
从0到1实现Transformer模型-CS336作业1
仓库地址(侵权即删):
https://github.com/Jingxu-Li/assignment1-basics
我能帮你省哪些坑?
| 读完本文,你将知道 |
|---|
| 1. CS336 作业 1 的真实工作量 |
| 2. BPE、RoPE、SwiGLU 等名词是什么 |
| 3. 一张 4090 上训 48 层 Transformer 到底要多久 |
| 4. 2B 参数量的估算口算过程 |
模型效果
根据给定的提示词补充完整一个故事:

图 1:模型的生成样例
背景知识: 一张图看懂Transformer
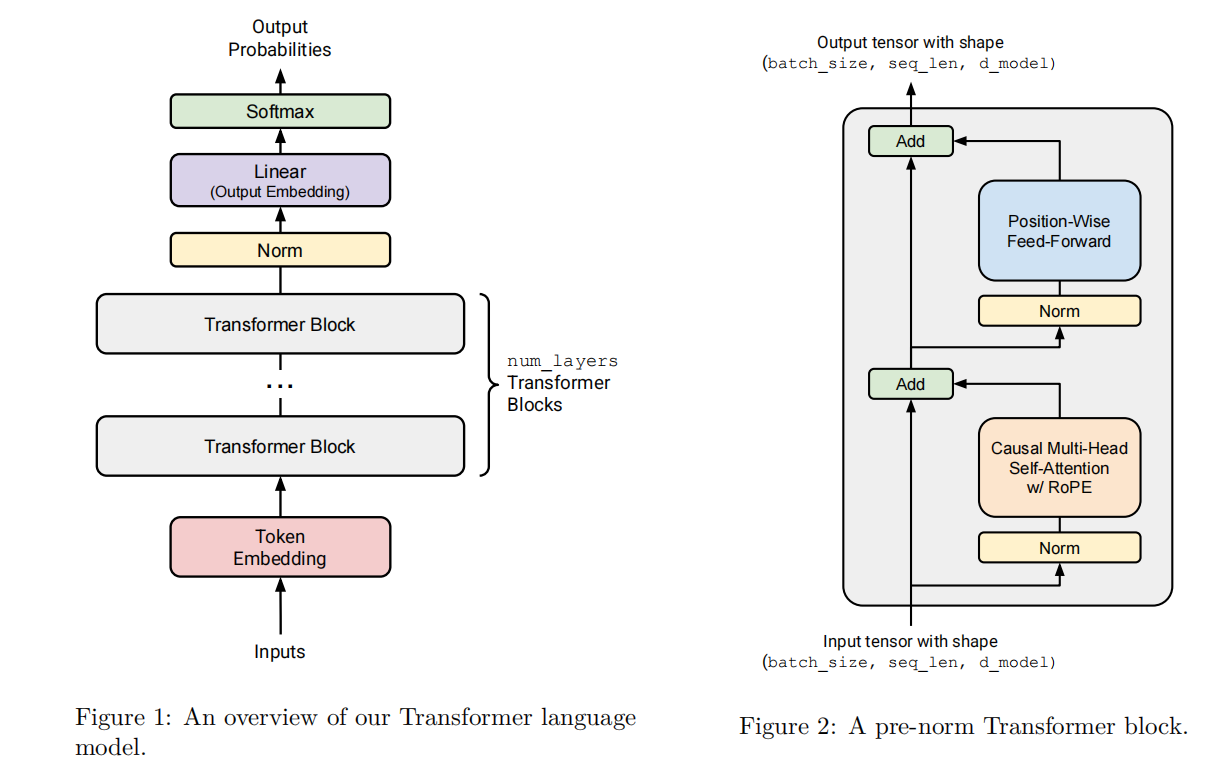
图 2:课程给出的“最小可运行” Transformer 结构
这里给出的结构是 课程中的 Transformer 结构,可以看出来大概由几个模块组成:
- Token Embedding
num_layers个 Transformer Block(Self-Attention + RoPE + SwiGLU FFN)- Final Norm
- Output Embedding & Softmax
模块实现及基本原理
Tokenizer
Tokenizer 是将输入的自然语言转换成 TokenId 的模块;这里使用的计算方法是 BPE(byte-level byte-pair encoding) 按字节分组后逐渐合并的方法。具体方法可以参考材料: BPE
下面给出流程图:
关于BPE的实现,最值得注意的是,每次更新所有 A B-> AB 这个步骤可以通过提前索引所有的 pair 和它们对应的 token list 来实现高效的查询和更新操作。
Q:为什么使用 Byte Level 的合并机制训练分词器,而不是直接使用字节作为输入或者词典作为输入?
