [10, 20, 30]
target = []
value = source.pop(0) # 取出 10
target.append(value)
print(target) # [10]
print(source) # [20, 30]
4️. 在循环中动态取出元素
处理队列(queue)或优先取任务时非常常见:
tasks = ["task1", "task2", "task3"]
while tasks:
task = tasks.pop(0)
print("处理:", task)
输出:
处理: task1
处理: task2
处理: task3
如果不用返回值,你就无法知道你取出的任务是什么。
del 删除(补充)
del fruits[1] # 删除索引1
del fruits[1:3] # 删除一段
del 不返回删除的值。
总结
| 操作 | 功能 | 是否返回值 | 会修改原列表 |
|---|---|---|---|
| sort() | 排序 | ❌ | ✔ |
| extend() | 扩展列表 | ❌ | ✔ |
| remove(value) | 按值删 | ❌ | ✔ |
| pop(index) | 按索引删 | ✔ | ✔ |
| del | 按索引/切片删 | ❌ | ✔ |
列表方法总表(PDF 原文)
| 方法 | 说明 |
|---|---|
| append() | 尾部添加 |
| clear() | 清空列表 |
| copy() | 复制 |
| count() | 某值出现次数 |
| extend() | 合并列表 |
| index() | 找到值的位置 |
| insert() | 插入 |
| pop() | 删除并返回元素 |
| remove() | 删除指定值 |
| reverse() | 反序 |
| sort() | 排序 |
⭐ Finger Exercise – 例子解释
代码:
fruits = []
for _ in range(3):
fruits.append(input("Name a fruit: "))
print(fruits)
for fruit in sorted(fruits):
print(fruit)
逐行解释:
fruits = []建立空列表for _ in range(3):循环 3 次;_表示不关心变量名- 每次
input()获取用户输入并放入列表 sorted()返回排序后的新列表- 最后逐行打印水果名
前面有提到不同类型不能比较,会报错,但是如果我这个程序分别输入 1 2 A,还是可以比较
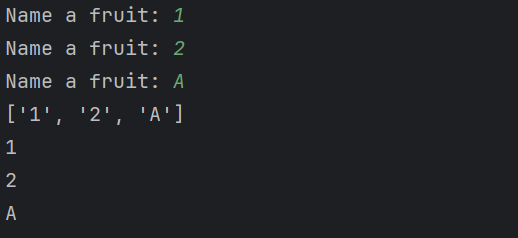
关键原因:input() 的返回值永远是字符串 str
用户输入:
1
实际上执行:
fruits.append("1") # append了 "1" 这个字符
输入:
1
2
A
fruits列表内容实际上是:
fruits = ["1", "2", "A"]
全部是字符串类型,同类型之间当然可以排序,所以不会报错。
那排序结果是什么?
按照字符串的排序规则(字典序 / Unicode):
字符的 ASCII 值比较顺序:
"A" = 65
"1" = 49
"2" = 50
所以顺序从小到大:
1 (ASCII 49)
2 (ASCII 50)
A (ASCII 65)
结果:
["1", "2", "A"]
打印时:
1
2
A
3️⃣ enumerate() 函数
将列表变成 “(索引, 值)” 形式的可迭代对象。
例子:
fruits = ["apple", "banana", "cherry"]
enu_fruits = enumerate(fruits, 10)
for index, item in enu_fruits:
print(index)
print(item)
解释:
enumerate(fruits, 10):从索引 10 开始- 每轮循环返回
(index, value) - 输出:
10 apple
11 banana
12 cherry
4️⃣ List Comprehension(列表推导式)
普通写法:
new_list = []
for x in fruits:
if "a" in x:
new_list.append(x)
推导式:
new_list = [x for x in fruits if "a" in x]
5️⃣ Tuple(元组)
特性
- 使用
() - 不可修改(immutable)
- 可包含不同类型
- 访问方式与列表一样
例子:
fruits = ("apple", "banana", "cherry", "banana")
常用方法
fruits.count("banana")
fruits.index("banana")
元组不可变,但可绕过:
this_tuple = ("apple", "banana", "cherry")
y = list(this_tuple) # 转列表
y.remove("apple")
this_tuple = tuple(y) # 转回元组
6️⃣ Dictionary(字典)
基本用法
car = {"brand": "BYD", "model": "SEAL", "year": 2024}
print(car["model"])
查看 keys、values、items
car.keys()
car.values()
car.items()
修改、增加
car["year"] = 2025
car["color"] = "RED"
删除
car.pop("model")
嵌套字典
cars = {
"car_1": {"brand": "Toyota", "model": "Corolla", "year": 2010},
"car_2": {"brand": "Mazda", "model": "CX5", "year": 2018}
}
print(cars["car_1"]["model"])
字典推导式
fruits = ["apple", "banana", "cherry"]
fruit_lengths = {fruit: len(fruit) for fruit in fruits}
7️⃣ Set(集合)
特性
{}表示- 无序、不重复
- 自动去重
例子:
this_set = {"apple", "banana", "cherry", "banana"}
输出将自动去掉重复值。
集合运算
Set_1 = {1, 2, 3, 4}
