
Catalog 类型
以下内容来自官网:

Hive Catalog 支持Flink 元数据的持久化存储,以前一直用 Hive Catalog 存,偶尔需要用的时候把 Hive Catalog 开启(需启动 hive metastore 和 hiveserver2,还要启动 Hadoop),大部分时候是不用 Catalog,好像也无所谓,最近用得多了,觉得很麻烦(夏天到了,服务起太多笔记本烫手) 😃
val catalog = new HiveCatalog(paraTool.get(Constant.HIVE_CATALOG_NAME), paraTool.get(Constant.HIVE_DEFAULT_DATABASE), paraTool.get(Constant.HIVE_CONFIG_PATH))
tabEnv.registerCatalog(paraTool.get(Constant.HIVE_CATALOG_NAME), catalog)
tabEnv.useCatalog(paraTool.get(Constant.HIVE_CATALOG_NAME))
Jdbc Catalog 只支持 Flink 通过 JDBC 协议连接到关系数据库,不支持持久化 Flink 元数据
所以需要在 Jdbc Catalog 的基础上,实现 Flink 元数据持久化功能(这样只需要启动个 Mysql就可以用 Catalog 功能)
flink-connector-jdbc
从 Flink 1.17 开始,flink 发行版本不再包含 flink-connector-jdbc
flink-connector-jdbc 成为独立的项目,与 flink 主版本解耦
sqlSubmit 中使用 maven 引入 flink-connector-jdbc
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-jdbc</artifactId>
<version>3.1-SNAPSHOT</version>
</dependency>
hive catalog 的数据库表结构
自定义 MySQL Catalog 主要参考了 Hive Catalog,不过简单了很多
Flink 的 hive Catalog 主要使用了 TBLS、TABLE_PARAMS 两张表:
TBLS 存储表名:
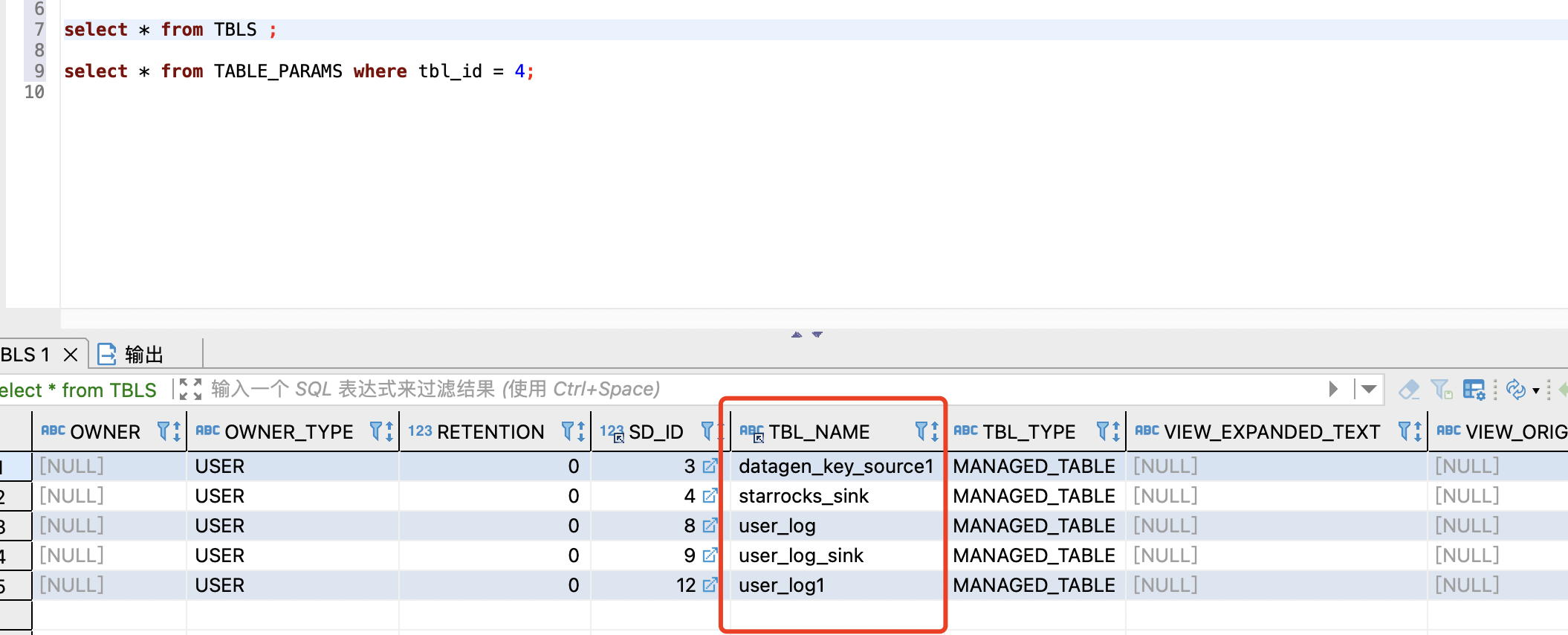
TABLE_PARAMS 存储 flink 的字段和 properties:

- flink.schema.x.name: 第 x 个字段的名字
- flink.schema.x.data-type: 第 x 个字段的类型
- flink.connector: connector 类型
- flink.comment: flink 表注释
- transient_lastDdlTime: 创建时间
- schema.primary-key.name: 主键名
- schema.primary-key.columns: 主键列
- 其他为 flink 表的 properties
flink 表:
CREATE TABLE user_log1
(
user_id VARCHAR,
item_id VARCHAR,
category_id VARCHAR,
behavior VARCHAR
) WITH (
'connector' = 'datagen'
,'rows-per-second' = '20'
,'number-of-rows' = '10000'
,'fields.user_id.kind' = 'random'
,'fields.item_id.kind' = 'random'
,'fields.category_id.kind' = 'random'
,'fields.behavior.kind' = 'random'
