MySQL数据库入门学习
数据库,就是数据的集合(a collection of data),用来存储数据。为什么要用数据库存储数据呢?因为它们有着特定的存储结构,能够快速高效地存取大量的数据,并且在存储结构上面又提供了一层逻辑结构(单个数据库和表),方便使用。可以把单个数据库想像成一个文件夹,表想像成一个excel表格文件,存取数据就像向表中插入和查询数据。正如excel表格有行和列之分,数据库中的表,也有行和列之分,列规定放什么数据(姓名,年龄),行就是插入的数据。数据库就是一个简单的物理位置,用来存放数据。怎么操作数据库?用数据库管理软件(Database Management System(DBMS)),比如MySQL和Oracle等。MySQL和Oracle等并不是数据库,而是数据库管理软件,用来管理数据库,比如创建数据库,创建表,从数据库中获取数据等等。数据库管理软件是以服务的形式存在的,使用之前要先启动服务,然后登录连接服务。比如安装了MySQL,还要启动MySQL 服务,然后登录,才能对数据库进行操作。管理员身份打开命令行工具,net start mysql 启动服务,mysql -u 用户名 -p 密码,

显示mysql>,表示登录成功。操作数据使用的是SQL指令或SQL语句。我们写SQL语句,发送给MySQL,MySQL执行SQL语句,从而实现对数据库的操作。SQL也是一门语言,有着特定的语法。比如创建数据库,CREATE {DATABASE | SCHEMA } [IF NOT EXISTS] db_name,{ } 大号表示必写项,里面的 | 表示二者选其一,[] 表示可写可不写,
CREATE DATABASE my_first_db; -- 创建my_first_db 数据库
SQL指令不区分大小写,但建议关键字(CREATE DATABASE)全部大写,数据库名等自定义的内容全部小写。每一个指令都要以分号结尾,MySQL见分号执行语句。SQL 关键字要以空格进行分隔,空格之后可以跟任意的空格,也可以跟换行,所以SQL指令可以写多行。还有一种不常见的,语句也可以以\g(go)结尾。SELECT NOW(); 和 SELECT NOW()\g 一样。
[IF NOT EXISTS],如果不存在数据库db_name, 就创建数据库 db_name,如要存在,就什么也不做,防止创建同名的数据库时报错。再创建一次my_first_db ,
![]()
报错了。如果加上IF NOT EXISTS
![]()
没有报错,只是一个warning。SHOW DATABASES; 命令, 显示创建了哪些数据库。创建数据库成功,就要使用数据库。USE 数据库名
USE my_first_db;
Database change,表示已经在my_first_db数据库下面了。SELECT DATABASE(); 也可以确定正在操作哪个数据库。接下来,就要向数据库存储数据,需要创建表。相当于已经创建了一个文件夹,要在其下面创建excel表格。 创建表就要考虑表中存储什么数据(字段)以及用什么类型去存储。CREATE TABLE [IF NOT EXIST] 表名( 字段名 数据类型, .....); 数据类型多种多样,有整数,小数,日期类型,字符串类型等。
整数分为INT,BIGINT,SMALLINT, TINYINT,MEDIUMINT 等,它们的主要区别在于所占内存空间不同,所存储的数值范围不同。INT占4个字节,BIGINT占8个字节,SMALLINT 占2个字节, TINYINT占1个字节,MEDIUMINT占3个字节。它们后面可以跟UNSIGNED,表示存储无符号整数。原来还有width,ZEROFILL,不过现在width和ZEROFILL已经废弃了。
小数分为定点数和浮点数,区别在于小数点的精度。定点数,存进去什么,取出来就是什么,一模一样,但是浮点数,存进去的数值和取出来的数值可能不一样。定点数类型是DECIMAL和NUMERIC,在MySQL中,它们是一样的。语法DECIMAL[(width[,decimals])] [UNSIGNED] [ZEROFILL],width表示一共多少位数,decimals表示其中有几位小数,DECIMAL(6,2) 存储 –9,999.99 ~ 9,999.99。width是可选的,默认是10,decimals也是可选的,默认是0。width最大能取65,decimals最大能取30。如查只想存正数,可以加UNSIGNED,用0对数字进行填充,加ZEROFILL。
浮点数是DOUBLE(也称Real)和FLOAT,存储近似值。FLOAT有两种格式,FLOAT[(width, decimals)] [UNSIGNED] [ZEROFILL] 或 FLOAT[(precision)] [UNSIGNED] [ZEROFILL], 第二种就是设置精度,精度如果取0-24,那它还是FLOAT, 如果取25-53,它就变成了DOUBLE。但通常,只使用FLOAT关键字,不设置任何参数,用来存储4个字节的单精度浮点数。DOUBLE 只有一种格式,DOUBLE [(width, decimals)] [UNSIGNED] [ZEROFILL], 和FLOAT一样,通常只使用DOUBLE关键字,不设置任何参数,用来存储8个字节的双精度浮点数。
字符串类型,经常用的是CHAR、VARCHAR、TEXT。CHAR类型语法是 CHAR(width),存储固定长度(width)的字符,如果width没有提供,width默认是1,就是char(1), width 的最大值是255. 若存入字符数小于width,则以空格补于其后。但当读取数据的时候,空格又会被移除掉,也就是说,如果原来字符串中末尾有空格,存储到char类型,这些空格就会消失掉。VARCHAR 后面也是跟一个长度, VARCHAR(width), 存储字符到最大长度(width),也就是说,存入多少就是多少,不会补空格,直到最大长度width,如果超出最大长度,就会截取到最大长度,空格也是有效字符,比如varchar(2), 如果存储 'a ' 会被截取成 'a '。width最大能取到65,536,VARCHAR最大能存储65536个字符。在实际存储中,varchar是存入的实际字符数+1个字节(n<=255)或2个字节(n>255),所以varchar(4),存入3个字符将占用4个字节。 TEXT最大能存储65536个字符。Mysql中,一个中文是一个字符,65536个字符,就是65536个汉字。VARCHAR(255),那就是255个汉字,765个字节(UTF-8下,一个汉字3个字节)