Set_2 = {2, 3, 5, 6}
Set_1 | Set_2 # 并集
Set_1 & Set_2 # 交集
Set_1 - Set_2 # 差集
总结对比
| 数据结构 | 优点 | 缺点 | 典型用途 |
|---|---|---|---|
| List | 灵活,可改,可重复 | 操作速度比 tuple 慢 | 收集任意数据 |
| Tuple | 不可变、安全、快 | 不能改 | 配置、固定数据 |
| Dictionary | 键值对结构清晰 | 键必须唯一 | 表示对象、资料结构 |
| Set | 自动去重、数学集合 | 无序、不能索引 | 唯一值、交并差 |
Topic 3 目录
讲解 Python 函数(Functions) 的所有基础与进阶概念,包括:
- 什么是函数、为什么使用函数
- 内建函数的使用方式
- 如何自定义函数
- 函数命名规范
- 参数(parameters)与参数传递(arguments)
- 默认参数、多参数、可变数量参数
- 全局变量、作用域(scope)
- 函数定义顺序
- 返回值、格式化返回
- 类型注解(Type annotation)
- Docstring 与 help()
- Generator(生成器)
- Lambda(匿名函数)
- Decorator(装饰器)
内容偏向 Python 编程基础,是理解 AI 应用开发之前必须掌握的 Python 核心知识。
什么是函数 Function
函数是一段 只有被调用(call) 才会执行的代码。
主要优点:
- 让代码可重用
- 结构更清晰
- 方便维护
示例:内建函数 print、input、len、sorted… 已经是函数。
print() 的格式化与参数
示例:
name = "Nick"
print("Hello", name) # 两个参数
print("Hello " + name) # 一个参数
❗ 两种方式不同:
- 第一种:print 内多个参数会用空格分隔
- 第二种:字符串拼接 → 只有一个参数
print() 的更多参数
end=
改变 print 结尾的内容:
print("Hello", end=", ")
print("how are you today?")
输出:
Hello, how are you today?
sep=
改变参数之间的分隔符:
print("Brand", "Honda", sep=":")
输出:
Brand:Honda
创建自定义函数(def)
基本结构:
def my_function():
print("Hello from a function")
调用方式:
my_function()
注意:缩进决定函数内部代码的范围
函数命名规范
- 可使用字母、数字、下划线
- 最佳实践:使用 snake_case
get_input()
- 单下划线开头
_internal_function()通常表示“内部使用”
向函数传入参数
示例:
def greeting(a):
print(f"Hello {a} ! ")
name = input("What is your name?\n")
greeting(name)
- argument:调用时给的值(name)
- parameter:函数定义中的接收者(to)
参数可为任何类型
def type_of_food(food):
for x in food:
print(x)
fruits = ["Apple", "Banana", "Durian"]
type_of_food(fruits)
这里传入的是 list。
无返回值的函数也称为 Procedure 过程。
默认参数 & 多参数
默认参数:
def greeting(to="World"):
print(f"Hello {to} ! ")
greeting() # 打印 Hello World
greeting("Nick") # 打印 Hello Nick
多参数:
def greeting(msg="Hello", to="world"):
print(f"{msg}, {to} ! ")
可变数量参数(*args)
如果参数个数不确定:
def greeting(*names):
for name in names:
print(f"Good day {name} !")
greeting("Nick", "Jess", "Alex")
*names 收集所有参数成为一个 tuple。
共享变量:global 关键字
示例:
RUN = 0
STOP = 1
game = RUN
def check():
global game
game = STOP
关键点:
- global 让函数可以修改外部变量
- 不推荐大量使用,但某些情境(状态控制)会用到
变量作用域(scope)
Python 变量有 4 种作用域:
- Local(函数内部)
- Enclosing(嵌套函数外层)
- Global(全局)
- Built-in
三个示例分别展示:
示例 1:使用到全局变量
x = 'global'
def outer():
print(x)
输出 global。
示例 2:内部使用 enclosing:
x = 'global'
def outer():
x = 'enclosing'
def inner():
print(x)
inner()
输出 enclosing。
示例 3:local 覆盖:
x = 'global'
def outer():
x = 'enclosing'
def inner():
x = 'local'
print(x)
inner()
输出 local。
函数定义顺序
可以将所有函数写在 main 下面;只要在调用前定义即可。
示例:
def main():
greeting_1("Nick")
greeting_2("Alex")
def greeting_1(name):
print(f"Hello, {name} !")
def greeting_2(name):
print(f"Good Day, {name} !")
main()
返回值 return
示例:
def multiply(a, b):
value = a * b
return value
return 将数据返回给调用者。
返回格式化字符串
def introduce(name, age):
return f"Hello, I am {name}, and I am {age} years old."