A:如果直接使用字节训练,词表很短,但是同一个token的表示就会很长,并且丢失了很多语义信息;如果直接使用单词训练,词表很短,但是会有一些中间特征被忽略了,因此使用BPE可以很好的得到中间的特征表示。
采用 byte-level BPE,总结:
| 方案 | 词表大小 | 序列长度 | 语义粒度 |
|---|---|---|---|
| 纯字节 | 256 | 很长 | 太细 |
| 整词 | 很大 | 很短 | 太粗 |
| BPE | 可控 | 适中 | 可调 |
Transformer Block
Self-Attention(注意力机制)
提到 Transformer 就不得不提到 经典的文章 Attention Is All You Need 给出的注意力机制的实现和 Transformer 模型。
关于注意力机制,个人理解是通过多次上下文的计算,求出上下文中词与词之间的相关性;这里有一篇比较好的博客可以参考注意力机制
这里直接引用实现的公式:
其中 \(Q\), \(K\) 和 \(V\) 是输入向量和权重向量相乘的结果,\(d_k\) 是模型参数
\(softmax\) 函数的表示是
简单来说,softmax 函数会把向量转化成概率表示,用于进一步的输出或者其他训练。
Mask
在注意力机制的实现过程中,还需要对于一些上下文的信息做隐藏操作;比如下面这个表格很好地体现了Mask的实现:
| 位置 | 1 | 2 | 3 | 4 |
|---|---|---|---|---|
| 1 | 0 | -∞ | -∞ | -∞ |
| 2 | 0 | 0 | -∞ | -∞ |
| 3 | 0 | 0 | 0 | -∞ |
| 4 | 0 | 0 | 0 | 0 |
第 1 行:生成第 1 个词时只能看自己;
第 3 行:生成第 3 个词时可看 1,2,3,不能看 4。
将这个矩阵加到原始的点积结果之后再进行softmax 操作就可以得到合法的token 概率输出
多头自注意力机制
简单来说,多头注意力机制通过并行运行多个Self-Attention层并综合其结果,能够通过不同的头的分解,得到更加丰富的信息表示
Pre-Norm
在原始 Transformer 里,LayerNorm 放在子层之后(Post-Norm)。
Pre-Norm 则把它挪到子层之前,并给输出加一条恒等通路:
好处:
- 梯度不受激活尺度放大/缩小影响,训练深模型时更稳;
- 初始化几乎不用“玄学”缩放;
- 当前主流大模型(LLaMA、GPT-NeoX、PaLM)清一色采用 Pre-Norm。
代价:理论表达能力略低于 Post-Norm,但在 4–32 层范围内几乎测不出差距,因此教学/工业界都默认用它。
SwiGLU:把 FFN 做成“门控” highway
Transformer 的 FFN 默认是两个线性+激活:
FFN(x) = max(0, x W1 + b1) W2 + b2
SwiGLU 用一张“门”控制信息通量:
SwiGLU(x) = (x W1) ⊗ silu(x W3) · W2
一句话:SwiGLU 就是“给 FFN 加扇门”,让梯度流更丝滑,性价比极高。
Embedding
输入 Embedding层用于将输入的Token Id的整数值矩阵转换成每个Token的\(d_{\text{model}}\) 维度的向量;这里一定要转换成向量表示是用于后续 Transformer 的矩阵计算;
输入Embedding 的模型结构有些接近线性层的实现;这一层的输入是:
(batch_size, sequence_length) 的矩阵
输出是(batch_size, sequence_length, d_model) 维度的矩阵,其中Embedding 矩阵的参数是 (vocab_size, d_model);
(以下问题是AI生成的)
Q: 为什么 Transformer 能把 Embedding 直接放第一层?