时间和日期类型:Date 存储年月日,MySQL 在存储和显示日期的时候是按照 YYYY-MM-DD 的格式,比如2024-01-31。Time 存储 时分秒,格式为HH:MM:SS,比如12:25:36。TIMESTAMP和DATETIME: 存储年月日和时分秒,可以带(),表示多少位子秒,比如TIMESTAMP(3),格式为YYYY-MM-DD HH:MM:SS[.fraction][time zone offset]。TIMESTAMP 在内部是用UTC 时区 进行存储的,而DATETIME 则不会转化成UTC。TIME 值通常被认为是一天中的时间值,但 MySQL 实际上将它们视为经过的时间( elapsed time)。因此,它们可能大于 23:59:59 甚至为负数。(TIME 列的实际范围是 -838:59:59 到 838:59:59。)DATETIME 支持的范围是 1000-01-01 00:00:00 至 9999-12-31 23:59:59,而 TIMESTAMP 值仅在1970 年至 2038 年期间有效。当客户端插入 TIMESTAMP 值时,服务器会将其从与客户端会话关联的时区转换为 UTC 并存储 UTC 值。当客户端检索 TIMESTAMP 值时,服务器会执行反向操作,将 UTC 值转换回客户端会话时区。与服务器处于不同时区的客户端可以配置其会话,以便此转换适合其自己的时区
ENUM类型:指定列的取值范围,列的值只能取定义的列表中的一个,比如 列的类型是ENUM('Apple', 'Orange', 'Pear')。SET类型和ENUM一样,也是定义取值范围,不过,列的值可以是一个或多个。ENUM和SET类型,虽然操作的都是字符串,但真正存储到数据库中的是数字,所以千万不要用ENUM或SET 来定义数字。
创建一个学生表,姓名,年龄,成绩,最喜欢的水果,水果列表,创建时间,更新时间。建议数据库名称,表名,字段名,使用小写字母并用下划线分割,因为在Linux下是区分大小写的,而在Windows下不区分大小写。在Linux下,Lucy,lucy和LUCY 是不同的数据库名,但是window下,它们是同一个数据库,不正确的大小会导致MySQL报错。
CREATE TABLE student( name VARCHAR(255), age INT, fruit ENUM('Apple', 'Orange', 'Pear'), fruit_list SET('Apple', 'Orange', 'Pear'), createdAt DATETIME, updateAt DATETIME );
SHOW TABLES; 命令,显示数据库中所有的表。创建表之后,就可以插入数据了,INSERT [INTO] 表名[(列名, ...)] VALUES(值, ....), 比如INSERT student(name) VALUES('sam'); 字符串字面量('sam')用单引号或双引号括起来,建议用单引号。多执行几次,查询一下,SELECT * FROM student; 除了name外,其他值都是null,并且相互之间不能区分,这不逻辑,学生要有名字和年龄,并且也要区分,是不是同一个学生(同名的太多),这就需要对值或行进行限制,称为约束。字段的值不能为null 是非空约束(NOT NULL)。行与行之间进行区分,要有主键。
主键约束:保证每条记录的唯一性,每张表中只能有一个主键,用primary key表示,当字段设为主键以后,它自动NOT NULL。为什么要保证每条记录的唯一性,这主要是对于表的操作来说,如果我们删除一个记录,执行成功后,mysql返回它删除了一个记录,如果每条记录都是唯一的,那我们就非常确信,执行的没有问题。但如果记录不唯一,我们就不能确定执行的是不是没有问题?那对于我们输入学生列表来说,怎么保证记录的唯一呢?难道要手动输入id , 1, 3 ,4, 那就麻烦了,其实它可以和AUTO INCREMENT 一起使用,auto increment 自动增长的意思, 很显然,它是一个数字类型,而且也解决了字段唯一的问题。MySql 有一个SERIAL类型, 表示 BIGINT UNSIGNED NOT NULL AUTO_INCREMENT UNIQUE。除了两个约束以外,还有唯一约束,默认约束,外键约束。
唯一约束(UNIQUE KEY):字段设为唯一约束时,每条记录的这些或这个字段的值都不能重复,name设为唯一约束,就没有重名了。默认约束(DEFAULT) ,就是给字段一个默认值,当插入数据时,如果没有给字段插入数据,字段取默认值。createAt 时间戳可以取默认值(DEFAULT CURRENT_TIMESTAMP) 。udpated时间戳,有的设置为null,然后更新行添加时间(ON UPDATE CURRENT_TIMESTAMP), 有的是,默认取创建时间,修改时再更新时间(DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP)。如果没有为TIMESTAMP 列指定 DEFAULT NULL 或 NULL,则其默认值为 0。
Drop table student,然后重新创建,
CREATE TABLE student( id serial, name VARCHAR(255) not null, age INT not null, fruit ENUM('Apple', 'Orange', 'Pear'), fruit_list SET('Apple', 'Orange', 'Pear'), createdAt DATETIME default current_timestamp, updateAt DATETIME DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP );
插入ENUM 用字符串('Apple'),插入SET也是,多个值用字符串拼接,拼接时中间不能有空格('Apple,Orange'),插入时间类型,必须符合MySQL的时间格式(ISO format),如果格式不对,要先手动转换成Mysql支持的格式,再插入。如果格式近似ISO format,MySQL也能识别,比如 YYYY-MM-DD,YYYY/MM/DD,不用手动转换。STR_TO_DATE用于转换。
INSERT INTO t (d) VALUES(STR_TO_DATE('May 13, 2007','%M %d, %Y'));