类型注解(Type Annotation)
让代码更易读:
def my_func(a: str, b: int) -> float:
...
a: str⇒ 参数 a 应为 string-> float⇒ 返回值为 float
1️. def my_func(...) —— 定义一个函数
def 是 Python 用来定义函数的关键字。
my_func 是函数名称。
你之后可以这样调用它:
my_func("hello", 5)
2️. 参数部分:a: str, b: int
这叫做类型注解(Type Hint / Type Annotation)
a: str 表示参数 a 应该是字符串类型(str)
例如:
my_func("hello", 3) # ✔ 合法
my_func(123, 3) # ✘ 不符合类型提示
注意:Python 不会强制检查类型,但 IDE 和类型检查器(如 mypy)会提醒你。
b: int 表示参数 b 应该是整数类型(int)
例如:
my_func("abc", 10) # ✔
my_func("abc", "x") # ✘ IDE 会提示类型错误
3️. 返回值部分:-> float
这是返回值类型注解。
表示这个函数应该返回一个浮点数(float)。
例如:
return 3.14 # ✔
return 10 / 3 # ✔ (结果是 float)
return "abc" # ✘ 类型检查工具会警告
4️. ...—— 函数体占位符
...在这里不是省略号的意思,而是 Python 的合法表达式,用来占位。
与 pass 类似,用于表示“这里以后再写”。
例如:
def func():
...
等同于:
def func():
pass
5. 如果这个函数真的要工作,它会长这样:
示例:
def my_func(a: str, b: int) -> float:
return len(a) * b * 0.1
# ---- 主程序 ----
# 输入字符串
a = input("请输入一个字符串 a: ")
# 输入整数 b
b = int(input("请输入一个整数 b: "))
# 调用函数
result = my_func(a, b)
# 输出结果
print("计算结果是:", result)
输入:
请输入一个字符串 a: hello
请输入一个整数 b: 3
输出:
计算结果是: 1.5
返回值计算方式:返回值 = 字符串长度 × b × 0.1
计算过程:
- len("hello") = 5
- 5 × 3 × 0.1 = 1.5
6. 补充:类型注解不会影响运行时行为
这段代码:
def my_func(a: str, b: int) -> float:
...
即使你写:
my_func(123, "hello")
也 不会报错(除非你写了运行时检查)。
但 IDE 会给出警告。
Docstring 与 help()
使用三引号写函数说明:
def calculate_area(length: float, width: float) -> float:
"""
Calculates the area of a rectangle.
Args:
length ...
width ...
Returns ...
"""
return length * width
help(calculate_area)
help() 会打印 docstring 内容。
Generator(生成器)与 yield
生成器使用 yield 一次返回一个值,不会终止函数。
示例:
def generator():
yield "Alex"
yield "Brian"
yield "Cindy"
优点:
- 节省内存
- 适合处理大数据量或无限序列
Lambda 匿名函数
把简单函数写成一行:
mac = lambda x, y: (x * y) + x
print(mac(3, 4))
等价于:
def mac(x, y):
return (x * y) + x
lambda 结合 filter()
用于筛选数据:
number_list = [1, 12, 13, 24, 35, 38, 47]
odd_numbers = filter(lambda x: x % 2 != 0, number_list)
print(list(odd_numbers))
筛选出所有奇数。
Decorator(装饰器)
装饰器使用 @ 符号,为函数添加额外功能。
示例:避免除以 0:
def guard_zero(func):
def wrapper(x, y):
if y == 0:
print("Cannot divide by 0.")
return
return func(x, y)
return wrapper
@guard_zero
def divide(x, y):
return x / y
调用 divide(10, 0) 时,会先执行 guard_zero。
总结
- 函数让代码更容易维护与复用
- Python 提供许多强大函数相关工具:
- Generator
- Lambda
- Decorator
Topic 4 (Modules and Packages)
1. Python 模块 (Modules)
模块是包含常用功能的代码库。Python 自带了许多内置模块,供开发者使用。
示例:导入模块
import time # 导入内置模块 time,用于处理时间相关功能
import random # 导入内置模块 random,用于生成随机数、随机选择等
通过 import 关键字导入 Python 的标准库模块。这样就可以使用模块中的所有函数和对象。
查看模块中的所有函数和变量
dir(random)
使用 dir() 函数可以查看模块中包含的所有函数和变量。
2. 使用模块中的特定函数
如果只需要使用模块中的某个函数,可以选择性导入:
示例:
from random import choice as ch # 从 random 模块中导入 choice() 函数,并给它起别名 ch
for _ in range(10): # 循环执行 10 次,下划线表示不需要使用循环变量
print(ch(["red", "green", "blue"])) # 每次随机从列表中选择一个颜色并输出
from random import choice as ch:从random模块中导入choice函数,并为它取一个别名ch。- 这样可以节省内存,因为只导入了需要的函数,而不是整个模块。
3. 创建自定义模块
您也可以创建自己的模块,保存自己定义的函数。这样,当程序变得很大时,可以将不同的功能拆分到不同的文件中,方便管理。
示例:
- 创建
my_module.py:
def greeting1(name): # 定义函数 greeting1,接受 name 参数
print(f"Hello, {name} !") # 输出问候语
def greeting2(name): # 定义函数 greeting2
print(f"Good Day, {name} !") # 输出另一种问候语
- 在程序文件中导入并使用:
import my_module # 导入自定义模块 my_module
my_module.greeting1("Nick") # 调用模块中的 greeting1 函数
my_module.greeting2("Alex") # 调用 greeting2 函数
这样,您就创建了一个简单的模块 my_module.py,并在另一个程序中导入和调用它。
4. 测试模块
在开发模块时,通常需要测试模块的功能,而不必依赖于另一个程序来导入它。可以在模块中加入 if __name__ == "__main__" 来实现当模块作为独立脚本运行时进行测试。
示例:
def main(): # 定义 main 函数
greeting1("test1") # 调用 greeting1
greeting2("test2") # 调用 greeting2
def greeting1(name):
print(f"Hello, {name} !")
