

P24_现有网络模型的使用及修改
24.1 VGG16网络模型:
(1)打开pytorch(0.9.0)—torchvision.models—VGG
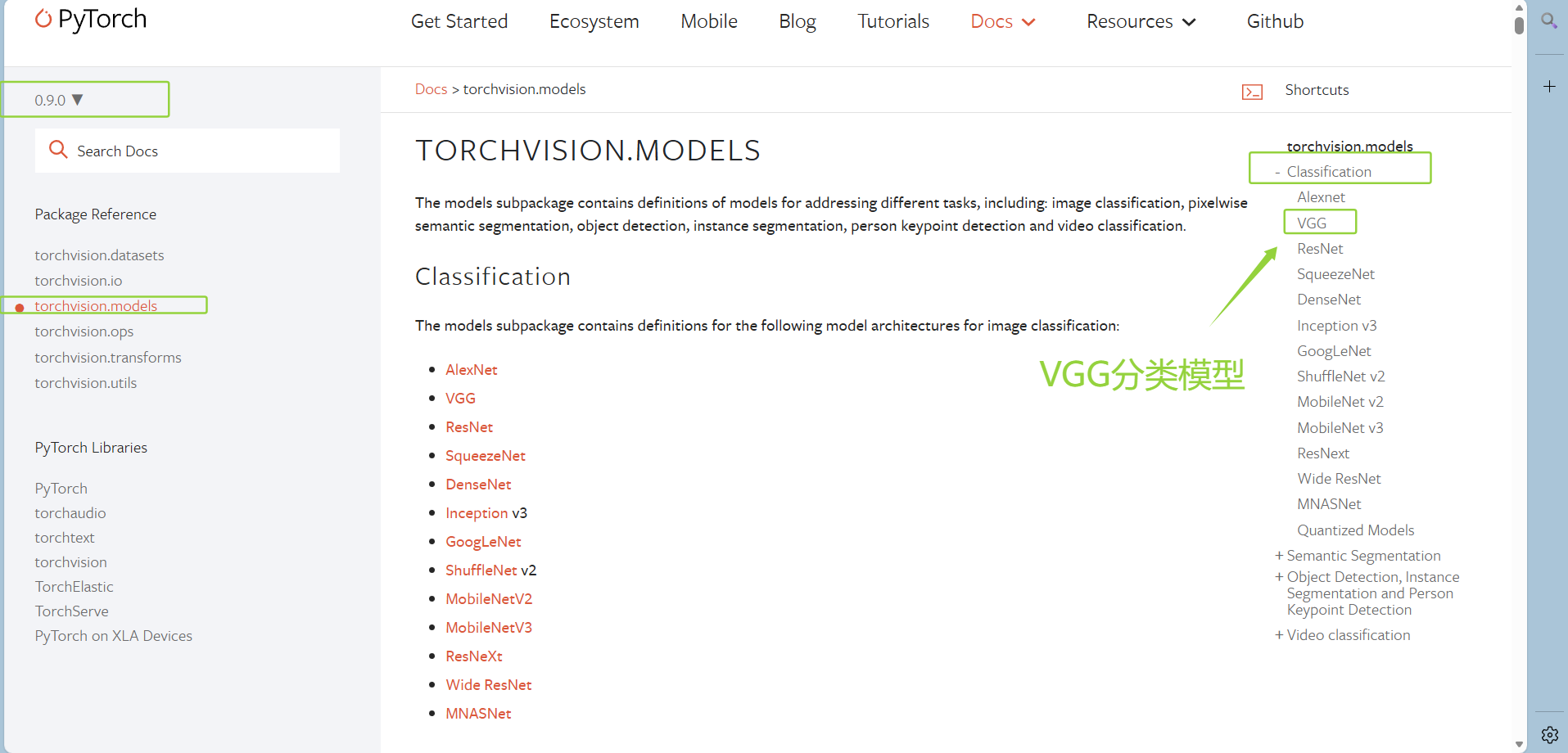
(2)参数
点击查看代码
pretrained (bool) – If True, returns a model pre-trained on ImageNet
progress (bool) – If True, displays a progress bar of the download to stderr
24.2 ImageNet数据集
(1)ImageNet数据集要求:
This requires scipy to be installed
【可以在pycharm的终端输入:pip list,查看是否安装了scipy库】
