基于多多看书网站热门榜单数据爬取
基于多多看书网站热门榜单数据爬取
一,选题背景
大数据时代,要进行数据分析,首先要有数据源,通过爬虫技术可以获得等多的数据源。在进行大数据分析或者进行数据挖掘的时候,数据源可以从某些提供数据统计的网站获得,也可以从某些文献或内部资料中获得,但从这些获得数据的方式,有时很难满足我们对数据的需求,此时就可以利用爬虫技术,自动地从互联网中获取需要的数据内容,并将这些数据内容作为数据源,从而进行更深层次的数据分析。
二,爬虫设计方案
1,爬虫名称:基于多多看书网站热门榜单数据爬取
2,爬虫的内容与数据特征分析
2.1,因为该专题结构清晰,数据易于爬取,易于清洗,该网站允许爬取且不容易被限制
2.2 预期目标是将数据爬取下来后保存下来,并绘制出不同图表以实现数据可视化
3, 技术难点
解析意味着从数据集或文本块中提取相关信息组件,以便以后可以容易地访问它们并将其用于其他操作。要将网页转换为实际上对研究或分析有用的数据,我们需要以一种使数据易于根据定义的参数集进行搜索,分类和服务的方式进行解析。最后,在获得所需的数据并将其分解为有用的组件之后,通过可扩展的方法来将所有提取和解析的数据存储在数据库或集群中,然后创建一个允许用户可及时查找相关数据集或提取的功能。思路有三步:爬取数据,数据清洗,数据保存,数据可视化
技术难点主要是第三方库的使用,因为是边做边学,中间走了很多弯路。
三,结构特征分析
1.页面的结构
2.Htmls页面解析

四,程序设计
1,数据爬取与采集
def crawl():
###网址
url = "https://xs.sogou.com/top/hot/"
###模拟浏览器
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'}
2,对数据清洗和处理
html = etree.HTML( requests.get( url, headers=header ).text )
rank = html.xpath( '//ul[@class="list-content list-0"]//span[@class="text-num icon"]/text()' ) # 序号
type = html.xpath( '//ul[@class="list-content list-0"]//a[@class="list-type"]/text()' ) # 类型
name = html.xpath( '//ul[@class="list-content list-0"]//a[@class="list-name"]/text()' ) # 小说名称
section = html.xpath( '//ul[@class="list-content list-0"]//a[@class="list-section"]/text()' ) # 更新章节
status = html.xpath( '//ul[@class="list-content list-0"]//span[@class="list-status"]/text()' ) # 状态
count = html.xpath( '//ul[@class="list-content list-0"]//span[@class="list-count"]/text()' ) # 字数
author = html.xpath( '//ul[@class="list-content list-0"]//span[@class="list-author"]/text()' ) # 作者
time = html.xpath( '//ul[@class="list-content list-0"]//span[@class="list-time"]/text()' ) # 更新时间
list = []
for i in range( 0, len( name ) ):
subList = []
subList.append( rank[i] )
subList.append( re.sub( '「', '', re.sub( '」', '', type[i] ) ) )
subList.append( name[i] )
subList.append( section[i] )
subList.append( status[i] )
subList.append( re.sub( ',', '', re.sub( '万字', '', count[i] ) ) )
subList.append( author[i] )
subList.append( time[i] )
list.append( subList )
name = ['排名', '类型', '小说名称', '更新章节', '状态', '字数(万字)', '作者', '更新时间']
3,数据分析与可视化以及数据持久化(包括图)
# 数据持久化
test = pd.DataFrame( columns=name, data=list )
print( test )
test.to_csv( 'bangdan.csv' )
return list
def remove_markers(str_list):
pattern = re.compile( r'[^\u4e00-\u9fa5]' )
return [pattern.sub( '', line ) for line in str_list]
def run():
# 读取数据
csv_file = './bangdan.csv' # 导入csv数据
data = pd.read_csv( csv_file )
datas = data['类型'].value_counts()
te = pd.DataFrame( data=datas )
te.to_csv( 'leixing.csv' )
datazt = data['状态'].value_counts()
t = pd.DataFrame( data=datazt )
t.to_csv( 'zhuangtai.csv' )
dataci = data['小说名称']
print( dataci )
word_list = list( dataci )
word_list = remove_markers( word_list )