def greeting2(name):
print(f"Good Day, {name} !")
if __name__ == "__main__": # 只有当此文件作为脚本运行时才会执行 main()
main()
if __name__ == "__main__":这个条件确保了只有当模块被直接运行时,main()函数才会执行。如果模块是被其他程序导入的,则不会执行main()。
5. 正则表达式模块 (re)
Python 提供了 re 模块用于正则表达式操作,允许用户根据特定模式查找字符串中的字符序列。
示例:
import re # 导入正则表达式模块 re
text = "That cloth is very nice" # 目标字符串
match = re.search("^That.*nice$", text) # 匹配开头为 That,结尾为 nice 的字符串
if match: # 如果匹配成功
print("matched!") # 输出 matched!
^That表示字符串以 "That" 开头。.*表示任意字符,出现 0 次或多次。nice$表示字符串以 "nice" 结尾。
6. 密码强度检测功能
我们可以利用正则表达式编写一个函数,要求用户输入符合要求的强密码。
示例:
from re import search # 从模块 re 中导入 search 函数
def strong_password(): # 定义密码强度检查函数
while True: # 无限循环,直到输入正确密码
password = input("Enter a strong password: ") # 用户输入密码
if len(password) < 8: # 检查最少 8 个字符
print("Password should be at least 8 characters long.")
elif search("[a-z]", password) == None: # 检查小写字母
print("Password should have at least one lowercase letter.")
elif search("[A-Z]", password) == None: # 检查大写字母
print("Password should have at least one uppercase letter.")
elif not search("[0-9]", password): # 检查数字
print("Password should have at least one number.")
elif not search("[!@#$%^&*()]", password): # 检查特殊字符
print("Password should have at least one special character.")
else: # 如果全部满足
print("Strong password set.") # 提示成功
break # 跳出循环
- 该函数要求密码至少包含 8 个字符,至少一个小写字母、一个大写字母、一个数字以及一个特殊字符(如
!@#$%^&*())。
7. 第三方库和包
包和库是指由第三方提供的代码文件,它们包含多个模块,帮助我们实现更复杂的功能。pandas 和 numpy 等是常见的 Python 包。
- 包(Package)是包含多个模块的文件夹。
- 库(Library)是包含多个包的文件集合。
安装第三方库
可以使用 pip 或 conda 命令来安装第三方库:
pip install pandas
安装后,可以在程序中通过 import 来使用库中的模块和功能:
import pandas
8. 使用 Conda 安装包
conda 是一个用于安装 Python 包的工具,通常用于 Anaconda 环境。
示例:
- 安装包时,
conda默认从 Anaconda 的主仓库下载包,但也可以指定其他仓库(如conda-forge)。
总结
- 模块:Python 内置的功能库,包含可直接使用的函数和对象。
- 自定义模块:可以将自定义函数保存为
.py文件,方便复用。 - 正则表达式:通过
re模块,用户可以处理文本中的模式匹配。 - 包与库:第三方提供的代码集合,通过
pip或conda安装并使用。
Topic 6
主要介绍了Python中的文件处理,涵盖了文件的读写操作、CSV文件处理、JSON文件处理等内容。下面是该PDF中每个部分的详细中文教程和代码解释。
1. Python文件处理
Python提供了多种内置函数来处理文件,包括创建、读取、更新和删除文件。最常用的函数是 open(),用于打开一个文件并返回一个文件对象。
示例:创建和写入文件
file = open("example.txt", "w") # 以写入模式打开文件,不存在则创建
file.write("Hello, World!") # 向文件写入内容
file.close() # 关闭文件,保存内容
open()的第一个参数是文件名,第二个参数是模式。"w"模式用于写入,如果文件不存在,会创建文件。- 记得使用
close()关闭文件,以确保写入的内容被保存。
2. 文件读取
read() 方法
用于一次性读取文件的全部内容。
file = open("example.txt", "r") # 以读模式打开文件
content = file.read() # 把整个文件内容读取为字符串
print(content) # 输出字符串内容
file.close() # 关闭文件
readline() 方法
逐行读取文件内容。
file = open("example.txt", "r") # 打开文件
line = file.readline() # 读取第一行
print(line) # 输出读取的行
file.close()
逐行循环读取文件
file = open("example.txt", "r") # 打开文件
for line in file: # 遍历每一行
print(line) # 输出每行内容
file.close()
for line in file会逐行读取文件。
3. 文件写入
w模式:覆盖文件内容,文件不存在时创建新文件。a模式:在文件末尾追加内容。
file = open("example.txt", "a")
file.write("Appended text.")
