《DEEP LEARNING》
《DEEP LEARNING》
- 《DEEP LEARNING》
- 1. 引言
- 2. 线性代数
- 3. 概率与信息论
- 4. 数值计算
- 5. 机器学习基础
- 6. 深度前馈网络
- 9. 卷积网络
- 10. 序列建模:循环和递归网络
- 11. 实践方法论
1. 引言
1.1 什么是、为什么需要深度学习
人工智能的困处:
-
那些对人类智力而言非常难的问题,特别是可以通过一系列形式化的数学规则描述的问题,对人工智能而言非常简单,可以迅速解决。
-
而那些对人而言很容易执行、但很难形式化描述的任务,对计算机而言就特别困难。比如语音识别,人脸识别,人类可以通过直觉轻松解决。
本书对此解决方案:
让计算机从经验中学习,避免人类提供形式化的知识。允许计算机基于简单的概念,构建相对复杂的层次化概念,从而得到一张“深”(层次多)的图。这种方法又称为AI deep learning。
1.2 简单的机器学习算法对数据表示的依赖
简单的机器学习算法的性能,很大程度上依赖于给定数据的representation。
例如,一个逻辑回归算法,用于判断产妇是否适合剖腹产。算法无法直接检查产妇再提供建议,而是必须由医生输入一系列数据:产妇是否有疤痕,是否患病等等。
对表示的依赖在科学问题中很普遍,但也是一个很棘手的问题。
-
P2图例中,利用极坐标表示数据,问题变得极其简单。
-
合适的特征很难选择。我们希望分离出数据的factors of variation,比如汽车图片中的观测视角、日夜光强变化等。因此特征往往是高层次且抽象的。
因此,机器不仅学习如何从输入映射到输出,还要学习自我发掘特征。这种方法又称为representation learning。而深度学习,有助于解决:表示学习解决特征难的问题。
不同AI学科的包含关系(P6):AI > 机器学习 > 表示学习 > 深度学习
-
AI还包括基于规则的系统,不需要特征和学习,计算即可。
-
机器学习还包括经典的机器学习,即特征是人工设计好的。而表示学习可以学习特征。
1.3 深度学习的历史趋势
最早的人工神经网络:旨在模拟生物学习的计算模型
20世纪40年代到60年代,深度学习的雏形出现在控制论cybernetics。
从神经科学的角度出发,人们设计了简单的线性模型:用n个输入及其权重,表示一个输出:
20世纪50年代,感知机成为第一个能根据不同类别的输入样本,自动学习权重的模型。
大概同一时期,adaptive linear element(ADALINE)也出现了。其权重的训练算法是随机梯度下降法stochastic gradient descent,至今仍是重要的深度学习训练算法。
上述模型称为linear model。线性模型有很多问题,最大的问题就是无法表示亦或XOR关系。这一缺陷使得神经网络大受批评,神经网络热潮第一次衰退。
如今,神经科学被视为深度学习的灵感源泉之一,但绝不是刚性指导。其核心问题在于,我们对大脑的理解太少太少了。现代深度学习更多地从线性代数、概率论、信息论等寻求灵感。
当然,神经科学不是一无是处。比如,神经科学佐证了一点:单一深度学习算法可以解决多个不同的任务。神经学家把雪貂大脑的视觉信号传到听觉区域,发现雪貂会逐渐得到视觉。
神经网络第二次浪潮:联结主义(connectionism)
20世纪80年代,神经网络研究的第二次浪潮,很大程度上是伴随着connectionism或并行分布处理parallel distributed processing的潮流而出现的。
联结主义是在认知科学的背景下出现的。认知科学是理解思维的跨学科领域,即具有多种不同的分析层次。其中心思想是:当网络将大量简单的计算单元连接在一起时,可实现智能。
20世纪80年代初期,大多数认知科学家研究符号推理模型。由于符号模型很难解释大脑如何利用神经元实现推理功能,因此科学家转向研究基于神经系统实现的认知模型。
在此期间形成了至今重要的关键概念和成果:
-
分布式表示(distributed representation)
系统的每一个输入都应该由多个特征表示;每一个特征都应该参与到多个可能输入的表示中。
比如,我们希望识别红色、绿色或蓝色的汽车、鸟类和卡车。最直接的想法是:设计9个神经元,分别学习红卡车、红汽车、绿鸟等。但从分布式的角度出发,既然有6个特征,那么我们只需要设计6个神经元,红色、汽车神经元都从红汽车图片中学习。
-
反向传播算法
-
20世纪90年代产生的Long Short-Term Memeroy(LSTM),在序列建模方面很强大。其应用在Google的自然语言处理任务等。
90年代中期,投资者发现AI并没有实现期望的效果。同时,机器学习的其他领域(非神经网络),如核方法和图模型,都产生了较好的效果。这两个因素导致了神经网络热潮的第二次衰退。
神经网络的突破
2006年,Hinton证明,一种名为“深度信念网络”的神经网络,借助“贪婪逐层预训练”的策略,可以有效地训练;其他研究者证明,该策略还可以用来训练许多其他类型的深度网络,并能显著提高在测试样本上的泛化能力。
此时,深度神经网络的性能已经显著优于其他机器学习方法以及手工设计的AI系统。
2. 线性代数
线性代数本质可视化视频:《线性代数的本质》 ,B站有全集。
线性代数教材推荐:《工程数学线性代数(第六版)》。
线性代数公式索引册推荐:《The Matrix Cookbook》。
2.1 标量、向量、矩阵和张量的一般表示方法
-
标量scalar:斜体小写
\[x \] -
向量vector:粗体斜体小写
\[\boldsymbol x \] -
矩阵matrix(二维数组):粗体斜体大写
\[\boldsymbol A \] -
张量tensor(多维数组):粗体大写。
\[\mathbf A \]
2.2 矩阵和向量的特殊运算
-
在深度学习中,我们允许矩阵和向量相加,产生一个新的矩阵。本质上是矩阵的每一行都和向量相加。这种简写方式称为广播broadcasting。
-
两个矩阵的对应元素相乘element-wise product,称为Hadamard product。
-
两个相同维数向量的乘法:点积dot product。
2.3 线性相关和生成子空间
方程的解问题
设线性方程组:
其中\(\boldsymbol A\)是m×n矩阵,\(\boldsymbol b\)是m×1的列向量。
我们来看看,这个方程何时有解,能有多少解。
把矩阵\(\boldsymbol A\)看作是n个列向量的组合(因为有n个未知数,相当于解n元方程组),那么\(\boldsymbol A\)就相当于对这n个向量的加权组合,即linear combination。
换一个角度看,就相当于求一个点的坐标;该点的行进路线是由这些向量组合而成的。
这些列向量线性组合后,所能抵达的所有点的集合,称为生成子空间span,又称为\(\boldsymbol A\)的列空间column space或\(\boldsymbol A\)的值域range。
思路
此时,求解\(\boldsymbol {Ax = b}\),就相当于在\(\boldsymbol A\)的列空间中,查看是否存在该点\(b\):
-
首先,列空间的维数显然不能\(<\boldsymbol b\)的维数n,否则是无解的。
要注意,n和m与维数无关。有一些列向量可能是冗余的,可以通过其余列向量线性组合而成。这种冗余称为线性相关linear dependence。 -
其次,如果列空间的维数 \(\geq\) n,则有解。如果是严格>,则有无穷个解。比如在三维空间中,最多需要3个列向量就可以组合出到达某一点的路径;因此提供大于3个列向量时(rank=3,因为是三维空间中的),会有无数种选择,类似于你多0.1,我少0.5。
结论
-
当且仅当:\(rank\boldsymbol A \geq n\) 时,\(x\)有解。由于\(\boldsymbol A\)是mxn矩阵,其中n是变量数,一般是固定的,因此rank最多为n(满秩)。
-
\(rank\boldsymbol A = n\),有解且只有一个解。因为列空间与检测点等维数。
-
\(rank\boldsymbol A < n\), 无解。不可能在低维空间中找到高维点。特别地,对不满秩的方阵,我们称之为奇异singular矩阵。
-
当然,我们可以构造一个更高维数的矩阵A和较低维数的点b。这样会导致无穷多解,原因在上面,满足x和y特征的点,其z特征可以任意。
反证法可以证明:不存在多于一个解但少于无穷个解的情况。
因为如果x1是解,x2是解,那么它们俩的任意互补组合:\(z=ax_1+(1-a)x_2\)还是解。
求解方式
如果\(\boldsymbol A\)是一个方阵square,我们可以用求逆矩阵的方法,得到方程解:
如果不是方阵,那么不能用求逆法求解。
2.4 范数(norm)
定义和要求
norm函数,是将向量映射到非负值的函数。当我们衡量一个向量的大小时,就会用到norm。\(L^P\)范数定义如下:
严格地说,范数是满足下列性质的任意函数:
-
\(f(\boldsymbol x) = 0 \Rightarrow \boldsymbol x = \boldsymbol 0\)
-
triangle inequality: \(f(\boldsymbol {x + y}) \leq f(\boldsymbol x) + f(\boldsymbol y)\)
-
\(\forall \alpha \in \mathbb R, f(\alpha \mathbf x) = \vert \alpha \vert f(\boldsymbol x)\)
常用的\(L^2\)范数和平方\(L^2\)范数
\(L^2\)范数即欧几里得范数Euclidean norm,表示从原点出发(所有范数都如此),到向量确定的点的欧几里得距离。
由于使用得极其频繁,因此常省略下标表示为\(\Vert \boldsymbol x\Vert\)。
我们经常忽略\(L^2\)范数的开根号,得到更常用的平方\(L^2\)范数。其优势在于:
-
一个向量的平方\(L^2\)范数,可以通过向量自身的dot product实现,非常简单。
-
范数中任意元素\(x_i\)的导数,只与\(x_i\)自身有关。如果是\(L^2\)范数,则与所有元素有关。
但在很多情况下,平方\(L^2\)范数也可能不受欢迎,原因是它在原点附近增长的非常缓慢(二维平面中的抛物线原点,三维平面中的抛物面原点)。
更好的\(L^1\)范数和其他特殊范数
为此,我们使用形式更简单、各处斜率相同的\(L^1\)范数:
在机器学习问题中,如果零和非零元素的差异(之间的较小的值)很关键,那么通常使用\(L^1\)范数。
我们还常用\(L^\infty\)范数,即最大范数max norm。该范数表征向量中最大绝对值的元素:
有时我们也希望衡量矩阵大小,最常见的做法是Frobenius norm,类似于向量的\(L^2\)范数。
2.5 特殊的矩阵和向量
对角矩阵和对称矩阵(方阵)
对角矩阵diagonal matrix(通常指方阵):只在对角线上含非零元素,用\(diag(\boldsymbol v)\)表示。
对角矩阵的优点:
-
乘法计算非常高效。\(diag(\boldsymbol v)\boldsymbol x = \boldsymbol v \bigodot \boldsymbol x\),即\(\boldsymbol x\)中每一个元素\(x_i\)放大\(v_i\)倍。
-
逆矩阵计算简单。首先,当且仅当对角元素全部非零时,对角矩阵可逆。此时,逆矩阵为\(diag([1/v_1,1/v_2,...,1/v_n]^T)\)
如果我们能将机器学习算法中的某些矩阵限制为对角矩阵,那么计算代价会很低。
当然,也存在非方阵的对角矩阵。这种矩阵没有逆矩阵,但计算仍是高效的:\(\boldsymbol {Dx}\)也是对\(\boldsymbol x\)中的元素进行缩放,只不过可能在末尾添0,或删掉一些结果。
对称sysmmetric矩阵:转置等于自己。
当某些不依赖参数顺序的双参数函数生成元素时,对称矩阵经常出现。
例如距离矩阵,显然距离函数是对称的。
标准正交向量
单位向量unit vector:具有单位范数的向量,即:
如果两个向量点积为0,那么两个向量互相正交orthogonal。
显然零向量和任意向量都正交。
如果两个向量都有非零范数,那么它们的夹角为90°。
在\(\mathbb R^n\)中,最多可以有n个范数非零向量相互正交。
如果这些相互正交的向量的范数都为1,那么它们就是标准正交的orthonormal。
我们超爱标准正交基!
首先,空间中任意一个向量都能表示成标准正交基的线性组合:
其次,每一个坐标都可以用点积快速求出:
因此,我们给向量空间取基底时,常常取标准正交基。
BIG BOSS:正交矩阵
正交矩阵orthogonal matrix:方阵,其行、列向量分别都是标准正交的。即有:
这意味着其具有一个超强性质:
其求逆代价更小。
最后,由正交矩阵\(\boldsymbol P\),可以得到正交变换:\(\boldsymbol {y = Px}\)。正交变换前后,向量的范数不变。
2.6 特征分解
什么是特征分解
特征分解eigendecomposition:把矩阵分解为一组特征向量和特征值;是使用最广的矩阵分解方法之一。
方阵\(\boldsymbol A\)的特征向量eigenvector $\boldsymbol v $:矩阵对该向量的作用效果为缩放:
其中\(\lambda\)称为特征向量$\boldsymbol v $对应的特征值eigenvalue。
上式意味着什么呢?
我们首先要知道,一个矩阵代表着一种线性变换。一个vector右乘一个matrix,将会得到一个新的vector。
特征向量,即在该线性变换的作用下,只做伸缩的vector。
求解特征方程(eigenvector)
如果我们把右边移到左边,就会得到:
我们知道,对某个给定的eigenvalue \(\lambda\),要存在非全零的eigenvector \(\boldsymbol v\),就要求\((\boldsymbol A -\lambda \boldsymbol I)\)行列式为0。
因为如果满秩,给定一组非全零的权重\(\boldsymbol v\),是不可能走到原点的。
换句话说,要想存在非全零的eigenvector,就要求eigenvalue必须满足下面的特征方程:
左边称为\(\lambda\)的特征多项式。
因此:
-
特征方程的解\(\lambda\)就是eigenvalue。
-
再求解$ (\boldsymbol A -\lambda \boldsymbol I) v = \mathbf 0$,就可以求出eigenvector了。
最后注意几点:
-
特征方程在复数范围内恒有解,解的个数取决于\(\boldsymbol A\)的维数。
-
通常我们只考虑单位特征向量。因为如果\(\boldsymbol v\)是\(\boldsymbol A\)的eigenvector,那么其任意非零缩放还是eigenvector。
-
我们通常只需要考虑实对称矩阵,其可以分解为实特征向量和实特征值。
复数特征值是非常不直观的。比如矩阵:
特征方程为\(\lambda^2+1=0\),没有实数解。
该变换的本质是旋转90度,显然不存在只放缩不旋转的特征向量。复数特征值无特征向量对应。
值得注意的是,如果特征值出现复数,往往意味着在变换域上产生了旋转。
相似
设n阶矩阵\(\boldsymbol A\)和\(\boldsymbol B\)。若存在可逆矩阵\(\boldsymbol P\),使得:
则称\(\boldsymbol A\)和\(\boldsymbol B\)相似。
性质:特征多项式相同,特征值相同。
对角化
假设一个n阶矩阵\(\boldsymbol A\)相似于一个对角阵\(\boldsymbol \Lambda\)。那么就有:
把\(\boldsymbol P\)按列向量写成\(\boldsymbol {(p_1,p_2,...,p_n)}\)的形式,则有:
这说明:对角阵\(\boldsymbol \Lambda\)对角线上的元素是特征值,而\(\boldsymbol P\)列向量就是对应的特征向量!
注意:虽然有且仅有n个特征值和特征向量,但特征值是唯一的(特征方程的n个解),特征向量不是唯一的。因此矩阵\(\boldsymbol P\)不唯一。
这说明了矩阵分解的一大好处:如果对角阵存在一个零特征值,由于相似前后特征值不变,那么原矩阵就是奇异的。
进一步,什么时候能对角化呢?
只要\(\boldsymbol A\)有n个线性无关的特征向量,那么\(\boldsymbol P\)就是可逆的(存在且满足要求),就能对角化!这是充要条件。
当然,特征值互不相等也可以对角化,由定理2可以推出特征向量线性无关。
特殊地,如果特征方程有重根,则不一定能对角化。
因为可能找不到n个线性无关的特征向量(有可能找得到)。例子参见教材P138例11。
最后,当存在0特征值时,为什么还能对角化?
