
从注意力机制到Swin Transformer
引言
近年来,Transformer[1]在自然语言处理(NLP)领域取得了重要的成果,通过完全的注意力机制引发了NLP领域的全新变革,在之后,bert模型应运而生,成为NLP领域中的重要模型。
同时,注意力的强大性能也引起了其他领域的关注,例如在图像处理领域就根据注意力机制和Transformer模型提出了Vision Transformer(VIT)[2]该模型也取得了很好的效果,而本文所介绍的Swin Transformer[3]则是对于VIT的更进一步的改进。
(本文是本人在阅读文献查阅资料后写的读书笔记,若有不对的地方,请多多包涵并欢迎指正!)
注意力机制的介绍
注意力的概念
在介绍Swin Transformer之前,需要对这一切的源头,注意力机制[4]做一个介绍。对于人来说,注意力就相当于专注度,比如当你专心读书时,你的目光会随着文字移动,虽然所有的句子都在你的视野当中,但是当你在阅读一个句子的时候,其他的句子在你眼中就会变得模糊。下面的热力图可以比较直观地展示这种情况。
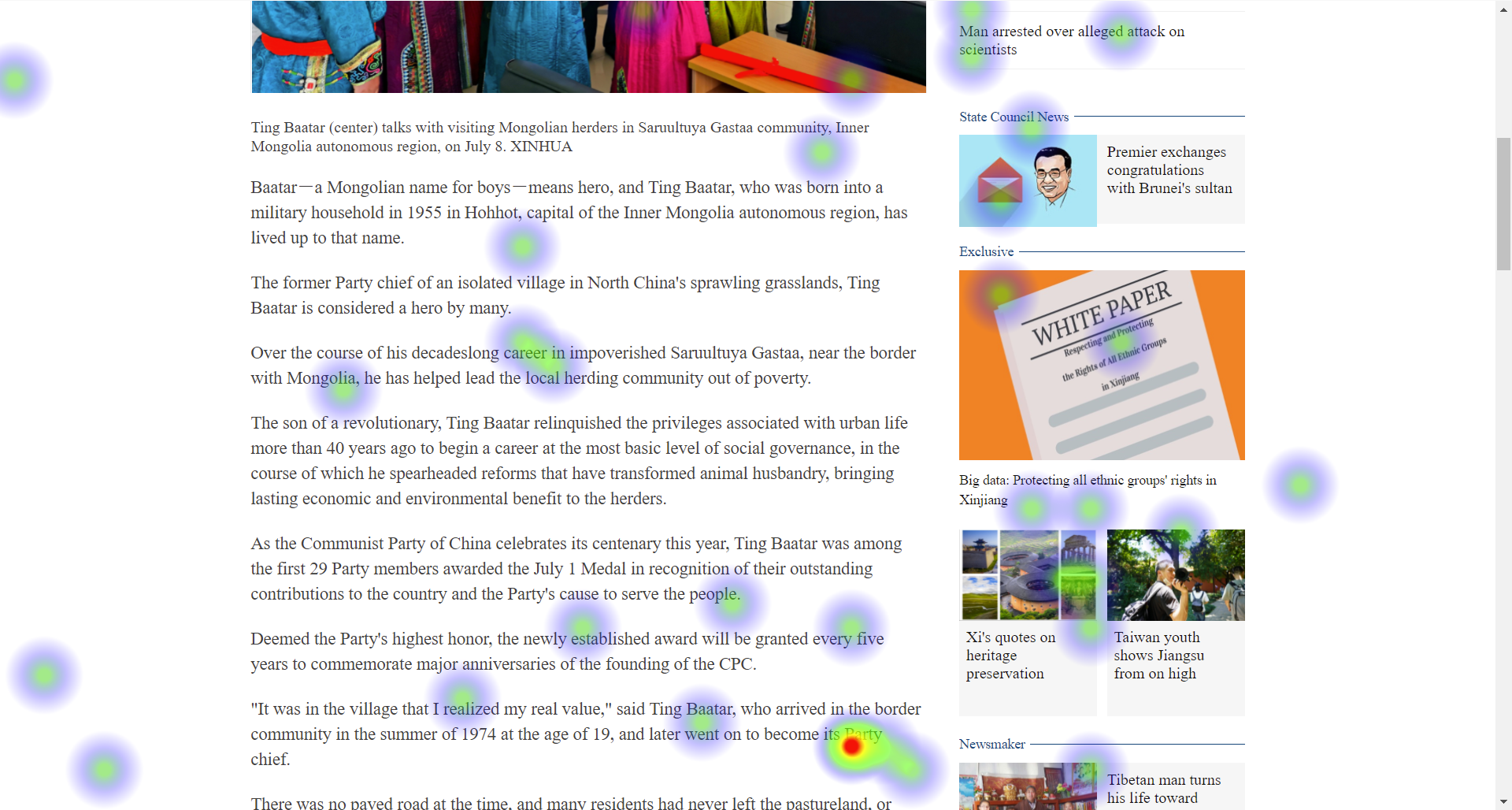
上图的每个点是用眼动仪实时采集你的目光坐标并将其展示在网页上,若你的目光停留时间久,则颜色会加深。这种情况就表示你现在正在专注的阅读这一个单词。这也表示你的注意力集中与这一个单词上。
那如何将注意力映射到机器学习上呢?我们可以采用NLP领域中很经典的Encoder-Decoder框架来解释。
Encoder-Decoder
在了解Encoder-Decoder框架之前,先需要总体了解一下NLP中对数据的常用处理思想,token化。
对于一段长长的句子,直接将其投入学习似乎不太现实,但若精确到每个汉字或者字母又会丢失语义,所以一般的操作就是对其进行token化。

比如上面两个句子,我讨厌你和I hate you,对其进行分词,就可以得到[我,讨厌,你]和[I,hate,you]这两个token序列,而token序列则正是NLP中最主要的输入输出方式。

