Redis 集群
Redis集群(Redis-Cluster)
Redis有四种模式,分别是单机版、主从复制模式、哨兵模式、以及集群模式。
Cluster模式
Cluster是真正的集群模式了,哨兵解决和主从不能自动故障恢复的问题,主机内存有限,主机写能力受限的问题,并且集群之前都是一台redis都是全量的数据,这样所有的redis都冗余一份,就会大大消耗内存空间。
集群模式实现了Redis数据的分布式存储,实现数据的分片,每个redis节点存储不同的内容,并且解决了在线的节点收缩(下线)和扩容(上线)问题。
集群模式真正意义上实现了系统的高可用和高性能,但是集群同时进一步使系统变得越来越复杂,接下来我们来详细的了解集群的运作原理。
数据分区原理
集群的原理图还是很好理解的,在Redis集群中采用的是虚拟槽分区算法,会把redis集群分成16384 个槽(0 -16383)。
比如:下图所示三个master,会把0 -16383范围的槽可能分成三部分(0-5000)、(5001-11000)、(11001-16383)分别数据三个缓存节点的槽范围。

当客户端请求过来(客户端链接哨兵节点),会首先通过对key进行CRC16 校验并对 16384 取模(CRC16(key)%16383)计算出key所在的槽,然后再到对应的槽上进行取数据或者存数据,这样就实现了数据的访问更新。

之所以进行分槽存储,是将一整堆的数据进行分片,防止单台的redis数据量过大,影响性能的问题。
节点通信
节点之间实现了将数据进行分片存储,那么节点之间又是怎么通信的呢?这个和前面哨兵模式讲的命令基本一样。
首先新上线的节点,会通过 Gossip 协议向老成员发送Meet消息,表示自己是新加入的成员。
老成员收到Meet消息后,在没有故障的情况下会回复PONG消息,表示欢迎新结点的加入,除了第一次发送Meet消息后,之后都会发送定期PING消息,实现节点之间的通信。

通信的过程中会为每一个通信的节点开通一条tcp通道,之后就是定时任务,不断的向其它节点发送PING消息,这样做的目的就是为了了解节点之间的元数据存储情况,以及健康状况,以便及时发现问题。
数据请求
每个redist服务器底层都维护了一个槽数组和节点数组
上面说到了槽信息,在Redis的底层维护了unsigned char myslots[CLUSTER_SLOTS/8] 一个数组存放每个节点的槽信息。因为他是一个二进制数组,只有存储0和1值,如下图所示:

这样数组只表示自己是否存储对应的槽数据,若是1表示存在该数据,0表示不存在该数据,这样查询的效率就会非常的高,类似于布隆过滤器,二进制存储。
比如:集群节点1负责存储0-5000的槽数据,但是此时只有0、1、2存储有数据,其它的槽还没有存数据,所以0、1、2对应的值为1。
并且,每个redis底层还维护了一个clusterNode数组,大小也是16384,用于储存负责对应槽的节点的ip、端口等信息,这样每一个节点就维护了其它节点的元数据信息,便于及时的找到对应的节点。
当新结点加入或者节点收缩,通过PING命令通信,及时的更新自己clusterNode数组中的元数据信息,这样有请求过来也就能及时的找到对应的节点。