-
假设存在n个互不相同的特征值。
-
首先,存在n个互不相同的特征值,可证明n个eigenvector线性无关,因此可逆的P矩阵存在,可对角化。
-
其次,存在0特征值,只能说明Ax=0。为了保证线性无关,eigenvector: x必须是非零向量。
因此A一定是不满秩的,仅此而已。但这不影响\(A-\lambda I\)满秩,其特征方程仍有n个不同的解。本质上,存在0特征值,说明A作用在某些x(eigenvector)上时,其效果为维数坍塌,直接变成0。原因正是A不满秩。
对称矩阵的对角化
由上一节,不是所有矩阵都可以进行特征分解。有一些分解涉及复数,也不好处理。
我们通常只需要考虑实对称矩阵,其有以下特殊性质:
-
可以分解为实特征向量和实特征值。
-
两个不相等的特征值对应的特征向量一定正交。
-
设\(\boldsymbol A\)为对称阵。则一定存在正交矩阵\(\boldsymbol Q\)使其相似到对角阵。
\[\boldsymbol A = \boldsymbol Q \boldsymbol \Lambda \boldsymbol Q^T \]
其中:
-
\(\boldsymbol Q\)是\(\boldsymbol A\)的eigenvector组成的正交矩阵,逆等于转置。
-
\(\boldsymbol \Lambda\)是对角矩阵,对角元素由特征值组成。
按照惯例,我们通常降序排列\(\boldsymbol \Lambda\)中的特征值。
正定
如果\(\boldsymbol A\)的所有特征值都是正数,那么\(\boldsymbol A\)就是正定的positive definite。
当然还可以定义半正定positive semidefinite,负定negative definite和半负定。
正定矩阵也可以这么定义:
以上定义是等价的,可证,都是充要条件。
当然在原点处是0:
半正定矩阵有时候很有用,因为存在下面的性质:
2.7 奇异值分解
奇异值分解singular value decomposition SVD是另一种矩阵分解方法。
其目标是把矩阵分解为奇异值singular value和奇异向量singular vector。
优势:每个实数矩阵都有一个奇异值分解,但不一定都有特征分解,如非方阵。
假设\(\boldsymbol A\)是一个\(m×n\)矩阵,那么可以分解为:
其中:
-
\(\boldsymbol U\)是一个\(m×m\)正交矩阵,列向量称为\(\boldsymbol A\)的左奇异值。
-
\(\boldsymbol D\)是一个\(m×n\)对角矩阵(不一定是方阵),对角线上的元素称为\(\boldsymbol A\)的奇异值。
-
\(\boldsymbol V\)是一个\(n×n\)正交矩阵,列向量称为\(\boldsymbol A\)的右奇异值。
事实上:
-
\(\boldsymbol A\)的左奇异值是\(\boldsymbol {AA^T}\)的特征向量。
-
\(\boldsymbol A\)的右奇异值是\(\boldsymbol {A^TA}\)的特征向量。
-
\(\boldsymbol A\)的非零奇异值是\(\boldsymbol {A^TA}\)的特征值的平方根,也是\(\boldsymbol {AA^T}\)的。
2.8 伪逆(Moore-Penrose)
我们希望求解:
如果\(\boldsymbol A\)的行数大于列数,那么方程可能无解。
假设是线性无关的,那么空间维数不足,寻求的点却是高维的,那么肯定无解。
如果反过来,那么上述矩阵可能有多个解。
假设是线性无关的,那么在高维空间中找一个低维点,肯定有无穷解。
伪逆定义见P28。说白了就是寻找\(\boldsymbol A\)的映射\(\boldsymbol B\),可以通过下面的方式求解:
伪逆具有以下性质:
-
如果\(\boldsymbol A\)的行数大于列数,那么通过伪逆求得的方程解,是最接近等号的。
-
如果\(\boldsymbol A\)的行数小于列数,那么伪逆求法只不过是众多方法中的一种。但求出的x是所有可行解中,\(L^2\)范数最小的。
2.9 迹运算和行列式
迹运算:返回矩阵对角元素之和。迹运算的性质见P29。
行列式:其绝对值可以衡量矩阵参与乘法后,空间扩大或缩小了多少。
2.10 应用:主成分分析PCA
参见我的博文:离散K-L变换
3. 概率与信息论
概率论是用于表示不确定性声明的数学框架。
它不仅提供了量化不确定性的方法,也提供了用于导出新的不确定性statement的公理。
不确定性来源于3个方面:
-
被建模系统内在的随机性。
-
不完全观测。
-
不完全建模。
有时候,使用一些简单而不确定的规则,要比复杂而确定的规则更为实用。复杂的规则可能难以维护、应用和沟通。
3.1 随机变量(random variable)
-
我们常用无格式字体中的小写字母,来表示随机变量random variable,如\(\mathrm x\)
-
用手写体中的小写字母,来表示随机变量的取值,如\(x_1,x_2\)
-
用粗体表示向量值随机变量:\(\boldsymbol x_1\)是\(\mathbf x\)可能的取值。
3.2 概率分布(probability distribution)
离散型随机变量的概率分布,通常用概率质量函数probability mass function(PMF)描述。
我们常用一个大写的\(P\)表示。要注意,\(P(\mathrm x)\)和\(P(\mathrm y)\)往往不是同一个函数(尽管函数名相同),因为随机变量不一样。
更多时候,我们用\(P(x)\),来表示\(\mathrm x = x\)的概率。
联合概率joint probability distribution:\(P(\mathrm x = x , \mathrm y = y) = P(x,y)\)
连续性随机变量的概率分布,通常用概率密度函数probability density function(PDF)描述。
\(p(x)\)没有直接给出概率;某一点\(x\)的概率要通过\(p(x)\delta x\)得到。
当我们只知道一组变量的联合概率分布时,可以通过边缘概率分布marginal probability distribution,了解其中一个子集的概率分布。
3.3 条件概率的链式法则
chain rule or product rule:
3.4 独立性和条件独立性
若:
则称这两个随机向量independent,表示为\(\mathrm x \bot \mathrm y\)。
条件独立性conditionally independent见P38。
3.5 期望、方差和协方差
期望expectation or expected value:加权平均
方差variance:\(Var(f(x)) = E[(f(x)-E[f(x)])^2]\)
方差小,意味着变量取值簇比较接近期望值。
标准差standard deviation:方差的平方根
协方差covariance: \(Cov(f(x),g(x)) = E[(f(x)-E[f(x)])(g(x)-E[g(x)])]\)
协方差的绝对值如果很大,则意味着变量值变化较大,并且离各自均值较远。
如果为正,那么都倾向于同时取得较大值;如果为负,则反向变化,一个倾向于较大,另一个倾向于较小(和期望比)。
若两个变量协方差为0,只能说明没有线性关系,因此一定不相关,但不一定独立。
反过来,协方差不为0,一定是相关的。
相关系数correlation:将每一个变量的贡献都归一化,在忽略各变量尺度大小的前提下,衡量相关性。
3.6 常用概率分布
Bernoulli distribution
单个二值随机变量的分布。
Multinoulli distribution
又称为范畴分布categorical distribution,是指一个具有k个不同状态的离散型随机变量的分布。
它由向量\(\boldsymbol p \in [0,1]^{k-1}\)表示,分量\(p_i\)表示第\(i\)个状态的概率。
实际上,multinoulli distribution是多项式分布multinomial distribution的特例。
多项式分布中,\(\boldsymbol p \in \{0,1,...,n\}^k\),分量\(p_i\)表示采样\(n\)次后,第\(i\)个类别被访问的次数。
显然,只采样1次,就是范畴分布。
高斯分布(normal distribution or Gaussian distribution)
为了方便求值,我们通常用另一种形式:
其中\(\beta\)是方差的倒数,恒为正。
当我们缺乏分布的先验知识时,正态分布通常是比较好的选择,原因如下:
-
现实中大部分建模对象满足正态分布。中心极限定理central limit theorem说明,大量独立随机变量的和近似服从正态分布。
-
在具有相同方差的所有概率分布中,正态分布在实数上具有最大不确定性。
多维正态分布见P41。
指数分布(exponential distribution)
指数分布限定在非负区间,即在\(x=0\)处取得边界点sharp point,因此常用。
当\(x<0\)时,概率为零。写法上可以采用指示函数indicator function。
Laplace分布
见P42,形似指数函数,但其峰值可任意指定,且无边界点。
Dirac分布和经验分布
Dirac分布借助Dirac delta function,把所有概率质量都集中在了点\(\mu\):
我们之前学习过多项式分布,即每一点的值,代表的是采样n次后,各自被访问的次数。
对于连续型随机向量,我们也可以用类似的分布,即经验分布empirical distribution。
比如每一点的概率都是\(\frac{1}{m}\),共\(m\)个点\({\boldsymbol x^{(i)}}\):
两个意义:
- 指明了采样源的分布
- 是训练数据的似然最大的概率密度函数,即交叉熵公式中的正确概率分布\(p\)
分布的混合
我们可以利用简单分布组合出新的分布。最常见的组合方法是构造混合分布mixture distribution,也是我们熟知的一个公式:
每一个\(P(c=i)P(\mathrm x | c=i)\)都称为一个组件component。
这里的\(P(c)\)服从Multinoulli分布,每次实验,都相当于从Multinoulli分布中采样。
\(c\)实际上是一个潜变量latent variable,在后面会学。
一个非常强大且常见的混合模型是高斯混合模型Gaussian Mixture Model,其组件均为高斯分布。
每个组件的参数(均值,协方差矩阵)可以不同,当然也可以互相约束。
高斯混合模型是概率密度的universal approximator,可以近似任何平滑的概率密度,只要组件足够多。
例如P43图,图中3种样本可以用3个组件来近似组合。并且,通过构造协方差矩阵,3块样本的方差展示特点和控制特点各有不同。
说白了,不管原样本概率分布如何,我都能用高斯混合模型,来近似模拟样本的原始分布。
3.7 常用函数的性质
Logistic sigmoid function
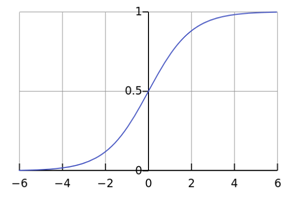
优点:取值在0和1之间,可以产生概率值
缺点:变量绝对值非常大时,取值会出现饱和saturate现象,变化非常平缓
重要性质:
该反函数在统计学中称为分对数logit,在机器学习中较少用。

Softplus function
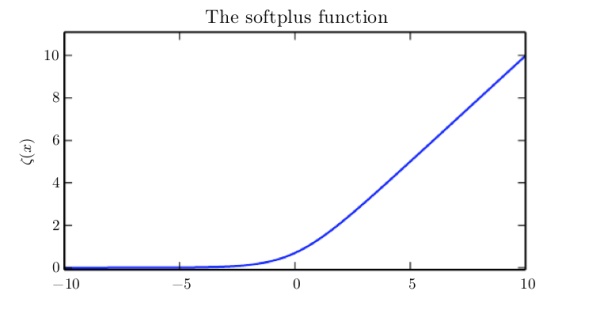
优点:取值恒为正,可以产生正态分布的\(\sigma\)和\(\beta\)
重要性质:
实际上,softplus函数是正部函数positive part function的平滑(软化):
当然也可以用正部和负部函数来恢复\(x\):
3.8 连续型变量的技术细节
连续性随机变量和概率密度函数的深入理解,需要用到测度论measure theory。详情见P46。
3.9 信息论
在机器学习中,我们常用奈特和自然对数,求导方便。
注意!!!我们学习过联合熵和交叉熵神似,但完全不是一个概念!!!
可以参考这个回答。
\(H(P)\)是真实分布本身的熵,\(H(P,Q)\)是用假设分布\(Q\)来表示真实分布\(P\)导致的熵:
\(H(P,Q)\)就是交叉熵cross-entropy。
因此我们不妨作差,差值就代表了二者的差异。我们定义其为KL散度Kullback-Leibler divergence:
如果一个随机变量\(\mathrm x\)有两个单独的概率分布\(P(\mathrm x)\)和\(Q(\mathrm x)\),则可以使用KL散度来衡量这两个分布的差异。
KL散度又称为相对熵。
性质:
-
非负
-
当且仅当P和Q相等时,KL散度为0。
-
KL散度是不对称的,因为加权系数为\(P(x)\)。
因此它被用作“距离”,但不是严格意义上的距离,因为非对称。
我们从训练效果上,观察其非对称性。
假设我们的目标分布为\(p(x)\),但得到的分布(用于近似的)是\(q(x)\)。
我们可以选择最小化\(D_{KL}(p||q)\),也可以选择最小化\(D_{KL}(q||p)\),但效果是不一样的。
假设\(p(x)\)是两个高斯分布混合,\(q(x)\)是单个高斯分布。
如P48图:
-
如果最小化\(D_{KL}(p||q)\),那么由于系数\(p(x)\)有两个峰,因此在这两处\(q(x)\)也会被迫趋于峰值,使得\(\log{\frac{p(x)}{q(x)}}\)趋于0。由于\(q(x)\)是单峰分布,因此会呈现出如图的效果,屹立在中央。
-
如果最小化\(D_{KL}(q||p)\),注意,\(p(x)\)是固定的,\(q(x)\)才是可变的,因此系数\(q(x)\)被迫在\(p(x)\)某个单峰处也得到峰值,而在其余处趋于0,强迫\(q(x)\log = 0\)。
通常“相对熵”也可称为“交叉熵”,因为真实分布P是固定的,D(P||Q)由H(P,Q)决定。
当然也有特殊情况,彼时2者须区别对待。
4. 数值计算
4.1 上溢和下溢
连续数学在计算机上实现的根本问题是:表示无限多位实数的位模式是有限的,因此我们总会引入近似误差。
近似误差往往是舍入误差,有以下两大致命情况:
- 下溢underflow
比如接近零的正数,被四舍五入为零。
这很有可能导致某个函数发生质变,如log函数,会得到负无穷的错误结果;或者是除零错误等。 - 上溢overflow
把一个较大的数变成了正无穷或其他非数字,如NaN
例如:
如果某个\(x_i\)特别大,会导致计算分子时就overflow,整个表达式未定义。
如果分母特别小,导致underflow,会发生除零错误,即又未定义。
最简单的数值稳定方法是:令
这样一来,一定存在一个\(x_i\)为0,且最大的\(x_i\)就是0。
首先分子不大,因此不可能overflow;其次分子一定有一个\(\exp(0)=1\),因此也不会underflow。
4.2 基于梯度的优化方法
梯度Gradient和Jacobian Matrix
首先我们看维基百科的定义:
In mathematics, the gradient is a multi-variable generalization of the derivative. While a derivative can be defined on functions of a single variable, for functions of several variables, the gradient takes its place. The gradient is a vector-valued function, as opposed to a derivative, which is scalar-valued.
-
梯度是一个多变量的generalization,整合的是导数(单变量的梯度就是导数)。
-
梯度的function value是一个向量,而导数是一个标量。
其定义如图:

the gradient points in the direction of the greatest rate of increase of the function, and its magnitude is the slope of the graph in that direction.
-
梯度的方向,是该函数增长率最大的方向;梯度的大小,就是该方向的导数(变化率)。
这一点在下一节,结合方向导数解释。
The gradient can also be used to measure how a scalar field changes in other directions, rather than just the direction of greatest change, by taking a dot product.
-
借助(和某方向上的单位向量的)点积,我们可以得到其他方向的变化率。这就是我们下一节要介绍的。
The Jacobian is the generalization of the gradient for vector-valued functions of several variables and differentiable maps between Euclidean spaces.
-
Jacobian是梯度的泛化,或者说梯度是Jacobian的特例。Jacobian适用于向量值的多变量函数,也可以理解为不同欧式空间的映射因子。

方向导数(directional derivative)
我们现在说明:为什么梯度指向增长最快的方向。这也将揭示梯度下降法的合理性。
首先,梯度的模值表征变化率,这一点比较好理解。
如果是单变量的导数,显然导数就是变化率,即\(\frac{\Delta y} {\Delta x}\);如果是多变量,那么相当于路径合成,也就是向量取模,即梯度的大小。
其次,其余方向上的变化率,需要用方向导数directional derivative来表示,其求法是点积。
以二维平面为例,我们已经求出了梯度\(\nabla f\),也就求出了\(\frac{\partial f}{\partial x}\)和\(\frac{\partial f}{\partial y}\)。
如果我们希望求出某个方向\(\boldsymbol u = (\cos \alpha , \sin \alpha)\)上的变化率,由路径合成,即:
那么,该值什么时候最大,什么时候最小呢?显然,由点积的几何意义:投影,当\(\boldsymbol u\)和\(\nabla f\)同向时,增长率最大,且刚好就是\(\vert \nabla f \vert\);当\(\boldsymbol u\)和\(\nabla f\)反向时,增长率负最大,即下降率最大。
因此,我们在funciton的负梯度方向上移动其自变量,可以以最快速度降低function value。
这就是最快下降法method of steepest descent或梯度下降法gradient descent的核心思想。
梯度下降法(gradient descent)
要注意,梯度的大小指明了function value的增长率,但并没有指示自变量如何变化。
我们可以借助梯度大小,同时赋予一个系数:学习率learning rate:
学习率有以下几种取法:
-
小常数
-
计算刚好使方向导数消失的步长
-
线搜索:选择几个数,采纳其中能使function value最小的那个步长
当存在多个局部极小点或平坦区域时,优化算法可能无法找到全局最小点。
在深度学习中,即使某个解非全局最小,但只要对应的代价函数足够小,我们通常就能接受。
最后注意,深度学习中的计算,通常是以迭代更新解的估计值的形式实现的,而不是通过解析过程推导出正确解。
尽管在有些情况下,我们可以直接求解梯度为0的点。
梯度下降法可以推广到离散空间,即hill climbing算法。
4.3 Hessian Matrix
二阶导数的意义
在介绍Hessian Matrix之前,我们先看看二阶导数的意义。
二阶导数确定函数在某一点的曲率curvature,见P56图。
曲率可以帮助我们调整学习率。
如果曲率为负,则函数曲线表现为上凸,梯度下降得比预期快。预期下降率就是学习率;
如果曲率为正,即\(\frac{\partial^2 f}{\partial x^2} > 0\),函数曲线表现为下凸,则说明函数即将到达局部极小值点,那么学习率不能过大,否则function value可能会到右侧,即反倒变大了。
Hessian Matrix的定义
梯度的Jacobian矩阵,即二阶导数的generalization,称为Hessian矩阵。

一定要注意,Hessian矩阵是对一个标量值函数求二阶导的结果,而Jacobian矩阵是对一个向量值函数求一阶导的结果。
请理解上述定义。比如,我们把梯度看作是一个向量值函数,输入为向量:\(\boldsymbol x = [x_1,...,x_n]\),输出还是向量:\([\frac{\partial f}{\partial x_1},...,\frac{\partial f}{\partial x_n}]\),那么我们就可以对其求Jacobian Matrix,得到Hessian Matrix,即:
Hessian Matrix的应用一:Second partial derivative test
参见维基百科:Second partial derivative test
通过二阶导和Hessian矩阵的行列式,可以判断某个点是否为极值点或鞍点等。
正定可以通过特征值全为正来判断,这是特征分解的有一大用途。
至于能否特征分解?