上图就是传统的Encoder-Decoder框架。将Source序列投入到Encoder模块,产生了与之相对应的语义编码C,将C投入到Decoder模块中就可以按照公式yi=g(C,y1,y2,y3…yi-1)的方式依次产生Target序列,将Target序列结合后就能得到最终输出的语句。更换Source和Target序列则可以使Encoder-Decoder模块承担不同的学习任务。例如,Source序列是中文,而Target序列是英文,则该Encoder-Decoder框架承担的就是机器翻译的功能;若Source序列是大段的文章,而Target序列是精简的句子,则该Encoder-Decoder框架承担的就是段落语义概括的功能。通过更改Source和Target序列并不断微调其中的细节能够使该框架承担NLP领域中大部分的任务,但是传统的Encoder-Decoder框架是“分心”的。
在前文中我们提到了注意力的机制,将该机制抽象,则得到的想法就是能够聚焦于一点,而舍弃掉不重要的信息。而在传统的没有使用注意力机制的Encoder-Decoder框架中,所有的Source对于Target都是同等重要的,因为所有的Target生成时参照的都是同样的一个语义编码C,而有些时候,一些Target的生成并不需要全部的Source信息,所以就有了下图,即加入了注意力机制的Encoder-Decoder框架。
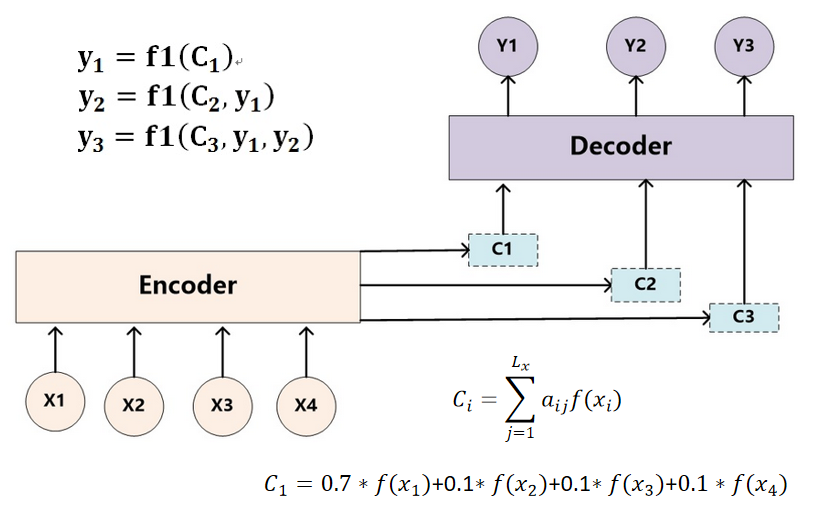
在图中可以看到,针对于不同的Target序列中的Yi,Encoder模块会生成不同的语义编码Ci用来实现针对性的输出(如上图中的y1,y2,y3的生成公式)。这一点正是体现了注意力机制的应用。值得一提的是,在Encoder-Decoder框架中使用的注意力机制称为软注意力机制,即加权求和(如C1的计算公式)的注意力,而非硬注意力机制(仅保留一个xi的影响)。
注意力机制的抽象表示