,'fields.user_id.length' = '20'
,'fields.item_id.length' = '10'
,'fields.category_id.length' = '10'
,'fields.behavior.length' = '10'
);
自定义 MySQL Catalog 配置
定义 Mysql Catalog 表信息
参考 hive Catalog 创建 tbls 和 col 两个表
tbls:
CREATE TABLE `tbls` (
`id` int NOT NULL AUTO_INCREMENT,
`TBL_NAME` varchar(128) NOT NULL COMMENT '表名',
`CREATE_TIME` datetime DEFAULT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `tbls_UN` (`TBL_NAME`)
);
col:
CREATE TABLE `col` (
`id` int NOT NULL AUTO_INCREMENT,
`TBL_ID` int NOT NULL,
`PARAM_KEY` varchar(256) NOT NULL COMMENT '表名',
`PARAM_VALUE` text NOT NULL COMMENT '表名',
`CREATE_TIME` datetime DEFAULT NULL,
PRIMARY KEY (`id`)
);
MyMySqlCatalog 核心方法 createTable/getTable
- 说明为了区分 JdbcCatalog 中的 MySQLCatalog,自定义的 Catalog 命令为 MyMySqlCatalog
Flink 自定义 Catalog 可以继承自 Catalog 接口,自定义 MySQL Catalog 从抽象类 AbstractJdbcCatalog 继承就可以了,很多方法已经预定义了
定义可以存储 flink 元数据的 Catalog 核心方法就 2 个:
- createTable: flink 执行创建表操作的方法,获取 flink 任务中的表结构,存储到 Catalog 数据库
- getTable: flink 执行 select 的时候,getTable 方法从 Catalog 数据库获取表结构
createTable
createTable 方法思路如下:
- flink 执行 createTable 方法的时候会传入 三个参数:
- tablePath: 表的全路径,如: mysql-catalog.flink_database.table_name
- table: flink 表结构
- ignoreIfExists: 是否忽略表已存在
- tablePath 中解析表名
- 将表名写入 tbls 表
- 获取 上一步写入 tbls 表中,flink 表的 id
- table 中解析字段信息,组装为: schema.x.name/schema.data-type
- 获取 table 中所有 配置信息
- 将 4/5/6 步 获取的信息写入 col 表,做完 flink 表的元数据信息
createTable 方法代码如下:
/**
* create table, save metadata to mysql
* <p>
* 1. insert table to table: tbls
* 2. insert column to table: col
*/
@Override
public void createTable(ObjectPath tablePath, CatalogBaseTable table, boolean ignoreIfExists)
throws DatabaseNotExistException, CatalogException {