print( word_list )
datazzzs = data[['作者', '字数(万字)']]
# datazzzs=datazzzs.groupby('作者').apply(lambda x:x['字数(万字)'].sum())
datazzzs = datazzzs.groupby( '作者' ).agg( {'字数(万字)': 'sum'} ).sort_values( by='字数(万字)', ascending=False )
testpm = pd.DataFrame( data=datazzzs )
testpm.to_csv( 'zzzs.csv' )
csvpm_file = './zzzs.csv' # 导入csv数据
datazzpm = pd.read_csv( csvpm_file )
datazzpm = datazzpm.head( 10 )
print( datazzpm )
words_list = []
for line in word_list:
# 扩展列表
words_list.extend( word for word, flag in pseg.cut( line, use_paddle=True ) if flag in ['a', 'vd', 'n'] )
# 计数
c1 = Counter( words_list )
print( c1 )
# 柱状图生成
a = (
Bar( init_opts=opts.InitOpts( height="450px", width="900px" ) )
.add_xaxis( list( datas.index ) )
.add_yaxis( "类型", list( datas ) )
.set_global_opts(
title_opts=opts.TitleOpts( title="热门小说类型统计" ),
datazoom_opts=[opts.DataZoomOpts(), opts.DataZoomOpts( type_="inside" )],
)
)

# 词云图生成
b = (
WordCloud( init_opts=opts.InitOpts( height="450px", width="900px" ) )
.add( series_name="热点分析", data_pair=c1.most_common(), word_size_range=[22, 66] )
.set_global_opts(
title_opts=opts.TitleOpts(
title="热点分析", title_textstyle_opts=opts.TextStyleOpts( font_size=23 )
),
tooltip_opts=opts.TooltipOpts( is_show=True ),
)
)

# 饼状图生成
c = (
Pie( init_opts=opts.InitOpts( height="450px", width="600px" ) )
.add(
"",
[list( z ) for z in zip( datazt.index, list( datazt ) )],
radius=["40%", "75%"],
)
.set_global_opts(
title_opts=opts.TitleOpts( title="小说状态" ),
legend_opts=opts.LegendOpts( orient="vertical", pos_top="15%", pos_left="2%" ),
)
.set_series_opts( label_opts=opts.LabelOpts( formatter="{b}: {c}" ) )
)

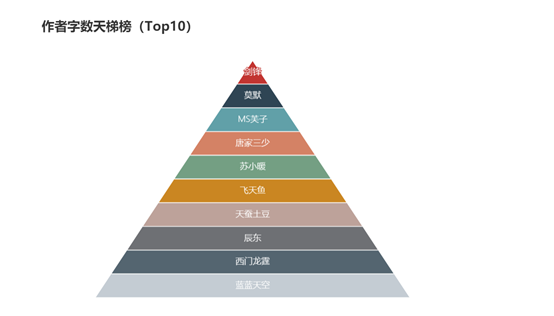
# 天梯图生成
d = (
Funnel( init_opts=opts.InitOpts( height="450px", width="600px" ) )
.add(
"作者",
[list( z ) for z in zip( list( datazzpm['作者'] ), datazzpm.index + 1 )],
sort_="ascending",
label_opts=opts.LabelOpts( position="inside" ),
)
.set_global_opts(
title_opts=opts.TitleOpts( title="作者字数天梯榜(Top10)" ),
legend_opts=opts.LegendOpts( is_show=False )
)
)
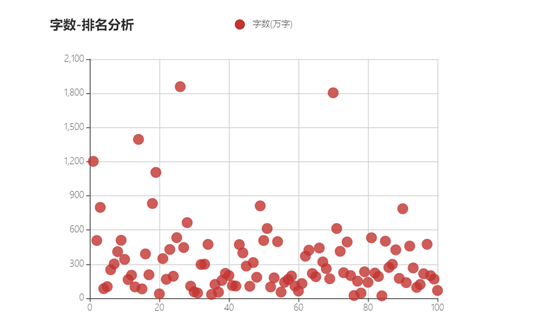
# 散点图生成
e = (
Scatter( init_opts=opts.InitOpts( height="450px", width="600px" ) )
.add_xaxis(
xaxis_data=data['排名'] )
.add_yaxis(
series_name="字数(万字)",
y_axis=data['字数(万字)'],
symbol_size=15,
label_opts=opts.LabelOpts( is_show=False ),
)
.set_series_opts()
.set_global_opts(
title_opts=opts.TitleOpts( title="字数-排名分析" ),
xaxis_opts=opts.AxisOpts(
type_="value", splitline_opts=opts.SplitLineOpts( is_show=True )
),
yaxis_opts=opts.AxisOpts(
type_="value",
axistick_opts=opts.AxisTickOpts( is_show=True ),
splitline_opts=opts.SplitLineOpts( is_show=True ),
),
tooltip_opts=opts.TooltipOpts( is_show=False ),
)
)
4,完整代码-------------
1 import re
2 from collections import Counter
