hadoop 简介
hadoop 的三大组件和关系
1. HDFS:分布式文件系统
hdfs 的特点和不适用使用场景
1.1 HDFS文件系统可存储超大文件(不适用有大量小文件场景和小量场景,默认块大小是MB,资源浪费)
1.2 一次写入,多次读取(不适用多用户更新,hadoop 不支持记录级别的插入更新)
1.3 运行在普通廉价的机器上
1.4 DFS适合存储半结构化和非结构化数据,HDFS延时较高 (不适用低延时场景和严格结构化数据场景,推荐使用Hbase)
2. MapReduce:计算模型(分布式并行计算框架)
2.1 概念浅析
MapReduce 可以将一个大型的数据处理任务分解成很多单个的可以在服务器集群中并行执行的任务,这些任务的计算结果可以合并在一起来计算最终结果。
MapReduce核心思想:分而治之
2.2 模型原理
MapReduce计算模型主要由三个阶段构成:Map、shuffle、Reduce
Map :将文件按设置的block大小切片,映射,负责数据的过滤分法,将原始数据转化为键值对记录,然后输出到环形缓冲区或磁盘;
Shuffle:对MapTask 输出的处理结果进行一定的排序与分割,进一步整理并交给Reduce的过程(Shuffle过程包含在Map和Reduce两端,即Map shuffle和Reduce shuffle)
Reduce: 并行处理Map的结果从缓存或者磁盘copy,合并,将具有相同key值的value进行处理后再输出新的键值对作为最终结果。
MapRduce过程详解
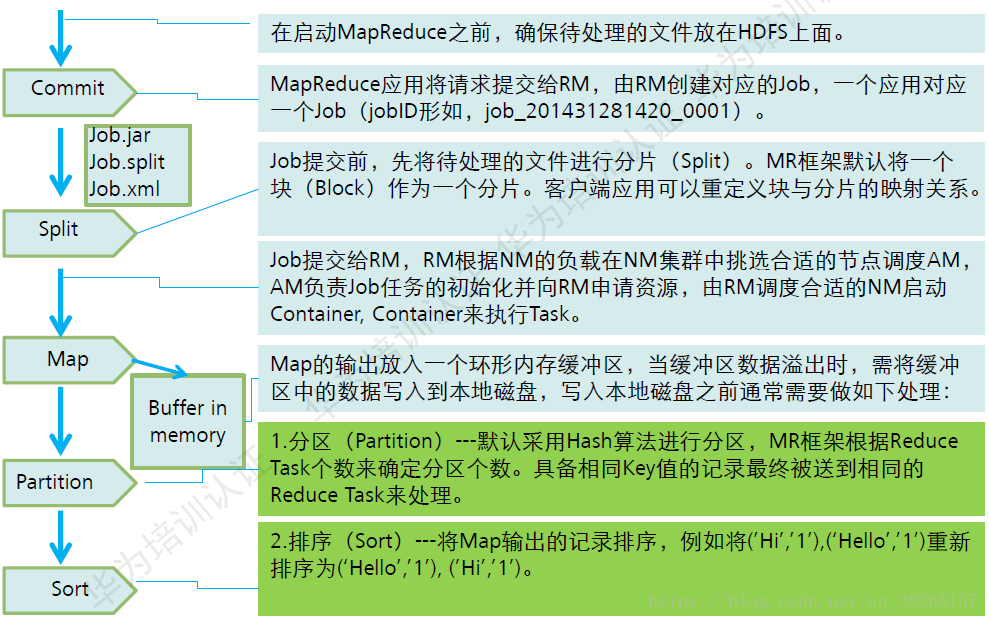

2.3 MadReduce的特点
- 易于编程:程序员仅需描述做什么,具体怎么做由系统的执行框架处理。
- 良好的扩展性:可通过添加结点以扩展集群能力。(硬件/价格/扩展性:普通PC机,便宜,扩展性好)
- 高容错性:通过计算迁移或数据迁移等策略提高集群的可用性与容错性
- 批处理、非实时、数据密集型
3. Yarn:
1.客户端:提交MapReduce作业
2.YARN的资源管理器(Resource Manager),协调集群中资源的分配
YARN的引入,使得多个计算框架(Spark,MapReduce,storm等)可运行在一个集群中
3.YARN的节点管理器(Node Manager)启动并监控集群中的计算容器。
4.ApplicationMaster:每个应用程序对应一个ApplicationMaster负责应用程序相关的事务、比如任务调度、任务监控和容错等。(Spark,MapReduce,storm等)
MapReduce的Application Master,协调MapReduce作业中任务的运行。Application Master和MapReduce任务运行于容器中。这些容器由resourcemanager调度,由namenode管理。
5.分布式文件系统(HDFS),在组建之间共享作业数据
hadoop 生态
Hadoop核心生态圈组件如下:
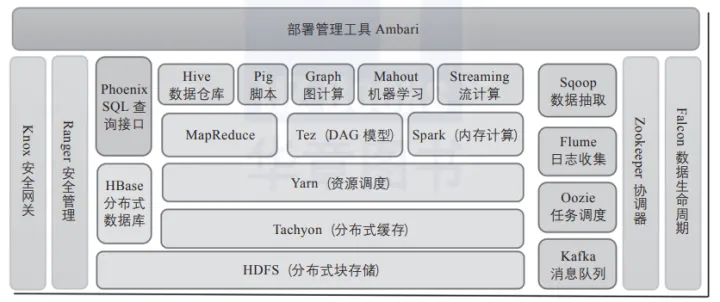
Hadoop包括以下4个基本模块。
1)Hadoop基础功能库:支持其他Hadoop模块的通用程序包。
2)HDFS:一个分布式文件系统,能够以高吞吐量访问应用中的数据。
