
Flink入门
Flink快速上手
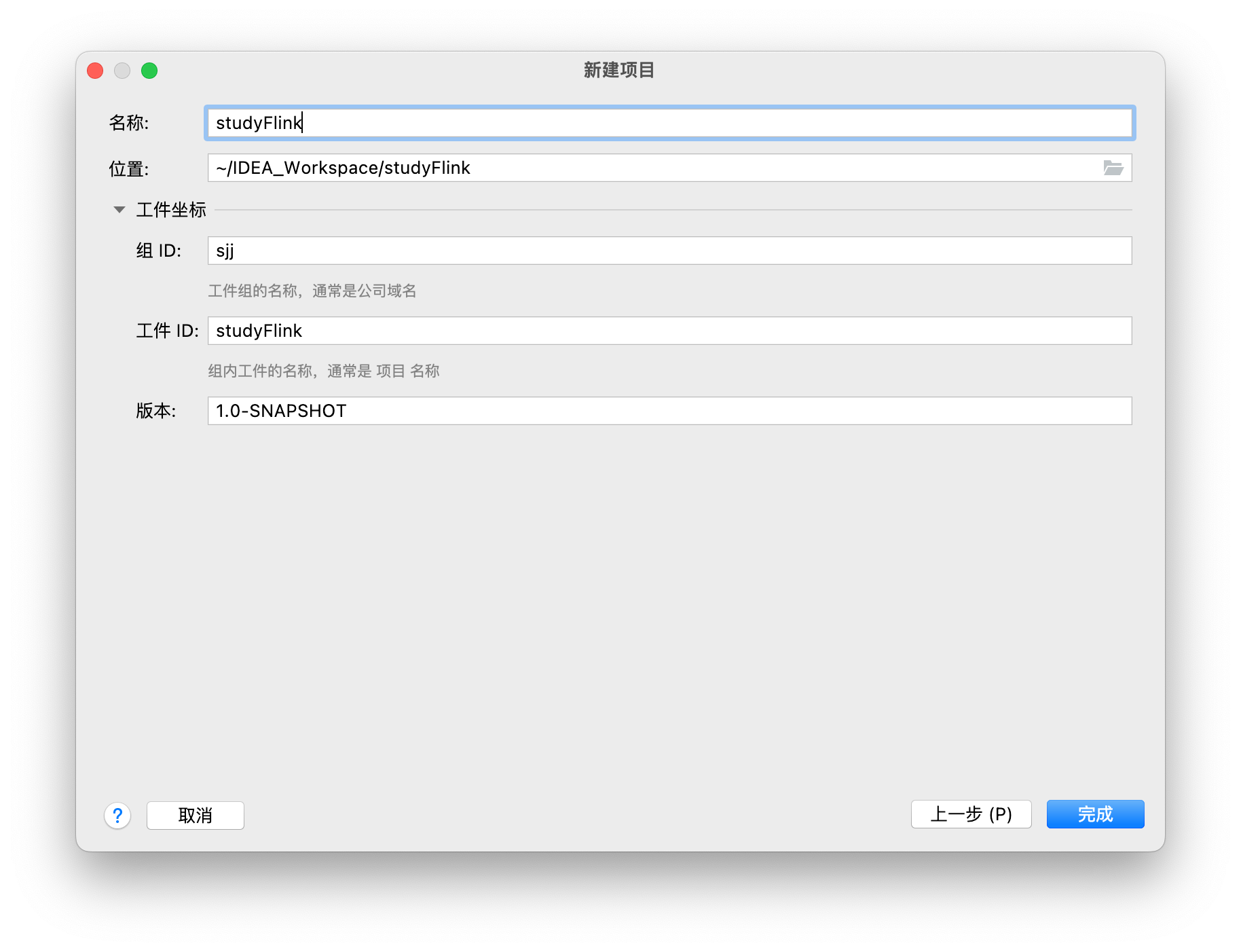
1-创建一个Maven项目
2-引入依赖
版本根据自己的情况和需求进行更改
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>sjj</groupId>
<artifactId>studyFlink</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<java.version>1.8</java.version>
<flink.version>1.13.0</flink.version>
<scala.binary.version>2.12</scala.binary.version>
<slf4j.version>1.7.25</slf4j.version>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<dependencies>
<!--Flink依赖-->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<!--日志管理依赖-->
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>${slf4j.version}</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-to-slf4j</artifactId>
<version>2.17.2</version>
</dependency>
</dependencies>
</project>
3-配置日志管理
在main/resource目录下新建log4j.properties文件
log4j.rootLogger=error, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%-4r [%t] %-5p %c %x - %m%n
4-试着编写一个wordCount
先准备一个input目录下的words.txt文件,当然其中需要一些单词,下面是 批处理的方式 进行单词统计:
/**
* 批处理的wordCount
*/
public class BatchWC {
public static void main(String[] args) {
// 1-创建执行环境 org.apache.flink.api.java.ExecutionEnvironment
ExecutionEnvironment environment = ExecutionEnvironment.getExecutionEnvironment();
// 2-获取数据源 org.apache.flink.api.java.operators.DataSource
DataSource<String> dataSource = environment.readTextFile("input/words.txt");
// 3-每行数据分词为二元组 收集器org.apache.flink.util.Collector 二元组org.apache.flink.api.java.tuple.Tuple2
FlatMapOperator<String, Tuple2<String, Integer>> word_1 = dataSource.flatMap((String lineData, Collector<Tuple2<String, Integer>> out) -> {
// 每行按空格切分
String[] words = lineData.split(" ");
// 单词转换为二元组
for (String word : words) {
// 包装为二元组,每个单词计数为1
out.collect(Tuple2.of(word, 1));
}
}).returns(Types.TUPLE(Types.STRING, Types.INT)); // org.apache.flink.api.common.typeinfo.Types
// 4-按照word分组 org.apache.flink.api.java.operators.UnsortedGrouping
UnsortedGrouping<Tuple2<String, Integer>> groupByWord = word_1.groupBy(0);
// 5-聚合统计 org.apache.flink.api.java.operators.AggregateOperator
AggregateOperator<Tuple2<String, Integer>> sum = groupByWord.sum(1);
// 6-打印结果
try {
sum.print();
} catch (Exception e) {
e.printStackTrace();
}
}
}
当然Flink最出名的当然还是 流批一体 (简单来说,流处理是一种特殊的批处理),使用上面的方法未免过于复杂。
在未来DataSet API恐怕是活不下去的,更简单的方法是 无论批处理还是流处理都统一采用DataStream API。
下面来编写一下 有界流处理 的wordCount:
/**
* 有界流处理的wordCount
*/
public class BoundedSteamWC {
