基于知识图谱的问答系统
实践
知识图谱的构建
参考链接
这里我们建立了一个简单的金融领域的知识图谱,建立的过程步骤如下:
网页信息到可导入neo4j的csv文件
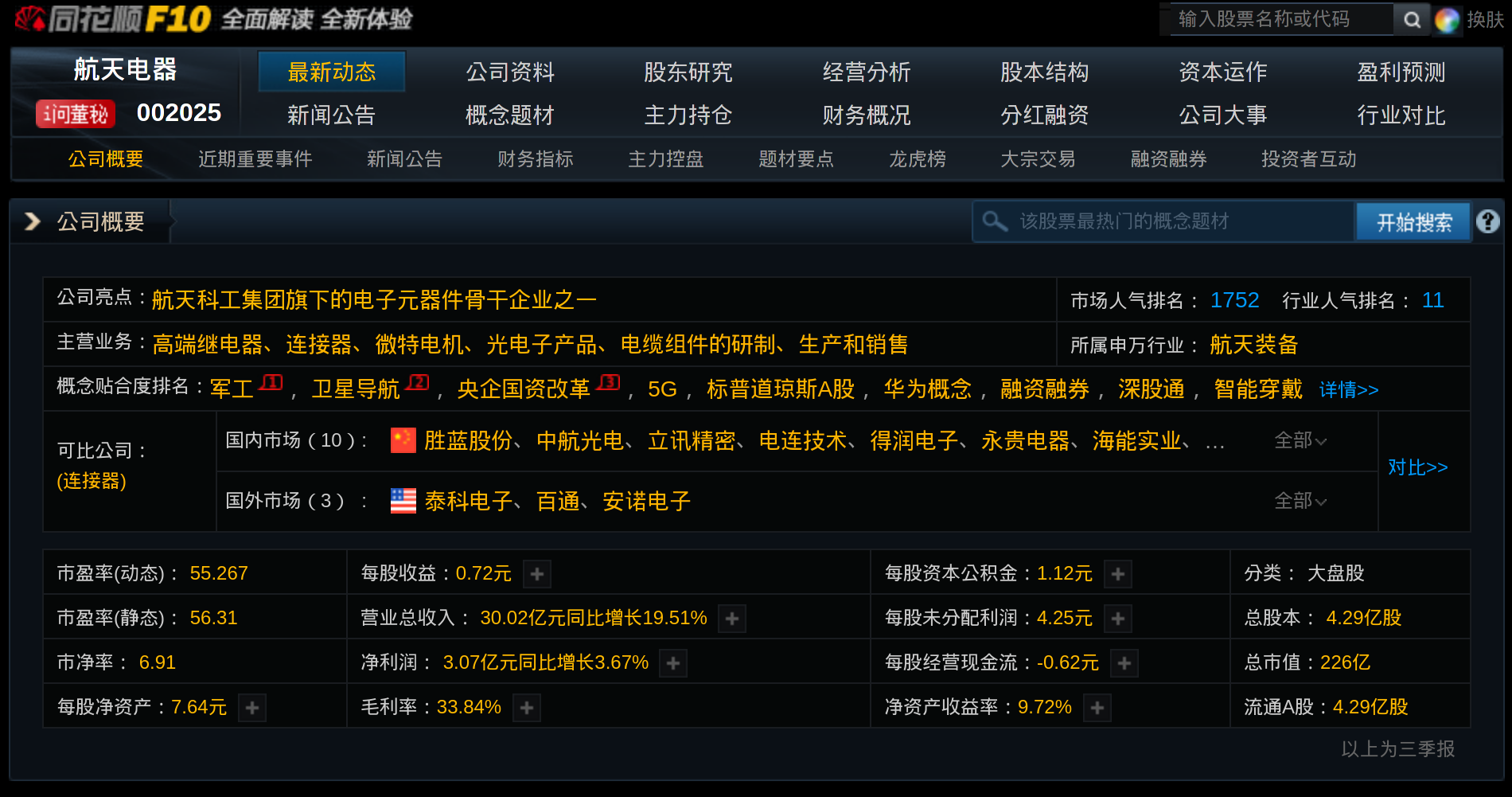
我们选择了金融网站同花顺F10, 该网站记录了上市公司的各种信息,如图所示:
通过网络爬虫我们得到了三个可导入neo4j的csv文件,分别为:
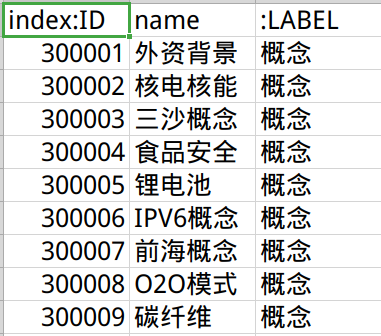
概念结点文件concept.csv
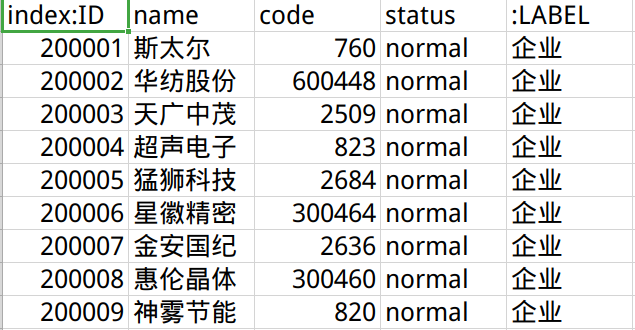
企业结点文件stock.csv
高管结点文件executive.csv
行业结点文件industry.csv

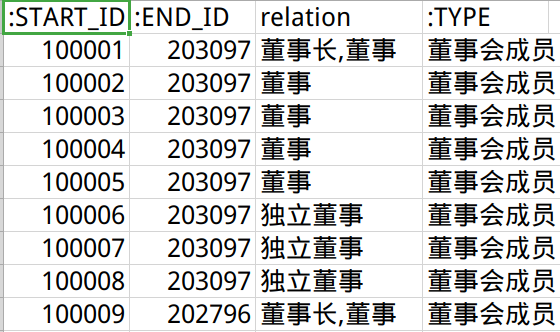
高管—企业关系文件executive_stock.csv
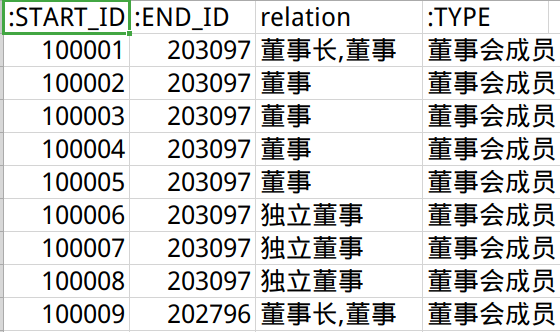
企业-概念关系文件stock_concept.csv
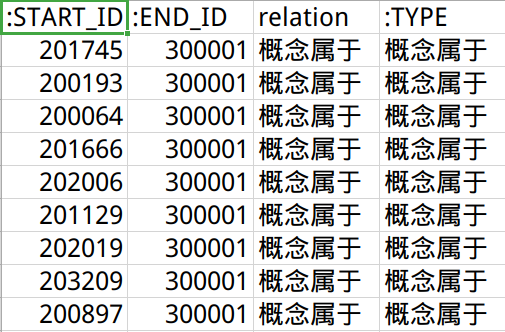
企业-行业关系文件stock-industry.csv

可导入neo4j的csv文件到neo4j知识图谱
(1)首先将得到的csv文件统一放入neo4j的安装目录下的import目录

(2)然后命令行进入neo4j安装目录下的bin目录,输入命令neo4j-admin import --mode=csv --database=mygraph2.db --nodes ../import/concept.csv --nodes ../import/executive.csv --nodes ../import/industry.csv --nodes ../import/stock.csv --relationships ../import/executive_stock.csv --relationships ../import/stock_concept.csv --relationships ../import/stock_industry.csv就可以将csv文件转换为知识图谱,得到的知识图谱如图所示:

建立问答系统
问答系统的整体结构图如下所示:
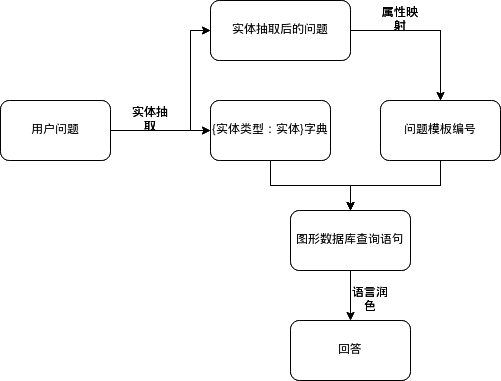
解释:用户问题先进行实体抽取来得到抽取后的问题和实体类型:实体字典,抽取后的问题通过属性映射得到问题模板(编号),然后用实体类型:实体字典和问题模板(编号)来得到图形数据库相应的查询语言,最后将查询到结果进行语言的上的润色得到相应的答案。
下面对每一个步骤做更具体的描述
用户问题清洗
用户的输入的问题总是会有很多的"杂质",比如一些不必要的标点符号等等,会影响后面的处理,所以我们需要进行清洗得到干净的问题。
例如:用户输入的问题“华为,是什么?”清洗后得到“华为是什么”
实体抽取
实体抽取采用jieba自定义词典再分词的方法。
(1)对于建立的金融数据库,其关键实体一般为高管、企业、概念、行业,于是将前面得到的可导入的csv文件中的所有的高管、企业、概念、行业抽取出来,分别给予ne、ns、nc、ni词性, 最后得到自定义词典mydict.txt,内容如下
余劲 15 ne
周学军 15 ne
艾华集团 15 ns
亿帆医药 15 ns
IPV6概念 15 nc
前海概念 15 nc
印刷包装 15 ni
家电行业 15 ni
...
使用jieba.load_usrdict(mydict_txt)的方法将自定义词典导入jieba分词中