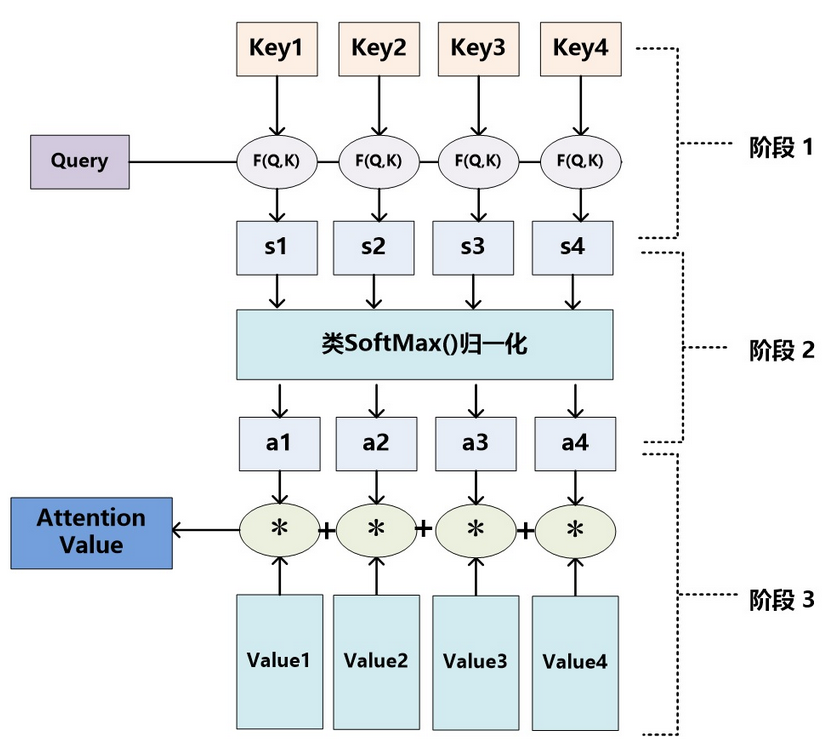
在上节中简单的介绍了注意力是如何嵌入到Encoder-Decoder模块中的,但是如果要广泛的推广,则需要对注意力机制进行进一步的抽象,而一般的抽象解释和抽象的使用方式就是Q-KV方法,即Query向量和Key-Value键值对。下图就是Q-KV方式的图解。Query向量与每一个Key值进行相似度的计算(一般是点积),随后对结果进行归一化,然后根据得到的每一个结果与Key对应Value值进行加权求和的操作,得到最终的注意力值。
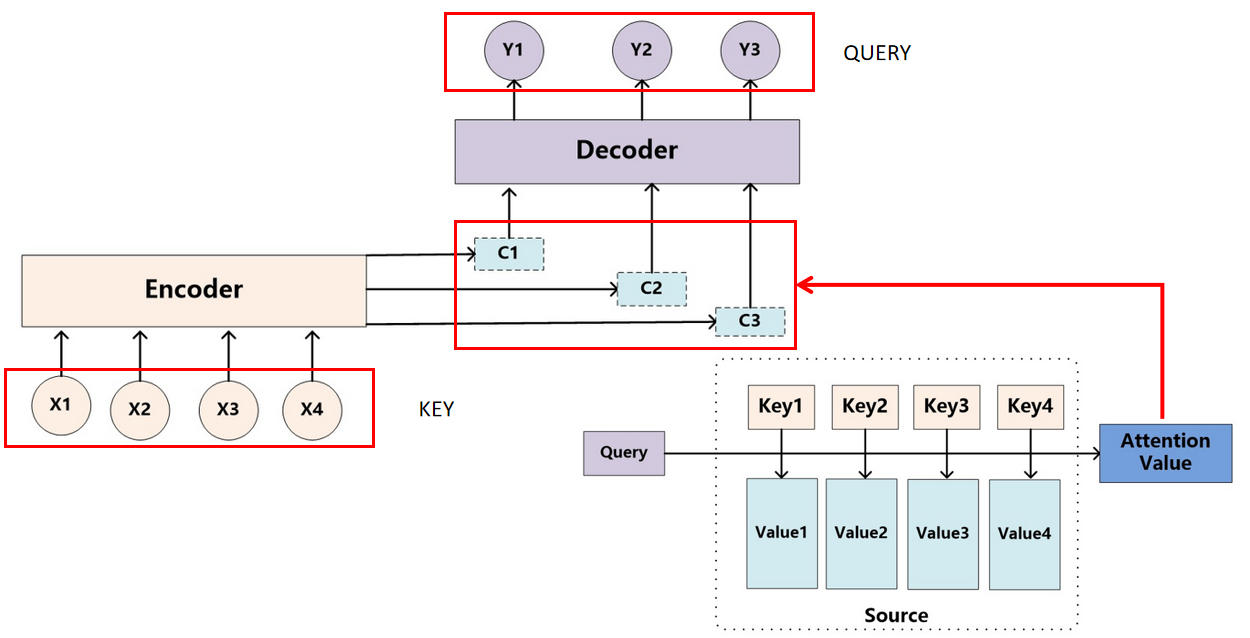
下图是Q-KV方法在Encoder-Decoder框架中的实例表示,Source序列表示Key序列,其有着固定的Value值,Target中的每一个Y都表示不同的Query向量,每一个Y与所有的X进行计算后得到语义编码C就是最终的注意力值。
自注意力机制
在实际的应用中,自注意力机制(Self Attention)也得到了广泛的应用。自注意力很好理解,一般的注意力机制就是Target序列对于Source序列的注意力,而在自注意力中,Target序列和Source序列是同一个序列,也就是自己对自己的注意力。自注意力机制能够更好地捕获远距离的依赖关系、更好地实现并行计算同时也能降低计算复杂度。而对于NLP领域来说,自注意力机制的直观意义就是能够帮助挖掘文本之间的语法联系。
而在其他领域,自注意力则有其他的含义,但主要的三点:捕获远距离依赖关系、并行计算、降低复杂度。都是共通的。
Transformer[5]
在《Attention Is All You Need》中,提出了Transformer结构,将注意力的强大的作用展现在大众眼前。下图是Transformer的完整结构示意图。
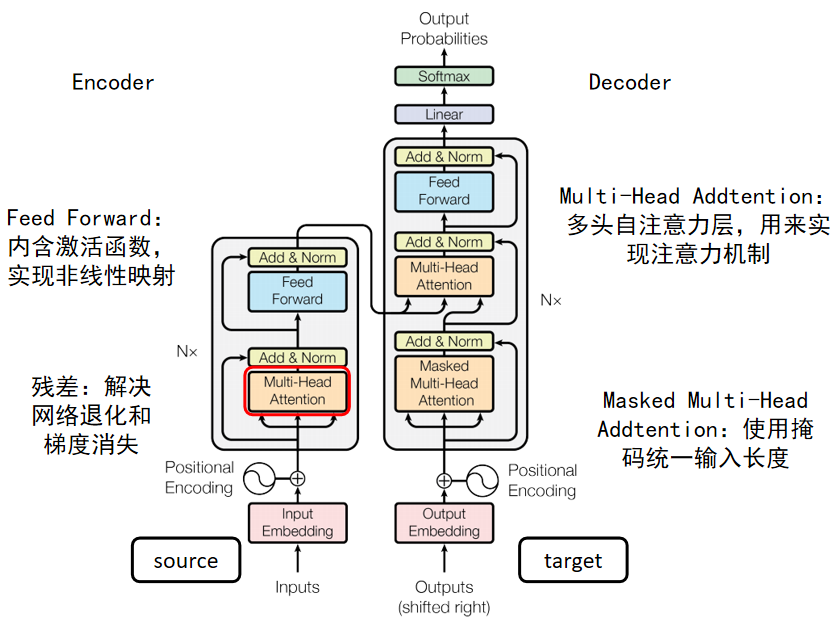