A: 可以把 Embedding 层直接放在 Transformer 第一层,根本原因是 Transformer 的所有后续运算都是“纯数值运算”(矩阵乘法 + 非线性),它不要求输入具有任何空间或顺序先验。
位置信息表示 - RoPE
核心思想:把绝对位置信息旋转进 Query & Key 向量。
精华文章:RoPE 旋转位置编码
模型参数计算
结合上面提到的信息,让我们进行一个简单的模型参数计算;假设目前有一个模型参数配置:
| 参数 | 值 |
|---|---|
| vocab_size | 50 257 |
| context_length | 1 024 |
| num_layers | 48 |
| d_model | 1 600 |
| num_heads | 25 |
| d_ff | 6 400 |
Q: 有多少训练参数?假设所有参数都是单精度的浮点数,加载模型需要多少内存?
输入/输出 Embedding:(vocab_size, d_model) = 2*80,411,200 = 160,822,400
单个Transformer Block:
- Attention层:
- \(W_Q:(h*d_k, d_{\text{model}})\)
- \(W_K:(h*d_k, d_{\text{model}})\)
- \(W_V:(h*d_v, d_{\text{model}})\)
这里的 \(d_k\)=\(d_v\)=\(d_{\text{model}}/h\)
-
FFN 层:$$\mathrm{FFN}(x)=\mathrm{SwiGLU}(x,W_1,W_2,W_3)=W_2!\bigl(\mathrm{SiLU}(W_1x)\odot W_3x\bigr)$$
- \(W_1, W_3: (d_\text{ff}, d_{\text{model}})\)
- \(W_2: (d_{\text{model}}, d_\text{ff})\)
因此单个 Transformer Block的参数是 \(W_{\text{block}} = 3*d_{\text{model}}*d_{\text{model}}+3*d_\text{ff}*d_{\text{model}}\) = 38400000
总计 \(\text{num_layers}*W_{\text{block}}=1,843,200,000\)
因此得到总计的模型参数量是:2B参数
GPT-2 XL 实测 1.5 B,差异主要来自 FFN 不使用 SwiGLU,多一层投影。
训练模块
交叉熵
计算模型的输出与实际的值之间的差异,这里不加解释地给出公式:
其中
AdamW 优化器
同样不加解释地给出优化器公式
模型训练过程
- GPU:1 × RTX 4090(AutoDL)
- 框架:PyTorch 2.1 + CUDA 12.1
创建时间: 2025-08-27 00:36:35
实验配置
| 参数 | 值 |
|---|---|
| vocab_size | 10000 |
| context_length | 256 |
| d_model | 512 |
| num_layers | 4 |
| num_heads | 16 |
| d_ff | 1344 |
| rope_theta | 10000.0 |
| batch_size | 128 |
| max_iters | 5000 |
| learning_rate | 0.0003 |
| min_learning_rate | 1e-05 |
| warmup_iters | 1000 |
| weight_decay | 0.1 |
| grad_clip | 1.0 |
| data_path | data/tokenized_data.bin |
| split_ratio | 0.9 |
| device | cuda |
| seed | 42 |
大概算下来整体参数量 0.16B
训练结果
- 最终训练损失: 1.6731
- 最终验证损失: 1.6473
- 最终验证困惑度: 5.19
- 总训练时间: 1644.53 秒 (0.46 小时)
训练统计
- 总迭代次数: 4999
- 平均每迭代时间: 0.3290 秒
下图为训练完成的学习率曲线

小结
- 跟着作业从零写 Transformer,代码量不大,坑不少。
- BPE 一定要做pair索引,否则合并一次 O(N²) 等到怀疑人生。
- 4090 上 48 层 512 dim 模型,不到半小时就能拉到 5 PPL 左右,当玩具足够。(PPL = e^Loss)
5 PPL 相当于模型每步只在 5 个词里猜答案,比随机盲猜 1 万词缩小了 2000 倍,肉眼已觉通顺。
下次见,推理优化见。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号