(2)使用jieba分词工具的词性标注方法得到实体类型:实体字典和实体抽取后的问题
若问题中有上面自定义词典中的实体,就会被词性标记为ne、ns、nc或ni,我们将该词性和对应的实体存入字典中,再将原先的问题中的抽出的关键实体用词性替换,得到抽取后的问题序列。下面举一个具体的例子。
问题“华为是什么”会被jieba分词标注为[('华为', 'ns'), ('是', 'v'), ('什么', 'r')], 进而我们得到字典{'ns', 华为} 和 实体抽取后问题 “nr 是 什么”
属性映射
接下来需要将实体抽取后的问题映射到具体的问题模板(编号),我们采用分类的方法。
(1)首先建立训练集, X_train是问题,y_train是对应的模板编号
'''
问题模板编号-问题模板
0:企业的介绍
1:高管的介绍
...
'''
X_train = ["ne 是 什么", "ne 的 介绍", "ne 的 个人信息", "ns 是 什么", "ns 怎么样"...]
y_train = [1, 1, 1, 0, 0...]
(2)接下来对X_train中的每一个数据进行文本特征的提取,我们使用了sklearn中的tfidvectorizer文本特征处理器,举例:
“ne 是 什么” 通过文本特征提取会得到 [0.70710678 0.70710678]
(3)将特征提取后的X_train, y_train输入分类器中进行训练得到问题-问题模板编号分类器, 这里我们使用贝叶斯分类器来进行分类
查询语句cql
前面我们得到了问题模板编号和实体类型:实体字典,下面就可以用它们来得到相应的查询语句cql。
比如,前面我们得到了问题模板编号0和{'ns':华为字典}, 进而可以得到如下查询语句
match (p:企业) where p.name='华为' return p.code
...