微分算子在任何二阶偏导连续点处可交换顺序,即\(H_{i,j} = H_{j,i}\)。
在深度学习中,我们接触的大部分Hessian矩阵都是实对称的。
进一步,由于是实对称矩阵,我们可以对其进行特征分解,并且具有以下性质:
-
可以分解为实特征向量和实特征值。
-
两个不相等的特征值对应的特征向量一定正交。
Hessian Matrix的应用二:optimization
我们复习一下一元函数的泰勒展开。
设一元函数\(f(x)\)在包含点\(x_0\)的开区间\((a,b)\)内具有\(n+1\)阶导数,则当\(x \in (a,b)\)时,有:
其中
且\(\xi\)在\(x\)和\(x_0\)之间,称为拉格朗日余项。上式称为\(f(x)\)的n阶泰勒公式。
如果不需要余项的精确表达式,\(R_n(x)\)可以记为\(o[(x-x_0)^n]\),被称为皮亚诺余项。
现在我们推广到二元函数。
设二元函数\(z=f(x,y)\)在点\((x_0,y_0)\)的某一邻域内连续,且有直到\(n+1\)阶的连续偏导数,则有:
其中\(0<\theta<1\)。
上式同样采用了拉格朗日余项,也可以采用皮亚诺余项:
在进一步拓展,如果多元函数\(f(\mathbf X)\)的自变量是一个多维向量\(\mathbf{X}\),并且在点\(\mathbf{X_0}\)的邻域内有连续二阶偏导,那么该函数在该点处的二阶泰勒展开为:
其中,\(\nabla^2 {f(\mathbf{X}_0)}\)就是一个Hessian Matrix。
我们可以借助上式和海森矩阵,来预测梯度下降的表现。
将\(\boldsymbol x' = \boldsymbol x - \epsilon \nabla{f(\boldsymbol x)}\)代入得:
式中三项分别为:函数原始值、预期改善和函数曲率导致的校正。
校正项是关键,因为如果太大,会导致迭代效果反而变差。
如果第三项是正的,那么上述方程的最小值取在对称轴处(以步长为变量),即最优步长为:
Hessian Matrix的应用三:牛顿法Newton's method
我们先看P59图,这是一个梯度下降的典型路径。
由于梯度下降属于一阶优化算法first-order optimization algorithms,无法利用包含在H矩阵内的曲率信息,因此很有可能把大量的时间浪费在尽管最陡峭,但效率确不高的路径中。原因是步长有点大,一步迈到了对面去了。
那么我们怎么利用曲率信息,实现二阶优化算法second-order optimization algorithms呢?
既然我们都得到了邻域点的二阶泰勒展开近似:
我们就可以直接对其求解临界点(最小点),得到P58的\(\boldsymbol x^*\)表达式。
当然,如果function是全局正定的,那么我们一步就可以得到最优解;如果只是局部正定的,那么我们只能反复迭代,但仍比梯度下降更快。
需要反复迭代的原因,是我们可能停留在鞍点。其显著特征就是鞍点处H矩阵存在负特征值,因此非正定。
但梯度下降不会进入鞍点,因为还有更陡峭之处(除非梯度刚好指向鞍点,即对称下降)。
因此,牛顿法在接近局部极小值点时,是一个特别有用的方法,但在鞍点附近是有害的!
4.4 约束优化constrained optimization
有时候我们不希望直接最大化或最小化函数,而是在一定约束下操作。
严格地说,我们希望给\(\boldsymbol x\)划定一个可行域\(\mathbb S\),其中的点称为可行feasible点。
简单的方法:维持约束问题,把迭代的结果,投影回\(\mathbb S\);如果是线搜索,就在可行域中搜索。
复杂的方法:改变约束问题。
Karush-Kuhm-Tucker方法
我们引入generalized Lagrangianorgeneralized Lagrange function。
首先,我们要用等式和不等式,来描述\(\mathbb S\),包括等式约束equality constraint和不等式约束inequality constraint:
其次,我们为每一个约束,引入变量\(\lambda_i\)和\(\alpha_j\),称为KKT乘子。
因此generalized Lagrange function定义如下:
那么,如何通过广义拉格朗日方程,解决约束最小化问题呢?(后面讨论最大化问题)
我们转而求解下述问题:
该式与\(\min_{\boldsymbol x \in \mathbb S} {f(\boldsymbol x)}\)等价。
证明:
我们先迭代\(\alpha\)和\(\lambda\),得到最优的这两个参数;
然后再迭代\(\boldsymbol x\),目标是最小化广义拉格朗日方程。
现在我们说明,方程解将不会停留在不可行域!
假设某\(\boldsymbol x\)不满足其中任意一个约束条件,则一定会导致:
-
若该\(\boldsymbol x\)不满足等式约束,即\(g^{(i)}(\boldsymbol x)\)可非零,又因为\(\lambda^*\)会使得第二层函数最大,因此\(\lambda^*\)一定会导致结果为正无穷。
-
若该\(\boldsymbol x\)不满足不等式约束,即\(h^{(j)}(\boldsymbol x)\)可为正,又因为\(\alpha^* > 0\)会使得最内层函数最大,因此\(\alpha^* > 0\)一定会导致结果为正无穷。
由于\(f(\boldsymbol x)\)不能取正无穷,因此函数会继续迭代。
反过来,当\(\boldsymbol x\)满足全部约束时,才有:
因此不满足任意一个约束的\(\boldsymbol x\)不会成为最终结果。
如果是约束最大化问题,那么代入\(-f(\boldsymbol x)\),重复即可。
可能大家对于如何求解广义拉格朗日方程还是很迷惑。我们继续看最后一节。
4.5 实例:线性最小二乘法
假设我们要找到下述方程的解:
我们转化为另一个问题:
尽管存在许多高效的线性代数算法解决这一问题,我们也可以用基于梯度的优化方法解决。
这是一个无约束问题。我们有以下两种方法:
-
该函数是二次的,因此用二阶泰勒展开近似是精确的。我们直接用牛顿法,一步求解,即可得到全局最小点。
-
我们还可以用梯度下降法。求梯度:
迭代即可:
精髓在于,梯度的各个分量大小,取决于各个方向上的增长率。增长率越大,slope越大,那么减得越多。
现在我们改为有约束问题。解决方法有二:
-
先考虑用Moore-Penrose伪逆,直接求解\(x \approx pinv(A)*b\)。
前面介绍过,使用Moore-Penrose伪逆可以得到最小范数解。
我们观察其是否满足约束条件,若不满足,用方法2。 -
迭代法。下述。
引入不等式约束:
构造广义拉格朗日方程:
我们的优化目标是:
关于\(\boldsymbol x\)对其微分,我们有:
关于\(\alpha\)对其微分,我们有:
根据上面二式,我们实际上可以直接分析得到结果:
这就是拉格朗日乘子法啊~两个变量两个方程,一定有解!
我们在这里使用梯度优化法。我们不妨想象一下迭代过程:
-
我们先迭代\(\alpha\)(目标是最大化),再迭代\(\boldsymbol x\)(目标是最小化);若function value不满足\(\delta\),重复执行;
-
假设\(\boldsymbol x\)的初始范数等于1,由于\(\nabla_{\alpha} {L(\boldsymbol {x,\alpha})} = 0\),因此\(\alpha\)本次不迭代,而\(\boldsymbol x\)正常迭代;
-
假设\(\boldsymbol x\)的初始范数小于1,由于\(\nabla_{\alpha} {L(\boldsymbol {x,\alpha})} < 0\),因此\(\alpha\)会减小,第二项增大;接着迭代\(\boldsymbol x\)时,为了最小化第二项,\(\boldsymbol x\)可能会朝着范数增大的方向进行(当然也要考虑第一项);
-
假设\(\boldsymbol x\)的初始范数大于1,由于\(\nabla_{\alpha} {L(\boldsymbol {x,\alpha})} > 0\),因此\(\alpha\)会增大,第二项仍然是增大;接着迭代\(\boldsymbol x\)时,为了最小化第二项,\(\boldsymbol x\)可能会朝着范数减小的方向进行(当然也要考虑第一项);
无论过程多么曲折,最终,\(\boldsymbol x\)的范数都会为1;这意味着此时function只留下了第一项,因此结果就是关于第一项的优化结果,约束在范数为1。
当然,有些不等式约束可能取不到等号,称为不活跃的约束。参见P61。
做了一个小实验:
function scratch
close all;clear;clc;
%% 人为构造具有无穷解的方程Ax=b
A=randn(2,3);
b=randn(2,1);
%% 迭代逼近一个合格解
delta = 0.001; % 容差
rate=0.0005; % learning rate 不要太大,否则误差大
x=randn(3,1); %随机初始化
alpha=rand; %注意要非负
round=0; % 记录循环次数
% L = 1/2|| Ax-b ||^2 + alpha(x^Tx-1)
% nabla_alpha= normest(x)-1
% nabla_x=A'*A*x-A'*b+2*alpha*x
value=[];
while(1)
round=round+1;
nabla_alpha= normest(x)-1;
nabla_x=A'*A*x-A'*b+2*alpha*x;
if alpha + rate*nabla_alpha<0 % 目标是最大化,所以是加号
alpha = 0; % 保证非负
else
alpha =alpha + rate*nabla_alpha;
end
x=x-rate.*nabla_x; % 目标是最小化,所以是减号
value =[value normest(nabla_x)];
if normest(nabla_x)<delta % 注意这里x的梯度才是退出条件
break;
end
end
plot([1:round],value);
disp(['norm_x: ' num2str(normest(x))])
disp(['norm_(A*x-b): ' num2str(normest(A*x-b))])
end
结果:
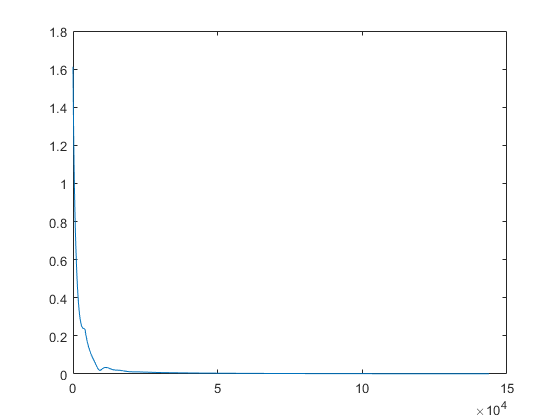
norm_x: 0.99998
norm_(A*x-b): 0.019697
实验表明:
- 由于随机初始化不同,每次试验结果差距其实是比较大的,即解的精度差距比较大。
- 但由于退出条件选为\(\boldsymbol x\)的梯度,因此退出时其范数基本都会接近于1,分析见大脑体操过程。
- 如果退出条件选为L的function value,范数往往与1相差较大。
5. 机器学习基础
荐书:Machine learning: A Probabilistic Perspective 机器学习 (Kevin P. Murphy)
在此我们将简单学习和了解:
-
学习算法,分为有监督和无监督两类。
-
如何组合不同的算法部分,如优化算法、代价函数、模型和数据集,来构建一个机器学习算法。
-
拟合训练集和提高泛化能力之间的矛盾。
-
限制传统机器学习泛化能力的因素。
-
使用额外的数据,从而设置超参数。
机器学习的本质是统计学,但更关注如何用计算机统计地估计复杂函数,而不太关注为这些函数提供置信区间。因此我们还要学习:
- 两种统计学的主要方法:贝叶斯推断和概率派估计。
大部分深度学习算法都基于梯度下降法。
5.1 学习算法
机器学习,是从数据中学习模型。Mitchell(1997)给machine learning提供了一个简洁的定义:
A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P if its performance at tasks in T, as measured by P, improves with experience E.
任务(Task)
首先一定要明确:学习本身不是任务!学习的本质是:获得完成任务的能力。
因此任务应理解为:机器学习系统该如何处理样本example。
样本是指:从某些目标对象或事件中收集的、已经量化的特征feature的集合。
样本通常表示成向量,而数据集通常表示成设计矩阵design matrix。
当然,如果样本的类型不同,是无法组成矩阵的。后面会介绍如何处理异构数据。
性能度量(Performance measure)
最常用的是准确率accuracy和错误率errorrate。其中错误率又称为0-1损失的期望。
我们通常更关注机器学习算法在未观测数据上的表现,因此我们单独划分测试集test set,其必须与训练集分开。
性能度量看似简单,实际上有很多问题:
-
有时准确率和错误率并不合适,比如密度估计。
-
有时我们很难确定应该度量什么。
比如在回归问题中,我们应该更多地惩罚频繁犯小错的系统,还是更多地惩罚偶尔犯大错的系统?
这应该取决于应用需求。 -
有时即便我们知道应该度量什么,却难以度量。
很多最好的概率模型,只能隐式地表示概率分布。
经验Experience
根据学习过程中的经验的不同,可分为以下两类:
-
无监督学习算法unsupervised learning algorithm
估计概率分布\(p(\mathbf x)\)。显式的如密度估计和聚类,隐式的如合成或去噪。
-
有监督学习算法supervised learning algorithm
估计\(p(\mathbf {y|x})\),可以理解为映射。
训练集带有标记label或目标target。
实际上这两个分类的交集是存在的。由于chain rule:
因此,无监督学习可以转化为多个有监督学习。
同理,由于贝叶斯公式:
因此,有监督学习也可以用传统的无监督学习算法,学习联合分布再推断。
此外还有:
-
半监督学习,一些样本有label而另一些没有。
-
强化学习reinforcement learning:训练并不局限于一个training set,而是与环境交互。
即学习系统和训练过程存在反馈回路。
举例:线性回归linear regression
线性回归的输出是输入的线性函数:
Task
根据\(\boldsymbol x\),输出\(\hat y = \boldsymbol {w^Tx}\),从而预测\(y\)。
Performance measure
我们采用均方误差MSE:
此时我们可以不用迭代法,而直接求解梯度为0的情况:
该解被称为正规方程normal equation。该方程实际上构成了一个简单的机器学习算法。
值得注意的是,下述函数实为仿射函数affine function:
但我们也常称之为线性回归。
不同的是,仿射函数需要添加永久偏置参数bias,加权固定项1。
尽管从特征\(\boldsymbol x\)到预测输出是一个仿射函数,但从参数\(\boldsymbol w\)和\(b\)到预测输出,仍然是一个线性函数。因此仍可以得到正规方程。下式同理:
5.2 容量、过拟合和欠拟合
训练误差和测试误差为什么有关系
机器学习系统在未观测数据上表现良好的能力,称为泛化generalization。
训练集和测试集,通过被称为data generating process的概率分布而生成。
通常,我们会提出独立同分布假设 i.i.d assumption。
在此假设下,单个样本的概率分布就可以描述data generating process。
并且训练样本和测试样本的采样遵循相同的分布,这一共享的潜在分布称为data generating distribution,记作\(p_{data}\)。
进一步,该假设允许我们从数学上研究训练误差training error和测试误差test error之间的关系。
最直接的关系是,二者期望是相同的。
否则,我们只能观测到训练集,而无法观测到测试数据,那么只存在训练误差的情况下,又如何研究测试误差呢?换句话说,测试误差与训练误差无关,无法借助研究。
欠拟合和过拟合
机器学习算法的效果取决于以下两点:
- 降低训练误差
- 缩小训练误差和测试误差的差距
第二点正是由iid假设得出的结论。
以上两点如果做得不好,就会产生相应的两大问题:欠拟合underfitting和过拟合overfitting。
个人认为,第一点矫枉过正了,实际上就会产生第二点不足的问题。
容量及其量化
模型的容量capacity,是指其拟合各种函数的能力。
容量低的模型难以拟合训练集;容量高的模型可能会过拟合,因为学习了不适用于测试集的训练集特性。
显然,我们要选择适用于当前任务复杂度和训练数据数量的算法容量。
容量不足的模型无法解决复杂问题,容量过高的模型可能产生过拟合。
一种控制训练算法容量的方法,是选择假设空间hypothesis space。
比如,线性回归问题,可以选择关于其输入的所有线性函数,作为假设空间。
要注意,广义线性回归的假设空间,不仅包含线性函数,还包括多项式函数。显然这样容量更大。
具体来说,上面是规定了可选的函数,因此容量被进一步称为表示容量representational capacity。
值得注意的是,由于优化算法不完美等限制因素,有效容量effective capacity可能小于模型簇容量。
然而很多时候,我们很难直接选出最优函数进行拟合。即我们需要其他容量选择的方法。
理论上说,学习算法也没有刻意找出最优函数,而仅仅是找到一个训练误差更小的函数。这一点给我们了启发,具体方法后面会说。
我们之前学习过一个简约原则:Occam's razor。该原则指出:在同样能解释观测现象的假设中,我们应该选择“最简单”的那一个。
统计学习理论提供了量化模型容量的不同方法。其中最有名的是Vapnik-Chervonenkis dimension, VC。
VC维度量的是二元分类器的容量,定义为“该分类器能分类的训练样本的最大数目”。
容量的意义
量化统计模型的容量,使得统计学习理论可以进行量化预测。
统计学习理论中有一条非常重要的结论:训练误差和泛化误差之间的差异的上界,
-
随着模型容量的增长而增长
-
随着训练样本的增多而下降
如果我们能找出这条边界,那么我们就证明了机器学习算法可以有效解决问题(泛化误差和训练误差一样小)。
然而,由于深度学习算法的边界非常难以找到,并且边界的定义并不严格,因此我们往往很少将容量用于分析。
并且,对于深度学习中的一般非凸优化问题,我们只有很少的理论支持。
但我们要知道,虽然越简单的函数越有可能泛化,但我们仍然需要选择一个充分复杂的假设(或者说提供这种选择),使训练误差足够小。
通常泛化误差和容量之间是一个U型关系,如P73图。
非参数模型
我们之前学习的是参数模型。参数模型学习的函数在观测到新数据前,参数向量的分量个数是有限且固定的,如线性回归模型使用的线性函数或仿射函数。
我们现在考虑容量任意高的模型,对参数个数没有限制,称为非参数模型non-parametric model。
可以想象,有些非参数模型是不可实现的理论模型,比如搜索所有可能的概率分布的算法。
当然,也存在可实现的实用的非参模型,并且可以让它们的复杂度和训练集大小有关。
如最邻近回归nearest neighbor regression,存储了所有的\(\boldsymbol X\),因此可以直接把最近点作为结果。
我们也可以把参数算法嵌入到参数数目可变的算法中,这就得到了一个非参算法。
比如,内层循环是线性回归模型,外层循环可调整多项式次数。
Bayes error
最理想情况下,我们能预先知道生成数据的真实概率分布。
然而,如果以此作为我们的模型假设,会出现很多问题。
分布中存在噪声、有些变量我们没有考虑到等,都会导致预测出现偏差,这种预测误差称为贝叶斯误差Bayes error。
In statistical classification, Bayes error rate is the lowest possible error rate for any classifier of a random outcome (into, for example, one of two categories) and is analogous to the irreducible error(不可约误差).