有两种其它的情况就是,若是请求过来发现,数据发生了迁移,比如新节点加入,会使旧的缓存节点数据迁移到新结点。
请求过来发现旧节点已经发生了数据迁移并且数据被迁移到新结点,由于每个节点都有clusterNode信息,通过该信息的ip和端口。此时旧节点就会向客户端发一个MOVED 的重定向请求,表示数据已经迁移到新结点上,你要访问这个新结点的ip和端口就能拿到数据,这样就能重新获取到数据。
倘若正在发生数据迁移呢?旧节点就会向客户端发送一个ASK 重定向请求,并返回给客户端迁移的目标节点的ip和端口,这样也能获取到数据。
扩容和收缩
扩容和收缩也就是节点的上线和下线,可能节点发生故障了,自动故障转移的过程(节点收缩)。
节点的收缩和扩容时,会重新计算每一个节点负责的槽范围,并根据虚拟槽算法,将对应的数据更新到对应的节点。(扩容需要手动重新分配槽位,缩容需要手动先把主节点槽位去除)
还有前面的讲的新加入的节点会首先发送Meet消息,详细可以查看前面讲的内容,基本一样的模式。
以及发生故障后,领头哨兵节点的选举,master节点的重新选举,slave怎样晋升为master节点,可以查看前面哨兵模式选举过程。
优点
集群模式是一个无中心的架构模式,将数据进行分片,分布到对应的槽中,每个节点(master)存储不同的数据内容,通过路由(redis的节点数组)能够找到对应的节点负责存储的槽,能够实现高效率的查询。
并且集群模式增加了横向和纵向的扩展能力,实现节点加入和收缩,集群模式是哨兵的升级版,哨兵的优点集群都有。
缺点
缓存的最大问题就是带来数据一致性问题,在平衡数据一致性的问题时,兼顾性能与业务要求,大多数都是以最终一致性的方案进行解决,而不是强一致性。
并且集群模式带来节点数量的剧增,一个集群模式最少要6台机,因为要满足半数原则的选举方式,所以也带来了架构的复杂性。
slave只充当备份,并不能缓解master的读的压力,只有master节点提供读写。
集群搭建
Redis5.0之后的版本放弃了 Ruby 的集群方式,改为使用 C 语言编写的redis-cli的方式,使集群的构建方式复杂度大大降低。
创建6个Redis的配置文件,如下所示:
/usr/local/redis-5.0.4/redis-cluster-conf/7001/redis.conf /usr/local/redis-5.0.4/redis-cluster-conf/7002/redis.conf /usr/local/redis-5.0.4/redis-cluster-conf/7003/redis.conf /usr/local/redis-5.0.4/redis-cluster-conf/7004/redis.conf /usr/local/redis-5.0.4/redis-cluster-conf/7005/redis.conf /usr/local/redis-5.0.4/redis-cluster-conf/7006/redis.conf
配置文件内容:
1 port 7001 # 端口,每个配置文件不同7001-7006 2 cluster-enabled yes # 启用集群模式 3 cluster-config-file nodes.conf #节点配置文件 4 cluster-node-timeout 5000 # 超时时间 5 appendonly yes # 打开aof持久化 6 daemonize yes # 后台运行 7 protected-mode no # 非保护模式 8 pidfile /var/run/redis_7001.pid # 根据端口修改
启动6个Redis节点:
./src/redis-server redis-cluster-conf/7001/redis.conf ./src/redis-server redis-cluster-conf/7002/redis.conf ./src/redis-server redis-cluster-conf/7003/redis.conf ./src/redis-server redis-cluster-conf/7004/redis.conf ./src/redis-server redis-cluster-conf/7005/redis.conf ./src/redis-server redis-cluster-conf/7006/redis.conf
此时启动的6个Redis服务是相互独立运行的,通过以下命令配置集群。
1 ./src/redis-cli --cluster create --cluster-replicas 1 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 127.0.0.1:7006
此命令配置集群后,不需要手动设置主从复制,集群会自动选择主节点以及对应从节点,槽位也会自动分配,之后可以手动再次分配槽位。
cluster-replicas 1 表示每个master有一个从节点
配置完看到如下图所示信息表示集群搭建成功:
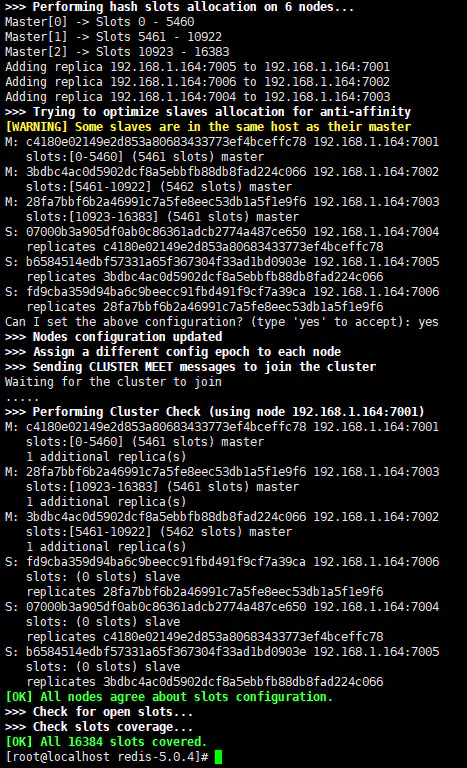
从图中可以看到启动了3个master节点,3个slave节点,集群16384个槽点平均分配到了3个master节点上。图中很长的一串字母数字的组合(07000b3a90......)为节点的ID。后面对节点的操作中会用到。
集群重新分片
如果对默认的平均分配不满意,我们可以对集群进行重新分片。执行如下命令,只需要指定集群中的其中一个节点地址即可,它会自动找到集群中的其他节点。(如果设置了密码则需要加上 -a <password>,没有密码则不需要,后面的命令我会省略这个,设置了密码的自己加上就好)。
新增节点后也需要重新分配槽