3)YARN:一个作业调度和资源管理框架。
4)MapReduce:一个基于YARN的大数据并行处理程序。
除了基本模块,Hadoop还包括以下项目。
1)Ambari:基于Web,用于配置、管理和监控Hadoop集群。支持HDFS、MapReduce、Hive、HCatalog、HBase、ZooKeeper、Oozie、Pig和Sqoop。Ambari还提供显示集群健康状况的仪表盘,如热点图等。Ambari以图形化的方式查看MapReduce、Pig和Hive应用程序的运行情况,因此可以通过对用户友好的方式诊断应用的性能问题。
2)Avro:数据序列化系统。
3)Cassandra:可扩展的、无单点故障的NoSQL多主数据库。
4)Chukwa:用于大型分布式系统的数据采集系统。
5)HBase:可扩展的分布式数据库,支持大表的结构化数据存储。
6)Hive:数据仓库基础架构,提供数据汇总和命令行即席查询功能。
7)Mahout:可扩展的机器学习和数据挖掘库。
8)Pig:用于并行计算的高级数据流语言和执行框架。
9)Spark:可高速处理Hadoop数据的通用计算引擎。Spark提供了一种简单而富有表达能力的编程模式,支持ETL、机器学习、数据流处理、图像计算等多种应用。
10)Tez:完整的数据流编程框架,基于YARN建立,提供强大而灵活的引擎,可执行任意有向无环图(DAG)数据处理任务,既支持批处理又支持交互式的用户场景。Tez已经被Hive、Pig等Hadoop生态圈的组件所采用,用来替代 MapReduce作为底层执行引擎。
11)ZooKeeper:用于分布式应用的高性能协调服务。
除了以上这些官方认可的Hadoop生态圈组件之外,还有很多十分优秀的组件这里没有介绍,这些组件的应用也非常广泛,例如基于Hive查询优化的Presto、Impala、Kylin等
里云E-MapReduce平台整合的Hadoop生态体系中的组件:
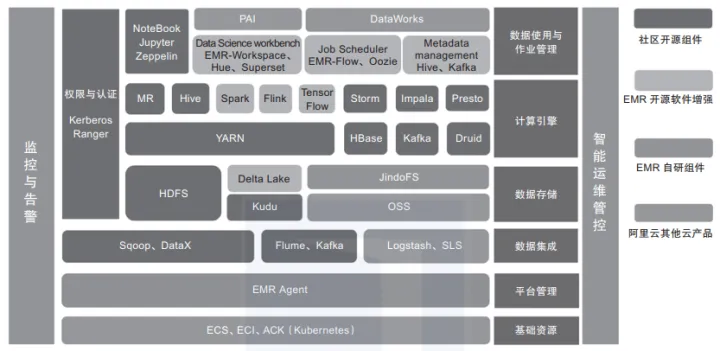
下面简单介绍其中比较重要的成员。
1)Presto:开源分布式SQL查询引擎,适用于交互式分析查询,数据量支持GB到PB级。Presto可以处理多数据源,是一款基于内存计算的MPP架构查询引擎。
2)Kudu:与HBase类似的列存储分布式数据库,能够提供快速更新和删除数据的功能,是一款既支持随机读写,又支持OLAP分析的大数据存储引擎。
3)Impala:高效的基于MPP架构的快速查询引擎,基于Hive并使用内存进行计算,兼顾ETL功能,具有实时、批处理、多并发等优点。
4)Kylin:开源分布式分析型数据仓库,提供Hadoop/Spark之上的SQL查询接口及多维分析(OLAP)能力,支持超大规模数据的压秒级查询。
5)Flink:一款高吞吐量、低延迟的针对流数据和批数据的分布式实时处理引擎,是实时处理领域的新星。
6)Hudi:Uber开发并开源的数据湖解决方案,Hudi(Hadoop updates and incrementals)支持HDFS数据的修改和增量更新操作。
参考摘录资料:
MapReduce技术原理
MapReduce原理浅显解析1
MapReduce原理浅显解析2
hadoop 生态

 浙公网安备 33010602011771号
浙公网安备 33010602011771号