
第二次结对编程作业
一、重现基线模型
我们选择的基线模型是CODEnn,其原理如下:
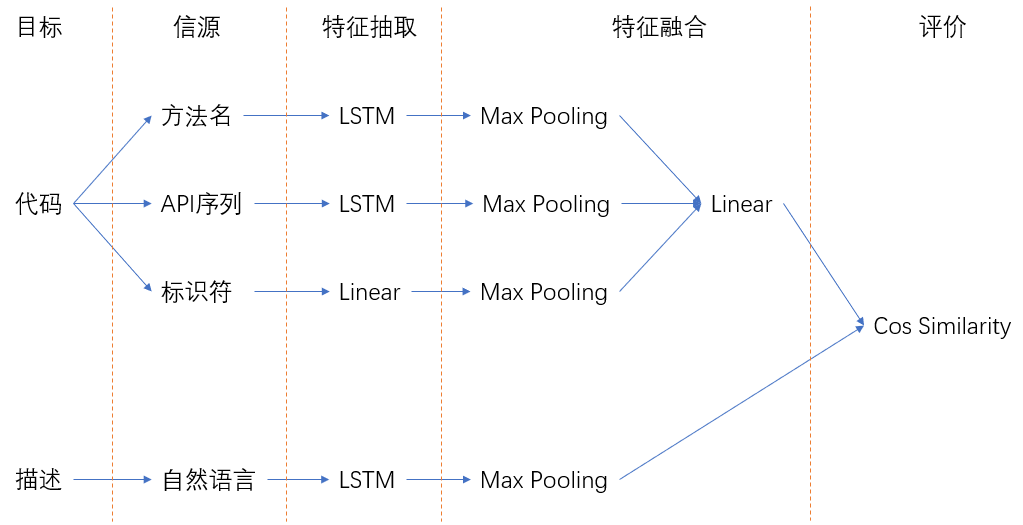
首先,目标是比较代码片段和问题描述之间的匹配程度。代码中,抽取的信息为方法名、API序列和标识符,问题描述就是自然语言。在抽取特征时,序列信息使用LSTM, 非序列信息使用MLP。抽取后,使用Max Pooling做融合,对于代码的三部分信息,再增加Linear层融合。最后。两个融合向量以余弦相似度度量匹配程度。
模型重现效果:
原论文中,R@1、5、10分别为0.46、0.76、0.86,但我们复现的结果为0.31、0.59、0.70,大概差了10个点。所以并没有完全复现原始效果。
模型优点:思路清晰,实现方法简单,效果也很明显。
模型缺点:局部设计感觉有些粗糙,比如Max Pooling感觉很奇怪。
二、模型改进
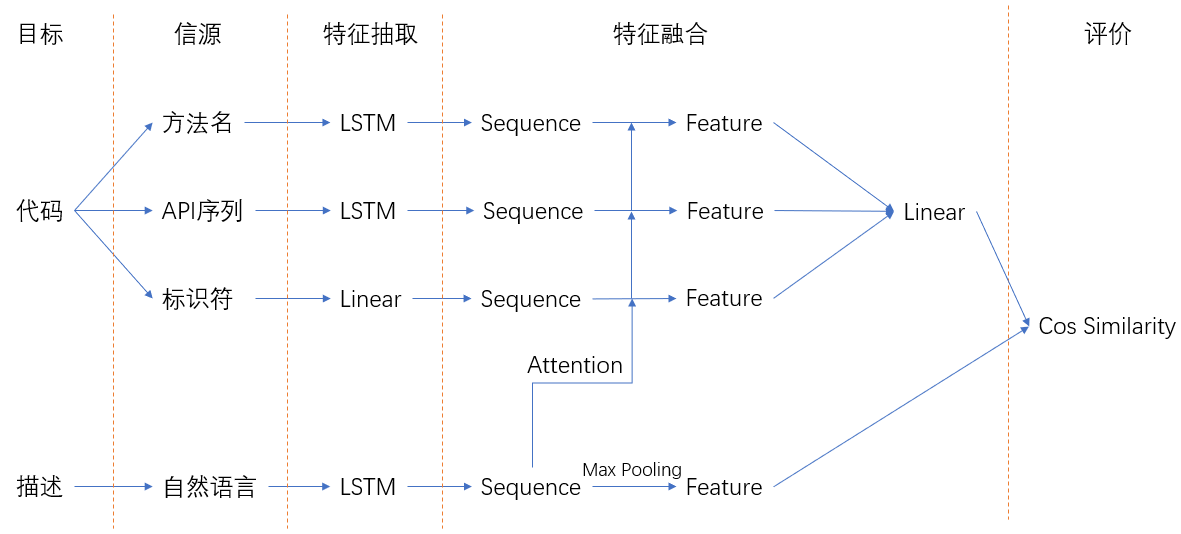
改进动机:Max Pooling感觉很奇怪。
新方法:做Max Pooling的目的是做局部融合,即把每个信源的特征融合成一个特征。不如考虑用一种加权的方式进行融合。所以,我们使用attention的方法求取权重,并把Max Pooling替换为加权求和,如下所示:
三、实现改进方法
结果十分差,可能这种方法行不通,也可能代码写的有问题,还没来得及寻找解决方案。感觉最大的问题在于,我们给代码的特征加了attention,但是描述却没有办法加,导致两部分特征缺乏可比性。
四、对小伙伴评价
我的小伙伴是林宇桐,他真的是一个十分靠谱的人,模型复现完全是他一个人做完的,在改进部分我也只参与了写代码,之后的调试也全部是他完成的。因为他的表现太好了,所以我觉得没办法三明治。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号