插入数字时,可以用表达式,需要注意的是,MySQL在内部进行数字计算时,使用的是signed BIGINT 或 signed DOUBLE,取值范围为–9,223,372,036,854,775,808 ~ 9,223,372,036,854,775,807。如是两个数的计算值,比如相乘,越出了范围,就会报错,insert into student(name, age, fruit, fruit_list, createdAt) values('sam', 30, 'Apple', "Apple,Orange", '2024/7/10'); 如果把 30 改成(18447440737095516 * 100) 就报错了
外键约束:数据库中有多张表,表与表之间就会存在关系,为了描述这种关系,就要在表中创建外键,比如学生表和留言表,每一个学生可发表多条留言,但每条留言只能属于一个学生,留言表定义一个列指向学生表,留言表这一列称为外键,它的值为学生表的主键(指向学生表),必须要在学生表主键字段中存在,外键的类型必须和主键的类型一致。学生表也称为参照表,学生表的主键也称为参照列。创建外键,foreign key(外键列名) references 参照的表名(参照列)创建外键
CREATE TABLE post( id serial, post VARCHAR(255) NOT NULL, student_id bigint unsigned, constraint FK_STUDENT_POST FOREIGN KEY(student_id) REFERENCES student(id) );
删除:由于数据库最小的操作单位是行,删除就是删除一整行,所以不需要提供字段,只需要提供表名和条件,满足条件就会删除,delete from 表名 where 条件表达式。更新也是以行为单位进行更新,所以where 条件要找到行,然后更新某个字段或某些字段的值,更新字段的值为set 字段名 = 新值, 整个更新操作是 update 表名 set 字段名 = 新值 [, 字段名 = 新值 ] where 条件。如果没有条件,对整张表的所有行数据进行更新。
外键约束-- 级联: 当表中的一条记录被另一张表中的记录关联时,就不能对表中的这条记录进行删除和修改主键。要怎样才能删除和修改主键呢?在创建主键的时候设置级联修改和级联删除,on update cascade on delete cascade, 级联操作,就是 更新或删除一个(被关联的记录)的时候,也把另一个(关联的记录)也更新或删除了。
查询
https://dev.mysql.com/doc/index-other.html 有 Example Databases,sakila库。下载zip到本地,解压,mysql命令行中,
source C:\Users\Sam\Downloads\sakila-db\sakila-schema.sql source C:\Users\Sam\Downloads\sakila-db\sakila-data.sql
查询: 查询出符合条件的记录, 如果没有列出条件,就把整张表的数据全列出来。select 字段名 from 表名 where 条件,
SELECT city FROM sakila.city;
查询条件,等值查询=, !=, 大于,小于,区间查询 between and , IS NULL和 IS NOT NULL 用来判断列是不是null 值。
SELECT name FROM sakila.language WHERE name = 'English'; SELECT city FROM sakila.city WHERE city_id < 5;
Sometimes it’s useful to map NULL values onto some other value that has more meaning in the context of your application. For example, use IF() to map NULL onto the string Unknown:
SELECT subject, test, IF(score IS NULL,'Unknown', score) AS 'score' FROM expt; -- 或者 SELECT subject, test, IFNULL(score,'Unknown') AS 'score' FROM expt; -- SELECT subject, test, COALESCE(score,'Unknown') AS 'score' FROM expt;
时间的比较用,字符串
SELECT d FROM date_val where d < '1900-01-01'; SELECT d FROM date_val where d BETWEEN '1900-01-01' AND '1999-12-31';
模糊查询 like: 表达式中的%表示任意多个字符,_ 表示任意一个字符。查询电影名中包含family的电影
SELECT title FROM sakila.film WHERE title LIKE "%family%"; SELECT first_name FROM sakila.actor WHERE first_name LIKE "NAT_%";

SQL patterns do not match NULL values. This is true both for LIKE and for
NOT LIKE:
一般情况下,要避免使用在模糊查询的开头使用%,因为,它不会使用索引,会进行全表扫描。
mysql还能用正则表达式进行模式匹配, REGEXP 或 NOT REGEXP 操作符, SELECT name FROM metal WHERE name REGEXP '^me';
If you’re matching against a column that is indexed and you have a choice
of using a pattern ,MySQL can use the index to narrow the
search for a pattern that begins with a literal string. Also, a LIKE comparison with a % in the beginning can be slow
due to the optimizer checking the entire content of the string.
