buu大杂侩(每日更新?法定节假日除外)
 古人云:君子性非异也,善假于物也
君子的资质秉性跟一般人没有不同,只是君子善于借助外物罢了。
古人云:君子性非异也,善假于物也
君子的资质秉性跟一般人没有不同,只是君子善于借助外物罢了。
sqltest
拿到压缩包进行分级,很像sql注入攻击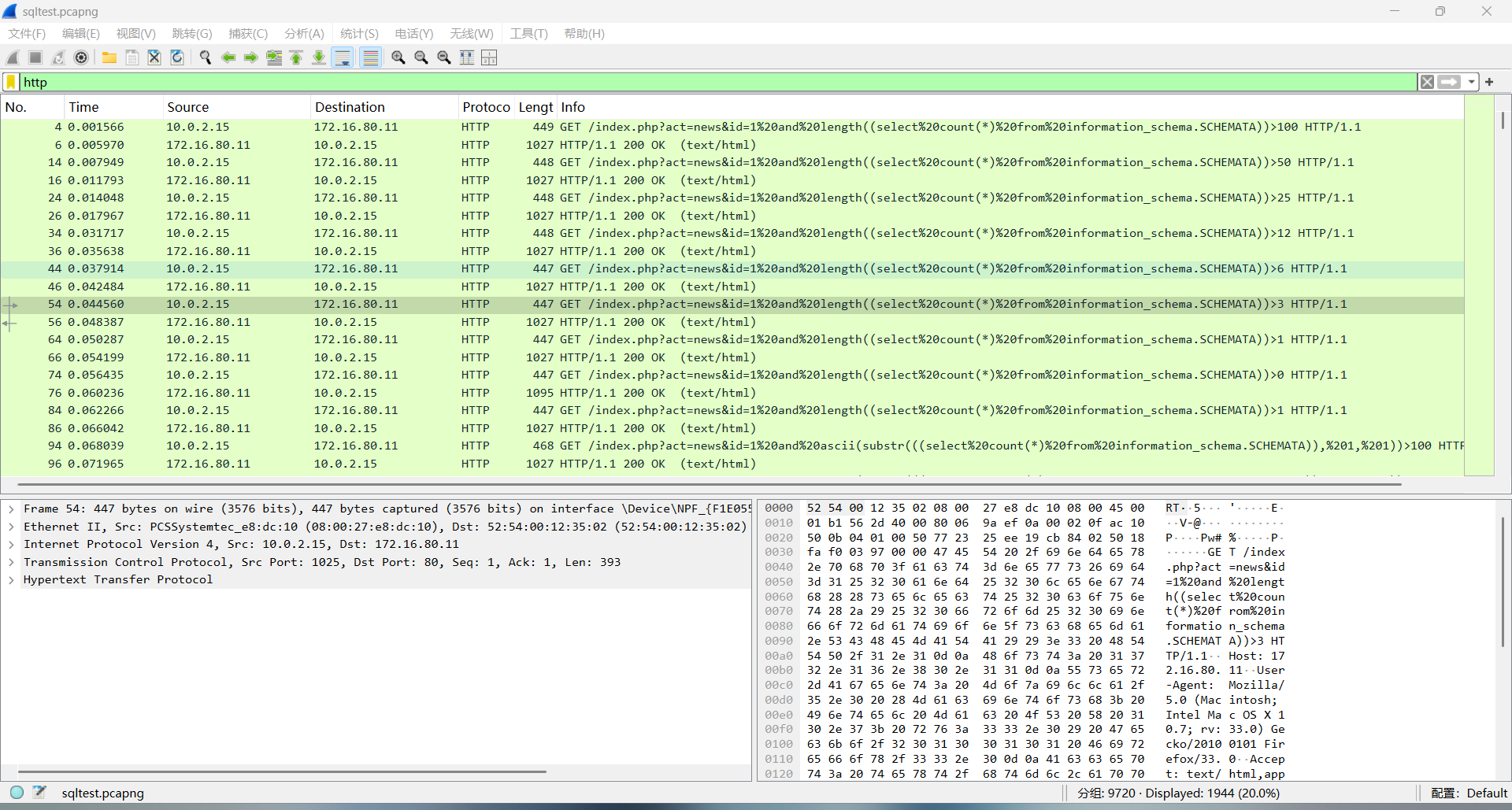
分组字节流导出为csv文件,根据其他人的wp知道这是sql盲注https://blog.csdn.net/tt_npc/article/details/124433203
跟着步骤走,最后将有效的ascii码值进行转换得到flag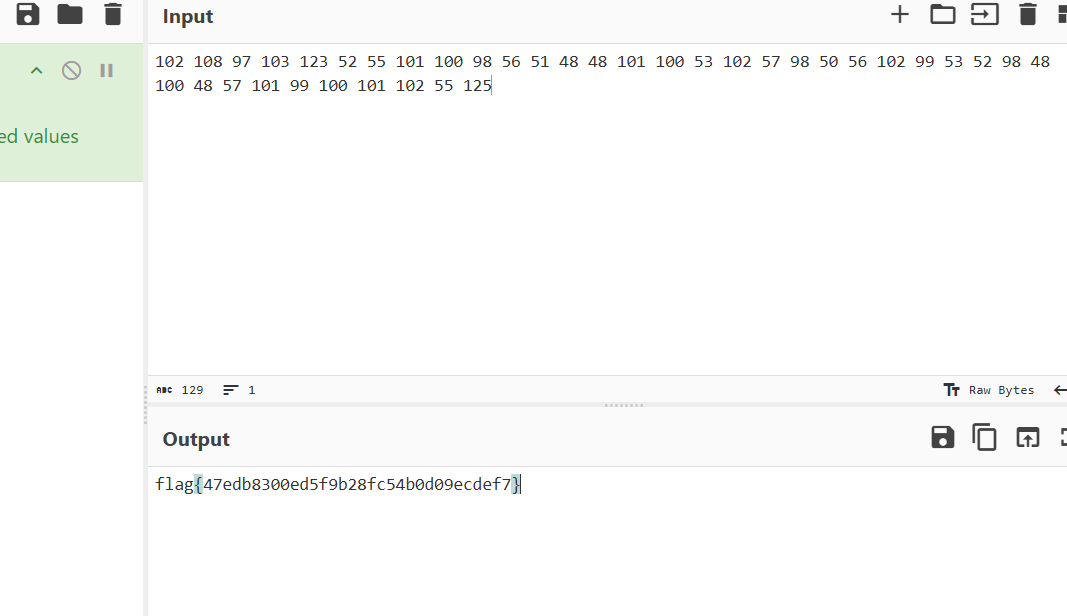
这道题目前的wp太水了,等我拿下sql以后再来看
九连环
下载完以后打开发现一张图片,拖入010发现夹带了很多私货,还有未知块,看来是大有来头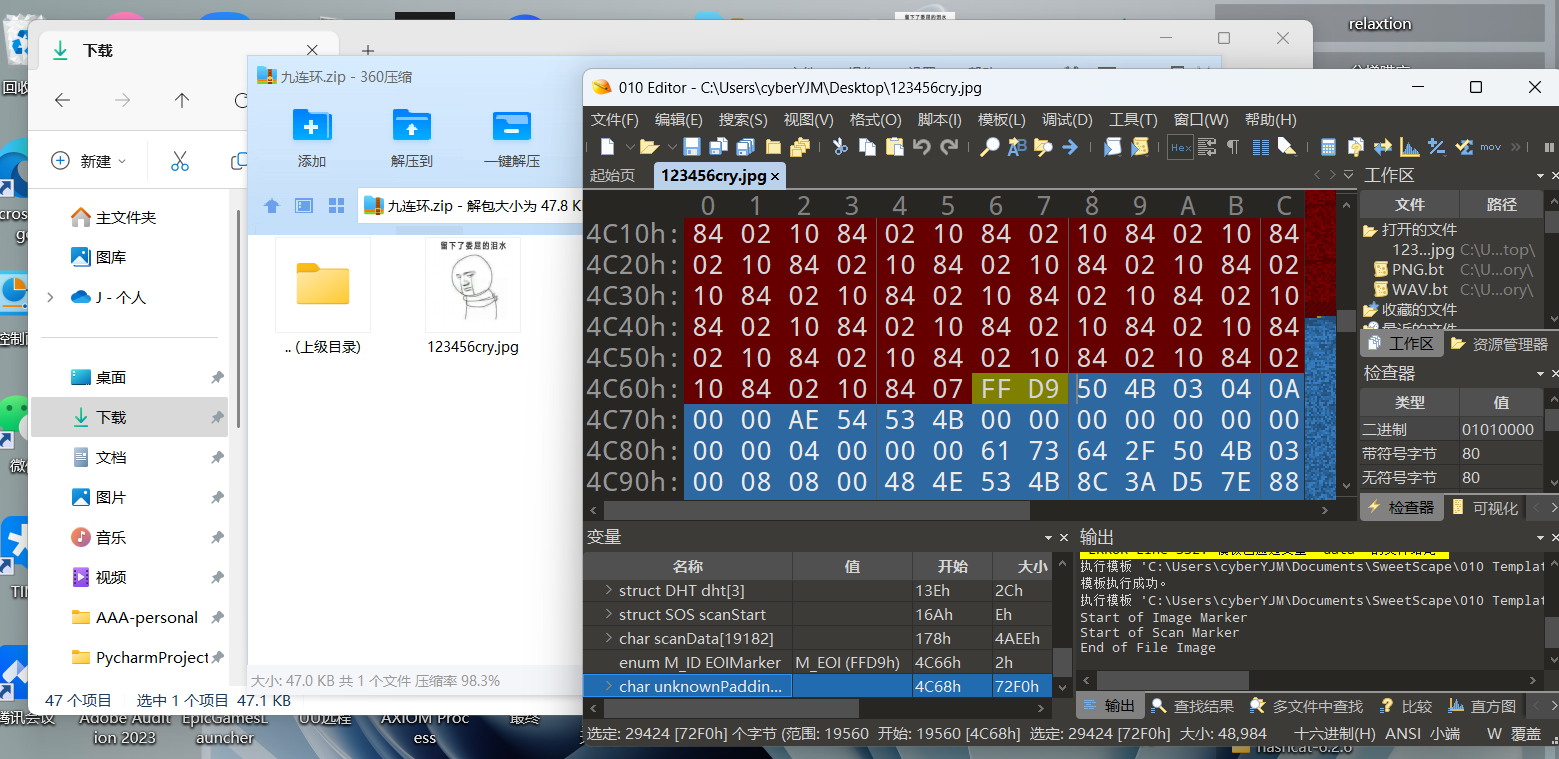
尝试使用binwalk 提取,在提取出的文件夹里发现了一个压缩包和一个asd文件夹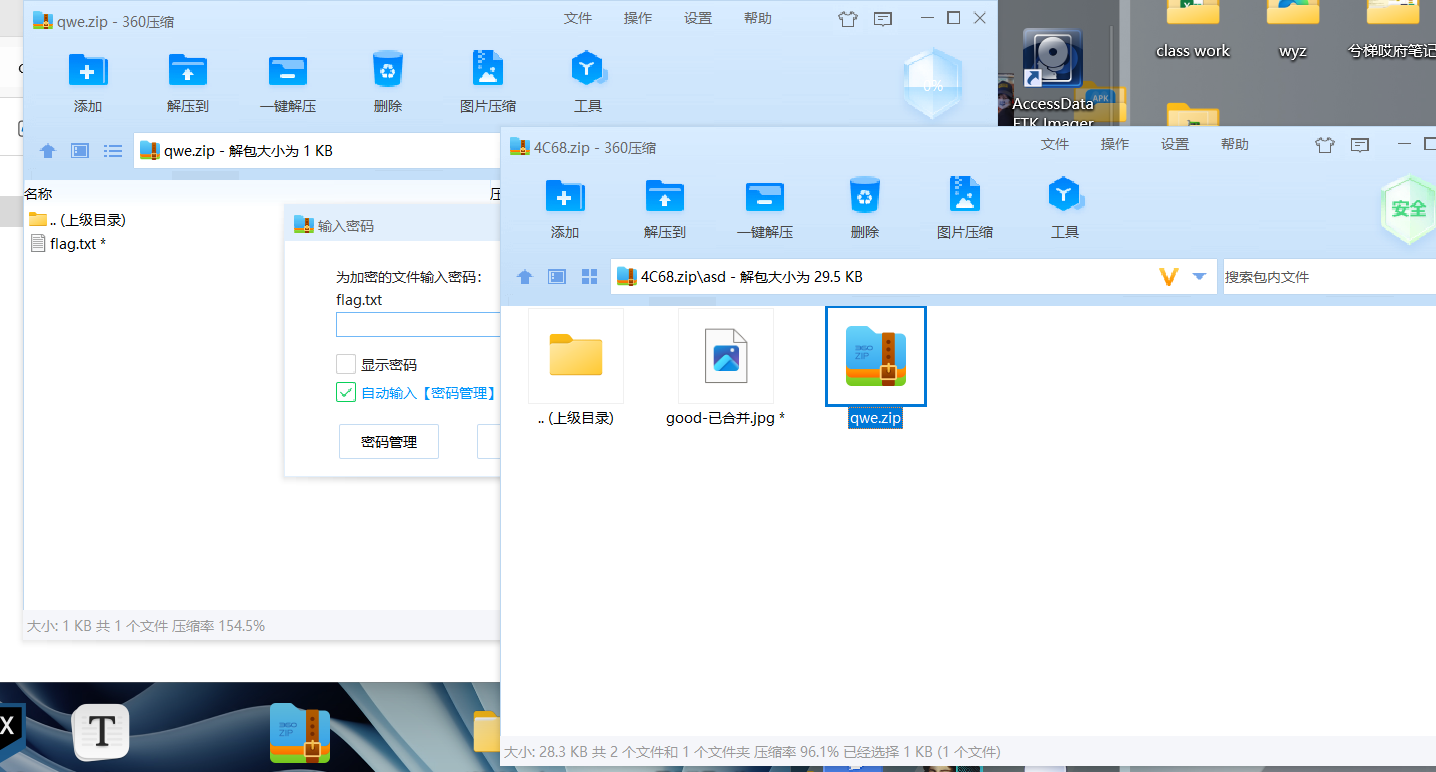
压缩包里发现一个文件夹内包含一个损坏的图片文件和一个压缩包,qwe压缩包内有一个加密的txt
把这个4c68拖到010看一看,发现存在伪加密,其他文件的frflag和deflag都是2048,唯独这个损坏的图片是2049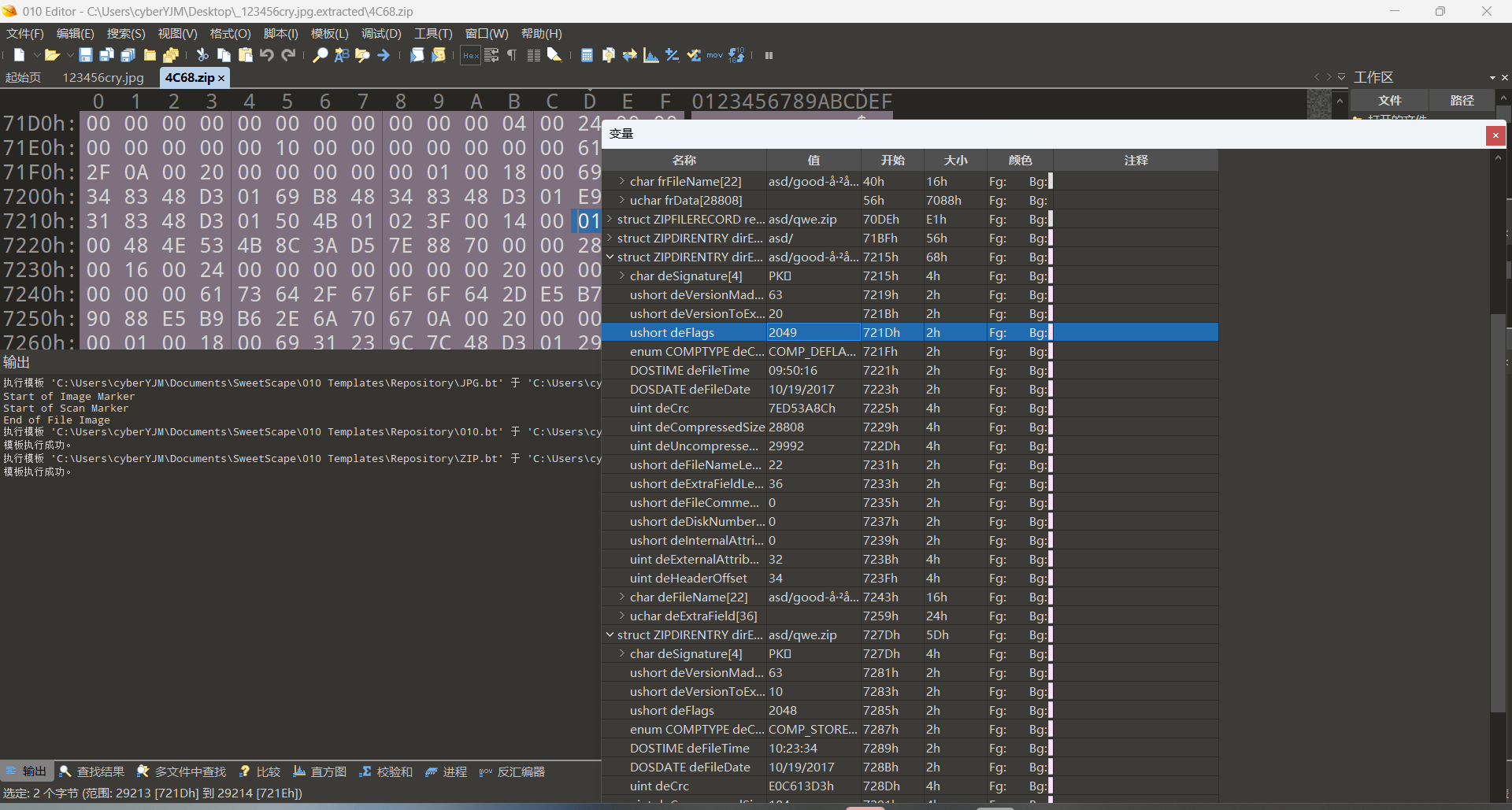
尝试修改,成功修复压缩包,获得图片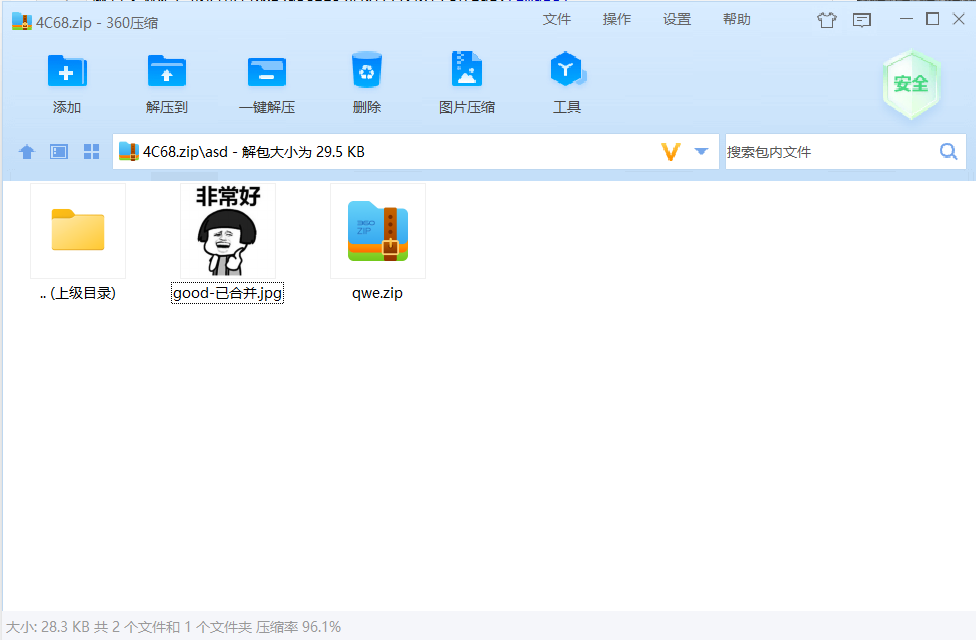
接下来将目光投向这个图片,010查看并未发现异常,考虑到是jpg文件,试试steghide
Steghide支持以下图像格式:JPEG,BMP,WAV,AU文件
使用apt install steghide指令安装,
如果出现Unable to locate package steghide的报错,试试更新软件包列表apt update -y再重新安装
用steghide extract -sf example.jpg指令提取(不会真的有人直接复制吧)
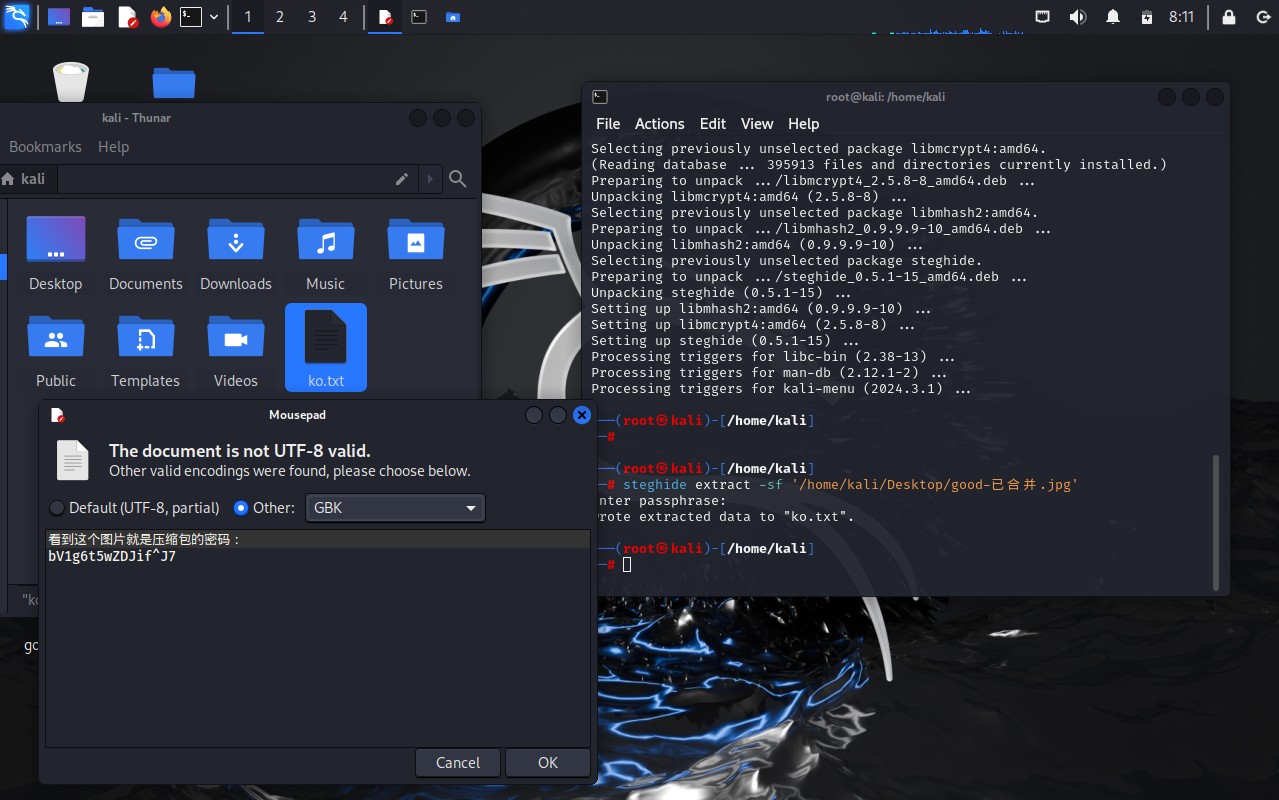
没有密码直接回车就行了,可以看到在home文件夹下生成了一个ko.txt文件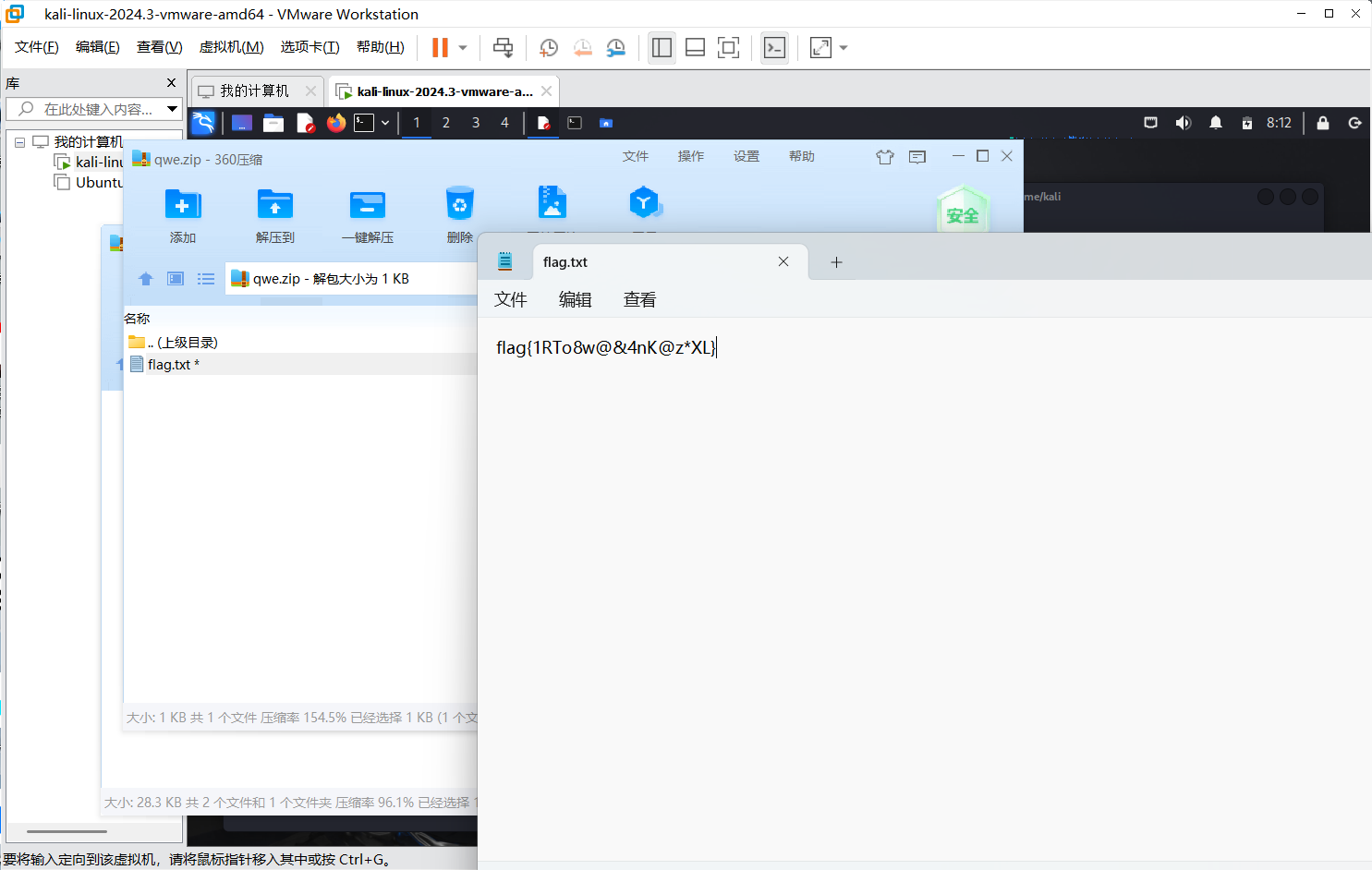
直接拿下
这道题其实卡我很久了,其核心考点在于压缩包伪加密原理(deflag和frflag),以及图片隐写分析(steghide),接下去会重视这两方面
佛系青年
下载压缩包后打开发现存在一个损坏的txt文件,凭借九连环的经验推测是伪(不)加密(欸我讲不清楚反正就是frflag和deflag暗藏玄坤)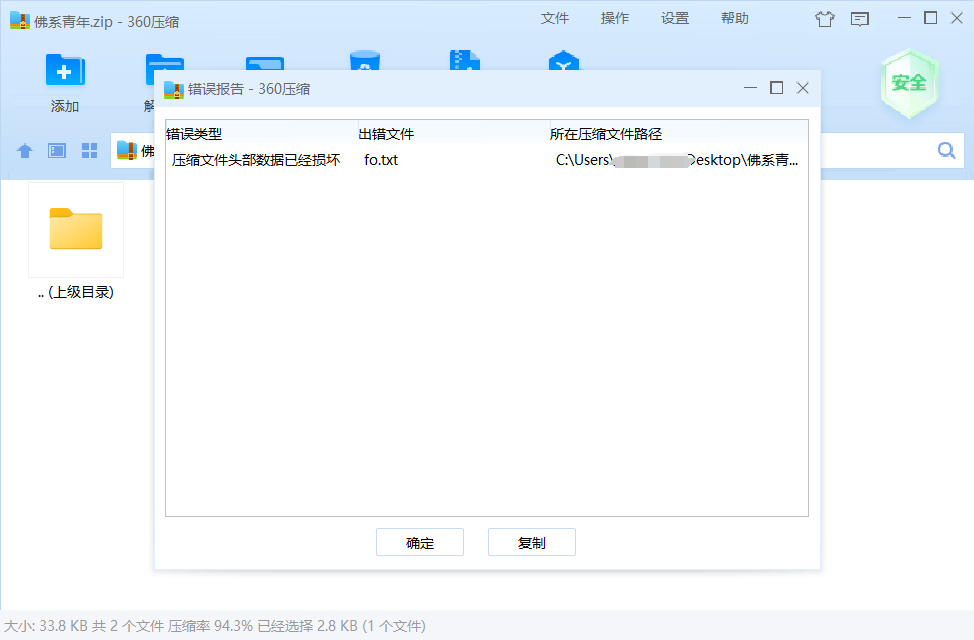
010打开观察发现果然是txt的deflag不对,其他的flag值都是0(未加密),txt的deflag是9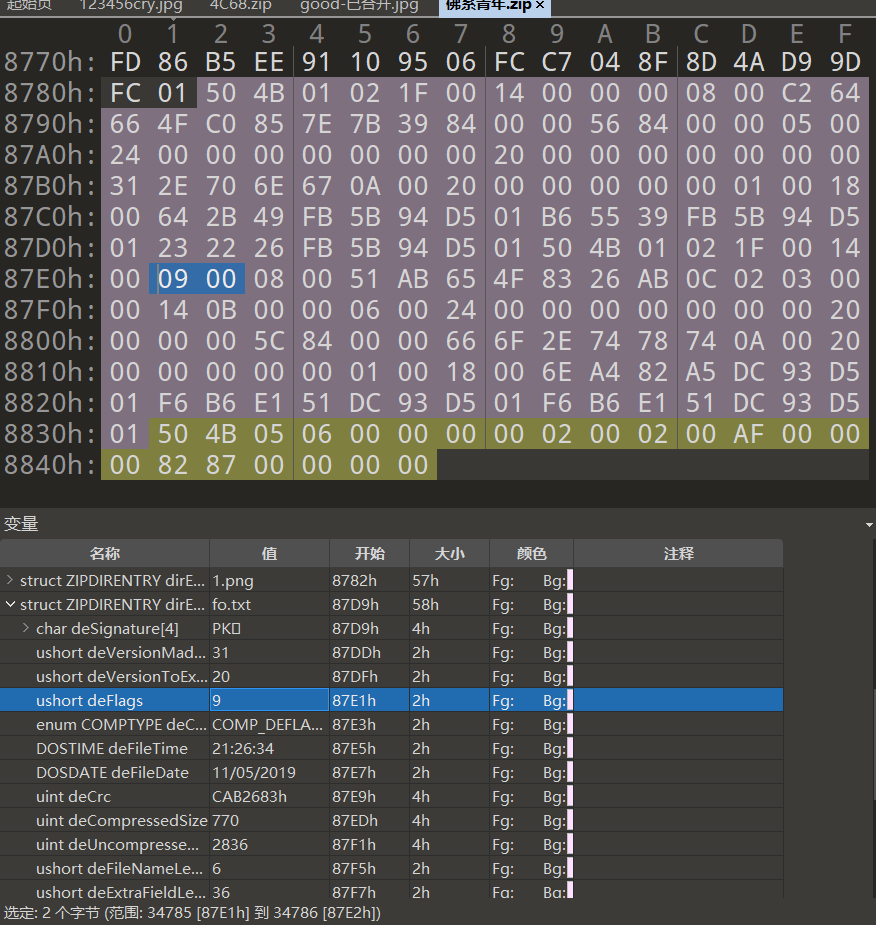
修改后成功打开,发现佛曰
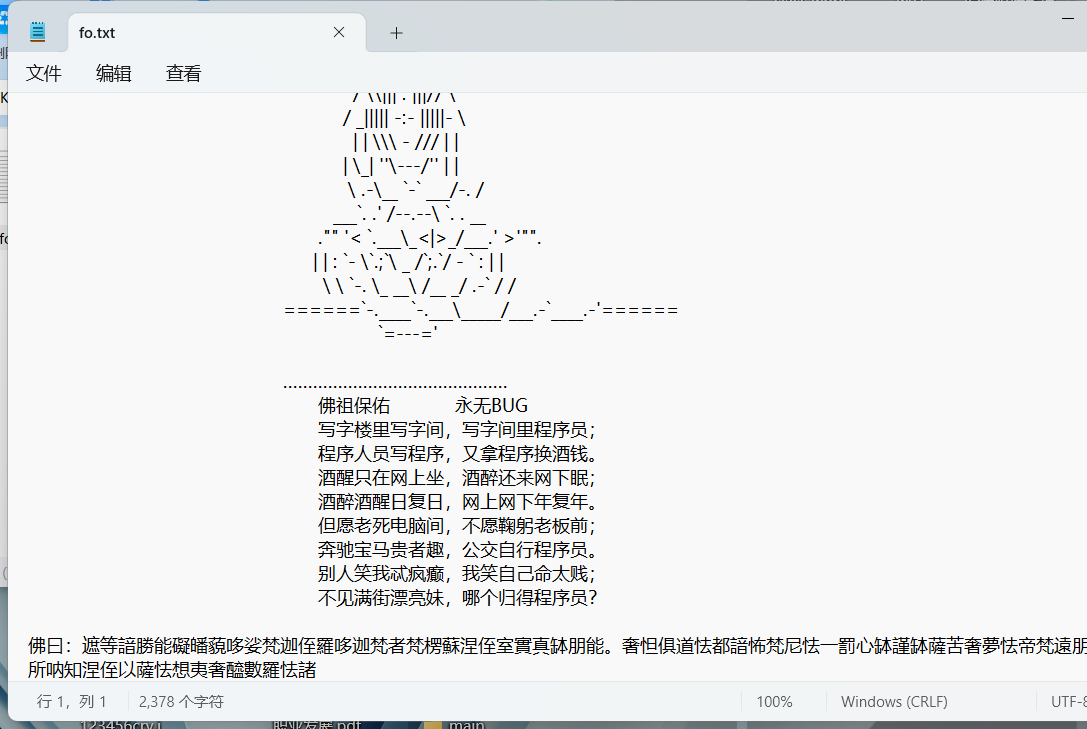
随波逐流一把梭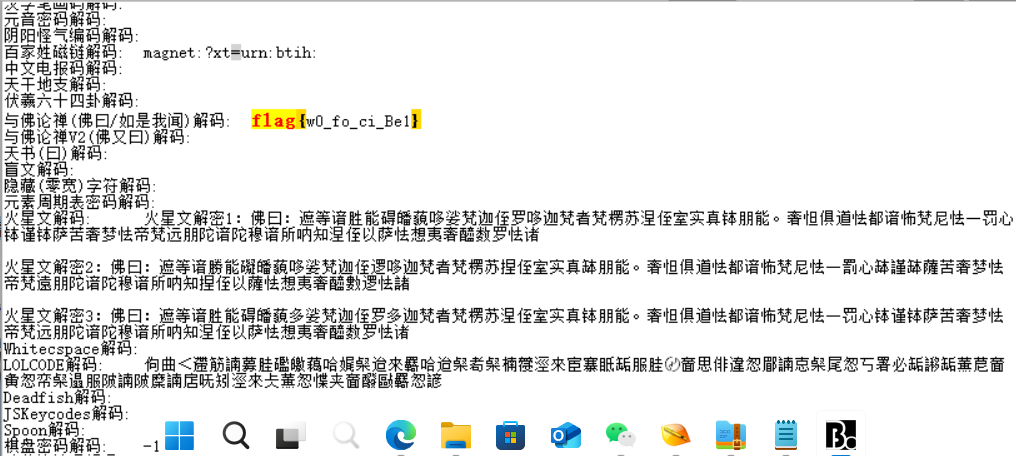
flag{w0_fo_ci_Be1}
考点 伪加密、佛曰编码
梅花香之苦寒来(新工具)
打开压缩包发现只有一张图片,拖入010分析发现jpg图片结束(FFD9)后还存在未知编码(疑似16进制),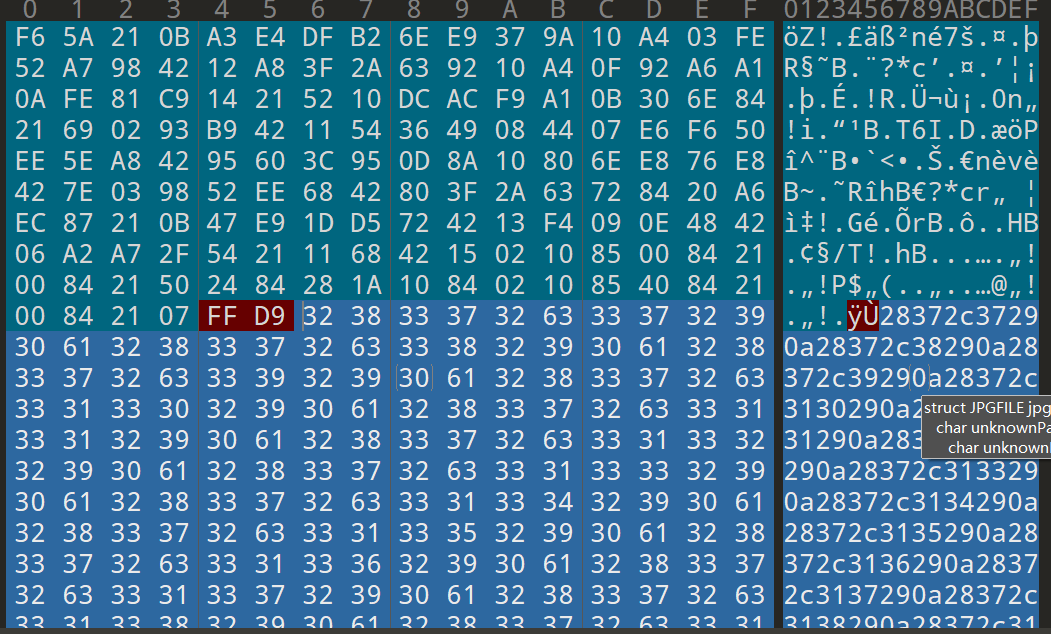
复制到赛博厨师看看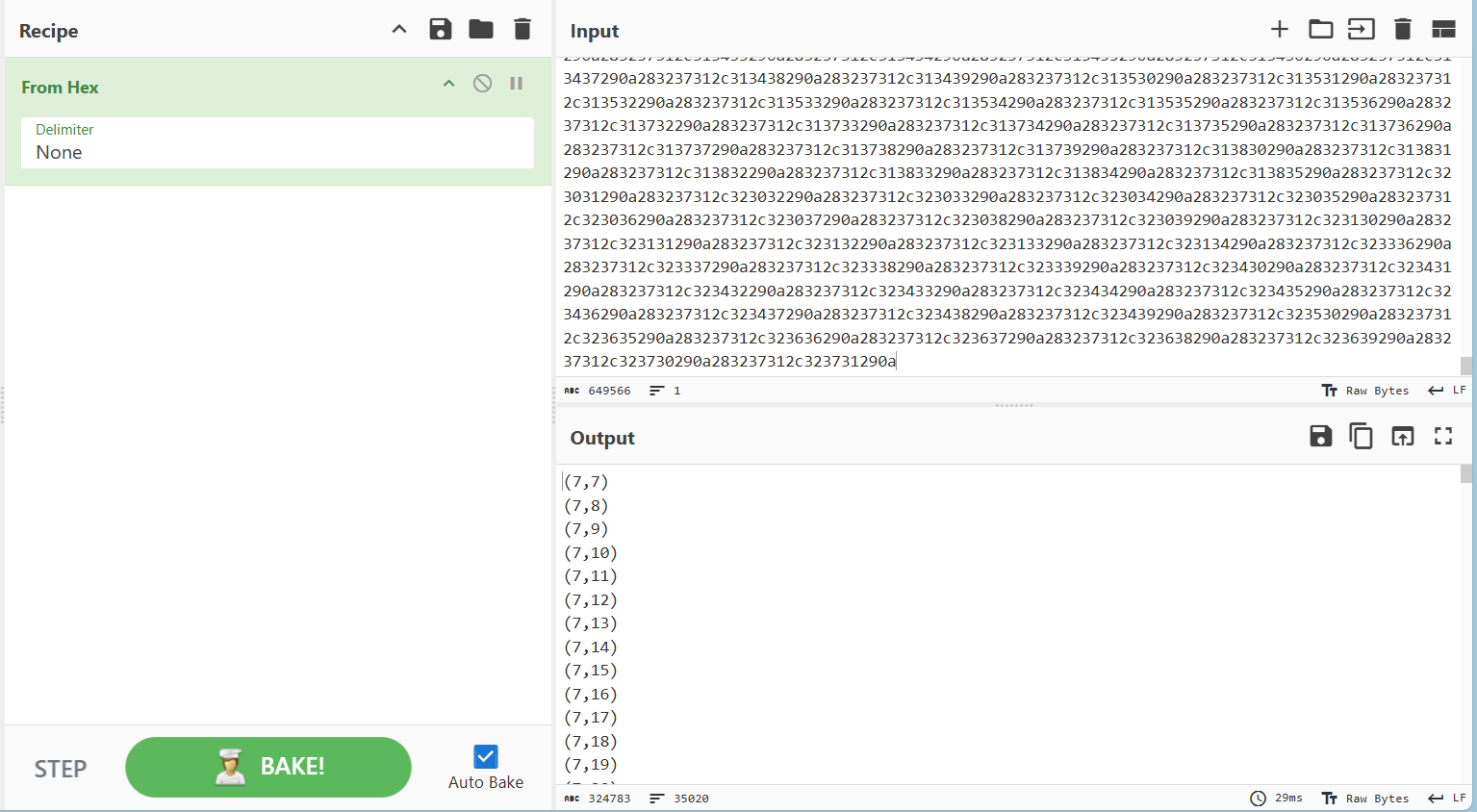
发现神秘坐标轴,猜测要画图然后就不会了,查阅其他师傅的wo得知(在图片的属性里也有画图的提示),要用到gnuplot工具
gnuplot——一个命令行驱动的科学绘图工具,gnuplot既支持命令行交互模式,也支持脚本。
官网:http://www.gnuplot.info/ (关闭代理访问)
十六进制得出的坐标并非工具能够读取的坐标数据,所以还需要用到脚本来转换格式
with open('download.txt', 'r') as res: # 坐标格式文件比如(7,7)
re = res.read()
res.close()
with open('gnuplottxt.txt', 'w') as gnup: # 将转换后的坐标写入gnuplotTxt.txt
re = re.split()
tem = ''
for i in range(0, len(re)):
tem = re[i]
tem = tem.lstrip('(')
tem = tem.rstrip(')')
for j in range(0, len(tem)):
if tem[j] == ',':
tem = tem[:j] + ' ' + tem[j+1:]
gnup.write(tem + '\n')
gnup.close()
得到输出文件后,打开gnuplot程序界面,将他加载到工具中
从其他wp得知可以使用load (gnuplottxt.txt的文件路径,如果直接把txt文件放到gnuplot的文件路径下可以略过这一步)实现文件加载,但我亲自测试后发现并不行,不知道是什么原因
我把文件放到安装目录的bin文件夹中,然后再执行plot "gnuploTtxt.txt"
即可得到一张二维码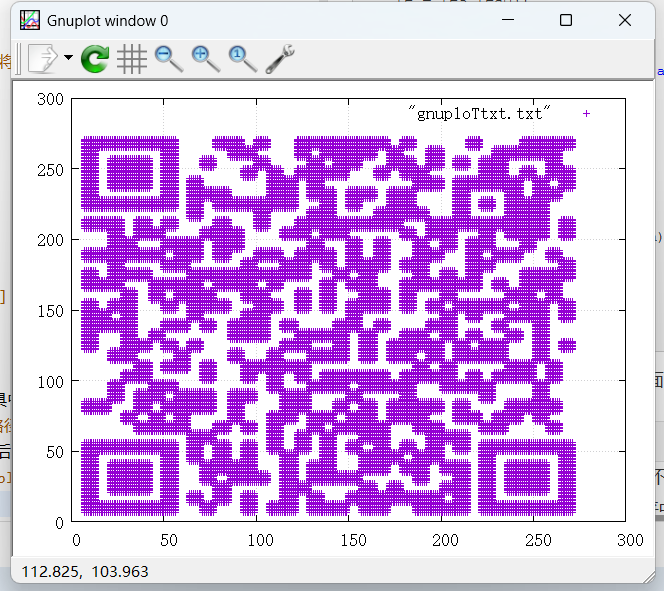
扫码得到flag
flag{40fc0a979f759c8892f4dc045e28b820}
考点 文件结束符后隐藏信息、字符编码转换、坐标画图工具的使用
穿越时空的思念
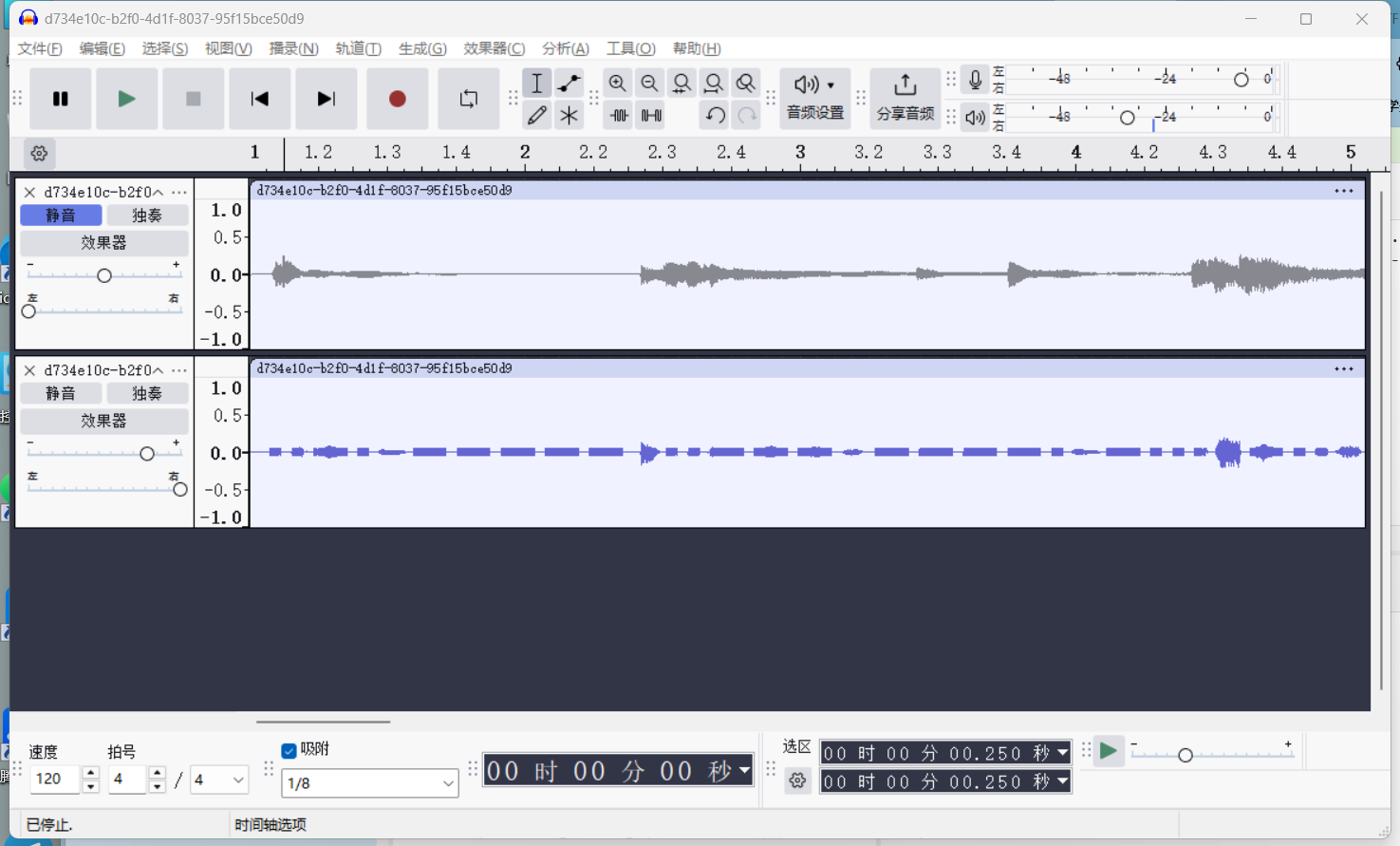
音频直接听发现有莫斯的声音,拖入音频分析文件发现右声道是摩斯电码
直接看吧,还能咋地
..-. ----- ..--- ----. -... -.. -.... ..-. ..... ..... .---- .---- ...-- ----. . . -.. . -... ---.. . ....- ..... .- .---- --... ..... -... ----- --... ---.. -.... 赛博厨师转换
F029BD6F551139EEDEB8E45A175B0786
后面还有一段
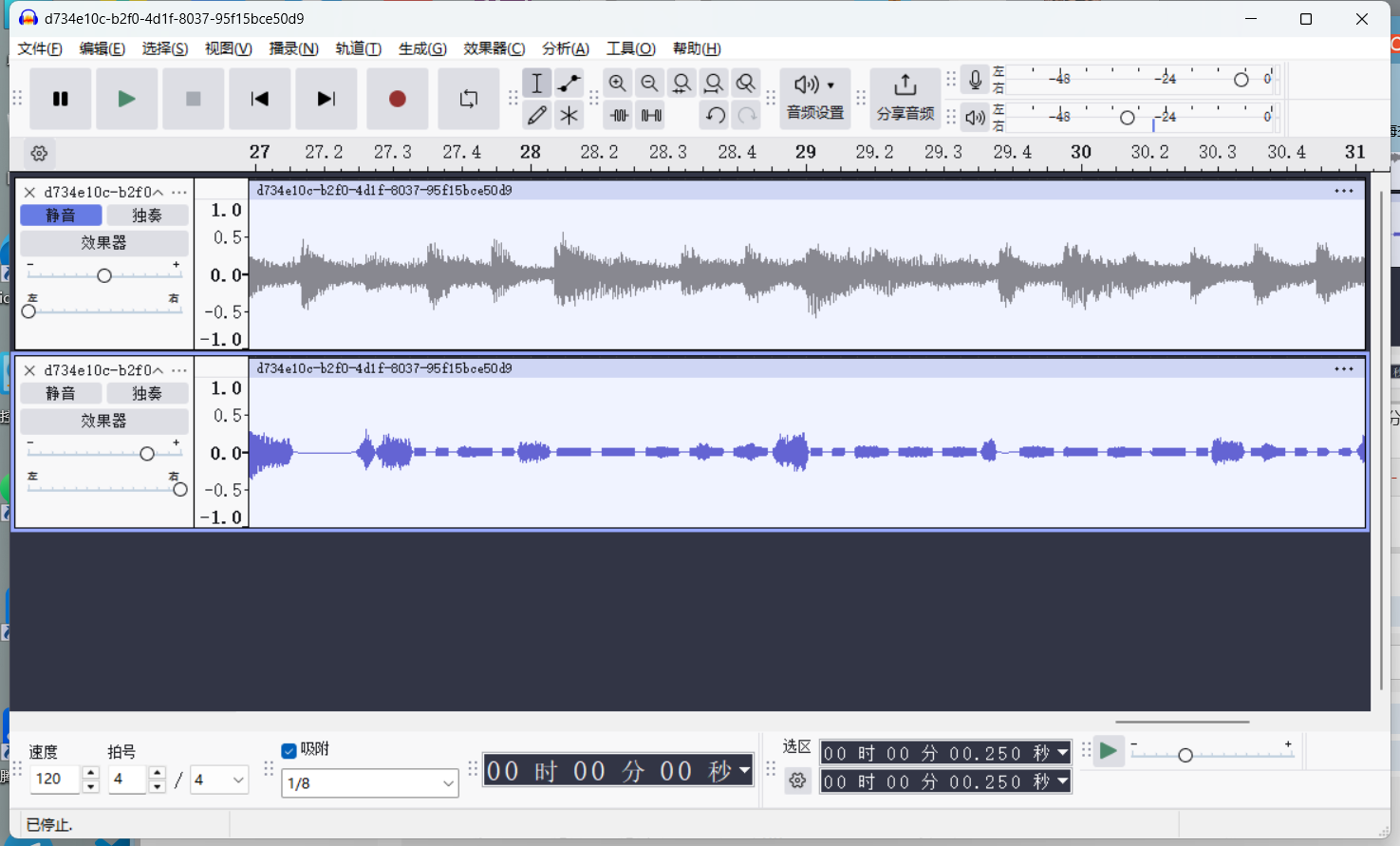
..-. ----- ..--- ----. -... -.. -.... ..-. .....
赛博厨师转换
F029BD6F5
开头重复,将第一段作为flag的内容提交,发现不对
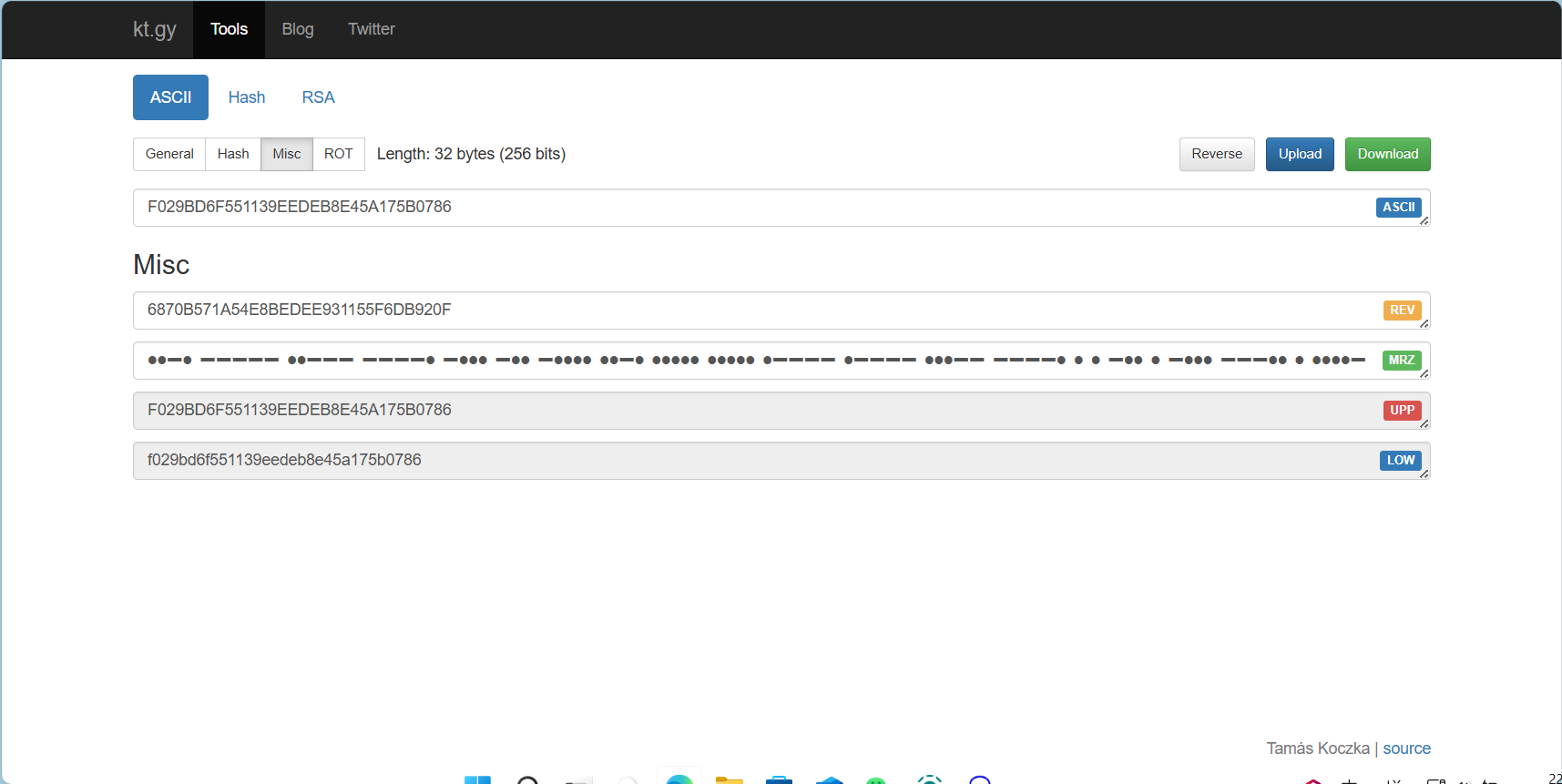
kt.gy转换大小写后再提交,正确
flag{f029bd6f551139eedeb8e45a175b0786}
没啥好说的,摩斯电码,有点折磨人了
[SWPU2019]伟大的侦探(编码新知识)
打开压缩包后发现解压图片需要密码,打开txt后发现乱码,在notepad++尝试无果
在010中打开,选择EBCDIC编码就能得到明文密码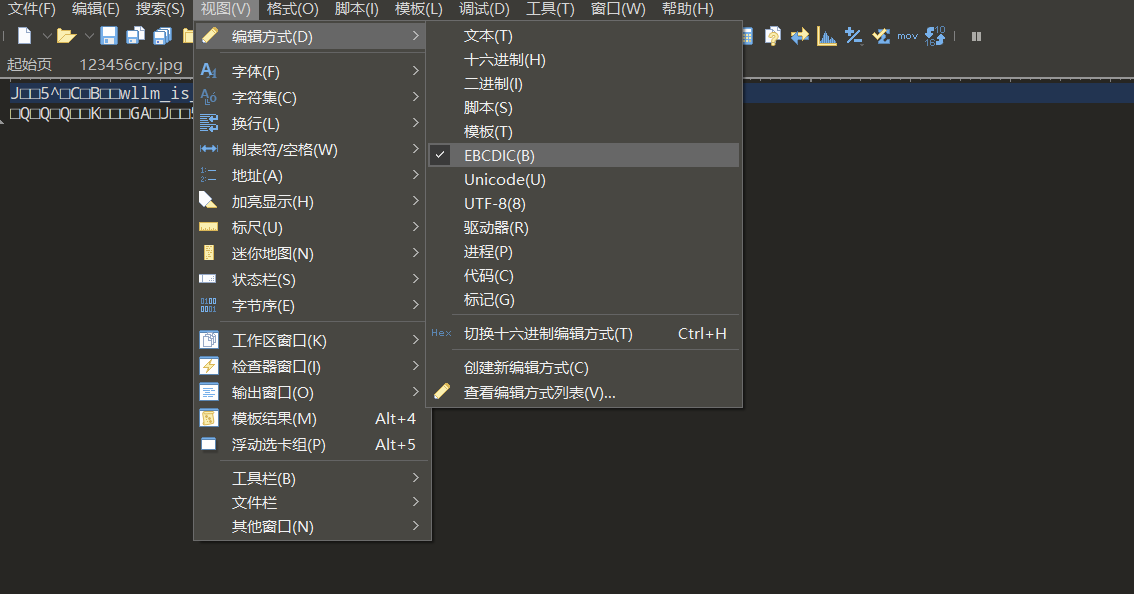
密码wllm_is_the_best_team!
输入密码后得到一堆小人图片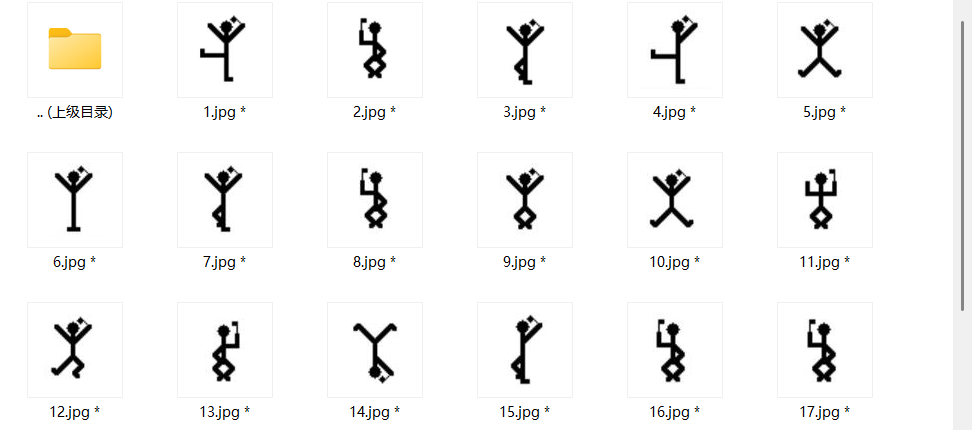
这是福尔摩斯小人密码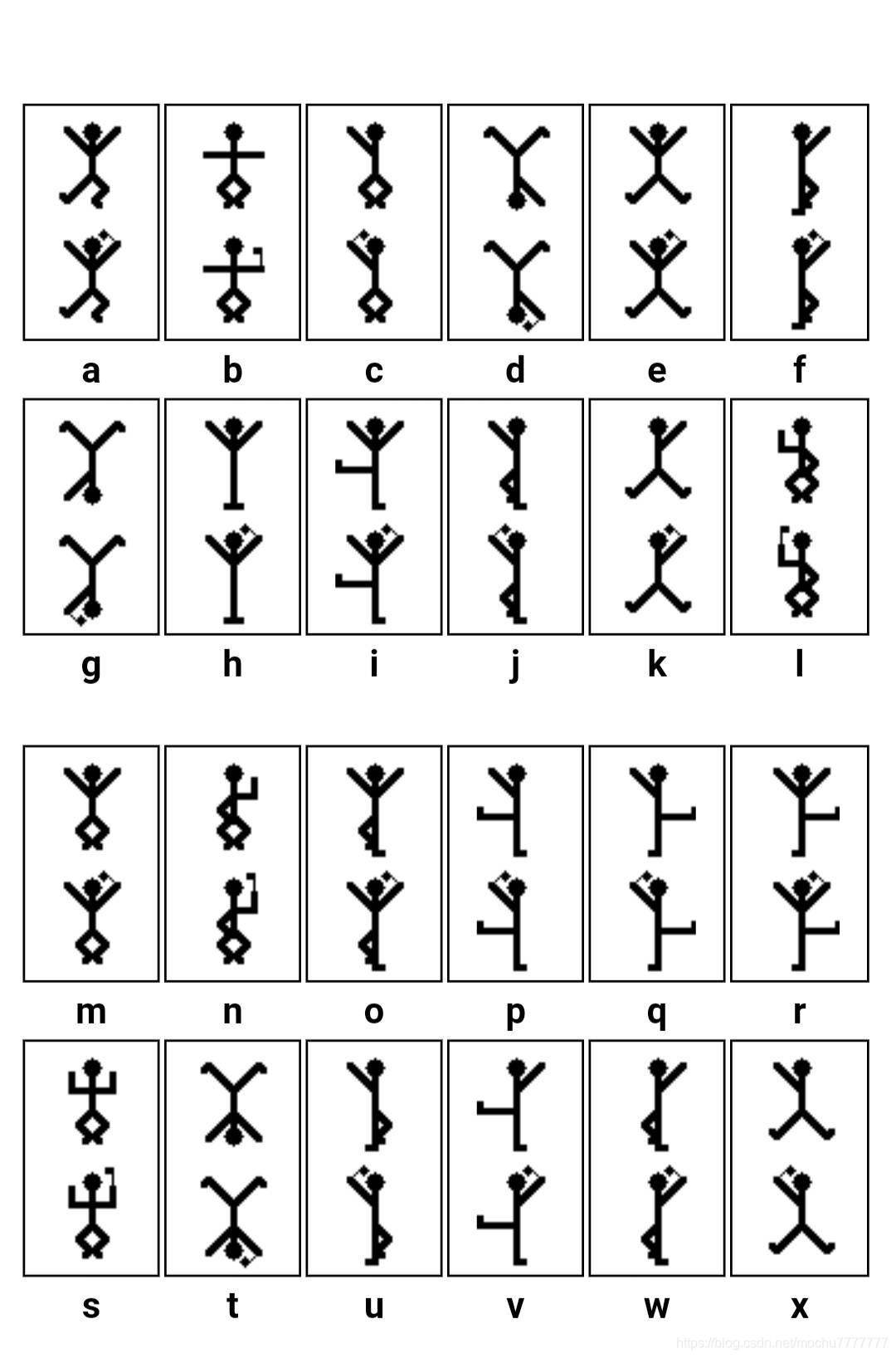
对照得知flag内容
flag{iloveholmesandwllm}
考点 EBCDIC编码、福尔摩斯小人密码(图形的单表替换密码)
喵喵喵
首先将压缩包拖入010,发现并无异常数据
打开,发现一张图片,解压后查看属性无信息,拖入010显示一切正常,那就考虑stegsolve,在逐个通道逐位查看时发现RGB通道的0位都存在异常数据,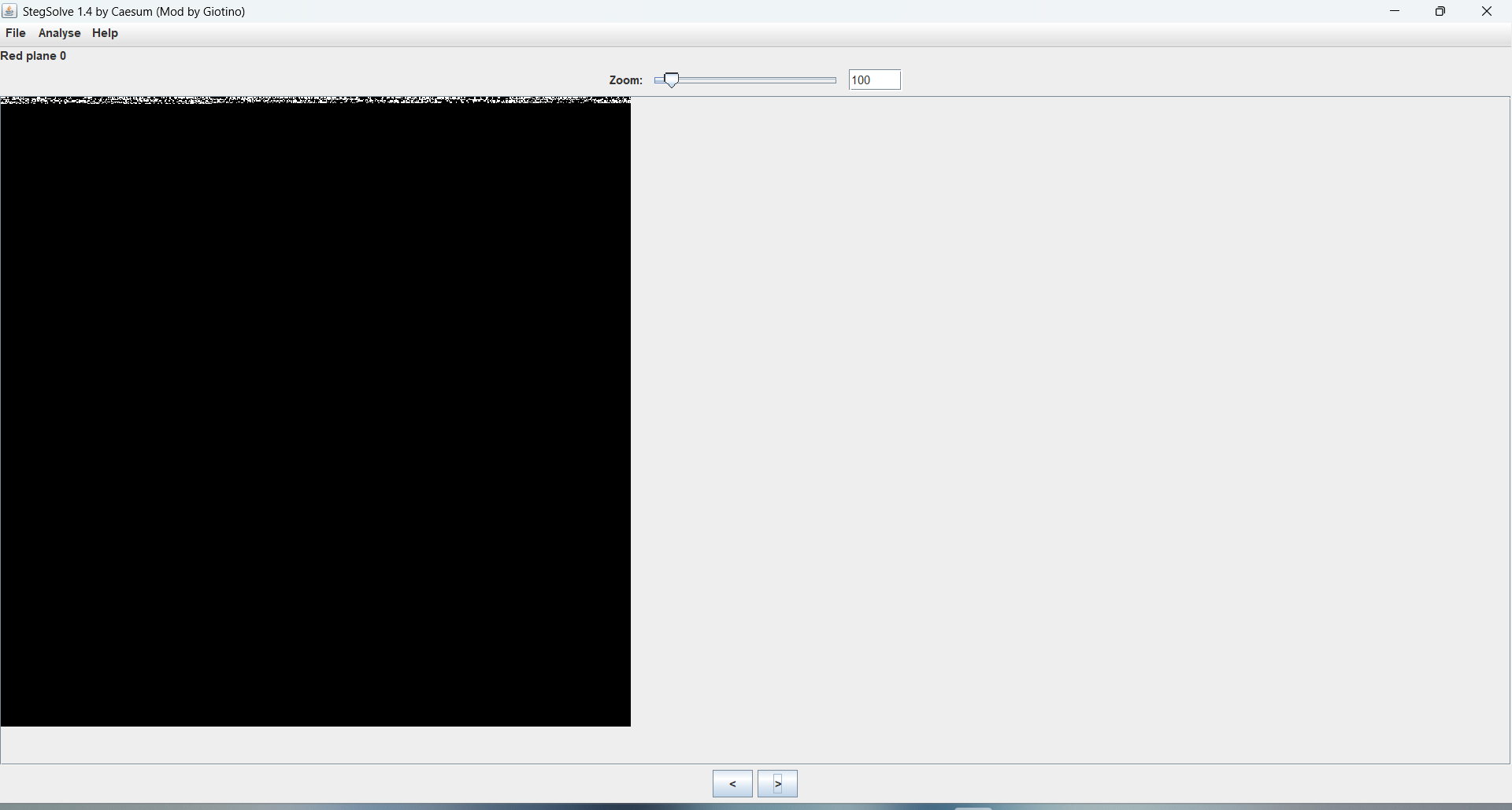
考虑lsb隐写,排列方式为BGR发现png文件头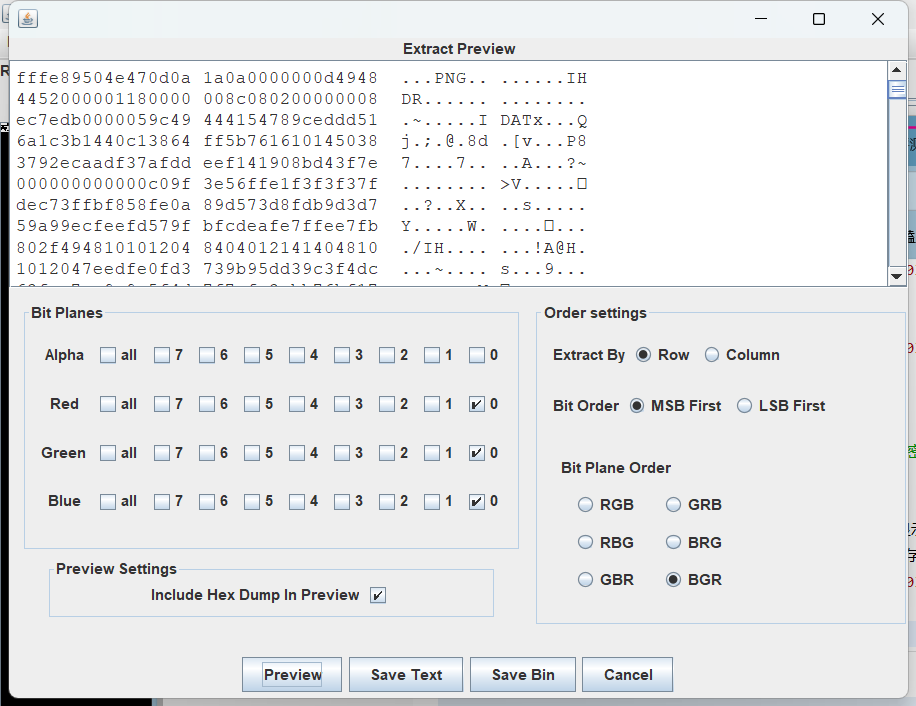
直接保存为png图片再去010打开,删去文件头前无关数据后执行png模板发现存在CRC报错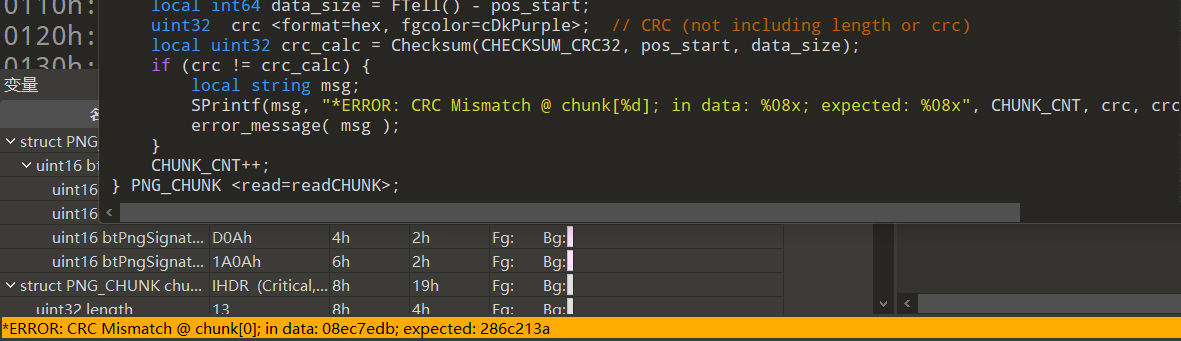
观察图片发现图片只有上半张二维码,猜测原图为完整的二维码,于是修改图片高度为280(与宽度一致),得到一张完整的色彩反转的二维码
去stegsolve里反转色彩扫码得到百度网盘链接https://pan.baidu.com/s/1pLT2J4f
下载后打开压缩包,里面有一个txt文件,发现flag并不在里面,考虑ntfs文件流隐写
黄金六年
mp4文件,查看文件属性并没有什么隐藏信息,拖到剪映(我就喜欢这么干)去盯帧,发现第一个二维码
扫码结果key1:i
第二个
扫码结果key2:want
第三个
扫码结果key3:play
第四个
这张图按照别人的wp把屏幕调亮了还是找不到,不管了
扫码结果key4:ctf
完整的keyiwantplayctf
然而这并不是flag……
用010打开看看发现视频末尾存在疑似base64编码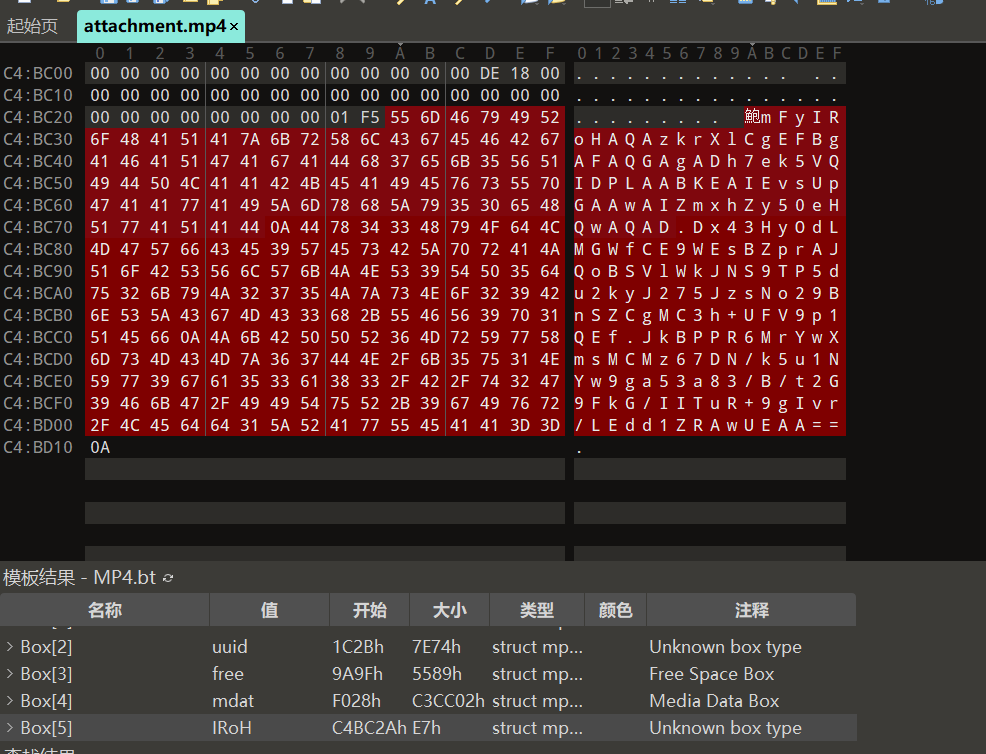
发现神秘rar
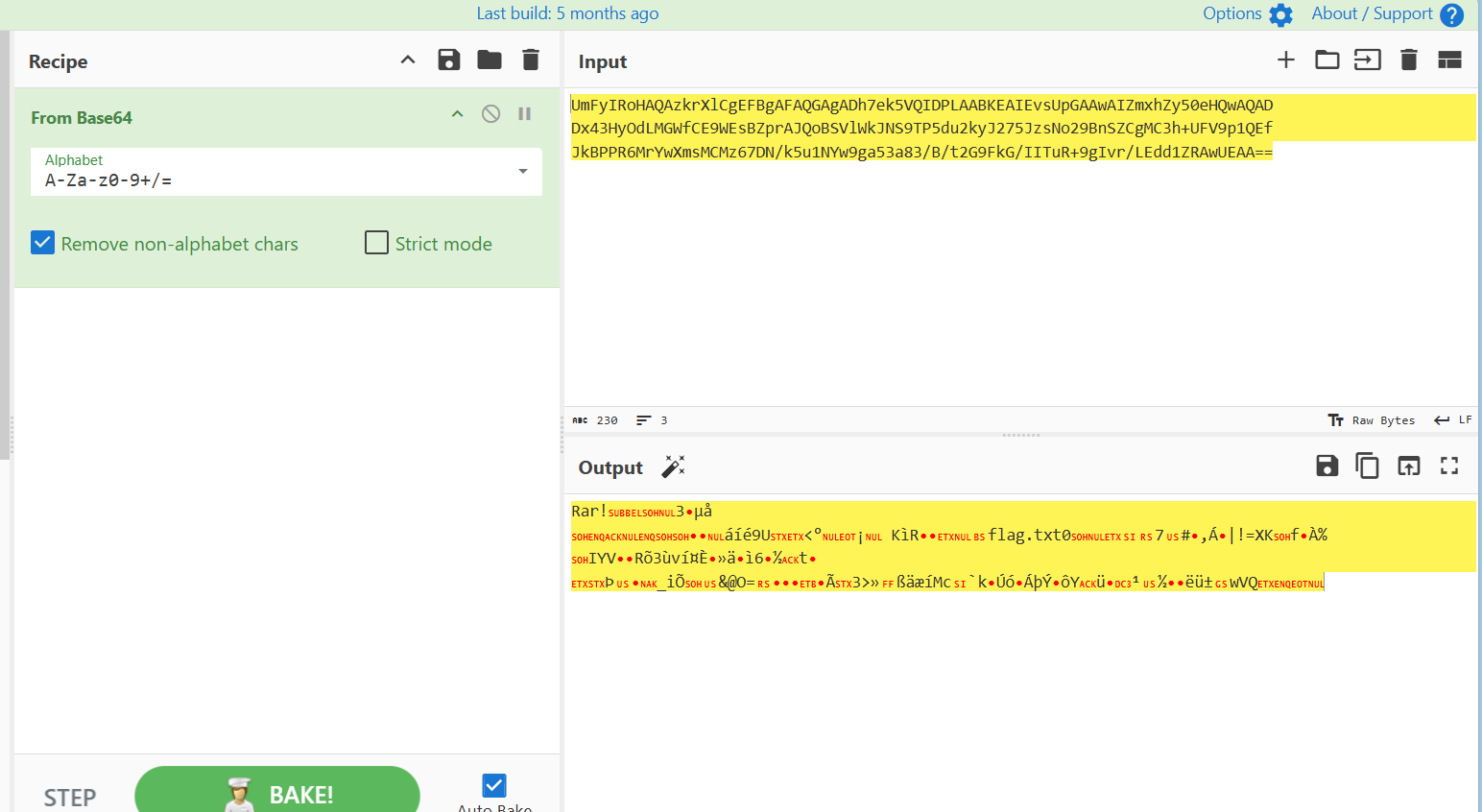
保存得到一个加密压缩包,把之前组合起来的key输进去就好了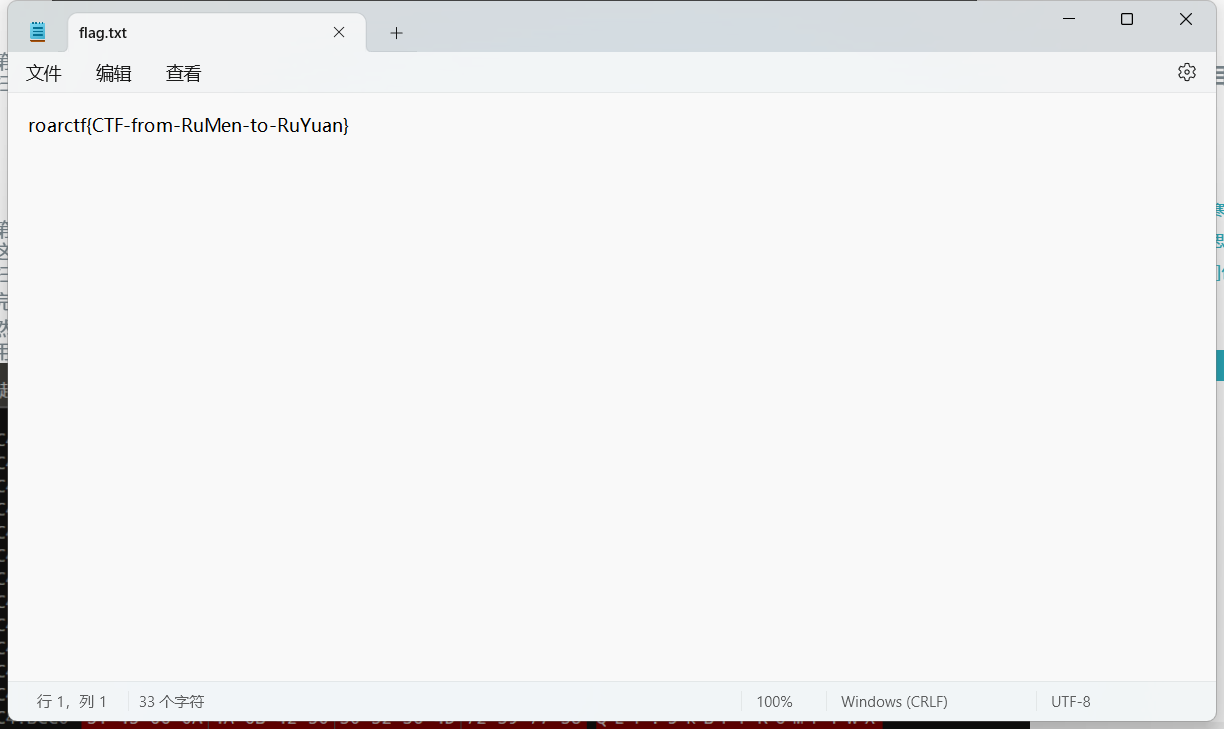
flagflag{CTF-from-RuMen-to-RuYuan}
考点 视频盯帧
文件末尾隐写
[WUSTCTF2020]alison_likes_jojo(新工具outguess)
下载后打开压缩包,发现没啥思路,随便点点看,每个文件都拉到010里去看看,解压后错乱的编码甚至花费了我好多时间……
用010的模板在boki.jpg文件末尾发现了未知块,拉下去一看发现是一个压缩包(PK起手)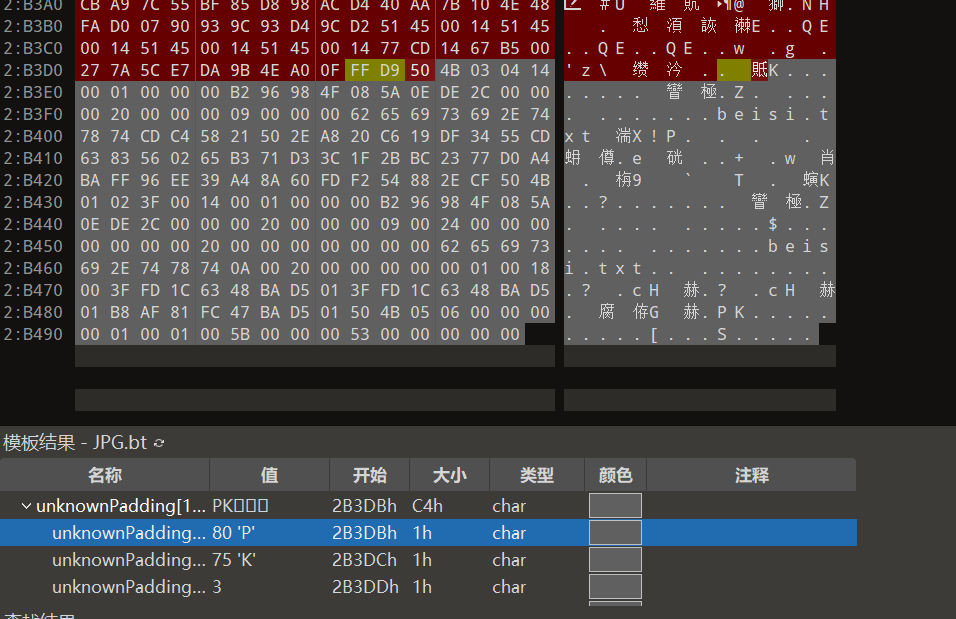
纯手工提取(0添加),另存为zip发现里面只有一个带密码的txt,分析发现这并不是伪加密,于是考虑爆破密码(4.66版本的速度真的优化了很多,超级快,想要的可以去煮啵在seafile共享的文件去找)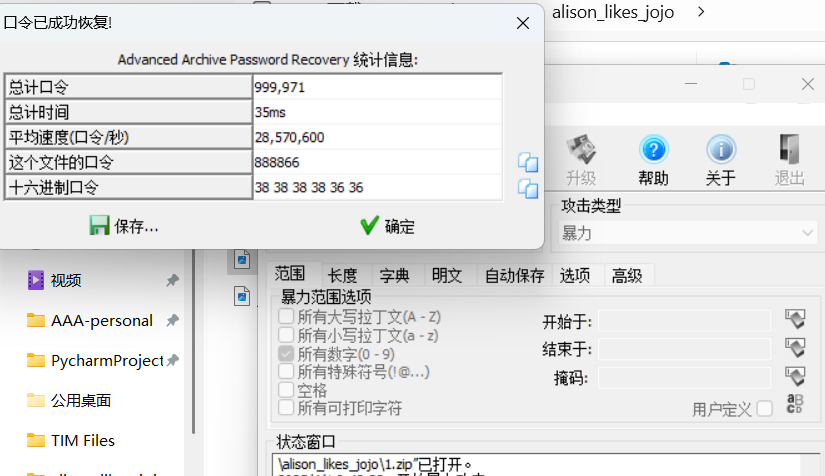
密码888866
打开发现是一串base64类似物WVRKc2MySkhWbmxqV0Zac1dsYzBQUT09
赛博厨师一把发现是三重base64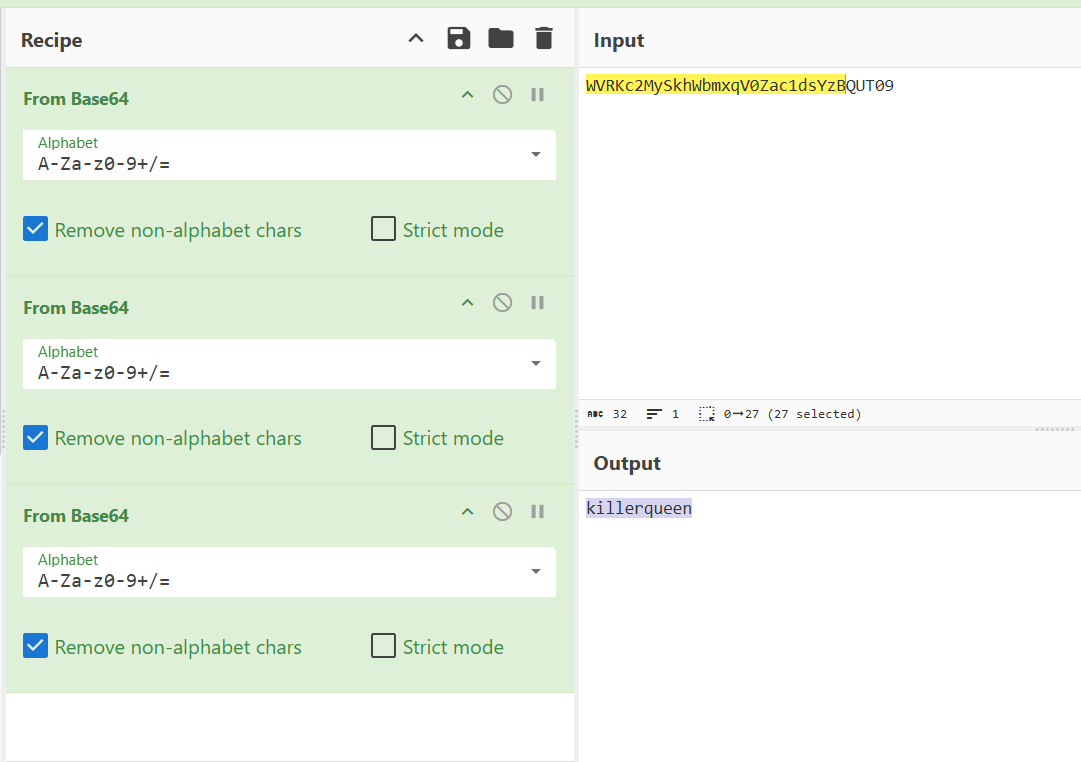
keykillerqueen
然后后面就不会了(毕竟第一次知道outguess(killerqueen是隐写的密码)
安装(不会真的有人忘了用root用户吧)
apt install outguess
outguess是一款开源的隐写工具,可以隐藏信息在图像和声音文件中。它使用了一种基于数据的方法,而不是基于修改的方法来隐藏信息,这使得它更加难以被检测到。
使用outguess隐写信息需要加密信息的密码key,也就是说我们需要找到key来找出jpg图片中隐写的信息。
otguess -k killerqueen -r jljy.jpg -t 1.txt
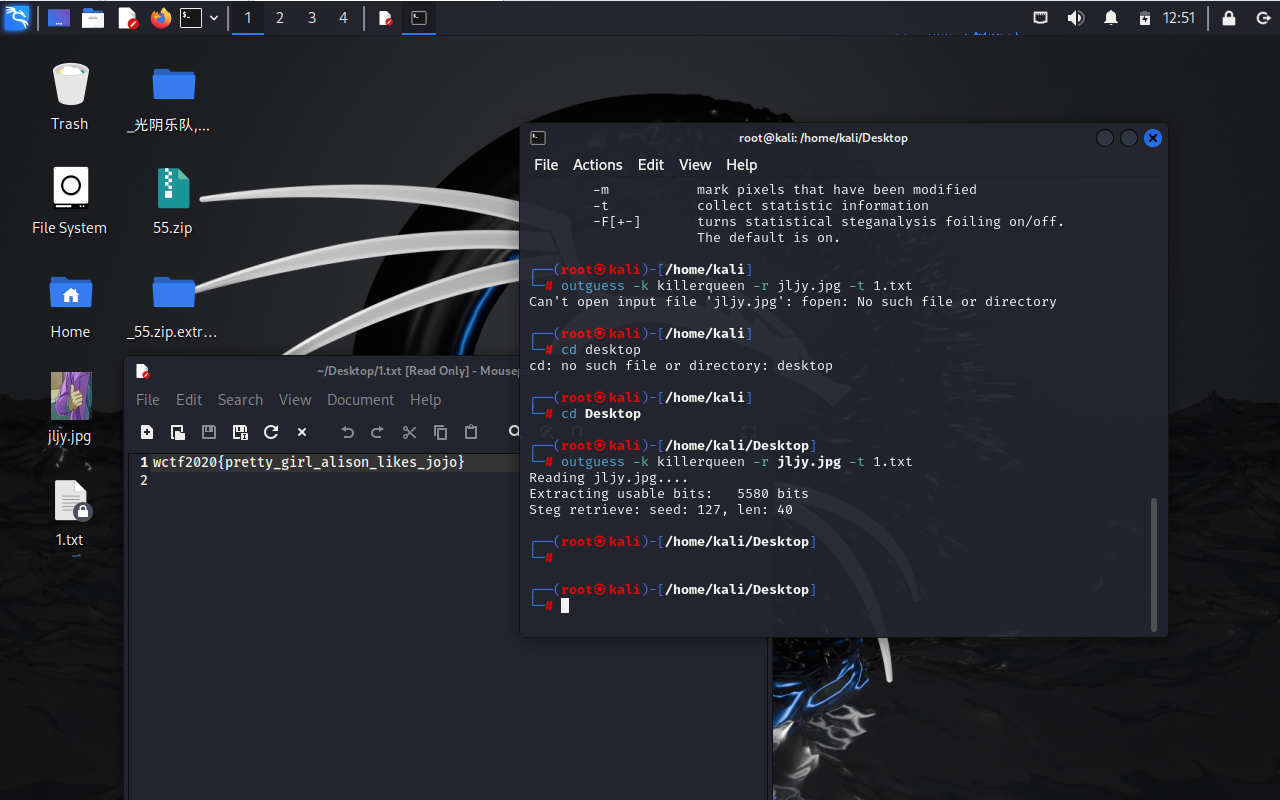
!!一定要记得cd目录到文件所在位置!!
flagflag{pretty_girl_alison_likes_jojo}
考点
文件末尾隐写
压缩包密码爆破(好久没写了甚至忘了有这事)
outguess提取隐写信息
[安洵杯 2019]吹着贝斯扫二维码(二维码新题型)
打开压缩包发现了一堆没有后缀的文件以及一个压缩包,经检验压缩包并不是伪加密,而且压缩包存在备注GNATOMJVIQZUKNJXGRCTGNRTGI3EMNZTGNBTKRJWGI2UIMRRGNBDEQZWGI3DKMSFGNCDMRJTII3TMNBQGM4TERRTGEZTOMRXGQYDGOBWGI2DCNBY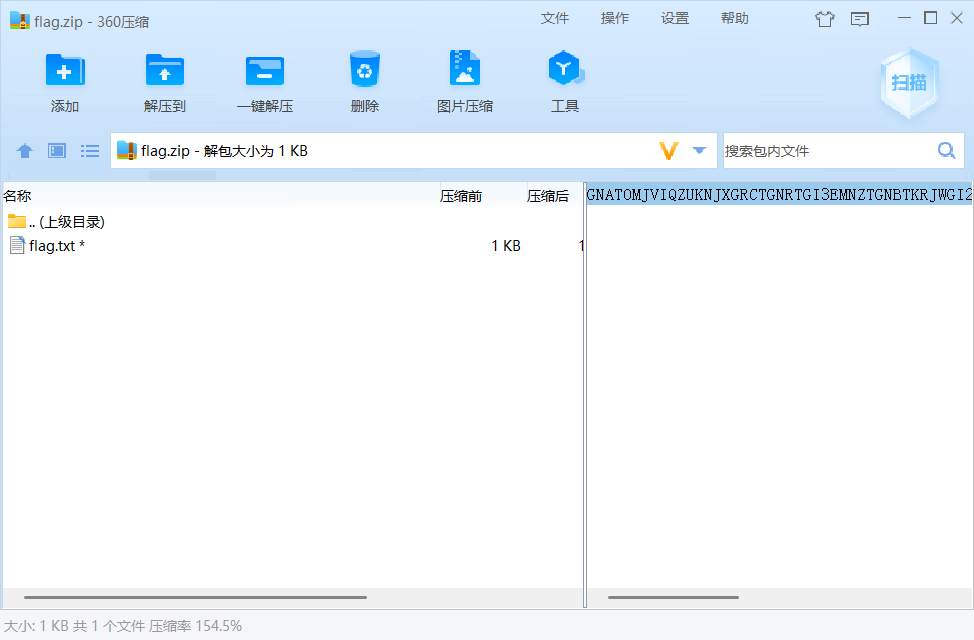
将备注拖入赛博厨师解码发现是base32和16进制混编,然而解码数据并不可读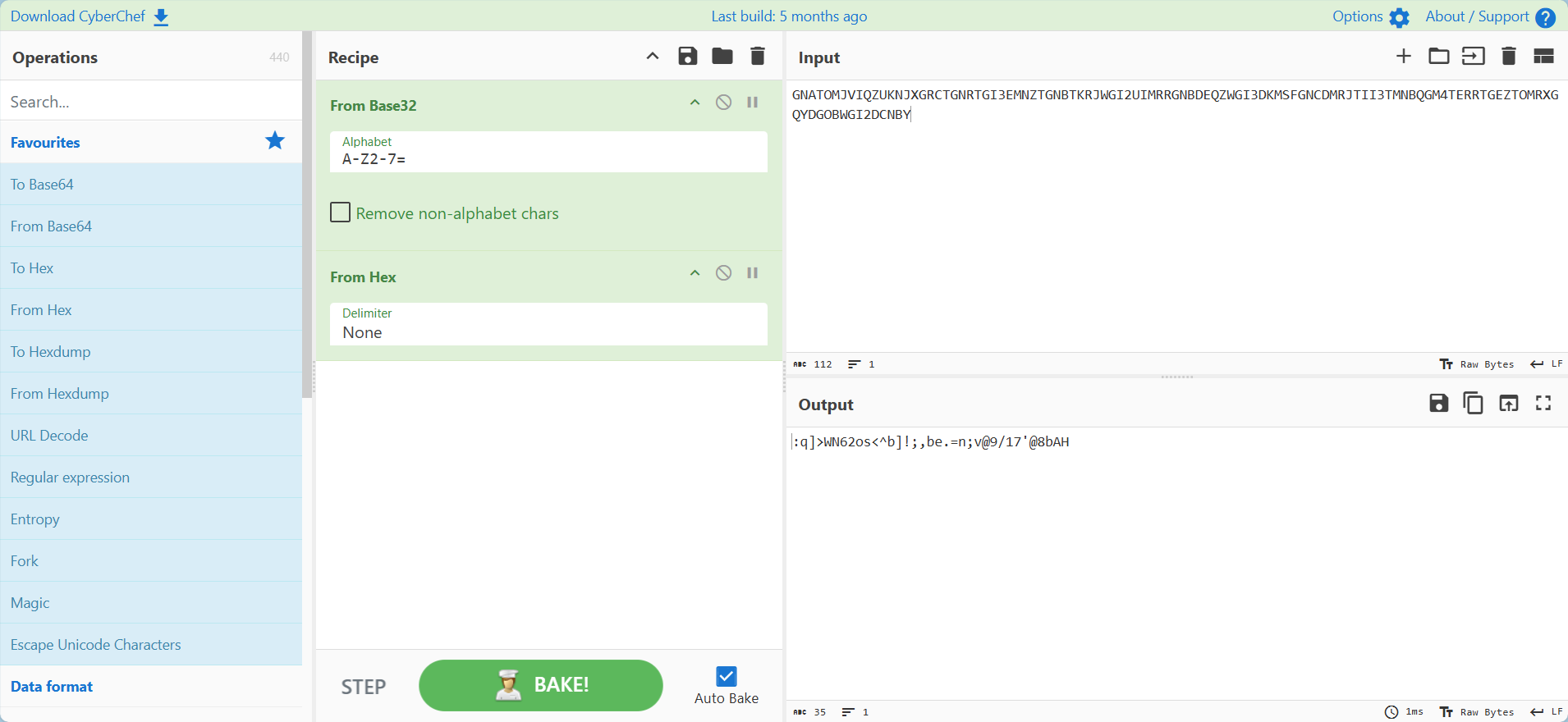
将任意一个无后缀文件放入010进行分析,发现是jpg文件
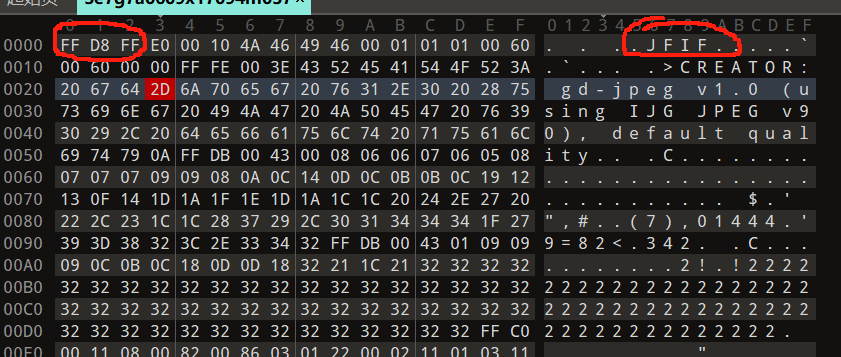
并在文件末尾结束后发现了神秘数字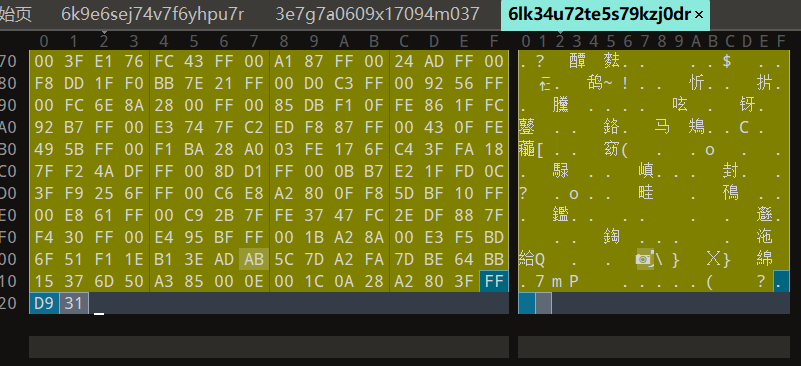
(就是不知道为什么长度不一样,怀疑是序号)
那么先给他变回jpg,
先把里面的压缩包拿开,再全选所有无后缀文件使用win自带的批量重命名操作
翻车了孩子们,我们在图片所在文件夹使用命令提示符来进行批量重命名
ren * *.jpg
现在我们有了二维码碎片,接下去把他们排好就行了,那么这个时候就需要用到我们在文件末尾发现的神秘数据了,使用以下脚本进行批量重命名
import os
from PIL import Image
#目录路径
dir_name = r"./"
#获取目录下文件名列表
dir_list = os.listdir('./')
#print(dir_list)
#从列表中依次读取文件
for file in dir_list:
if '.jpg' in file:
f=open(file ,'rb')
n1 = str(f.read())
n2 = n1[-3:]
#经过测试发现这里要读取最后3个字节,因为最后还有一个多余的字节,不知道是不是转字符串的原因导致在末尾多了一个字符
#print(file) #输出文件内容
#print(n2)
f.close() #先关闭文件才能重命名,否则会报`文件被占用`错误
os.rename(file,n2+'.jpg') #重命名文件
(来自https://blog.csdn.net/WYHPROGRAME/article/details/124056192)
代码bug
文件名90多的,其实是1-9,改一下吧
~~打开ps(没有ps的宝宝可以去看看隔壁雪剑的wp)按下图新建项目
文件->置入嵌入对象,选择图片
~~
由于手动拼好码实在是难度高,煮啵是手残党,只能寻求机器的力量……
# coding=utf-8
import os
from PIL import Image
# 图片压缩后的大小
width_i = 134
height_i = 130
# 每行每列显示图片数量
row_max = 6
line_max = 6
all_path = []
num = 0
pic_max = line_max * row_max
# 文件夹路径
dir_name = r"./"
# 获取文件夹下文件名的列表
dir_list = os.listdir('./')
# 将文件列表重新排序(按文件原始数据末尾的数字)
for i in range(36, 0, -1):
for file in dir_list:
if file.endswith('.jpg'):
with open(file, 'rb') as f:
n1 = f.read()
n2 = n1[-2:]
if i > 9:
if str(i).encode() in n2:
all_path.insert(0, os.path.join(file))
break
else:
# Python 3 中使用 hex() 替代 encode('hex')
hex_data = n1.hex()
if 'd9' in hex_data[-4:] and str(i).encode() in n2:
all_path.insert(0, os.path.join(file))
break
print(all_path)
toImage = Image.new('RGBA', (width_i * line_max, height_i * row_max))
# 拼接图片
for i in range(row_max):
for j in range(line_max):
if num >= len(all_path):
break
pic_file_head = Image.open(all_path[num])
# 获取图片的尺寸
width, height = pic_file_head.size
# 按照指定的尺寸,给图片重新赋值
tmppic = pic_file_head.resize((width_i, height_i))
# 计算每个图片的左上角的坐标点
loc = (int(j % line_max * width_i), int(i % row_max * height_i))
print(loc)
toImage.paste(tmppic, loc)
num += 1
if num >= pic_max:
break
toImage.save('merged.png')
感谢大佬的脚本(https://www.cnblogs.com/m718/p/14132769.html)(已经过修改,能在py38环境运行)
扫码图片得到加密流程(别问为什么不是解密,试试就知道了)(那个13应指rot13)
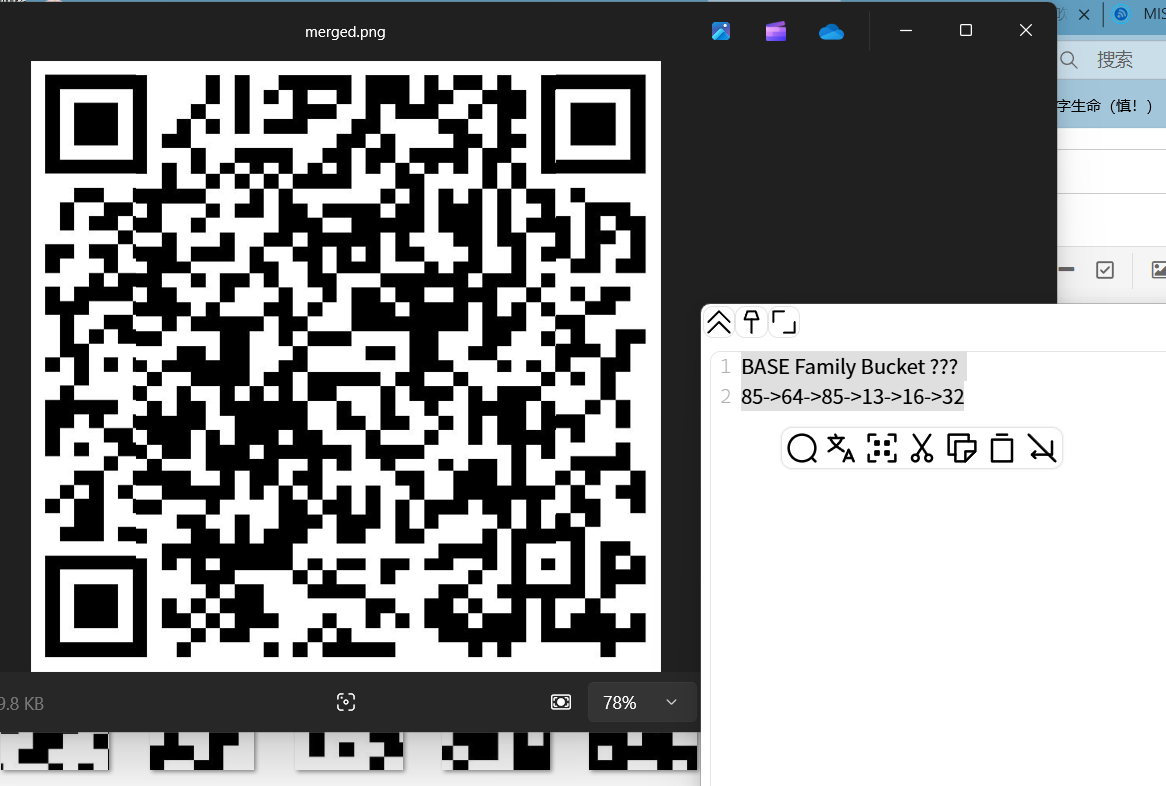
将备注进行解码得到密码
keyThisIsSecret!233
解压压缩包得到flagflag{Qr_Is_MeAn1nGfuL}
考点
无后缀文件类型识别(文件头识别)
文件末尾隐写
脚本编写
多重混合编码
从娃娃抓起(新编码知识)

