7.Spark SQL
1.请分析SparkSQL出现的原因,并简述SparkSQL的起源与发展。
SparkSQL的前身Shark对于Hive的太多依赖(如采用Hive的语法解析器、查询优化器等等),制约了Spark的One Stack Rule Them All的既定方针,制约了Spark各个组件的相互集成,所以提出了SparkSQL项目。
Spark SQL是Spark用来处理结构化数据的一个模块,它提供了一个叫作Data Frame的编程抽象结构数据模型(即带有Schema信息的RDD),Spark SQL作为分布式SQL查询引擎,让用户可以通过SQL、DataFrame API和Dataset API三种方式实现对结构化数据的处理。但无论是哪种API或者是编程语言,都是基于同样的执行引擎,因此可以在不同的API之间随意切换。
Spark SQL的前身是 Shark,Shark最初是美国加州大学伯克利分校的实验室开发的Spark生态系统的组件之一,它运行在Spark系统之上,Shark重用了Hive的工作机制,并直接继承了Hive的各个组件, Shark将SQL语句的转换从MapReduce作业替换成了Spark作业,虽然这样提高了计算效率,但由于 Shark过于依赖Hive,因此在版本迭代时很难添加新的优化策略,从而限制了Spak的发展,在2014年,伯克利实验室停止了对Shark的维护,转向Spark SQL的开发。
2. 简述RDD 和DataFrame的联系与区别?
Spark RDD
->RDD是一种弹性分布式数据集,是一种只读分区数据。它是spark的基础数据结构,具有内存计算能力、数据容错性以及数据不可修改特性。
Spark Dataframe
->Dataframe也是一种不可修改的分布式数据集合,它可以按列查询数据,类似于关系数据库里面的表结构。可以对数据指定数据模式(schema)。
共同点
->RDD、DataFrame、Dataset全都是spark平台下的分布式弹性数据集,在处理超大型数据提供便利。
->都会根据spark的内存情况自动缓存运算,这样即使数据量很大,也不担心会内存溢出。
->都有惰性机制,在进行创建、转换,如map方法时,不会立即执行,只有在遇到Action如foreach时,三者才会开始遍历运算,极端情况下,如果代码里面有创建、转换,但是后面没有在Action中使用对应的结果,在执行时会被直接跳过。
不同点
->RDD不支持sparkSQL操作。
->RDD总是搭配spark mlib使用。
->DataFrame每一行的类型固定为Row,只有通过解析才能获取各个字段的值。
->DataFrame总是搭配spark ml使用。
->DataFrame支持一些特别方便的保存方式,比如保存成csv,可以带上表头,这样每一列的字段名一目了然。
3.DataFrame的创建
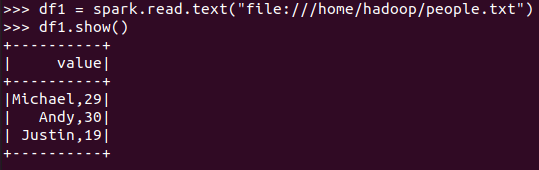
spark.read.text(url)
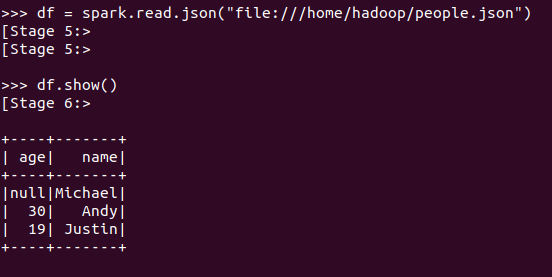
spark.read.json(url)
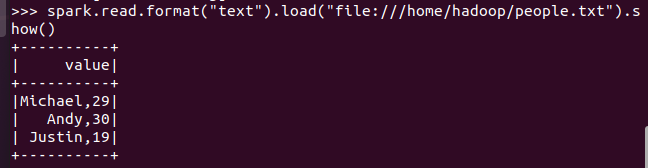
spark.read.format("text").load("people.txt")
spark.read.format("json").load("people.json")
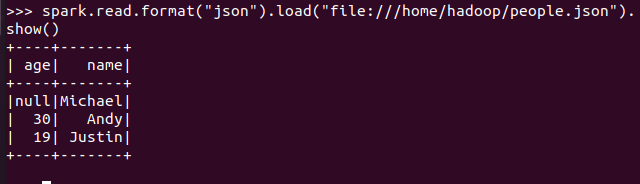
描述从不同文件类型生成DataFrame的区别。
DataFrame可以看作是分布式的Row对象的集合,在二维表数据集的每一列都带有名称和类型,这就是Schema元信息,这使得Spark框架可以获取更多的数据结构信息,从而对在DataFrame背后的数据源以及作用于DataFrame之上数据变换进行了针对性的优化,从而提升效率。
用相同的txt或json文件,同时创建RDD,比较RDD与DataFrame的区别。
RDD是分布式的Java对象的集合,虽然它以Person为类型参数,但是对象内部之间的结构相对于Spark框架本身是无法得知的,这样在转换数据形式时效率相对较低。
4. PySpark-DataFrame各种常用操作
基于df的操作:
打印数据 df.show()默认打印前20条数据
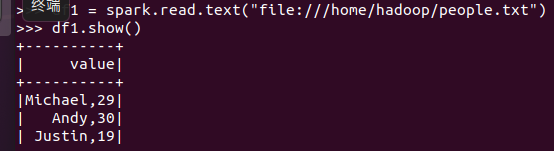
打印概要 df.printSchema()

