CRUD工程师——基础容器HashSet
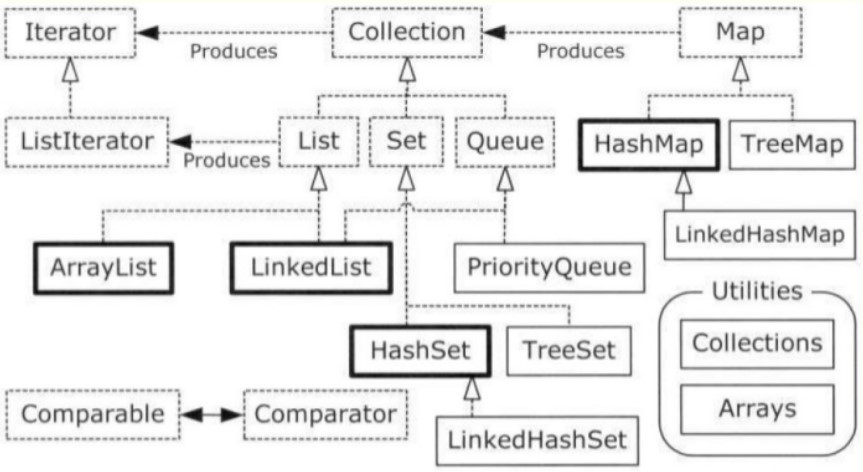
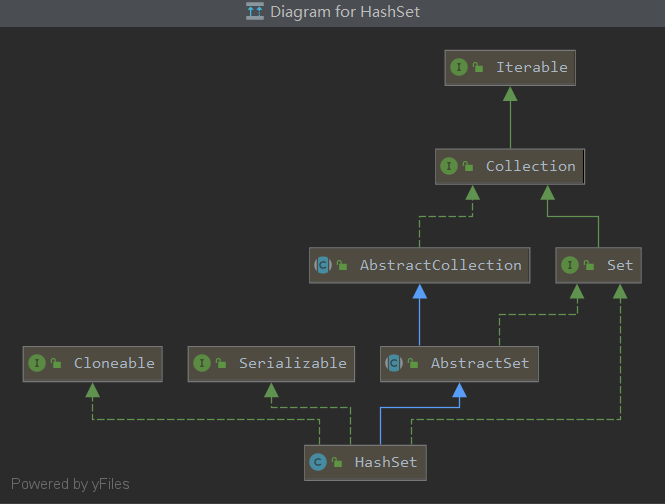
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable
{
//序列化和反序列化的标识
static final long serialVersionUID = -5024744406713321676L;
//对应了上面说的,HashSet其实是基于HashMap的实例(成员变量不参与序列化过程)
private transient HashMap<E,Object> map;
//定义一个虚拟的Object对象作为HashMap的value,将此对象定义为static final
private static final Object PRESENT = new Object();
//空参构造,出来的其实是个HashMap
public HashSet() {
map = new HashMap<>();
}
//带参数构造
public HashSet(Collection<? extends E> c) {
//实际底层会初始化一个空的HashMap,并使用默认初始容量为16和加载因子0.75
map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16));
addAll(c);
}
//以指定的initialCapacity和loadFactor构造一个空的HashSet,其实还是HashMap
public HashSet(int initialCapacity, float loadFactor) {
map = new HashMap<>(initialCapacity, loadFactor);
}
//只有初始容量大小的构造方法
public HashSet(int initialCapacity) {
map = new HashMap<>(initialCapacity);
}
//以指定的initialCapacity和loadFactor构造一个新的空链接哈希集合。 此构造函数为包访问权限,不对外公开,实际只是是对LinkedHashSet的支持
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
//返回对此set中元素进行迭代的迭代器。返回元素的顺序并不是特定的。底层实际调用底层HashMap的keySet来返回所有的key
//可见HashSet中的元素,只是存放在了底层HashMap的key上
public Iterator<E> iterator() {
return map.keySet().iterator();
}
//底层实际调用HashMap的size()方法返回Entry的数量,就得到该Set中元素的个数。
public int size() {
return map.size();
}
public boolean isEmpty() {
return map.isEmpty();
}
//底层实际调用HashMap的containsKey判断是否包含指定key。
public boolean contains(Object o) {
return map.containsKey(o);
}
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
/**
* 如果此set中尚未包含指定元素,则添加指定元素。
* 更确切地讲,如果此 set 没有包含满足(e==null ? e2==null : e.equals(e2))
* 的元素e2,则向此set 添加指定的元素e。
* 如果此set已包含该元素,则该调用不更改set并返回false。
* 底层实际将将该元素作为key放入HashMap。
* 由于HashMap的put()方法添加key-value对时,当新放入HashMap的Entry中key
* 与集合中原有Entry的key相同(hashCode()返回值相等,通过equals比较也返回true),
* 新添加的Entry的value会将覆盖原来Entry的value,但key不会有任何改变,
* 因此如果向HashSet中添加一个已经存在的元素时,新添加的集合元素将不会被放入HashMap中,
* 原来的元素也不会有任何改变,这也就满足了Set中元素不重复的特性。
* @param e 将添加到此set中的元素。
* @return 如果此set尚未包含指定元素,则返回true。
*/
public boolean remove(Object o) {
return map.remove(o)==PRESENT;
}
public void clear() {
map.clear();
}
//去除警告,克隆
@SuppressWarnings("unchecked")
public Object clone() {
try {
HashSet<E> newSet = (HashSet<E>) super.clone();
newSet.map = (HashMap<E, Object>) map.clone();
return newSet;
} catch (CloneNotSupportedException e) {
throw new InternalError(e);
}
}
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException {
s.defaultWriteObject();
s.writeInt(map.capacity());
s.writeFloat(map.loadFactor());
s.writeInt(map.size());
for (E e : map.keySet())
s.writeObject(e);
}
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
s.defaultReadObject();
int capacity = s.readInt();
if (capacity < 0) {
throw new InvalidObjectException("Illegal capacity: " +
capacity);
}
float loadFactor = s.readFloat();
if (loadFactor <= 0 || Float.isNaN(loadFactor)) {
throw new InvalidObjectException("Illegal load factor: " +
loadFactor);
}
int size = s.readInt();
if (size < 0) {
throw new InvalidObjectException("Illegal size: " +
size);
}
capacity = (int) Math.min(size * Math.min(1 / loadFactor, 4.0f),
HashMap.MAXIMUM_CAPACITY);
SharedSecrets.getJavaOISAccess()
.checkArray(s, Map.Entry[].class, HashMap.tableSizeFor(capacity));
map = (((HashSet<?>)this) instanceof LinkedHashSet ?
new LinkedHashMap<E,Object>(capacity, loadFactor) :
new HashMap<E,Object>(capacity, loadFactor));
for (int i=0; i<size; i++) {
@SuppressWarnings("unchecked")
E e = (E) s.readObject();
map.put(e, PRESENT);
}
}
public Spliterator<E> spliterator() {
return new HashMap.KeySpliterator<E,Object>(map, 0, -1, 0, 0);
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号