对于非参模型,训练数据越多,泛化能力越强,直到最佳可能的泛化误差。
对于参数模型,如果模型容量小于最优容量,其误差会逐渐大于贝叶斯误差。
比如,对于一个5阶多项式加噪声生成样本构造的训练集:
- 我们如果用2阶模型拟合,训练误差会随着样本数增大而越来越大,并且大于贝叶斯误差。因为误差的主因已经不是噪声了,而是无法拟合。
尽管其测试误差会逐渐减小(假设趋于比较合理),但最终会保持在一个较高水平(其实仍很不合理)。
- 如果用最优容量模型,训练误差会趋于0,而测试误差会趋于贝叶斯误差。
图见P74。
从该例中也可以看出,即使模型容量达到最优,其训练误差和泛化误差的差距仍可能很大,因为训练集太小,表示的特征不够复杂。此时只能增加训练样本。
No free lunch theorem
我们都知道,从特殊到一般是很困难的。
而学习理论表明,机器学习算法能从有限的训练集中,得到足够的泛化能力,这一点如何解释呢?
原因在于,从特殊到一般,往往是一个严格推理的过程;而机器学习可以通过概率法则解决问题,而无需使用纯逻辑,推理整个确定性法则。
机器学习寻找的,是一个在大多数样本上正确的规则,而不是全部样本上正确。
尽管某个机器学习算法的泛化能力可以得到保证,但我们必须指出,该算法往往只在特定任务上奏效!
根据no free lunch theorem,假设所有可能的数据生成分布均匀出现,或者说所有可能的任务等可能出现的情况下,每一个分类算法都具有相同的测试性能(泛化性能)!比如,简单地把所有点都归为一类。
幸运的是,实际中我们往往会对概率分布进行一定的假设,并设计出在该分布上表现良好的算法。换句话说,我们的算法往往是专用的。
总而言之,机器学习的目标绝不是寻找通用算法或绝对第一算法!
正则化
前面提到了“选择假设空间”这一控制容量的方法。
现在,我们介绍另一种更简单、更常用的控制方法。
我们加入权重衰减weight decay来布置惩罚。
假设在线性回归问题中,我们倾向于平方范数较小的权重,则构造:
\(\lambda\)越大,说明我们的倾向越强,对较大权重的惩罚越剧烈。\(\lambda\)过大可能导致欠拟合。
\(\Omega(\boldsymbol w) = \boldsymbol {w^Tw}\)被称为正则化项regularizer。
此外,还有很多显式或隐式表达对解的偏好的方法,我们统称为正则化regularization。
正则化是机器学习的中心问题之一,同等重要的还有优化,此外无他。
5.3 超参数和验证集
超参数hyperparameters是无法学习得到的参数,尽管我们可以用另一个算法专门学习超参数,并嵌套在原算法外层。
大多数学习算法都具有超参数。比如回归问题中的多项式阶数,又比如正则化因子\(\lambda\)。
设置超参数的原因有二:
- 有些参数实在难以优化,干脆设为超参数。
- 有些参数不适合训练。
如控制模型容量的所有超参数,一旦设为普通参数用以训练,那么最终结果一定是容量越大越好。
此时训练误差最小,但过拟合。
个人认为,这是人类无法向机器传递的先验知识导致的。
为了“训练”超参数,我们特设验证集validation set。
验证集通常是从训练集中划分出来的子集,但一定要严格区别于训练集,即训练算法无法观测。
比如,训练集和验证集比例通常为8:2。
因此,测试集、验证集、训练集三者是互无交集的。
要强调的是,我们设置交叉验证集的目的是调节超参数,但本职工作(原理)仍是估计泛化误差。
要注意,验证集会低估泛化误差,因此我们一定要把最终的性能测试放在测试集上完成。
交叉验证
验证集往往是从训练集中按一定比例分离出来的。
这就带来一个潜在的问题:如果原本的训练集就很小,那么验证集会更小。
前面已经强调,交叉验证集的本职工作就是估计泛化误差。
小规模的测试集意味着泛化误差估计的严重的统计不确定性,其方差很大,结果很不可信。
为了解决小规模数据集带来的问题,我们常用K-fold cross-validation验证方法。其代价是:
-
计算量增大。
-
不存在平均误差方差的无偏估计。可以看看这篇博客
K-fold cross-validation算法如下:
-
将数据集\(\mathbb D\)分为互斥的\(k\)个子集\(\{\mathbb D_i\}\),并集为\(\mathbb D\)。
-
除去\(\mathbb D_i\),取其他\(k-1\)个子集,训练得到算法\(f_i\)。
-
将算法\(f_i\)放在\(\mathbb D_i\)上作测试(将\(\mathbb D_i\)用作测试集),得到标量\(e_i\)。
-
重复2、3步,会得到由\(k\)个标量组成的误差向量\(\boldsymbol e\)。
-
\(\boldsymbol e\)的均值即最终结果:估计的泛化误差。
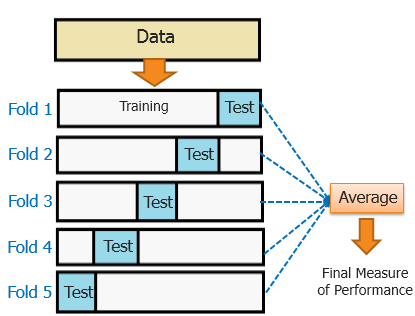
需要说明的是,经过交叉验证后,我们的估计的泛化误差的置信区间是没有得到证明的。
但通常做法是,只有当算法A误差的置信区间低于算法B误差的置信区间,且二者互不相交时,我们才说A更好。
举例:假设建立一个BP神经网络,其中,隐含层的节点数目是一个待确定的超参数。此时我们可以这么做:
-
先将节点数设定为某一具体的值。
-
由交叉验证法,选出训练集和测试集。
-
由训练集训练出模型,再由验证集检测误差。
-
重复2、3步骤\(k\)次,取均值,作为该节点数下的交叉验证误差。
-
改变节点数,重复2-4步骤,直至选出交叉验证误差最小对应的节点数。
-
将该节点数作为最优节点数,并重新训练出模型(直接分为训练集和测试集再训练?)。
-
测试误差即估计的泛化误差。
5.4 估计、偏差和方差
点估计的概念
点估计point estimator或统计量statistics试图为一些感兴趣的量提供“最优”预测。
感兴趣的量可以是一个参数,一个向量甚至是一个函数。
参数\(\boldsymbol \theta\)的点估计常表示为\(\hat {\boldsymbol \theta}\)。
点估计一般由一个映射函数和一些数据点实现。
假设\(\{\boldsymbol x^{(i)},1 \leq i \leq\}\)是\(m\)个\(i.i.d\)数据点,则点估计是这些数据点的任意函数:
从“任意”可以看出,点估计并没有要求\(g\)返回一个接近\(\theta\)的值。但好的估计会实现这一点。
由于数据是从随机过程中采样得到的,因此数据的任何函数都是随机的,点估计\(\hat {\boldsymbol \theta}\)是一个随机变量。
换句话说,即使是相同的分布,从该分布中得到其他样本时,得到的统计量也会不同。
为什么要学点估计
剧透一下我们后面到底在学什么。
我们通过交叉验证等方法,得到了一组误差\(\{e_i\}\)。这组误差,实际上是衡量泛化误差的重要指标。
现在,我们要看看,这组误差的均值在哪里,方差又是多少。
我们假设这组误差服从某种分布,通过采样的方式得到了这\(m\)个误差点。
因此,不论是误差的均值,还是误差的方差,其实都是“点估计”。其中,误差的均值的估计为:
而误差的方差的估计有两种方式,对应无偏、有偏,后述。
那么得到这两个数据,又有什么用呢?
-
误差的均值,是直接衡量泛化误差的指标
-
误差的均值和误差的方差一起,可以说明系统是欠拟合还是过拟合。
-
由于误差的均值是估计得到的,因此对应的会有其置信区间和置信水平。借助置信区间,我们可以比较算法优劣。
接下来我们步入正题。
误差的均值和方差(估计)
估计的偏差定义为:
- 无偏unbiased:\(bias(\hat {\boldsymbol \theta}_m) = 0\)
- 渐进无偏asymptotically unbiased:\(\lim_{m\to \infty} {bias(\hat {\boldsymbol \theta}_m)} = 0\)
我们下面都以高斯分布为例:
首先,高斯分布的均值估计如下,并且是无偏的:
一定注意,\(\hat \mu_m\)是一个随机变量,而不是一个常数!千万不要\(\mathbb E[\hat \mu_m] = \mathbb E[\mu] = \mu\)!!!
其次,我们介绍高斯分布方差的两种估计。
第一种方差估计称为样本方差sample variance:
其中:
代入得:
出现偏差的本质原因,是均值也是估计的。如果均值为已知的\(\mu\),则可以证明估计无偏。
第二种方差估计称为无偏样本方差unbiased sample variance:
无偏估计并不总是最佳选择。我们也常用其他具有重要性质的有偏估计。
另外,对上述二者开根号,得到对标准差的估计。但是,二者都低估了真实标准差。
其中,开根号与求期望不能交换顺序,因为是非线性运算。
可参考一篇博文。
现在,我们知道误差的均值、误差的方差是如何估计的了。
由于误差的均值有特殊用途,我们来看看均值估计的性质。
均值估计的标准差
我们已经证明,高斯分布的均值估计是无偏的,那么均值估计的方差或标准差呢?
其实这本书没法给出求法。个人推测,就是多测几组误差的均值(\(m\)个均值而不再是\(m\)个误差),按上一节的两种方法之一求。
理论上,均值估计的标准差,与真实标准差\(\sigma\)之间的关系如下:
由结论,均值数\(m\)越大,均值估计的标准差越小(逼近0),均值估计得就越准确。
误差的均值估计、误差的方差估计、误差的均值估计的标准差 有什么用
我们通常用测试集样本的误差的均值,来估计泛化误差。
上式告诉我们,均值测试数\(m\)越大,均值的估计越精确(合理)。
误差的均值估计的标准差,为我们比较算法优劣提供了依据。
中心极限定理指出,该均值会接近一个高斯分布。
我们就假设估计的均值\(\hat \mu_m\)服从均值为\(\hat \mu_m\)、方差为\(SE(\hat \mu_m)^2\)的高斯分布,那么我们就可以计算出真实期望落在某个区间的概率。
比如95%置信区间为:
回顾交叉验证一节中提到的内容,通常只有当算法A的误差的95%置信区间的上界,小于算法B的误差的95%置信区间的下界时,我们才说算法A优于算法B。
进一步我们会指出,(误差的均值的)偏差和方差,往往是矛盾的。为什么矛盾?有什么指导意义?如何权衡?下一节见分晓。
高偏差vs.高方差 欠拟合vs.过拟合
偏差和方差,衡量的是估计量的不同误差来源。为了进一步了解,我们可以参考这篇博文,有以下总结:
任何机器学习算法的预测误差可以分解为三部分:
-
偏差误差
-
方差误差
-
不可约的误差(对于给定的模型,我们不能进一步减少的误差)
首先看偏差误差。
简单来说,偏差误差的罪魁祸首,往往是模型(假设)过于简单。
因此,参数模型的偏差,往往要大于非参数模型。
参数模型训练很快,也很好理解,但不灵活,因此偏差也大;非参模型比较复杂,往往需要更多的数据,但很强大。
低偏差的例子有KNN和SVM,高偏差的例子有线性回归和logistic regression。
我们再看方差误差。
简单来说,方差误差的罪魁祸首,往往是模型(假设)过于复杂。
此时,当数据集变化时,误差就会发生很大的变化。
一般而言,具有很大灵活性的非参数学习算法都具有很高的方差。
KNN和SVM往往是高方差的。
这张图完美地诠释了,高方差和高偏差的不同特点,以及随着容量的增大,误差的变化:
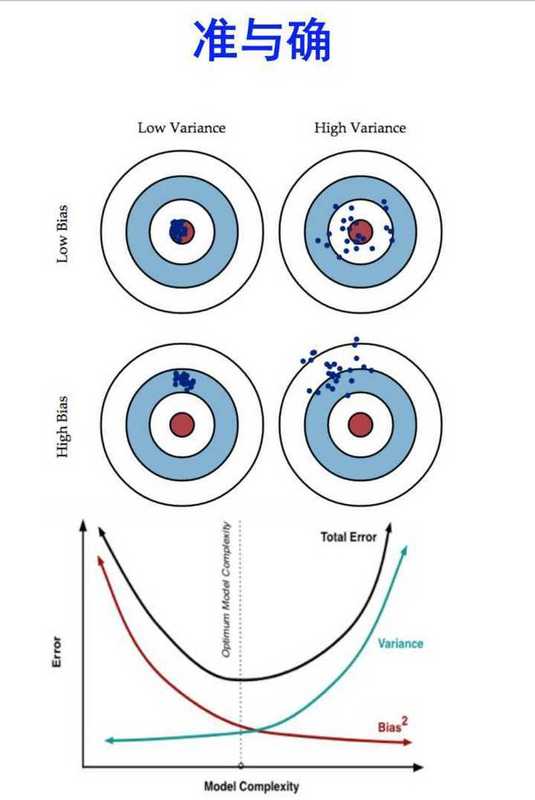
图中,容量和误差是一一对应的,那么唯一的误差是怎么得到的呢?
我们常用交叉检验法,再求多次估计的均值;也可以用均方误差MSE表示:
MSE计算起来比较简单,就是一个加和。式中bias和var都由之前学的估计方法得到。
事实上,偏差和方差与欠、过拟合密切相关!见P82图。
-
当模型容量较小时,偏差较大,方差较小,模型呈现欠拟合;
-
当模型容量较大时,模型足够复杂,偏差较小,但方差会逐渐增大,模型趋于过拟合。
而参考MSE公式,二者的组合,正是U型曲线!因此我们可以找到一个比较合适的模型容量。
有同学会问了:如果模型过拟合,那么偏差不会大吗?其实往往会,因为泛化能力差。
在吴恩达的机器学习中,直接把过拟合对应于high variance,欠拟合对应于high bias。
这里的低偏差,是相对高偏差而言的。
高偏差:无论新数据集和原数据集是否相似,偏差都很高。这显然是欠拟合情况。
因此低偏差说的是:如果新数据集和原数据集类似,那么仅此情况偏差会低,其他大部分情况都很高。
一致性
我们希望:当训练集样本数量\(m\)增大时,点估计可以依概率收敛到真实值,即:
对\(\forall \epsilon > 0\),当\(m \to \infty\)时,有:
该条件即一致性consistency。实际上这是弱一致性。
一致性保证渐进无偏;但渐进无偏并不保证一致性。
5.5 最大似然估计
之前我们只是唐突地给出了估计,那么这些估计是怎么来的呢?