主要的模块都在上图中有所介绍,其结构也采用了Encoder-Decoder框架的模式,左侧为Encoder模块,右侧为Decoder模块。其余结构为一般神经网络中的模块,这里暂且不表。和注意力相关的主要就是Multi-Head Addtention模块,至于Masked Multi-Head Addtention只是加了一个掩码机制。
多头自注意力模块
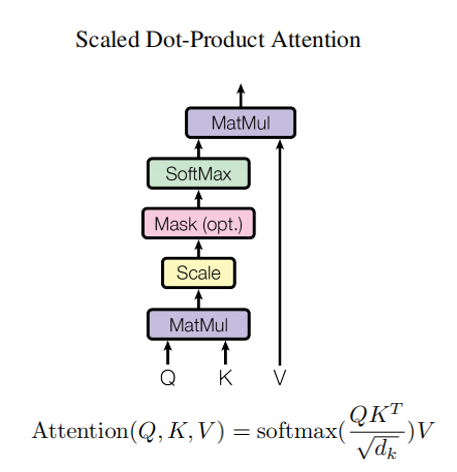
上图为单个注意力头,可以看到其注意力的计算方式就是经典的Q-KV方式,但是在进入softmax之前会除以一个根号dk,这是由于有时候由于其维度过大,导致经过softmax后梯度减少,所以通过根号dk用于平衡。
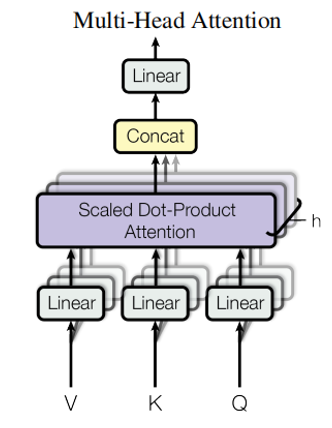
上图为多个单头注意力结合后产生的多头注意力模块。至于使用多头注意力,而不是一个大的单头注意力的原因为:将key,value,query线性的分开可以有更好的效果。且线性投影分开后再结合并不会提升维度复杂度。同时分开来还能并行地执行注意函数,加快运行速度。在文本方面也有特殊的含义,可以使每个单头注意力更好地聚焦于某一个方面例如:why、where、what等方面。
Vision Transformer
上面介绍了这么多,还是文本处理方面的模型,那么如何将Transformer应用到机器视觉领域呢?这就是Vision Transformer做出的重大改进了。
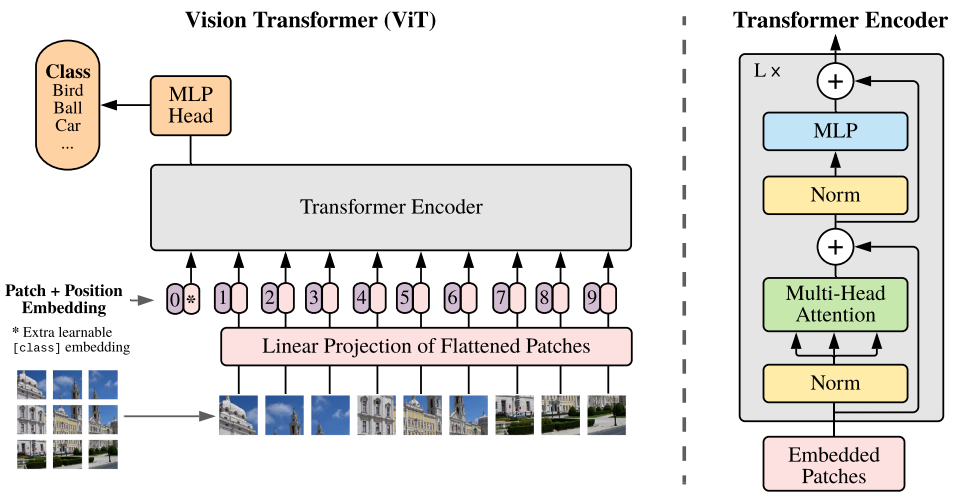
对于图片的处理,VIT采用了一个很巧妙的方法,用M×M的patch将一张图片均匀地分开,得到一连串的patch序列,而这就是Transformer在文本中对文字进行的token化的处理,VIT将图片处理成一个长长的patch序列,然后通过线性层对其进行展平,这样就可以作为一个Source序列投入到原本的Transformer模型中去了。同时,在图像分类的领域上并不需要重新生成图片,所以VIT将Transformer中的Decoder舍去,仅保留Encoder模块,将其产生的编码信息作为特征输入到多层感知网络中再进行分类。