语言润色
最终将查询到结果进行整合、润色就可以得到答案
最后用一张实例图来总结上面的流程
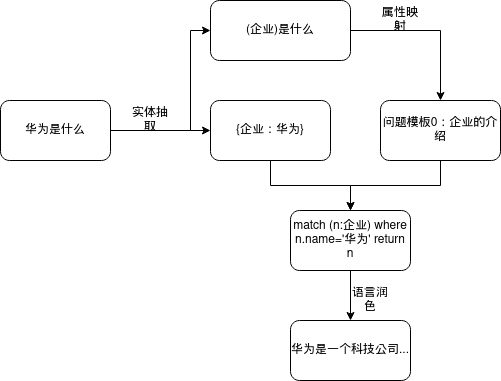
效果展示
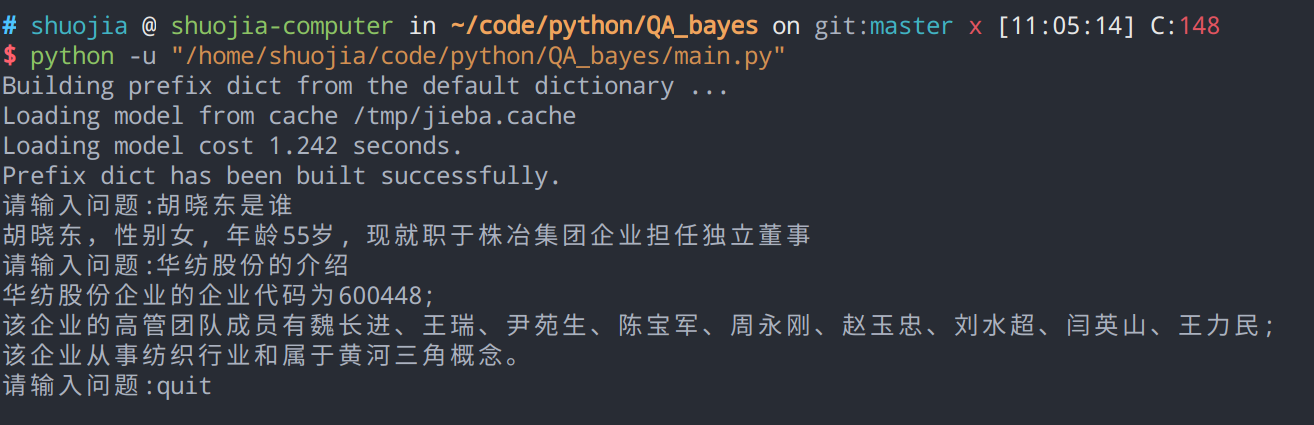
不足和改进
由于时间关系,暂时没有时间对这个系统进行改进,所以先将该系统的不足和改进放在这里
(1)
不足:实体抽取缺少灵活性,我们采用的jieba词性标注来抽取实体的方法,一个前提就是问题的关键实体必须在自定义的词典中并且要一模一样,然而很多不同名称的实体其实指向同一个实体,我们却将他们看做不同的实体
改进:使用实体链接的方法将不同名称的实体映射到同一个实体,我想能不能进行词的相似度计算,在自定义词典中找到最相近的词作为实体。在网上了解到BERT+CRF的命名实体识别的效果比较好
(2)
不足:图形数据库的建立的比较简单
改进:使用一些好的技术来建立更大更复杂的知识图谱
(3)
不足:该系统进行属性映射的方式,我们需要手动建立训练集来进行分类,当问题变得复杂,这项工作将变得费时费力,同时问题的回答范围由自己建立的问题模板的数量决定,具有一定的局限性。
改进:从网络上了解到可以通过实体得到一个子图,然后再子图中寻找与问题最匹配的答案(进行相似度计算)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号