LOG.debug("create table in mysql catalog");
checkNotNull(tablePath, "tablePath cannot be null");
checkNotNull(table, "table cannot be null");
String databaseName = tablePath.getDatabaseName();
String tableName = tablePath.getObjectName();
String dbUrl = baseUrl + databaseName;
if (!this.databaseExists(tablePath.getDatabaseName())) {
throw new DatabaseNotExistException(this.getName(), tablePath.getDatabaseName());
} else {
// get connection
try (Connection conn = DriverManager.getConnection(dbUrl, username, pwd)) {
// insert table name to tbls
PreparedStatement ps = conn.prepareStatement("insert into tbls(TBL_NAME, CREATE_TIME) values(?, NOW())");
ps.setString(1, tableName);
try {
ps.execute();
} catch (SQLIntegrityConstraintViolationException e) {
// Duplicate entry 'user_log' for key 'tbls.tbls_UN'
if (!ignoreIfExists) {
throw new SQLIntegrityConstraintViolationException(e);
}
// table exists, return
return;
}
// get table id
ps = conn.prepareStatement("select id from tbls where TBL_NAME = ?");
ps.setString(1, tableName);
ResultSet resultSet = ps.executeQuery();
int id = -1;
while (resultSet.next()) {
id = resultSet.getInt(1);
}
if (id == -1) {
throw new CatalogException(
String.format("Find table %s id error", tablePath.getFullName()));
}
////////// parse propertes
/// parse column to format :
// schema.x.name
// schema.x.data-type
Map<String, String> prop = new HashMap<>();
int fieldCount = table.getSchema().getFieldCount();
for (int i = 0; i < fieldCount; i++) {
TableColumn tableColumn = table.getSchema().getTableColumn(i).get();
prop.put("schema." + i + ".name", tableColumn.getName());
prop.put("schema." + i + ".data-type", tableColumn.getType().toString());
}
/// parse prop: connector,and ext properties