当然之后的模型与原本的Transformer类似,且本文的重点并不是VIT,在这里不在赘述。在本节最后再讲一下VIT中的缺点。
诚然,VIT是一个极具创新的模型,将文本处理领域和机器视觉领域联系起来,但作为一个分支的先行者,必然有着缺陷等后人来改进,VIT的缺点如下:
1.视觉中像素的分辨率比文本段落中的文字高很多,如语义分割,需要在像素级上进行密集预测,因此self-attention在视觉任务中的计算复杂度高比NLP中高二次方的量级。
2.自然语言处理中的Transformer以单词的token为基本元素,scale规模是固定的,但是计算机视觉中的元素规模变化很大,比如目标检测任务中的不同大小目标的识别。在原本的CNN中可以通过下采样操作对不同的scale进行识别,但是VIT中并没有实现下采样步骤。
这些缺点就引出了下文,即《Swin Transformer: Hierarchical Vision Transformer using Shifted Windows》。
Swin Transformer
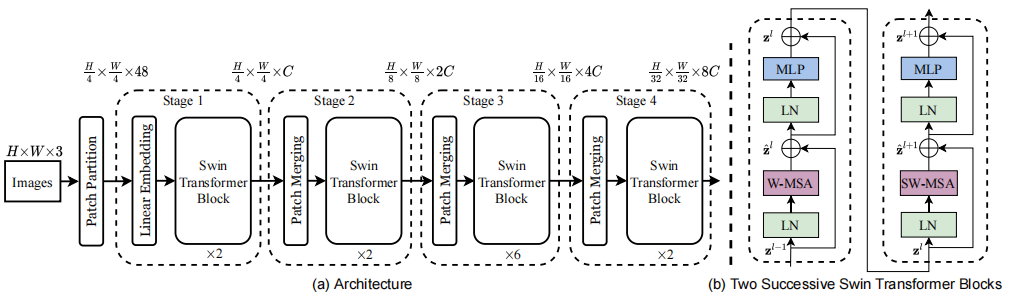
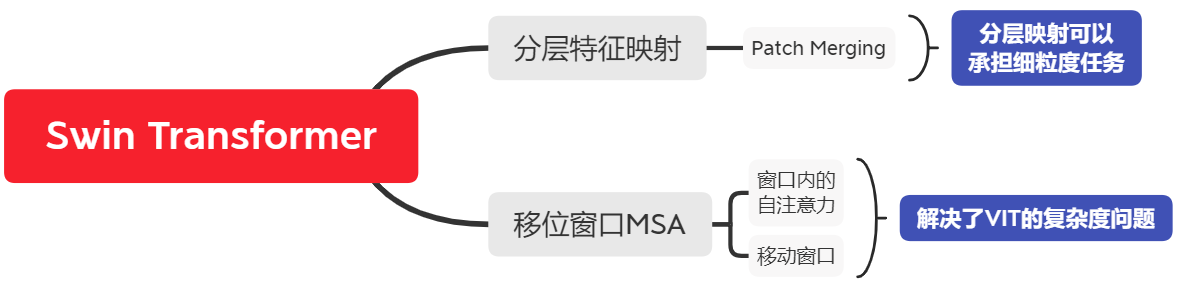
上图是Swin Transformer的结构总览图和我对Swin Transformer画的思维导图,可以很明显的看到,它的结构是类似于CNN的分层式结构,这就是它相对于VIT的一大改进,而另一大改进则是将多头自注意力模块换成了移动窗口自注意力模块。这两点在我的思维盗图中体现为分层特征映射和移位窗口MSA。这两点改进分别解决了VIT无法承担细粒度任务和复杂度过高的问题。而在骨架上,还是才用了VIT的结构骨架进行设计,对于输入图片数据的处理也是一样的patch化。
窗口级别的自注意力