打开txt,不能说毫无头绪,只能说一点不会,把手头上的一把梭和各种编码试了都没啥用……
上网搜到了那句话
计算机的普及要从娃娃抓起
转成md5发现并不是flag
查阅前人的智慧得知这道题的考点分别是中文电码和五笔编码
中文电码表采用了四位阿拉伯数字作代号,从0001到9999按四位数顺序排列,用四位数字表示最多一万个汉字、字母和符号。汉字先按部首,后按笔划排列。字母和符号放到电码表的最尾。后来由于一万个汉字不足以应付户籍管理的要求,又有第二字面汉字的出现。在香港,两个字面都采用同一编码,由输入员人手选择字面;在台湾,第二字面的汉字会在开首补上“1”字,变成5个数字的编码。
使用在线解码网站对第一段进行解码https://dianma.bmcx.com/
解码得到人工智能
对第二段五笔编码进行解码https://www.qqxiuzi.cn/bianma/wubi.php

合起来就是人工智能也要从娃娃抓起
md5编码得到3b4b5dccd2c008fe7e2664bd1bc19292
flag{3b4b5dccd2c008fe7e2664bd1bc19292}
考点
中文电码
五笔编码
弱口令(新知识点和工具(sublime&cloacked-pixel))
打开压缩包发现加密文件,经过爆破无果,发现压缩包备注存在不可见字符,可以复制到sublime查看
其中,空格是点,tap是横,摩斯解码得到HELL0FORUM
填入压缩包得到女神图片
查看文件,并未发现有其他隐写形式,这里需要用到新工具cloacked-pixel
Cloacked-pixel——第二使用的png特定图片隐写工具
由于主包的环境实在是抽象,只能去找py3版本的工具,因此在命令上会与py2的不太相同
在pycharm里配好环境以后,把图片移动到相同文件夹下(这里的密码并没有提示,是看别的wp知道的)
python lsb.py extract -i 1.png -o 1.txt -p 123456
即可得到flag{jsy09-wytg5-wius8}
考点
不可见字符的显示(空格和tap的组合)
cloacked-pixel隐写工具的使用
[GUET-CTF2019]zips
打开压缩包,发现222里面有一个加密的111,经过检验发现并不是伪加密,进行6位纯数字爆破得到key723456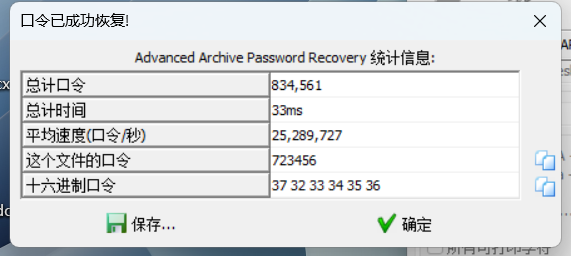
打开111发现两个文件,一个是无加密的flag压缩包,另一个是伪加密的.sh文件
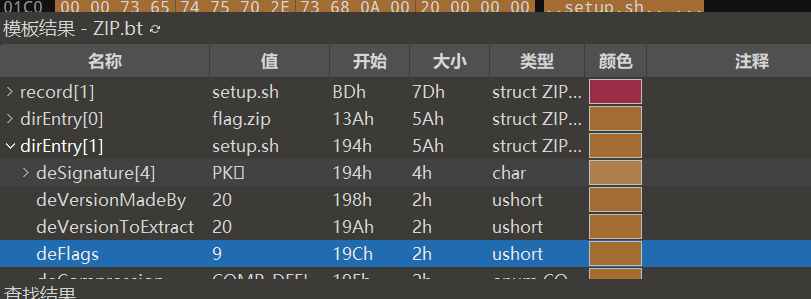
sh的frflag是0
我们可以手动修改修复伪加密,也可以用工具来修复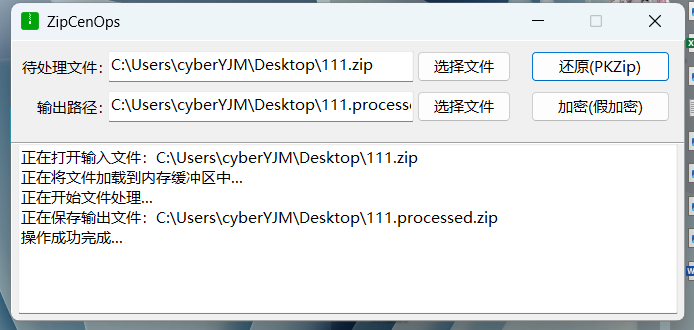
发现.sh以及能正常打开,用文本编辑器看一下,感觉这是加密脚本,time指的应该是unix时间戳,那我们转换一下这个文件的修改时间,对应时间戳应该是1558080600
然而发现不对,这样子我就不会了
AI解析
关于时间戳(新知)
时间戳的考点有很多,包括毫秒级时间戳(13位,如果要爆破可以增加掩码已知数位)
而且py2和3的时间戳小数点位数是不一致的,如图,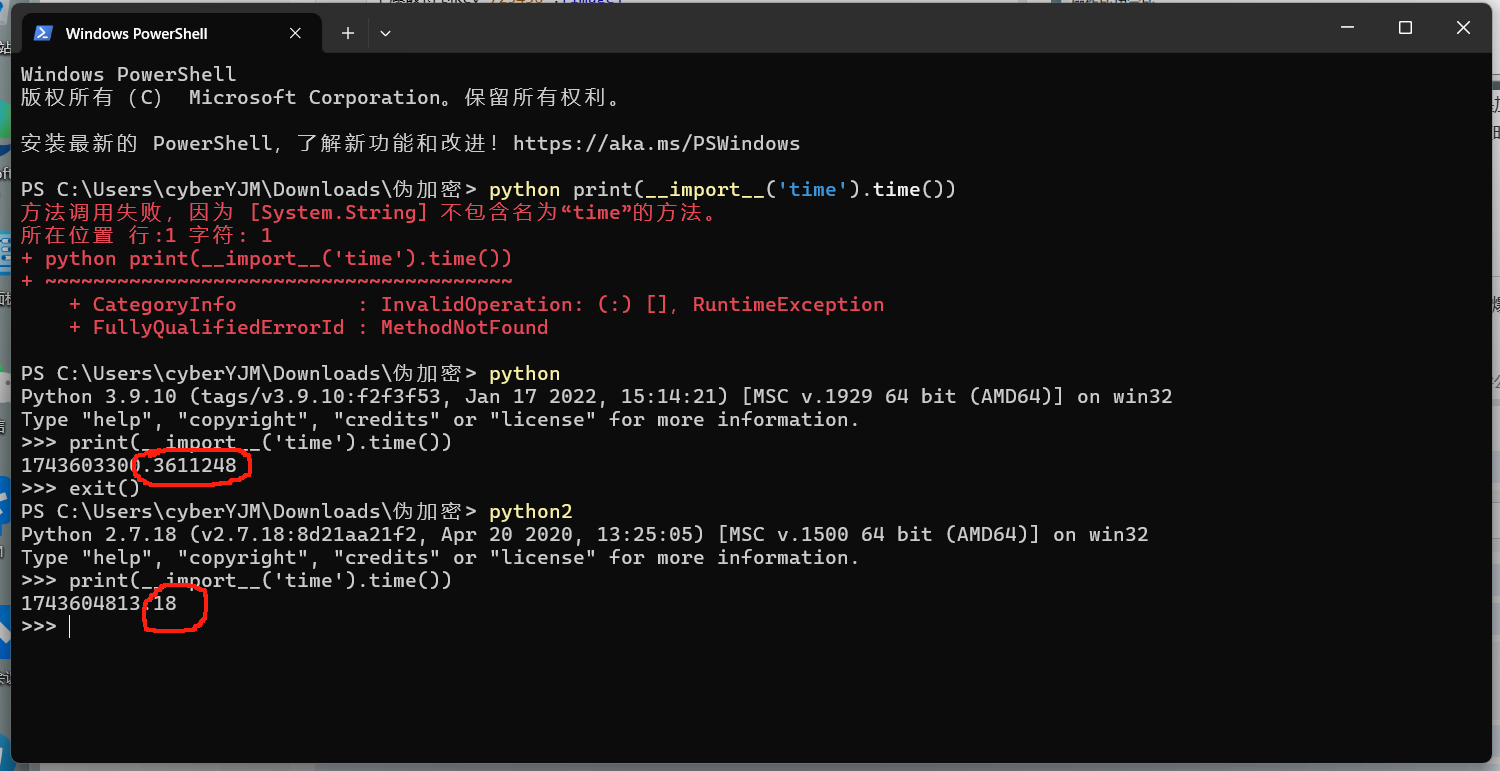
2小数点后只有两位,3的小数点后能精确到7位
时间戳也可能不准确,因此需要考虑时间范围内爆破,可以通过爆破工具的掩码爆破来实现
在本题中,时间戳的考点是时间戳范围,因为实测时间戳并不准确,所以考虑把时间戳在一段时间范围内进行爆破,经过实测,这道题使用的是python2得到的两位小数点的时间戳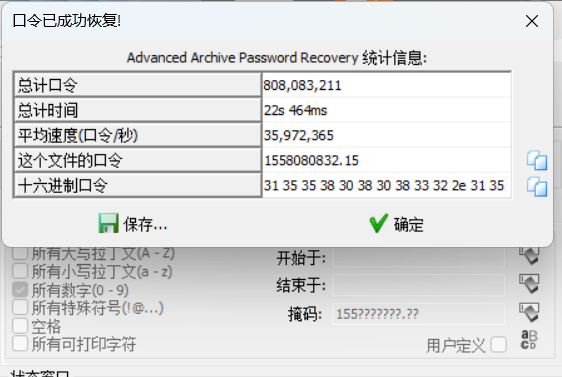
密码1558080832.15
010打开无后缀文件即可得知flag
flag{fkjabPqnLawhvuikfhgzyffj}
考点
加密压缩包简单暴力爆破
伪加密
时间戳的概念及其在本题中衍生的压缩包掩码爆破
(较为特殊,目前无广泛性)时间戳范围爆破密码
[UTCTF2020]file header
下载下来是一张无法打开的图片,结合题目“文件头”,在010中打开发现文件头缺失,其他部分完好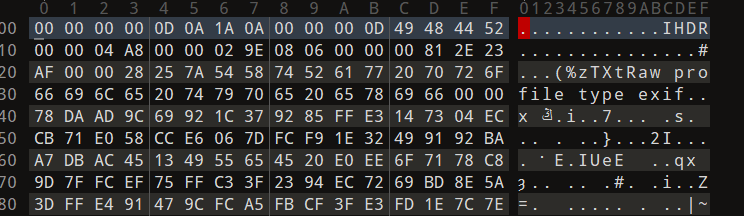
把文件头补上就好了
得到图片

flag{3lit3_h4ck3r}
考点
文件头修复
Mysterious(基础逆向(新))
下载下来就是一个exe文件
双击打开发现只有一个输入框界面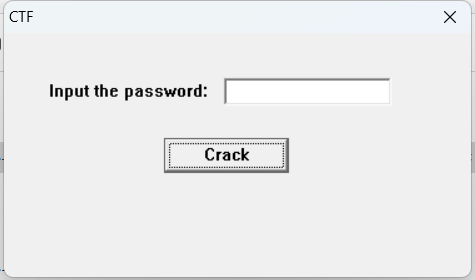
随便输几个数也没啥反应,根据题给信息推测这是逆向题
IDA打开,shift+f12查看字符型变量,发现well down挂顶上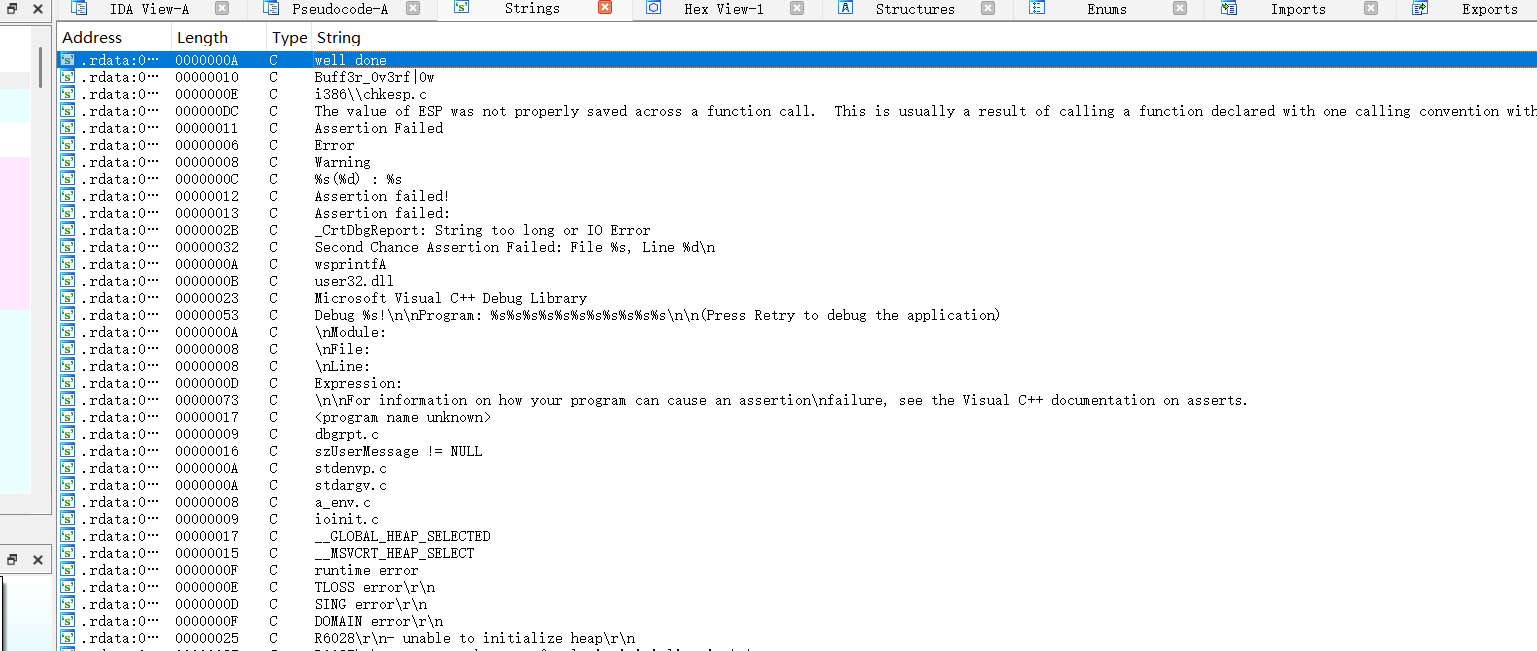
双击跳转到所在地址,发现跳到了DialogFunc函数底下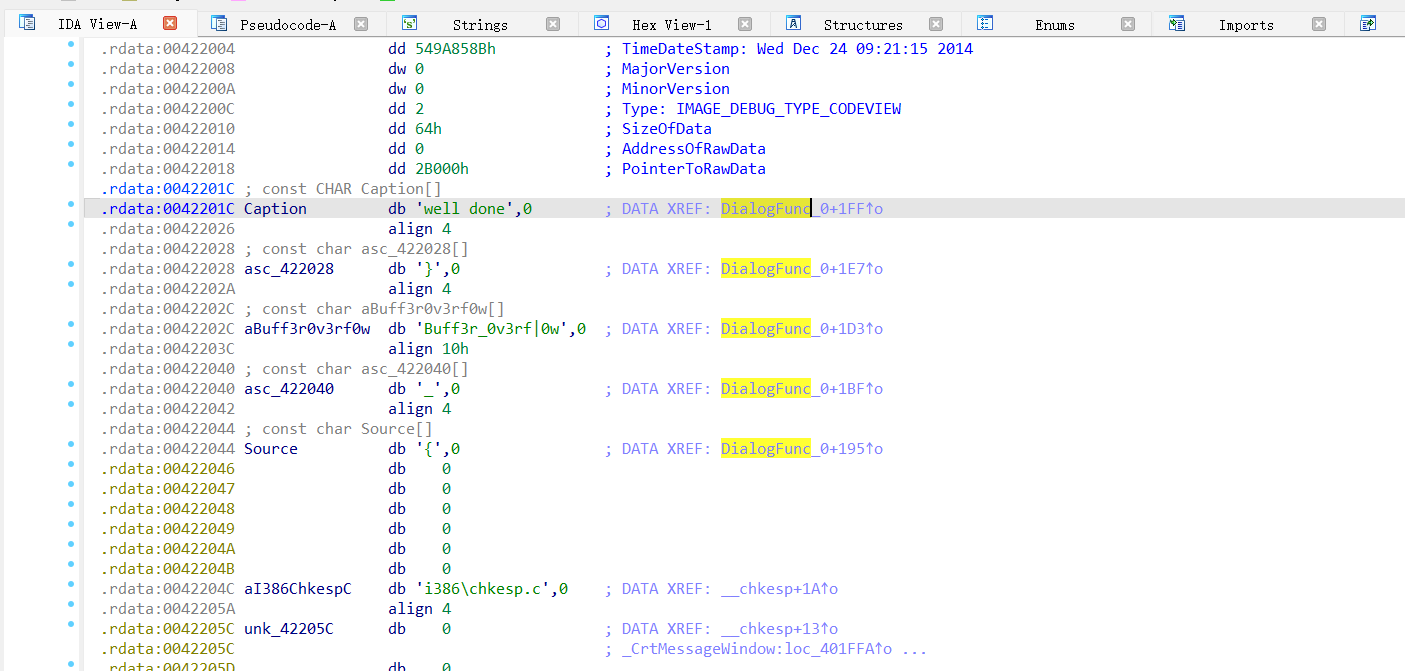
再双击DialogFunc跳转到流程图后按f5进行反编译得到伪c代码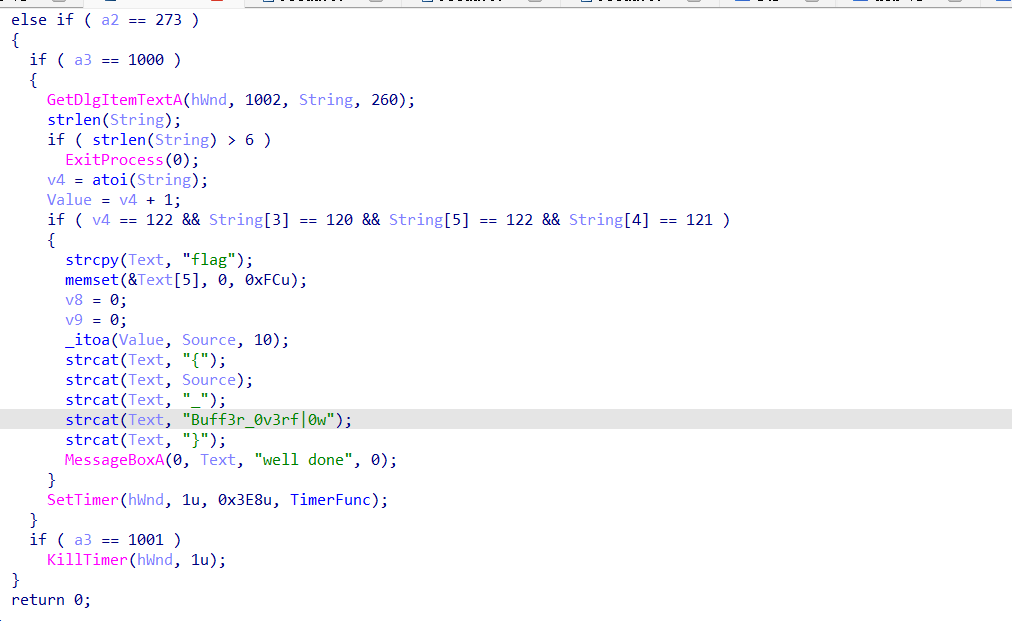
点下面展开代码解析
代码解析
// 对话框处理函数,使用__stdcall调用约定,处理窗口消息
int __stdcall DialogFunc_0(HWND hWnd, int a2, int a3, int a4) {
int v4; // eax 用于临时存储数值
char Source[260]; // 存储转换后的数值字符串
_BYTE Text[257]; // 构建flag的缓冲区
__int16 v8; // 用于Text数组的结束符
char v9; // 同上
int Value; // 存储转换后的输入值+1的结果
CHAR String[260]; // 存储用户输入的字符串
// 初始化String和Value
memset(String, 0, sizeof(String)); // 清空输入缓冲区
Value = 0;
// 处理窗口消息
if (a2 == 16) { // WM_CLOSE消息
DestroyWindow(hWnd); // 销毁窗口
PostQuitMessage(0); // 退出消息循环
} else if (a2 == 273) { // WM_COMMAND消息(按钮点击等)
if (a3 == 1000) { // 控件ID为1000(例如"确认"按钮)
// 获取ID为1002的控件(输入框)中的文本
GetDlgItemTextA(hWnd, 1002, String, 260);
// 检查输入长度是否超过6
strlen(String);
if (strlen(String) > 6) // 输入长度超过6则强制退出
ExitProcess(0);
// 将输入转换为整数
v4 = atoi(String);
Value = v4 + 1; // 计算Value值
// 校验输入格式:v4必须等于122,且第4、5、6字符分别为x,y,z(索引3,4,5)
if (v4 == 122 && String[3] == 120 && String[5] == 122 && String[4] == 121) {
// 构建flag
strcpy(Text, "flag"); // 初始化flag前缀
memset(&Text[5], 0, 0xFCu); // 清空剩余空间
v8 = 0; // 字符串结束符
v9 = 0;
_itoa(Value, Source, 10); // 将Value转为字符串存入Source
strcat(Text, "{"); // 拼接格式
strcat(Text, Source); // 添加数值部分
strcat(Text, "_");
strcat(Text, "Buff3r_0v3rf|0w"); // 固定字符串
strcat(Text, "}");
MessageBoxA(0, Text, "well done", 0); // 弹出成功提示
}
SetTimer(hWnd, 1u, 0x3E8u, TimerFunc); // 设置定时器(可能用于超时处理)
}
if (a3 == 1001) // 控件ID为1001(例如"取消"按钮)
KillTimer(hWnd, 1u); // 关闭定时器
}
return 0;
}
可总结为下:
输入必须为6字符,格式为"122xyz"(前3位转为122,后3位为x,y,z)
(注:120 121 122位的阿斯克码分别是xyz)
计算Value = 122 + 1 = 123
把123拼入字符串得到flag
最终可得flag{123_Buff3r_0v3rf|0w}
考点
IDA基本使用
对c语言的理解
[XMAN2018排位赛]通行证(编码新题型)
题目a2FuYmJyZ2doamx7emJfX19ffXZ0bGFsbg==
一眼base64,本以为就这,解码完才发现另有乾坤
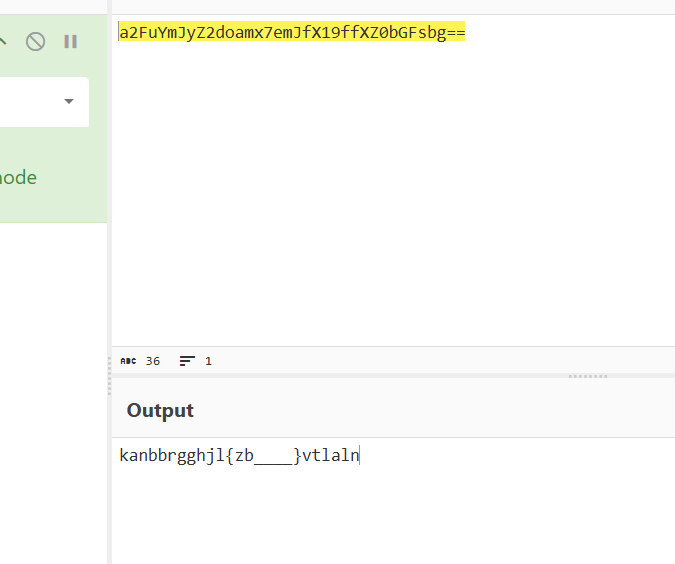
这种调换顺序的编码方式优先考虑栅栏编码,可是放到随波逐流一把梭穷举并无发现有效信息
在这里会被惯性思维框住,但这道题反其道而行之,需要我们自己将其编码出有效信息
我们考虑编码,在key值为7时发现了正确顺序
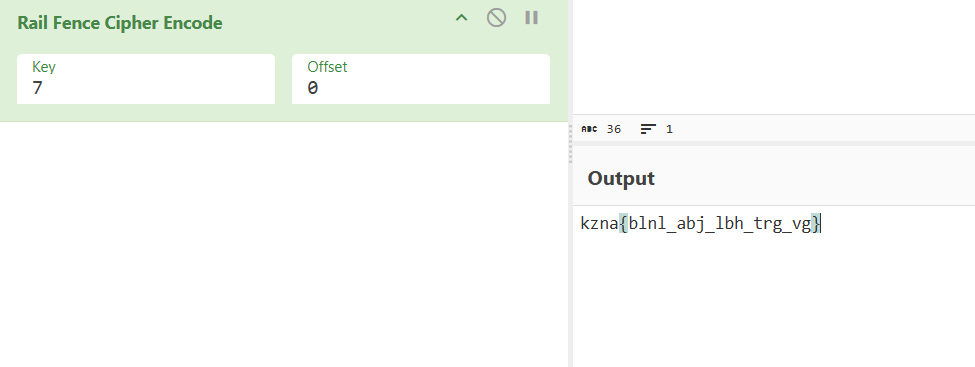
但内容并不是正确flag,考虑是凯撒
在rot13和rot18发现flag
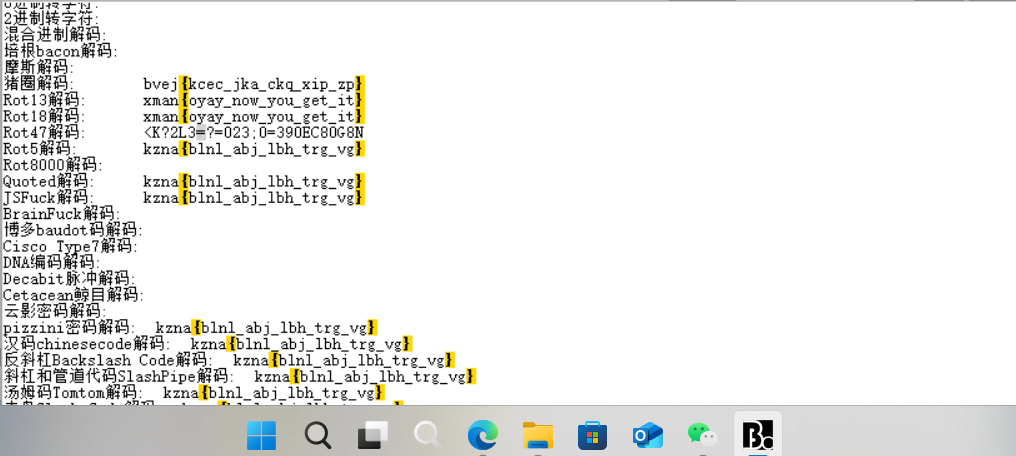
flagflag{oyay_now_you_get_it}
考点
对于各种编码的了解度和“眼熟度”
逆向思维,不能老是局限在“编码题就是解码的框架中”
zip(压缩包新题型)
打开发现68个压缩包,体积都很小,优先考虑crc碰撞爆破密码
脚本代码
#python3
import zipfile
import string
import binascii
def CrackCrc(crc):
for i in dic:
for j in dic:
for k in dic:
for h in dic:
s = i + j + k + h
if crc == (binascii.crc32(s.encode())):
f.write(s)
return
def CrackZip():
for i in range(0,68):
file = 'out'+str(i)+'.zip'
crc = zipfile.ZipFile(file,'r').getinfo('data.txt').CRC
CrackCrc(crc)
print('\r'+"loading:{:%}".format(float((i+1)/68)),end='')
dic = string.ascii_letters + string.digits + '+/='
f = open('out.txt','w')
print("\nCRC32begin")
CrackZip()
print("CRC32finished")
f.close()
网上找来的脚本,实现了压缩包密码爆破拼在一起的功能
打开整合完的txt文件,发现一串base64疑似物
z5BzAAANAAAAAAAAAKo+egCAIwBJAAAAVAAAAAKGNKv+a2MdSR0zAwABAAAAQ01UCRUUy91BT5UkSNPoj5hFEVFBRvefHSBCfG0ruGnKnygsMyj8SBaZHxsYHY84LEZ24cXtZ01y3k1K1YJ0vpK9HwqUzb6u9z8igEr3dCCQLQAdAAAAHQAAAAJi0efVT2MdSR0wCAAgAAAAZmxhZy50eHQAsDRpZmZpeCB0aGUgZmlsZSBhbmQgZ2V0IHRoZSBmbGFnxD17AEAHAA==
赛博厨师解码并不能得出很直观的内容,考虑查看原文件数据看看到底是什么牛马
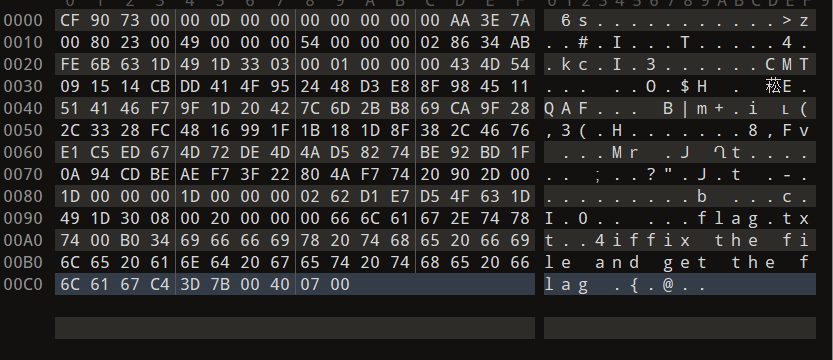
奇奇怪怪,搜一下结尾十六进制发现原来是rar大人