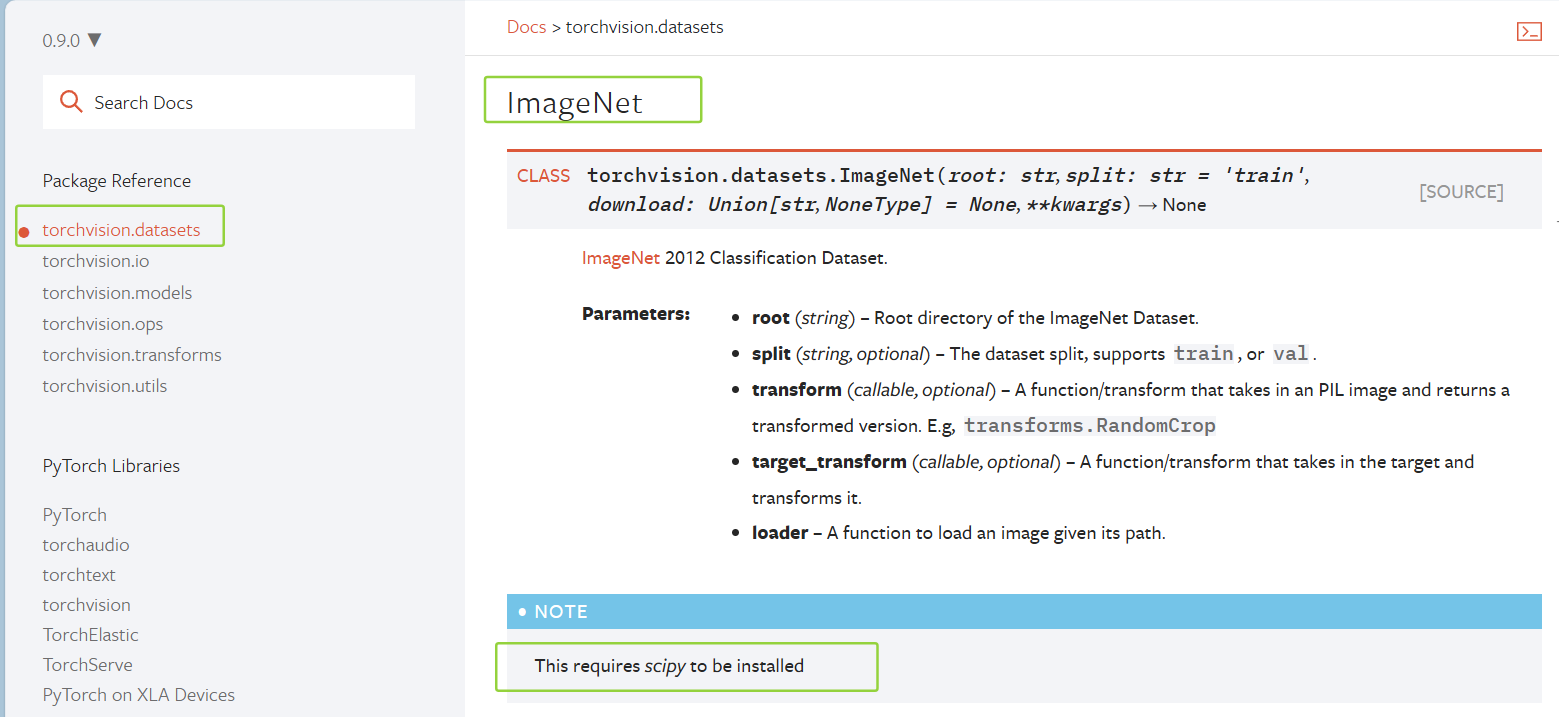
(2)下载该数据集
点击查看代码
import torchvision.datasets
train_data = torchvision.datasets.ImageNet("./data_image_net",split='train', download=True,transform=torchvision.transforms.ToTensor())
(3)报错如下:
点击查看代码
The archive ILSVRC2012_devkit_t12.tar.gz is not present in the root directory or is corrupted. You need to download it externally and place it in ./data_image_net.
