

有一种算法叫做“Union-Find”?
前言:
不少搞IT的朋友听到“算法”时总是觉得它太难,太高大上了。今天,跟大伙儿分享一个比较俗气,但是却非常高效实用的算法,如标题所示Union-Find,是研究关于动态连通性的问题。不保证我能清晰的表述并解释这个算法,也不保证你可以领会这个算法的绝妙之处。但是,只要跟着思路一步一步来,相信你一定可以理解它,并像我一样享受它。
-----------------------------------------
为了便于引入算法,下面我们假设一个场景:
假设现在有A,B两人素不相识,但A通过熟人甲,甲通过熟人乙,乙通过熟人丙,丙通过熟人丁,而丁又刚好与B是熟人。就这样,A通过一层一层的人际关系最后认识了B。
基于以上介绍的“关系网”,现在给出一道思考题:13亿中国人当中一共有几个“关系网”呢?
------------------------------------------
1.Union-Find初探
是的,想到1,300,000,000这个数字,或许此刻你大脑已经懵了。那好,我们就先从小数据分析:
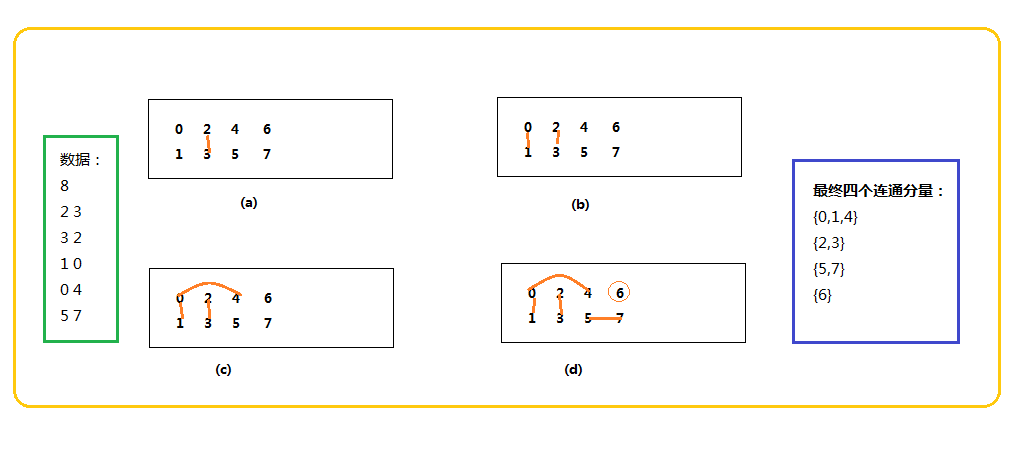
图1
从上图中,其实很好理解。初始每个人都是单独的一个“点”,用科学语言,我们把它描述为“连通分量”。随着一个一个关系的确立,即点与点之间的连接,每连接一次,总连通分量数即减1(理解算法的关键点之一)。最后的“关系网”几乎可以很轻易地数出来。所以,只要你把所有国人两两之间的联系给出,然后不断连线,连线,...,最后再统计一下不就完事儿了麽~
问题是:怎么存储点的信息?点与点怎么连,怎么判断该不该连?