file.close()
4. 使用 with 语句自动关闭文件
with open("example.txt", "r") as file: # 使用 with 自动关闭
content = file.read() # 读取文件
print(content) # 输出内容
# 文件自动关闭,不需要显式调用 file.close()
5. 文件操作模式总结
"r":以读取模式打开文件。"w":以写入模式打开文件(文件不存在则创建,存在则覆盖)。"a":以追加模式打开文件(文件不存在则创建,存在则在末尾添加内容)。"r+":以读写模式打开文件。"w+":以读写模式打开文件,文件内容会被清空。"a+":以读写模式打开文件,文件内容会追加。
6. CSV文件处理
CSV(Comma Separated Values)是一种常见的存储数据的文本格式。
示例CSV文件内容(cars.csv)
id,brand,model,year,color
1,Mazada,CX5,2014,red
2,VW,Jetta,2018,silver
3,Honda,Civic,2022,white
使用 csv.reader 读取CSV文件
import csv # 导入 csv 模块
file = open("cars.csv") # 打开 CSV 文件
cars = csv.reader(file) # 使用 reader 读取
header = next(cars) # 读取第一行(表头)
print(header) # 输出表头
rows = []
for row in cars: # 遍历余下行
print(row) # 输出每行
rows.append(row) # 保存到列表
file.close()
- 使用
csv.reader逐行读取CSV内容,next()用于读取第一行表头。
使用 csv.DictReader 将每行转换为字典
import csv
cars = csv.DictReader(open("cars.csv")) # 每行转成字典
for row in cars:
print(row) # 输出字典
- 每一行会被转换成字典,键是列名,值是对应的内容。
7. JSON文件处理
JSON(JavaScript Object Notation)是一种常见的文本数据格式,广泛用于客户端和服务器之间传输数据。
示例JSON数据
{
"brand": "Mazada",
"model": "CX5",
"year": 2014,
"color": "red"
}
使用 json.loads() 解析JSON字符串
import json # 导入 json 模块
x = '{"brand":"Mazada", "model":"CX5", "year":2014, "color":"red"}' # JSON 字符串
y = json.loads(x) # 转为 Python 字典
print(f'Model = {y["model"]}') # 输出 model
print(f'Year = {y["year"]}') # 输出 year
json.loads()将JSON字符串转换为Python字典。
8. 总结
通过本教程,你可以掌握Python中关于文件操作的基础知识,包括如何读取、写入文件,处理CSV和JSON格式的数据等。理解并灵活运用文件操作对于处理存储和数据交换非常重要。
Topic 7
Python错误处理教程
1. 错误类型
Python中有两种主要的错误类型:
- 语法错误 (Syntax Error):程序因代码错误无法运行。
- 运行时/逻辑错误 (Runtime/Logic Error):程序运行时出现的错误,通常是由于程序未能预见到用户的输入或操作。
2. 异常处理(try-except)
Python通过 try 和 except 语句来捕获并处理在程序执行过程中出现的错误。
- try:用于测试代码块是否有错误。
- except:用于处理在
try代码块中出现的错误。
示例:
try:
print(x) # 尝试打印 x,但 x 未定义,会报错
except:
print("something goes wrong!") # 捕获任何异常并执行
解释:这里我们试图打印变量 x,如果 x 没有定义,会抛出异常,except 块捕获该异常并打印错误信息。
3. 常见的内置异常
Python有许多内置的异常类,常见的有:
- NameError:当变量未定义时抛出。
- ValueError:当值无效时抛出。
- KeyError:当字典中没有指定的键时抛出。
4. 使用 try-except 处理异常
在实际应用中,我们可以使用 try-except 来处理错误。例如,当用户输入一个无效值时:
try:
n = int(input("Enter a value: ")) # 用户输入转为整数
print(f"Value is {n}") # 如果成功,打印
except ValueError: # 输入不能转为 int
print("Please enter the value properly")
except:
print("something goes wrong!")
解释:这段代码尝试将用户输入的值转换为整数,如果输入无效(如字母或符号),会捕获 ValueError 异常并提示用户。
例
try:
numerator = 30
denominator = int(input("key in a value"))
result = numerator/denominator
print(result)
except ValueError:
print("Error 1")
except:
print("Error 2")
逻辑:
- 程序尝试将用户输入转换为整数
- 再执行
30 / denominator - 如果输入不能转换为整数 → ValueError → 打印
"Error 1" - 如果其他错误发生(如除以 0) → 第二个
except→"Error 2"
A. input = 2 → output = 15
✔ 输入 2 可以成功转换为整数
✔ 30 / 2 = 15
✔ 没有错误,不走 except
所以输出:15
➡ A 正确
B. input = a → output = "Error 1"
✔ 输入 a 无法转成整数
✔ int("a") 产生 ValueError
✔ 被第一个 except 捕获
输出:"Error 1"
➡ B 正确
C. input = a → output = "Error 1" and "Error 2"
✘ 错误原因:
ValueError只会被第一个except ValueError捕获- 不会继续执行后面的 except
- except 不会连环执行
➡ C 错误
D. input = 0 → output = "Error 2"
✔ int("0") 成功 → 0
✔ 30 / 0 → ZeroDivisionError
✔ ZeroDivisionError 不是 ValueError
✔ 被第二个 except 捕获 → "Error 2"
➡ D 正确
5. 使用 else
else 语句在没有异常发生时执行。它通常与 try-except 一起使用,确保只有在没有错误时才执行某些操作。
try:
# 开始 try 块,用来尝试执行可能会发生异常的代码
n = int(input("Enter a value: "))
# 显示提示“Enter a value: ”并等待用户输入
# input() 返回字符串,int() 尝试将其转换为整数
# 如果输入的内容无法转换为整数,就会抛出 ValueError
except ValueError:
# 如果上面的 int(...) 转换失败(例如输入 abc、3.14、空字符串)
# 就会执行这个分支
print("Please enter the value properly")
# 当发生 ValueError 时,打印此提示信息
except:
# 捕获除 ValueError 之外的所有其他异常
# 比如 KeyboardInterrupt(Ctrl+C)或 EOFError
print("something goes wrong!")