./src/redis-cli -a <password> --cluster reshard 127.0.0.1:7001
输入你想重新分配的哈希槽数量
How many slots do you want to move (from 1 to 16384)?
输入你想接收这些哈希槽的节点ID
What is the receiving node ID?
输入想从哪个节点移动槽点,选择all表示所有其他节点,也可以依次输入节点ID,以done结束。
1 Please enter all the source node IDs. 2 Type 'all' to use all the nodes as source nodes for the hash slots. 从所有的master中重新分配 3 Type 'done' once you entered all the source nodes IDs. 4 Source node #1:
输入yes执行重新分片
Do you want to proceed with the proposed reshard plan (yes/no)?
Redis常见数据丢失情况分析及解决
1. 异步复制导致的数据丢失
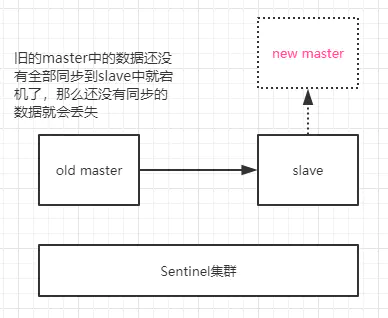
因为master->slave的数据同步是异步的,所以可能存在部分数据还没有同步到slave,master就宕机了,此时这部分数据就丢失了。
2. 脑裂导致的数据丢失
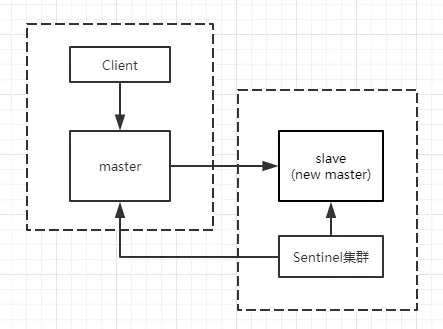
当master所在的机器突然脱离的正常的网络,与其他slave、sentinel失去了连接,但是master还在运行着。此时sentinel就会认为master宕机了,会开始选举把slave提升为新的master,这个时候集群中就会出现两个master,也就是所谓的脑裂。
此时虽然产生了新的master节点,但是客户端可能还没来得及切换到新的master,会继续向旧的master写入数据,这部分数据会丢失。
当网络恢复正常时,旧的master会变成新的master的从节点,自己的数据会清空,重新从新的master上复制数据。
解决方案
Redis提供了这两个配置用来降低数据丢失的可能性
1 min-slaves-to-write 1
2 min-slaves-max-lag 10
上面两行配置的意思是,要求至少有1个slave,数据复制和同步的延迟不能超过10秒,如果不符合这个条件,那么master将不会接收任何请求。
(1)减少异步复制的数据丢失
有了min-slaves-max-lag这个配置,就可以确保,一旦slave复制数据和ack延时太长,就认为master宕机后损失的数据太多了,那么就拒绝写请求,这样可以把master宕机时由于部分数据未同步到slave导致的数据丢失降低到可控范围内。
(2)减少脑裂的数据丢失
如果一个master出现了脑裂,跟其他slave丢了连接,那么上面两个配置可以确保,如果不能继续给指定数量的slave发送数据,而且slave超过10秒没有给自己ack消息,那么就直接拒绝客户端的写请求
这样脑裂后的旧master就不会接受client的新数据,也就避免了数据丢失。
Redis并不能保证数据的强一致性,看官方文档的说明


 浙公网安备 33010602011771号
浙公网安备 33010602011771号