根据rar文件解析补全我们的文件
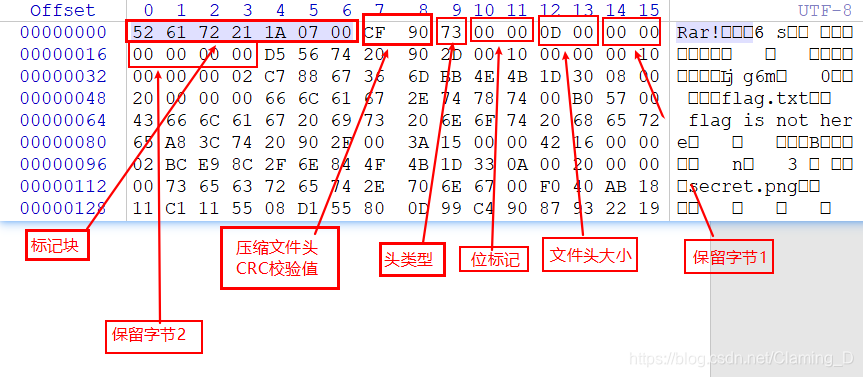
(我怎么觉着winhex更好用)
加上文件头以后把后缀改成rar,打开就可以在文件备注里面发现flag
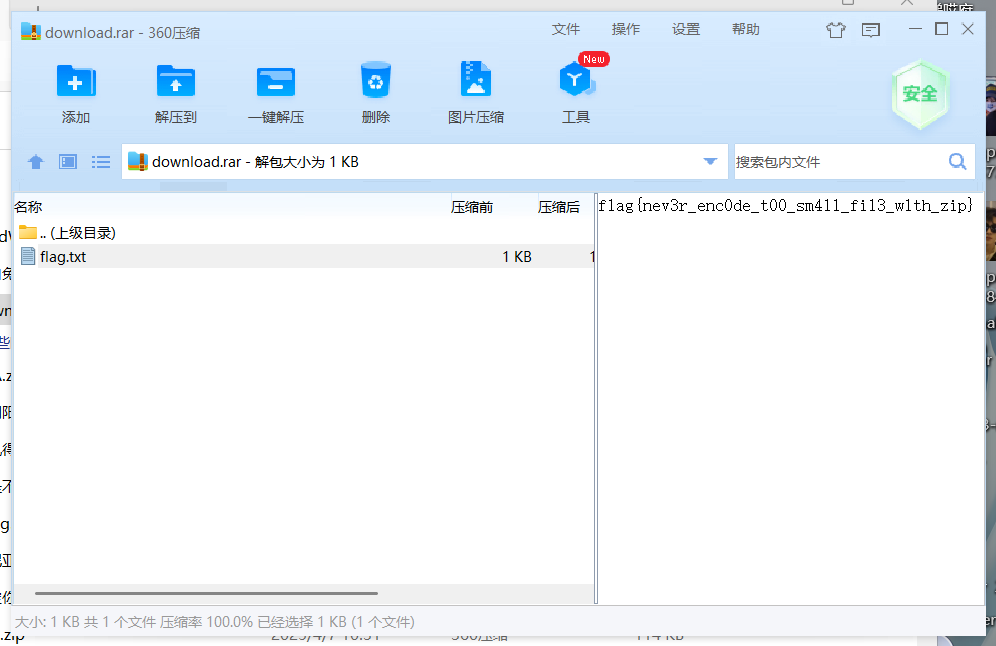
flag{nev3r_enc0de_t00_sm4ll_fil3_w1th_zip}
考点
批量小型压缩文件crc碰撞爆破密码
文件头修复(文件判别)
[WUSTCTF2020]girlfriend(新音频隐写(拨号音识别))
拨号音介绍
双音多频信号(Dual Tone Multi-Frequency, DTMF)由高频群和低频群组成,高低频群各包含4个频率。电话上的每个按键(数字键和功能键)对应一个唯一的DTMF信号,每个DTMF信号由高频群中的一个高频信号和低频群中的一个信号叠加组成。
国际上采用697Hz、770Hz、852Hz和941Hz作为低频群,采用1209Hz、1336Hz、1477Hz和1633Hz作为高频群。用这8种频率可形成16种不同的组合,代表16种不同的数字键或功能键
对于拨号音,我采用了工具法(真的有人会用古法频谱人眼识别吗)
这里我使用了一款命令行工具dtmf2num
下载链接http://aluigi.altervista.org/mytoolz/dtmf2num.zip
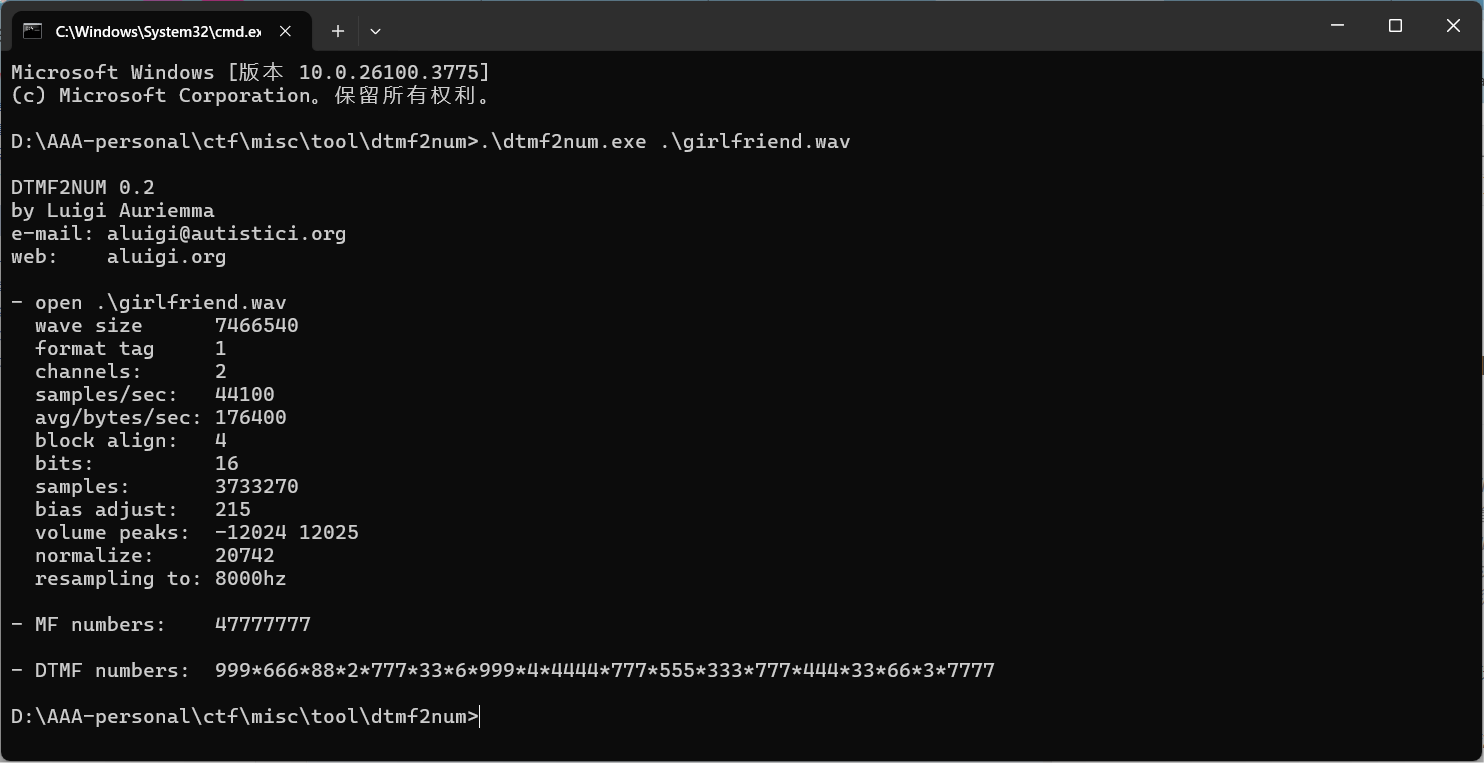
直接识别就行
999*666*88*2*777*33*6*999*4*4444*777*555*333*777*444*33*66*3*7777
当然懒人也可以用随波逐流一把梭,也是可以的