3
4 import jieba.posseg as pseg
5 import pandas as pd
6 import requests
7 from bs4 import BeautifulSoup
8 from lxml import etree
9 from pyecharts import options as opts
10 from pyecharts.charts import Bar, WordCloud, Pie, Page, Scatter
11 from pyecharts.charts import Funnel
12 import webbrowser
13 from threading import Thread
14 from tkinter import *
15 from tkinter import ttk
16 import tkinter as tk
17
18
19 # from dask.bytes.tests.test_http import requests
20
21
22 def crawl():
23 ###网址
24 url = "https://xs.sogou.com/top/hot/"
25 ###模拟浏览器
26 header = {
27 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'}
28
29 ### 使用xpath技术解析网页
30 html = etree.HTML( requests.get( url, headers=header ).text )
31
32 rank = html.xpath( '//ul[@class="list-content list-0"]//span[@class="text-num icon"]/text()' ) # 序号
33
34 type = html.xpath( '//ul[@class="list-content list-0"]//a[@class="list-type"]/text()' ) # 类型
35
36 name = html.xpath( '//ul[@class="list-content list-0"]//a[@class="list-name"]/text()' ) # 小说名称
37
38 section = html.xpath( '//ul[@class="list-content list-0"]//a[@class="list-section"]/text()' ) # 更新章节
39
40 status = html.xpath( '//ul[@class="list-content list-0"]//span[@class="list-status"]/text()' ) # 状态
41
42 count = html.xpath( '//ul[@class="list-content list-0"]//span[@class="list-count"]/text()' ) # 字数
43
44 author = html.xpath( '//ul[@class="list-content list-0"]//span[@class="list-author"]/text()' ) # 作者
45
46 time = html.xpath( '//ul[@class="list-content list-0"]//span[@class="list-time"]/text()' ) # 更新时间
47
48 list = []
49 for i in range( 0, len( name ) ):
50 subList = []
51 subList.append( rank[i] )
52 subList.append( re.sub( '「', '', re.sub( '」', '', type[i] ) ) )
53 subList.append( name[i] )
54 subList.append( section[i] )
55 subList.append( status[i] )
56 subList.append( re.sub( ',', '', re.sub( '万字', '', count[i] ) ) )
57 subList.append( author[i] )
58 subList.append( time[i] )
59 list.append( subList )
60 name = ['排名', '类型', '小说名称', '更新章节', '状态', '字数(万字)', '作者', '更新时间']
61 # 数据持久化
62 test = pd.DataFrame( columns=name, data=list )
63 print( test )
64 test.to_csv( 'bangdan.csv' )
65 return list
66
67
68 def remove_markers(str_list):
69 pattern = re.compile( r'[^\u4e00-\u9fa5]' )
70 return [pattern.sub( '', line ) for line in str_list]
71
72
73 def run():
74 # 读取数据
75 csv_file = './bangdan.csv' # 导入csv数据
76 data = pd.read_csv( csv_file )
77
78 datas = data['类型'].value_counts()
79 te = pd.DataFrame( data=datas )
80 te.to_csv( 'leixing.csv' )
81
82 datazt = data['状态'].value_counts()
83 t = pd.DataFrame( data=datazt )
84 t.to_csv( 'zhuangtai.csv' )
85
86 dataci = data['小说名称']
87 print( dataci )
88 word_list = list( dataci )
89 word_list = remove_markers( word_list )