以上两张动图[6]可以很直白的解释窗口级自注意力与传统全局自注意力的区别,同时也能直观地看到,窗口级别的自注意力计算在图像增大的过程中仅会线性增长,而传统的全局自注意力则会形成二次方复杂度的增加。而复杂度的详细计算则如下图[7]所示:
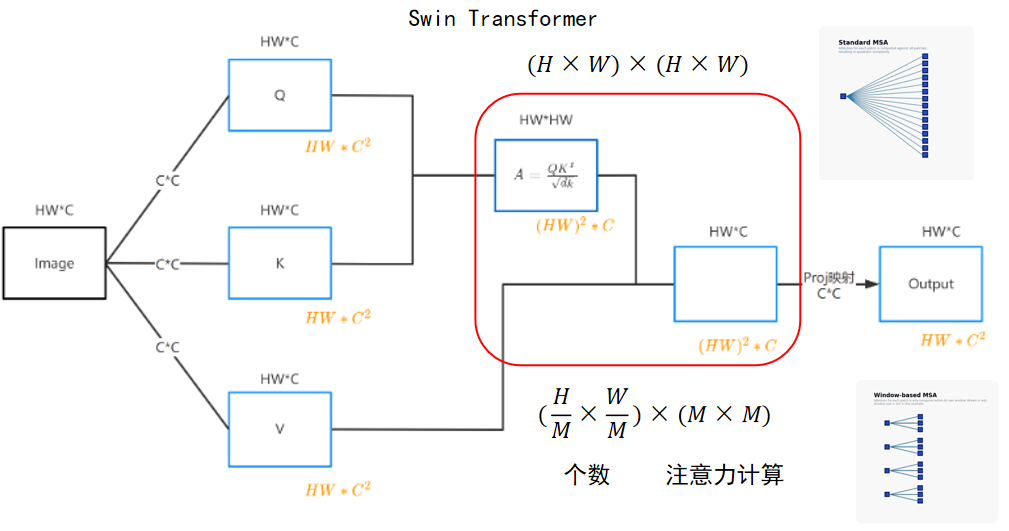
最右侧和最左侧的复杂度在全局和窗口级别的自注意力计算中都是相同的,不同的是中间的部分。在全局自注意力的计算中为2(hw)2C但是在窗口级别的自注意力的计算中则为2M2hwC。上图也给出了计算的方式,下图则展示了相同图像下的注意力计算之间的复杂度差别。

但是基于窗口的MSA有一个明显的缺点:将注意力限制在每个窗口,限制了网络的建模能力,尤其是位于窗口边界的信息,无法跨窗口进行信息地交互。为了解决这个问题,Swin Transformer在W-MSA模块之后使用了移位窗口MSA (SW-MSA)模块。这种移动窗口的方法引入了重要的窗口之间的交叉连接的信息,可以提高网络的性能。
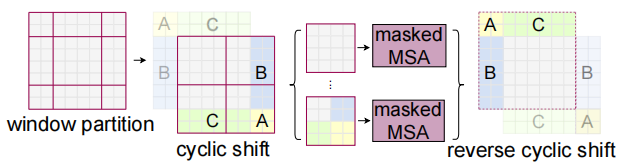
同时移动的方式也非简单的滑动窗口,而是在两个方向上同时移动半个窗口的距离,这样能够将前一部分缺失的边缘部分的信息尽可能地补全。同时Swin Transformer还采用跨窗口链接的方式,将窗口外的信息再转移到窗口内部,在不增加窗口的前提下获取更全面的信息,但是这种做法又会产生新的问题。
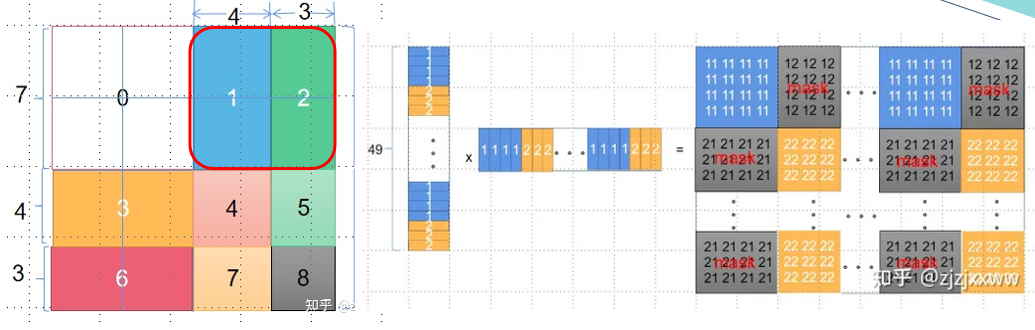
上图中蓝色的1部分和绿色的2部分原本并不是连续的,那么在做自注意力点乘的时候,1和2之间的点乘则会导致注意力中有错误的信息。而处理方法则如上图的右侧所示,其中蓝色和黄色部分是我们要留下的,灰色部分是不要的,需要mask掉,具体做法是加上一个维度一样的矩阵,其中蓝色和黄色部分设为0,灰色部分都设成-100,加完后蓝色和黄色不变,而灰色部分接近-100。这样灰色部分再进行softmax时候就几乎为0了。