# 打印通用错误信息,用于处理非 ValueError 的异常
else:
# 当 try 块中的代码 **完全没有发生异常** 时执行该块
print(f"Value is {n}")
# 打印成功转换后的整数值 n
程序执行逻辑(流程步骤,按执行顺序)
-
程序进入
try块并执行input("Enter a value: "),在控制台显示提示并等待用户输入。 -
用户输入并按回车,
input()返回一个字符串。 -
程序尝试用
int()将该字符串转换为整数:- 如果转换成功 → 将整数赋值给
n,try块执行结束,跳到else块,打印Value is {n}。 - 如果转换失败(例如输入是
"abc"、"3.14"等)→ 抛出ValueError,程序跳到第一个except ValueError:分支并打印相应提示,else不执行。 - 如果发生其它异常(比如没有输入导致
EOFError,或用户中断KeyboardInterrupt),程序跳到裸except:分支并打印通用错误信息;else也不执行。
- 如果转换成功 → 将整数赋值给
-
程序结束。
示例 A — 合法整数(正常走 else)
交互:
> Enter a value: 42
输出:
Value is 42
解释:input() 得到 "42" → int("42") 成功 → 打印 Value is 42。
示例 B — 有前后空格的整数(int 可处理空格)
交互:
> Enter a value: 100
输出:
Value is 100
解释:int() 会忽略前后空白,转换成功。
示例 C — 负整数
交互:
> Enter a value: -5
输出:
Value is -5
解释:int("-5") 转换成功。
示例 D — 非整数字符串(触发 ValueError)
交互:
> Enter a value: abc
输出:
Please enter the value properly
解释:int("abc") 抛 ValueError,进入第一个 except。
示例 E — 小数(触发 ValueError)
交互:
> Enter a value: 3.14
输出:
Please enter the value properly
解释:int("3.14") 不能直接转换,抛 ValueError。
示例 F — 十六进制字符串(触发 ValueError)
交互:
> Enter a value: 0x10
输出:
Please enter the value properly
解释:int("0x10")(不带 base 参数)会抛 ValueError。要解析需用 int("0x10", 0) 或 int("10", 16)。
示例 G — 空输入(按回车但没有任何字符,input() 返回空字符串)
交互:
> Enter a value:
输出:
Please enter the value properly
解释:input() 返回 "",int("") 抛 ValueError。
示例 H — 文件/管道中没有更多输入(触发 EOFError),或在某些环境中直接触发 EOF
情形:在非交互环境或读到 EOF 时发生
程序可能输出:
something goes wrong!
解释:input() 在没有可读数据时抛 EOFError,被裸 except: 捕获并打印通用错误信息。
示例 I — 用户按 Ctrl+C(触发 KeyboardInterrupt)
交互(用户中断):
> Enter a value: ^C
输出:
something goes wrong!
解释:按 Ctrl+C 会导致 KeyboardInterrupt,被裸 except: 捕获并打印通用错误信息。
注:在某些环境下(例如交互式终端),
KeyboardInterrupt也可能终止程序并显示堆栈,具体行为取决于运行环境及异常处理细节。
建议(更健壮、清晰的写法)
- 避免使用裸
except:,改为捕获具体异常(例如except (EOFError, KeyboardInterrupt):),并对用户友好提示或重新抛出。 - 给出更明确的错误信息,例如显示用户输入是什么或再次提示输入格式。
- 如果想重复询问直到用户给出合法整数,可以把
try放到循环中。
示例改进版本:
while True:
try:
n = int(input("Enter an integer: "))
except ValueError:
print("Please enter a valid integer (no decimals, letters).")
except (EOFError, KeyboardInterrupt):
print("Input interrupted or no input available. Exiting.")
break
else:
print(f"Value is {n}")
break
6. 使用 finally
finally 语句块会在 try-except 后无论是否发生异常都会执行。通常用于释放资源(如关闭文件、数据库连接等)。
try:
# 显示提示并等待用户输入,然后尝试将输入转换为整数
n = int(input("Enter a value: "))
except ValueError:
# 当输入无法转换为整数时(如 abc、3.5、空字符串),会触发 ValueError
print("Please enter the value properly")
except:
# 捕获除 ValueError 之外的任何其他异常(如 KeyboardInterrupt、EOFError)
print("something goes wrong!")