得到的密码是手机键盘编码,具体可参考那种功能机的九键键盘
其中999指的是9按三次,得到的是y,以此类推
密码解析
999 ---> y
666 ---> o
88 ---> u
2 ---> a
777 ---> r
33 ---> e
6 ---> m
999 ---> y
4 ---> g
4444 ---> i
777 ---> r
555 ---> l
333 ---> f
777 ---> r
444 ---> i
33 ---> e
66 ---> n
3 ---> d
7777 ---> s
[DDCTF2018](╯°□°)╯︵ ┻━┻(编码新考点(旧知新考))
题目d4e8e1f4a0f7e1f3a0e6e1f3f4a1a0d4e8e5a0e6ece1e7a0e9f3baa0c4c4c3d4c6fbb9b2b2e1e2b9b9b7b4e1b4b7e3e4b3b2b2e3e6b4b3e2b5b0b6b1b0e6e1e5e1b5fd
可以看出来这是一个16进制编码,但是直接解码并不能得到有效的字符
将首位拿去解码发现结果是212
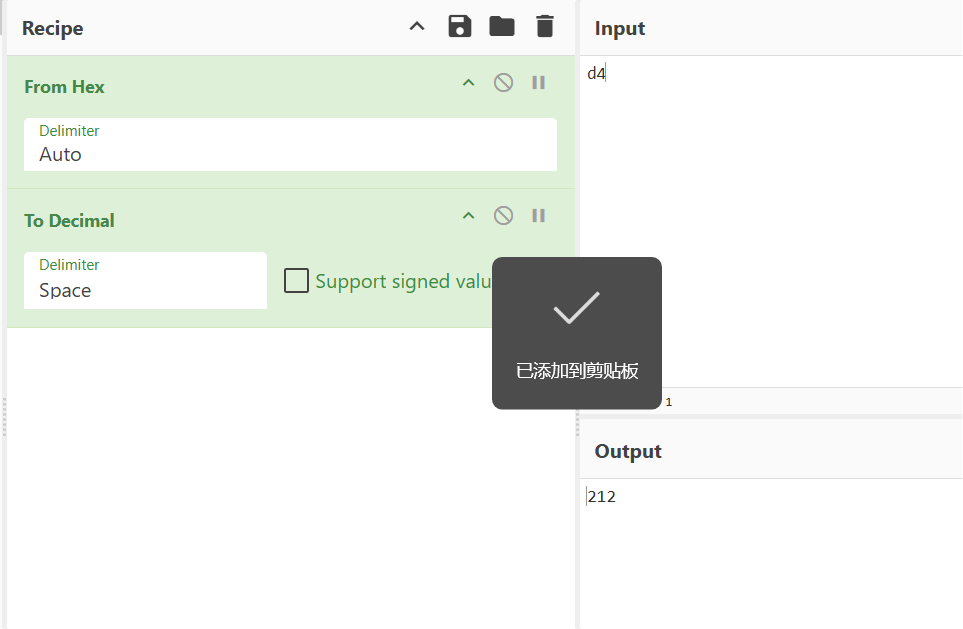
这明显不是正常的阿斯克码范围,难怪乱码
但是倘若将其减去128以后,或许一切都会明朗起来……
# 假设 data 是十六进制字符串
data = 'd4e8e1f4a0f7e1f3a0e6e1f3f4a1a0d4e8e5a0e6ece1e7a0e9f3baa0c4c4c3d4c6fbb9b2b2e1e2b9b9b7b4e1b4b7e3e4b3b2b2e3e6b4b3e2b5b0b6b1b0e6e1e5e1b5fd'
# 遍历 data,每两个字符作为一个十六进制数,转换为十进制,再转换为对应的 ASCII 字符
result = ''
for i in range(0, len(data), 2):
# 获取两个字符,组成一个十六进制数
hex_value = data[i:i+2]
# 将十六进制数转换为十进制并减去128
decimal_value = int(hex_value, 16) -128
# 将十进制数转换为对应的 ASCII 字符
result += chr(decimal_value)
# 输出转换后的字符串
print(result)
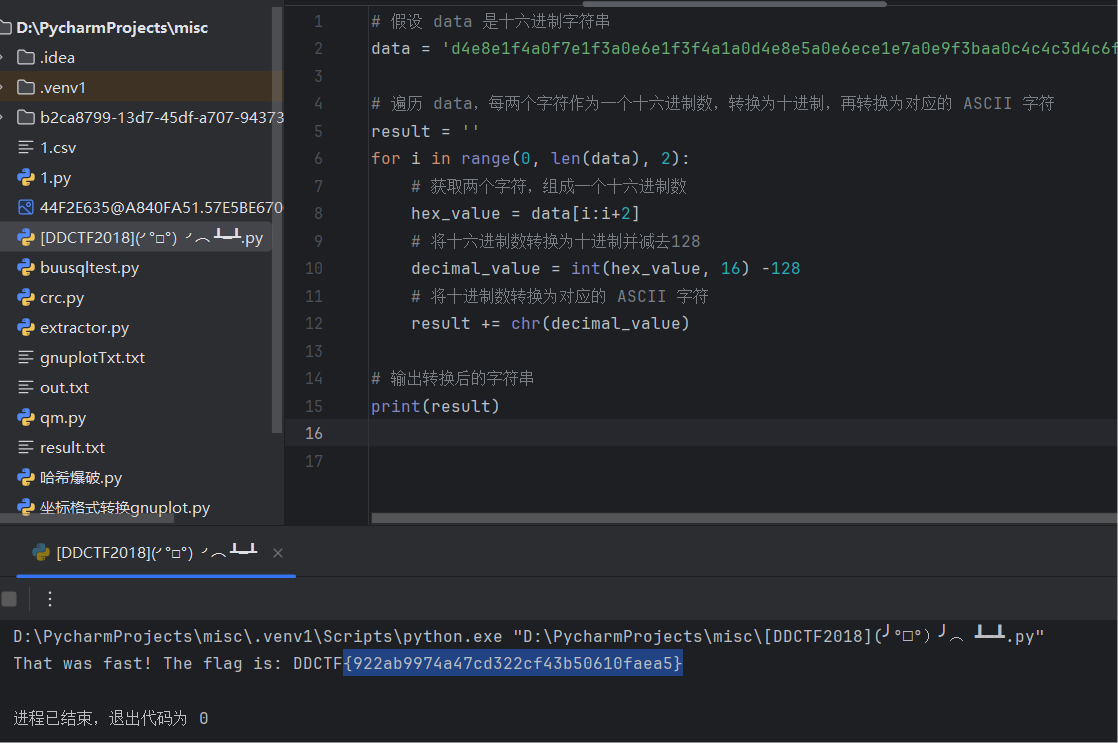
十分好用
flag{922ab9974a47cd322cf43b50610faea5}
考点
十六进制和阿斯克码的理解
脚本编写
[SUCTF2018]followme(流量分析基础巩固)
流量题也得注意顺序,
1.如果是http协议居多,可以尝试在http协议里面搜索flag的明文(例如CTF、flag这些)
2.如果发现有文件的上传,可以尝试导出这些文件,鲨鱼会自动尝试将其拼好
3.要明白这一坨流量里面发生了什么事情
这题很基础,直接在过滤器输CTF就能出flag
或者导出文件使用命令grep -r 'CTF' ./文件夹名称/也可以实现
Linux grep 命令
Linux grep (global regular expression) 命令用于查找文件里符合条件的字符串或正则表达式。
grep 指令用于查找内容包含指定的范本样式的文件,如果发现某文件的内容符合所指定的范本样式,预设 grep 指令会把含有范本样式的那一列显示出来
我们先进行协议分级,发现http占比很大,直接过滤,发现很多流量,足足有一万多
左上角导出文件选择http协议,看看都传了些啥
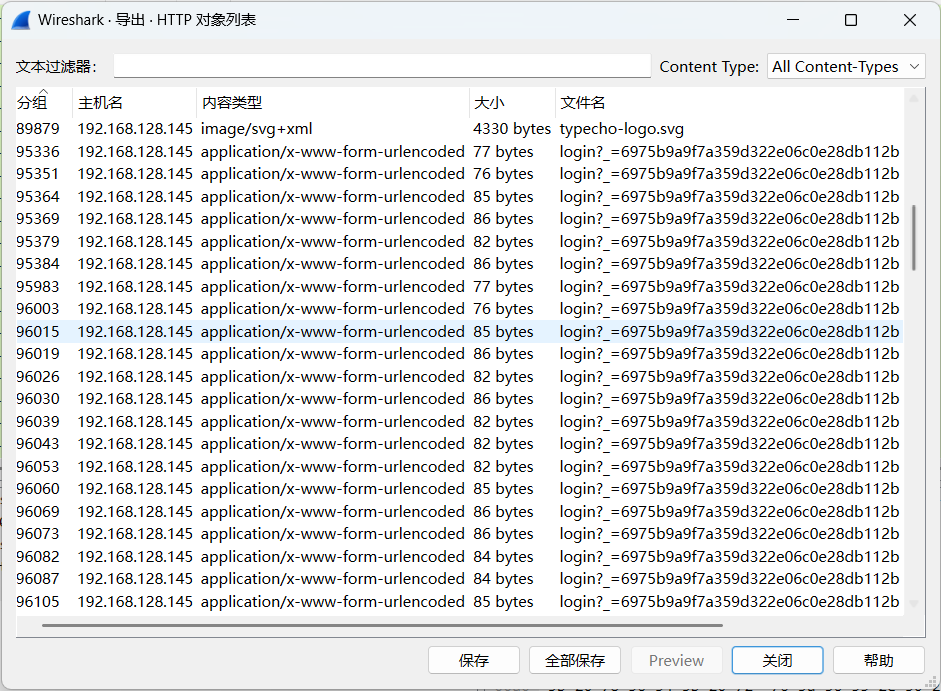
可以看到有很多尝试登录账户的信息,一般来说最大的那个数据包是登录成功的包(100多比特的那个)
点击跳转到对应包,直接看到明文flag
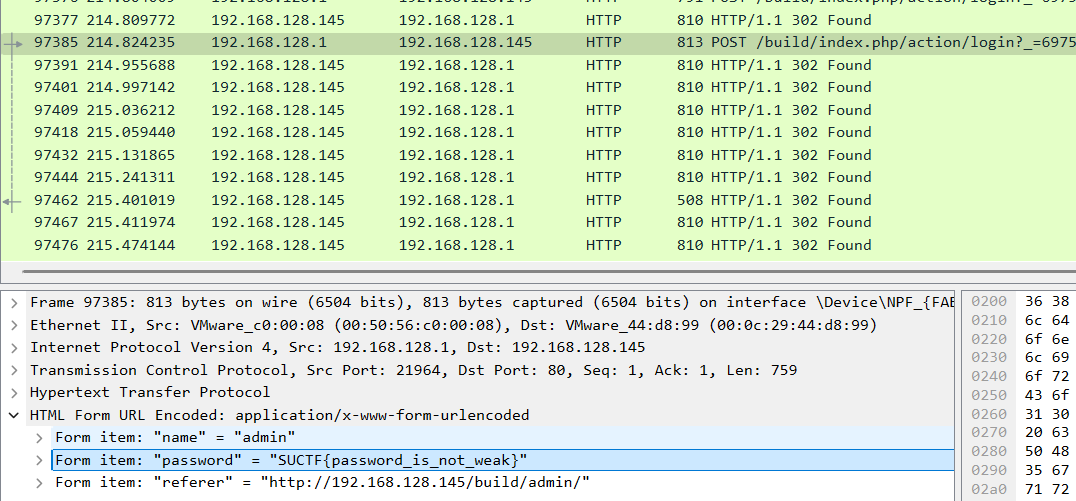
flag{password_is_not_weak}
考点
很基础的流量包分析
[MRCTF2020]千层套路
打开发现一个数字命名的压缩包,里面也有一个数字命名的压缩包
结合题目名称以及提示,可以知道题目希望我们能够编写一个脚本进行批量解压
根据实操推测压缩包密码就是本压缩包的名称
那么我们来写一个美味小jio本😋😋😋
import os
import zipfile
import pyzipper
def extract_final_archive(start_file, output_dir="final_extracted"):
current_archive = start_file
extracted_count = 0
while True:
# 获取当前压缩包的文件名(不带扩展名)作为密码
filename = os.path.splitext(os.path.basename(current_archive))[0]
if not (filename.isdigit() and len(filename) == 4):
print(f"文件名 '{filename}' 不是四位数字,无法作为密码")
return None
password = filename
print(f"正在处理: {current_archive}, 使用密码: {password}")
try:
# 检查是否是最后一个压缩包
with pyzipper.AESZipFile(current_archive) as zf:
file_list = zf.namelist()
# 检查压缩包内是否还包含压缩包
inner_archives = [f for f in file_list if f.lower().endswith(('.zip', '.rar', '.7z'))]
if not inner_archives:
print(f"找到最终压缩包: {current_archive}")
# 创建输出目录
os.makedirs(output_dir, exist_ok=True)
zf.extractall(path=output_dir, pwd=password.encode('utf-8'))
print(f"已提取到: {output_dir}")
return output_dir
# 如果还有内部压缩包,继续处理
if len(inner_archives) == 1:
# 提取内部压缩包到临时目录
temp_dir = "temp_extract"
os.makedirs(temp_dir, exist_ok=True)
zf.extractall(path=temp_dir, pwd=password.encode('utf-8'))
# 更新当前压缩包为内部压缩包
current_archive = os.path.join(temp_dir, inner_archives[0])
extracted_count += 1
else:
print("发现多个内部压缩包,无法自动处理")
return None
except Exception as e:
print(f"解压失败: {str(e)}")
return None
if __name__ == "__main__":
import sys
if len(sys.argv) < 2:
print("请拖放一个压缩包文件到本脚本上运行")
print("用法: python script.py <初始压缩包文件> [输出目录]")
sys.exit(1)
start_file = sys.argv[1]
output_dir = sys.argv[2] if len(sys.argv) > 2 else "final_extracted"
if not os.path.isfile(start_file):
print(f"文件不存在: {start_file}")
sys.exit(1)
result = extract_final_archive(start_file, output_dir)
if result:
print("\n最终提取结果:")
for root, _, files in os.walk(result):
for file in files:
print(f"- {os.path.join(root, file)}")
else:
print("提取失败")
终端输入下面的代码运行脚本
python 解压嵌套压缩包.py 0573.zip
代码好像有点问题,并不能直接提取最后一个压缩包里的内容
不过没关系,直接看运行结果就知道最后一个包是0156
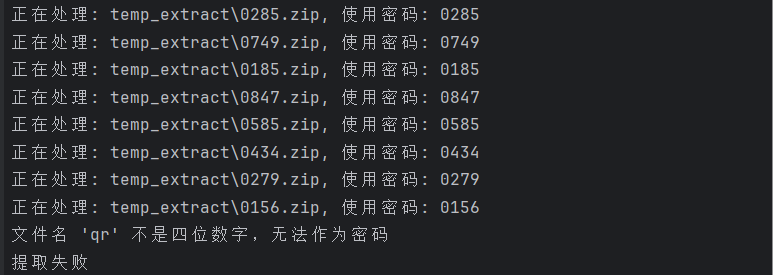
我们在脚本生成的文件夹里面找到该压缩包,解压以后发现里面有一个qr.txt文件,打开发现是一堆RGB数据
编写脚本将它们转换成图片
from PIL import Image
import re
import os
def rgb_text_to_image(input_file, output_image="output.png"):
# 读取文件内容
with open(input_file, 'r') as f:
content = f.read()
# 使用正则表达式提取所有RGB值
rgb_values = re.findall(r'\((\d+),\s*(\d+),\s*(\d+)\)', content)
if not rgb_values:
print("未找到有效的RGB数据!")
return
# 将字符串转换为整数元组
pixels = [tuple(map(int, rgb)) for rgb in rgb_values]
# 假设数据是正方形排列的(如果不是,需要额外处理)
size = int(len(pixels) ** 0.5)
if size * size != len(pixels):
print("警告:像素数量不是完全平方数,图片可能不完整")
# 使用最接近的方形尺寸
size = int(len(pixels) ** 0.5)
# 创建新图片
img = Image.new('RGB', (size, size))
# 填充像素数据
img.putdata(pixels[:size * size]) # 确保只使用适合方形图片的像素
# 保存图片
img.save(output_image)
print(f"图片已保存为 {output_image}")
# 显示图片(可选)
img.show()
if __name__ == "__main__":
input_file = "qr.txt" # 默认输入文件名
output_image = "qr_code.png" # 默认输出文件名
# 检查文件是否存在
if not os.path.exists(input_file):
print(f"错误:文件 {input_file} 不存在!")
else:
rgb_text_to_image(input_file, output_image)
直接运行即可,可以发现脚本马上跑了个图出来
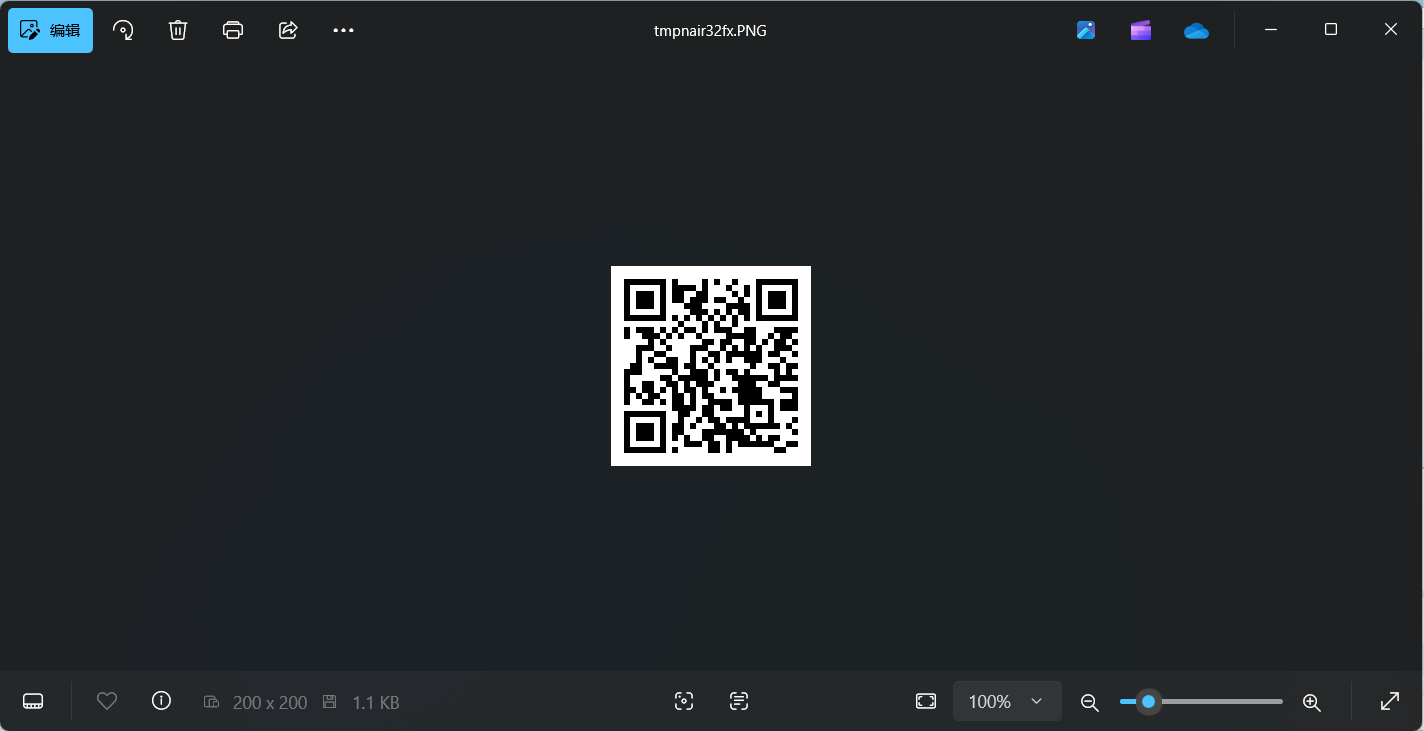
扫码得到flag
flag{ta01uyout1nreet1n0usandtimes}
考点
嵌套压缩包解压
RGB数据转图片
脚本编写
百里挑一(图片流量包混合新题型)
打开流量包进行协议分级发现大量jpg文件,导出后有一百多张
根据别人的wp可知这里需要用到exiftool(linux)进行图片exif信息批量读取
然鹅,直接在小鲨鱼ctrl+f或者搜索分组字节流flag就能得到前半段flag……
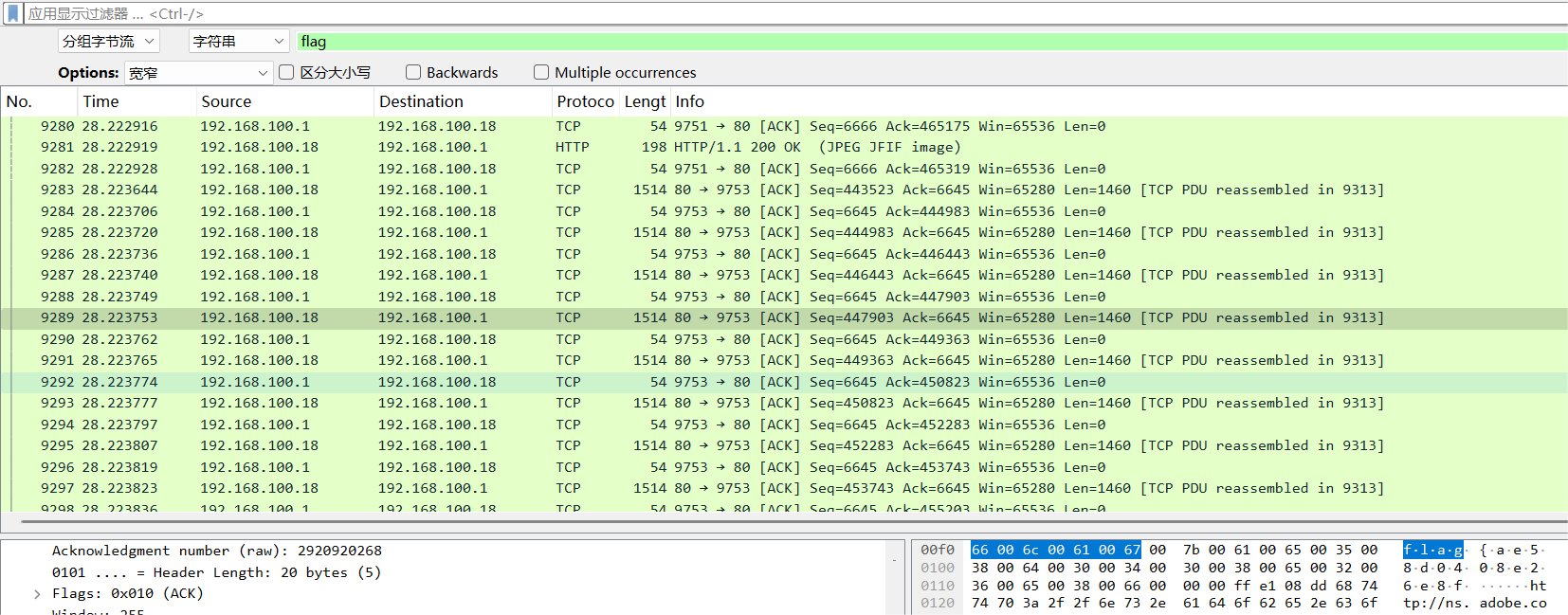
所以,流量包还是要善用搜索……
后半段flag,老样子,直接搜exif
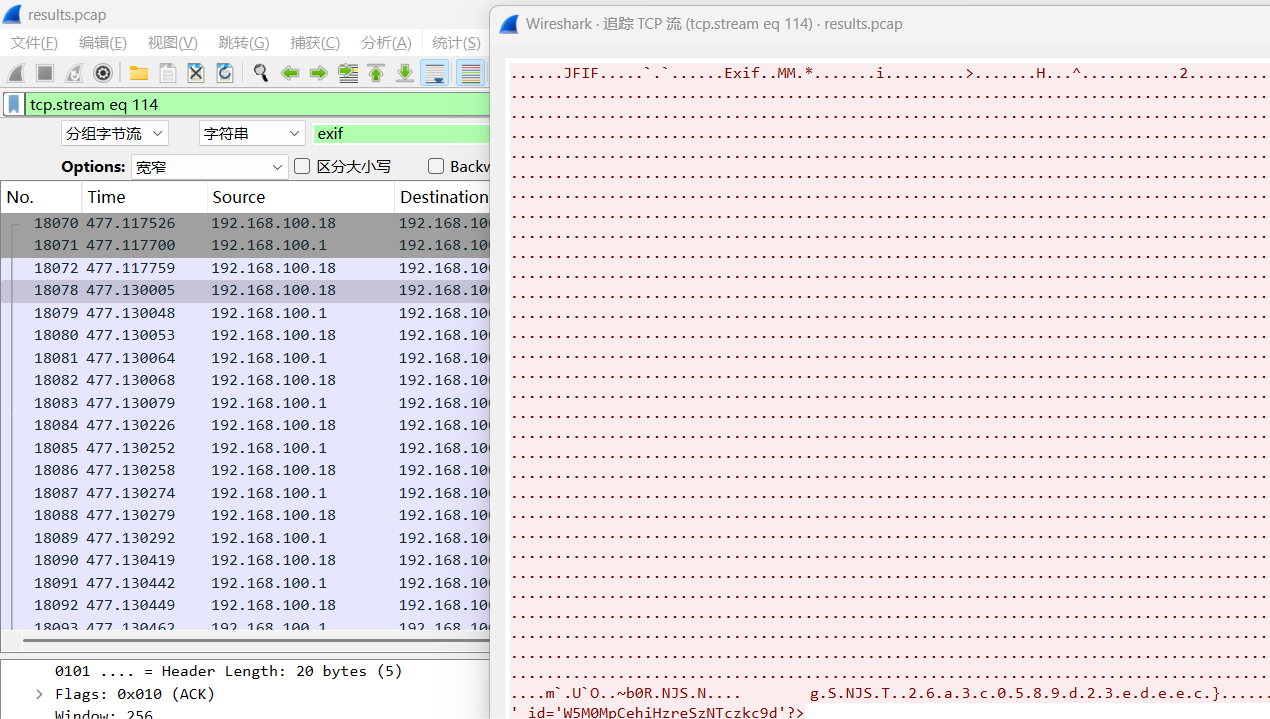
在高亮的那个流选择追踪就能看到
其他的做法就是直接一个个追踪tcp,一直到114流
flagflag{ae58d0408e26e8f26a3c0589d23edeec}
考点
小鲨鱼搜索
图片exif批量分析(exiftool使用)
流量追踪(耐心版)
[MRCTF2020]CyberPunk
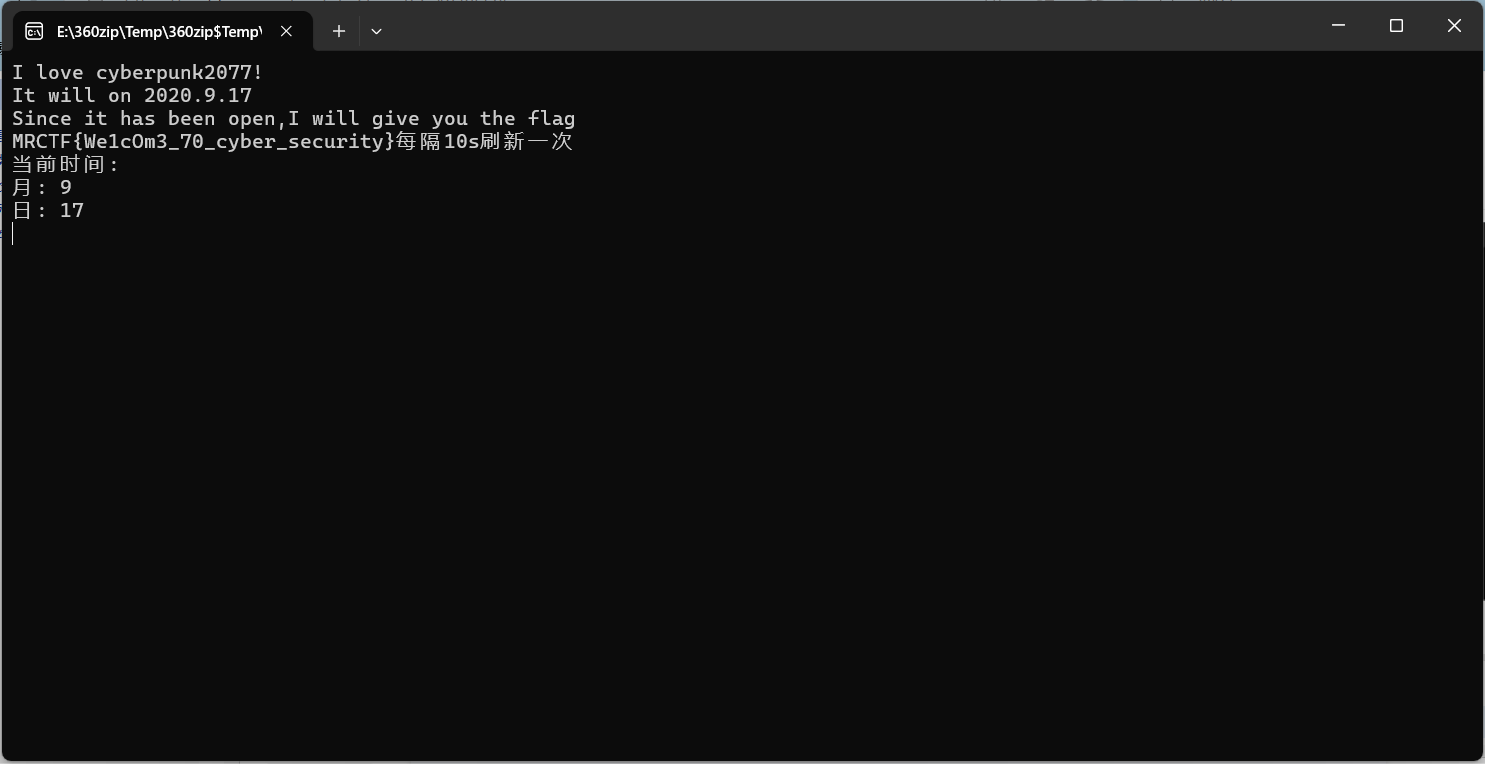
我喜欢赛博朋克2077!他在2020.9.17发售,到了那时候我会给你flag!
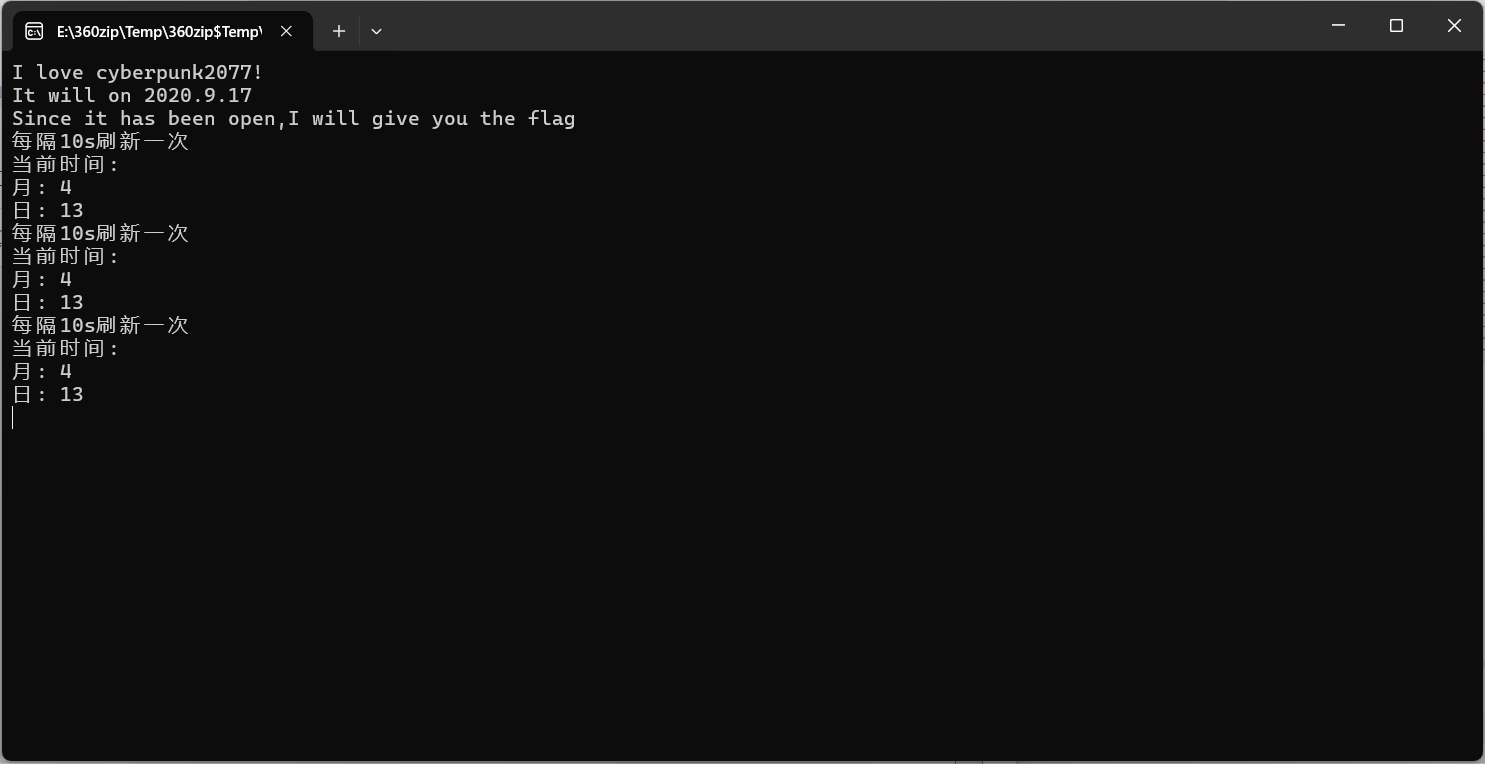
把时间改到2020.9.17就好了
考点
好运来
[BSidesSF2019]zippy
打开发现是压缩包,结合题目信息,应该是找到里面的zip
tcp过滤后只剩几个流量包,一个个点着看,发现一个压缩包
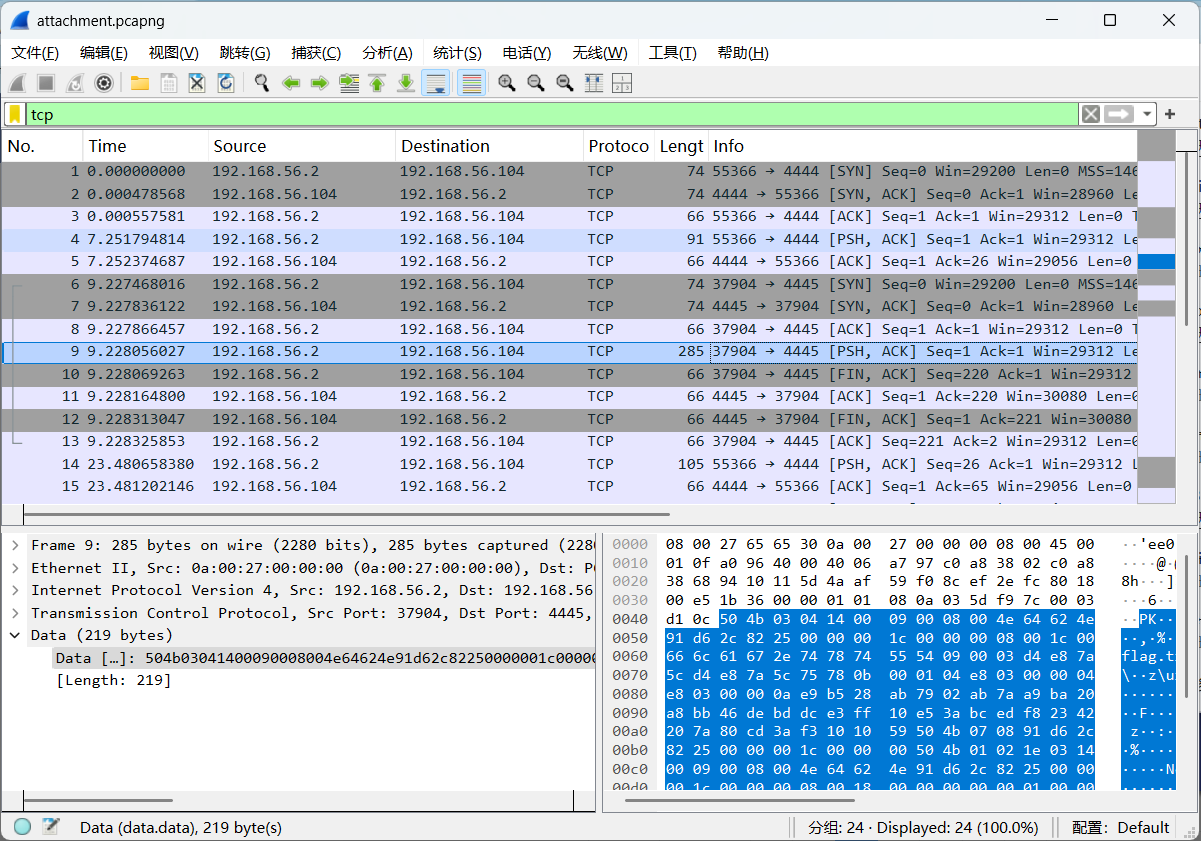
导出分组字节流
发现压缩包有密码,且不是伪加密
密码就在这几个tcp流里面,直接找吧
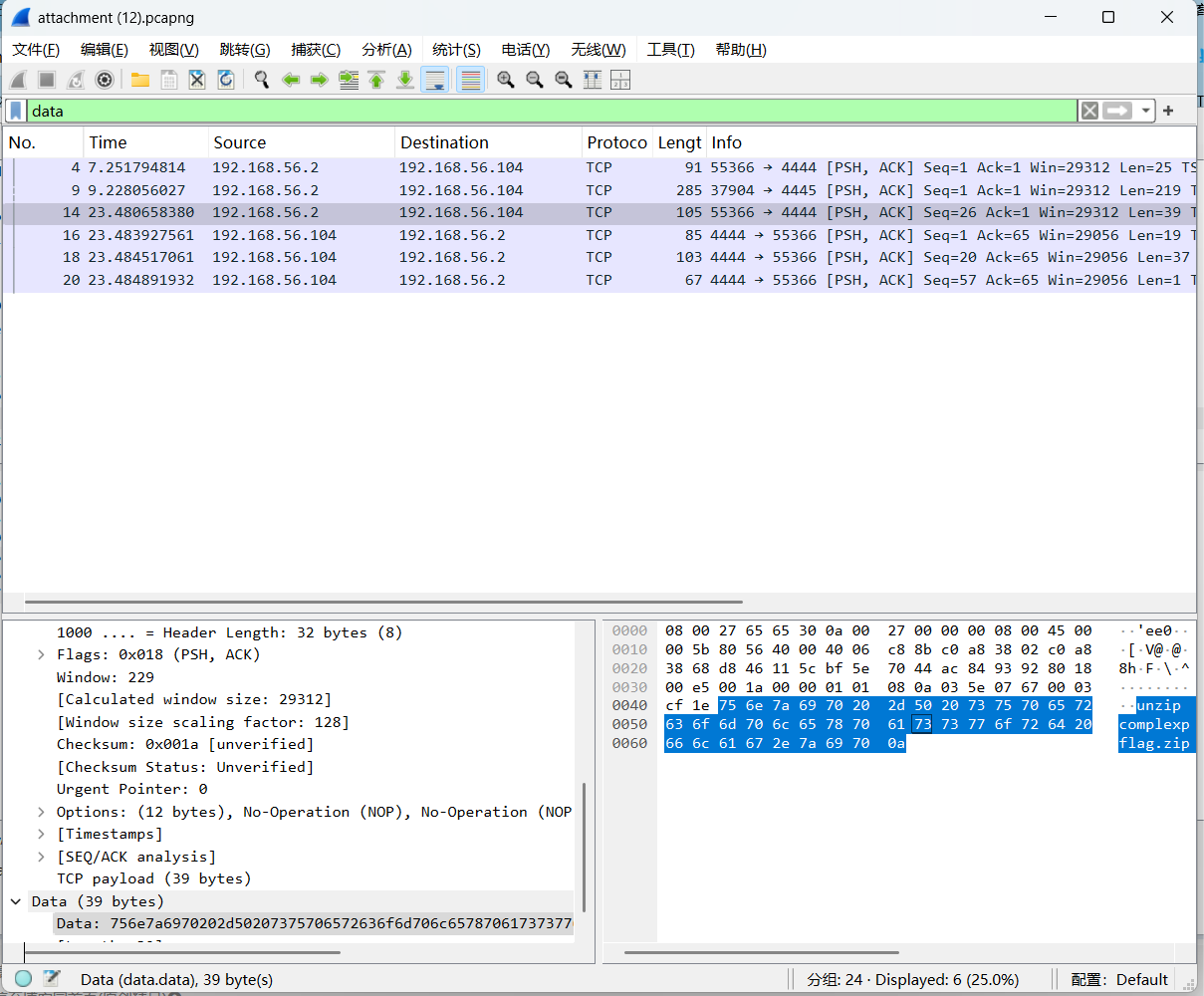
unzip是linux里面的解压zip文件的命令(-p 后面是这个压缩包的密码)
unzip -P supercomplexpassword flag.zip
-p是命令选项
supercomplexpassword是解压密码
flag.zip是文件名字
输入密码得到flag
flag{this_flag_is_your_flag}
考点
流量包分析
[安洵杯 2019]Attack
随便搜搜,发现有压缩包,但一直找不到
尝试用十六进制504B搜,搜到成功搜到压缩包
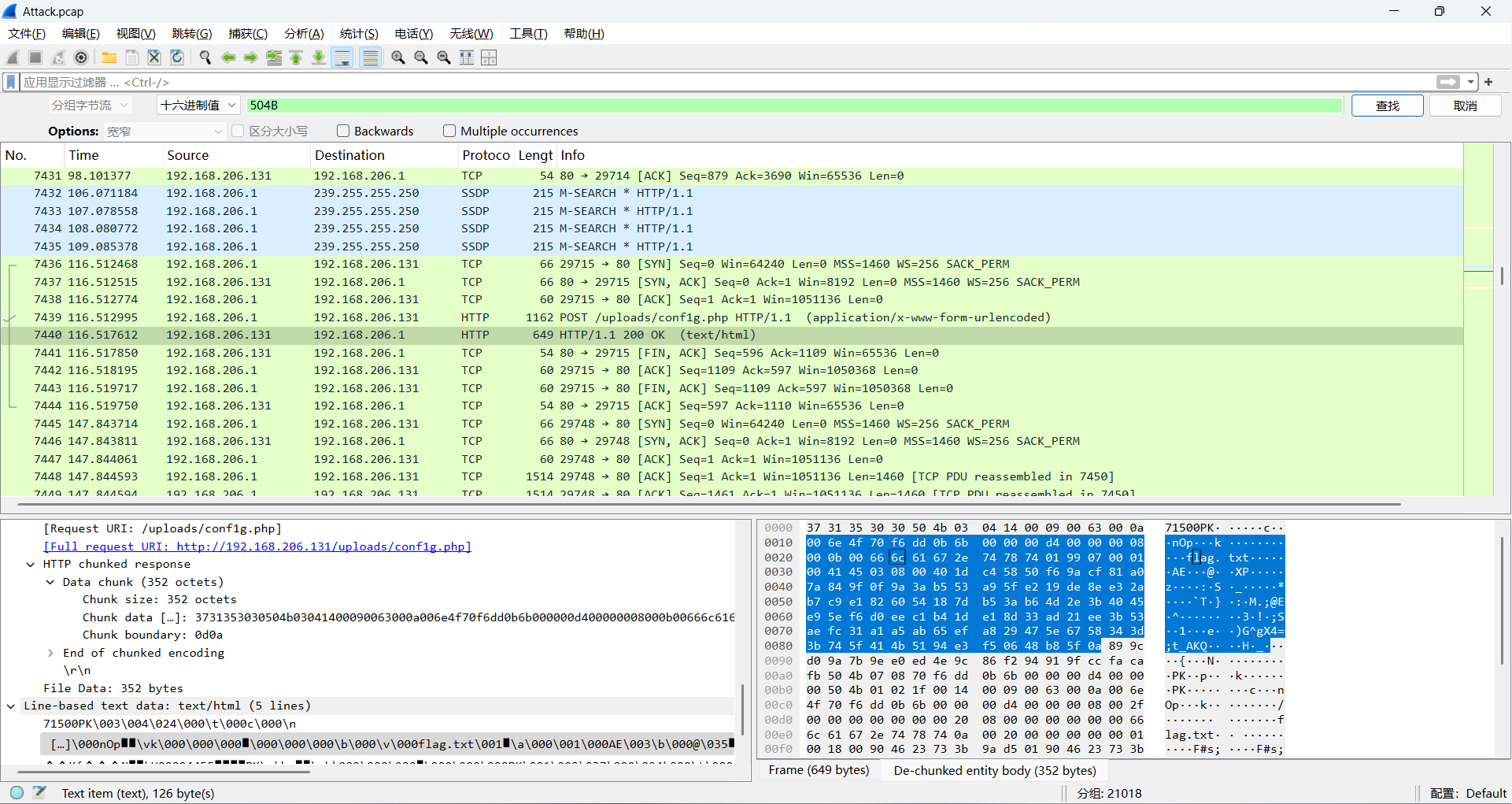
导出分组字节流
发现压缩包有密码,且不是伪加密
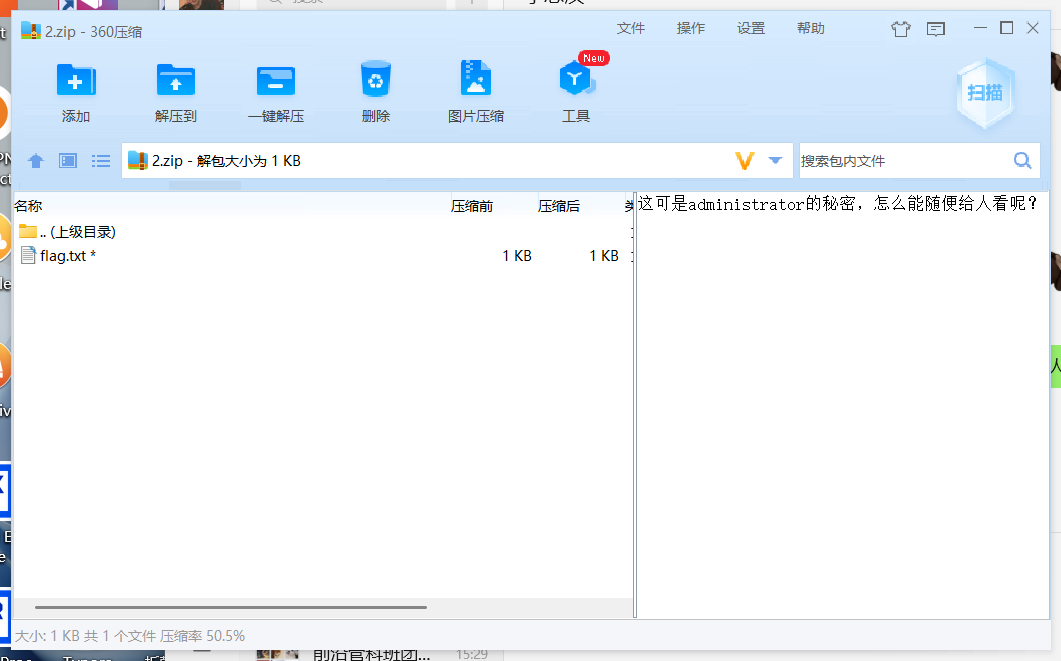
这可是Windows管理员的密码
在导出http对象中找到了一个lsass.dmp文件
.dmp文件的重要性
.dmp 文件通常是内存转储(Memory Dump)文件的扩展名。它保存了程序在特定时间点(通常是程序崩溃或发生错误时)内存中的内容。这些文件通常用于调试目的,以帮助开发人员了解程序崩溃或错误发生的原因。
如果 .dmp 文件包含了程序内存中的敏感信息,如明文密码、加密密钥、用户数据等,黑客可能通过分析 .dmp 文件获取这些信息。
我们将.dmp文件导出,使用新工具进行分析——mimikatz
mimikatz——内网渗透神器
Mimikatz 是一个广为人知的开源工具,主要用于安全测试和渗透测试领域。它由法国安全研究员 Benjamin Delpy 开发,最初是为了展示 Windows 操作系统中存在的安全漏洞。Mimikatz 可以执行多种操作,特别是在 Windows 系统上提取敏感信息。
我们使用mimikatz分析.dmp文件:
//提升权限
privilege::debug
//载入dmp文件
sekurlsa::minidump lsass.dmp
//读取登陆密码
sekurlsa::logonpasswords full