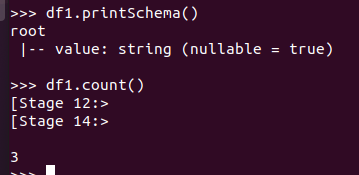
查询总行数 df.count()
df.head(3) #list类型,list中每个元素是Row类

输出全部行 df.collect() #list类型,list中每个元素是Row类

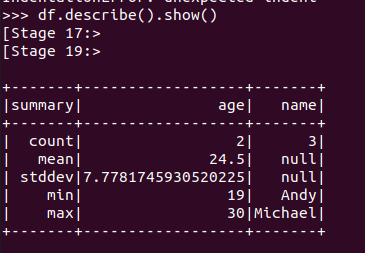
查询概况 df.describe().show()
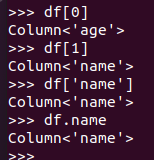
取列 df[‘name’], df.name, df[1]
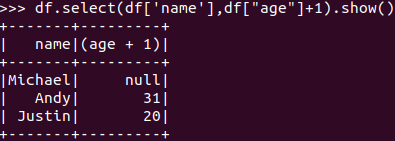
选择 df.select() 每个人的年龄+1
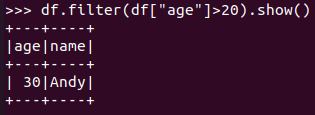
筛选 df.filter() 20岁以上的人员信息
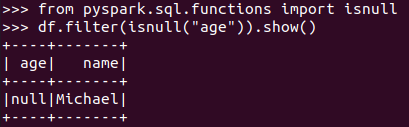
筛选年龄为空的人员信息
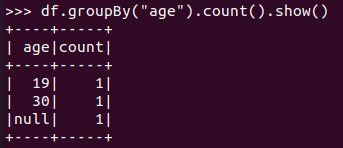
分组df.groupBy() 统计每个年龄的人数
排序df.sortBy() 按年龄进行排序
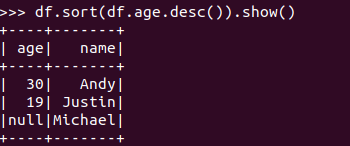
基于spark.sql的操作:
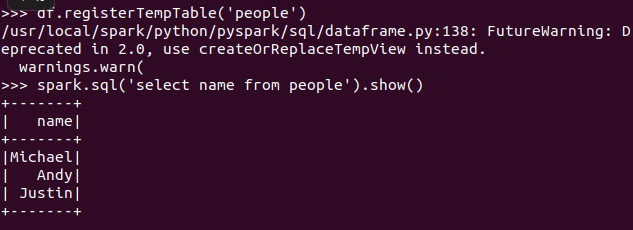
创建临时表虚拟表 df.registerTempTable('people')
spark.sql执行SQL语句 spark.sql('select name from people').show()
5. Pyspark中DataFrame与pandas中DataFram
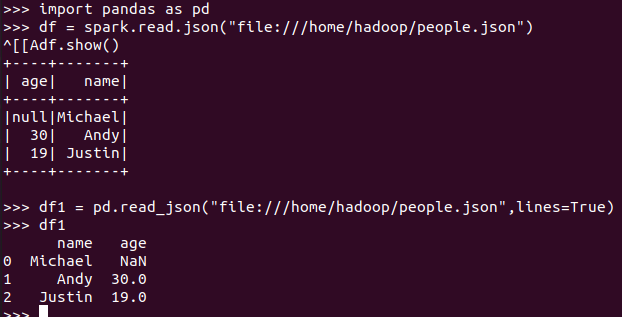
分别从文件创建DataFrame
pandas中DataFrame转换为Pyspark中DataFrame
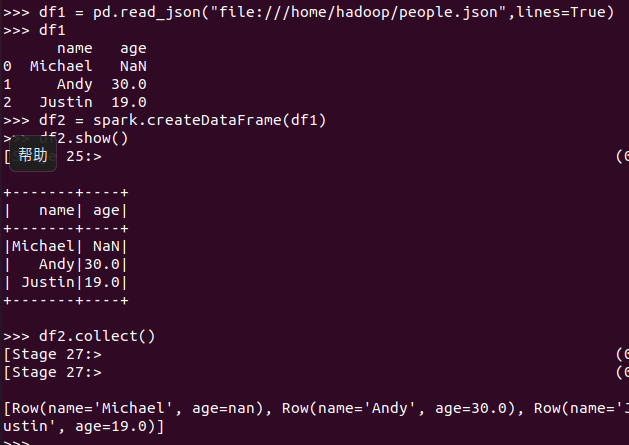
Pyspark中DataFrame转换为pandas中DataFrame
从创建与操作上,比较两者的异同
pandas中DataFrame创建出来的DataFrame有index索引,而Pyspark中DataFrame创建出来的没有。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号