因此,我们需要维护2个变量,其中一个变量count表示实时的连通分量数,另一个变量可以用来存储具体每一个点所属的连通分量。因为不需要存储复杂的信息。这里我们选常用的数组 id[N] 存储即可。然后,我们需要2个函数find(int x)和union(int p,int q)。前者返回点“x”所属于的连通分量,后者将p,q两点进行连接。注意,所谓的连接,其实可以简单的将p的连通分量值赋予q或者将q的连通分量值赋予p,即:
id[p]=q 或者id[q]=p。
有了上面的分析,我们就可以牛刀小试了。且看Java代码实现第一版。
Code:
1 package com.gdufe.unionfind; 2 3 import java.io.File; 4 import java.util.Scanner; 5 6 public class UF { 7 8 int count; //连通分量数 9 int[] id; //每个数所属的连通分量 10 11 public UF(int N) { //初始化时,N个点有N个分量 12 count = N; 13 id = new int[N]; 14 for (int i = 0; i < N; i++) 15 id[i] = i; 16 } 17 //返回连通分量数 18 public int getCount(){ 19 return count; 20 } 21 //查找x所属的连通分量 22 public int find(int x){ 23 return id[x]; 24 } 25 //连接p,q(将q的分量改为p所在的分量) 26 public void union(int p,int q){ 27 int pID=find(p); 28 int qID=find(q); 29 for(int i=0;i<id.length;i++){ 30 if(find(i)==pID){ 31 id[i]=qID; 32 } 33 } 34 count--; //记得每进行一次连接,分量数减“1” 35 } 36 //判断p,q是否连接,即是否属于同一个分量 37 public boolean connected(int p,int q){ 38 return find(p)==find(q); 39 } 40 41 public static void main(String[] args) throws Exception { 42 43 //数据从外部文件读入,“data.txt”放在项目的根目录下 44 Scanner input = new Scanner(new File("data.txt")); 45 int N=input.nextInt(); 46 UF uf = new UF(N); 47 while(input.hasNext()){ 48 int p=input.nextInt(); 49 int q=input.nextInt(); 50 if(uf.connected(p, q)) continue; //若p,q已属于同一连通分量不再连接,则故直接跳过 51 uf.union(p, q); 52 System.out.println(p+"-"+q); 53 54 } 55 System.out.println("总连通分量数:"+uf.getCount()); 56 } 57 58 }
测试结果:
2-3
1-0
0-4
5-7
总连通分量数:4
分析:
find()操作的时间复杂度为:O(l),Union的时间复杂度为:O(N)。因为算法可以非常高效地实现find(),所以我们也把它称为“quick-find”算法。
--------------------
2.Union-find进阶:
仔细一想,我们上面再进行union()连接操作时,实际上就是一个进行暴力“标记”的过程,即把所有连通分量id跟点q相同的点找出来,然后全部换成p的id。算法本身没有错,但是这样的代价太高了,得想办法优化~
因此,这里引入了一个抽象的“树”结构,即初始时每个点都是一棵独立的树,所有的点构成了一个大森林。每一次连接,实际上就是两棵树的合并。通过,不断的合并,合并,再合并最后长成了一棵棵的大树。