90 print( word_list )
91
92 datazzzs = data[['作者', '字数(万字)']]
93 # datazzzs=datazzzs.groupby('作者').apply(lambda x:x['字数(万字)'].sum())
94 datazzzs = datazzzs.groupby( '作者' ).agg( {'字数(万字)': 'sum'} ).sort_values( by='字数(万字)', ascending=False )
95 testpm = pd.DataFrame( data=datazzzs )
96 testpm.to_csv( 'zzzs.csv' )
97 csvpm_file = './zzzs.csv' # 导入csv数据
98 datazzpm = pd.read_csv( csvpm_file )
99 datazzpm = datazzpm.head( 10 )
100 print( datazzpm )
101
102 words_list = []
103 for line in word_list:
104 # 扩展列表
105 words_list.extend( word for word, flag in pseg.cut( line, use_paddle=True ) if flag in ['a', 'vd', 'n'] )
106 # 计数
107 c1 = Counter( words_list )
108 print( c1 )
109 # 柱状图生成
110 a = (
111 Bar( init_opts=opts.InitOpts( height="450px", width="900px" ) )
112 .add_xaxis( list( datas.index ) )
113 .add_yaxis( "类型", list( datas ) )
114 .set_global_opts(
115 title_opts=opts.TitleOpts( title="热门小说类型统计" ),
116 datazoom_opts=[opts.DataZoomOpts(), opts.DataZoomOpts( type_="inside" )],
117 )
118 )
119 # 词云图生成
120 b = (
121 WordCloud( init_opts=opts.InitOpts( height="450px", width="900px" ) )
122 .add( series_name="热点分析", data_pair=c1.most_common(), word_size_range=[22, 66] )
123 .set_global_opts(
124 title_opts=opts.TitleOpts(
125 title="热点分析", title_textstyle_opts=opts.TextStyleOpts( font_size=23 )
126 ),
127 tooltip_opts=opts.TooltipOpts( is_show=True ),
128 )
129 )
130 # 饼状图生成
131 c = (
132 Pie( init_opts=opts.InitOpts( height="450px", width="600px" ) )
133 .add(
134 "",
135 [list( z ) for z in zip( datazt.index, list( datazt ) )],
136 radius=["40%", "75%"],
137 )
138 .set_global_opts(
139 title_opts=opts.TitleOpts( title="小说状态" ),
140 legend_opts=opts.LegendOpts( orient="vertical", pos_top="15%", pos_left="2%" ),
141 )
142 .set_series_opts( label_opts=opts.LabelOpts( formatter="{b}: {c}" ) )
143 )
144 # 天梯图生成
145 d = (
146 Funnel( init_opts=opts.InitOpts( height="450px", width="600px" ) )
147 .add(
148 "作者",
149 [list( z ) for z in zip( list( datazzpm['作者'] ), datazzpm.index + 1 )],
150 sort_="ascending",
151 label_opts=opts.LabelOpts( position="inside" ),
152 )
153 .set_global_opts(
154 title_opts=opts.TitleOpts( title="作者字数天梯榜(Top10)" ),
155 legend_opts=opts.LegendOpts( is_show=False )
156 )
157 )
158 # 散点图生成
159 e = (
160 Scatter( init_opts=opts.InitOpts( height="450px", width="600px" ) )
161 .add_xaxis(
162 xaxis_data=data['排名'] )
163 .add_yaxis(
164 series_name="字数(万字)",
165 y_axis=data['字数(万字)'],
166 symbol_size=15,
167 label_opts=opts.LabelOpts( is_show=False ),
168 )
169 .set_series_opts()
170 .set_global_opts(
171 title_opts=opts.TitleOpts( title="字数-排名分析" ),
172 xaxis_opts=opts.AxisOpts(
173 type_="value", splitline_opts=opts.SplitLineOpts( is_show=True )