else:
# 如果 try 块没有发生任何异常,则执行这里
print(f"Value is {n}")
finally:
# 无论前面是否发生异常,finally 都会执行(必定执行)
print("try-except completed")
解释:即使发生异常或没有发生异常,finally 块中的内容都会执行。它通常用于清理操作。
程序执行逻辑
程序流程如下:
-
进入
try块- 程序执行:
input("Enter a value: ") - 等待用户输入
- 尝试用
int(...)转换为整数
- 程序执行:
-
如果发生异常 → 程序跳转到对应的
except分支- ValueError → 输入不能转成整数
- 其他异常 → Ctrl+C 中断、输入流结束等
-
如果没有异常 → 执行
else:- 打印成功转换的值
-
finally:总是执行
- 无论是否发生异常,都会打印
"try-except completed"
- 无论是否发生异常,都会打印
示例 A:输入合法整数(正常执行 else)
> Enter a value: 10
Value is 10
try-except completed
说明:int("10") 转换成功,执行 else,然后执行 finally。
示例 B:输入带空格的整数(仍可转换)
> Enter a value: 50
Value is 50
try-except completed
int() 可以自动忽略前后空格。
示例 C:输入负数
> Enter a value: -8
Value is -8
try-except completed
示例 D:输入不能转换为整数(触发 ValueError)
输入字符串:
> Enter a value: abc
Please enter the value properly
try-except completed
因为 "abc" 不能转换成整数。
示例 E:输入浮点数(同样 ValueError)
> Enter a value: 3.14
Please enter the value properly
try-except completed
示例 F:输入空字符串(直接按回车)
> Enter a value:
Please enter the value properly
try-except completed
int("") 会抛出 ValueError。
示例 G:输入十六进制形式(仍然 ValueError)
> Enter a value: 0x10
Please enter the value properly
try-except completed
int("0x10") 不带 base 时会报错。
示例 H:用户按 Ctrl+C 中断(KeyboardInterrupt → 第二个 except)
> Enter a value: ^C
something goes wrong!
try-except completed
因为 KeyboardInterrupt 不属于 ValueError,所以进入第二个 except。
示例 I:EOFError(没有输入流)
例如运行环境输入流结束:
something goes wrong!
try-except completed
7. 文件操作中的错误处理
当操作文件时,可能会遇到打开文件、读取文件、写入文件等错误。可以通过 try-except 来捕获这些错误:
try:
f = open("file.txt") # 打开文件
try:
f.write("Hello") # 尝试写入(但 file.txt 若为只读会出错)
except:
print("Something goes wrong when writing to file")
finally:
f.close() # 关闭文件
except:
print("something goes wrong when opening the file")
解释:首先尝试打开文件,如果文件不存在或权限问题,捕获异常并输出错误信息;然后尝试写入文件,如果出错,也会捕获异常。
8. 使用 assert 进行调试
assert 语句用于检查条件是否为真。如果条件为假,程序会抛出 AssertionError 异常并停止执行。通常用于调试阶段验证程序的正确性。
assert 5+10 == 15 # 这行代码不会抛出异常
assert 5+10 == 12, "This is not correct" # 这行代码会抛出异常并提示错误信息
解释:assert 用于验证表达式的正确性。如果表达式为 False,则会抛出错误并提供错误信息。
9. 类型化异常
Python还提供了其他类型的异常,可以通过不同的异常类型来处理不同的错误情境。例如 ValueError、KeyError、IndexError 等。
10. 性能分析(Software Profiling)
性能分析用于优化程序的运行效率。例如,使用 time 模块来测量代码的执行时间。
import time # 导入 time 模块
def main():
t1 = time.perf_counter() # 获取开始时间
# 调用某个函数(此处省略)
t2 = time.perf_counter() # 获取结束时间
print(f"Execution time: {t2 - t1} seconds") # 输出执行时间差
解释:time.perf_counter() 返回高精度的时间,用于测量代码执行的时间差,从而帮助分析性能瓶颈。
11. 示例代码:sleep 与 add 函数的性能分析
import time
def sleep():
time.sleep(1) # 暂停 1 秒
def add():
total = 0
for a in range(100_000_000): # 大循环,耗时较长
total += a
def main():
for function in [sleep, add]: # 遍历两个函数
t1 = time.perf_counter()
function() # 执行函数
t2 = time.perf_counter()
print(f"{function.__name__}() execution time: {t2 - t1} seconds")
main()
示例代码
import random # 导入 random 模块,用于生成随机数(AI 随机落子用)
# import os # (可选)用于在控制台模式下清屏,图片里已注释掉
# 使用列表来表示 3x3 棋盘位置,索引 1..9 有效(0 位不使用)
loc = [' ', ' ', ' ', ' ', ' ', ' ', ' ', ' ', ' ', ' ']
# 说明:loc[1] 到 loc[9] 对应棋盘格子;初始均为空格 ' ' 表示未被占用
def main():
draw_board() # 先绘制初始棋盘
while True:
player_input() # 让玩家输入落子
state = check_result() # 检查当前局面(胜/继续/和)
if state == "win": # 如果玩家赢了
print("You win !") # 输出玩家胜利提示
break # 结束主循环,游戏结束
elif state == "draw": # 如果是和局(没有空位且无人获胜)
print("It's a draw") # 输出平局提示
break # 游戏结束