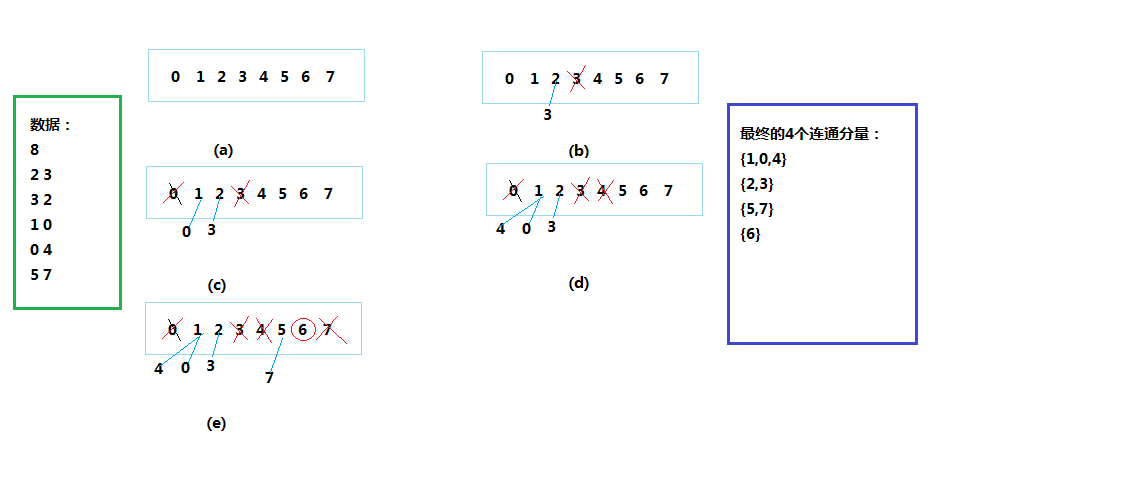
图2
Code:
1 package com.gdufe.unionfind; 2 3 import java.io.File; 4 import java.util.Scanner; 5 6 public class UF { 7 8 int count; //连通分量数 9 int[] id; //每个数所属的连通分量 10 11 public UF(int N) { //初始化时,N个点有N个分量 12 count = N; 13 id = new int[N]; 14 for (int i = 0; i < N; i++) 15 id[i] = i; 16 } 17 //返回连通分量数 18 public int getCount(){ 19 return count; 20 } 21 22 //查找x所属的连通分量 23 public int find(int x){ 24 while(x!=id[x]) x = id[x]; //若找不到,则一直往根root回溯 25 return x; 26 } 27 //连接p,q(将q的分量改为p所在的分量) 28 public void union(int p,int q){ 29 int pID=find(p); 30 int qID=find(q); 31 if(pID==qID) return ; 32 id[q]=pID; 33 count--; 34 } 35 /* 36 //查找x所属的连通分量 37 public int find(int x){ 38 return id[x]; 39 } 40 41 //连接p,q(将q的分量改为p所在的分量) 42 public void union(int p,int q){ 43 int pID=find(p); 44 int qID=find(q); 45 if(pID==qID) return ; 46 for(int i=0;i<id.length;i++){ 47 if(find(i)==pID){ 48 id[i]=qID; 49 } 50 } 51 count--; //记得每进行一次连接,分量数减“1” 52 } 53 */ 54 //判断p,q是否连接,即是否属于同一个分量 55 public boolean connected(int p,int q){ 56 return find(p)==find(q); 57 } 58 59 public static void main(String[] args) throws Exception { 60 61 //数据从外部文件读入,“data.txt”放在项目的根目录下 62 Scanner input = new Scanner(new File("data.txt")); 63 int N=input.nextInt(); 64 UF uf = new UF(N); 65 while(input.hasNext()){ 66 int p=input.nextInt(); 67 int q=input.nextInt(); 68 if(uf.connected(p, q)) continue; //若p,q已属于同一连通分量不再连接,则故直接跳过 69 uf.union(p, q); 70 System.out.println(p+"-"+q); 71 72 } 73 System.out.println("总连通分量数:"+uf.getCount()); 74 } 75 76 }
测试结果:
2-3
1-0
0-4
5-7
总连通分量数:4
分析:
利用树本身良好的连通性,我们算法仅需要O(l)时间代价进行union()操作,但此时find()操作的时间代价有所增加。结合本算法对quick-find()的优化,我们把它称为“quick-union”算法。
--------
3.Union-Find再进阶
等等,还没完!
