Paper | LISTEN, ATTEND AND SPELL: A NEURAL NETWORK FOR LARGE VOCABULARY CONVERSATIONAL SPEECH RECOGNITION
LISTEN, ATTEND AND SPELL: A NEURAL NETWORK FOR LARGE VOCABULARY CONVERSATIONAL SPEECH RECOGNITION
本文提出了一个基于神经网络的语音识别系统List, Attend and Spell(LAS),能够将语音直接转录为文字。
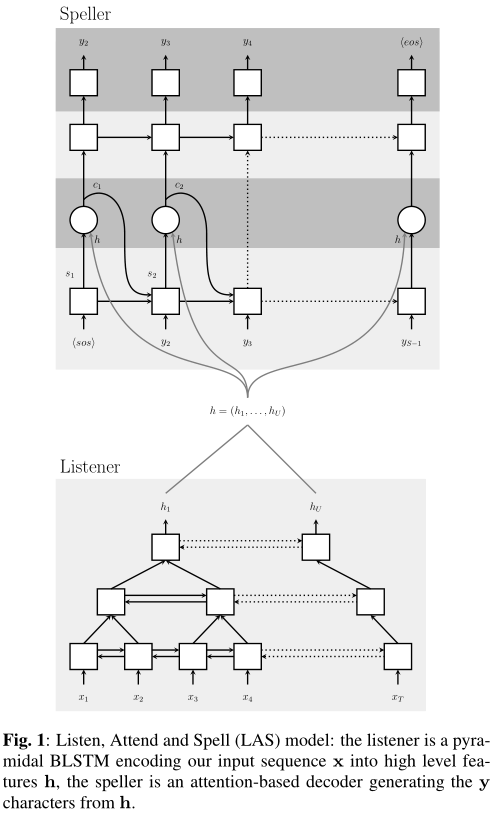
进步性:LAS将声学、发音和语言模型融合为一个神经模型,因此可以实现端到端。LAS只包含两部分:收听器(listener)和拼写器(speller)。收听器是一个金字塔循环网络编码器,拼写器是一个基于注意力机制的循环网络解码器。
1. 相关工作
当前最先进的语音识别器包含多个组分:声学模型、语言模型、发音模型和文本规范化模型。每个模型都有各自的假设和概率模型。也有工作尝试让这些组分联合训练,但一般是前端的声学模型会被迭代,后端的语言、发音和文本模型基本不变。
2. 方法细节
LAS的输入是一系列被过滤出来的bank spectra特征,输出是一系列字母、数字、标点符号、语气或未知符号。
LAS的基本方法是:在收听器,声音信号被编码为特征;拼写器根据 特征 以及 过去所有时刻的输出,依照条件概率的链式法则,来推断输入和输出符号之间的条件概率,然后选择条件概率最大者作为输出。
核心公式就是两个:
从图上就能观察出这两个公式。
2.1 收听器
整体框架如图,是一个金字塔形的多层双向LSTM结构。为什么不直接用LSTM呢?作者发现BiLSTM收敛巨慢无比,而且效果还不好。【看来应该是因为时间步太多导致收敛慢,因为每个时间步的输入差异大。因为有些句子单词很多】
在这个金字塔形BiLSTM中,每层的时间步数目会依次减半。实验中设了3层BiLSTM。
2.2 注意力和拼写
这里采用的是结合了注意力机制的单向LSTM。如图:
-
每一时刻的上下文向量由 特征向量 和 该时刻的状态向量 共同决定的:
\[c_i = \text{AttentionContext} (s_i, \mathbf{h}) \] -
每一时刻的状态向量由 上一时刻的状态向量、上一时刻的输出 和 上一时刻的环境向量 共同决定:
\[s_i = \text{RNN} (s_{i-1}, y_{i-1}, c_{i-1}) \]
那么具体这个上下文是怎么算的呢?其实是简单的加权组合:
\(h_u\)就是第\(u\)个特征。而权重\(\alpha_{i,u}\)是将\(s_i\)和\(h_u\)分别输入MLP后,算内积得到的。注意最后所有的\(\alpha_{i,u}\)要输入softmax归一化。
在训练后,\(\alpha_{i,u}\)通常会收敛到某些\(u\)附近,即只与少数的\(h_u\)有关。
其他细节就不管了,因为我们也不做这个。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号