我们希望有一些准则,指导我们从一系列函数中,选出最好的估计。
最常用的就是最大似然估计。
假设我们手里有一组(\(m\)个)数据\(\{x^{(i)}\}\),独立地由未知的真实数据生成分布\(p_{data}(\mathbf x)\)产生。
因此其概率为\(p_{data}(\boldsymbol x)\),也是未知的。
我们的思路是:根据假设创建了一个model,其中model的一组\(\boldsymbol \theta\)待定,也就是要学习的。
我们通过调整\(\boldsymbol \theta\),使得model输出的概率\(p_{model}(\boldsymbol {x;\theta})\)最大。
此时的\(\boldsymbol \theta\)就是我们想要的\(\boldsymbol \theta_{ML}\),其对应的model的输出就最大程度上近似了原始分布。
数学阐述:
由独立性:
多个概率的乘积容易导致数值下溢等计算问题。因此我们常化为等效的求和:
再等效地除以常数\(m\),就可以化成期望的形式:
另一种解释是:首先我们用KL散度,衡量训练集上的经验分布\(\hat p_{data}\),和模型分布\(p_{model}\)之间的差异:
由期望的线性性,考虑到第一项是常数,因此忽略第一项:
我们的目标便是最小化KL散度,即取相反数。结果与第一种解释不谋而合。
换句话说:最大似然和最小化KL散度,对优化的参数而言是等价的。
但目标函数值是不同的,因为KL散度最小只能为0,但负对数似然NLL(最大化变成最小化)可以为负值。
我们下一节证明:均方误差MSE是经验分布和高斯模型之间的交叉熵,是服从最大似然准则的误差估计方法。
条件对数似然和均方误差
实际上我们之前学习的(条件)最大似然估计是这样的:
这构成了大多数监督学习的基础。如果样本是独立同分布的,还可以进一步分解为:
现在,我们以最大似然估计的角度,重新审视线性回归。
我们采用高斯model,其中均值是预测值\(\hat y\),方差是固定的(已知的):
换句话说,我们的目标仅仅是改变预测的均值\(\hat y = \boldsymbol {w^Tx}\),其余参数是确定的。
代入得:
显然这等效于:
因此我们说明了:对于线性回归,最大化关于\(\boldsymbol w\)的对数似然,和最小化MSE是等价的,会得到相同的参数估计,尽管对象函数不同。当然模型假设是高斯分布。
最大似然的性质
最大似然估计最吸引的人的地方在于:当样本数量趋于无穷时,就收敛速率而言,最大似然估计是最好的渐进估计。
首先要说明,最大似然估计的渐进性有一定前提。前提条件为:
-
真实分布\(p_{data}\)必须在假设空间\(p_{model}\)中,否则是不可还原的。
-
真实分布\(p_{data}\)刚好对应model的一组参数\(\boldsymbol \theta\)。
否则,即使最大似然估计恢复出真实分布\(p_{data}\),也不能决定数据生成过程应使用哪一个\(\boldsymbol \theta\)。
我们回到一致估计。
一致估计的统计效率statistic efficiency差别很大。
某些一致估计只需要少量样本,就能达到一个固定程度的泛化误差。
统计效率通常用于研究有参情况parametric case。
Cramer-Rao下界表明,当m较大时,不存在均方误差低于最大似然估计的一致估计。
因此,最大似然通常是机器学习中的首选估计方法。
当样本数量过少导致过拟合时,我们可以增大正则化策略权重,以获得有偏但方差较小(high variance对应过拟合)的最大似然估计。
5.6 贝叶斯统计
前面介绍的是概率派统计frequentist statistics,基于估计单一的目标\(\boldsymbol \theta\)。
现在我们学习贝叶斯统计Bayesian statistics,一次考虑所有可能的\(\boldsymbol \theta\)。
之前,我们认为存在一个真实参数(定值)\(\theta\),然后去估计它。我们基于数据集\(\{\boldsymbol x^{(i)}\}\),并且数据集是随机变量。
贝叶斯统计完全不同。数据集是可观测的因此是确定的而不是随机的,并且\(\theta\)是未知的因此是随机变量。
我们用概率表示知识状态的确定性程度。
我们将关于\(\theta\)的已知知识,表示成先验概率分布prior probability distribution:\(p(\boldsymbol \theta)\)。
一般而言,我们会选择一个相当宽泛的(高熵的)先验分布,如均匀分布、高斯分布。
这样,先验知识会偏向于简单的解。
现在,假设我们有了一组数据\(\{x^{(1)},...,x^{(m)}\}\)。由贝叶斯规则:
后验熵往往要比先验熵低。
前面我们提到,最大似然准则是我们选择估计方法的原则之一。相对于最大似然估计,贝叶斯估计有以下两大区别:
-
贝叶斯估计不使用\(\boldsymbol \theta\)的点估计\(\boldsymbol {\hat \theta}\),而使用\(\boldsymbol \theta\)的全分布。例如,如果我们观测到了\(m\)个样本,那么下一个样本可以这么预测:
\[p(x^{(m+1)}|x^{(1)},...,x^{(m)}) = \int {p(x^{(m+1)}|\boldsymbol \theta)p(\boldsymbol \theta | x^{(1)},...,x^{(m)})d{\boldsymbol \theta}} \]进一步说,每一个具体的\(\boldsymbol \theta\),通过积分的形式,都会参与下一个样本的预测。积分的方法有助于防止过拟合。
概率派通过估计的标准差,来衡量估计的不确定性,如前面的“误差的均值估计的置信区间”。而贝叶斯派通过积分得到一个分布,实际上就反映了(内含了)不确定性。
-
贝叶斯方法需要先验知识。实践中,人们往往偏向于简单、光滑的模型。因此也有人批判:贝叶斯方法引入了人的主观判断。
但训练数据有限时,贝叶斯方法泛化比较好;如果数据过多,贝叶斯方法计算代价很高。高就高在矩阵计算上,我们看一个例子。
例:贝叶斯线性回归
给定一组\(m\)个训练样本\((\boldsymbol {X,y})\),预测为:
我们假设数据生成分布为方差为1的高斯分布,即:
我们先要指定一个先验分布。如高斯分布:
其中,\(\boldsymbol \mu_0\)和\(\boldsymbol \Lambda_0\)分别是先验分布的均值向量和协方差矩阵。
除非特殊要求,协方差矩阵一般设为对角阵:\(\boldsymbol \Lambda_0 = diag(\boldsymbol \lambda
_0)\)
此时我们就可以确定后验分布了。根据贝叶斯规则有:
指数乘法还可以进一步整合,结果见P87。
\(p(\boldsymbol {w|X,y})\)就是我们想要的结果,当提供了训练集和label后,关于参数\(\boldsymbol w\)的分布的预测。
最大后验MAP估计
我们可以让先验知识影响点估计的选择,然后再利用点估计。这种方法就是最大后验Maximum A Posteriori点估计。
MAP估计是两种学派方法的折衷,其原则是选择后验概率(或概率密度)最大的点:
式中,第一项是标准的对数(条件)似然项,第二项对应先验分布。
例如,如果先验分布是高斯分布\(\mathscr N(\boldsymbol {w;0,\frac{1}{\lambda}I^2})\),那么第二项就正比于我们熟悉的正则化项\(\lambda \boldsymbol {w^Tw}\)。
因此,许多正则化估计方法,可以被解释为贝叶斯推断的MAP近似,其中先验权重为高斯分布。
当然,也有不满足的。有一些正则化项依赖于数据,还有的可能不是一个概率分布的对数。
进一步,MAP贝叶斯推断提供了一个直观的设计复杂正则化项的方法。如用混合高斯分布代替一个单独的高斯分布,来作为先验分布。
5.7监督学习算法
概率监督学习
我们已经学习过,利用最大似然估计,找到对于有参分布族\(p(y|\boldsymbol {x;\theta})\)最好的参数\(\boldsymbol \theta\)。
实际上,本书大部分监督学习算法,都基于估计概率分布\(p(y|\boldsymbol x)\)。
我们再次理解一下线性回归对应的估计概率分布。
我们采用高斯model,其中均值是预测值\(\hat y\),方差是固定的(已知的):
显然,参数\(\boldsymbol w\)不同,预测值就会不同,高斯model的均值就不同;对于同一个\(y\),其概率(密度)就不同。
如果参数设的好,预测值接近label:\(y\),那么这个概率(密度)就越大。
假设样本独立同分布,那么我们的目标,就是让每一个样本对应的概率(密度)的乘积最大,也就是对数加和最大。
不难想象,只要我们改变估计概率分布,就能改变我们参数优化的对象,从而解决各种各样的监督学习问题。
最常见的是二分类问题。
二分类问题中,只存在两个互补的概率需要我们考虑。
因此,我们常用Logistic sigmoid函数,把输出限定在0和1之间:
如果我们仍然采用最大似然估计,那么我们应该输入label=1对应的样本,此时sigmoid函数理论上的输出应该越大越好,这样才能“最大化”。因此我们设:
互补的label=0的特征\(\boldsymbol {\theta^Tx}\)自然就被最小化了。
上述方法称为逻辑回归logistic regression,但注意是分类方法而不是回归!
与线性回归不同的是,逻辑回归无法使用求解正规方程的方法,其最佳权重没有闭解。
我们必须最大化似然,来搜索最优解。基于梯度下降的最小化负对数似然是其中一种搜索方法。
支持向量机
监督学习中,最有名的方法之一就是支持向量机support vector machine,SVM。
SVM深入内容,参见这篇博客。
和逻辑回归类似,其模型基于线性函数\(\boldsymbol {w^Tx} + b\);
不同的是,其输出不是概率,而是类别:输出为正表示正类,输出为负表示负类。
SVM方法中的一个重要创新是核技巧kernel trick。
注意,SVM只是核技巧的应用之一,参见这篇回答。这些方法统称为核机器kernel machine或核方法kernel method。
核技巧基于一个事实:许多机器学习算法,都可以写成样本间点积的形式。如SVM中的线性函数可以重写为:
注意!这里的\(\boldsymbol x^{(i)}\)是指训练样本点,和输入的\(\boldsymbol x\)不存在任何关系!
我们可以把其中的向量\(\boldsymbol x\)包装成特征函数的输出:\(\phi(\boldsymbol x)\)。
此时的点积,被替换为了核函数kernel function:
但对于某些特征空间,我们不会用向量内积这种表示方式。
比如在某些无限维空间中,我们会用其他类型的内积,如基于积分而不是加和的内核。
因此我们统一表示为:
此时我们得到以下预测函数:
我们深入一点看这个函数。该函数虽然关于\(\boldsymbol x\)是非线性的,但关于\(\phi(\boldsymbol x)\)是线性的。
换句话说,核函数的作用相当于预处理,使得学习在新的转换空间内进行,并且学习的仍是线性模型。
核函数有两大优点:
-
它使我们能够使用凸优化技术来学习关于\(\boldsymbol x\)的非线性模型。而凸优化能保证有效收敛。
-
核函数的实现,通常比直接构建\(\phi(\boldsymbol x)\)再求点积要高效,尽管是等价的。
-
还有更深入的理由,参见开篇推荐的知乎页面其他回答。
在某些情况下,\(\phi(\boldsymbol x)\)可以是无穷维的;对普通的显式方法,这显然是不可计算的,但对核函数而言,可能是易算的。
比如,输入一个非负整数,\(\phi(x)\)返回一个向量,前\(x\)个元素为1,后面是无穷个零。核函数可以轻易写出:
最常用的kernel是高斯核Gaussian kernel:
该核又被称为径向基函数radial basis function,RBF核,因为以\(\boldsymbol u\)为中心,随着\(\boldsymbol v\)向外辐射,函数值不断减小。
显然,高斯核对应的是无限维空间中的点积。
更直观的理解是,高斯核在执行一种模板匹配template matching。
当输入测试点\(\boldsymbol x\)和某个训练样本点\(\boldsymbol x^{(i)}\)十分接近时,高斯核函数输出较大,即预测输出时,关于label:$ y^{(i)}$的权重就比较大,即模型倾向于考虑这个相似样本点的label。
显然,核方法最大的缺点,是决策函数的计算成本太高,与训练样本数目之间呈线性关系。
因为训练样本越多,参与分配权重者就越多,并且该数目与计算量大致是线性的。
为此,如果我们能让大部分权重\(\boldsymbol \alpha_i\)为0,那么在训练时,我们就可以挑出其中具有非零权重的训练样本的核函数。
这些训练样本就称为支持向量support vector。
然而这只是缓解之计,当数据集很大时,核机器的计算量是很大的。
我们最后会指出,带通用核函数的本质目的,是为了提高model的泛化能力。
BTW,现代深度学习,就是旨在克服核机器的限制。
在深度学习兴起以前,学习非线性模型的主要方法,就是结合核技巧的线性模型。
为此,我们需要建立\(m*m\)矩阵,计算量为\(O(m^2)\)。
而借助深度学习,我们不仅可以解决大数据集问题,而且还可以训练非线性模型。
当前深度学习的复兴,正是始于Hinton等人在2006年证明,神经网络在MNIST上的表现,胜过了RBF核的SVM。
其他简单的监督学习算法
我们在非参模型中提到过:最近邻回归,这是另一种非概率的监督学习算法,可用于分类或回归。
其中简单又好用的算法,是K-最近邻算法k-nearest neighbors algorithm, KNN。
KNN也是无参的,事实上还是无需训练和学习过程的,仅存在一个预测阶段的简单函数。
假设我们有一个用0-1误差度量性能的多分类任务。
如果训练样本数目是无穷的,那么与待测\(\boldsymbol x\)距离为0的样本也是无穷多的。
如果我们使用这无穷多个样本进行投票,那么model的误差将会是贝叶斯误差。
当训练样本数量趋于无穷时,1-最近邻算法会收敛到两倍贝叶斯误差。因为至少存在两个等距离样本,而算法只能从中随机选择一个。
由上述分析可以看出KNN的缺点:
-
训练样本数目不够大时,泛化能力很差。
-
训练样本数目较大时,计算代价和存储代价都很高。
我们再来学习决策树decision tree。
决策树将输入空间划分为不同的区域,每个区域的算法参数相互独立。
决策树通常使用坐标轴相关的拆分,有时解决一些逻辑回归问题反而很费力。
比如,若\(f(x)=x\)为决策边界,那么决策树就需要无穷多个节点,来回穿梭于真正的决策函数。
决策树还有一个问题。每一个区域,需要至少一个训练样本来定义。因此如果一个函数的局部极大值比训练样本数目多,决策树算法是不可用的。
还有更多的传统监督学习算法,请参见开篇参考书。
5.8 无监督学习算法
我们提到过,有无监督学习实际上界限并不严格。
本质上说,有监督学习比无监督学习,增加了监督信号。
但是,特征和监督信号的区别是不严格的,因此把监督信号也看作特征,那么算法就是无监督的。
通俗地说,监督学习需要人为标注的信息,而无监督学习是不需要的。
无监督学习通常与密度估计相关,学习从分布中采样、去噪、聚类、寻找数据分布的流形等。
数据的“最佳表示”,常常是指更简单或更易访问的表示。哪怕受到惩罚或限制,数据也能较好的保存。
常见的“简单表示”有3种:低维表示、稀疏表示和独立表示。这3种情况并不互斥,比如低维表示和独立表示就是密切相关的。
稀疏表示常用于需要数据升维的情况,此时由于大部分都为0,因此不会过多地丢失信息。
这意味着,稀疏表示倾向于把数据表示在空间坐标轴上。
主成分分析
参见我的博文。
根据SVD与特征分解之间的关系(回顾),我们可以把\(\boldsymbol {XX^T}\)特征分解的任务交给SVD完成,特别是当\(\boldsymbol X\)非方阵时。
因此PCA也可以用SVD实现,见P93。
尽管PCA是一种非常有效的数据降维方式,但其并不是表示学习的全部。
我们不仅希望尽可能消除数据元素间的相关性,同时还希望找出数据间更复杂的依赖关系。
此时,简单的线性变换已经不再适用。
K-均值聚类
k-means clustering将训练集分为\(k\)个聚类。具体方法不细说了,比较简单。
我们可以认为,该算法提供了\(k\)维one-hot编码向量。这实际上是一种极端的稀疏表示,只有一个1,其余都是0。
这种稀疏表示的计算效率特别高,但显然丢掉了许多分布上的信息,而只是简单归为一类。
这暴露出聚类的一大问题。比如,聚类算法把红色卡车、灰色卡车、红色汽车归为一类(vehicle),但并不能告诉我们,红色汽车和红色卡车在颜色上相似度更高。
反过来说,相对于one-hot编码,我们通常更倾向于分布式表示。
5.9 随机梯度下降
随机梯度下降stochastic gtadient descent, SGD是几乎所有深度学习算法都要用到的。SGD是梯度下降的拓展。
目标问题:好的泛化需要大数据集,然而训练大数据集的计算成本高。
为此,我们把机器学习算法中的代价函数,分解为每个样本的代价函数的总和。
等价地,每一次训练,我们只从训练集中均匀地抽出一小批量minibatch样本,再执行梯度下降。
显然,每一步SGD的计算量,并不取决于训练集大小\(m\)。
当\(m\)趋于无穷大时,model一定会在SGD抽取完所有样本之前,已经收敛到可能的最优测试误差。
换句话说,继续增大\(m\),是不会改变模型的收敛时间的。
我们在第八章还会继续讨论SGD。
5.10 构建机器学习算法
说了这么多,我们来看看,究竟如何构建机器学习算法。
几乎所有的机器学习算法,都可以由以下部件组成:特定数据集、代价函数和优化算法。
我们先看监督学习,以线性回归为例。
-
我们的数据集是\(\boldsymbol X\)和\(\boldsymbol y\),代价函数使用cross-entropy:
\[J(\boldsymbol w,b) = \mathbb E_{\mathbf x,y\sim\hat p_{data}}[- \log {p_{model}(y | \boldsymbol x)}] \]其中,训练集上的经验分布是\(p_{data}\),模型分布是\(p_{model}\)。
当然,代价函数也可以使用MSE,且已证明等价于最大似然(最小化负对数似然),是最佳的渐进估计方法。但使用交叉熵,可以避免使用MSE的问题:在梯度下降前期(误差较大时)速度反而很慢。并且,交叉熵在softmax回归中是凸函数(在神经网络中不是),参见一篇博客。
-
代价函数可以有附加项,如正则化项:
\[J(\boldsymbol w,b) = \lambda\Vert \boldsymbol w \Vert_2^2 + \mathbb E_{\mathbf x,y\sim\hat p_{data}}[- \log {p_{model}(y | \boldsymbol x)}] \] -
大多数情况下,优化算法可以是简单的求解正规方程,即令梯度为\(\boldsymbol 0\)。
即使是2中的情况,加入了附加项,此时仍有闭解(解析解)。但如果模型变成非线性的,如逻辑回归,那么就不存在闭解,需要通过迭代数值优化的方法。
我们再看无监督学习。
以PCA为例。我们知道,PCA的初衷,是有限项估计前后,均方误差最小。因此其代价函数为:
只要有近似其梯度的方法,我们就能使用迭代数值优化的方法,近似最小化目标。
有些模型,如决策树或k-means,需要特殊的优化,因为它们的代价函数有平坦区域,不适合用梯度优化方法。
5.11 促使深度学习发展的机器学习挑战
本章介绍的机器学习算法,都不能解决人工智能的核心问题,如语音识别或对象识别。
本质原因,就是机器学习方法泛化能力远远不足。
维数灾难
当数据的维数很高时,很多机器学习问题会变得异常困难。这种现象就被称为维数灾难curse of dimensionality。
由维数灾难带来的一个挑战,是统计挑战,以P97图为例。对于每一个空间中的区域,我们都需要足够多的样本,对该区域进行描述,进而描述整个空间。
-
假设我们只对1个变量感兴趣,其取值仅有10种,那么一共只有10个区域需要考虑。如果每个区域的样本足够多,那么泛化能力会很好。
-
假设我们对3个变量感兴趣,那么一共就有\(10^3 = 1000\)个区域需要考虑。这对样本数量的要求苛刻的多。
-
一般而言,如果有\(d\)维,每个维数有\(v\)个值需要区分,我们就需要\(O(v^d)\)个区域和样本需要考虑。
如果某个区域缺乏样本,大多数传统机器学习算法只会简单地假设:输出应与最接近的训练点相同。
局部不变性和平滑正则化
为了更好地泛化,我们通常需要用先验知识,来引导机器学习算法学习特定类型的函数。
简单来说,先验知识直接影响函数,从而间接影响参数。
我们的先验知识,往往是在小区域内变化不太剧烈的,即要求学习到的函数应近似满足:
这意味着:如果我们知道\(\boldsymbol x\)处的输出,那么其邻域内的输出也应该相同;如果在邻域内有好几个候选答案,我们可以进行组合。这一点解释了上一节的最后一句话。
这种广泛使用的隐式先验知识,称为平滑先验smoothness prior或局部不变性先验local constancy prior。
说白了,这种局部假设,在面对复杂AI问题时,往往是不充分的。
比如我们之前学习的核函数,实际上应称为局部核local kernel。当距离较大时,核函数值较小;反之较大。
因此,局部核可以看作是执行模板匹配的相似函数。
而深度学习的很多研究,就致力于打破局部核模板匹配的局限性。
流形学习
流形manifold是机器学习中很多思想的内在概念。
从数学定义上说:
A manifold is a topological space that locally resembles Euclidean space near each point. More precisely, each point of an n-dimensional manifold has a neighbourhood that is homeomorphic to the Euclidean space of dimension n.