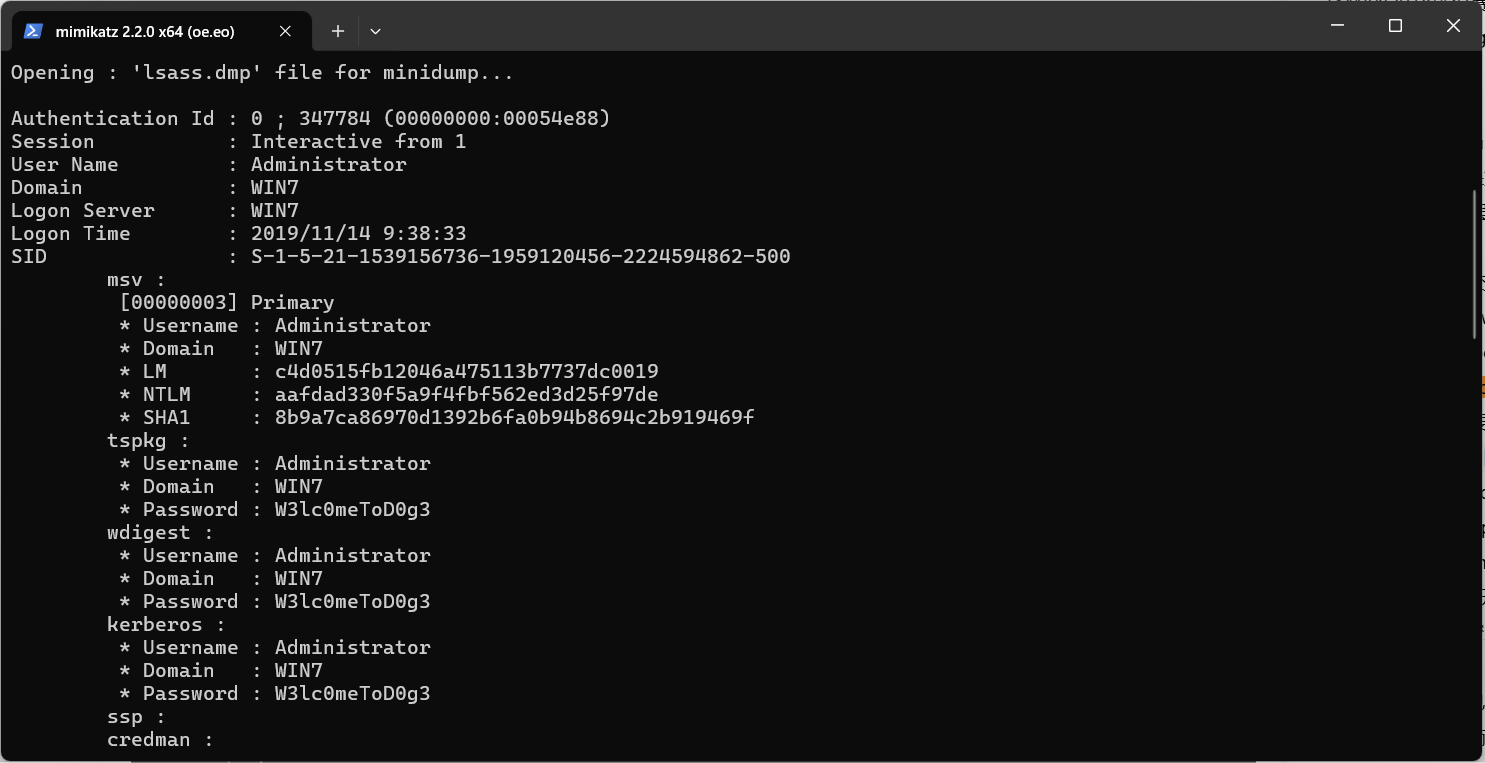
得到密码W3lcOmeToD0g3
flagflag{3466b11de8894198af3636c5bd1efce2}
考点
流量包分析
内存取证
[UTCTF2020]basic-forensics
下载发现是一张打不开的jpg
到010看看,发现是纯文本文件
直接搜flag
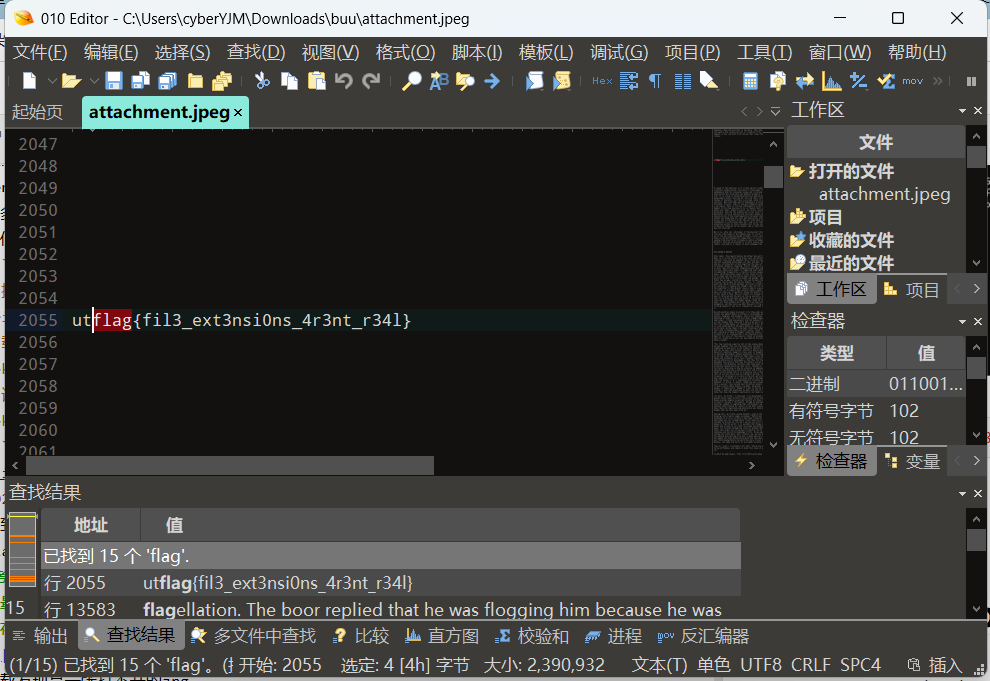
flagflag{fil3_ext3nsi0ns_4r3nt_r34l}
考点
010搜索功能
[DDCTF2018]流量分析(小鲨鱼使用:TLS密钥的导入)
拿到题目,协议分级
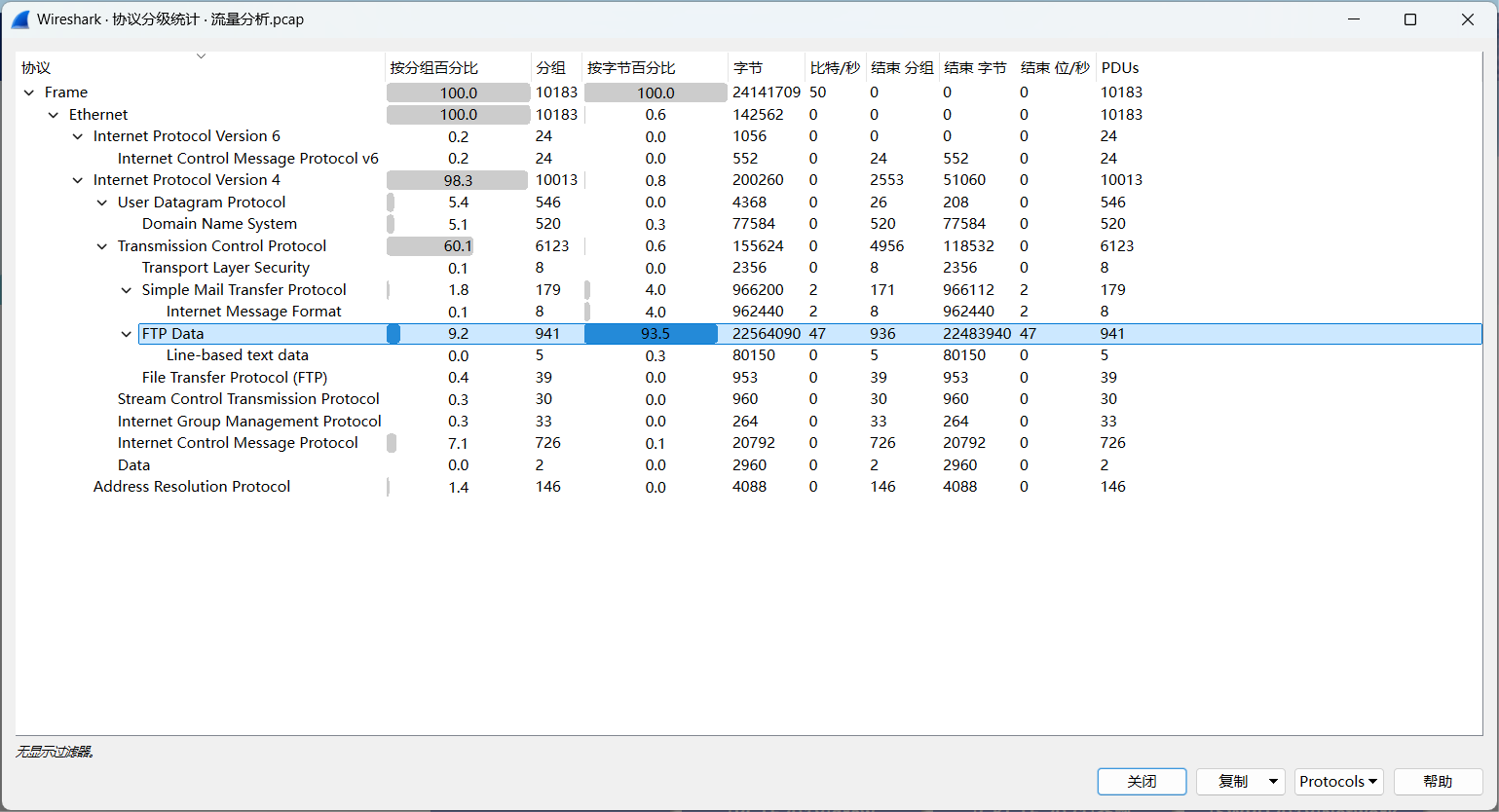
发现占了很大空间的FTP,并且有TLS协议(与提给信息相互对应)
导出对象,发现FTP里面有两个压缩包,IMF里面有一堆eml文件
IMF是什么
IMF(Internet Message Format),因特网消息格式。因特网消息格式是指文本消息在因特网上传输的格式。
其中SMTP等价于邮件信封,IMF等价于信封中的信件。
它包含发起者、接收者、主题和日期。
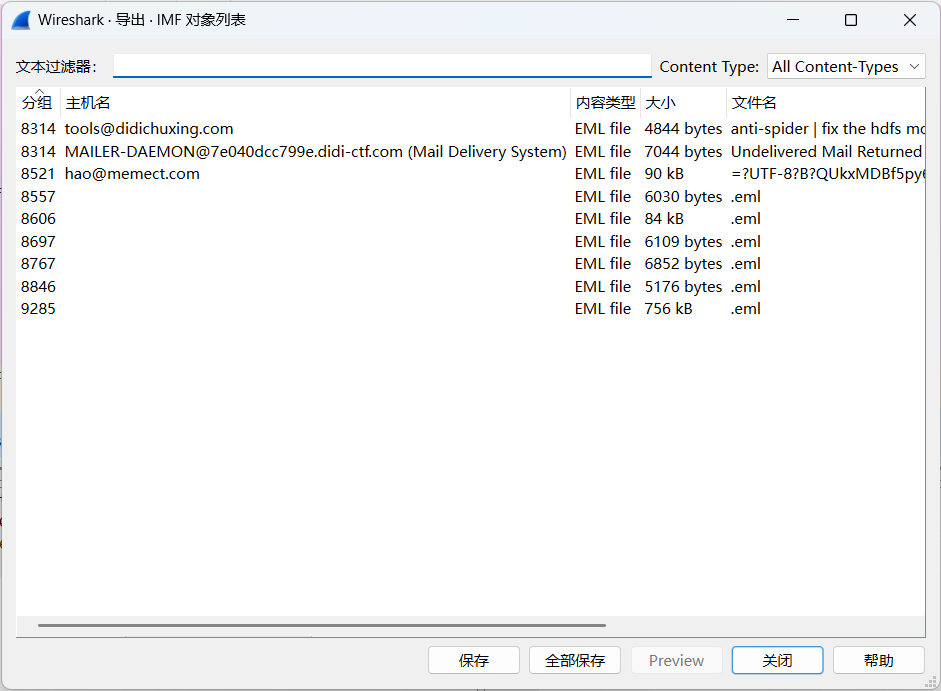
在文件夹里发现一个邮件特别的大,足足比别人大了一位数,很难不想去看看里面藏了什么小秘密
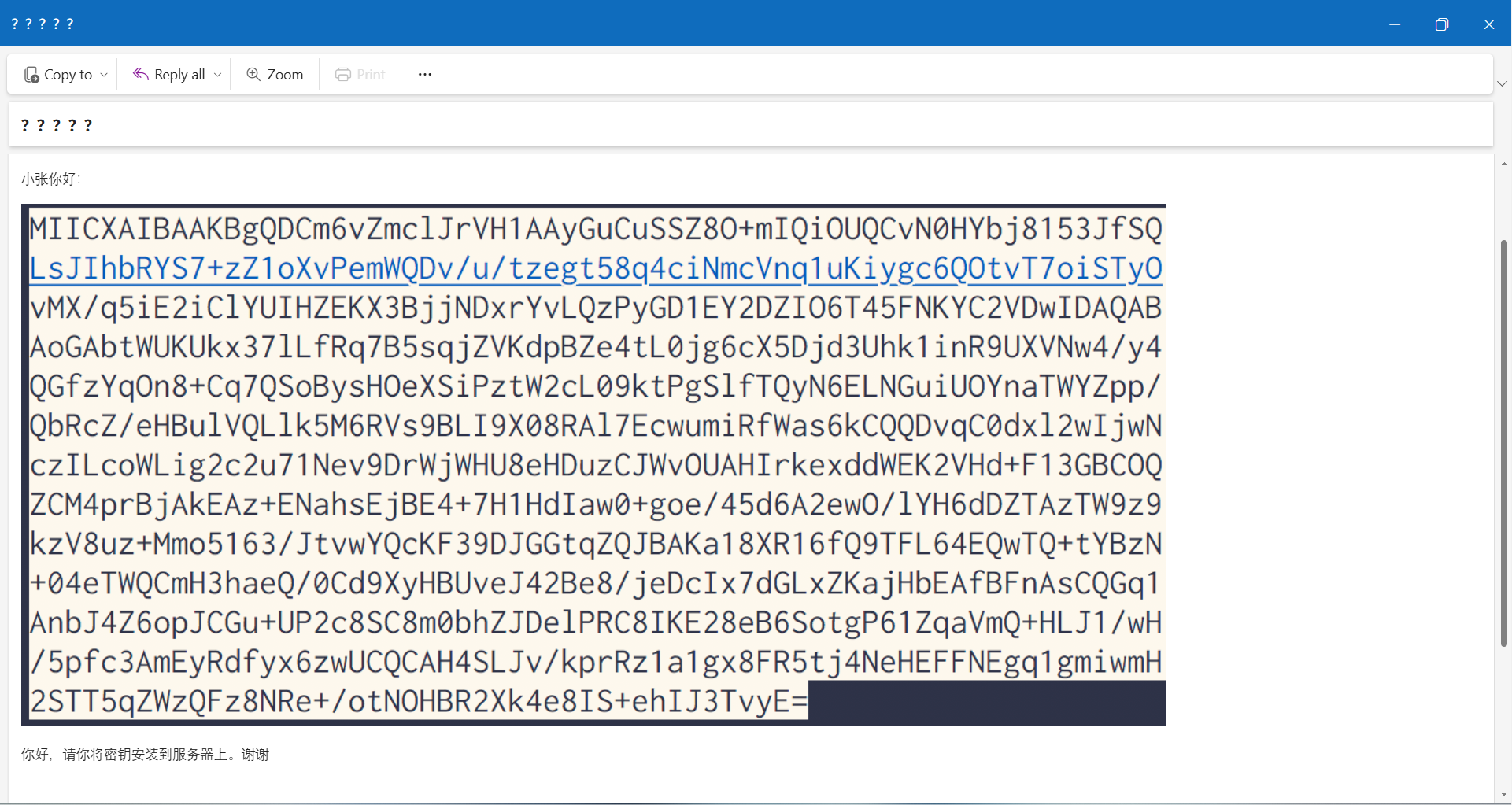
原来是我们的私钥大宝贝(邮件说的)
把私钥OCR出来,填到题目给的私钥模板里,并把拓展名改成.key
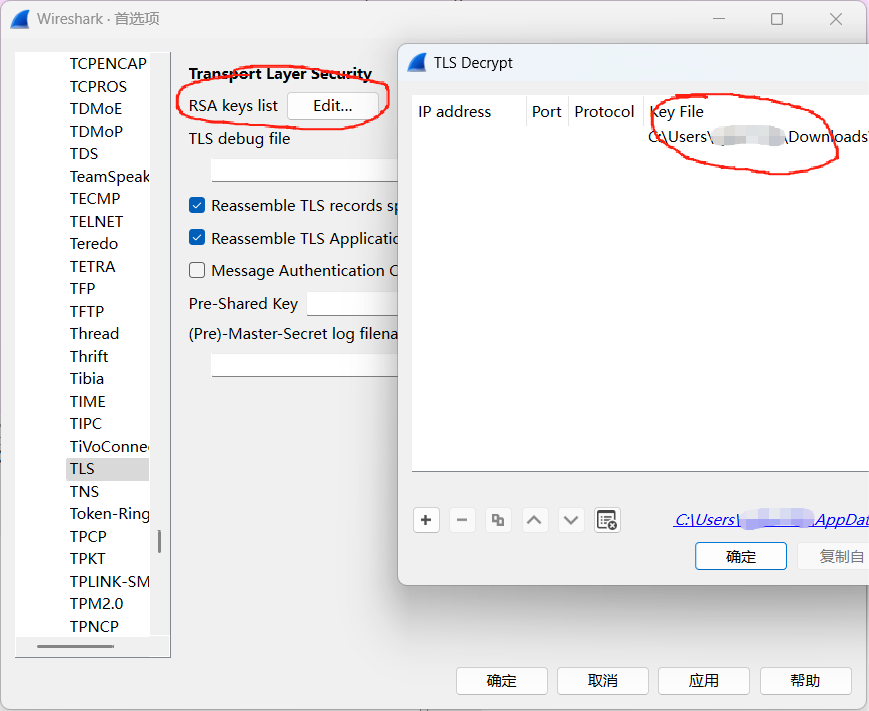
先点edit,再点key file就能导入TLS密钥了
导入私钥成功后我们就可以查看http协议中加密的内容了:
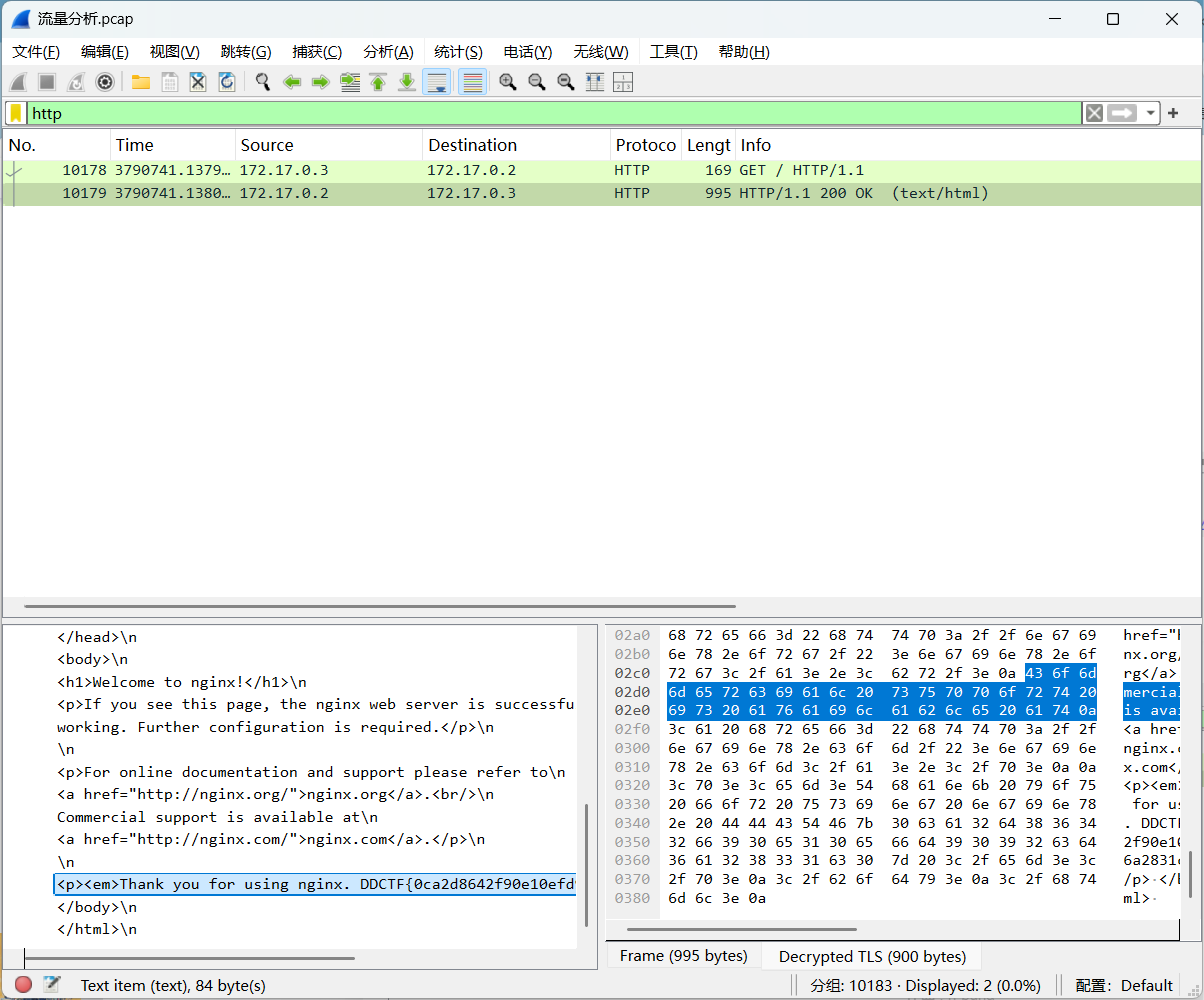
找到flagflag{0ca2d8642f90e10efd9092cd6a2831c0}
考点
流量分析
对于使用鲨鱼解密https协议的操作
[SUCTF 2019]Game
在index.html里找到了一个flag
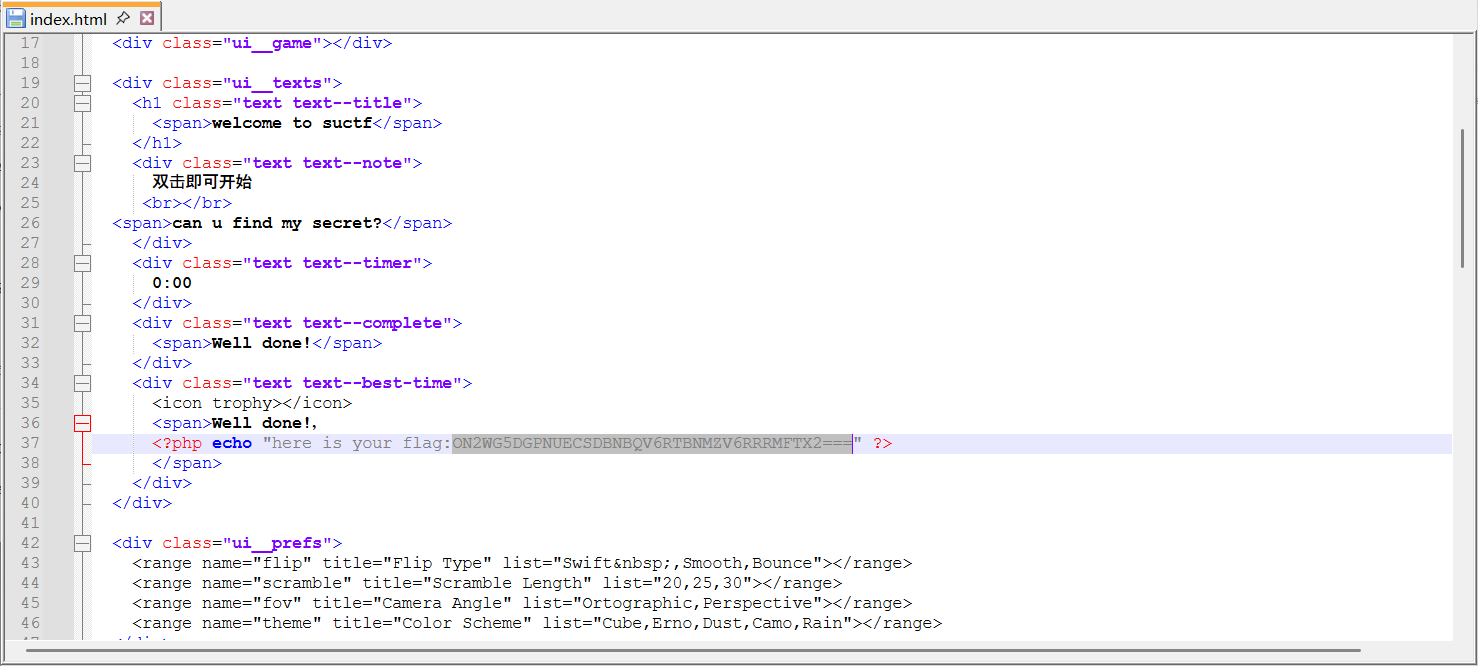
然鹅解码结果是suctf{hAHaha_Fak3_F1ag}
这是个假flag
把另一个附件 和泉纱雾按照流程分析一遍,发现存在LSB隐写
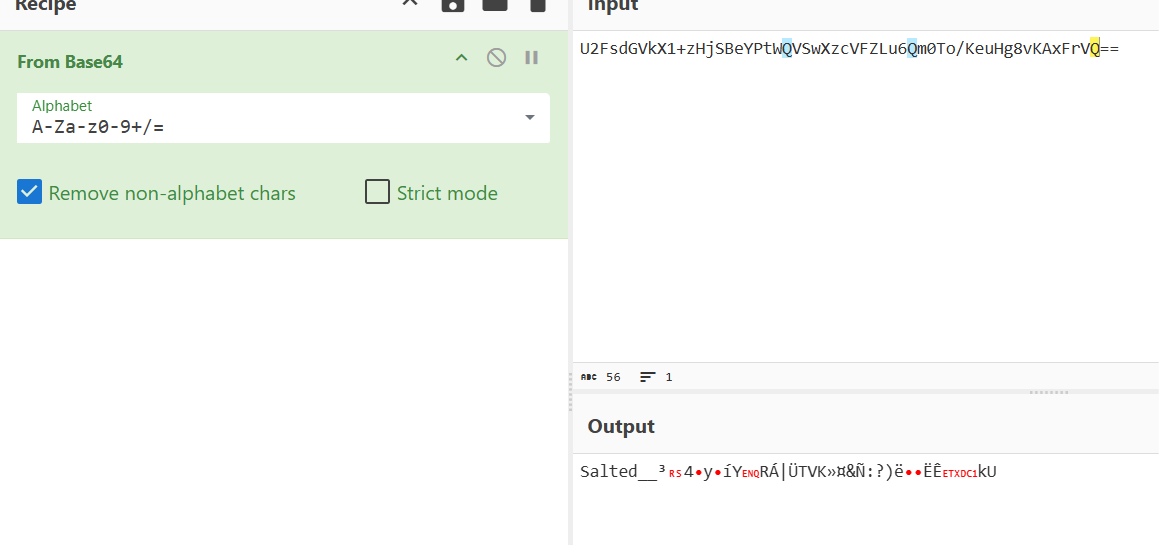
解码出一个奇奇怪怪的东西
搜索解码结果发现什么密码加盐???
https://www.cnblogs.com/handsomesnowsword/p/18302560
已有前人研究,不过多赘述了(我是懒狗😭😭😭)
在这个解密网站,将fake flag作为密码进行解密就好了
https://www.sojson.com/encrypt_triple_des.html
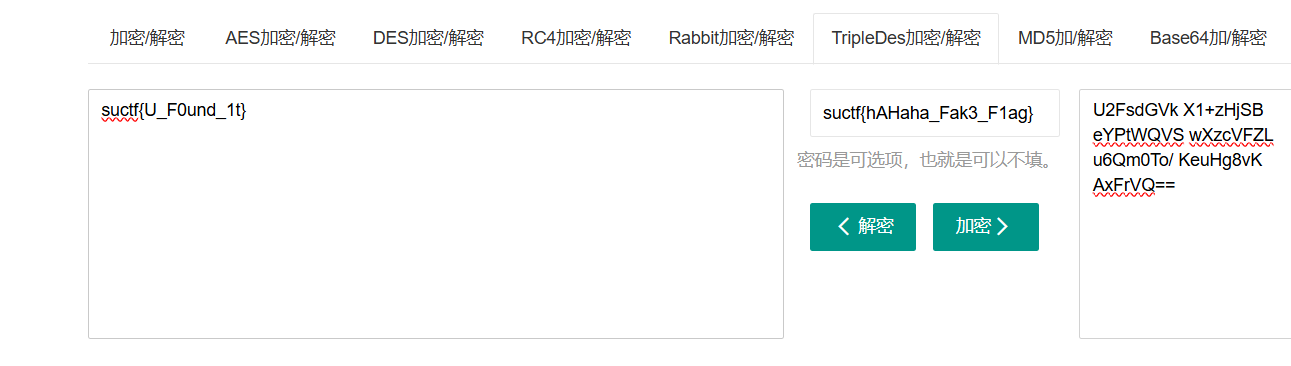
flagflag{U_F0und_1t}
USB(新难混合)
下载题目以后发现一个压缩包和一个未知ftm文件
压缩包提示信息不匹配
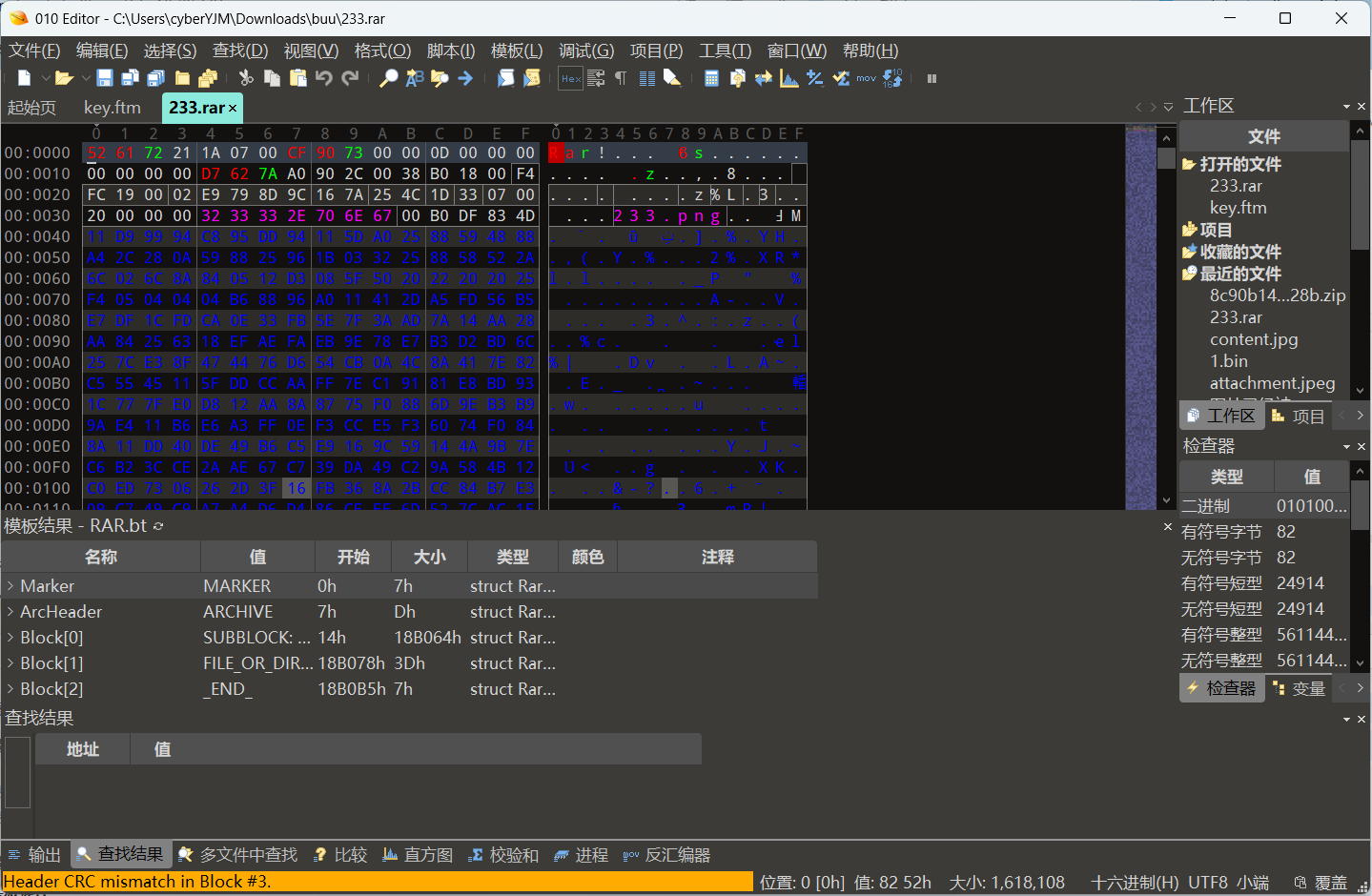
ftm文件里面发现一个压缩包(用binwalk无脑提取也可以)
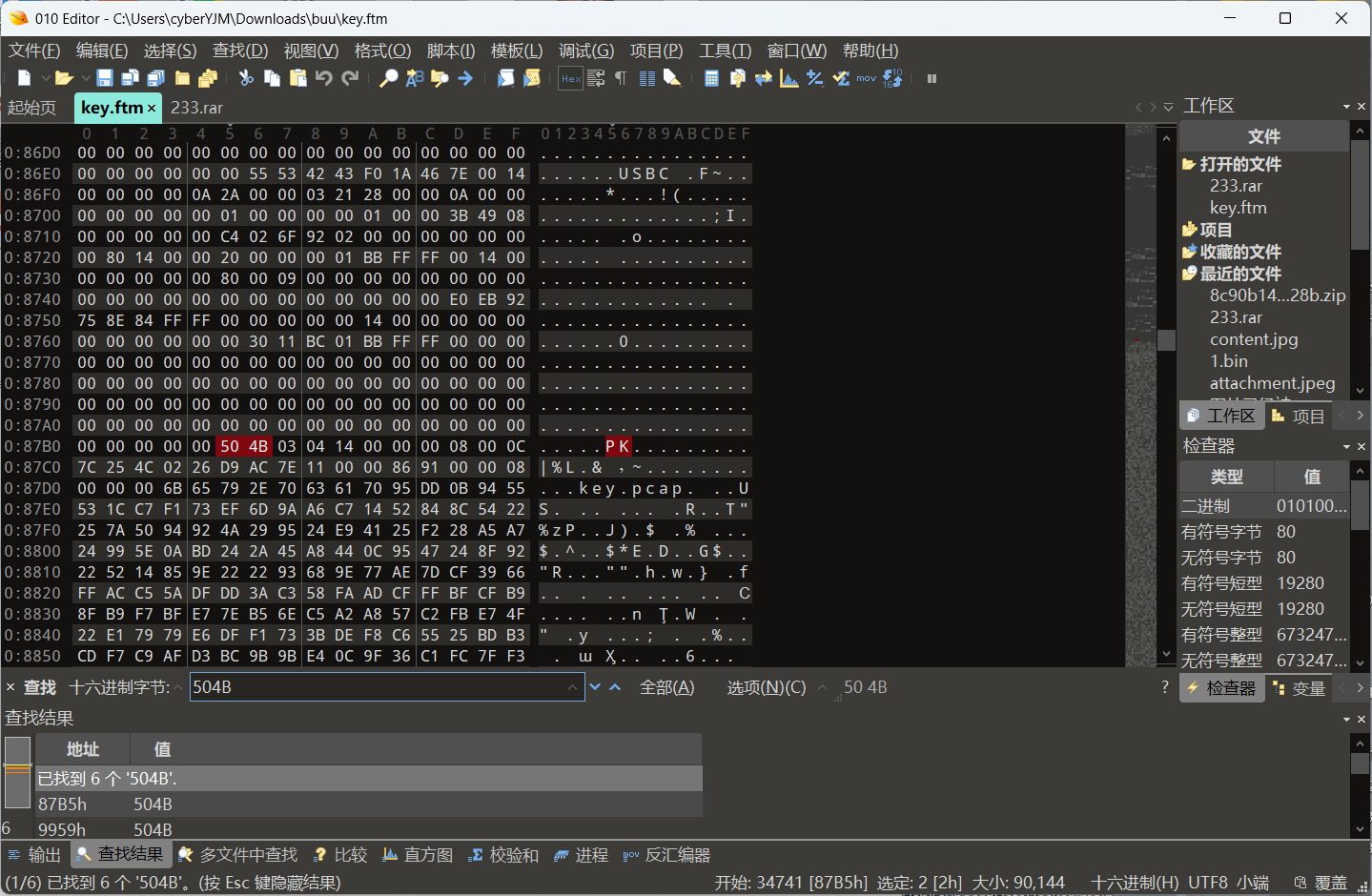
古法手动取出压缩包以后打开发现一个流量包
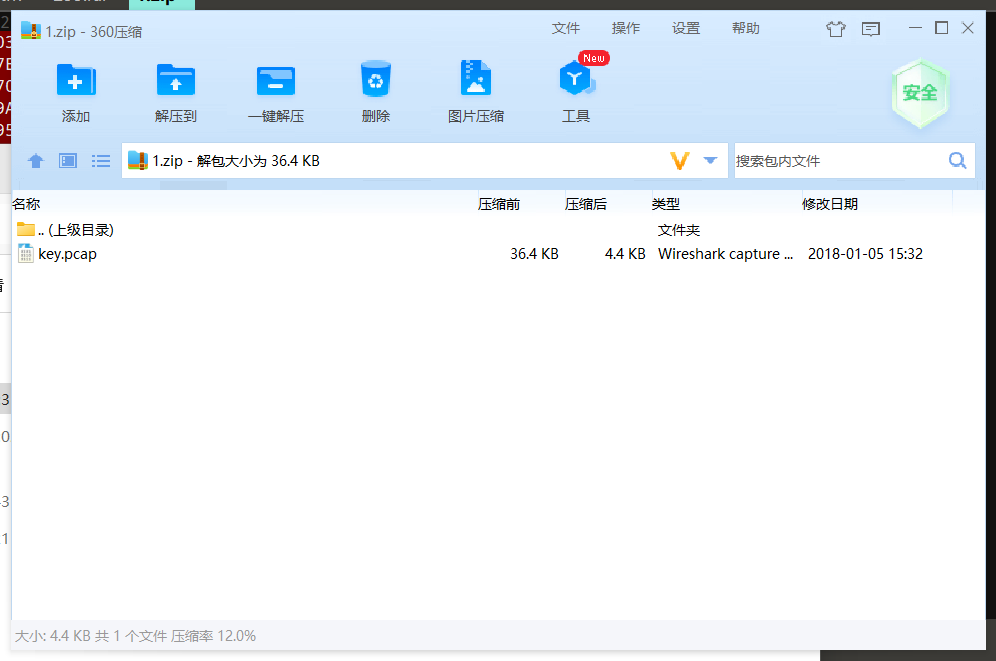
里面全是USB流量
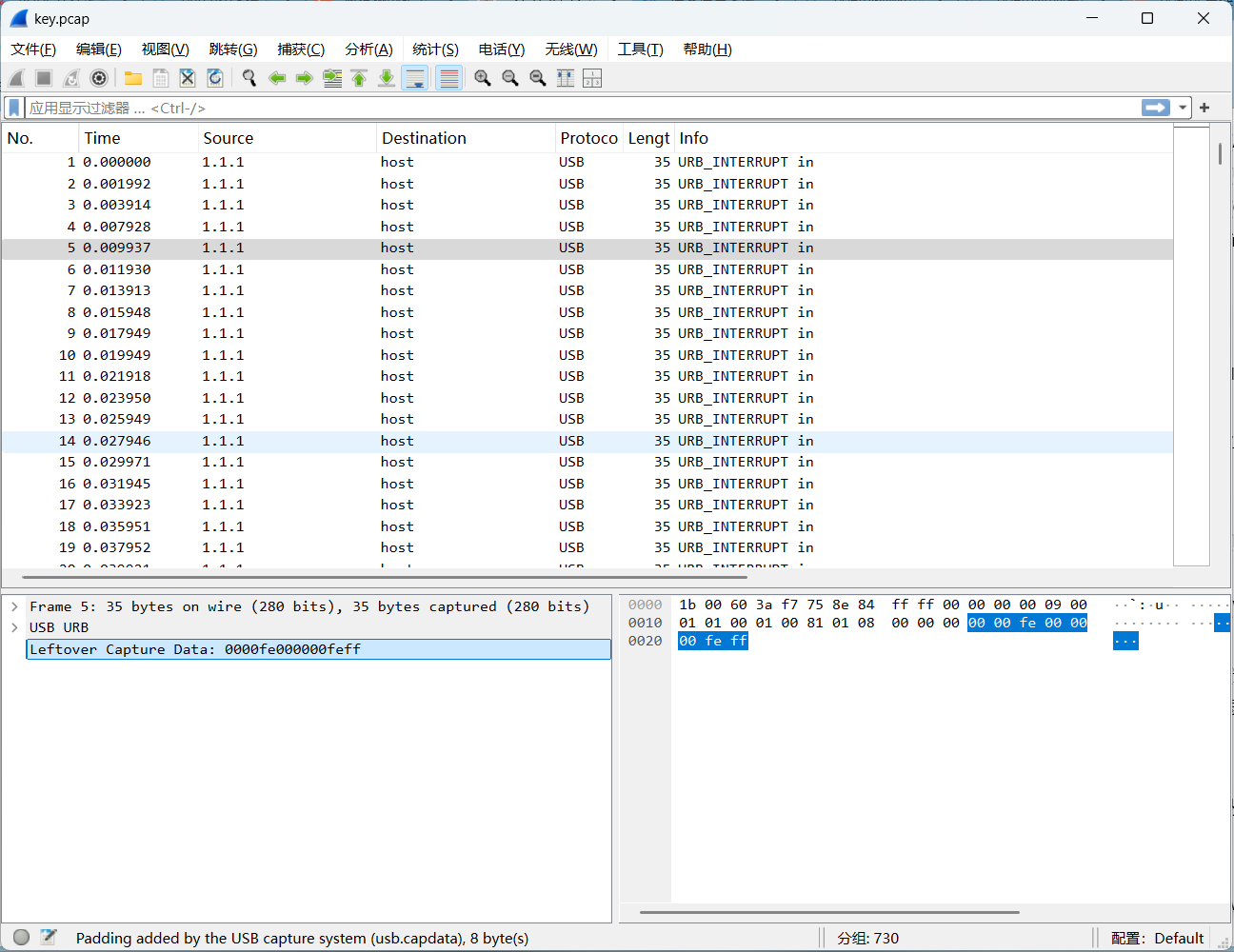
USB键盘流量包详解
usb.capdata是 USB 数据包中的最主要的字段,用于显示捕获的 USB 数据的原始字节。这些字节通常表示设备在 USB 总线上发送的实际数据。对于 USB 键盘,usb.capdata 通常包含按键操作的编码信息。比如我们分析一下第一个数据包
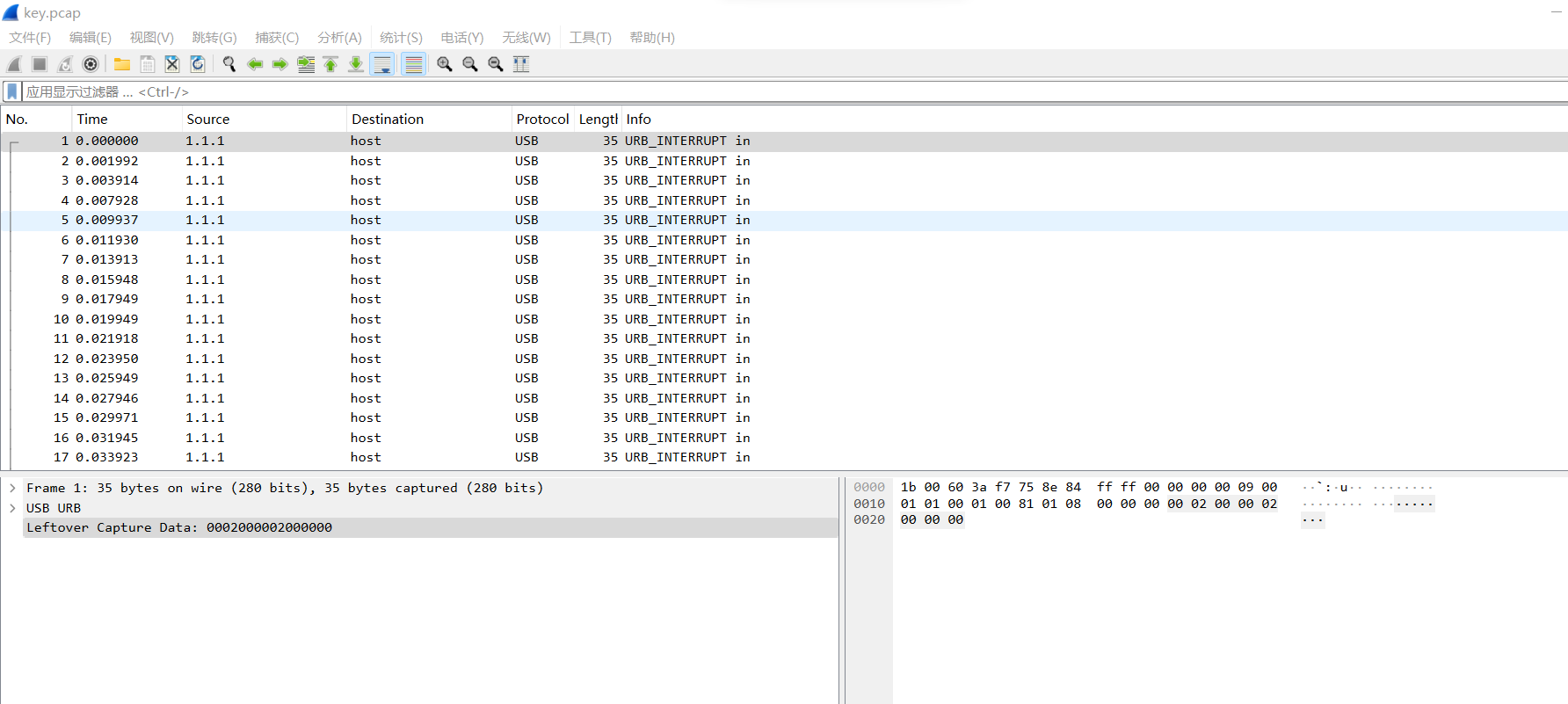
usb.capdata的值为0002000002000000
第一个字节 (00): 修饰键(Modifier Key)状态,如 Ctrl、Shift、Alt 等。值为 00 表示没有修饰键被按下。
第二个字节 (02): 保留位(Reserved)。通常没有特别意义,固定为 00。
第三到第八个字节 (00 02 00 00 00 00): 这些字节表示按键编码(Keycode)。每个字节表示一个按键,其中 00 表示没有按键被按下。按键编码 02 对应的是大键盘 1 键。
更多可以参考http://www.willhsu.com/zb_users/upload/2021/06/202106241624549419156181.pdf
总之这个流量包记录了USB连接的键盘输入数据,我们应该进行提取和分析。
这里,我们使用脚本UsbKeyboardDataHacker进行分析
py版本务必在310以上,记得换源
当然也可以用单脚本
#!/usr/bin/env python
# 修改为Windows兼容版本的USB键盘数据提取脚本
import sys
import os
DataFileName = "usb.dat"
presses = []
# 键盘映射表
normalKeys = {
"04":"a", "05":"b", "06":"c", "07":"d", "08":"e", "09":"f", "0a":"g", "0b":"h",
"0c":"i", "0d":"j", "0e":"k", "0f":"l", "10":"m", "11":"n", "12":"o", "13":"p",
"14":"q", "15":"r", "16":"s", "17":"t", "18":"u", "19":"v", "1a":"w", "1b":"x",
"1c":"y", "1d":"z","1e":"1", "1f":"2", "20":"3", "21":"4", "22":"5", "23":"6",
"24":"7","25":"8","26":"9","27":"0","28":"<RET>","29":"<ESC>","2a":"<DEL>",
"2b":"\t","2c":"<SPACE>","2d":"-","2e":"=","2f":"[","30":"]","31":"\\",
"32":"<NON>","33":";","34":"'","35":"<GA>","36":",","37":".","38":"/",
"39":"<CAP>","3a":"<F1>","3b":"<F2>", "3c":"<F3>","3d":"<F4>","3e":"<F5>",
"3f":"<F6>","40":"<F7>","41":"<F8>","42":"<F9>","43":"<F10>","44":"<F11>","45":"<F12>"
}
shiftKeys = {
"04":"A", "05":"B", "06":"C", "07":"D", "08":"E", "09":"F", "0a":"G", "0b":"H",
"0c":"I", "0d":"J", "0e":"K", "0f":"L", "10":"M", "11":"N", "12":"O", "13":"P",
"14":"Q", "15":"R", "16":"S", "17":"T", "18":"U", "19":"V", "1a":"W", "1b":"X",
"1c":"Y", "1d":"Z","1e":"!", "1f":"@", "20":"#", "21":"$", "22":"%", "23":"^",
"24":"&","25":"*","26":"(","27":")","28":"<RET>","29":"<ESC>","2a":"<DEL>",
"2b":"\t","2c":"<SPACE>","2d":"_","2e":"+","2f":"{","30":"}","31":"|",
"32":"<NON>","33":"\"","34":":","35":"<GA>","36":"<","37":">","38":"?",
"39":"<CAP>","3a":"<F1>","3b":"<F2>", "3c":"<F3>","3d":"<F4>","3e":"<F5>",
"3f":"<F6>","40":"<F7>","41":"<F8>","42":"<F9>","43":"<F10>","44":"<F11>","45":"<F12>"
}
def main():
if len(sys.argv) != 2:
print("使用方法:")
print(" python UsbKeyboardHacker.py 数据包.pcap")
print("提示:")
print(" 需要先安装tshark (Wireshark自带)")
print(" 请确保pcap文件包含USB键盘数据")
exit(1)
pcapFilePath = sys.argv[1]
# 修改为Windows兼容的tshark命令
tshark_cmd = f'tshark -r "{pcapFilePath}" -T fields -e usb.capdata -Y "usb.data_len == 8" > "{DataFileName}"'
os.system(tshark_cmd)
# 读取数据
try:
with open(DataFileName, "r") as f:
presses = [line.strip() for line in f if line.strip()]
except FileNotFoundError:
print("[错误] 未能生成数据文件,请检查:")
print("1. tshark是否安装并位于PATH中")
print("2. 输入文件路径是否正确")
return
# 解析按键数据
result = ""
for press in presses:
if not press:
continue
Bytes = press.split(":") if ":" in press else [press[i:i+2] for i in range(0, len(press), 2)]
if Bytes[0] == "00":
if Bytes[2] != "00" and Bytes[2] in normalKeys:
result += normalKeys[Bytes[2]]
elif int(Bytes[0], 16) & 0b10 or int(Bytes[0], 16) & 0b100000: # Shift键按下
if Bytes[2] != "00" and Bytes[2] in shiftKeys:
result += shiftKeys[Bytes[2]]
else:
print(f"[!] 未知按键码: {Bytes[0]}")
print("[+] 提取结果: ", result)
# Windows下删除临时文件
if os.path.exists(DataFileName):
os.remove(DataFileName)
if __name__ == "__main__":
main()
运行结果
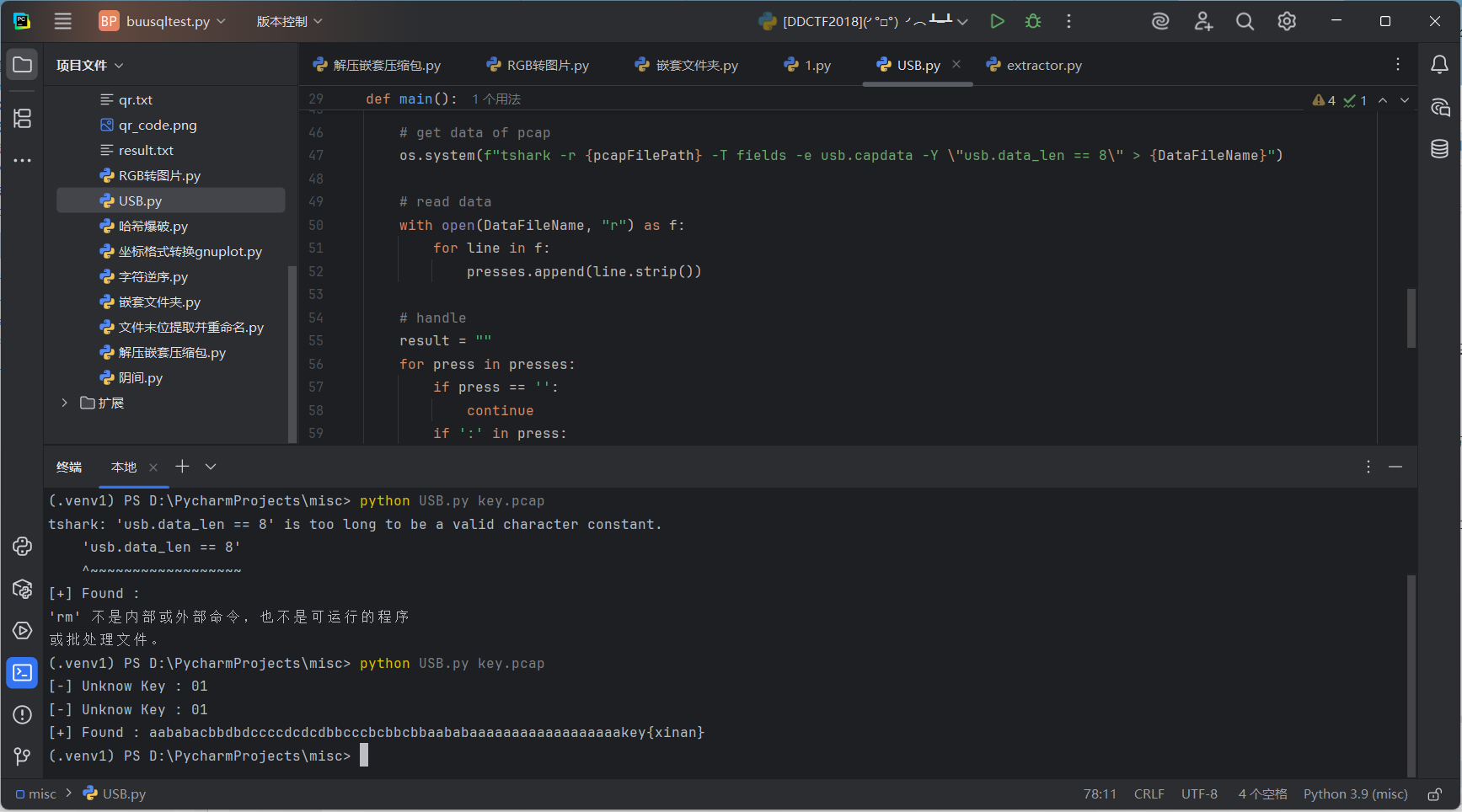
key{xinan}
然鹅这并不是flag
来看RAR,还记得一开始说的报错吗
在第三个块,也就是文件头块
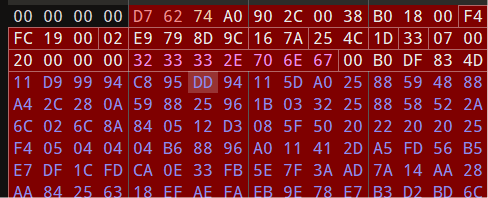
(我已经把文件改了,将就着看吧)
D5 56 :HEAD_CRC,2字节,也就是文件头部分的crc校验值
74 :HEAD_TYPE,1字节,块类型,74表示块类型是文件头
20 90 :HEAD_FLAGS,2字节,位标记,这块在资料上没找到对应的数值,不知道20 90代表什么意思。
2D 00 :HEAD_SIZE,2字节,文件头的全部大小(包含文件名和注释)
10 00 00 00 :PACK_SIZE,4字节,已压缩文件大小
10 00 00 00 :UNP_SIZE,4字节,未压缩文件大小
02:HOST_OS,1字节,保存压缩文件使用的操作系统,02代表windows
C7 88 67 36:FILE_CRC,4字节,文件的CRC值
6D BB 4E 4B :FTIME,4字节,MS DOS 标准格式的日期和时间
1D:UNP_VER,1字节,解压文件所需要的最低RAR版本
30:METHOD,1字节,压缩方式,这里是存储压缩
08 00 :NAME_SIZE,2字节,表示文件名大小,这里文件名大小是8字节(flag.txt)
20 00 00 00 :ATTR,4字节,表示文件属性这里是txt文件
66 6C 61 67 2E 74 78 74:FILE_NAME(文件名) ,NAME_SIZE字节大小,这里NAME_SIZE大小为8
再往后是txt文件内容,一直到第六行 65 结束,下面是另一个文件块的开始
这个块中存在两个crc值,一个是文件头块中从块类型到文件名这38个字节的校验,后一个则是压缩包中所包含文件的crc校验,解压时,会计算解压后生成文件的crc值,如果等于这里的crc,则解压完成,如果不同,则报错中断。
在题给压缩包中,第三个字节'74'的值被改成了'7A'
改回74即可
现在我们能够正常打开压缩包了,在压缩包中发现一个223.png
在图片的蓝色通道发现了二维码
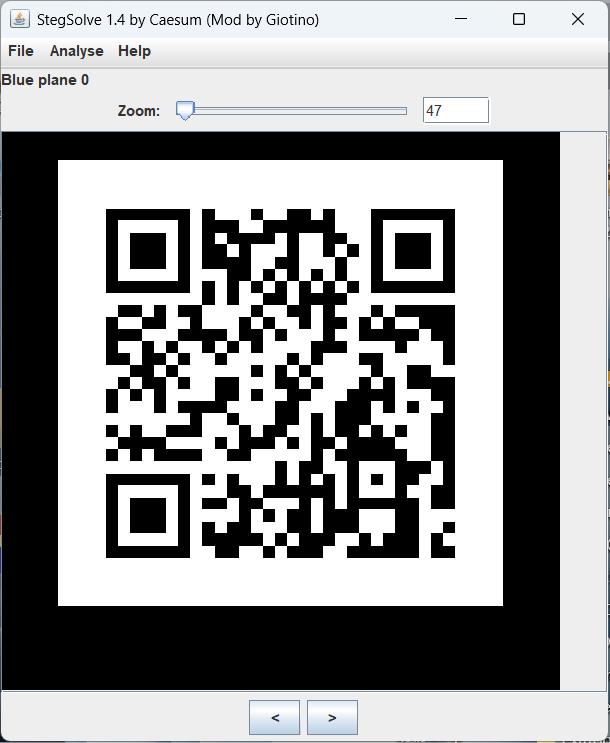
ci{v3erf_0tygidv2_fc0}
然鹅这还不是flag
结合之前在键盘流量里找到的神秘字符串,推测这是由密钥“xinan”加密的内容
按照思路,我们需要将所有需要密钥的密码都尝试一遍,并得出最有可能的结果
热门需要密钥的加密方式思路(顺序从古典到现代)
维吉尼亚密码->Playfair密码->数据加密标准 (DES)->三重DES (Triple DES)->AES->RC4->Rabbit等等……(越到后边越需要复杂的条件)
发现是维吉尼亚密码加密(看上去比较合理)
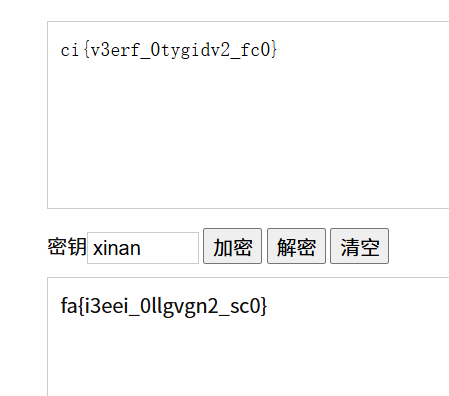
flag形状已出,但是目前来看字母的顺序被打乱了,考虑栅栏编码
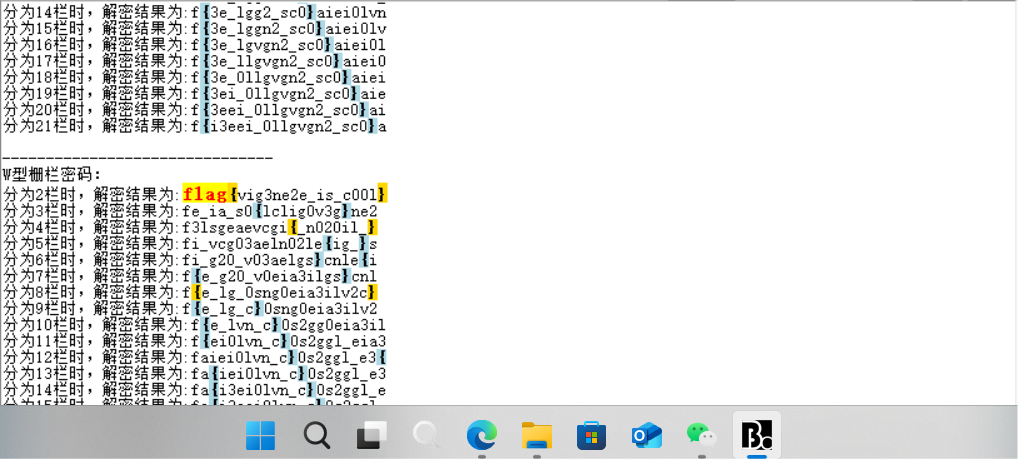
flag{vig3ne2e_is_c00l}
拿下
考点
文件内数据隐写
RAR压缩包的详细结构
图片隐写
带密钥密码解密
W型栅栏
[GUET-CTF2019]虚假的压缩包
在虚假的压缩包.zip有伪加密,但是,360解压会带你杀出重围(自动无视,我还是看雪剑wp才知道有伪加密的)
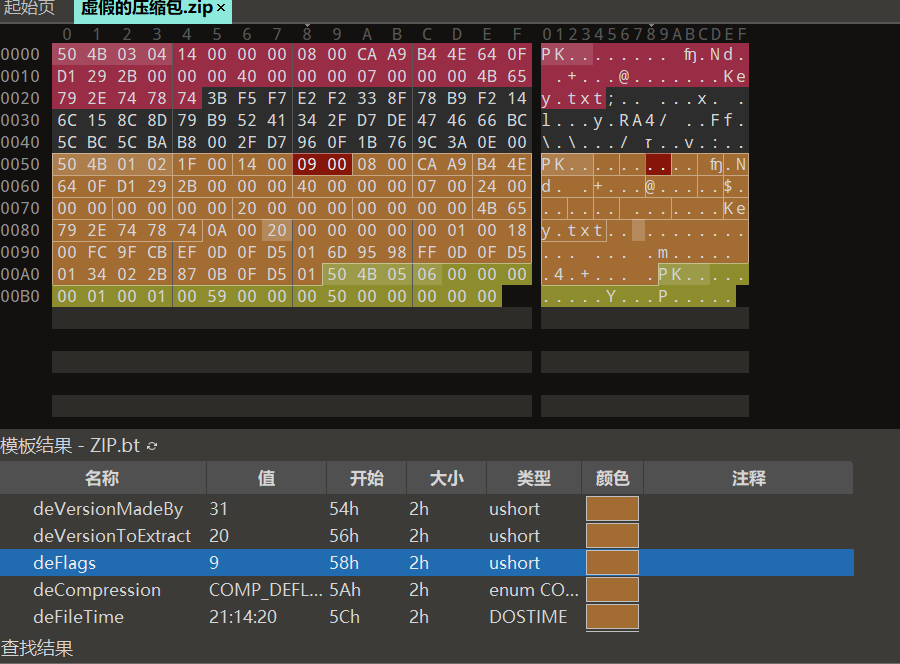
压缩包里的文件内容

