
一个基本的AI建模议题:分类的标签设定
by 高焕堂
<<议题>>
为什么在多类别的分类时,其标签(Label)值要设定像[0,0,1]、[0,1,0]、[1,0,0]这样的格式呢?
<<观摩范例>>
例如,针对104网页上的工作机会,如果只取一个特征(如<钱多>)来作为判断(即分类)的依据,而进行分类,分为<喜欢>与<不喜欢>两类。使用Excel表达如下:
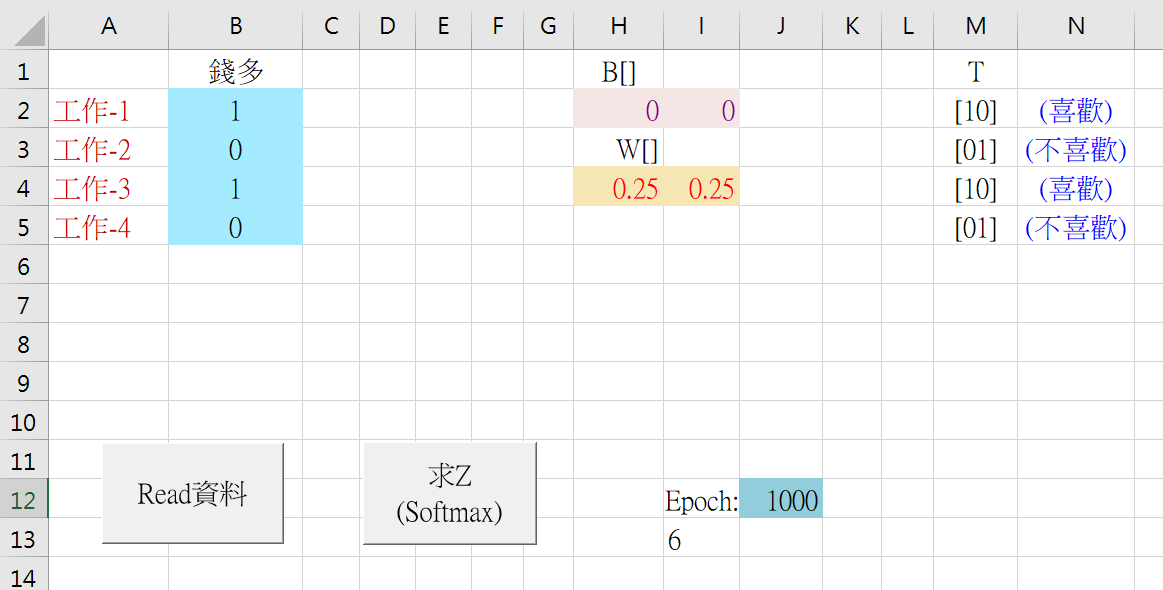
因为分为两类,所以就设定两个Label值:[10]和[01]。这里的[10]就代表数学的阵列[1,0]的意思。
以此类推,如果分为3类,如下:
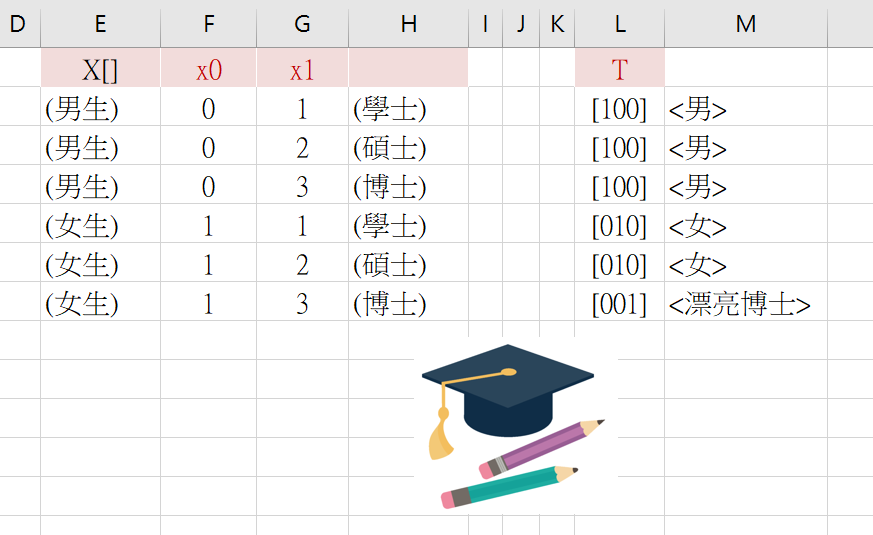