多条件进行查询,AND,OR, NOT,XOR
SELECT city, city_id FROM sakila.city WHERE city_id = 3 OR city_id = 4
当AND和OR组合使用时,要注意执行顺序,优先级,AND的执行顺序高于OR,不过可以使用括号,改变优先级
SELECT city, city_id FROM sakila.city WHERE (city_id = 3 OR city_id = 4) AND country_id = 60;
SELECT fid, title FROM sakila.film_list WHERE FID < 7 AND NOT (FID = 4 OR FID = 6);
Order by 字段名,以哪个字段对查询结果进行排序,可以多个字段。order by放到select 语句的最后
SELECT address, district FROM sakila.address ORDER BY district ASC, address DESC; SELECT address, district FROM sakila.address ORDER BY district, address;
LIMIT: 一个参数限制返回的条数,二个参数,第一个参数是offset(从哪一条数据开始返回,从0开始计算),第二个参数是返回最多几条
SELECT name FROM customer_list LIMIT 10; SELECT name FROM sakila.customer_list LIMIT 5, 5;
多表关联join,ON指定组成条件所需的列,告诉 MySQL 保存表之间关系的列
SELECT city, country FROM sakila.city INNER JOIN sakila.country ON city.country_id = country.country_id WHERE country.country_id < 5 ORDER BY country, city;
如果join条件中用于匹配两个表的列名相同,则可以改用USING子句
SELECT city, country FROM sakila.city INNER JOIN sakila.country USING (country_id) WHERE country.country_id < 5 ORDER BY country, city;
mysql语句,以\G 结尾,结果会以行显示
别名:使用AS, 字段别名,计算字段,就是表中没有字段,这个字段是计算出来的, 但是计算字段的名字呢? 实际上,它没有名字,使用as 起个别名
SELECT first_name AS 'First Name' FROM sakila.actor;
SELECT CONCAT(first_name, ' ', last_name, ' played in ', title) AS movie FROM sakila.actor JOIN sakila.film_actor USING (actor_id) JOIN sakila.film USING (film_id) ORDER BY movie LIMIT 20;
表名起别名:
use sakila; SELECT ac.actor_id, ac.first_name, ac.last_name, fl.title FROM actor AS ac INNER JOIN film_actor AS fla USING (actor_id) INNER JOIN film AS fl USING (film_id) WHERE fl.title = 'AFFAIR PREJUDICE';
remove the duplicate rows, and produce a set of unique values, add DISTINCT to the query:
SELECT DISTINCT srcuser FROM mail;
函数,字符串函数,DATE_FORMAT(d,'%M %d, %Y'),
CURDATE(), CURTIME(), or NOW() functions to obtain values
expressed in the client session time zone. Use UTC_DATE(),
UTC_TIME(), or UTC_TIMESTAMP() for values in UTC time.
CURRENT_DATE, CURRENT_TIME, and CURRENT_TIMESTAMP are
synonyms for CURDATE(), CURTIME(), and NOW(), respectively.
聚合函数:they operate on aggregates (groups) of values。可以对整张表进行操作,得出一个值,也可以和groupby一起使用,group by 把整张表分组,分成一个个子集,聚合函数,对每一个子集进行操作得出一个体。没有group by,整张表就是一个组。
To count the number of unique values in a column, use COUNT(DISTINCT):选择中的distinct, distinct 要放到所有列名的前面,所有列的值的组合只要是唯一的,就可以出现在搜索结果中,
A summary operation that uses no aggregate functions is determining the
unique values or rows in a dataset. Do this with DISTINCT
SELECT COUNT(DISTINCT srcuser) FROM mail;
distinct: The DISTINCT clause applies to the query output and removes rows that have identical values in the columns selected for output in the query. To remove duplicates, MySQL needs to sort the output. If indexes are available that are in the same order as required for the sort, or the data itself is in an order that’s useful, this process has very little overhead. However, for large tables and without an easy way of accessing the data in the right order, sorting can be very slow. You should use DISTINCT (and other aggregate functions) with caution on large datasets. If you do use it, you can check its behavior using the EXPLAIN statement
where 中不能使用聚合函数,SELECT MAX(pop), name FROM states WHERE pop = MAX(pop); The statement fails because SQL uses the WHERE clause to determine which rows to select, but the value of an aggregate function is known only after selecting the rows from which the function’s value is determined! So, in a sense, the statement is self-contradictory.