# 下面轮到 AI 行动(图片里给了两种 AI:AI0(随机)和 AI1(进攻/阻挡启发式)
# 可选使用 AIO_turn() 或 AI1_turn()
# AI0_turn() # 使用随机选位算法(注释掉)
AI1_turn() # 使用“赢-阻挡”策略算法(优先赢,再阻挡,再随机)
state = check_result() # 再次检查结果(AI 落子后)
if state == "win": # 如果 AI 赢了
print("You lose !") # 提示玩家失败
break # 游戏结束
elif state == "draw": # 如果平局
print("It's a draw") # 提示平局
break # 游戏结束
def draw_board(): # 绘制/更新井字棋显示
# os.system('cls') # (可选:控制台模式下清屏,Windows 下用 cls)
print(f" {loc[1]} | {loc[2]} | {loc[3]} ") # 打印第一行格子(1 2 3)
print("___|___|___") # 行间分隔线
print(f" {loc[4]} | {loc[5]} | {loc[6]} ") # 第二行(4 5 6)
print("___|___|___") # 分隔线
print(f" {loc[7]} | {loc[8]} | {loc[9]} ") # 第三行(7 8 9)
print(" | | ") # 底部空行(美观)
def player_input(): # 询问玩家选择,并把 'x' 放到对应位置
while True:
choice = int(input("Enter your choice between [1-9]")) # 要求输入 1~9 的整数
if loc[choice] == ' ': # 如果该位置为空(尚未被占用)
loc[choice] = 'x' # 将玩家标记 'x' 放到该位置
draw_board() # 更新并显示棋盘
return # 返回到主循环(玩家回合结束)
# 如果位置不为空,则循环继续,要求玩家再次输入(图片里没写提示,但会继续询问)
def check_result(): # 检查是否有人获胜或是否仍有空位(返回 "win"/"continue"/"draw")
# 检查所有可能的获胜组合(行、列、斜)
if (loc[1] == loc[2] == loc[3]) and (loc[1] != ' '):
return("win")
if (loc[4] == loc[5] == loc[6]) and (loc[4] != ' '):
return("win")
if (loc[7] == loc[8] == loc[9]) and (loc[7] != ' '):
return("win")
if (loc[1] == loc[4] == loc[7]) and (loc[1] != ' '):
return("win")
if (loc[2] == loc[5] == loc[8]) and (loc[2] != ' '):
return("win")
if (loc[3] == loc[6] == loc[9]) and (loc[3] != ' '):
return("win")
if (loc[1] == loc[5] == loc[9]) and (loc[1] != ' '):
return("win")
if (loc[3] == loc[5] == loc[7]) and (loc[3] != ' '):
return("win")
# 检查是否存在任何空格(如果有空位则继续游戏)
for i in range(1, 9): # 注意:图片中是 range(1,9),但 Python range(1,9) 会遍历 1..8(未包含 9)
if loc[i] == ' ':
return("continue") # 还有空位,继续游戏
# 如果没有空位且没有人获胜,则为平局
return("draw")
def AI0_turn(): # 简单的 AI:随机选一个空位置放 'o'
while True:
choice = random.randint(1, 9) # 生成 1~9 的随机整数
if loc[choice] == ' ': # 如果该位置为空
loc[choice] = 'o' # 放置 AI 的标记 'o'
print(f"AI choice = {choice}")# 打印 AI 选择了哪个位置
draw_board() # 更新并显示棋盘
return # AI 行动结束
def AI1_turn(): # 更聪明的 AI:尝试先赢、再阻止玩家、否则随机选位
while True:
# 先尝试自己能否落子立即获胜(遍历每个位置并试放 'o')
for i in range(1, 10): # 遍历 1 到 9(注意图片里是 range(1,10))
if loc[i] == ' ': # 若该位为空
loc[i] = 'o' # 试探性地把 'o' 放上去
state = check_result() # 检查放这个子后是否获胜
if state == "win": # 如果能获胜
print(f"AI choice = {i}") # 打印 AI 的最终选择
draw_board() # 显示棋盘
return # 已落子并获胜,返回
else:
loc[i] = ' ' # 否则撤回(回退为原样)
# 如果不能直接赢,再检查玩家是否能下一步胜利(需阻挡)
for i in range(1, 10):
if loc[i] == ' ':
loc[i] = 'x' # 先把玩家的 'x' 放到该位置,模拟玩家下一步
state = check_result()
if state == "win": # 如果玩家在该位置会赢
loc[i] = 'o' # 那么 AI 在该位置放 'o' 来阻挡
print(f"AI choice = {i}") # 打印 AI 的选择(阻挡)
draw_board()
return
else:
loc[i] = ' ' # 否则撤回(还原为空)
# 如果既不能赢也不需要立即阻挡,退而求其次随机选择一个位置
AI0_turn()
return
额外说明(重要的细节与建议)
-
check_result()中的空位检测范围:图片里写的是for i in range(1,9):,这会只检查1..8(不包含 9)。正确应为range(1, 10)或for i in range(1, len(loc)):,以包含第 9 个格子。建议修改为range(1,10)。 -
索引 0:代码把
loc[0]留空不用,这是可行的做法,但需要注意所有range遍历都从 1 开始。 -
玩家输入的鲁棒性:当前
player_input()直接用int(input(...)),若用户输入非整数会抛异常。建议捕获异常并提示重新输入:try: choice = int(input(...)) except ValueError: print("请输入 1 到 9 的整数") continue -
AI1_turn 的逻辑:图片里的写法是先尝试“自己能否赢”,若不能则尝试“玩家能否赢并阻挡”,最后随机。该策略简单但有效(影子策略)。
-
美化:
draw_board()中的分隔线与格式可按需调整。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号