每个点的邻域的定义,暗示着变换可以在邻域内进行。比如在地球这个三维流形中,我们在任何一点都可以朝任意方向移动。
机器学习中的manifold,可以简单理解为:一组点,其自由度或维数嵌入在高维空间中。
比如P100图5.11,尽管训练数据在二维空间(高维空间)中,但流形(这组点)是一维的。
这个一维流形就是我们的推断目标,而我们看到的是复杂纷乱的二维点集。
流形学习manifold learning认为:
-
空间中大部分区域都是无效输入,有意义的输入只存在于包含少量数据点的一组流形中。
-
待学习的输出,其有意义的变化只沿流形方向变化,或只发生在当我们切换到另一流形时。
-
数据位于低维流形。但这一点并非总是成立。
尽管流形学习最初定义在连续数值和无监督学习环境下,但也可以泛化到离散数值和监督学习设定。关键要求概率质量高度集中。
其余内容参见P99-101,以及本书最后。
本书第六章到第十二章,归为第二部分:现代实践,总结深度学习解决实际问题的现状。
第三部分会进一步讨论尚不发达的分支。
总的来说,深度学习为有监督学习提供了强大的框架。
如果我们需要将输入向量映射到输出向量,那么深度学习可能会有帮助:可以配置更多的层和单元,使得函数复杂性不断增加。
但是,如果是不能描述为向量之间关联的任务,那么仍超出了深度学习的能力范围。
本书第二部分,总体呈现的是:参数化函数近似技术的核心。概括如下:
-
表示这些函数:前馈深度网络模型
-
高级技术:正则化和优化模型
-
专门用于高分辨率图像(拓展):卷积网络
-
专门用于时间序列(拓展):循环神经网络
6. 深度前馈网络
6.0 概述
深度前馈网络deep feedforward network,别名:
-
前馈神经网络feedforward neural network
-
多层感知机multilayer perceptron, MLP
目标:近似某个函数\(f^*\),如分类器。
方式:定义一个映射\(\boldsymbol y = f(\boldsymbol {x;\theta})\),并学习最佳\(\boldsymbol \theta\)值。
特点:信息流经用于定义\(f\)的中间计算过程,直接到达输出\(\boldsymbol y\)。输出和模型之间没有反馈feedback连接,因此该模型称为前向的feedforward。
前馈神经网络如果增加了反馈环节,则升级为循环神经网络recurrent neural network,在第十章介绍。
注意卷积网络属于前馈网络。
实际上这是我们第一次接触网络network这一概念。这些网络受神经科学启发而生,因此又称为神经网络。
前馈神经网络之所以称为网络,是因为它通常由许多不同的函数复合而成,形成一个有向无环图。
如三个函数复合:\(f(\boldsymbol x) = f^{(3)}(f^{(2)}(f^{(1)}(\boldsymbol x)))\)
通常情况下,\(f^{(1)}\)被称为first layer,以此类推。
最后一层为输出层output layer。
训练数据(实际上是前一层的输出数据)可以直接告诉输出层,在每一个输入点\(\boldsymbol x\)上该怎么做。但是,由于复合了多层函数,训练数据无法指明其他层应该怎么做。因此这些层称为隐藏层hidden layer。隐藏层的使用,是由学习算法自行决定的。
我们可以把层理解为向量-向量函数,也可以理解为由许多并行操作的单元unit组成,每一个都是向量-标量函数。
链的全长称为深度depth。
隐藏层的维数决定了模型的宽度width。
为了理解前馈网络,我们再次回顾线性模型,考虑如何克服其局限性。
逻辑回归(严格上不是线性模型)和线性回归的明显缺陷,是无法理解两个输入变量间的相互作用。
它们的能力局限于线性函数。
为了拓展线性模型以表示非线性函数,我们有两种方法:
-
将线性模型作用在一个非线性输入\(\phi (\boldsymbol x)\)上。注意不是逻辑回归的\(\sigma\)函数,那是作用在输出上的。
-
核技巧,隐式地使用\(\phi\)映射。
因此核心就是\(\phi\)映射的选取。有以下两种方法:
-
使用一个通用的\(\phi\),如无限维的高斯核(对应无限维空间上的点积),可以隐式地用于基于RBF核的核机器上。
通常只基于局部光滑原则,并且没有足够的先验知识来解决高级问题。因此泛化能力往往不足。 -
手工设计。不同领域之间很难迁移tranfer,设计时间也很长。
显然上述两种方法都有很大的局限性。为此,我们利用深度学习的方法学习\(\phi\)。
我们设模型为:
现在有两种参数需要学习。\(\boldsymbol \theta\)与映射\(\phi\)相关,\(\boldsymbol w\)用于将\(\phi(\boldsymbol {x;\theta})\)映射到输出。
以上是深度前馈网络的例子,其中\(\phi\)定义了一个隐藏层。
显然,这样做放弃了训练问题的凸性,但利大于弊。\(\boldsymbol \theta\)是通过学习算法实现的。
并且,这种方法可以涵盖前两种方法,只需要对函数族\(\phi(\boldsymbol {x;\theta})\)进行限定。
6.1 前馈网络实例:学习XOR
XOR问题看似很简单:我们完全不需要关心统计泛化,只需要拟合训练集。
训练集中只有4个点(向量):
尽管是离散点,我们仍可将其归为回归问题,并采用MSE损失函数。
对于二进制数据建模,MSE通常不是最佳(后叙),这里只是为了简单。
因此有代价函数:
其中模型采用线性模型:
我们可以直接使用正规方程,得到闭解。该解下\(J\)最小。解为:
即:无论输入是什么,都输出0.5!
我们分析一下原因:
-
当\(x_1 = 1\)时,XOR在\(x_2 = 0\)时为1,因此函数应该随着\(x_2\)减小而增大。
-
当\(x_1 = 0\)时,XOR在\(x_2 = 1\)时为1,因此函数应该随着\(x_2\)增大而增大。
这对线性模型而言是一个矛盾!因为\(x_2\)的系数是固定的。\(x_1\)同理。
由对称性,系数最终停在0.5。
解决这一问题的其中一种方法是:让一个新的模型,学习一个不同的特征空间,并且此时线性模型可以表示解。
见P107图右。\(h_1\)和\(h_2\)是从\(x_1\)和\(x_2\)映射得到的非线性特征。显然此时线性模型是有解的。
具体是怎么实现的呢?
我们引入一个简单的前馈神经网络,只有一层隐藏层,包含两个单元,见P108图。表示为:
我们可以隐约察觉到:隐藏层实现非线性映射,把线性特征映射为非线性特征。输出层是对非线性特征的线性模型,以最终求解。
那么非线性函数是什么呢?
大多数神经网络,都在仿射变换以后,通过一个激活函数activation funtion来实现。具体而言就是:
激活函数通常是对向量中的每一个元素起作用。在现代神经网络中,通常使用整流线性单元rectified linear unit或称为ReLU:

如图,ReLU函数实际上非常接近线性函数,因此在分段上保留了线性模型的优点:易于使用梯度优化方法。
现在我们直接给出XOR问题的一个解。
整个网络为:
其中注意,激活函数是对每个元素起作用的,因此是和\([0,0]^T\)相比。
解为:
将输入\(\boldsymbol X\)代入:
新特征为:
分析一下。四个点被映射到新的四个坐标,正是P107图所示!
最后要说明的是,实践中我们常使用梯度下降法。梯度法会得到XOR问题的其他等价解,但通常不会得到零误差的解。
6.2 基于梯度的学习
线性模型和神经网络最大的区别:神经网络的非线性,导致大多数我们感兴趣的代价函数,都变得非凸。
相比之下,逻辑回归或SVM可以采用凸优化,保证全局收敛。
显然,非凸损失函数的随机梯度下降,对参数的初始值特别敏感。
对于前馈神经网络,将所有的权重值初始化为小随机数是很重要的。参数初始化在第八章介绍。
我们暂时只需要知道:训练算法几乎总是基于梯度方法。
关于梯度下降的改进,在5.9节我们学习过随机梯度下降方法,在4.3节我们学习过:利用二阶导信息调整学习率以更快地下降(避免来回跳跃)。
现在,我们把基于梯度的学习方法,在神经网络背景下重温。
代价函数
代价函数基本没有变化。
如果我们简单地使用最大似然原理,那么我们将会使用交叉熵作为代价函数。
线性模型中常用权重衰减方法正则化,这在深度学习中同样是最流行的。更高级的正则化策略将在第七章介绍。
方案1. 使用最大似然,学习条件分布:
代价函数就是负对数似然:
上式还可以进一步简化,如在5.1.1节中,由于分布是高斯分布,因此可以提出一些常数项,变成了MSE的形式。即当时我们有结论:
对于线性回归,最大化关于w的对数似然,和最小化MSE是等价的。
使用负对数似然有一个潜在的好处。
在设计神经网络时,我们通常要求:代价函数的梯度必须足够大,以较好地引导学习算法。
而饱和的激活函数会破坏这一目标。很多输出单元都会包含一个指数函数,其自变量为负较大值时,会造成饱和。
而负对数似然中的对数函数,可以消除某些输出单元中的指数效应。后叙。
在实际应用交叉熵代价函数时,会遇到一个问题:它通常没有最小值。
比如,在\(p_{data}(y|x)\)非零处,\(p_{model}(y|x)\)很小,则会导致交叉熵趋于负无穷。
第七章提供的正则化技术,可以修正这一问题。
方案2. 直接从海量数据中学习条件统计量,而无需学习数据分布:
参见P112。意思就是,如果我们把学习模型参数,认为是学习特定的函数,那么我们就可以把代价函数看作一个泛函。
因此,对代价函数,求关于\(f\)的最小值,将会得到某个特定的函数解。该函数就是我们的model。
这样,模型就可以避免学习整个概率分布\(p_{data}\)让代价函数最小。
过程需要用到变分法calculus of variations,这在19.4.2节讨论。
我们会发现,如果以MSE为代价函数,那么最优函数\(f^*\)将会是均值函数:
这个结果可以理解。最优模型输出的是预测值的加权平均。
该结论告诉我们,如果我们能得到大量(理论上应是无穷)源于真实数据分布的样本,那么我们只需要简单地计算加权平均近似期望即可,而不需要真正拟合出\(p_{data}(\boldsymbol {y|x})\)。
如果代价函数改为一阶范数,又称为平均绝对误差mean absolute error,那么最优模型将输出预测值的中位数。
值得一提的是,如果数据不够多,那么我们还是老老实实用最大似然法吧。
无论代价函数取均方误差还是平均绝对误差,在使用梯度优化方法时都效果不佳,原因就是输出单元会饱和,梯度过小。因此KL散度再一次占据上风。
输出单元
代价函数的选择,与输出单元的选择紧密相关。
通常我们会使用数据分布和模型分布之间的交叉熵,因此输出单元的选择,将决定交叉熵的函数形式。
在本节中,我们假设前馈网络为输出层提供了一组隐藏特征:\(\boldsymbol h = f(\boldsymbol {x;\theta})\)。
用于高斯输出分布的线性单元
对于高斯分布的输出,我们往往采取基于简单的仿射变换的输出单元。我们直接称之为线性单元:
采用线性单元的好处是:易于梯度优化。因为每一个参数的偏导数都是常系数。
例子在前面一章已经提到。我们知道,如果采用高斯模型(也就是输出分布是高斯分布),那么对于线性回归,最大化关于\(\boldsymbol W\)的对数似然,和最小化MSE是等价的,会得到相同的参数估计。说白了,估计参数\(\boldsymbol W\)就是估计高斯模型的均值\(\boldsymbol {\hat y}\)。
高斯模型的协方差矩阵也可以学习,这在最后一节介绍。
用于Bernoulli输出分布的sigmoid单元
对于二分类问题,我们要让输出介于0、1之间,因此采用sigmoid输出单元。图和性质见3.10节。
sigmoid输出单元包含两个部分:
-
线性层
\[z = \boldsymbol {w^Th} + b \] -
sigmoid激活函数
\[y = \sigma(z) \]
sigmoid函数只是其中一种将\([-\infty,+\infty]\)映射到\([0,1]\)的非线性函数。
至于为什么考虑使用sigmoid,可以参见这篇博客。
如果使用sigmoid输出单元,损失函数配合最大似然准则将好处多多。
我们常用负对数似然,即损失函数记为:
若输出单元采用sigmoid输出单元,即:
其推导方式(一种解释)见P114,y是label,z是sigmoid函数的输入(注意未限制在0和1之间)。
代入得:
直接从函数形式可以看出:
-
当答案正确时,即\(y = 0\ \&\ z >> 0\)或\(y = 1\ \&\ z << 0\)时,\((1-2y)z\)才会取到较大负值,代价函数因此饱和。
-
当答案(严重)错误时,\((1-2y)z \approx |z| >> 0\),代价会非常高。
代价函数关于z求导(chain law其中一步),结果近似于\(sign(z)\),因此梯度下降会很快。