public static void main(String[] args) throws Exception {
// 1-创建流式的执行环境 org.apache.flink.streaming.api.environment.StreamExecutionEnvironment
StreamExecutionEnvironment environment = StreamExecutionEnvironment.getExecutionEnvironment();
// 2-获取数据源 org.apache.flink.streaming.api.datastream.DataStreamSource
DataStreamSource<String> dataStreamSource = environment.readTextFile("../input/words.txt");
// 3-转换计算(类似批处理的思路) 收集器org.apache.flink.util.Collector 二元组org.apache.flink.api.java.tuple.Tuple2
SingleOutputStreamOperator<Tuple2<String, Integer>> word_1 = dataStreamSource.flatMap((String lineData, Collector<Tuple2<String, Integer>> out) -> {
String[] words = lineData.split(" ");
for (String word : words) {
out.collect(Tuple2.of(word, 1));
}
}).returns(Types.TUPLE(Types.STRING, Types.INT));
// 4-分组 org.apache.flink.streaming.api.datastream.KeyedStream
KeyedStream<Tuple2<String, Integer>, String> word_1KeyedStream = word_1.keyBy(data -> data.f0);
// 5-聚合 org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator
SingleOutputStreamOperator<Tuple2<String, Integer>> sum = word_1KeyedStream.sum(1);
// 6-输出
sum.print();
// 流处理应该是在等待是否还有输入
// 应当还有一步启动执行的步骤
// 7-启动执行
environment.execute();
}
}
若是要处理 无界流的数据 ,就只需要在数据源的地方稍加修改即可:
// 这里的端口以7777为例
DataStreamSource<String> dataStreamSource = environment.socketTextStream("hostname", 7777);
// 运行程序后在你的机器上执行下面的命令,之后在机器输入一些句子就可进行单词统计
// nc -lk 7777
Flink的部署
上面的快速上手,实际是IDEA模拟的一个Flink集群来进行的,而实际的生产环境中我们需要部署自己的Flink集群。
单机安装
单机安装非常简单只需要 从官网下载指定的安装包 并解压到你想防止的位置即可。
启动或停止等命令也在bin目录下
# 启动
bin/start-cluster.sh
# 停止
bin/stop-cluster.sh
需要注意的是单机安装是没不支持单作业模式部署的,但是可以使用应用模式。
集群安装
集群的安装无非是多了几台机器。
首先进入conf目录,修改 fink-conf.yaml 文件
# 指定JobManager节点
jobmanager.rpc.address: 机器1的IP或其映射
然后修改 workers 文件,写入指定为TaskManager的机器
机器2的IP或其映射
机器3的IP或其映射
最后尤为重要的一点, 将flink分发到各机器上 完成搭建。
集群的使用方法和单点的时候无二。
使用YARN模式
除了Flink自带的模式,Flink还支持外部的资源管理器,比如说YARN。
使用YARN首先要保证自己的机器上 部署好了Hadoop ,并且版本至少在2.2以上
如果你的版本较低(1.11前)就需要去官网下载支持hadoop的组件:

高版本只需要一些环境配置:
vim /etc/profile
# 配置hadoop环境
export HADOOP_HOME=/home/sjj/install/hadoop-3.2.2
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HADOOP_CLASSPATH='hadoop classpath'
启动YARN的会话模式如下:
- 启动hadoop集群(hdfs、yarn)
- 执行命令向yarn申请资源,开启yarn会话,启动flink集群
bin/yarn-session.sh -nm test
# -d 后台运行
# -jm 配置jobManager所需要的内存,单位MB
# -nm 任务的名字
# -qu 队列的名字
# -tm 配置每个taskManager所使用的内存

 浙公网安备 33010602011771号
浙公网安备 33010602011771号