解出来明文是5
真实的压缩包.zip存在加密,爆破什么的也爆不出来,还是看别人wp才知道解压密码是密码是5
(让我想起来商丘的比赛web有一题是要传入崩铁大黑塔pv(链接已给出)的bv号,难绷)
解压得到一张图片和未知文件
打开图片发现是png格式并且存在crc不匹配,手动修改宽高以后发现图片有个异或5的提示

注意,这是十六进制异或,和ASCII异或不一样,010的异或结果是有问题的
编写脚本进行操作吧
import sys
def hex_xor_file(input_file, output_file):
try:
with open(input_file, 'r', encoding='utf-8') as f:
content = f.read()
result = []
for char in content:
# 将字符视为十六进制数字(0-9, a-f, A-F),否则保留原字符
if char.lower() in '0123456789abcdef':
# 转换为16进制整数,异或5,再转回16进制字符
hex_val = int(char, 16)
xor_val = hex_val ^ 5
result_char = f'{xor_val:x}' # 转为小写十六进制字符
result.append(result_char)
else:
result.append(char) # 非十六进制字符保持不变
with open(output_file, 'w', encoding='utf-8') as f:
f.write(''.join(result))
print(f"处理完成,结果已保存到 {output_file}")
except Exception as e:
print(f"错误: {e}")
if __name__ == "__main__":
if len(sys.argv) != 3:
print("用法: python hex_xor_5.py <输入文件.txt> <输出文件.txt>")
sys.exit(1)
input_file = sys.argv[1]
output_file = sys.argv[2]
hex_xor_file(input_file, output_file)
使用python xor.py input.txt output.txt运行脚本(不会的找deepseek沉淀去)
打开脚本生成的文件发现是504b起手,原来是我们的zip老朋友,但是小写的十六进制并不能正常被当作文件打开,我们修改脚本
将result_char = f'{xor_val:x}' 中的 x 改为 X(大写格式说明符)
将新生成的txt内容复制为16进制保存就是zip了
芝士docx
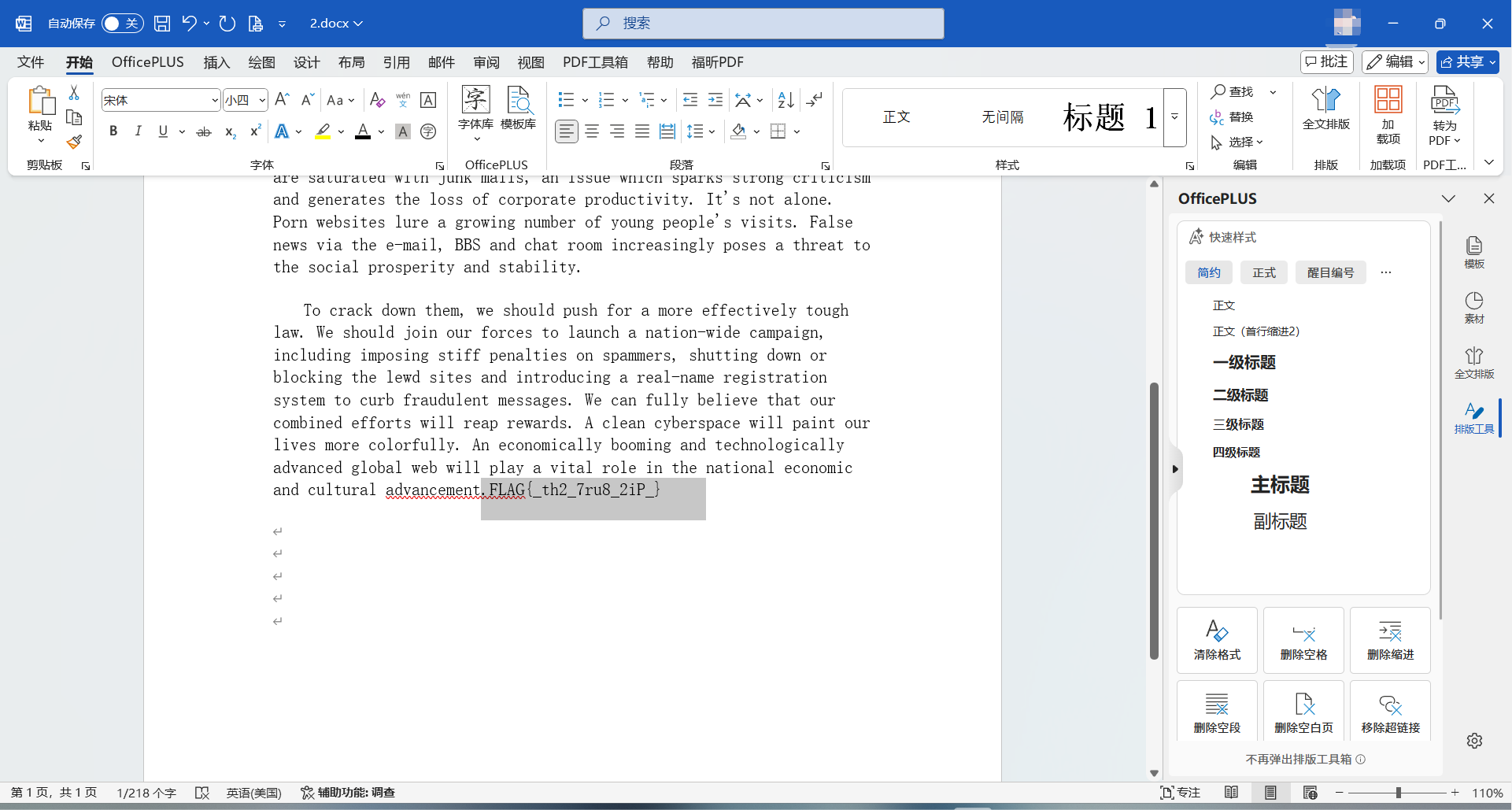
全选把文字颜色改成黑色即可看到flag
flag{_th2_7ru8_2iP_}
考点
伪加密
png crc修复
十六进制异或
压缩包识别
office文件辨认以及隐写基础
[ACTF新生赛2020]明文攻击
解压得到一张图片和一个加密压缩包
在图片的十六进制数据结束后发现了没有头(PK)的zip文件
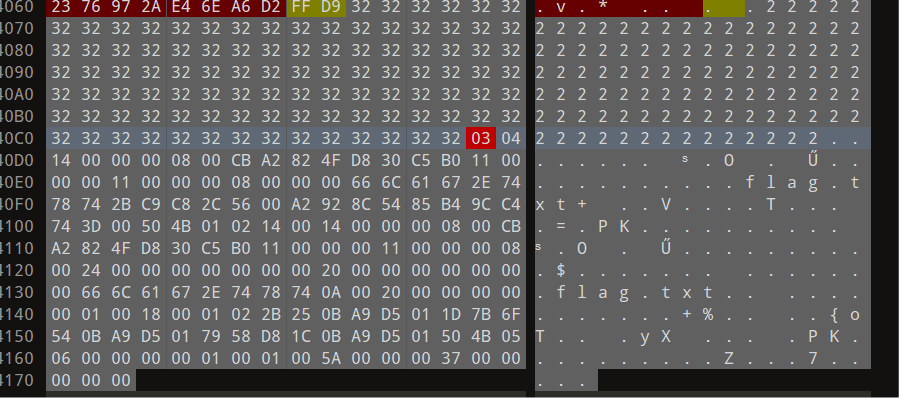
找个正常的zip文件来把头补上