SELECT pop AS 'highest population', name FROM states WHERE pop = (SELECT MAX(pop) FROM states);
分组:对数据进行分组,然后对每个组而不是整个结果集执行聚合操作,聚合函数:count计算行数,count(*)把所有行都加起来,不管行的值 是不是null,count(字段名)则仅把值为非null的行加起来,可以使用count(distinct 字段句)统计去重的行数。
SELECT COUNT(email) FROM customer;
还有min(), max(), sum(), avg()聚合函数,对一组行进行操作(计算)并返回单个值,计算过程中会忽略NULL。分组之后,要对符合条件的组进行操作,使用having 来筛选满足条件的组。分组之后,只能查询分组字段和使用聚合函数对分组后的数组进行统计,求和和取平均值等。HAVING 子句必须包含 SELECT 子句中列出的表达式或列
多表查询:必须指定要包含的所有表以及它们之间的关系。
SELECT title, COUNT(rental_id) AS num_rented FROM film INNER JOIN inventory USING (film_id) INNER JOIN rental USING (inventory_id) GROUP BY title HAVING num_rented > 30 ORDER BY num_rented DESC LIMIT 5;
大多数连接将一个表中的行与另一个表中的行关联起来。但有时,您希望包含没有相关行的行,这样称为外连接。使用外连接时,必须使用 RIGHT 或 LEFT 关键字来指定哪个表包含所有行的。在左连接中,左表(负责驱动的表)中的每一行都会被处理并输出,如果第二个表中存在匹配数据,则输出其中的数据,如果第二个表中没有匹配数据,则输出 NULL 值。
自连接:一个表当做两个表进行使用,使用别名
SELECT c1.cust_id, c1.cust_name, c1.cust_contact FROM Customers AS c1, Customers AS c2 WHERE c1.cust_name = c2.cust_name AND c2.cust_contact = 'Jim Jones'; The WHERE clause first joins the tables and then filters the data by cust_contact in the second table to return only the wanted data.
nested query, 当nest query返回一行一列,可以把它赋值给一个值,可以进行比较大少,
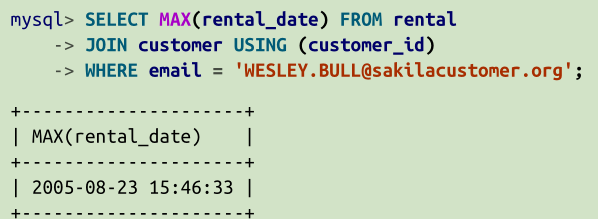
然后

当返回一列多行时,就相当于一个数组,可以使用 in( = Any) 子查询,> any(或some) 子查询,<= All 字查询, NOT IN。 当子查询返回多行多列时,要使用特殊的语法,
mysql> SELECT emp_no, YEAR(from_date) AS fd -> FROM titles WHERE title = 'Manager' AND -> (emp_no, YEAR(from_date)) IN -> (SELECT emp_no, YEAR(from_date) -> FROM titles WHERE title <> 'Manager');
nest Query
mysql> SELECT first_name, last_name FROM staff -> WHERE EXISTS (SELECT * FROM customer -> WHERE customer.first_name = staff.first_name -> AND customer.last_name = staff.last_name);
在子查询中,子查询语句可以访问外查询中列出的表。在这个例子,staff.first_name和staff.last_name 是作为常量提供给子语句,然后和 customer 的first_name和last_name相比较,比如匹配成功,子查询返回true,外查询那一行记录就出现在结果集中。举例:比如外查询中,staff表中的一行记录,first_name和 last_name 是 Jon and Stephens , 子查询返回false,因为SELECT * FROM customer WHERE first_name = 'Jon' and last_name = 'Stephens' 没有查到任何记录,所以 staff表中的这一行记录就不会出现结果集中。再比如staff 表中的记录,first_name和 last_name 是 Mike and Himily, 子查询返回true,因为SELECT * FROM customer WHERE first_name = 'Jon' and last_name = 'Stephens' 返回一条记录,staff表中这一行,就出现在结果集中。
子查询不止在where中,还可以在from中, select 返回的是一个表(多行多列)
mysql> SELECT emp_no, monthly_salary FROM
-> (SELECT emp_no, salary/12 AS monthly_salary FROM salaries) AS ms
-> LIMIT 5;
sql语句的执行顺序:执行from-> join -> on -> where -> group by -> having -> select -> distinct -> order by
事务:事务是作为一个逻辑工作单元在数据库上执行的操作(使用一个或多个 SQL 语句)。事务中的所有 SQL 语句的修改要么作为一个单元提交(应用于数据库)要么回滚(从数据库撤消),而不能是部分修改。事务就是要保证一组数据库操作,要么全部成功,要么全部失败。数据库事务必须是原子性、一致性、隔离性、持久性(ACID ( Atomicity 、 Consistency 、 Isolation 、 Durability )。
原子性,就是想么同时成功,要么同时失败。一致性,事务执行之前,和事务执行之后,数据库中的数据是一致的。隔离性:数据库允许多个事务同时执行,多个并行的事务之间不能相互影响。持久性:事务完成后,对数据库的影响是持久的
MySQL 每秒可以处理数千个请求,并且并行处理它们,而不是串行处理,有多个事务同时执行时,有可能出现脏读,不可重复读,和幻读。脏读就是一个事务A读取到另一个事务B还没有提交的数据,事务B只是执行了数据的更改,还没有commit,事务A就读到了更改后的数据。如果事务B回滚了,事务A的数据就不对了。不可重复读:在事务A 中做了两次查询,一个在T1时间,一个在T2时间,结果不一致,因为在T1 和T2 时间间隔内,另一个事务做了提交(更新)。初始的查询不可重复,因为再一次查询时,返回了不同的结果。幻读:事务A正在执行,在事务A读取的记录范围内,事务B添加或删除了一行记录并提交了,导致在事务A中,如要再次执行查询,会得到不同的行数,幻读是因为没有range 锁。
MySQL事务管理:默认情况下,DML指令执行时,自动提交。当一个DML指令执行后,自动同步到数据库中。开启事务,就关闭自动提交,需要手动提交(comit, rollback)
mysql 默认的隔离级别是可重复读,在同一个事务中,所有查询结果都是一致的,也就是说,第一个查询语句返回的结果和以后所有查询语句返回的结果是一致的。 In this mode, InnoDB locks the index range scanned, using gap locks or next-key locks to block insertions by other sessions into any gaps within that range.