prop.putAll(table.getOptions());
prop.put("comment", table.getComment());
prop.put("transient_lastDdlTime", "" + System.currentTimeMillis());
// insert TABLE_PARAMS
ps = conn.prepareStatement("insert into col(TBL_id, PARAM_KEY, PARAM_VALUE, CREATE_TIME) values(?,?,?, now())");
for (Map.Entry<String, String> entry : prop.entrySet()) {
String key = entry.getKey();
String value = entry.getValue();
ps.setInt(1, id);
ps.setString(2, key);
ps.setString(3, value);
ps.addBatch();
}
// todo check insert stable
ps.executeBatch();
} catch (SQLException e) {
//todo
throw new CatalogException(
String.format("Failed create table %s", tablePath.getFullName()), e);
}
}
}
getTable
getTable 方法思路如下:
- flink 执行 createTable 方法的时候会传入 tablePath 参数:表的全路径,如: mysql-catalog.flink_database.table_name
- 从 col 表获取表元数据信息
- 以属性中 schema 为标准,将字段和配置信息拆分到不同的 map 中存放
- 从配置信息 map 中,移除主键信息
- 从字段信息 map 中解析字段个数,组装 字段名数组和字段类型数组(一一对应)
- 使用 字段名数据和字段信息数组创建 TableSchema,添加主键信息
- 使用 TableSchema 和 配置信息 map 创建 CatalogTableImpl
getTable 方法代码如下:
/**
* get table from mysql
*/
@Override
public CatalogBaseTable getTable(ObjectPath tablePath) throws TableNotExistException, CatalogException {
// check table exists
if (!tableExists(tablePath)) {
throw new TableNotExistException(getName(), tablePath);
}
try (Connection conn = DriverManager.getConnection(baseUrl + tablePath.getDatabaseName(), username, pwd)) {
// load table column and properties
PreparedStatement ps =
conn.prepareStatement(
String.format("select PARAM_KEY, PARAM_VALUE from col where tbl_id in (select id from tbls where TBL_NAME = ?);", getSchemaTableName(tablePath)));
ps.setString(1, tablePath.getObjectName());
ResultSet resultSet = ps.executeQuery();