如果我们使用其他损失函数,如均方误差,那么无论答案正确还是错误,梯度都会很小(中间情况反而很大),严重影响训练速度。因此,最大似然基本上是sigmoid输出单元的最佳组合。
最后,sigmoid函数的返回值可能非常接近0,要避免下溢问题。因为最后可能会取log函数。
用于Multinoulli输出分布的softmax单元
相较于二分类问题,多分类问题常采用softmax函数。
当我们想表示一个具有n个可能取值的离散型随机变量的分布时,都可以使用softmax函数:
其中\(z_i = \log \hat P(y = i | \boldsymbol x)\)。
这沿用了sigmoid输出单元对Bernoulli分布的解释,即指数化+归一化。
同理,指数化为对数似然提供了好处,log抵消了exp:
第一项显然不会饱和;第二项会强烈惩罚那些错误答案,因为没法和第一项相抵消。
和sigmoid函数一致,如果不采用对数似然,softmax函数将会不起作用,尤其是平方误差。
具体而言,如果不使用对数抵消softmax中的指数,那么梯度将在极端情况下消失(主要指误差很大时)。
为了缓解上述极端的\(\{z_i\}\)导致的梯度消失问题,我们可以使用下面的数值优化方法,证明很简单:
softmax输出的成功之处,在于创造了一种相互竞争的环境。
由于归一化,因此它们存在约束:总和为1。一者增大,一定有另一者减小。
如果有一者大得远超众人,那么其softmax输出就会接近1,其余输出都会接近0。这种奇妙的竞争结果称为赢者通吃winner-take-all。
显然,这种归一化输出类似于前面学过的one-hot向量。
不同的是,one-hot向量是argmax函数的输出,即最大的z才会得到1,其余都得0。
而argmax函数显然是不可微的,但softmax函数是连续可微的。因此'softargmax'才更加准确,但我们不这么说。
其他输出类型**
由于多见离散情形,因此sigmoid和softmax输出单元是最常用的。最大似然原则是它们的最佳拍档。
一般而言,如果我们定义了一个条件分布\(P(\boldsymbol {y|x;\theta})\),那么最大似然准则建议我们使用负对数似然,即将\(-\log P(\boldsymbol {y|x;\theta})\)作为代价函数。
回到前面的高斯输出模型。
简单情况下,我们假设方差是一个常数,仅学习均值。
更一般的情况是,我们设立精度参数\(\beta = \frac{1}{\sigma^2}\)。这种模型称为异方差heteroscedastic模型。
相比之下,如果我们使用\(\sigma\),会涉及除法,在零附近任意陡峭。
尽管大梯度下降快,但会不稳定。
注意,我们必须保证高斯分布的协方差矩阵是正定的。
此外,我们经常需要执行多峰回归multimodal regression。
如P119图,输出\(y\)在\(x\)较大时有两个差异较大的峰值。
此时常用的方法是混合组件,前面已经提及。
将高斯混合作为其输出的神经网络,通常被称为混合密度网络mixture density network。
有报告指出,基于梯度的优化方法对于混合高斯模型可能不可靠。原因是当方差较小、梯度较大时,数值不稳定。解决办法有梯度截断clip gradient和启发式缩放梯度。
6.3 隐藏单元
这一节是前馈神经网络独有的问题,也是一个研究活跃但无太多理论指导的问题。
整流线性单元及其扩展
整流线性单元使用激活函数\(g(z) = max\{0,z\}\)。
Relu单元是隐藏单元的一个较好的通用选项。
虽然Relu函数在原点不可微,但由于代价函数极难取到局部最小值,因此使用效果也不错。
整流线性单元处于激活状态时,其一阶导处处为1,梯度不但大而且保持一致。
如果作用于仿射变换之上:
在初始化时,可以将\(\boldsymbol b\)的所有元素都设置成较小的正值,如0.1。
这样做的好处是,整流线性单元很可能在一开始就对训练集中的大多数输入呈现激活状态。
整流线性单元的一个缺点是:对于零样本,通过基于梯度的方法是无法激活的。为此我们引入拓展:
-
绝对值整流absolute value rectification:\(g(z) = |z|\)。
多用于图像中的对象识别。特别是对象特征具有输入照明极性反转不变性时,该拓展非常有用。 -
渗漏整流线性单元Leaky ReLU:左侧梯度是一个较小的值,如0.01。
-
参数化整流线性单元parametric ReLU:该梯度是一个要学习的参数。
整流线性单元和它们的这些拓展,都是基于一个原则:如果它们的行为更接近线性,那么模型更容易优化。
除了深度线性网络,循环网络也借鉴了这一思想。
如LSTM,通过求和在时间上传播信息。这就是一个特别直观的线性激活。
Logistic sigmoid与双曲正切函数
在引入整流线性单元前,大部分神经网络都在使用这两种激活函数:
二者关系紧密:
Sigmoid单元作为输出单元的缺点,在这里同样存在。
只有当\(z\)接近0时,sigmoid单元才会对输入强烈敏感。
当sigmoid单元作为输出单元时,我们可以找到合适的代价函数,来抵消其饱和性,因此其可以作为输出单元,与基于梯度的学习方法相兼容。但作为隐藏单元,我们不推荐。
在循环网络、许多概率模型以及一些自编码器中,有一些额外的要求使得它们不能使用分段线性激活函数。此时sigmoid单元就派上用场了。
相比之下,tanh函数比sigmoid函数表现得更好。 tanh在0附近近似于单位函数:

因此,如果我们能让激活保持得比较小,模型就会表现得像线性模型一样,因而更好训练。
当然还有其他隐藏单元,如softmax单元(开关),径向基函数RBF(模板不匹配时几乎都饱和为0,很难优化),softplus函数(尽管被看做是整流线性单元的优化,但实验表明效果反而不如整流线性单元)和硬双曲正切函数hard tanh(有界的)等。
6.4 架构设计
神经网络设计的另一个关键点是确定其架构architecture。
一般而言,更深层的网络能够对每一层使用更少的单元数和更少的参数,泛化能力也更好,但也更难以优化。
对于一个具体任务,理想的架构必须通过实验,观测在验证集上的误差而找到。
根据机器学习的知识,如果我们需要学习非线性函数,那么我们就要提供一类包含该特定非线性函数的函数族。
幸运的是,根据万能近似定理universal approximation theorem:具有隐藏层的前馈网络,提供了一种万能近似框架。
具体来说:一个前馈神经网络,如果具有线性输出层,以及至少一层具有任何一种“挤压”性质的激活函数(如sigmoid)的隐藏层,并且有足够数量的隐藏单元,那么它可以以任意精度近似:从一个有限维空间到另一个有限维空间的Borel可测函数。
定义在\(\mathbb R^n\)的有界闭集上的任意连续函数都是Borel可测的。
但我们会遇到两大问题。第一,优化算法可能找不到用于期望函数的参数值,因为定理没有告诉我们网络究竟需要多大,甚至有可能大得无法实现。第二,训练算法可能因为过拟合而选择了错误的函数。
P125图6.7告诉我们,如果网络不够深,即使增加参数数量,训练效果也很难得到提升。
到目前为止,我们都把神经网络描述成简单的链式结构。
实践中还有很多复杂的结构,如卷积神经网络。
在一些结构中,层之间可以跳跃,即从第i层跳跃到i+2层。
这样使得梯度可以更快地从输出层传递到前面的层。
在一些专用网络中,层与层之间的连接并不多,输入层中的单元可能只连接到输出层单元中的某一个子集。
如卷积神经网络,其使用了对CV问题非常有效的稀疏连接专用模式。
6.5 反向传播和其他微分算法
基于梯度的优化方法,需要根据标量代价函数\(J(\boldsymbol \theta)\)计算梯度。
反向传播back propagation算法,就是一种通过反向流动,计算梯度的方法。
利用chain law计算梯度的计算代价非常高。BP算法可以降低计算成本。
当然,一些计算其他导数的任务,BP算法同样适用。
BP算法还可以用于输出向量的网络。这里我们只讨论单输出网络。
计算图
计算图computational graph可以帮助我们精确描述BP算法。
即使输出是向量,我们也画成一个节点。一个节点就是一个变量,可以是任意类型。
图例见P127。
Chain law
设\(\boldsymbol x \in \mathbb R^m , \boldsymbol y \in \mathbb R^n, \boldsymbol y = g(\boldsymbol x), z = f(\boldsymbol y)\),则有:
我们借助Jacobian矩阵,会得到更加简洁的向量写法:
BP算法的实现(待补充)
简单来说,许多子表达式可能在梯度表达式中出现多次。
我们反向计算,保存相同的计算表达式的结果,就可以避免重复计算。
当然,当内存受限时,正常使用chain法则可以减少内存使用。
(P131-139待补充)
9. 卷积网络
卷积网络convolutional network,也叫卷积神经网络convolutional neural network, CNN,是一种专门用来处理具有类似网格结构的数据的神经网络。
如时间序列数据,可以看作是一维网格;又如图像数据,是二维像素网格数据。
卷积是一种特殊的线性运算,而卷积网络是指那些至少在网络的一层中使用了卷积运算的神经网络。
9.1 卷积运算
物理意义
卷积的物理意义有一个经典的解释:一个拳击手揍一个胖子。
假设t时刻的权重为加权函数\(w(t)\),拳击手t时刻的击打输出为\(x(t)\),则胖子t时刻脸的肿胀程度\(s(t)\)可以这样平滑估计:
\(x\)通常叫做输入input,\(w\)通常叫做核函数kernel function。输出有时叫做特征映射feature map。
我们更常用离散形式的卷积:
在机器学习应用中,输入通常是多维数组,我们称之为张量;核函数通常是由学习算法优化得到的多维数组的参数。
卷积的可交换性
卷积是可交换的commutative:
可交换性需要我们对核函数进行翻转flip。
一定要注意,可交换性中\(m,n\)必须从负无穷到正无穷遍历,即必须是无限求和。只是我们规定:数组外的无穷多个点皆为0。
因此卷积往往对应着一个非常稀疏的矩阵,因为核通常要远远小于输入图像。
怎么理解可交换性呢?
回忆一维离散卷积,\(g(\tau)\)先翻转,然后平移\(t\),再和\(f(\tau)\)逐点相乘。因此\(t\)是指位移,效果当然是对称的。
二维同理,\(i,j\)分别是水平和垂直位移。
互相关函数
虽名为卷积,但我们实际操作的往往是互相关函数cross-correlation:
许多机器学习库中的卷积,实际实现的就是互相关。
由于\(i,j\)仍然是指水平和垂直位移,因此仍是可交换的。
单独使用卷积的情况很少见。卷积经常与其它函数一起使用,因而通常是不可交换的。
9.2 使用卷积的动机
卷积运算内涵三个重要思想,以帮助改进机器学习系统:稀疏交互、参数共享和等变表示。
稀疏交互
在传统的神经网络中,由于采用的是矩阵乘法,因此每一个输出单元和每一个输入单元都产生交互。
而卷积网络具有稀疏交互sparse interactions(稀疏连接sparse connectivity或稀疏权重sparse weights)的特征。
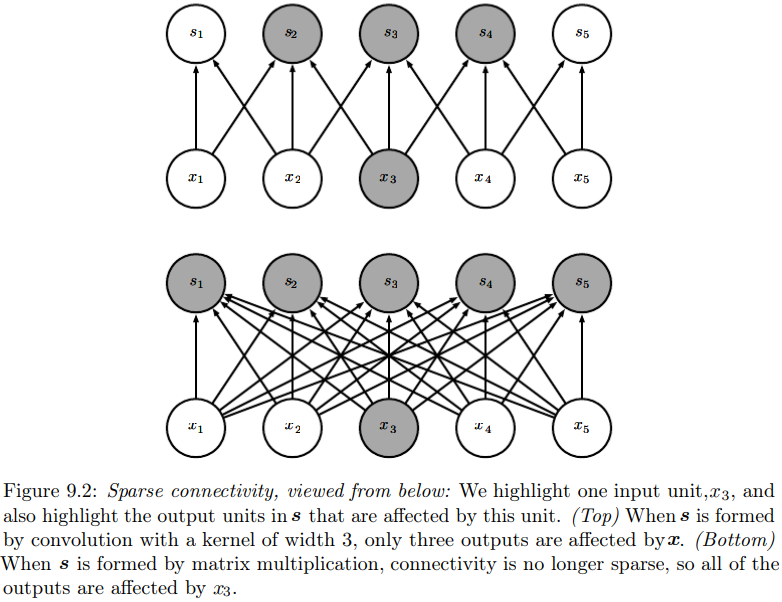
见P204图。下图是矩阵乘法连接图,上图是稀疏连接图。
例如,我们可以通过只占用几十到几百个像素点的核,来检测一些小的、有意义的特征,如图像边缘。
而原图像可能有成千上万的像素点,如果采用矩阵乘法,则每一个输出都要和所有像素点产生交互。
显然,稀疏交互即减小了存储量,也提高了统计效率。
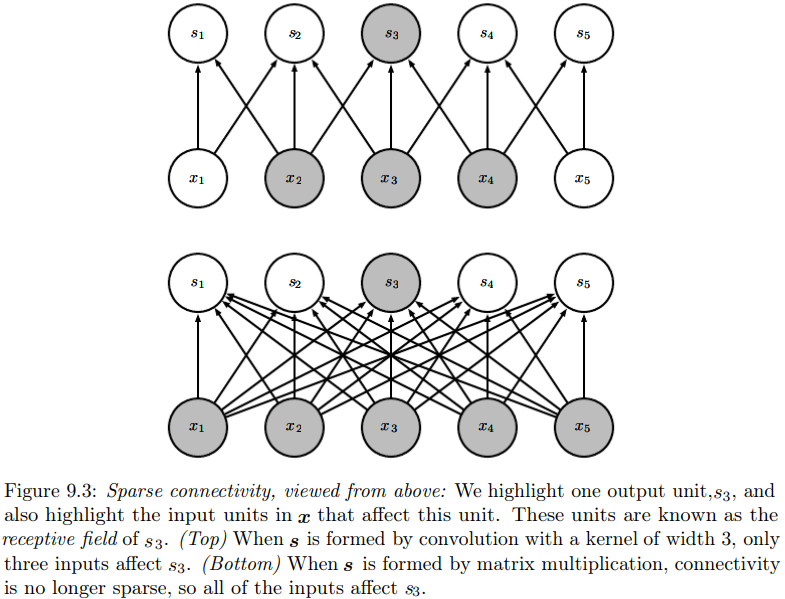
P205上图解释了接受域receptive field的概念。输入单元\(x_2,x_3,x_4\)都是输出单元\(s_3\)的接受域。
稀疏交互会导致欠拟合吗?
在深度卷积网络中,处在网络深层的单元,将与绝大多数输入都间接交互,如P205下图。
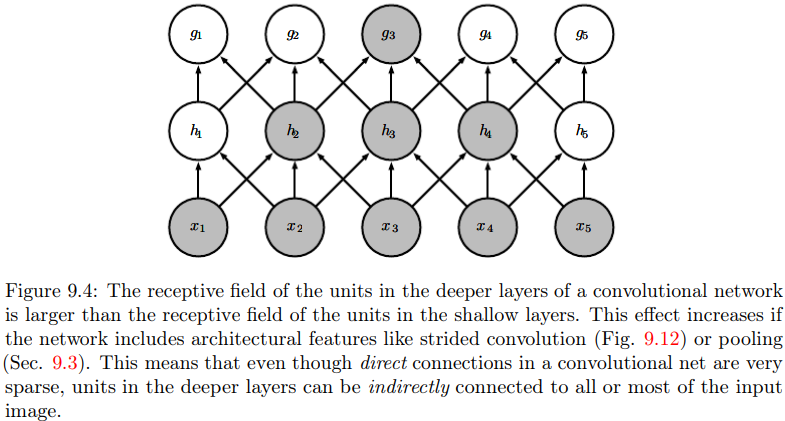
因此,深层单元的实际接受域是非常大的。
参数共享
参数共享parameter sharing是指在一个模型中的多个函数使用相同的参数。
在传统的神经网络中,权重是被独立使用的。
而在卷积神经网络中,我们只需要学习一个参数集合,可用于所有输入位置。
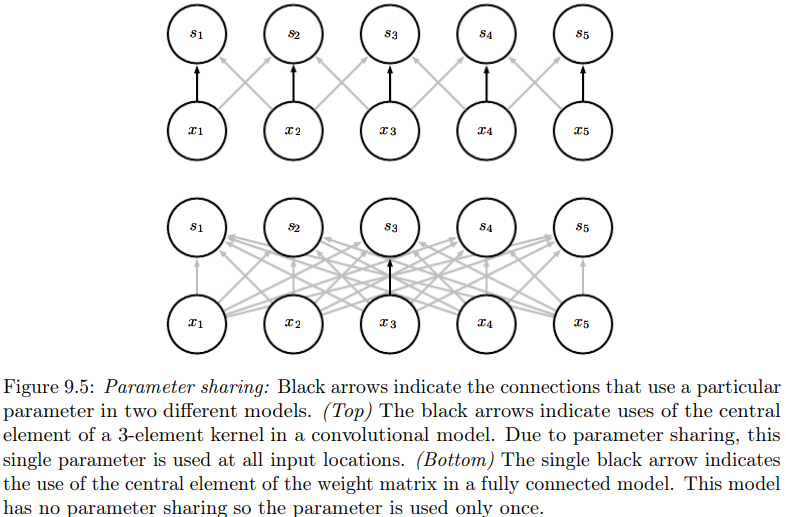
如P206上图,每一个输入位置的3元素核的中央元素是共享的。
个人理解,意思就是相同的核!
这样虽然不改变运行时间,但极大减小了存储量。
但也有时候,我们不希望进行参数共享。
参数共享多用于:同样的特征出现在图像的多处。如边缘检测,相同的边缘特征在图像中会多次出现。
说白了,我们想利用该特征的等变表示,即默认目标函数应具有平移等变性质,见下一节。
但是,我们如果希望提取出图像的各种不同的特征,那么一般不采用参数共享。
说白了,我们应该换核了!