174 ),
175 yaxis_opts=opts.AxisOpts(
176 type_="value",
177 axistick_opts=opts.AxisTickOpts( is_show=True ),
178 splitline_opts=opts.SplitLineOpts( is_show=True ),
179 ),
180 tooltip_opts=opts.TooltipOpts( is_show=False ),
181 )
182 )
183 # html 生成
184 page = (
185 Page( page_title="result", layout=Page.SimplePageLayout )
186 .add( a )
187 .add( b )
188 .add( c )
189 .add( d )
190 .add( e )
191 .render( "result.html" )
192 )
193
194 with open( "热门小说分析.html", "r+", encoding='utf-8' ) as html:
195 html_bf = BeautifulSoup( html, 'lxml' )
196 divs = html_bf.select( '.chart-container' )
197 divs[0][
198 "style"] = "width:500px;height:250px;position:absolute;top:5px;left:0px;border-style:solid;border-color:#000000;border-width:0px;"
199 divs[1][
200 'style'] = "width:500px;height:400px;position:absolute;top:5px;left:505px;border-style:solid;border-color:#000000;border-width:0px;"
201 divs[2][
202 "style"] = "width:500px;height:400px;position:absolute;top:255x;left:0px;border-style:solid;border-color:#000000;border-width:0px;"
203 divs[3][
204 "style"] = "width:500px;height:400px;position:absolute;top:255px;left:505px;border-style:solid;border-color:#000000;border-width:0px;"
205 body = html_bf.find( "body" )
206 body["style"] = "background-color:#333333;"
207 html_new = str( html_bf )
208 html.seek( 0, 0 )
209 html.truncate()
210 html.write( html_new )
211 html.close()
212
213
214 def thread_it(func, *args):
215 '''
216 将函数打包进线程
217 '''
218 # 创建
219 t = Thread( target=func, args=args )
220 # 守护
221 t.setDaemon( True )
222 # 启动
223 t.start()
224
225
226 class uiob:
227
228 def clear_tree(self, tree):
229 '''
230 清空表格
231 '''
232 x = tree.get_children()
233 for item in x:
234 tree.delete( item )
235
236 def add_tree(self, list, tree):
237 '''
238 新增数据到表格
239 '''
240 i = 0
241 for subList in list:
242 tree.insert( '', 'end', values=subList )
243 i = i + 1
244 tree.grid()
245
246 def searh(self):
247 self.clear_tree( self.treeview ) # 清空表格
248 self.B_0['text'] = '正在努力搜索'
249 list = crawl()
250 self.add_tree( list, self.treeview ) # 将数据添加到tree中
251
252 self.B_0['state'] = NORMAL
253 self.B_0['text'] = '更新榜单'
254
255 run()
256
257 def center_window(self, root, w, h):
258 """
259 窗口居于屏幕中央
260 """
261 # 获取屏幕 宽、高
262 ws = root.winfo_screenwidth()
263 hs = root.winfo_screenheight()
264
265 # 计算 x, y 位置
266 x = (ws / 2) - (w / 2)
267 y = (hs / 2) - (h / 2)
268
269 root.geometry( '%dx%d+%d+%d' % (w, h, x, y) )
270
271 def click(self):
272 webbrowser.open( r"file:///D:/code/Python/CrawlAndCloud/result.html" )
273
274 def ui_process(self):
275 root = Tk()
276 self.root = root
277
278 root.title( "多多图书热门榜" )
279 self.center_window( root, 900, 350 )
280 root.resizable( 0, 0 )