// for column
Map<String, String> colMap = new HashMap<>();
// for properties
Map<String, String> props = new HashMap<>();
while (resultSet.next()) {
String key = resultSet.getString(1);
String value = resultSet.getString(2);
if (key.startsWith("schema")) {
colMap.put(key, value);
} else {
props.put(key, value);
}
}
/////////////// remove primary key
String pkColumns = props.remove("schema.primary-key.columns");
String pkName = props.remove("schema.primary-key.name");
/////// find column size
int columnSize = -1;
String regEx = "[^0-9]";
Pattern p = Pattern.compile(regEx);
for (String key : colMap.keySet()) {
Matcher m = p.matcher(key);
String num = m.replaceAll("").trim();
if (num.length() > 0) {
columnSize = Math.max(Integer.parseInt(num), columnSize);
}
}
++columnSize;
/////////////// makeup column and column type
String[] colNames = new String[columnSize];
DataType[] colTypes = new DataType[columnSize];
for (int i = 0; i < columnSize; i++) {
String name = colMap.get("schema." + i + ".name");
String dateType = colMap.get("schema." + i + ".data-type");
colNames[i] = (name);
colTypes[i] = MysqlCatalogUtils.toFlinkType(dateType);
}
// makeup TableSchema
TableSchema.Builder builder = TableSchema.builder().fields(colNames, colTypes);
if (StringUtils.isNotBlank(pkName)) {
builder.primaryKey(pkName, pkColumns);
}
TableSchema tableSchema = builder.build();
String comment = props.remove("comment");
props.remove("transient_lastDdlTime");
// init CatalogTable
return new CatalogTableImpl(tableSchema, new ArrayList<>(), props, comment);
} catch (Exception e) {
throw new CatalogException(
String.format("Failed getting table %s", tablePath.getFullName()), e);
}
}
配置 MysqlCatalog