【正在尝试使用的 torchvision.datasets.ImageNet 数据集没有自动下载成功】
(4)PyTorch 要求用户必须手动下载 ImageNet 数据集
ImageNet数据集太大了,仅训练集就有147.9GB
所以:就没有办法通过下载ImageNet数据集去验证vgg16模型的pretrained这个参数:
pretrained (bool) – If True, returns a model pre-trained on ImageNet
24.3 改变现有网络的参数:添加or修改
(1)查看vgg16不同pretrained情况中其网络模型参数的差别
①把pretrained这个参数设置为true或false的情况下,看其下载的网络模型其中的参数有什么差别
点击查看代码
vgg16_false = torchvision.models.vgg16(pretrained=False)
vgg16_true = torchvision.models.vgg16(pretrained=True)
print("ok")
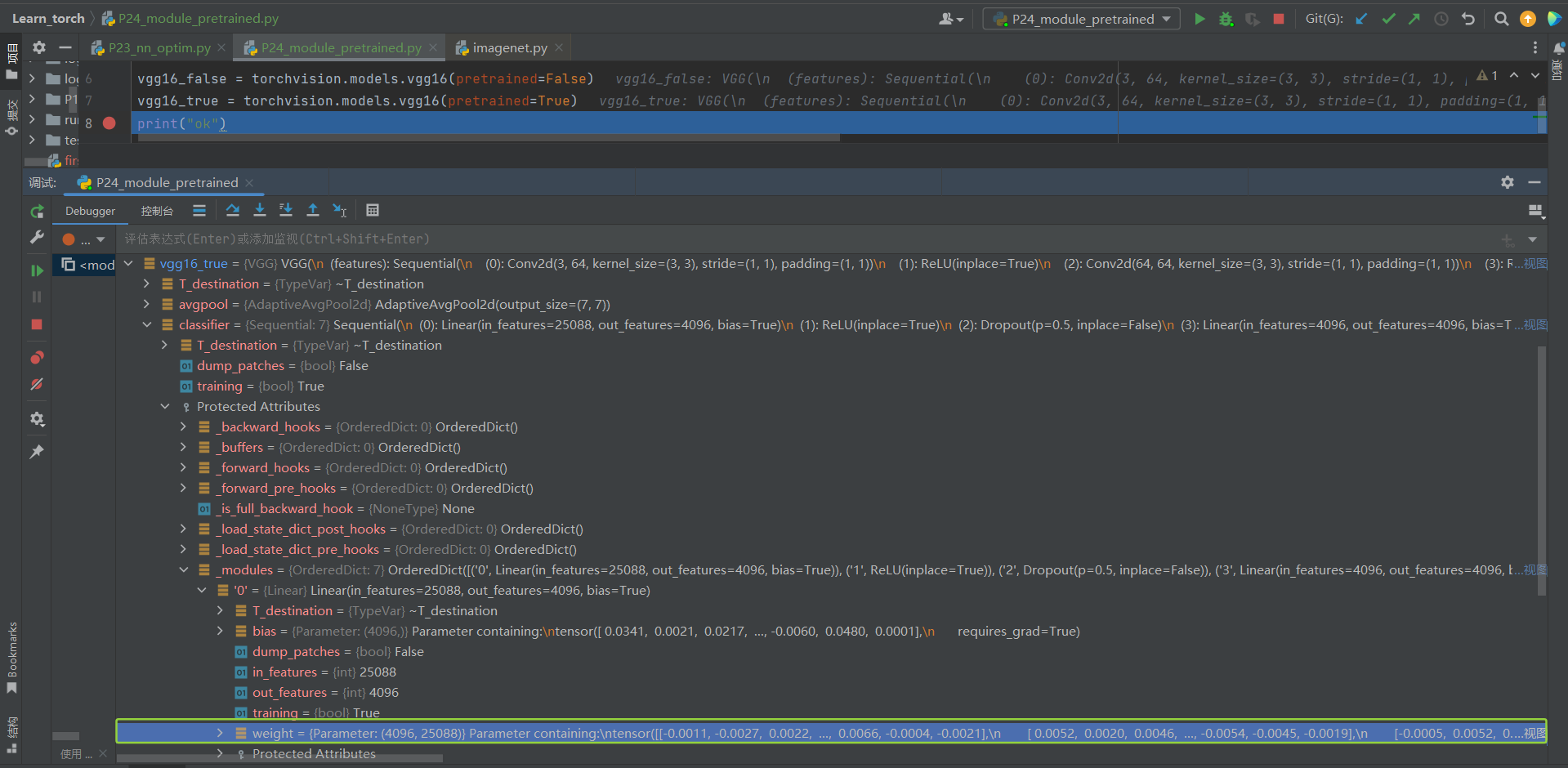
②把断点打在print("ok"),让其debug到print的上一行代码
vgg16_true和vgg16_false:
打开vgg16_true的classifier的Protected Attributes中的_modules下的'0'中的权重weight
打开vgg16_false的classifier的Protected Attributes中的_modules下的'0'中的权重weight
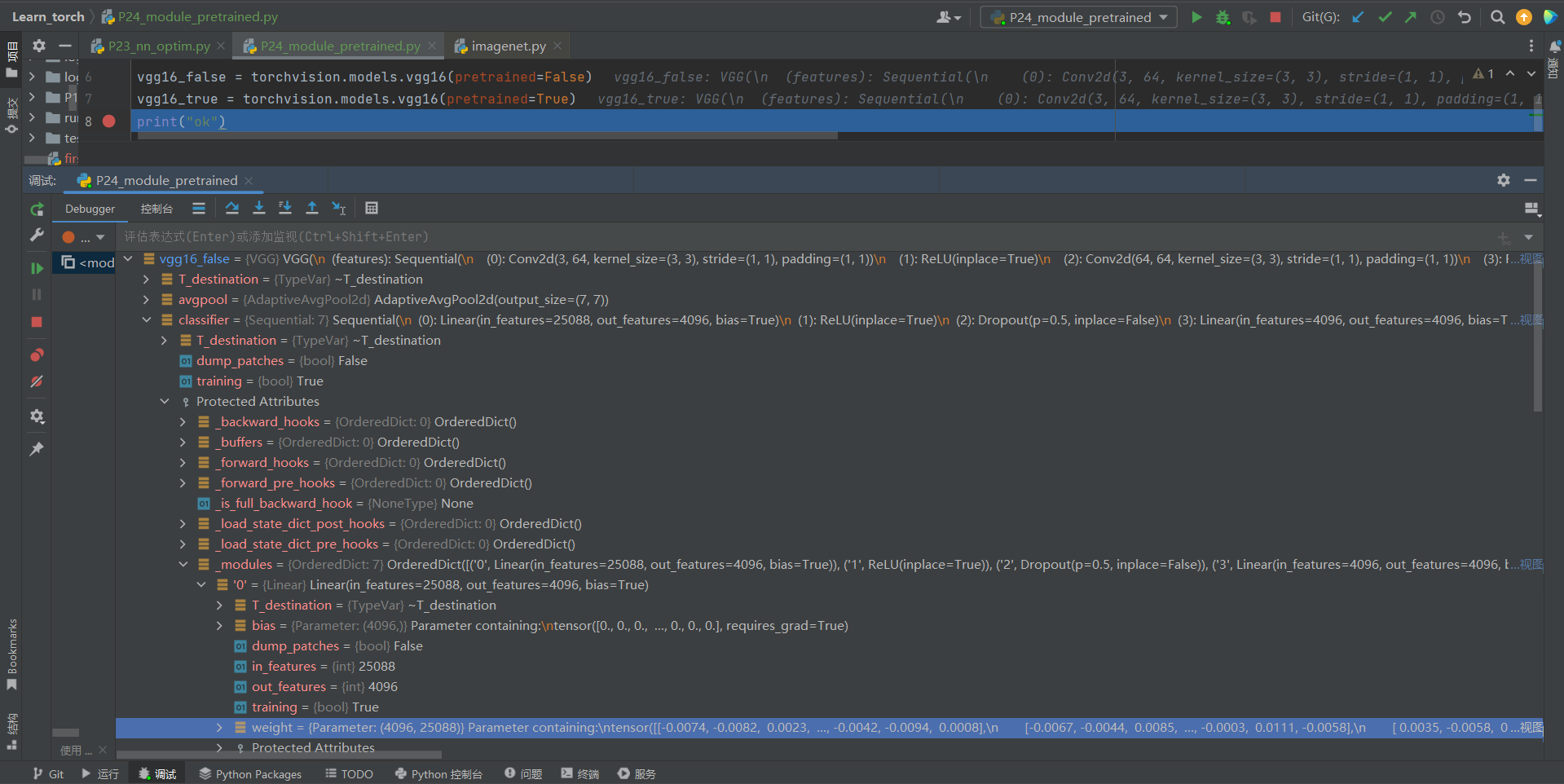
③【区别:vgg16_false没训练,vgg16_true训练好的】
(2)print(vgg16_true),查看vgg16的网络架构
点击查看代码
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
通过out_features=1000,可以知道vgg16能分出的类别是1000个
(3)应用vgg16模型到CIFAR10数据集
