RPC核心概念理解
1 RPC概念
- RPC(Remote Procedure Call)远程过程调用,简单的理解是一个节点请求另一个节点提供的服务。
- 对应rpc的是本地过程调用,函数调用是最常见的本地过程调用。
- 将本地过程调用变成远程过程调用会面临各种问题。
1.1 本地过程调用与远程过程调用
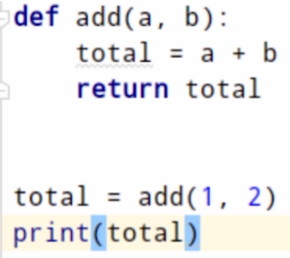
函数调用过程:
- 将1和2压入add函数的栈;
- 进入add函数,从栈中取出1和2分别赋值给a和b;
- 执行a + b将结果赋值给局部的total并压栈;
- 将栈中的值取出来赋值给全局的total。
原本的本地函数放到另一个服务器上去运行即远程过程调用,会引入很多新问题:
-
Call的id映射:我们怎么告诉远程机器我们要调用add,而不是sub或者Foo呢?在本地调用中,函数体是直接通过函数指针来指定的,我们调用add,编译器就自动帮我们调用它相应的函数指针。
但是在远程调用中,函数指针是不行的,因为两个进程的地址空间是完全不一样的。所以,在RPC中,所有的函数都必须有自己的一个ID。这个ID在所有进程中都是唯一确定的。客户端在做远程过程调用时,必须附上这个ID。然后我们还需要在客户端和服务端分别维护一个 {函数<-->Call lD} 的对应表。两者的表不一定需要完全相同,但相同的函数对应的Call ID必须相同。当客户端需要进行远程调用时,它就查一下这个表,找出相应的Call lD,然后把它传给服务端,服务端也通过查表,来确定客户端需要调用的函数,然后执行相应函数的代码。
-
序列化和反序列化(编码和解码):客户端怎么把参数值传给远程的函数呢?在本地调用中,我们只需要把参数压到栈里,然后让函数自己去栈里读就行。但是在远程过程调用时,客户端跟服务端是不同的进程,不能通过内存来传递参数。甚至有时候客户端和服务端使用的都不是同一种语言(比如服务端用C++,客户端用Java或者Python),这时候就需要客户端把参数先转成一个字节流(json\xml\protobuf\msgpack),传给服务端后,再把字节流转成自己能读取的格式。这个过程叫序列化和反序列化。同理,从服务端返回的值也需要序列化反序列化的过程。
-
网络传输:远程调用往往用在网络上,客户端和服务端是通过网络连接的。所有的数据都需要通过网络传输,因此就需要有一个网络传输层。网络传输层需要把Call ID和序列化后的参数字节流传给服务端,然后再把序列化后的调用结果传回客户端。只要能完成这两者的,都可以作为传输层使用。因此,它所使用的协议其实是不限的,能完成传输就行。尽管大部分RPC框架都使用TCP协议,但其实UDP也可以,而gRPC干脆就用了HTTP2。Java的Netty也属于这层的东西。
1.2 数据编码协议和传输协议
1.2.1 数据编码协议
编码协议:在客户端,远程过程调用数据传输时需要把参数先转成一个字节流(json\xml\protobuf\msgpack),传给服务端后,再把字节流转成自己能读取的格式。这个过程叫序列化和反序列化(也称为编码和解码)。同理,从服务端返回的值也需要序列化反序列化的过程。
package main
import (
"fmt"
)
type Company struct {
Name string
Address string
}
type Employee struct {
Name string
company Company
}
type PrintResult struct {
Info string
Err error
}
//用于远程调用的函数
func RpcPrintln(employee Employee) PrintResult {
/*
客户端的工作:
1.建立连接,基于tcp、http建立连接
2.将employee对象序列化成json字符串 - 序列化
3.发送json字符串 - 网络传输只能使用二进制数据,所以调用成功后实际上接收到的是一个二进制数据
4.等待服务器发送结果
5.将服务器返回的数据即二进制数据解析成PrintResult对象,此举是为了方便本地直接能使用对象,二进制数据是不能用的 - 反序列化
服务端的工作:
1.监听网络端口 80
2.读取数据 - 二进制的json数据
3.对数据进行反序列化成Employee对象 - 反序列化
4.开始处理业务逻辑
5.将处理结果的PrintResult对象序列化成json二进制数据 - 序列化
6.将数据返回
序列化和反序列化的编码协议是可以选择的,不一定要用json,xml、protobuf、msgpack也可以选择
*/
}
func main() {
/*
情景示例:有一个电商系统,有一个减库存的函数reduce,但是库存服务是一个独立的系统,需要远程调用reduce,
那如何远程调用呢?一定会牵扯到网络,所以可以做成一个web服务(框架:gin、beego、自带的net/httpserver)
1.函数的调用参数如何传递?
最常用的是json(json是一种数据格式的协议或者说叫编码协议,但json并不是一个高性能的编码协议)
除此之外还有其他的协议,比如:xml、protobuf、msgpack
客户端把参数通过编码协议先转成一个字节流,传给服务端后,再把字节流转成自己能读取的格式。这个过程叫序列化和反序列化。同理,从服务端返回的值也需要序列化反序列化的过程。
现在网络调用有两个端,即客户端和服务端,客户端为main函数,客户端负责将数据传输到gin,gin是服务端,服务端负责解析数据。
*/
//将这个打印的工作放在另一台服务器上
//此时需要将本地内存对象struct传到远程的服务器上,当然不能直接传,可行的方式是将struct序列化成json对象(即二进制对象)并进行传输
fmt.Println(Employee{
Name: "lee",
company: Company{
Name: "ByteDance",
Address: "beijing",
},
})
//远程的服务需要将二进制对象反解成struct对象
}
1.2.2 数据传输协议
传输协议:数据在网络中传输需要遵循数据的传输协议,协议有两种,即tcp协议和http协议,常用的是http协议,有两个版本:http1.x和http2.0。
将服务器A的数据传输到服务器B需要在两服务器之间建立连接,可以选择tcp协议或者http协议,http协议是基于tcp协议建立的,其本身也是tcp连接,http协议有一个问题:一次性,一旦对方返回了结果连接会断开,http2.0可以保持长连接;在建立连接时也可以基于tcp协议封装一层应用协议。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号