【Hadoop】MapReduce练习:分科目等级并按分区统计学生以及人数
需求
背景:学校的学生的是一个非常大的生成数据的集体,比如每次考试的成绩
现有一个班级的学生一个月的考试成绩数据。
科目 姓名 分数
需求:求出每门成绩中属于甲级的学生人数和总人数
乙级的学生人数和总人数
丙级的学生人数和总人数
甲级(90及以上)乙级(80到89)丙级(0到79)
处理数据结果:
甲级分区
课程\t甲级\t学生1,学生2,...\t总人数
乙级分区
课程\t乙级\t学生1,学生2,...\t总人数
丙级分区
课程\t丙级\t学生1,学生2,...\t总人数
文档格式
English,liudehua,80
English,lijing,79
English,nezha,85
English,jinzha,60
English,muzha,71
English,houzi,99
English,libai,88
English,hanxin,66
English,zhugeliang,95
Math,liudehua,74
Math,lijing,72
Math,nezha,95
Math,jinzha,61
Math,muzha,37
Math,houzi,37
Math,libai,84
Math,hanxin,89
Math,zhugeliang,93
Computer,liudehua,54
Computer,lijing,73
Computer,nezha,86
Computer,jinzha,96
Computer,muzha,76
Computer,houzi,92
Computer,libai,73
Computer,hanxin,82
Computer,zhugeliang,100
代码示例
StuDriver
import org.apache.hadoop.io.Text;
import stuScore.JobUtils;
public class StuDriver {
public static void main(String[] args) {
String[] paths = {"F:/stu_score.txt", "F:/output"};
JobUtils.commit(paths, true, 3, false, StuDriver.class,
StuMapper.class, Text.class, Text.class, null, StuPartitioner.class, StuReduce.class,
Text.class, Text.class);
}
}
JobUtils
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.File;
import java.io.IOException;
public class JobUtils {
private static Configuration conf;
static {
conf = new Configuration();
}
/**
* 提交job
*
* @param paths 输入输出路径数组
* @param isPartition 是否包含自定义分区类
* @param reduceNumber reduce数量(若自定义分区为true,则此项必须>=自定义分区数)
* @param isGroup 是否分组
* @param params 可变参数
*/
public static void commit(String[] paths, boolean isPartition, int reduceNumber, boolean isGroup, Class... params) {
try {
Job job = Job.getInstance(conf);
job.setJarByClass(params[0]);
job.setMapperClass(params[1]);
job.setMapOutputKeyClass(params[2]);
job.setMapOutputValueClass(params[3]);
if(isGroup) {
job.setGroupingComparatorClass(params[4]);
}
if (isPartition) {
job.setPartitionerClass(params[5]);//设置自定义分区;
}
if (reduceNumber > 0) {
job.setNumReduceTasks(reduceNumber);
job.setReducerClass(params[6]);
job.setOutputKeyClass(params[7]);
job.setOutputValueClass(params[8]);
} else {
job.setNumReduceTasks(0);
}
FileInputFormat.setInputPaths(job, new Path(paths[0]));
FileOutputFormat.setOutputPath(job, new Path(paths[1]));
job.waitForCompletion(true);
} catch (InterruptedException | ClassNotFoundException | IOException e) {
e.printStackTrace();
}
}
}
StuMapper
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class StuMapper extends Mapper<LongWritable, Text, Text, Text> {
Text k = new Text();
Text v = new Text();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] splits = line.split(",");
int score = Integer.parseInt(splits[2]);
String level;
if (score >= 90) {
level = "甲级";
} else if (score < 90 && score >= 80) {
level = "乙级";
} else {
level = "丙级";
}
k.set(splits[0] + "\t" + level);
v.set(splits[1]);
context.write(k, v);
}
}
StuReduce
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class StuReduce extends Reducer<Text,Text,Text, Text> {
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
StringBuilder builder = new StringBuilder();
int count =0;
for (Text v : values) {
builder.append(v+",");
count++;
}
builder.replace(builder.length()-1,builder.length(),"\t");
builder.append(count);
context.write(key,new Text(builder.toString()));
}
}
StuPartitioner
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
public class StuPartitioner extends Partitioner<Text, Text> {
@Override
public int getPartition(Text text, Text text2, int i) {
String line = text.toString();
if(line.contains("甲级")){
return 0;
}else if(line.contains("乙级")){
return 1;
}else{
return 2;
}
}
}
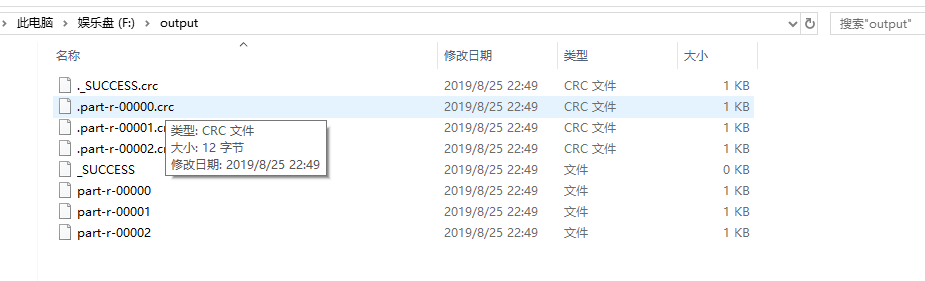
输出结果



作者:ShadowFiend
出处:http://www.cnblogs.com/ShadowFiend/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。如有问题或建议,请多多赐教,非常感谢。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号