vgg16模型能分出的类别是1000个,CIFAR10数据集把数据分为10类
①法一:将vgg16模型架构中的最后一行代码中的:(6): Linear(in_features=4096, out_features=1000, bias=True)里面的out_features=1000改成out_features=10
②法二:在线性层 (6): Linear(in_features=4096, out_features=1000, bias=True)后面再加一层:使in_features为1000,out_features为10
(4)【添加】使用(3)的法二:add_module
①输入:
点击查看代码
import torchvision.datasets
# train_data = torchvision.datasets.ImageNet("./data_image_net",split='train',
# download=True,transform=torchvision.transforms.ToTensor())
from torch import nn
vgg16_false = torchvision.models.vgg16(pretrained=False)
vgg16_true = torchvision.models.vgg16(pretrained=True)
print(vgg16_true)
train_data = torchvision.datasets.CIFAR10("./dataset",train=True,transform=torchvision.transforms.ToTensor(),
download=True)
vgg16_true.add_module("add_linear",nn.Linear(in_features=1000,out_features=10))
print(vgg16_true)
②得到的结果中就会多加一层add_linear层:
(add_linear): Linear(in_features=1000, out_features=10, bias=True)
点击查看代码
Files already downloaded and verified
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
(add_linear): Linear(in_features=1000, out_features=10, bias=True)
)
③想要(add_linear): Linear(in_features=1000, out_features=10, bias=True)加到classifier()里面,而不是整个VGG()里面,可以修改代码:
vgg16_true.classifier.add_module("add_linear",nn.Linear(in_features=1000,out_features=10))
可见:add_linear已经加到了classifier里面:
点击查看代码
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
(add_linear): Linear(in_features=1000, out_features=10, bias=True)
)
(5)【修改】使用(3)的法一:[i]
由于vgg16_true已经被修改过(即被添加了add_linear层),现在在vgg16_false进行修改
①先打印vgg16_false
print(vgg16_false)
得到classifier里面:
点击查看代码
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
②直接修改:
vgg16_false.classifier[6] = nn.Linear(in_features=4096,out_features=10,bias=True)
得到:
点击查看代码
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=10, bias=True)
)
可见,out_features变成了10

 浙公网安备 33010602011771号
浙公网安备 33010602011771号