比如在一个事务中,SELECT * FROM person WHERE i BETWEEN 1 AND 4; 返回
+---+----------+
| i | name |
+---+----------+
| 1 | Vinicius |
| 2 | Sergey |
| 3 | Iwo |
| 4 | Peter |
+---+----------+
然后在第二个事务中,UPDATE person SET name = 'Kuzmichev' WHERE i=2; 然后commit ; 然后SELECT * FROM person WHERE i BETWEEN 1 AND 4;
i | name |
+---+-----------+
| 1 | Vinicius |
| 2 | Kuzmichev |
| 3 | Iwo |
| 4 | Peter
但在在第一个事务中,SELECT * FROM person WHERE i BETWEEN 1 AND 4;
+---+----------+
| i | name |
+---+----------+
| 1 | Vinicius |
| 2 | Sergey |
| 3 | Iwo |
| 4 | Peter |
+---+----------+
用锁实现隔离级别:锁有表级锁,
使用select 实现插入数据。
mysql> INSERT INTO recommend (film_id, language_id, release_year, title, length) -> SELECT film_id, language_id, release_year, title, length -> FROM film ORDER BY RAND() LIMIT 10;
The overall effect is that the rows output from the SELECT statement is inserted into the destination table by the INSERT INTO statement.
Note also that the column names don’t need to be the same for the SELECT and the INSERT
mysql> INSERT INTO art.people (person_id, first_name, last_name) -> SELECT actor_id, first_name, last_name FROM sakila.actor;
Sometimes, you’ll encounter duplication issues when inserting with a SELECT state‐
ment. If you want MySQL to ignore this and keep going, add the IGNORE keyword after INSERT
mysql> INSERT IGNORE INTO recommend (film_id, language_id, release_year, -> title, length, sequence_id ) -> SELECT film_id, language_id, release_year, title, length, 1 -> FROM film LIMIT 1;
MySQL doesn’t complain, but it does report that it encountered a duplicate. Note that
the data is not changed; all we did was ignore the error.
mysql> SHOW WARNINGS;
+---------+------+-------------------------------------------------+
| Level | Code | Message |
+---------+------+-------------------------------------------------+
| Warning | 1062 | Duplicate entry '1' for key 'recommend.PRIMARY' |
+---------+------+-------------------------------------------------+
delete or update rows from more than one table in one statement, and
you can use those or other tables to decide what rows to change.