保存得到一个正常的无密码压缩文档,在压缩文件里找到一个flag.txt,
结合题目“明文攻击”,推测这就是我们的明文压缩包
需要攻击的压缩包就是那个res.zip
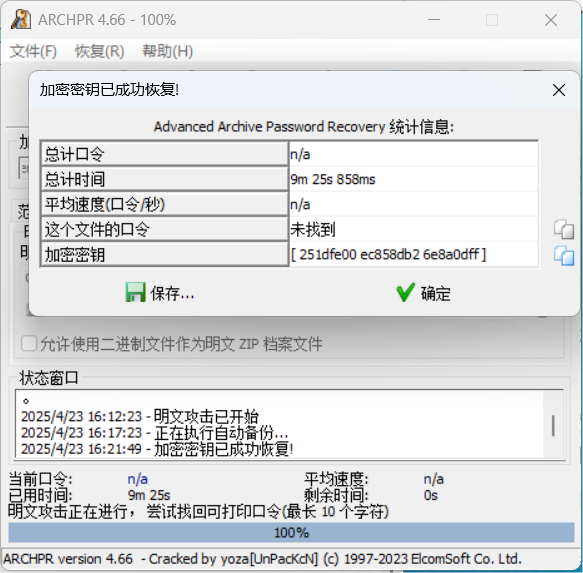
完事拿下
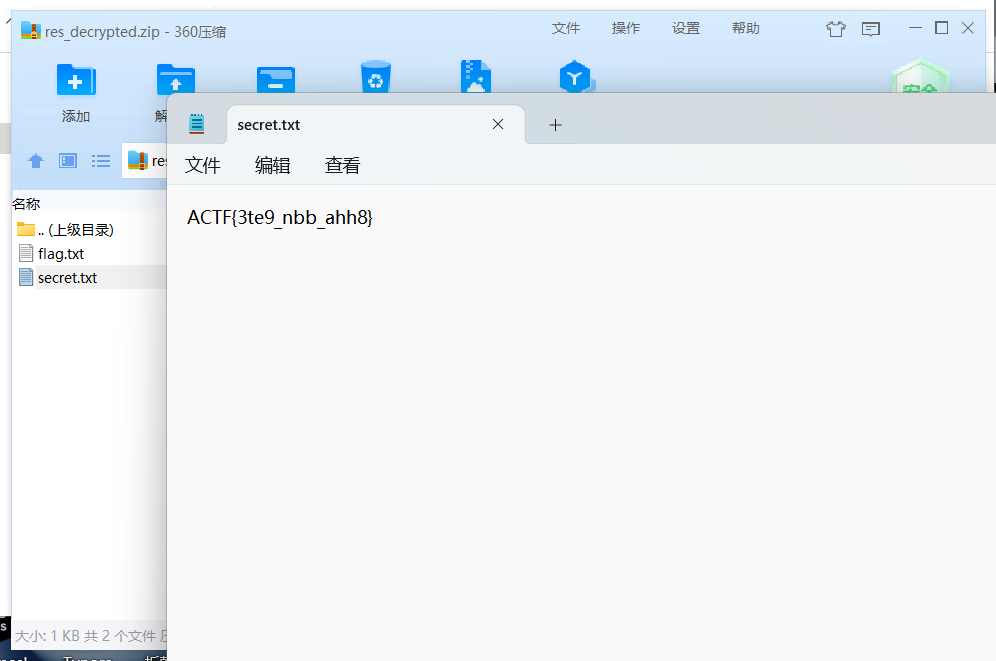
flag{3te9_nbb_ahh8}
考点
文件隐写
压缩包文件头补全
明文攻击
[RCTF2019]draw(新)
打开不知道这是什么,全部复制去谷歌搜一下,发现是logo语言
https://personal.utdallas.edu/~veerasam/logo/
介绍
https://www.calormen.com/jslogo/
解释器
复制进去跑一下,就好了
flag{RCTF_HeyLogo}
考点
logo语言
[GKCTF 2021]签到
发现有很多的http流量包 给他过滤了
选择第一个流量包追踪tcp看看,在下图发现了黑阔的攻击痕迹
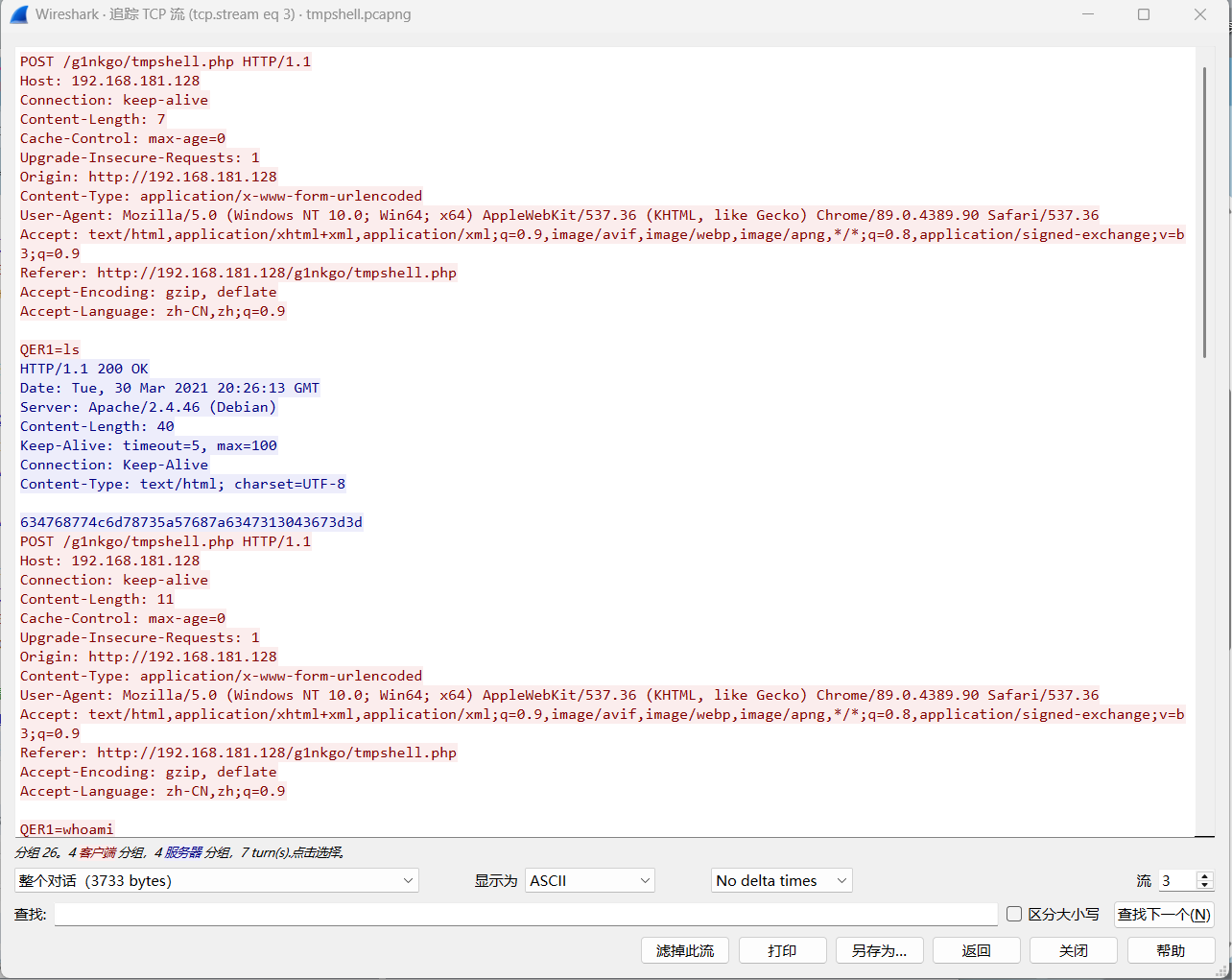
QER1是马子的密码,攻击者先是执行了ls命令,然后执行了whoami指令来查询用户身份
中间有一串神秘十六进制,安排赛博厨师处理一下,发现是一串逆序的字符串(敲黑板,后面要考)
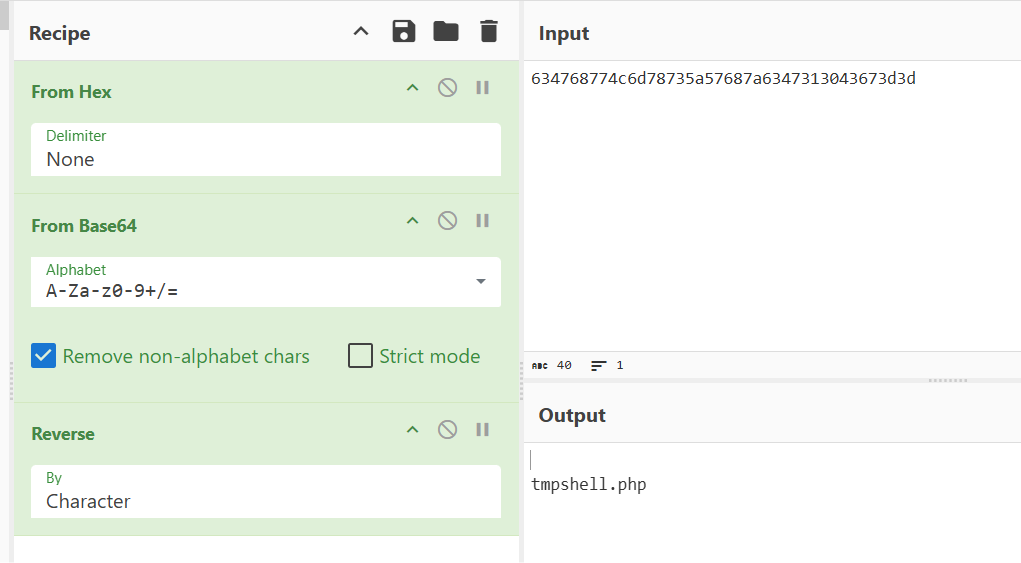
一个个查看流可以看到攻击者执行了很多指令,查看了用户信息,查询了几个文件的内容,一直到cat /f14g|base64
接着往下看,发现了经base64编码的“f14g”,我们提取并且解码:
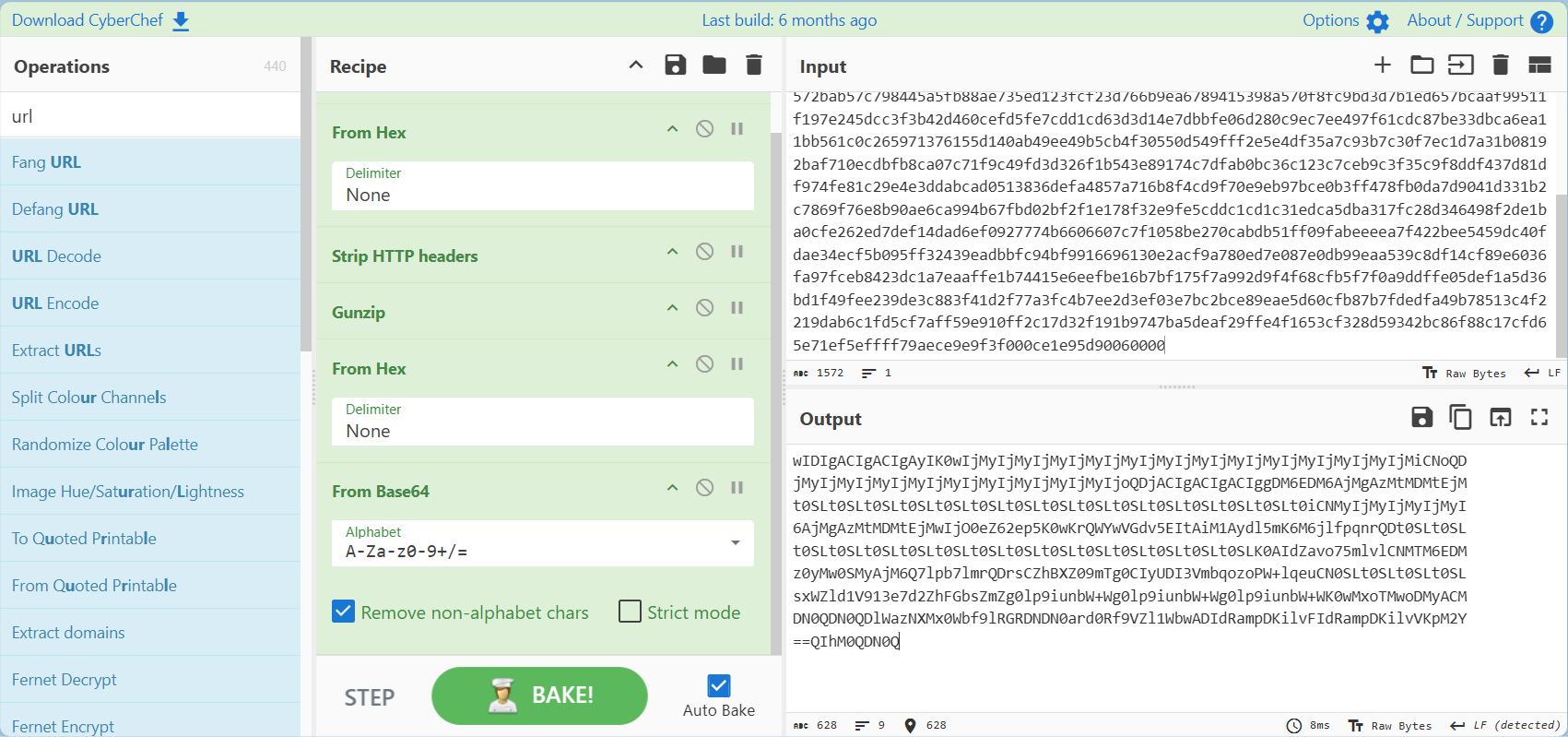
发现了逐行倒序的base64编码
我们可以手动编写脚本进行修复(当然也可以手动逐行调回来)
脚本
def reverse_lines(input_file, output_file):
"""
将输入文件的每一行字符串倒序后写入输出文件
参数:
input_file: 输入文件名
output_file: 输出文件名
"""
try:
with open(input_file, 'r', encoding='utf-8') as infile, \
open(output_file, 'w', encoding='utf-8') as outfile:
for line in infile:
# 去除行尾换行符,倒序后再添加回来
reversed_line = line.rstrip('\n')[::-1] + '\n'
outfile.write(reversed_line)
print(f"成功处理文件,结果已保存到 {output_file}")
except FileNotFoundError:
print(f"错误:文件 {input_file} 不存在")
except Exception as e:
print(f"处理文件时出错: {e}")
# 使用示例
input_filename = 'input.txt' # 输入文件名
output_filename = 'output.txt' # 输出文件名
reverse_lines(input_filename, output_filename)
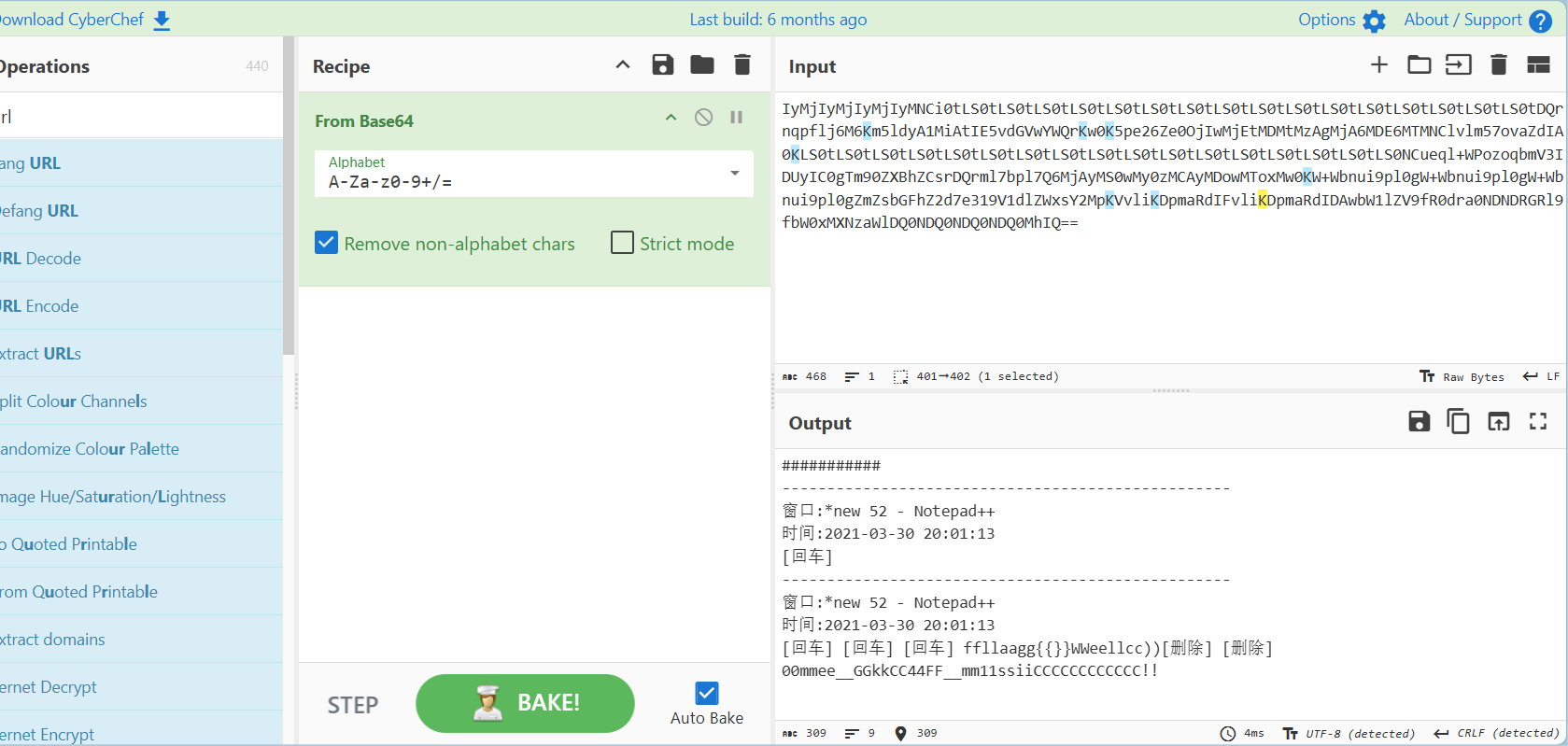
flag{Welc0me_GkC4F_m1siCCCCCC!}
考点
流量包分析
guess能力
[SWPU2019]Network(新知识)
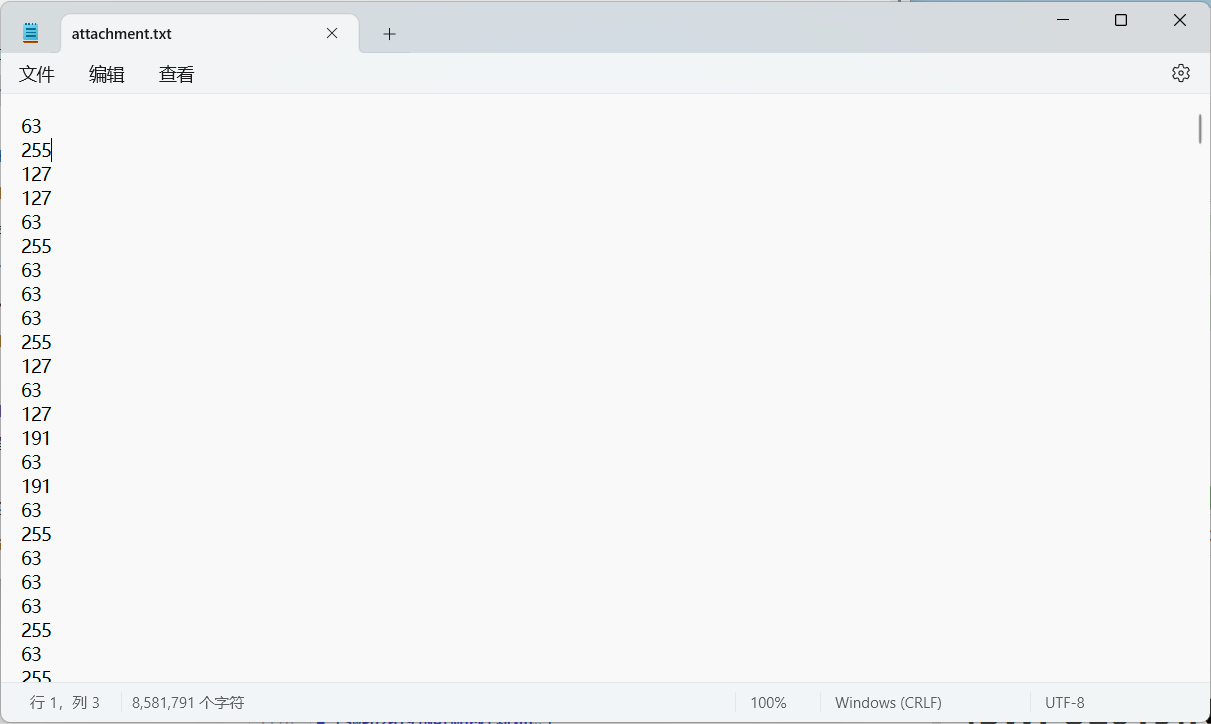
一开始以为是阿斯克码,怎么写都写不出来……看了wp才知道这是TTL隐写
TTL解释:
TTL是IP协议包中的一个值,它告诉网络路由器包在网络中的时间是否太长而应被丢弃。有很多原因使包在一定时间内不能被传递到目的地。例如,不正确的路由表可能导致包的无限循环。一个解决方法就是在一段时间后丢弃这个包,然后给发送者一个报文,由发送者决定是否要重发。TTL的初值通常是系统缺省值,是包头中的8位的域。TTL的最初设想是确定一个时间范围,超过此时间就把包丢弃。由于每个路由器都至少要把TTL域减一,TTL通常表示包在被丢弃前最多能经过的路由器个数。当记数到0时,路由器决定丢弃该包,并发送一个ICMP报文给最初的发送者。
TTL加密:
简单来说就是,图中63,127,191,255转化为二进制的值分别为 00111111,01111111,10111111,11111111。
发现只有前两位不同,TTL加密就是利用前两位进行加密,将每个前两位重新进行合并,8位为一组。
所以TTL加密的解密方法:
将所有前两位合并为8位,并且每八位一组。(将63转换成00、将127转换成01、将191转换成10、将255转换成11后将所有内容组合起来也可以,而且会更高效,对于这类题型效率更高)
脚本(特殊优化版)
def hex_to_binary(hex_str):
# 将十六进制字符串转换为二进制字符串,并去掉前缀 '0b'
binary_str = bin(int(hex_str, 16))[2:]
# 保证二进制字符串长度是8的倍数,前面补充0
binary_str = binary_str.zfill(8)
return binary_str
def dec_to_binary(dec_str):
# 将十进制字符串转换为二进制字符串,并去掉前缀 '0b'
binary_str = bin(int(dec_str))[2:]
# 保证二进制字符串长度是8的倍数,前面补充0
binary_str = binary_str.zfill(8)
return binary_str
# 配置开关,选择十六进制或十进制
is_hex = False # 设置为True表示十六进制,False表示十进制
# 读取attachment.txt文件内容
with open('attachment.txt', 'r') as file:
lines = file.readlines()
# 初始化结果字符串
result = ''
# 遍历每一行,将每一行的数值转换成二进制并提取前两位
for line in lines:
line = line.strip() # 去掉行末的换行符
if is_hex:
binary_representation = hex_to_binary(line)
else:
binary_representation = dec_to_binary(line)
# 提取前两位
result += binary_representation[:2]
# 输出组合后的二进制字符串
print(result)
# 将结果保存到一个新的文件中
with open('output.txt', 'w') as outfile:
outfile.write(result)
能得到一个txt文件,将这个文件导入到赛博厨师,自动解码就能发现这是一个压缩包
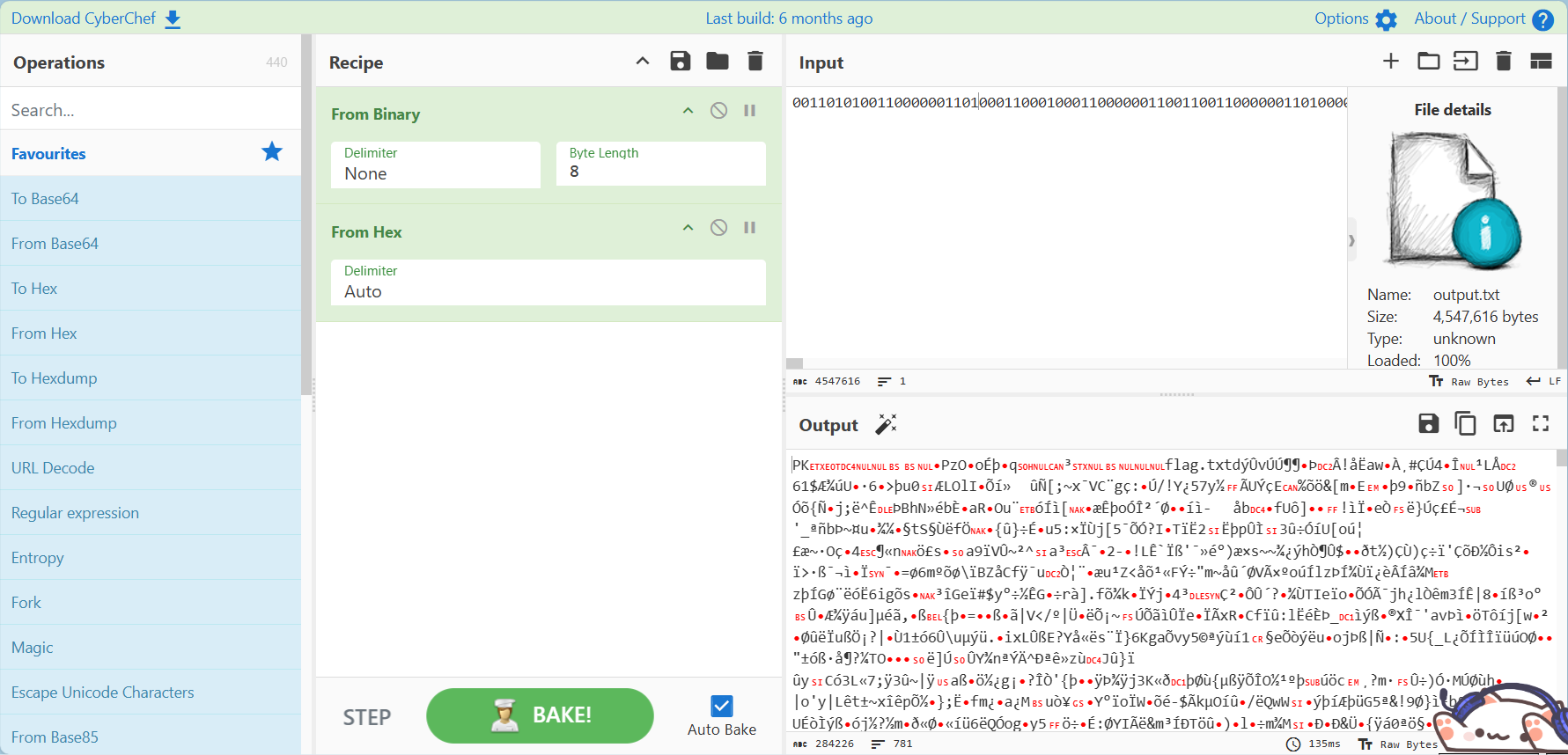
打开压缩包以后(360解压能无视这个伪加密),发现里面有一个flag.txt
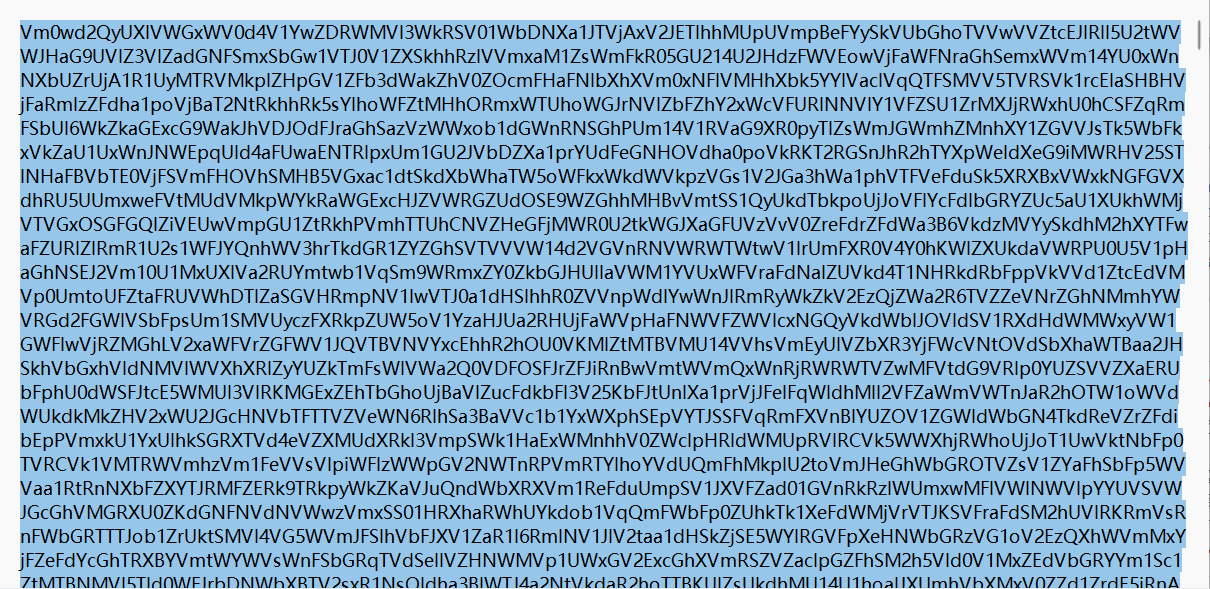
感觉是base64
拖入赛博厨师进行base64套娃解得flag
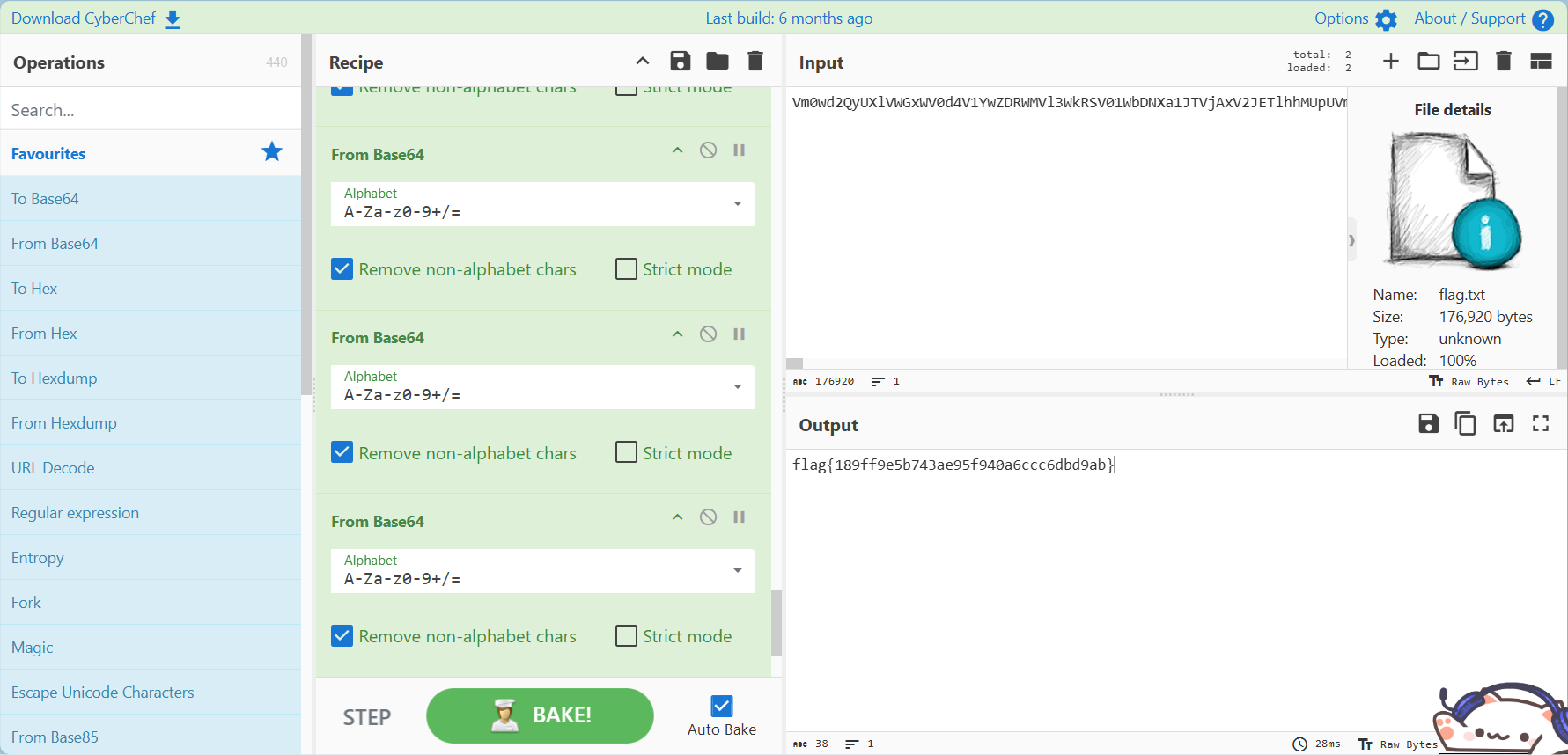
flag{189ff9e5b743ae95f940a6ccc6dbd9ab}
考点
ttl隐写(新),编码转换,伪加密
[CFI-CTF 2018]webLogon capture
打开压缩包发现两个流量包
打开logon.pcapng
里面总共也没几条,直接看吧
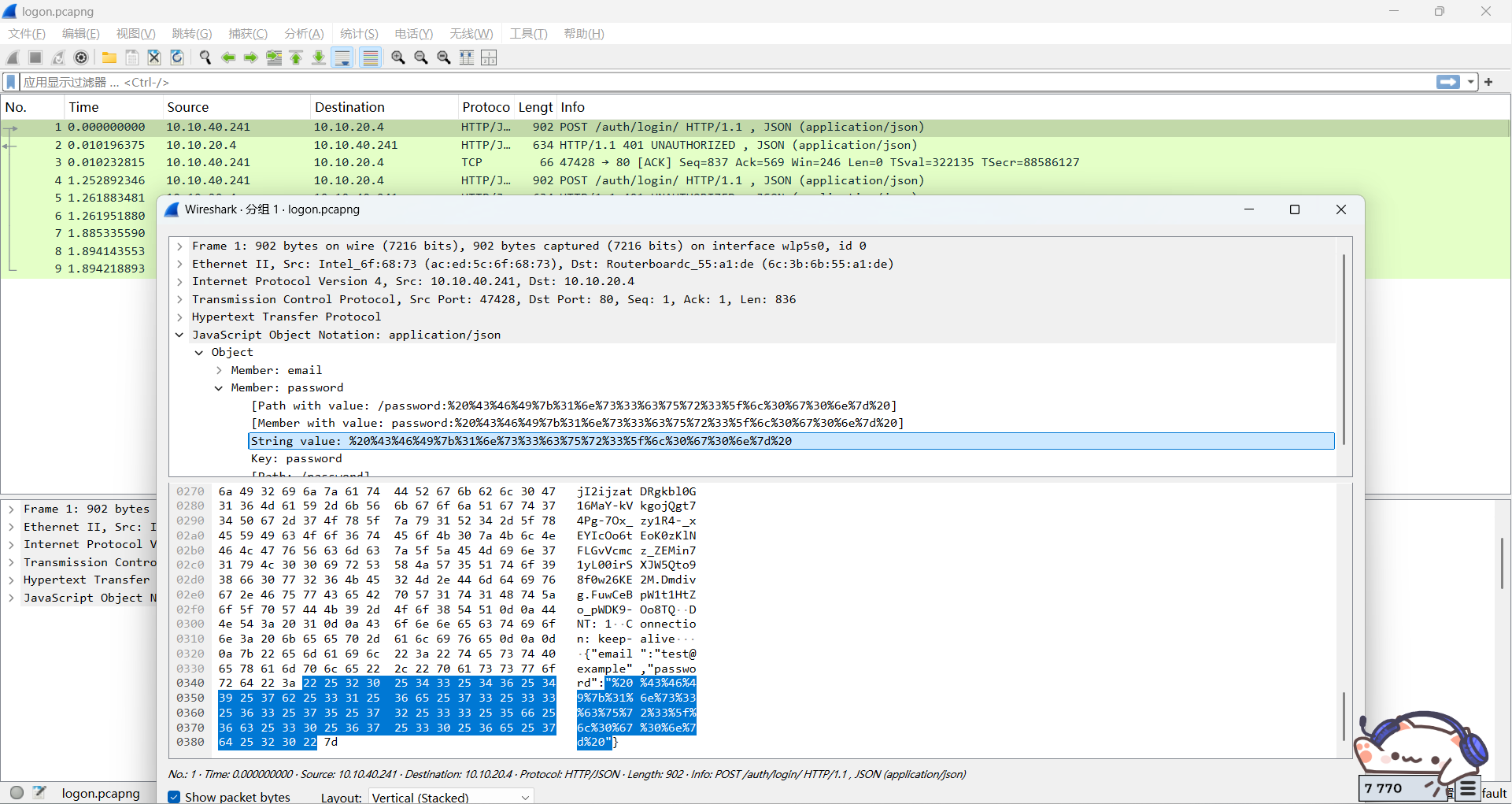
第一条直接就是……
pwd直接拿去url解码就秒了
flagflag{1ns3cur3_l0g0n}
考点
流量分析
[MRCTF2020]Hello_ misc(综合性)
打开压缩包,图片存在肉眼可见的lsb隐写特征
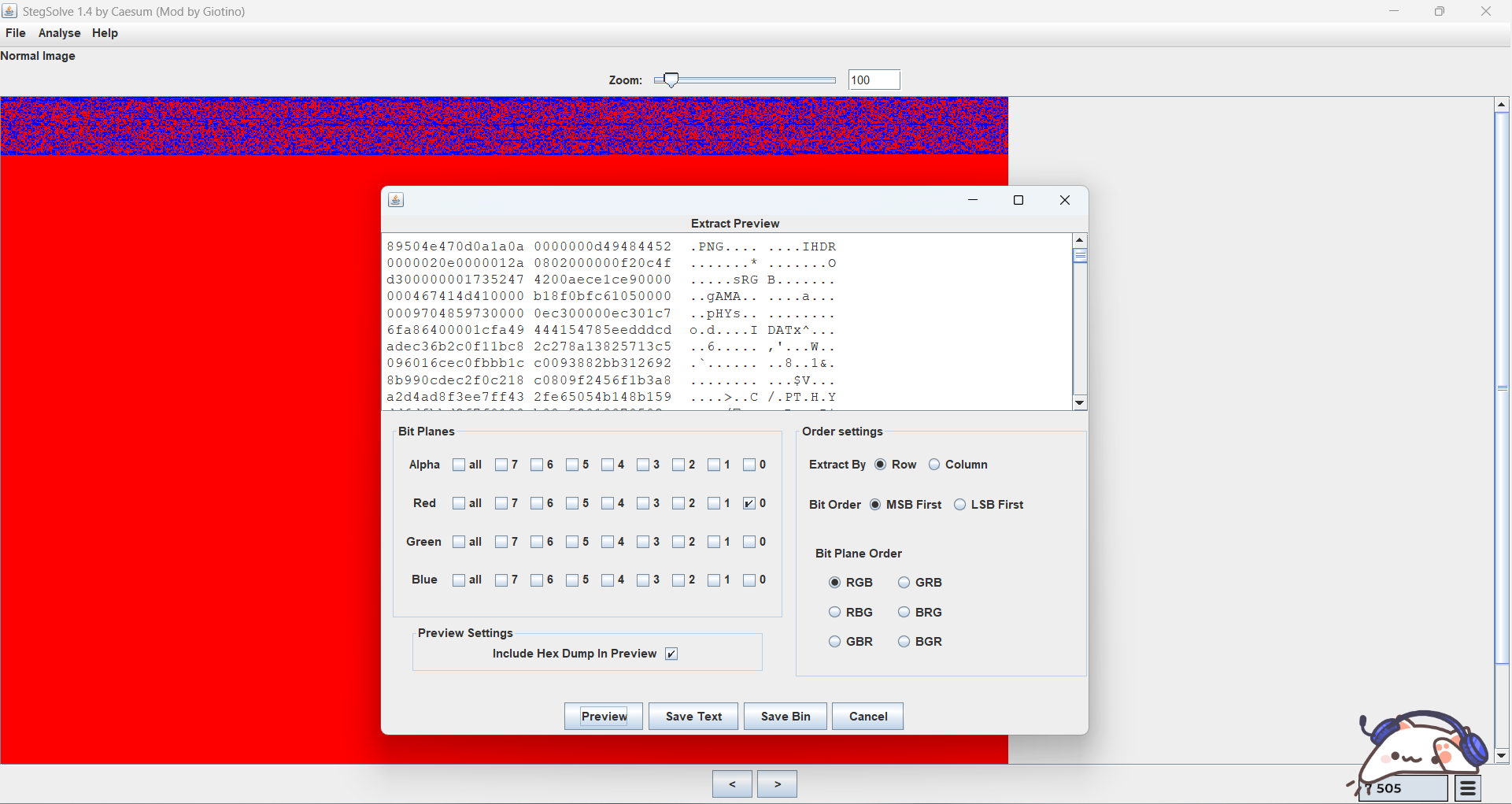
另存r通道的图片