这是根据两个特征(性别和学历)而进行分类,将其分为3类:男、女、漂亮博士。所以就设定3个Label值:[100]、[010]和[001]。这里的[100]就代表数学的阵列[1,0,0]的意思。以此类推,再看看这个例子:

这个范例是参考Donald J. Norris所写的〝Raspberry Pi Python Prolog〞一书的范例。只利用几条直线线段来呈现0到9等十位数字。例如下图:
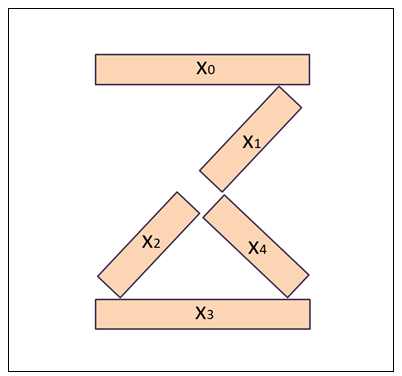
透过五条线段的组合,可以组合出<0>、<1>、<2>与<3>阿拉伯数字,如下:
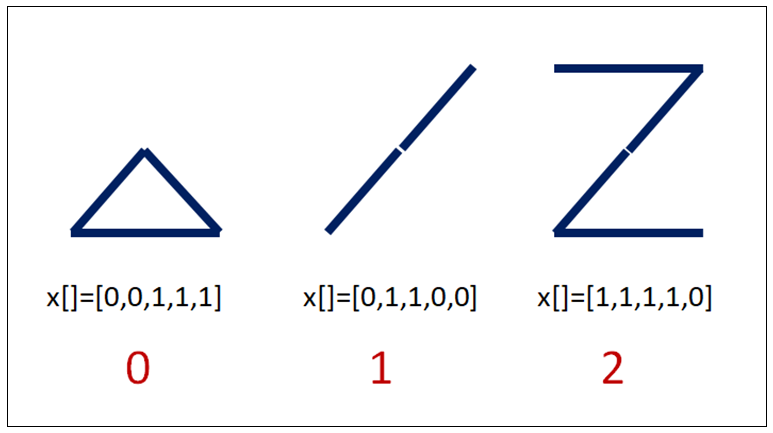
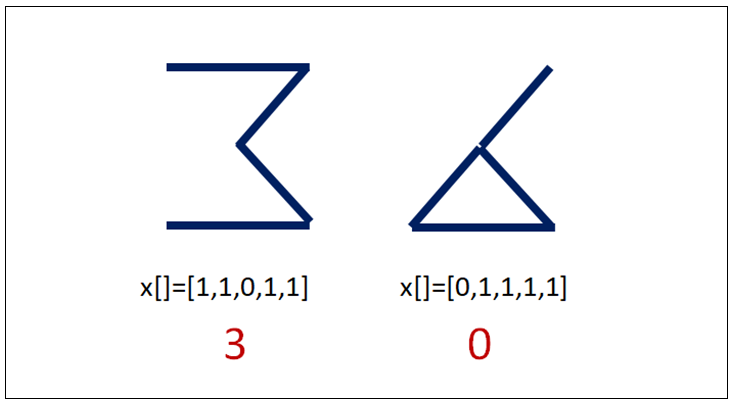
人们很容易就能辨识出来,那么我们如何去训练AI机器,让它具有智慧,也能迅速辨别出来呢? 本章就透过这范例,让您来观摩一下啰。 