删除:
DELETE FROM inventory USING inventory LEFT JOIN rental USING (inventory_id) WHERE rental.inventory_id IS NULL;
USING indicates that a filter query (a join or otherwise) is going to follow. 当删除多张表时,由于外键约束,写一个query语句可能会报错。
DELETE FROM film_actor, film USING film JOIN film_actor USING (film_id) LEFT JOIN inventory USING (film_id) WHERE inventory.film_id IS NULL;
ERROR 1451 (23000): Cannot delete or update a parent row:
a foreign key constraint fails (
`sakila`.`film_actor`, CONSTRAINT `fk_film_actor_film`
FOREIGN KEY (`film_id`) REFERENCES `film` (`film_id`)
ON DELETE RESTRICT ON UPDATE CASCADE)
这时解决办法有两种,一种是开启事务,依次删除,
mysql> BEGIN; Query OK, 0 rows affected (0.00 sec) mysql> DELETE FROM film_actor USING -> film JOIN film_actor USING (film_id) -> LEFT JOIN inventory USING (film_id) -> WHERE inventory.film_id IS NULL; Query OK, 216 rows affected (0.01 sec) mysql> DELETE FROM film_category USING -> film JOIN film_category USING (film_id) -> LEFT JOIN inventory USING (film_id) -> WHERE inventory.film_id IS NULL; Query OK, 42 rows affected (0.00 sec) mysql> DELETE FROM film USING -> film LEFT JOIN inventory USING (film_id) -> WHERE inventory.film_id IS NULL; Query OK, 42 rows affected (0.00 sec) mysql> COMMIT;
一种是SET foreign_key_checks=0; 删除前去掉外键检查,删除成功后,再加上外键检查
mysql> SET foreign_key_checks=0; Query OK, 0 rows affected (0.00 sec) mysql> BEGIN; Query OK, 0 rows affected (0.00 sec) mysql> DELETE FROM film, film_actor, film_category -> USING film JOIN film_actor USING (film_id) -> JOIN film_category USING (film_id) -> LEFT JOIN inventory USING (film_id) -> WHERE inventory.film_id IS NULL; Query OK, 300 rows affected (0.03 sec) mysql> commit; Query OK, 0 rows affected (0.00 sec) mysql> SET foreign_key_checks=1;
但不建议这么做。
利用多表信息更新,就是在update 表的后面,加join,提供条件。
mysql> UPDATE film JOIN film_category USING (film_id) -> JOIN category USING (category_id) -> SET rating = 'R' WHERE category.name = 'Horror';
无论是多表删除还是多表更新,都不能使用order by 和limit,更新的时候,还不能更新子查询中要读取的表。
Replace:它会先删除,再插入,所以,如果有外键约束,它还是会报错,
REPLACE INTO actor VALUES (1, 'Penelope', 'Guiness', NOW());
REPLACE INTO actor_2 (actor_id, first_name, last_name)
VALUES (1, 'Penelope', 'Guiness');
REPLACE actor_2 SET actor_id = 1,
-> first_name = 'Penelope', last_name = 'Guiness';
Note that if you don’t specify a value for a col‐
umn, it’s set to its default value, just like for INSERT
In contrast, if there isn’t a matching row in a REPLACE statement, it acts just like an
INSERT :
mysql> REPLACE actor_2 (actor_id, first_name, last_name)
-> VALUES (1000, 'William', 'Dyer');
Query OK, 1 row affected (0.00 sec)
You can tell that only the insert occurred, since only one row was affected.
If a table doesn’t have a primary key or another unique key, replacing doesn’t make
sense. This is because there’s no way of uniquely identifying a matching row in order
to delete it. When you use REPLACE on such a table, its behavior is identical to INSERT
mysql 提供了一个非标准的 INSERT ... ON DUPLICATE KEY UPDATE,和replace 功能相似,
mysql> INSERT INTO actor_3 (actor_id, first_name, last_name) VALUES -> (1, 'Penelope', 'Guiness'), (2, 'Nick', 'Wahlberg'), -> (3, 'Ed', 'Chase'), (1001, 'William', 'Dyer') -> ON DUPLICATE KEY UPDATE first_name = VALUES(first_name), -> last_name = VALUES(last_name);

The EXPLAIN statement tells you how MySQL is going to do the job in terms of the indexes, keys, and steps it’ll take if you ask it to resolve a query. 比如:EXPLAIN SELECT * FROM actor。它会返回许多字段。
id: first and only select 语句,在这个query中,如果使用子查询,每一个select可能会产生不同的id。
select_type: SIMPLE, 表示,它没有使用子查询,也没有使用UNION
type: all: meaning all rows in the table are processed by this SELECT statement.
possible_keys: 可能使用到的key。key:真正使用的key。
rows:MySQL 需要处理的行数。filtered: query的语句返回的行数占整个table行数的比例,100表示整个表的所有行都返回了。
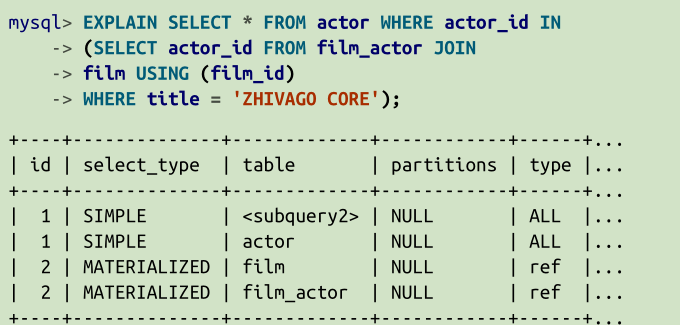
<subquery2> ? That’s a virtual
table name used here because the optimizer materialized the results of the subquery,
or in other words stored them in a temporary table in memory. You can see that the
query with an id of 2 has a select_type of MATERIALIZED . The outside query ( id 1)
will look up the results of the inner query ( id 2) from this temporary table. This is
just one of many optimizations that MySQL can perform while executing complex
queries.
Mysql8 提供了 EXPLAIN ANALYZE
mysql> EXPLAIN ANALYZE SELECT first_name, last_name -> FROM actor JOIN film_actor USING (actor_id) -> JOIN film USING (film_id) -> WHERE title = 'ZHIVAGO CORE'\G \G 表示不用表格
Key:
创建索引,在创建表的时候,index或key 索引名 (要添加索引的字段名)比如 KEY idx_names_email (first_name, last_name, email));
For MySQL to be able to use an index, the query needs to meet both the following conditions:
The leftmost column listed in the KEY (or PRIMARY KEY ) clause must be in the query.