而在使用窗口级别注意力的同时,他还加入了一个bias的设置,为了在窗口中也能感知到窗口之外的信息。其称之为相对位置偏置。文章中也通过实验,证明了引入相对位置偏置可以提高准确率。
Patch Merging
分层特征映射需要进行下采样的工作,在图像识别常用的下采样一般才用池化操作。而Swin-Transformer并没有使用池化操作,而是使用Patch Merging进行的下采样操作。

通过Patch Merging对图片进行下采样。H和W都会缩小一半。C会变成4倍。但是在前文的结构图中,在相邻两层之间的维度的上C仅仅变成两倍,个人推测可能是通过全连接层进行连接,能在保持信息传输的同时压缩维度。
总结
在《Swin Transformer: Hierarchical Vision Transformer using Shifted Windows》一文中,作者在VIT的基础上提出了Swin Transformer。该模型弥补了VIT的缺点:复杂度过高和无法进行细粒度的任务的缺陷。它可以产生一种分层的特征表示方法,并且对输入图像的大小具有线性的计算复杂度。Swin Transformer在COCO目标检测和ADE20K语义分割方面取得了最先进的性能,明显超过了以往的最佳方法。在视觉和语言信号的统一建模方面做出的努力。
而Swin Transformer作为注意力机制在机器视觉领域在2021年的重大创新,展现了Transformer模型的巨大潜力的同时也展现了视觉和语言信号处理方式统一的可能性。
文献引用
[1] Ashish Vaswani,Noam Shazeer,Niki Parmar,etc:Attention Is All You Need.[J/OL].arXiv preprint arXiv:1706.03762,2017.https://doi.org/10.48550/arXiv.1706.03762
