python学习记录
jieba
分词
'''
函数 jieba.cut(sentence, cut_all=False)
参数 sentence为待分词的字符串 cut_all为是否为全模式
返回指 生成器
'''
import jieba
sentence = "我考上了清华大学"
seg_list = jieba.cut(sentence, cut_all=True)
print('[全模式]:' + '/'.join(seg_list))
seg_list = jieba.cut(sentence, cut_all=False)
print('[精确模式]:' + '/'.join(seg_list))
'''
函数 jieba.lcut(sentence, cut_all=False)
参数 sentence为待分词的字符串,cut_all为是否使用全模式
返回值 列表
'''
import jieba
sentence = "我考上了清华大学"
seg_list = jieba.lcut(sentence, cut_all=True)
print('[全模式]:' + '/'.join(seg_list))
seg_list = jieba.lcut(sentence, cut_all=False)
print('[精确模式]:' + '/'.join(seg_list))

词性标注
'''
函数 jieba.posseg.cut(sentence)
参数 setence待分词的字符串
返回值 生成器
同理cut前面加上l返回列表
'''
import jieba.posseg
sentence = '我是中国人'
for w, p in jieba.posseg.cut(sentence):
print(w, p)

添加字典
'''
函数 jieba.load_userdict(path)
参数 path添加字典路径
'''
import jieba
jieba.load_userdict('mydict.txt')
装饰器
正则表达式
列表
list.extend(seq)
参数: seq -- 列表
返回值: 无
功能: 将seq中的元素添加到list的末尾
例子:
代码:
aList = ['a', 'b', 'c']
bList = ['d', 'e', 'f']
aList.extend(bList)
print("添加后的列表={}".format(aList))
print(aList)
执行结果
添加后的列表=['a', 'b', 'c', 'd', 'e', 'f']
['a', 'b', 'c', 'd', 'e', 'f']
在python中使用neo4j知识图谱
neo4j知识图谱的基本概念
一个知识图谱可通常由3部分组成:结点Node、关系Relationship、属性Property
结点Node:

结点用一个圆圈表示,结点具有属性,属性存储着结点的数据; 结点拥有标签Label(在图中通常用颜色表示),使得结点属于某一个或几个群体,就像我这个人有学生标签、男性标签等等
关系Relationship:
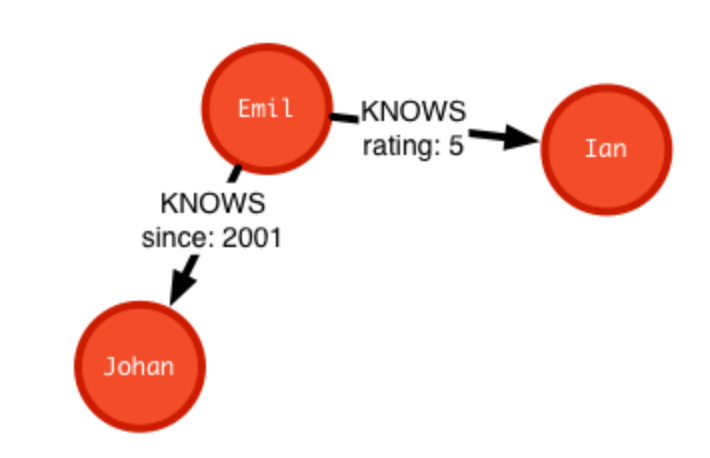
关系是结点与结点之间的联系,不如两个代表人的结点有着认识的关系;关系可以拥有属性,用来对关系对进一步详细的刻画,比如具体在什么时间认识; 关系拥有标签,来区别不同种类的关系
属性Property:
属性有(属性名:属性值)构成,用来描述结点和关系的信息。
neo4j知识图谱的建立
通过Create语句创建
创建结点
//一般形式
Create (结点变量:标签(属性...))
//具体例子
Create (Mark:Person(name:'Mark', hobby:'play the guitar'))
创建关系
//一般形式
Create (结点变量)-[:标签(属性...)]->(结点变量)
//具体例子
Create (Mark)-[:Know(since:2020)]->(John)
LOAD CSV的方法
我们知道一个关系数据由若干个数据表组成,而csv文件是存储数据表的一种文件形式。
图形数据库的适用范围包含关系数据库,所以关系数据库可以很容易转换为图形数据库。
关系数据库和图形的数据库的对应关系为:
数据表:表名~一个标签,每一条记录~每一个结点,属性~结点的属性。可以说,一个数据表就是一组拥有相同标签的结点群。
数据表与数据表:外键~结点群之间的关系
举个例子
有如下的关系数据库:

转化为图形数据库的步骤为:
(1)数据表转换为结点群
//对于products表
LOAD CSV WITH HEADERS FROM "http://data.neo4j.com/northwind/products.csv" AS row
CREATE (n:Product)
SET n = row,
n.unitPrice = toFloat(row.unitPrice),
n.unitsInStock = toInteger(row.unitsInStock), n.unitsOnOrder = toInteger(row.unitsOnOrder),
n.reorderLevel = toInteger(row.reorderLevel), n.discontinued = (row.discontinued <> "0")
//对于categories表
LOAD CSV WITH HEADERS FROM "http://data.neo4j.com/northwind/categories.csv" AS row
CREATE (n:Category)
SET n = row
//对于suppliers表
LOAD CSV WITH HEADERS FROM "http://data.neo4j.com/northwind/suppliers.csv" AS row
CREATE (n:Supplier)
SET n = row
(2)创建索引(提升第三步的速度)
Create Index On :Product(ProductID)
Create Index on :Category(CategoryID)
Create Index on :Supplier(SupplierID)
(3)将外键转换为关系
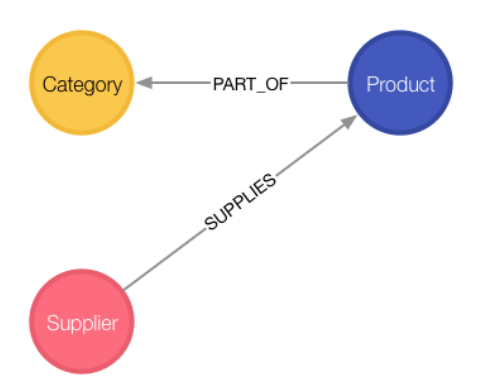
//Products的外键CategoryID
Match (p:Product), (c:Category)
Where p.CategoryID = c.CategoryID
Create (p)-[:Part_of]->(c)
//Products的外键SupplierID
Match (p:Product), (s:Supplier)
Where p.SupplierID = s.SupplierID
Create (s)-[Supplie]->(p)
注意:一个数据表也可以转换为一个关系,条件:该表拥有两个表的关系
neo4j知识图谱的删除
//删除整个知识图谱
Match (n) Detach Delete n
//确认删除成功与否
Match (n) return n
neo4j的查询语句
Match ()...
Where ...
操作
举例:返回喜欢打篮球的人
Match (n:Person)
Where n.hobby = 'play basketball'
return n
neo4j在python中的使用
首先在python中要安装好py2neo
pip install py2neo
然后在程序中导入库
from py2neo import Graph
接着建立Graph对象(这是链接neo4j数据库的过程)
graph = Graph(address, username, password)
最后就可以使用CQL语句来查询
graph.run(CQL)
注意:run函数返回的是Cursor对象,我们可以更具需求进行格式转换
graph.run().data() # a list of dictionary
graph.run().to_data_frame() # pd.DataFrame
graph.run().to_ndarray() # numpy.ndarray
graph.run().to_subgraph()
graph.run().to_table()
下面举个例子
假设建好了一个图形数据库,两个结点——(n:Person{name='小明'})和(n:Person{name='小红'})
from py2neo import Graph
#创建Graph对象——链接neo4j数据库
graph = Graph('http://localhost:7474', username='neo4j', password='neo4j')
#执行CQL语句
result = graph.run('match (n:Person) return n').data()
print(result)

文本文件读取
基本形式为
with open(文件名, 打开方式) as f:
读写操作
打开方式可为:读文本文件方式'rt' 写文本文件方式'wt'
读写操作
read()读取全部字符串并返回
readline()读取一行字符串并返回
write(str)写入字符串
numpy的读写
通过save和load函数可实现numpy对象读写。注意文件的后缀必须为.npy。下面举例
import numpy as np
if __name__ == "__main__":
# numpy的读写
a = np.ones([2, 2])
np.save('test.npy', a)
b = np.load('test.npy')
print(b)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号