2. The query must contain no OR clauses for columns that aren’t indexed.
mysql> SELECT * FROM customer_mod WHERE
-> last_name = 'Williams' AND
-> email = 'rose.w@nonexistent.edu';
以上就不能用索引
MySQL语句的执行过程,比如 select * from T where id = 10; 是怎么执行的?下图是MySQL的基本架构

连接数据库,等待你的是连接器,它负责建立连接,验证身份,获取权限,维护和管理连接。客户端如果太长时间没动静,连接器就会自动将它断开。这个时间是由参数 wait_timeout 控制的,默认值是 8 小时。数据库长连接是指客户端持续有请求,则一直使用同一个连接。短连接是指每次执行完很少的几次查询就断开连接,下次查询再重新建立一个。建立连接的过程比较复杂,建议尽量减少建立连接的动作,也就是尽量使用长连接。

分析器 先做词法分析,做什么查询,表名,条件,
MySQL 从你输入的 "select" 这个关键字识别出来,这是一个查询语句。它也要把字符串 “T” 识别
成 “ 表名 T” ,把字符串 “ID” 识别成 “ 列 ID” 。 再做语法分析,
根据词法分析的结果,语法分析器会根据语法规则,
判断你输入的这个 SQL 语句是否满足 MySQL 语法。如果不满足,就报错语法错误。
优化器:
优化器是在表里面有多个索引的时候,决定使用哪个索引;或者在一个语句有多表关联( join )
的时候,决定各个表的连接顺序,决定语句的执行方案
执行器:执行语句,不过要先判断你对表有没有查询权限,如果没有,返回权限错误,如果有,调用引擎提供在接口。

更新语句和查询语句执行过程一样,只不过,更新流程还涉及两个重要的日志模块, redo log (重做日志)和 binlog (归档日志)。更新的时候先写日志,再写磁盘,称为 Write-Ahead Logging。具体来说,当有一条记录更新时,InnoDB 引擎就会先把记录写到 redo log 里面,并更新内存,这个时候更新就算完成了。同时, InnoDB 引擎会在适当的时候,将这个操作记录更新到磁盘里面,而这个更新往往是在系统比较空闲的时候做,但如果更新较多,redo log 写满了,只好将操作记录先写到磁盘中,再把redo log 清空(也可以写一部分,清空一部分redo log)。
InnoDB 的 redo log 是固定大小的,比如可以配置为一组 4 个文件,每个文件的大小是
1GB ,就是可以记录 4GB 的操作。从头开始写,写到末尾就又回到开头循环

write pos 是当前记录的位置,一边写一边后移,写到第 3 号文件末尾后就回到 0 号文件开头。
checkpoint 是当前要擦除的位置,也是往后推移并且循环的,擦除记录前要把记录更新到数据文
件。
write pos 和 checkpoint 之间的是 “ 粉板 ” 上还空着的部分,可以用来记录新的操作。如果 write pos
追上 checkpoint ,表示 “ 粉板 ” 满了,这时候不能再执行新的更新,得停下来先擦掉一些记录,把
checkpoint 推进一下。
有了 redo log , InnoDB 就可以保证即使数据库发生异常重启,之前提交的记录都不会丢失,这个
能力称为 crash-safe
redo log 是 InnoDB 引擎特有的日志,而 Server 层也有自己的日志,称为 binlog (归档日志)。
redo log 是物理日志,记录的是 “ 在某个数据页上做了什么修改 ” ; binlog 是逻辑日志,记录的
是这个语句的原始逻辑,比如 “ 给 ID=2 这一行的 c 字段加 1 ” 。
redo log 是循环写的,空间固定会用完; binlog 是可以追加写入的。 “ 追加写 ” 是指 binlog 文件
写到一定大小后会切换到下一个,并不会覆盖以前的日志。
update T set c=c+1 where ID=2; 的执行过程
1. 执行器先找引擎取 ID=2 这一行。 ID 是主键,引擎直接用树搜索找到这一行。如果 ID=2 这一
行所在的数据页本来就在内存中,就直接返回给执行器;否则,需要先从磁盘读入内存,然
后再返回。
2. 执行器拿到引擎给的行数据,把这个值加上 1 ,比如原来是 N ,现在就是 N+1 ,得到新的一行
数据,再调用引擎接口写入这行新数据。
3. 引擎将这行新数据更新到内存中,同时将这个更新操作记录到 redo log 里面,此时 redo log 处
于 prepare 状态。然后告知执行器执行完成了,随时可以提交事务。
4. 执行器生成这个操作的 binlog ,并把 binlog 写入磁盘。
5. 执行器调用引擎的提交事务接口,引擎把刚刚写入的 redo log 改成提交( commit )状态,更
新完成。
redo log 的写入拆成了两个步骤: prepare 和
commit ,这就是 " 两阶段提交 " 。为什么必须有 “ 两阶段提交 ” 呢?这是为了让两份日志之间的逻辑一致

 浙公网安备 33010602011771号
浙公网安备 33010602011771号