其中,最后一个看起来很像数字<6>,在本范例里刻意也将它视为数字<0>。这个模型经过训练之后,将能辨别<0>、<1>、<2>与<3>共四个阿拉伯数字。也就是分为4类。于是设定其Label值如下:
- 第#0笔资料的实际值是t[1 ,0, 0, 0] --- 代表数字<0>
- 第#1笔资料的实际值是t[0 ,1, 0, 0] --- 代表数字<1>
- 第#2笔资料的实际值是t[0 ,0, 1, 0] --- 代表数字<2>
- 第#3笔资料的实际值是t[0 ,0, 0, 1] --- 代表数字<3>
- 第#4笔资料的实际值是t[1 ,0, 0, 0] --- 代表数字<0>
<<说明缘由>>
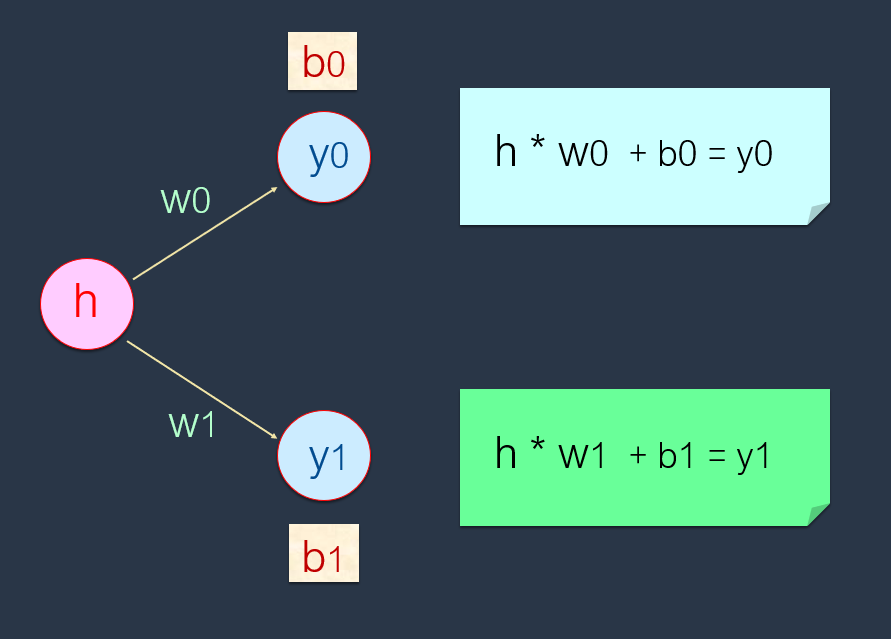
这需要复习一下,最基本的NN(神经网路)结构:

其运算公式是:
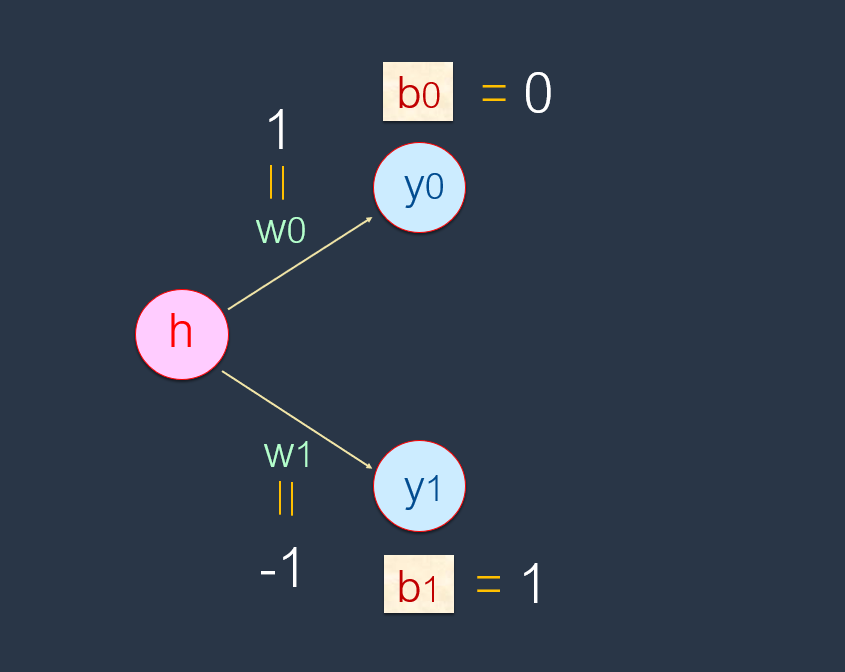
设定:W0 = 1, b0 = 0。而且设定:W1 = -1, b1 = 1。
输入第1笔资料(即工作-1)的特征值:
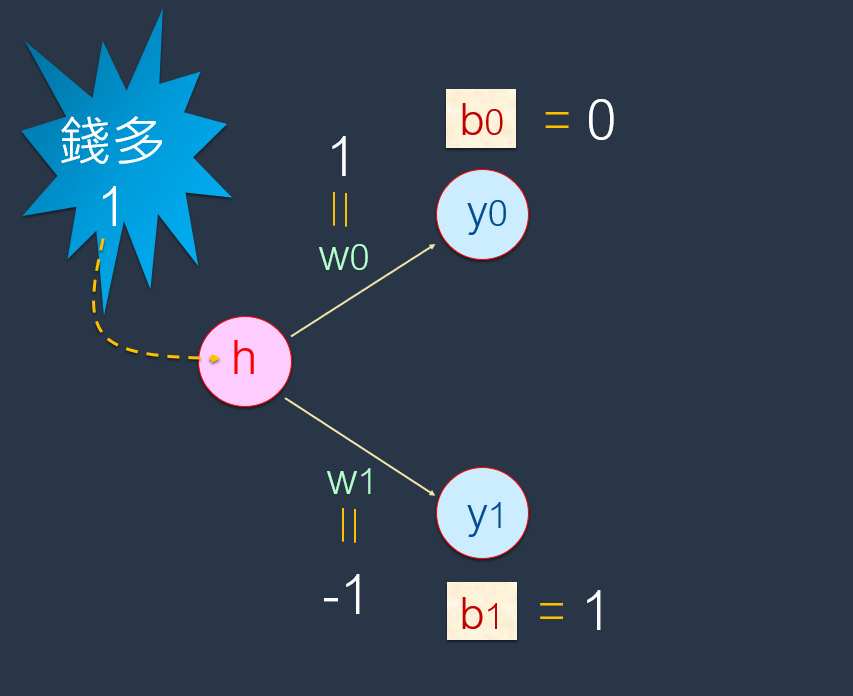
计算出结果:
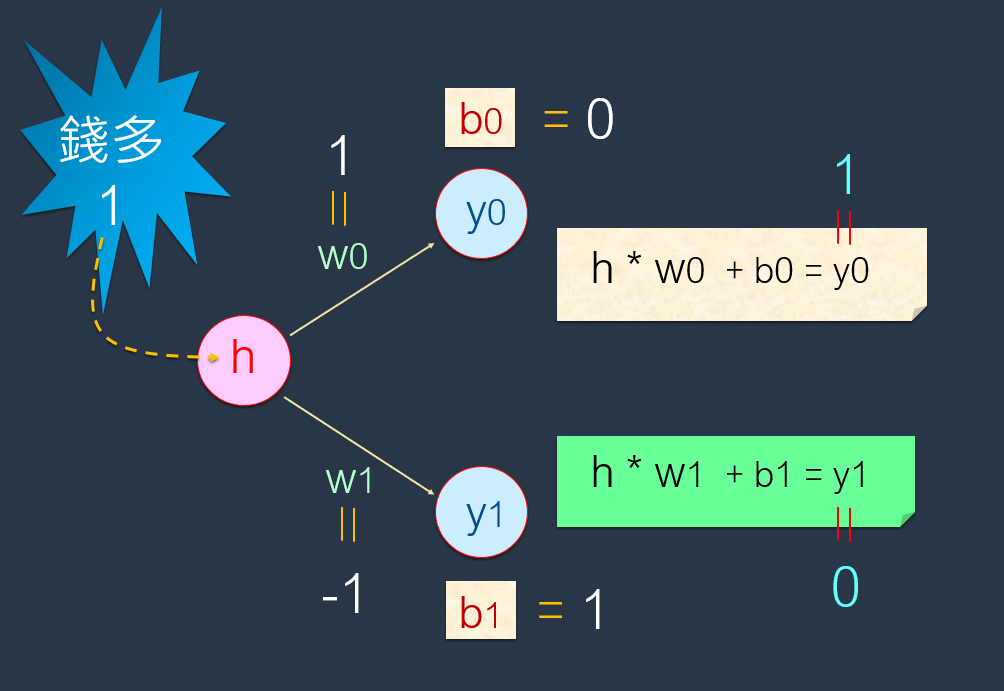
上面已经输入第1笔资料(即工作-1)的特征值:1(代表钱多)。而输出的值:[1,0]则代表<喜欢>。
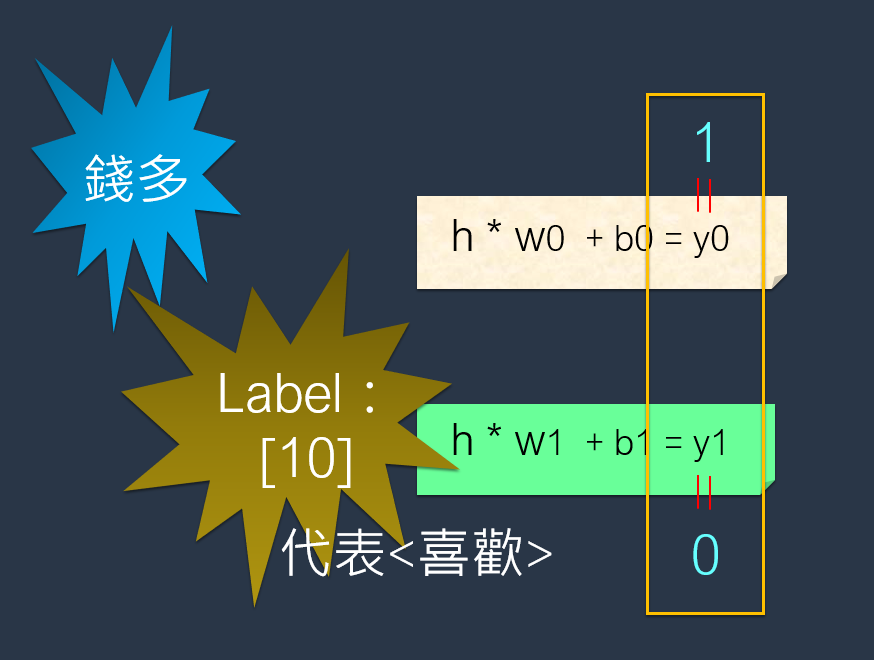
于是,在Excel上列出其中的对应关系,来训练AI模型:
以上是从简单的NN模型架构,让您充分理解为什么我们要为每一笔资料做<标注>(Label),而且是像[10000]、[01000]这样的格式。这就是当今主流的AI:监督式学习。接下來,按下<求Z>,就展开<训练>的动作:
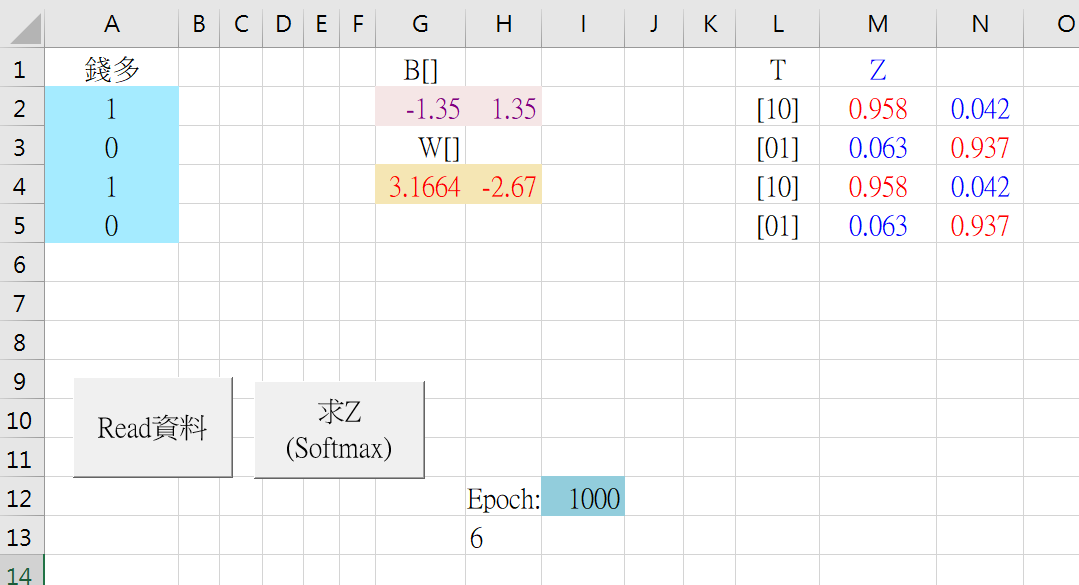
例如,针对第#1笔资料而计算出了z[] = [0.958, 0.042]。其中,最大值是0.958,就以1来取代0.958,并以0来取代其他较小的值,就得到新的阵列值:[1, 0],它就是代表<喜欢>的Label值,于是这AI机器就预测您会喜欢这第#1笔资料所代表的:工作-1。
再如,针对第#2笔资料而计算出了z[] = [0.063, 0.937]。其中,最大值是0.937,就以0来取代0.937,并以0来取代其他较小的值,就得到新的阵列值:[0, 1],它就是代表<不喜欢>的Label值,于是这AI机器就预测您不会喜欢这第#2笔资料所代表的:工作-2。
~ END ~
