MIT6.s081_Lab1 util: Unix utilities
MIT6.s081 Lab1:Unix utilities
lab1比较简单,内容较多,但是都是实现一些简单的命令,其中primes这个很有趣,还是花了点时间。
1. sleep
在user/sleep.c中添加如下代码:
int main(int argc, char** argv) {
if (argc <= 1) {
fprintf(2,"usage: sleep n second...\n");
exit(1);
}
sleep(atoi(argv[1]));
exit(0);
}
2. pingpong
在user/pingpong.c中添加如下代码:
#include "kernel/types.h"
#include "kernel/stat.h"
#include "user/user.h"
int main(int argc, char** argv) {
int p[2];
pipe(p);
char buffer[5];
if (fork() != 0) {
int status;
write(p[1], "ping\n", 5);
close(p[1]);
wait(&status);
read(p[0], buffer, 5);
close(p[0]);
fprintf(1, "%d: received %s",getpid(), buffer);
} else {
read(p[0], buffer, 5);
close(p[0]);
fprintf(1, "%d: received %s",getpid(), buffer);
write(p[1], "pong\n", 5);
close(p[1]);
exit(0);
}
exit(0);
}
3. primes
这个属于难度较大的编程,重点需要理解这个,图片放在下面了
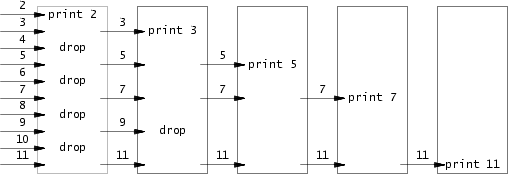
下面注释后补的,可能没有那么深刻,代码如下:
#include "kernel/types.h"
#include "kernel/stat.h"
#include "user/user.h"
int main(int argc, char** argv) {
//开了35,2的数组,0为读,1为写
int p[35][2];
int pipe_num = 0;
//只开了第一个管道,因为第一个进程只需要向第一个管道写
pipe(p[pipe_num++]);
int child = -1;
if((child = fork()) != 0) {
//关闭第一个读端
close(p[0][0]);
//向第一个管道写入,从2写到36
for (int i = 2; i < 36; ++i) {
write(p[0][1], &i, sizeof(int));
}
//全部写完后,关闭写端
close(p[0][1]);
wait(&child);
}else {
//因为前面pipe(p[pipe_num++]);,此时pipe_num已经变成了1
int cur_pn = pipe_num - 1;
//关闭0,1
close(p[cur_pn][1]);
//通往子进程的管道
int next_pn = pipe_num;
int *num = 0;
//当读到第一个数据的时候退出循环,打印
while(!read(p[cur_pn][0], num, sizeof(int)));
fprintf(1, "prime %d\n", *num);
int cur = *num;
while(read(p[cur_pn][0], num, sizeof(int)) != 0) {
//下面是关键,先从管道读取数据,如果读取的数无法当前子进程保留的数, 就送到下一个管道,第一次会生成一个子进程接收,使用pipe_num控制生成个数
if (*num % cur != 0) {
//保证每个进程只会生成一个子进程
if (pipe_num - 1 == cur_pn){
pipe(p[pipe_num++]);
child = fork();
}
write(p[next_pn][1], num, sizeof(int));
//更新子进程维护的数据,curpn是读取数据的管道,nextpn是写给子进程的管道
//每个子进程只有无法整除才会送到下一个,因此在第一次生成子进程的时候打印即可
if(child == 0) {
cur_pn = pipe_num - 1;
next_pn = pipe_num;
close(p[cur_pn][1]);
read(p[cur_pn][0], num, sizeof(int));
cur = *num;
fprintf(1, "prime %d\n", cur);
}
}
}
//关闭管道
close(p[cur_pn][0]);
close(p[next_pn][1]);
close(p[next_pn][0]);
wait(&child);
}
exit(0);
}
4. find
主要是需要知道两个结构体,stat和dirent,以及递归查询子目录的方法。删除了部分检测代码。
void find(char* path, char* name) {
int fd;
char buf[512], *p;
struct stat st;
struct dirent de;
strcpy(buf, path);
p = buf + strlen(buf);
*p++ = '/';
while(read(fd, &de, sizeof(de)) == sizeof(de)) {
if(de.inum == 0)
continue;
memmove(p, de.name, DIRSIZ);
p[DIRSIZ] = 0;
if(stat(buf, &st) < 0){
printf("ls: cannot stat %s\n", buf);
continue;
}
if(st.type == T_FILE) {
if(0 == strcmp(de.name, name))
printf("%s\n", buf);
continue;
}
if(st.type == T_DIR && 0 != strcmp(".", de.name) && 0 != strcmp("..", de.name)) {
find(buf, name);
}
}
close(fd);
}
int main(int argc, char** argv) {
if (argc < 3) {
fprintf(2, "usage: find dir ...");
exit(0);
}
find(argv[1], argv[2]);
exit(0);
}
5. xargs
重点是\的处理,然后是exec的使用,难度不大,代码如下:
#include "kernel/types.h"
#include "kernel/stat.h"
#include "user.h"
int main(int args, char** argv) {
char c, buf[512];
char* p = buf;
char* argv_exc[32];
argv_exc[0] = argv[1];
for (int i = 1; i < args - 1; i++) {
argv_exc[i] = argv[i+1];
}
while(read(0, &c, 1) > 0) {
if(c == '\\') {
if(read(0, &c, 1) > 0) {
if(c == 'n') {
c = '\n';
} else {
*p++ = '\\';
}
}
}
if(c == '\n') {
*p++ = '\0';
argv_exc[args - 1] = buf;
argv_exc[args] = 0;
int child = fork();
if (child == 0) {
exec(argv[1], argv_exc);
exit(1);
} else {
p = buf;
wait(&child);
}
} else {
*p++ = c;
}
}
exit(0);
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号