Paper | Attention Is All You Need
Attention Is All You Need
【这是一篇4000+引用的文章。博主虽然不做NLP,但还是很感兴趣。当然,博主对本文的理解和翻译非常生涩】
动机:注意力机制很重要,现在的SOTA的NLP模型将编码器和解码器通过注意力机制连接在一起。
贡献:在本文中,作者提出了转换器(transformer)。该结构与循环和卷积网络无关,只与注意力机制有关。整体模型训练更快,更容易并行,效果最好。
1. 动机详述
当前的循环网络的逻辑 和 人类叙述的逻辑 一样,都是序列化的:运算是随着符号位置的推进而展开的,即\(t\)时刻的隐含状态\(h_t\)是 上一时刻隐含状态\(h_{t-1}\) 和 当前时刻输入 的函数。
但这种序列化逻辑有个缺点:不利于并行化。特别是当序列较长时,这种缺点被放大。
此时,注意力机制进入了作者的视野。注意力机制已经是很多 序列化建模任务 和 转换(transduction)模型 的不可或缺的部分,可以用来建模任意长距离的依赖关系。但是,这种注意力机制是和循环网络同时使用的。
本文提出的转换器,就是要让注意力模型跳出循环网络的框架。此时,转换器就具有了并行化能力。
2. 相关工作
已经有一些工作在尝试减少序列化计算量,如ByteNet和ConvS2S。它们的基础都是卷积神经网络。它们的共同问题:当序列长度增加时,运算量会线性增长或对数增长。
而转换器能做到:让运算量是一个固定的常数,尽管将损失一定性能。
自注意力机制:在单个序列内部,建立不同位置间的注意力机制,并用于建模该序列自身。
【端到端记忆网络:博主没看懂,也没去了解。】
作者声称,转换器是第一个 完全基于自注意力机制 的转换模型,而无需RNN或卷积结构。
3. 转换器结构
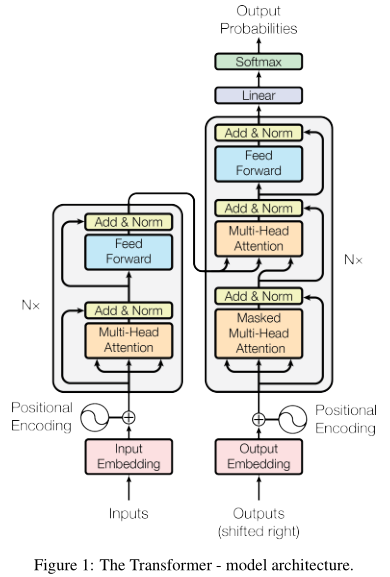
左边是编码器,右边是解码器。
如图左侧,编码器由6个相同的结构(\(N=6\))组成,每个结构包含2层:1层多头注意力机制(橙色),1层是全连接网络(蓝色)。内部共有两处短连接和层归一化。所有层的输出都是\(d_k = 512\)维。
右侧是解码器。解码器也是由6个相同的结构组成,但每个结构多了一个多头注意力机制(中间那个)。这个模块是对编码器的输出执行的。此外,最下面那个多头注意力模块也被修改了:只对前面的输出执行自注意力机制,而与其后的输出无关。修改方式就是masked。
3.1 注意力机制详解
注意力机制的本质很简单:输入query和一组键-值对;输出被加权组合的值;权值通过query和键的兼容函数计算得到。
3.1.1 放缩的点积注意力机制
作者称提出的注意力机制为:放缩的点积注意力(scaled dot-product attention)。如图左:
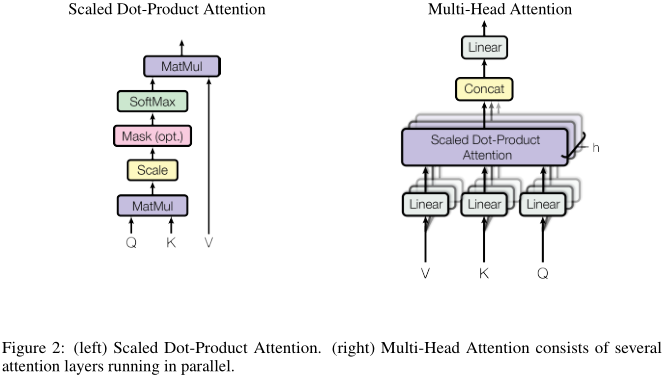
query和key点乘,再除以根号下512(放缩),经过softmax后与value相乘,就完成了注意力加权流程。
实操中会将这个过程矩阵化,即先pack成矩阵\(Q\)、\(K\)和\(V\),然后计算:
除了这里用到的点积形式,还有一种常用的注意力策略:加性注意力。加性注意力(additive attention)只需要借助单层前向网络计算兼容函数。尽管理论上,加性注意力和点积注意力的计算复杂度接近,但由于矩阵操作有加速算法,因此点积注意力更高效。在性能上,当\(d_k\)较大时,点积注意力不如加性注意力。可能的原因是:当维度较高时,点积结果可能会很大(脚注4),因此softmax函数的梯度很小,导致训练困难。因此,我们将点积结果除以根号512。
3.1.2 多头注意力机制
我们总结一下上一节的放缩点积注意力机制:只有单个注意力函数,输入key和query,输出加权后的value。注意,输入、输出都是\(d_k = 512\)维。
除此之外,作者提出了更进一步的处理,如上图右:我们首先将value、query和key分别线性映射到\(d_k = 64\)、\(d_k\)和\(d_v = 64\)维,然后再通过上一节的注意力机制,处理得到\(d_v\)维的输出。该操作执行\(h = 8\)次,每一次的线性映射函数和注意力函数都不一样。最后,\(h\)个\(d_v\)维输出再经过一次线性映射,得到一个\(d_v\)维最终输出。这就是所谓的multi-head。
多头与之前的“单头”有什么进步呢?博主的想法:
-
不仅仅是对key、query进行综合处理,还对key、query和value进行单独处理。可能有一些key和query天生就很不引人关注。
-
执行了8次不同的“单头”,然后最终再加权组合每一次的结果。这实际上允许每一个注意力函数负责8个不同的表示空间。比如有的函数更注意主语,有的函数更注意动词等等。
-
由于每一次“单头”的维度都降低了,因此总体运算量并没有提高。
我们再回到第一张图。在Transformer中,作者有3处用到多头注意力:
-
编码器-解码器之间。query来自解码器的上一层,而key和value来自编码器输出。即:让解码器注意输入序列的每一个位置。这是典型的注意力机制。
-
编码器。此时,key、value和query都来自于上一层。即:让该层注意上一层的每一个位置。
-
解码器。此时,key、value和query都来自于上一层。即:让该层注意上一层的每一个位置。注意,我们不需要leftward的信息流,因此我们让相关的mask值为负无穷(完全无关)。
3.2 全连接网络
一个全连接网络包含两次映射,ReLU非线性化。输入、输出都是512维,隐含层维度是2048。
Embeddings不懂,不看了。
3.3 编码位置信息
由于Transformer不包含循环和卷积结构,因此我们要特别地编码位置信息。细节略。
其余部分略。
总的来说,谷歌一举打破了原来的固有模型:用RNN或CNN建模序列,而是直接用注意力机制建模序列。这种突破是本文最大的贡献。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号