281 root['highlightcolor'] = 'yellow'
282
283 labelframe = LabelFrame( root, width=900, height=350, background="white" )
284 labelframe.place( x=5, y=5 )
285 self.labelframe = labelframe
286 # # 图片
287 # photo = tk.PhotoImage( file="duoduo.png" )
288 # Lab = tk.Label( root, image=photo, )
289 # Lab.place( x=10, y=10 )
290
291 B_1 = Button( labelframe, text="数据分析", background="white" )
292 B_1.place( x=500, y=25, width=150, height=50 )
293 self.B_1 = B_1
294 B_1.configure( command=lambda: thread_it( self.click() ) ) # 按钮绑定单击事件
295 # 查询按钮
296 B_0 = Button( labelframe, text="更新榜单", background="white" )
297 B_0.place( x=700, y=25, width=150, height=50 )
298 self.B_0 = B_0
299 B_0.configure( command=lambda: thread_it( self.searh ) ) # 按钮绑定单击事件
300 # 框架布局,承载多个控件
301 frame_root = Frame( labelframe )
302 frame_l = Frame( frame_root )
303 frame_r = Frame( frame_root )
304 self.frame_root = frame_root
305 self.frame_l = frame_l
306 self.frame_r = frame_r
307
308 # 表格
309 columns = ("序号", "类型", "小说名称", "更新章节", "状态", "字数(万字)", "作者", "更新时间")
310 treeview = ttk.Treeview( frame_l, height=10, show="headings", columns=columns )
311 treeview.column( "序号", width=50, anchor='center' )
312 treeview.column( "类型", width=50, anchor='center' )
313 treeview.column( "小说名称", width=200, anchor='center' )
314 treeview.column( "更新章节", width=200, anchor='center' )
315 treeview.column( "状态", width=50, anchor='center' )
316 treeview.column( "字数(万字)", width=75, anchor='center' )
317 treeview.column( "作者", width=75, anchor='center' )
318 treeview.column( "更新时间", width=150, anchor='center' )
319
320 treeview.heading( "序号", text="序号" ) # 显示表头
321 treeview.heading( "类型", text="类型" )
322 treeview.heading( "小说名称", text="小说名称" )
323 treeview.heading( "更新章节", text="更新章节" )
324 treeview.heading( "状态", text="状态" )
325 treeview.heading( "字数(万字)", text="字数(万字)" )
326 treeview.heading( "作者", text="作者" )
327 treeview.heading( "更新时间", text="更新时间" )
328
329 # 垂直滚动条
330 vbar = ttk.Scrollbar( frame_r, command=treeview.yview )
331 treeview.configure( yscrollcommand=vbar.set )
332
333 treeview.pack()
334 self.treeview = treeview
335 vbar.pack( side=RIGHT, fill=Y )
336 self.vbar = vbar
337
338 # 框架的位置布局
339 frame_l.grid( row=0, column=0, sticky=NSEW )
340 frame_r.grid( row=0, column=1, sticky=NS )
341 frame_root.place( x=10, y=100 )
342
343 root.mainloop()
344
345
346 uicrawl = uiob()
347 uicrawl.ui_process()
五,总结
1.得到的结论:
根据柱状图发现,穿越题材的小说最受大家欢迎,然后依次是世家、言情、世代......;根据关键词词云分析,小说中最喜欢用的主题是总裁、重生、神医、兵王等。;根据饼状图分析,大部分热门小说已经完结,只有百分之13左右还在连载。;根据天梯图分析,写作字数最多的作者是剑锋、莫默等人。;根据散点图分析,小说的字数多少与其排名几乎没有任何联系。基本达到预期的目标。
2.收获:
这次设计过程中让我学会了爬取网站信息的分析和技巧,需要掌握的知识点还有很多,还需要不断学习改进。
将数据用层叠列表的格式存储起来,然后使用panda库的Dataframe函数将数据存到文件中
list=[]
for i inrange(0,len( name )):
subList =[]
