
Wfuzz(支持各种web漏洞扫描的工具)
Wfuzz is a tool designed for bruteforcing Web Applications, it can be used for finding resources not linked (directories, servlets, scripts, etc), bruteforce GET and POST parameters for checking different kind of injections (SQL, XSS, LDAP,etc), bruteforce Forms parameters (User/Password), Fuzzing,etc.
It's very flexible, here are some functionalities:
- -Recursion (When doing directory bruteforce)
- -Post, headers and authentication data bruteforcing
- -Output to HTML (easy for just clicking the links and checking the page, even with postdata!!)
- -Colored output on all systems ;)
- -Hide results by return code, word numbers, line numbers, etc.
- -Encodings:
- - random_upper
- - urlencode
- - sHA1
- - bin_ascii
- - base64
- - double_nibble_hex
- - uri_hex
- - md5
- - double_urlencode
- - utf8
- - utf8_binary
- - html
- - html decimal
- - many more...
- -Cookies fuzzing
- -Multithreading
- -Proxy support
- -Multiple FUZZ capability with multiple dictionaries
- -Authentication support (Ntlm, Digest,Basic)
- -All parameters bruteforcing (POST and GET)
- -Dictionaries tailored for known applications (Weblogic, Iplanet, Tomcat, Domino, Oracle 9i, Vignette, Coldfusion and many more. (Many dictionaries are from Darkraver's Dirb, www.open-labs.org)
It was created to facilitate the task in Web Applications assessments, it's a tool by pentesters for pentesters ;)
One of the strengths of wfuzz is the speed, just try it...
- How does it works?
-
The tool is based on dictionaries and ranges, you choose where you want to bruteforce just by replacing the part of the URL or the POST by the keyword FUZZ.
Check the video to see it running: Video
- Examples
-
-
- wfuzz.py -c -z file -f wordlists/commons.txt --hc 404 --html http://www.mysite.com/FUZZ 2> results.html
- This will bruteforce the site http://www.mysyte.com/FUZZ in search of resources (directories, scripts, files,etc), it will hide from the output the return code 404 (for easy reading the results), it will use the dictionary commons.txt for the bruteforce, and also will output the results to the results.html
file (with a cool format to work).
-
wfuzz.py -c -z range -r 1-100 --hc 404 http://www.mysite.com/list.asp?id=FUZZ
- In this example instead of using a file as dictionary, it will use a range from 1-100, and will bruteforce the parameter "id".
-
wfuzz.py -c -z file -f wordlists/commons.txt --hc 404 --html -d "id=1&catalogue=FUZZ" http://www.mysite.com/check.asp 2 > results.html
- Here you can see the use of POST data, with the option "-d".
-
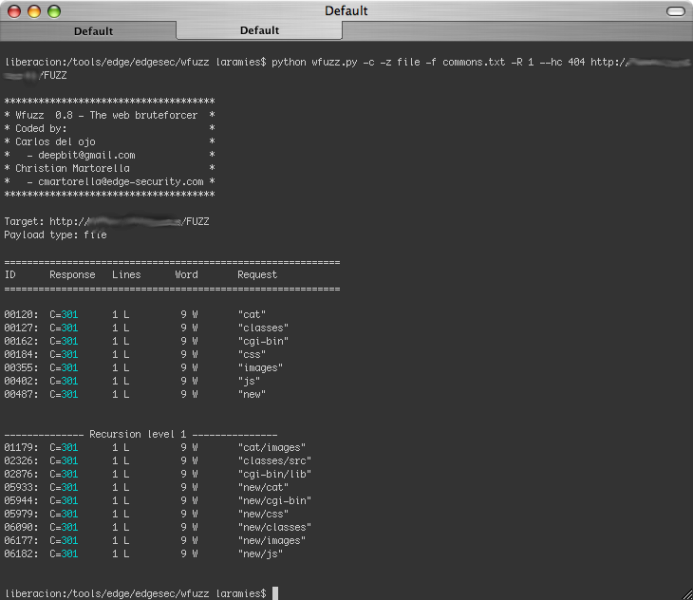
wfuzz.py -c -z file -f wordlists/commons.txt --hc 404 -R 1 http://www.mysite.com/FUZZ
- Example of path discovery, using a recursive level of 1 paths.
-
wfuzz.py -c -z file -f wordlists/Injection/SQL.txt -V allvars http://www.mysite.com/res.asp?id=1&name=cars&cat=2
- Example of Sql injection on every parameter of the request, you can fuzz every parameter with the option "-V allvars".
-
- Downloads
-
- Wfuzz 1.4 - Source (20/01/2008) last
- Wfuzz 1.4b - Windows binary (17/02/2008) last
- Wfuzz 1.3 - Source (18/10/2007)
- Wfuzz 1.2 - Source (14/08/2007)
- Wfuzz 1.1 - Win32
- Wfuzz 1.1 - Unix
- Changelog:
-
Wfuzz 1.4:
- -More encoders (UTF8,UT8 binary, HTML decimal, HTML hexadecimal,Mysql and Mssql CHAR, )
- -Some bugs fixed
- -Performance improved
Wfuzz 1.3:
- -Multiple encoding, it's possible to encode both dictionaries with different encodings.
- -Hidecode XXX (cuando da muchos errores, pero puede servir)
- -Word count fixed
- -More encoders (binascii,md5,sha1)
- -Authentication support (NTLM, Digest, Basic)
- -Authetication fuzzing
- -Results output length reduced to 50 chars.
Wfuzz 1.2:
- -Multiple FUZZ capability (FUZ2Z)
- -Colored output fixed
- -Redesign of payloads and encoders
- -Better management of objects, now it's possible to use a large dictionary or range.
- -More encoders
- -More dictionaries
- -Some bug fixes