在启动类中添加 Catalog
val catalog = new MyMySqlCatalog(this.getClass.getClassLoader
, "mysql-catalog"
, "flink"
, "root"
, "123456"
, "jdbc:mysql://localhost:3306")
tabEnv.registerCatalog("mysql-catalog", catalog)
tabEnv.useCatalog("mysql-catalog")
测试创建表
执行 demo 脚本,包含 source、sink 表创建,执行 insert:
-- kafka source
-- drop table if exists user_log;
CREATE TABLE if not exists user_log
(
user_id VARCHAR,
item_id VARCHAR,
category_id VARCHAR,
behavior VARCHAR
)
COMMENT 'abcdefs'
WITH (
'connector' = 'datagen'
,'rows-per-second' = '20'
,'number-of-rows' = '10000'
,'fields.user_id.kind' = 'random'
,'fields.item_id.kind' = 'random'
,'fields.category_id.kind' = 'random'
,'fields.behavior.kind' = 'random'
,'fields.user_id.length' = '20'
,'fields.item_id.length' = '10'
,'fields.category_id.length' = '10'
,'fields.behavior.length' = '10'
);
--
--
-- -- set table.sql-dialect=hive;
-- -- kafka sink
drop table if exists user_log_sink;
CREATE TABLE user_log_sink
(
user_id STRING,
item_id STRING,
category_id STRING,
behavior STRING
) WITH (
'connector' = 'kafka'
,'topic' = 'user_log_test_20230309'
-- ,'properties.bootstrap.servers' = 'host.docker.internal:9092'
,'properties.bootstrap.servers' = 'localhost:9092'
,'properties.group.id' = 'user_log'
,'scan.startup.mode' = 'latest-offset'
,'format' = 'json'
);
-- streaming sql, insert into mysql table
insert into user_log_sink
SELECT user_id, item_id, category_id, behavior
FROM user_log;
测试运行正常:
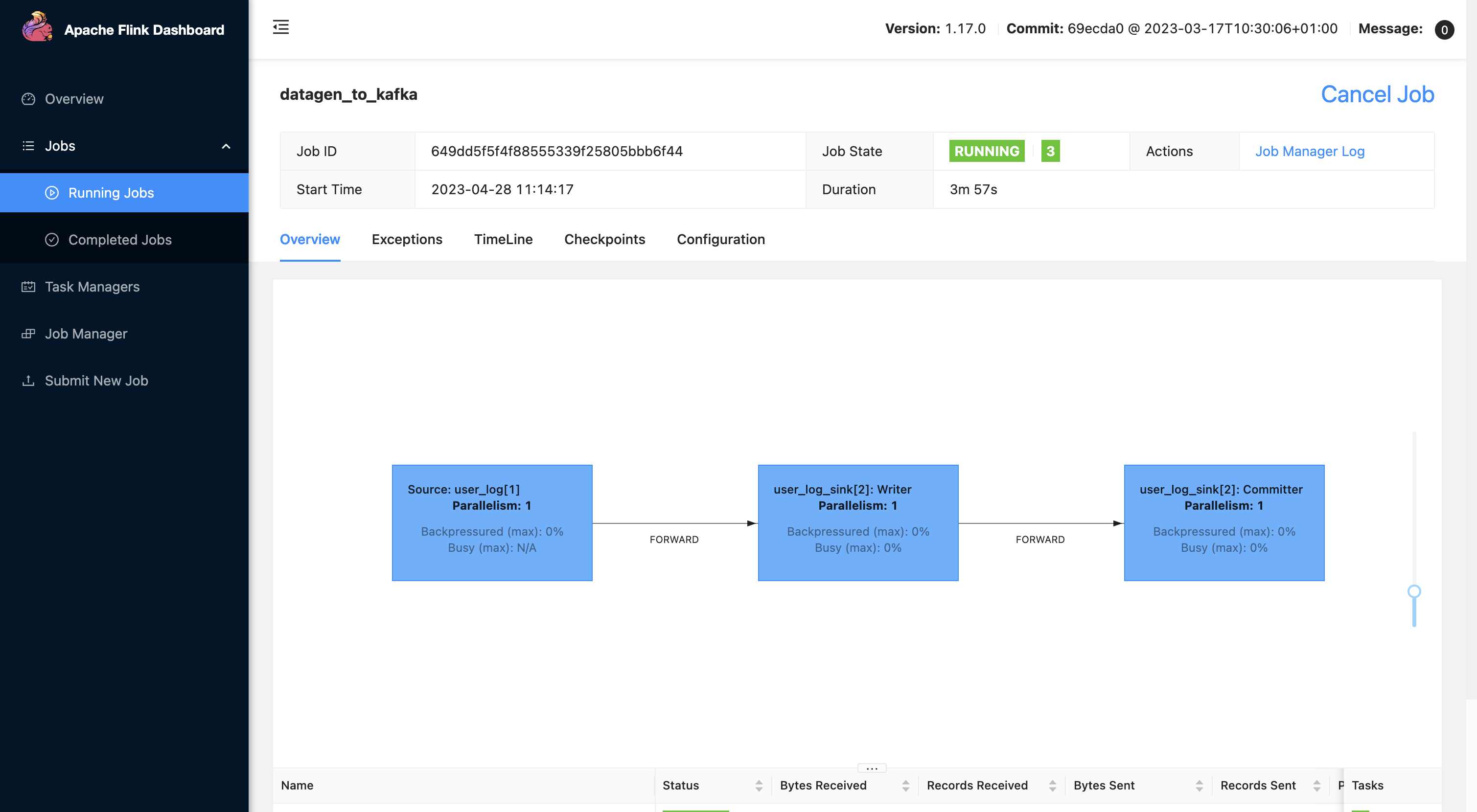
查看 tbls 和 col 表内容:
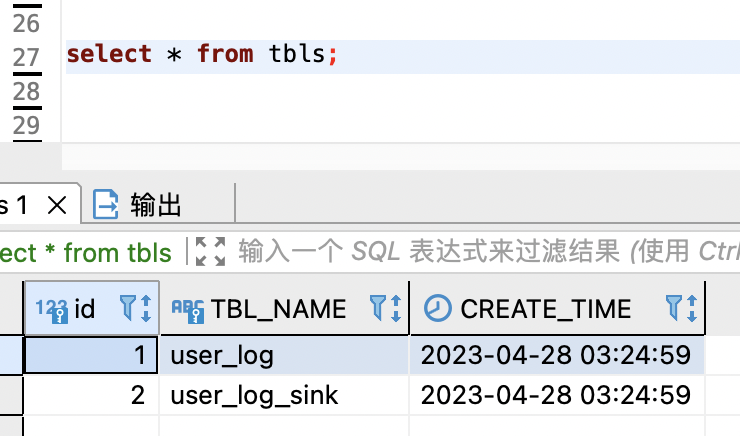
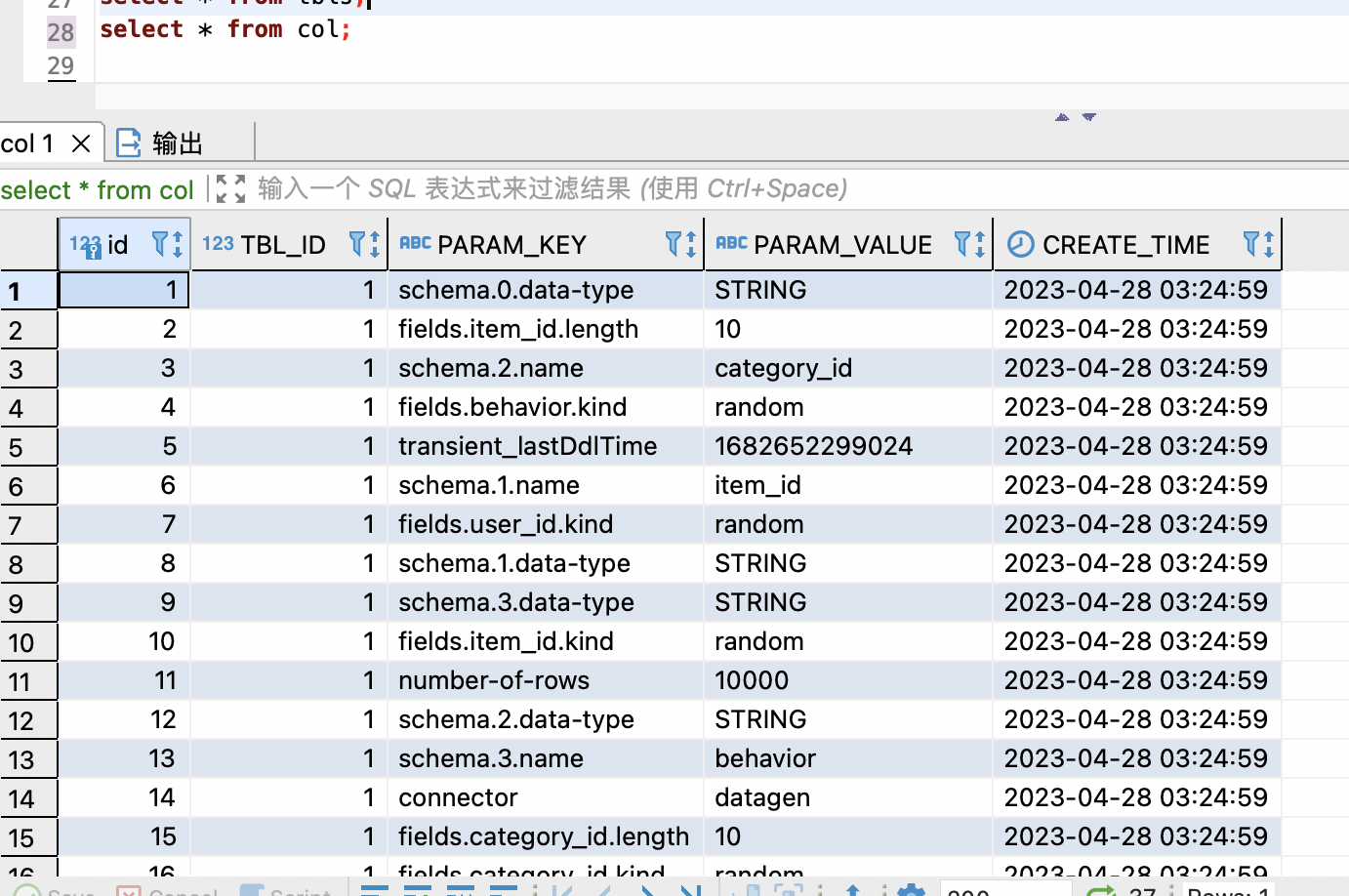
搞定
完整代码参数:github sqlSubmit dev 分支
欢迎关注Flink菜鸟公众号,会不定期更新Flink(开发技术)相关的推文


 浙公网安备 33010602011771号
浙公网安备 33010602011771号