但是这个密码并不能直接用于hello文件夹中ffflag压缩包的解密
并且根据提示,我们还需要分离文件
我们继续观察图片,发现在IEND后面还存在一个压缩包
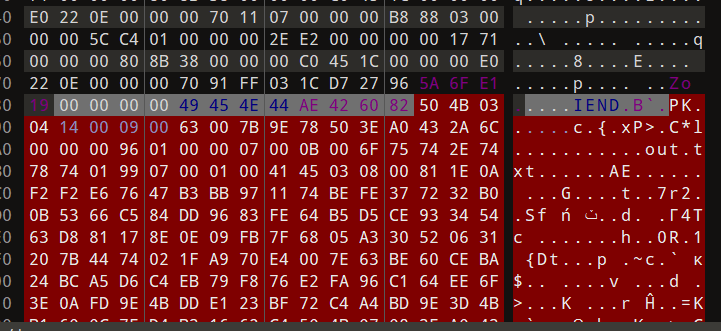
提取出来
输入密码!@#$%67*()-+就能打开压缩包,里面有一个out.txt
打开文件,一眼ttl隐写
把之前的脚本略作修改就可以了
得到的二进制转码得到
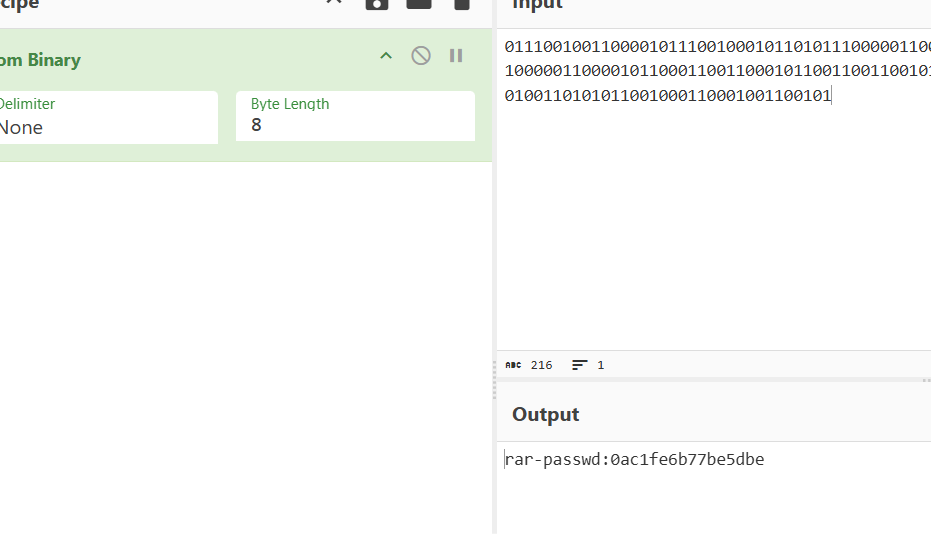
rar-passwd:0ac1fe6b77be5dbe
解压得到压缩包内容
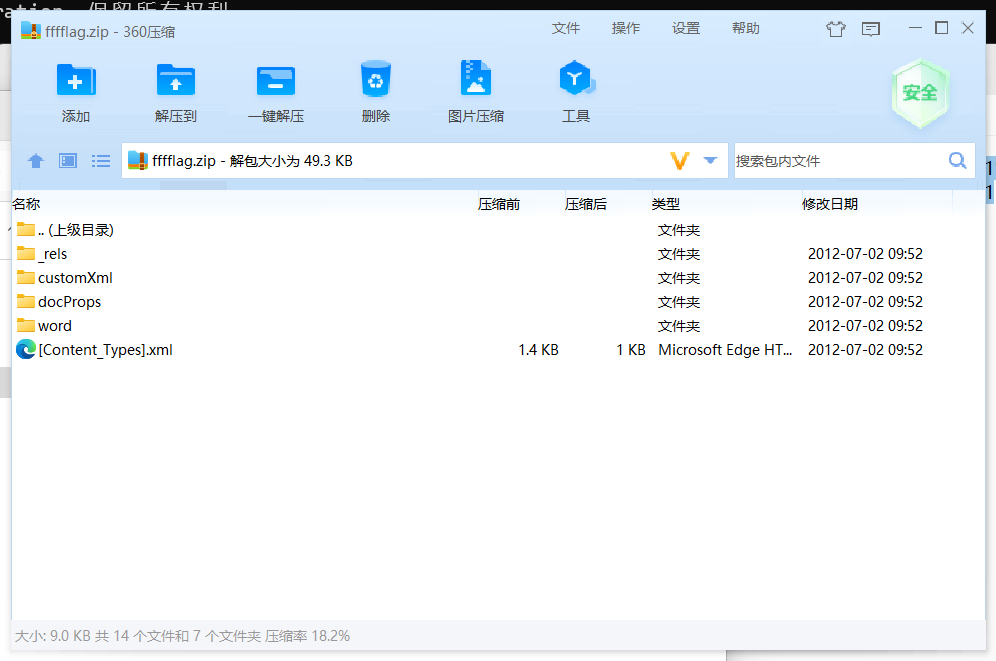
这是某种office文件的解压形态,观察得到这是docx文件

改后缀打开全选发现有透明字,给他改成黑的就能看到了
多行base64解码

隐约发现有字的形状
编写脚本把1换成空格
with open('data.txt','r') as file:
content = file.read()
# 替换 '1' 为空格,并保持原有格式
modified_content = content.replace('1', ' ')
print(modified_content) # 打印替换后的内容
# (可选)保存到新文件
#with open('modified_' + file_path, 'w') as new_file:
# new_file.write(modified_content)
#print(f"修改后的内容已保存到 modified_{file_path}")
就像这样。
有天才告诉我直接批量替换就行了。。。
flagflag{He1Lo_mi5c~}
考点
lsb隐写
文件分离
ttl隐写
文档隐写
脑洞(观察力)
[UTCTF2020]zero
下载附件,一眼零宽隐写秒了

考点
零宽
[WUSTCTF2020]spaceclub
另存到本地发现是由每行四个或者八个空格组成的怪东西,一开始还以为是摩斯电码但是也识别不出来
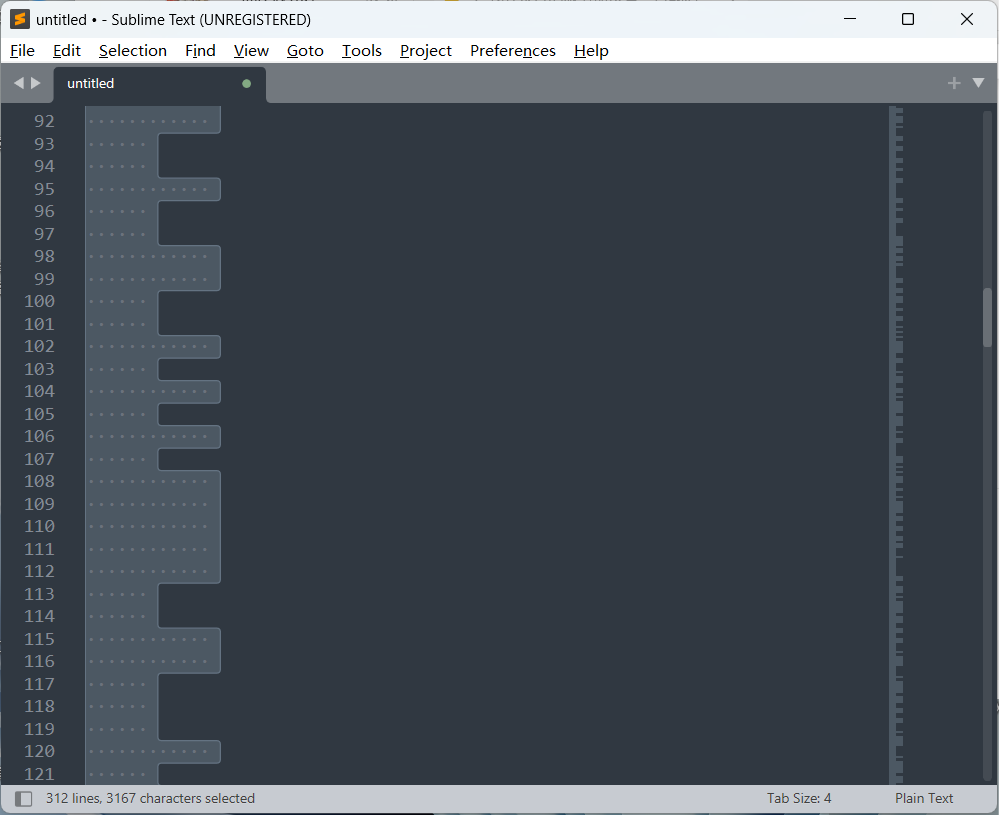
在这道题中,短的是0,长的是1
编写脚本进行替换
def convert_spaces_to_binary(input_file, output_file):
with open(input_file, 'r') as f_in, open(output_file, 'w') as f_out:
for line in f_in:
# 去除行尾的换行符
stripped_line = line.rstrip('\n')
if stripped_line.startswith(' ' * 8):
# 八个空格替换为1
f_out.write('1')
elif stripped_line.startswith(' ' * 4):
# 四个空格替换为0
f_out.write('0')
else:
# 如果不是四个或八个空格开头,可以选择忽略或处理
pass
# 如果需要保留原始文本结构,可以添加换行符
# f_out.write('\n')
if __name__ == "__main__":
input_filename = "input.txt" # 替换为你的输入文件名
output_filename = "output.txt" # 替换为你的输出文件名
convert_spaces_to_binary(input_filename, output_filename)
print(f"转换完成,结果已保存到 {output_filename}")
运行结果
赛博厨师启动
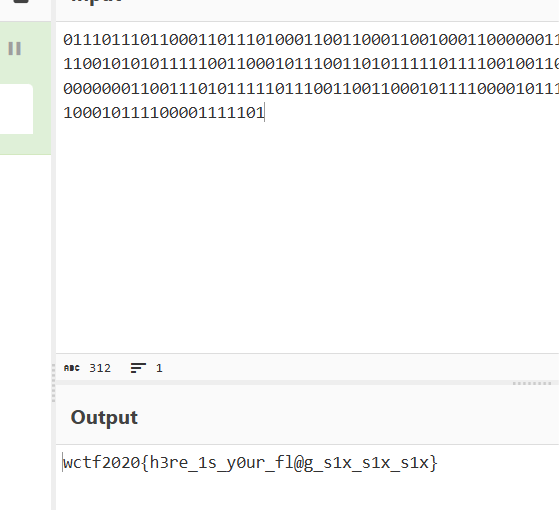
flagflag{h3re_1s_y0ur_fl@g_s1x_s1x_s1x}
考点
脑洞
[ACTF新生赛2020]music
解压后发现只有一个音频文件,010打开发现一堆A1并且无法识别文件类型,播放器也打不开
查阅wp后得知这是文件异或,在010里面选择工具-二进制异或
即可得到正常的文件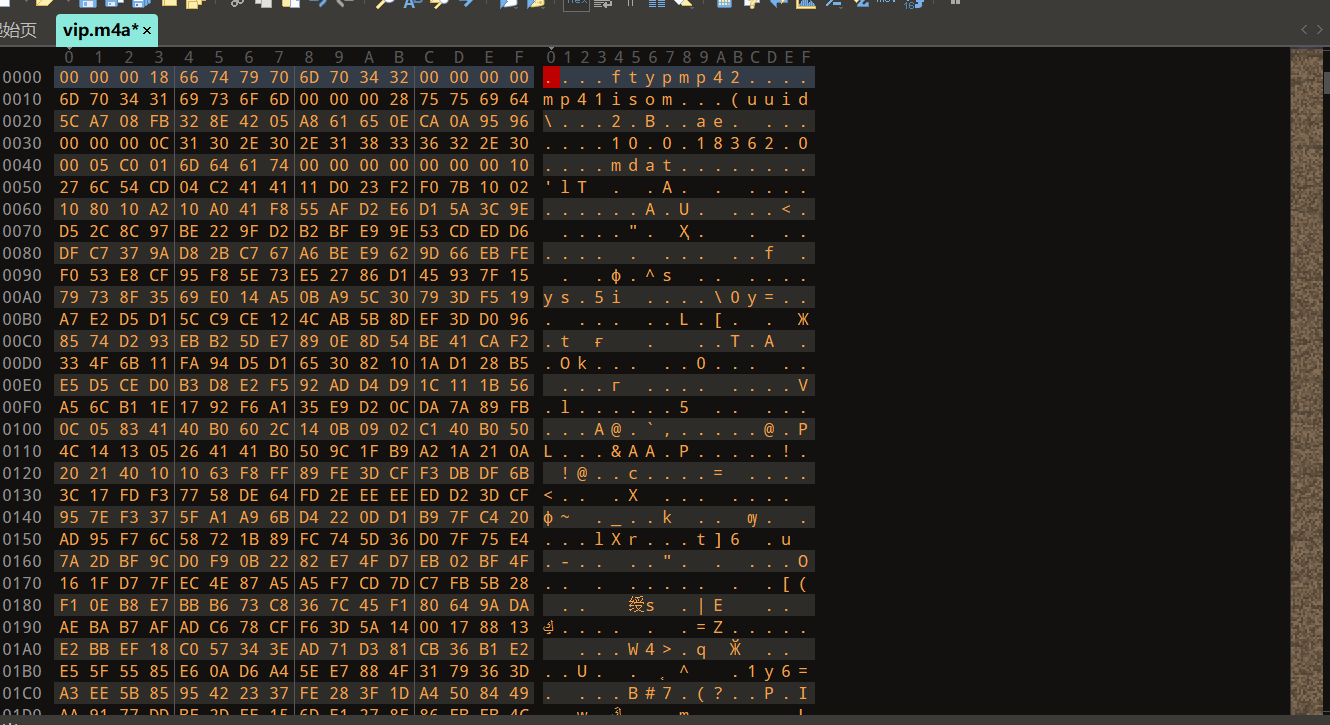
保存后播放音频听到flag内容
flag{abcdfghijk}
ps:网易云加密歌曲文件同理https://blog.csdn.net/lushuaibao/article/details/105456129
总结经验:遇到类似的十六进制特征(大量重复字节)考虑文件异或(第二次遇到)
考点
全文件异或
[MRCTF2020]Unravel!!(旧考点)
打开发现加密压缩包,神秘图片和神秘音频
音频Look_at_the_file_ending.wav明示你去看他尾巴
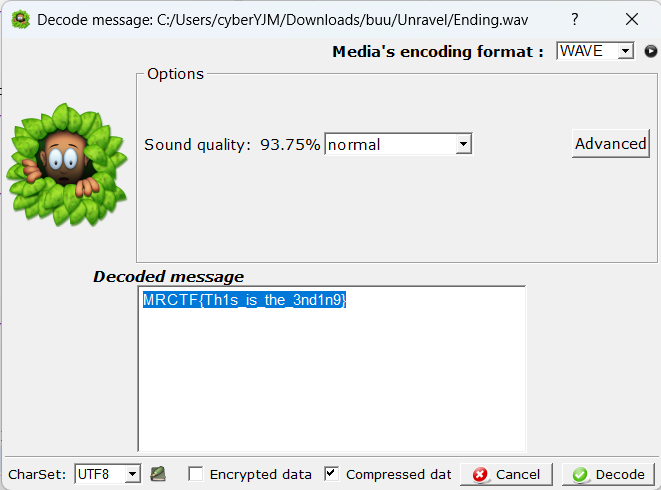
010看一看(随波逐流也可以)
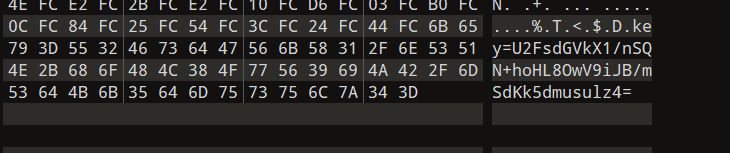
发现神秘key
U2FsdGVkX1/nSQN+hoHL8OwV9iJB/mSdKk5dmusulz4=
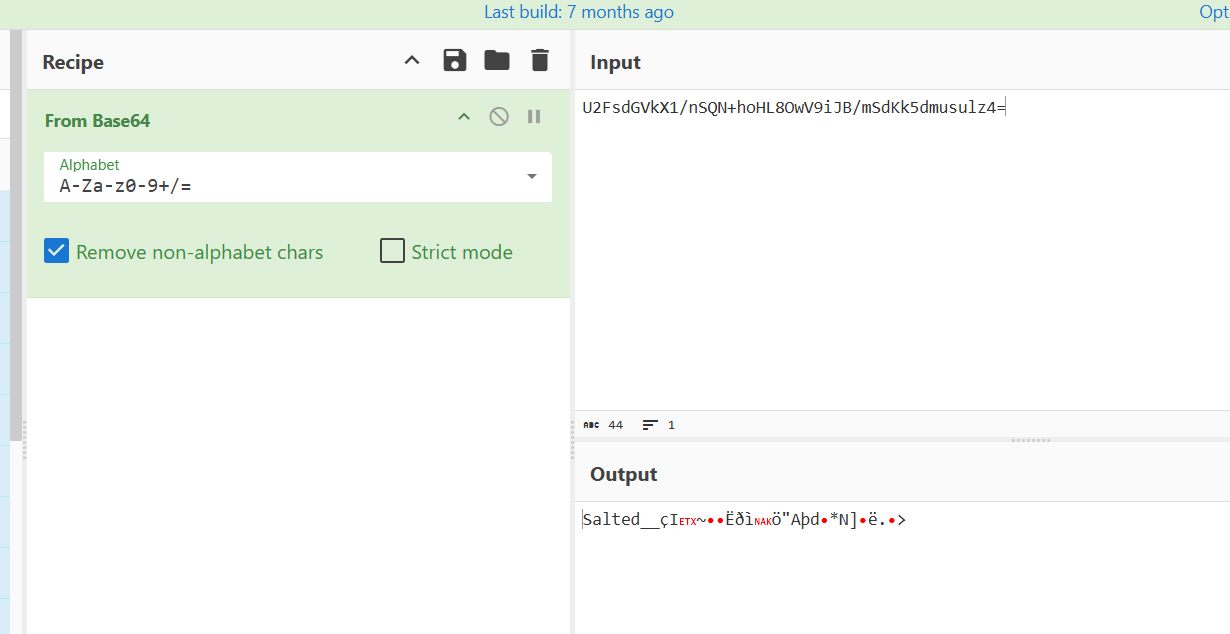
发现是加盐密码
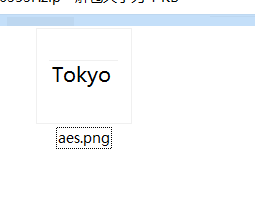
观察其他文件,在JM.png末尾发现另一张png,提取出来发现只有Tokyo
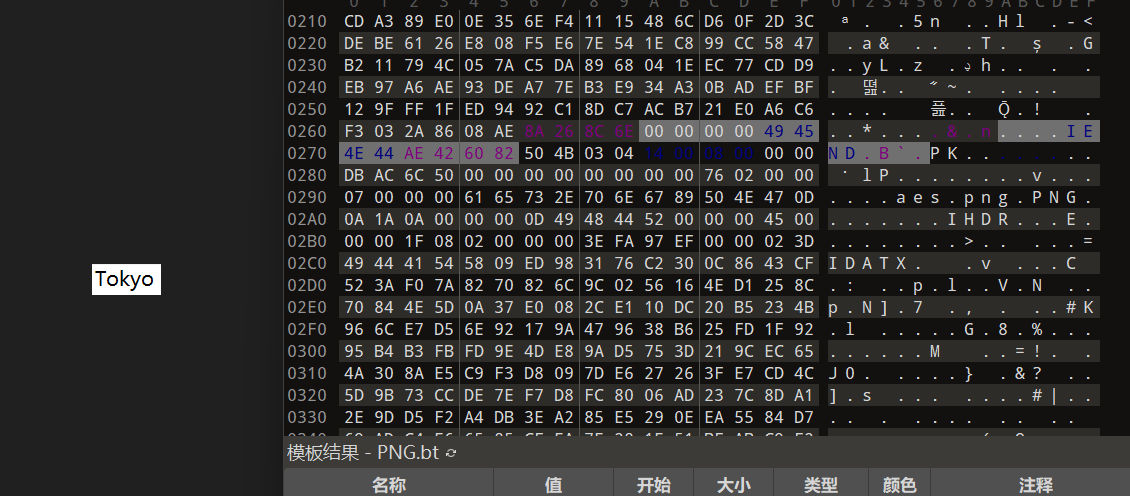
但在该图片末尾又发现新的压缩包,提取后发现是一个压缩包
aes应该是他的加密方式
在解密网站https://www.sojson.com/encrypt_aes.html
解密后得到原文

CCGandGulu
发现是压缩包的密钥
解压压缩包,里面只有一个音频文件,音频文件拖入silent eye即可得到flag
考点
文件隐写
密码加盐
音频隐写工具使用
[GKCTF 2021]excel 骚操作
看起来没用技能+1
打开文档发现
就算全选上色也没发现白色字符
但是有一些单元格还是有字符的
全选单元格,右键设置单元格格式
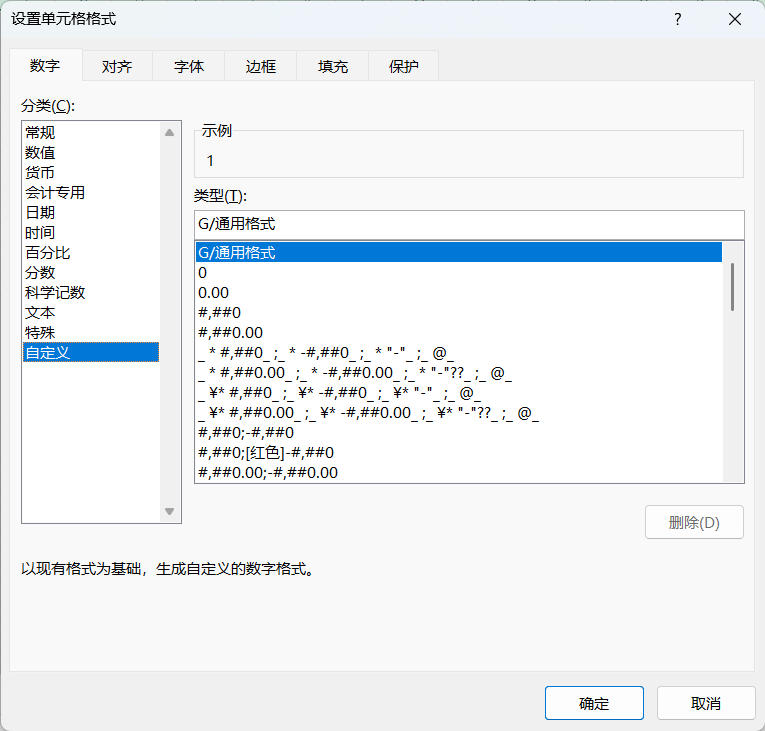
设置完以后发现出现了之前隐藏的1
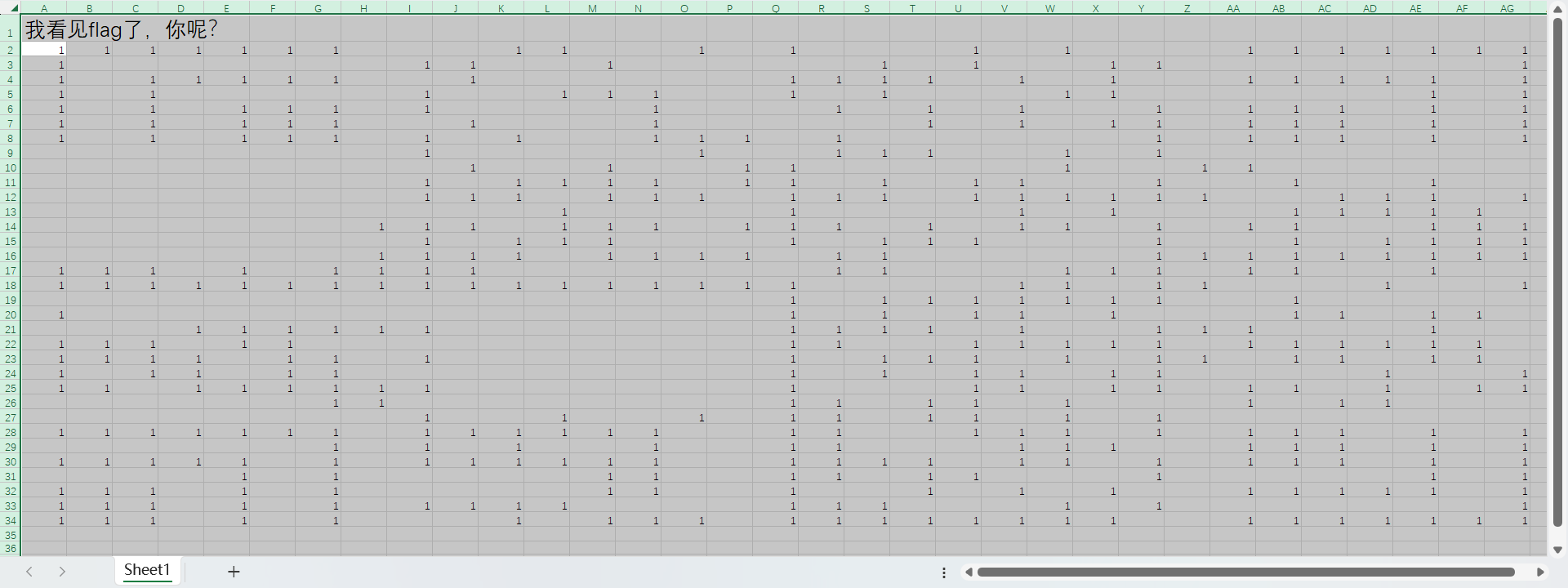
疑似规律排列,把这些单元格填充颜色
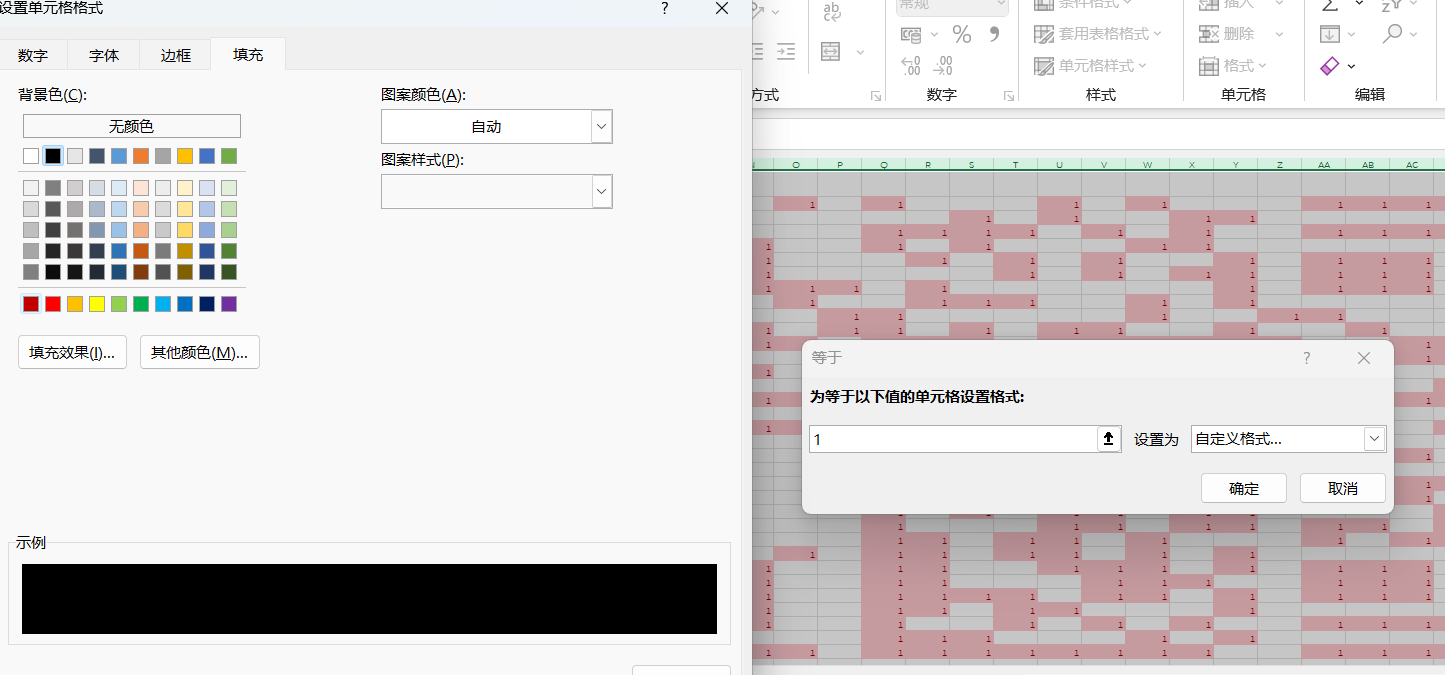
操作:条件格式-突出显示单元格规则-等于
出现了二维码
调整列宽就能得到正常尺寸的二维码了
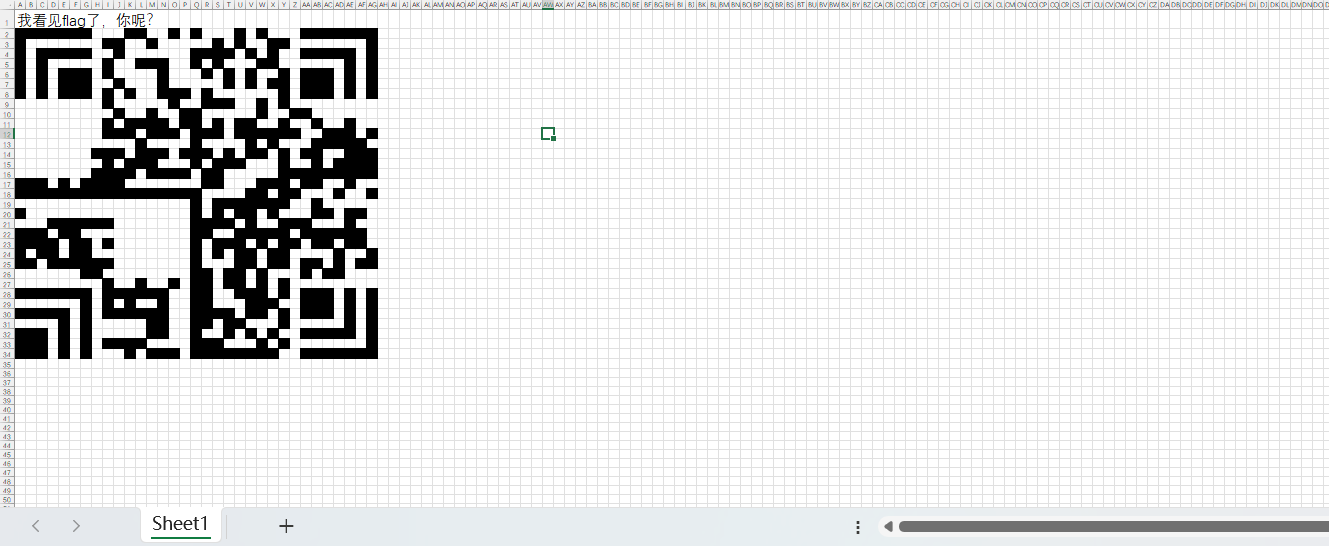
但是扫描他并没有什么反应,原来这不是常用的qr二维码,是汉信码(此码在TGCTF中亦有出现)
在这个网站中https://tuzim.net/hxdecode/ 解析即可

考点
汉信码
excel操作(隐写方式)
[UTCTF2020]File Carving
一张图片,010零帧起手发现文件尾包含信息
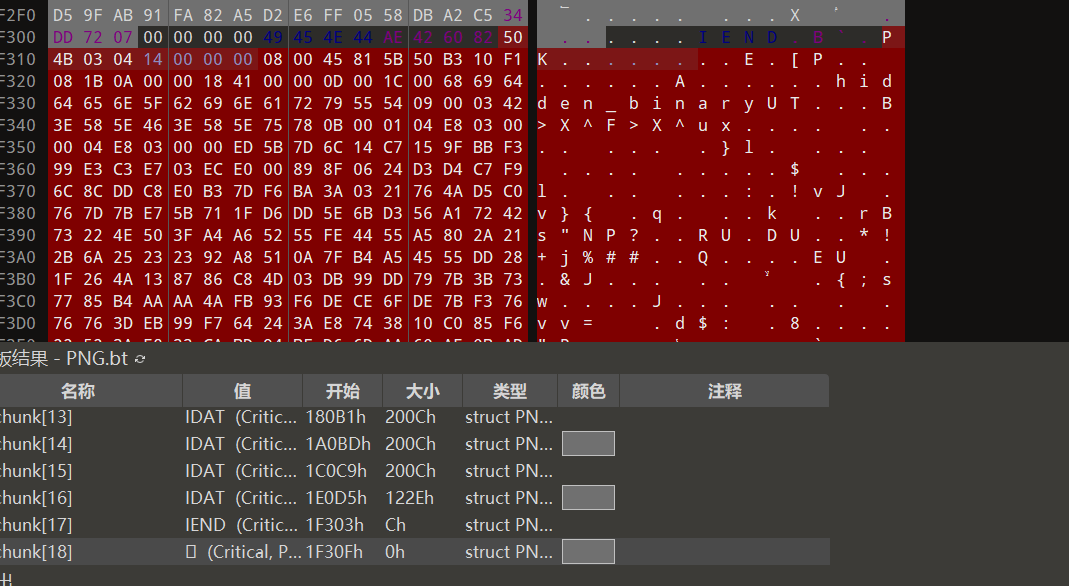
同时发现lsb隐写(无效信息)
随波逐流真的很好用
提取出压缩包以后发现里面有一个无后缀文件
010检查发现是elf文件
ELF代表Executable and Linkable Forma,是一种对可执行文件、目标文件和库使用的文件格式,跟Windows下的PE文件格式类似。ELF格式是是UNIX系统实验室作为ABI(Application Binary Interface)而开发和发布的,早已经是Linux下的标准格式了
https://blog.csdn.net/daide2012/article/details/73065204
直接搜关键词就能发现flag字符串,删去大写和非法字符即可使用
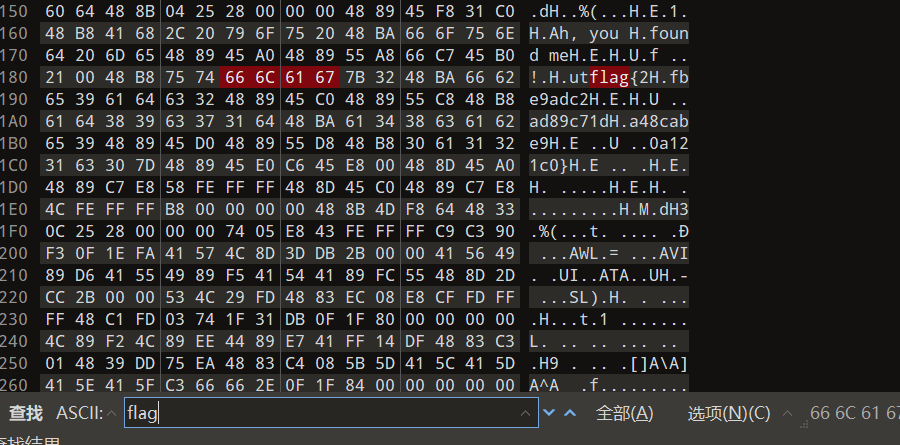
或者直接Linux允许也能显示flag(snow说的)
考点
文件包含
elf文件认识
[watevrCTF 2019]Evil Cuteness
下载完图片后文件尾发现压缩包,
提取出来发现无后缀的abc文件
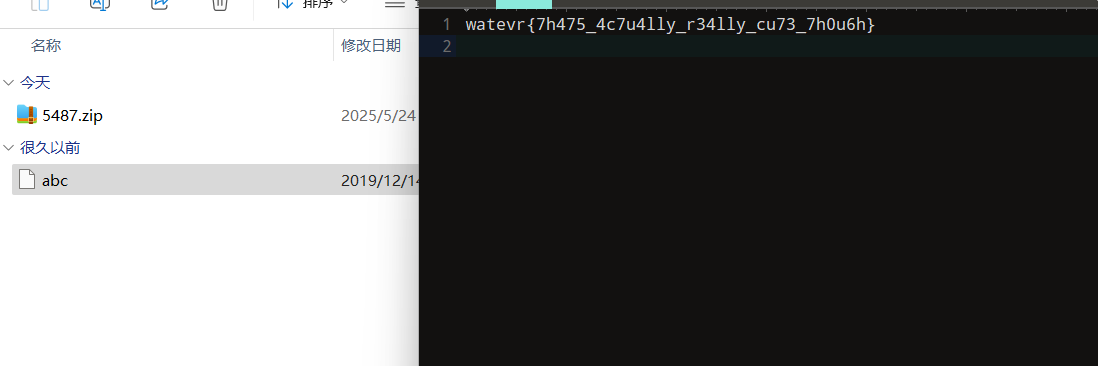
文件尾包含
[MRCTF2020]pyFlag
解压发现有三张图和.DS_Store文件
DS_Store,英文全称是 Desktop Services Store(桌面服务存储),开头的 DS 是 Desktop Services(桌面服务) 的缩写。它是一种由macOS系统自动创建的隐藏文件,存在于每一个用「访达」打开过的文件夹下面。
总而言之就是MacOS拉的屎
查看三张图片,文件尾都有【秘密文件】的提示
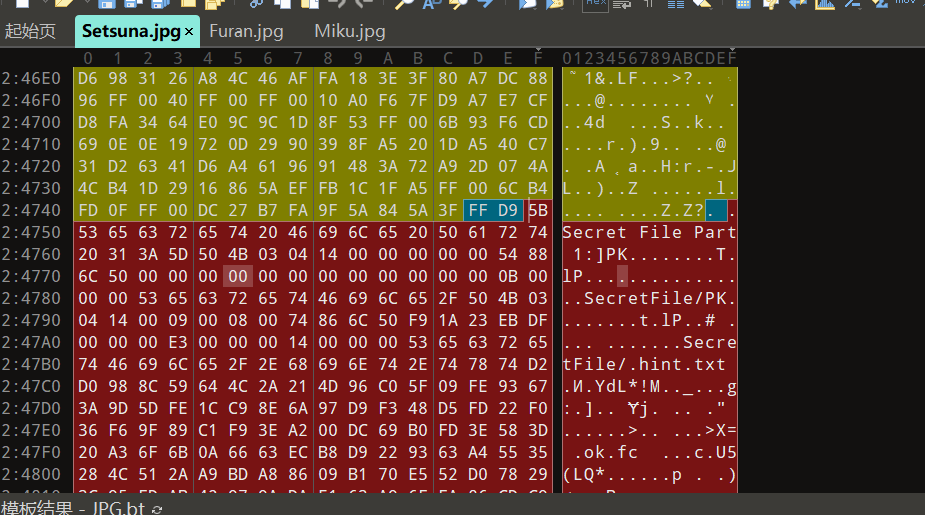
(图片不一一展示)
观察可知应该是把一个压缩包的十六进制分成三份塞到这三张图片里去,古法手动提取拼接即可
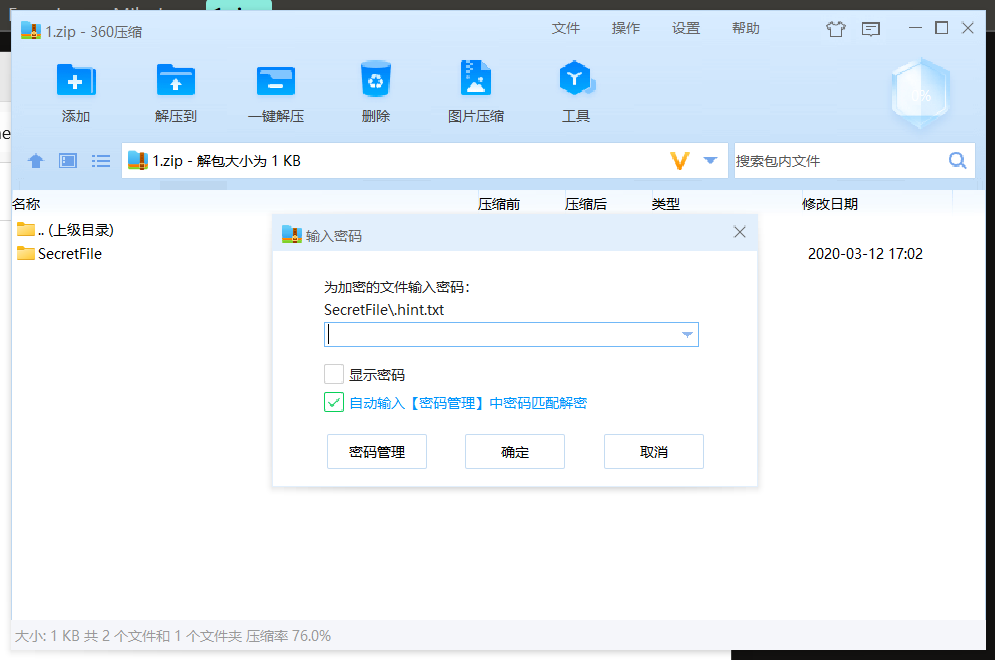
上来就要密码,de fr检查以后没发现伪加密,那就爆破
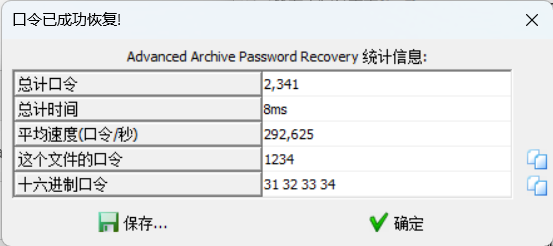
打开flag文件,可以发现是一串神秘编码,随波逐流一把梭即可
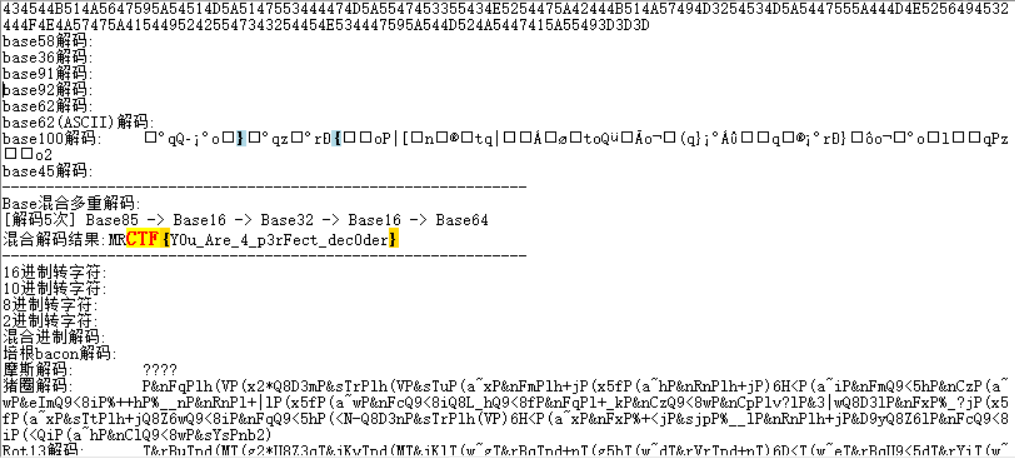
(别问为什么不用厨师,厨师报错了我也不知道为什么)
考点
文件包含
压缩包密码爆破
混合编码


 浙公网安备 33010602011771号
浙公网安备 33010602011771号