[2] Alexey Dosovitskiy,Lucas Beyer,Alexander Kolesnikov,etc:AN IMAGE IS WORTH 16X16 WORDS:TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE.[J/OL].arXiv preprint arXiv:2010.11929,2021.https://arxiv.org/abs/2010.11929
[3] Z. Liu et al., "Swin Transformer: Hierarchical Vision Transformer using Shifted Windows," 2021 IEEE/CVF International Conference on Computer Vision (ICCV), 2021, pp. 9992-10002, doi: 10.1109/ICCV48922.2021.00986.
[4]深度学习中的注意力机制(2017版)[EB/OL].https://blog.csdn.net/malefactor/article/details/78767781
[5] Transformer论文详解——想不懂都难[EB/OL].https://zhuanlan.zhihu.com/p/434357918
[6] 使用动图深入解释微软的Swin Transformer[EB/OL].https://avoid.overfit.cn/post/50b62c574f364a62b53c4db363486f74
[7] Swin-Transformer中MSA和W-MSA模块计算复杂度推导[EB/OL]https://blog.csdn.net/qq_45588019/article/details/122599502
前面两篇文章我只找到arxiv的来源,若有引用不当,敬请谅解,同时Swin Transformer也可以在arxiv网站上找到,网址如下:https://arxiv.org/abs/2103.14030

 浙公网安备 33010602011771号
浙公网安备 33010602011771号