表面上,上述引入“树”结构的算法时间复杂度由原来的O(N)改进为O(lgN)。但是,不要忽略了这样一种极端情况,即每连接一个点之后,树在不断往下生长,最后长成一棵“秃树”(没有任何树枝)。
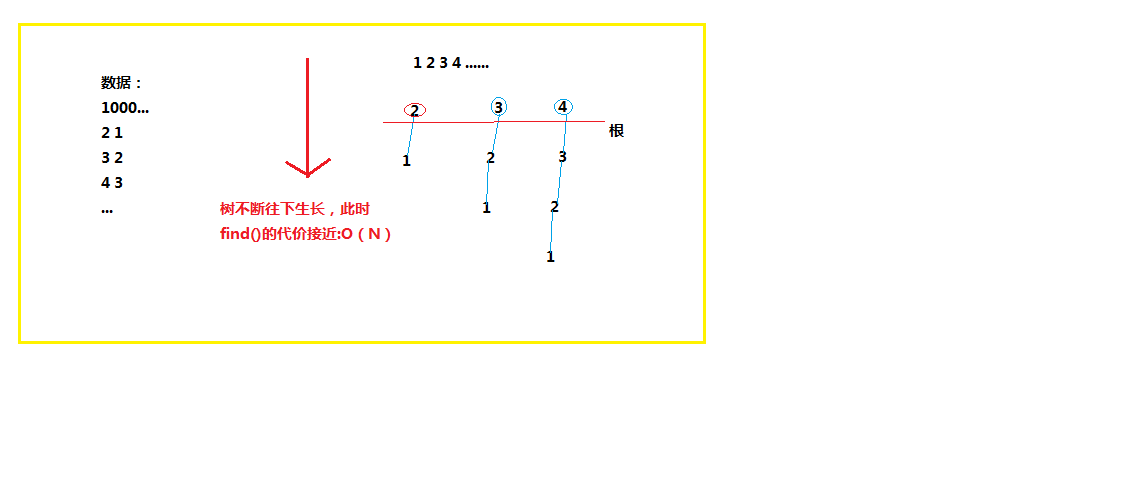 图3
图3
为了不让我们前面做的工作白费,必须得采取某些措施避免这种恶劣的情况给我们算法带来的巨大代价。所以...
是的,或许你已经想到了,就是在两棵树进行连接之前做一个判断。每一次都优先选择将小树合并到大树下面,这样子树的高度不变,能避免树一直往下增长了!下图中,数据增加了“6-2”的一条连接,得知以“2”为根节点的树比“6”的树大,对比(f)和(g)两种连接方式,我们最优选择应该是(g),即把小树并到大树下。
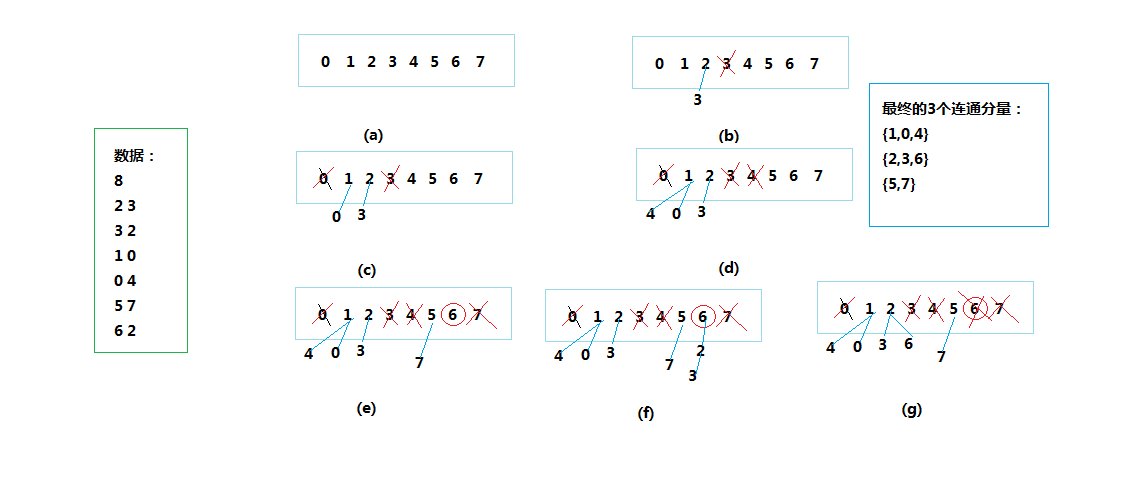 图4
图4
基于此,我们还得引入一个变量对以每个结点为根节点的树的大小进行维护,具体我们以sz[i]表示i结点代表的树(或子树)的结点数作为它的大小,初始sz[i]=1。因为现在的每一个结点都有了权重,所以我们也把这种树结构称为“加权树”,本算法称为“weightedUnionFind”。
Code:
1 package com.gdufe.unionfind; 2 3 import java.io.File; 4 import java.util.Scanner; 5 6 public class UF { 7 8 int count; // 连通分量数 9 int[] id; // 每个数所属的连通分量 10 int[] sz; 11 12 public UF(int N) { // 初始化时,N个点有N个分量 13 count = N; 14 sz = new int[N]; 15 id = new int[N]; 16 for (int i = 0; i < N; i++) 17 id[i] = i; 18 19 for (int i = 0; i < N; i++) 20 sz[i] = 1; 21 22 } 23 24 // 返回连通分量数 25 public int getCount() { 26 return count; 27 } 28 29 // 查找x所属的连通分量 30 public int find(int x) { 31 while (x != id[x]) 32 x = id[x]; // 若找不到,则一直往根root回溯 33 return x; 34 } 35 36 // 连接p,q(将q的分量改为p所在的分量) 37 public void union(int p, int q) { 38 int pID = find(p); 39 int qID = find(q); 40 if (pID == qID) 41 return; 42 43 if (sz[p] < sz[q]) { //通过结点数量,判断树的大小并将小树并到大树下 44 id[p] = qID; 45 sz[q] += sz[p]; 46 } else { 47 id[q] = pID; 48 sz[p] += sz[q]; 49 } 50 count--; 51 } 52 53 /* 54 * //查找x所属的连通分量 public int find(int x){ return id[x]; } 55 * 56 * //连接p,q(将q的分量改为p所在的分量) public void union(int p,int q){ int pID=find(p); 57 * int qID=find(q); if(pID==qID) return ; for(int i=0;i<id.length;i++){ 58 * if(find(i)==pID){ id[i]=qID; } } count--; //记得每进行一次连接,分量数减“1” } 59 */ 60 // 判断p,q是否连接,即是否属于同一个分量 61 public boolean connected(int p, int q) { 62 return find(p) == find(q); 63 } 64 65 public static void main(String[] args) throws Exception { 66 67 // 数据从外部文件读入,“data.txt”放在项目的根目录下 68 Scanner input = new Scanner(new File("data.txt")); 69 int N = input.nextInt(); 70 UF uf = new UF(N); 71 while (input.hasNext()) { 72 int p = input.nextInt(); 73 int q = input.nextInt(); 74 if (uf.connected(p, q)) 75 continue; // 若p,q已属于同一连通分量不再连接,则故直接跳过 76 uf.union(p, q); 77 System.out.println(p + "-" + q); 78 79 } 80 System.out.println("总连通分量数:" + uf.getCount()); 81 } 82 83 }
测试结果:
2-3
1-0
0-4
5-7
6-2
总连通分量数:3
4.算法性能比较:
|
|
读入数据 |
find() |
union() |
总时间复杂度 |
|
quick-find |
O(M) |
O(l) |
O(N) |
O(M*N) |
|
quick-union |
O(M) |
O(lgN~N) |
O(l) |
O(M*N)极端 |
|
WeightedUF |
O(M) |
O(lgN) |
O(N) |
O(M*lgN) |
----------------------
结语:
读到了最后,有朋友可能觉得“不就是一个O(N)到O(lgN)的转变吗,有必要这么长篇大论麽”?对此,本人就只有无语了。有过算法复杂度分析的朋友应该知道算法由O(N)到O(lgN)所带来的增长效益是多么巨大。虽然,前文中13亿的数据,就算我们用最后的加权树算法一时半会儿也无法算出。但假如现在同样是100w的数据,那么我们最后的“加权树”因为整体的时间复杂度:O(M*lgN)可以在1秒左右跑完,而O(M*N)的算法可能得花费1千倍以上的时间,至少1小时内还没算出来(当然啦,也可能你机器的是高性能的~)。
最后的最后,罗列本人目前所知晓的本算法适用的几个领域:
l 网络通信(比如:是否需要在通信点p,q建立通信连接)
l 媒体社交(比如:向通一个社交圈的朋友推荐商品)
l 数学集合(比如:判断元素p,q之后选择是否进行集合合并)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号