subList.append( rank[i])
subList.append( re.sub('「','', re.sub('」','',type[i])))
subList.append( name[i])
subList.append( section[i])
subList.append( status[i])
subList.append( re.sub(',','', re.sub('万字','', count[i])))
subList.append( author[i])
subList.append( time[i])
list.append( subList )
name =['排名','类型','小说名称','更新章节','状态','字数(万字)','作者','更新时间']
# 数据持久化
test = pd.DataFrame( columns=name, data=list)
将保存在文件中的数据分类再保存在不同的文件中,例如“类型”
csv_file ='./bangdan.csv' # 导入csv数据
data = pd.read_csv( csv_file )
datas = data['类型'].value_counts()
te = pd.DataFrame( data=datas )
te.to_csv('leixing.csv')
柱状图生成
a =(
Bar( init_opts=opts.InitOpts( height="450px", width="900px"))
.add_xaxis(list( datas.index ))
.add_yaxis("类型",list( datas ))
.set_global_opts(
title_opts=opts.TitleOpts( title="热门小说类型统计"),
datazoom_opts=[opts.DataZoomOpts(), opts.DataZoomOpts( type_="inside")],
)
)
词云图生成:
b =(
WordCloud( init_opts=opts.InitOpts( height="450px", width="900px"))
.add( series_name="热点分析", data_pair=c1.most_common(), word_size_range=[22,66])
.set_global_opts(
title_opts=opts.TitleOpts(
title="热点分析", title_textstyle_opts=opts.TextStyleOpts( font_size=23)
),
tooltip_opts=opts.TooltipOpts( is_show=True),
)
)
饼状图生成:
c =(
Pie( init_opts=opts.InitOpts( height="450px", width="600px"))
.add(
"",
[list( z )for z inzip( datazt.index,list( datazt ))],
radius=["40%","75%"],
)
.set_global_opts(
title_opts=opts.TitleOpts( title="小说状态"),
legend_opts=opts.LegendOpts( orient="vertical", pos_top="15%", pos_left="2%"),
)
.set_series_opts( label_opts=opts.LabelOpts( formatter="{b}: {c}"))
)
天梯图生成:
d =(
Funnel( init_opts=opts.InitOpts( height="450px", width="600px"))
.add(
"作者",
[list( z )for z inzip(list( datazzpm['作者']), datazzpm.index +1)],
sort_="ascending",
label_opts=opts.LabelOpts( position="inside"),
)
.set_global_opts(
title_opts=opts.TitleOpts( title="作者字数天梯榜(Top10)"),
legend_opts=opts.LegendOpts( is_show=False)
)
)
散点图生成:
e =(
Scatter( init_opts=opts.InitOpts( height="450px", width="600px"))
.add_xaxis(
xaxis_data=data['排名'])
.add_yaxis(
series_name="字数(万字)",
y_axis=data['字数(万字)'],
symbol_size=15,
label_opts=opts.LabelOpts( is_show=False),
)
.set_series_opts()
.set_global_opts(
title_opts=opts.TitleOpts( title="字数-排名分析"),
xaxis_opts=opts.AxisOpts(
type_="value", splitline_opts=opts.SplitLineOpts( is_show=True)
),
yaxis_opts=opts.AxisOpts(
type_="value",
axistick_opts=opts.AxisTickOpts( is_show=True),
splitline_opts=opts.SplitLineOpts( is_show=True),
),
tooltip_opts=opts.TooltipOpts( is_show=False),
)
)
将各个图表模块生成为html
page =(
Page( page_title="热门小说分析", layout=Page.SimplePageLayout )
.add( a )
.add( b )
.add( c )
.add( d )
.add( e )
.render("热门小说分析.html")
)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号