等变表示
如果一个函数满足输入改变时,输出也以同样的方式改变,那么该函数就等变的。
特别的,如果有\(f(g(x)) = g(f(x))\),那么就说\(f(x)\)对于变换\(g\)具有等变性。
参数共享使得神经网络层将具有平移等变equivariance的性质。
卷积对于平移变换是天然等变的,本质是互相关的时不变性。
然而,卷积对于其他变换并不是天然等变的,比如旋转和放缩,需要特殊的机制实现。后面讲。
9.3 池化
什么是池化
卷积网络中的一个典型层包含3级,见P208图9.7:
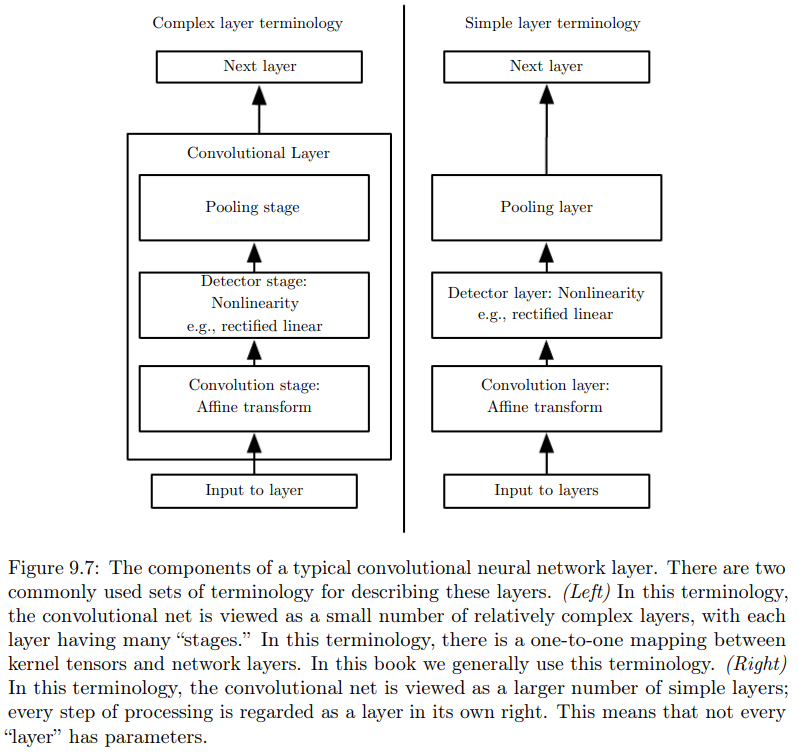
-
第一级,并行地计算多个卷积,产生一组线性激活响应。一般是加入一个偏置\(\boldsymbol b\),即仿射变换。
-
第二级,又称为探测级detector stage,每一个线性激活响应将通过一个非线性的激活函数,如ReLU。
-
第三级,通过池化函数pooling function来进一步调整这一层的输出。
池化函数使用某一位置的、相邻输出的总体统计特征,来代替网络在该位置的输出。
如最大池化max pooling函数,将相邻矩形区域内的最大值,作为输出。
其他常用的还有取平均值、\(L^2\)范数、距中心像素距离的加权平均等。
相同参数的卷积的池化,引入平移不变性
不管采用什么样的池化函数,其效果都是使得输入的表示近似不变invariant,即平移不变性。
见P208下图。由于采用了最大池化,尽管非线性层的输出向右平移了一个,但取最大值后,只有一半的输出发生了变化。
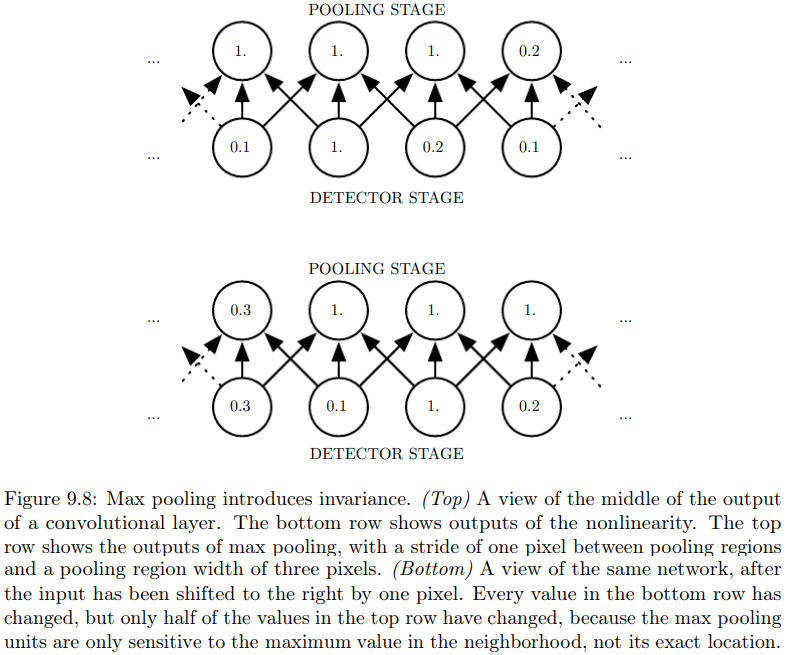
当我们关心某个特征是否出现,而不关心其出现的具体位置时,这种性质尤为重要。
比如,我们只想在图像中识别出人脸,或者,只想大致识别出:人的眼睛在左边有一个,在右边也有一个,那么平移不变性就是可行的。
但是,如果我们想知道两条边相交而成的拐角,那么这两条边的位置就非常重要,不能模糊化。
本质上,池化是一种很强的先验:我们希望学的函数,对于小量的平移,输出不变。
基于平移不变的假设,池化可以极大地提高网络的统计效率。
分离参数的卷积的池化,引入其他不变性
如果我们对分离参数的卷积的输出进行池化,那么我们将学得一种特殊的不变性。
见P209上图。我们想学习数字5特征的旋转不变形。
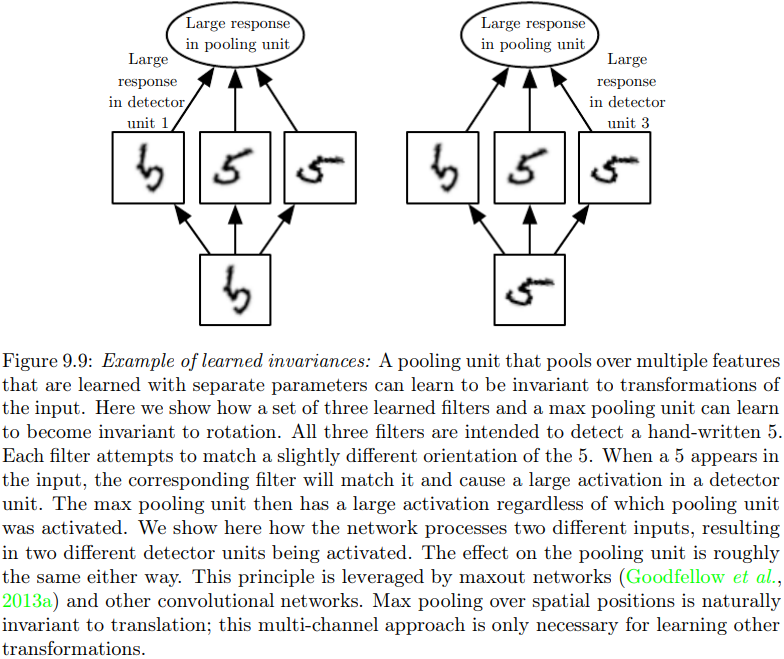
为此,我们将3个训练好的滤波器接入同一个最大池化单元。这3个滤波器分别可以检测出3个如图方向的数字5。
因此,无论输入数字5是以何种姿态出现,池化单元都会具有较大激活。
带降采样的池化
P209下图给出了一个进一步提高效率的方法。
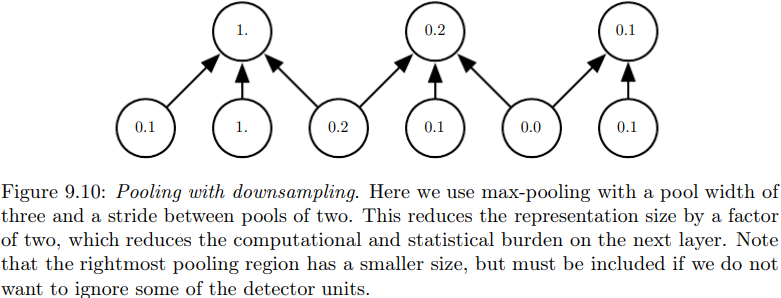
图中,池的宽度为3,步幅为2。通过这样的池化,下一层的输入(也就是池化单元数)可以从6个减少到3个。这样做不仅减小了对参数的存储需求,而且提高了统计效率。
池化用于处理不同大小的输入
池化可以用来处理不同大小的输入。
例如,我们希望对一些图片进行分类。在传统方法中,这些图片必须等大。但现在,我们可以调整池化区域的偏置大小,使得最终的统计特征数目一致,而与输入图片大小无关。换句话说,我们可以让网络具有大小可变、数量固定的池。
有的学者认为:可以先学习得到一个池化结构,再应用到全部图像中;还有的学者认为:对感兴趣的区域运行聚类算法,即对每幅图像,产生一个不同的池化区域集合。
9.4 卷积与池化分别都是无限强的先验
先验的强或弱,取决于先验中概率密度的集中程度,或者说熵值(不确定性)的大小。
弱先验具有较大的熵值,如高斯分布。在具有相同方差的所有概率分布中,正态分布在实数上具有最大不确定性。如果固定为高斯分布,那么显然方差越大,熵越大。
如果是一个无限强的先验,那么其会对一些参数的概率置零。无论数据对这些参数给予了多么大的支持,这些参数都是禁止被赋值的。
首先,卷积网络本身就内涵了强大的先验。其先验是:一个隐藏单元的权重,必须与其邻居的权重相同(参数共享)。这是平移等变性的基础。
其次,池化也是一个无限强的先验:每个单元都具有对少量平移的不变性。
需要注意的是,卷积和池化可能导致欠拟合。
无论是哪一种先验,都必须在前提假设合理时使用。
-
如果一项任务依赖于保存精确的空间信息,那么在所有特征上池化,将会增大训练误差。
对此,我们可以只在某些特征通道上使用池化。 -
如果一项任务会将输入中相距较远的信息合并,那么卷积的先验可能就不正确了。
9.5 基本卷积函数的变体
当在神经网络的上下文中讨论卷积时,我们通常是指卷积的各类变体。
并行卷积
首先,我们通常是指多个并行卷积。
这是因为,只具有单个核的卷积只能提取一种类型的特征。
我们希望网络的每一层能够在多个位置提取多种特征。
张量卷积
另外,输入不仅可以是实值网络,还可以是由一系列观测数据(向量)构成的网络。
例如输入一副彩色图像,一个像素点通常有红绿蓝三种颜色的亮度。在卷积处理时,我们通常把卷积的输入和输出,都看作3维的张量,最后一个维数用来索引通道。实际上我们用的是4维张量,因为还有第4维索引样本序号。
继上例,我们可以把多通道卷积表示为:
其中:
-
\(\mathbf Z\)是4维核张量\(\mathbf K\)和观测数据\(\mathbf V\)卷积的输出。
-
\(Z_{i,j,k}\):通道\(i\)中,第\(j\)行、第\(k\)列的输出。
-
\(K_{i,l,m,n}\):输出中通道\(i\)的某单元,输入中通道\(l\)的某单元,二者之间的连接强度。
\(m\)和\(n\)是互相关函数中的偏置,见\(V\)的脚标。 -
\(V_{l,j+m-1,k+n-1}\):通道\(l\)中,第\((j+m-1)\)行、第\((k+n-1)\)列的观测数据(如亮度)。
\(-1\)是因为在线性代数中,\(m\)和\(n\)通常从1开始,\(m-1\)则从0偏置开始。但在C和Python中,\(m\)和\(n\)从0开始。
要学会看这个式子。\(Z\)和\(V\)下标意义相同,\(K\)是中间媒介,所以需要索引两个通道。
注意要遍历输入通道\(l\)。
降采样卷积(带有步幅的卷积)
这和带有步幅的池化类似。
我们先看P213图。
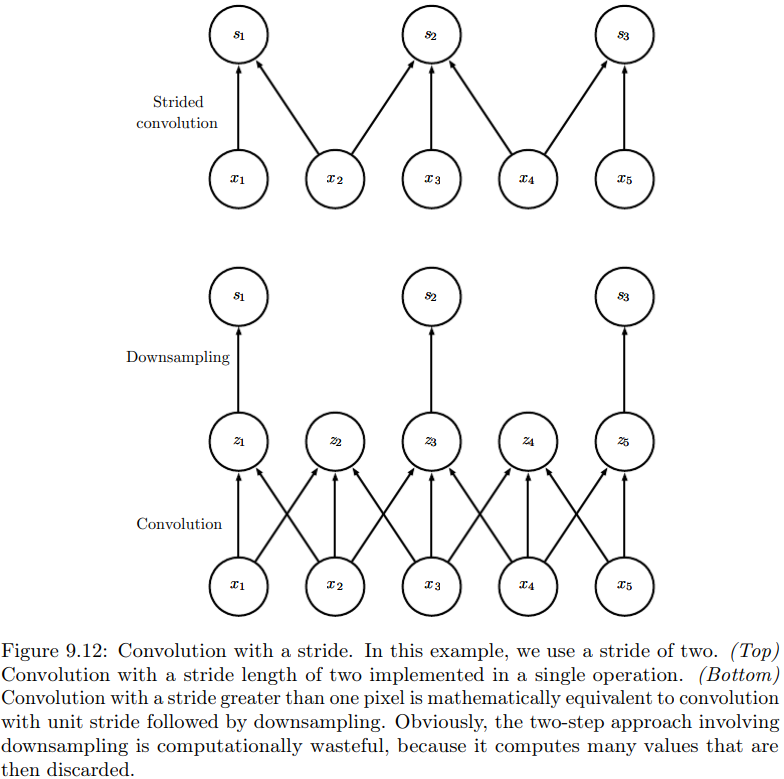
下图是先进行完整的卷积,然后再降采样。显然这样导致了许多计算冗余。
上图就是步幅卷积。可以看到,输出每隔两步才会出现一次,因此步幅stride为2。
当然,这样做虽然降低了计算开销,但提取的特征也会差一些。
设步幅为\(s\),则卷积变成:
主要是看起点。原来输出1对应的输入起点1,输出2对应的输入起点2,以此类推……
现在输出1对应的输入起点1,输出2对应的输入起点(2-1)×2,输出3对应的输入起点(3-1)×2……
当然,每个方向的步幅可以不同。
默认零填充
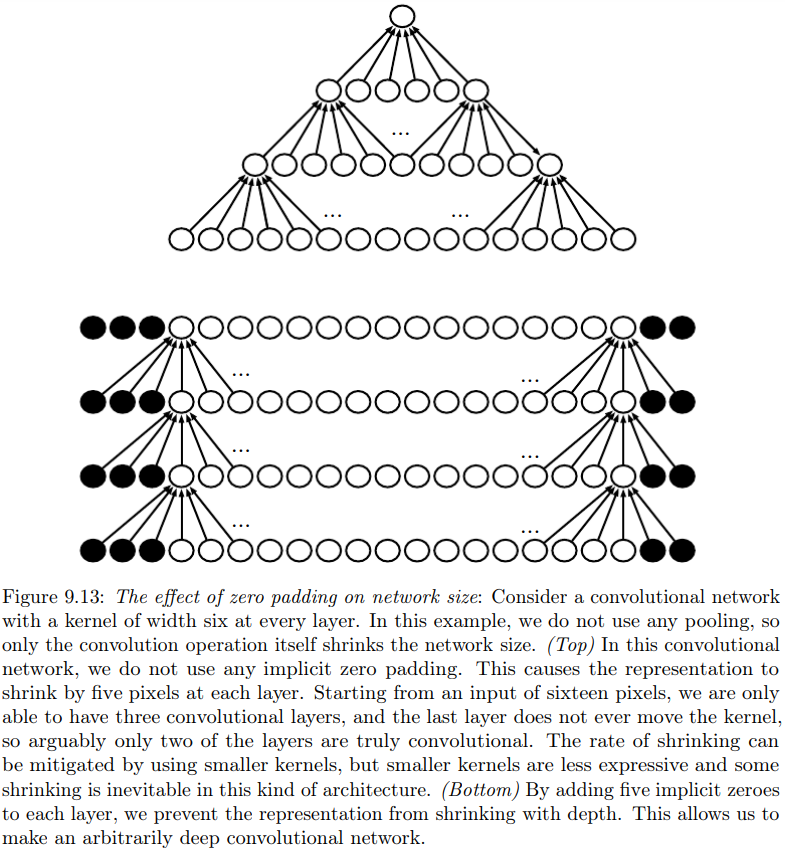
见P214图。我们使用宽度为6的核,不使用任何池化。
-
在上图中,由于输出不断减少,导致整个网络越来越小。
图中,每一个卷积核都只访问那些能包含完整的一个核的位置。这又称为有效valid卷积。
这是最严苛的情况,由于坍塌过快,深层网络很难实现。 -
在下图中,我们每一次都在两侧补零,保证网络不会坍塌。
填充的目的是保证输入和输出具有同等大小。这又称为相同same卷积。
但边界像素可能会欠表示,因为实际受很多0的影响,受输入像素影响较小。 -
还有一种更极端的情况:全full卷积,添加更多的0,保证在每个方向上,每一个像素被访问的次数都是相同的。输出层将会比输入更宽。
显然,卷积核在边界的表现将会更为糟糕。
如果我们不作补零操作,将面临二选一的局面:
-
网络空间宽度快速缩减。
-
选择一个小型核。
显然这两种情况都会限制网络的表示能力。
通常,零填充的最佳数量(测试集分类正确率最高)通常在前两种情况之间。
非共享卷积
有些时候,我们并不是真的想用卷积,而是想用一些局部连接的网络层。
它和一个具有小核的离散卷积运算很像,但并不共享参数。因此局部连接又称为非共享卷积unshared convolution。
P215图给出了三者的区别:局部连接、卷积和全连接。
局部连接只采用了卷积的稀疏交互特征,但没有共享参数。即便如此,局部连接也给神经网络带来了巨大的好处。
如果我们知道某个特征只是空间中一小块区域的函数,比如,眼睛只会出现在人脸的上半部分,那么我们的眼睛特征卷积只需要与上半部分的像素点进行交互即可。
补充一点,限制卷积或局部连接的通道关系,也可以降低计算成本,使得前向和反向传播更快一些。
如P216图,我们限制卷积网络的前两个输出通道,只与前两个输入通道交互,后两个只和后两个交互。
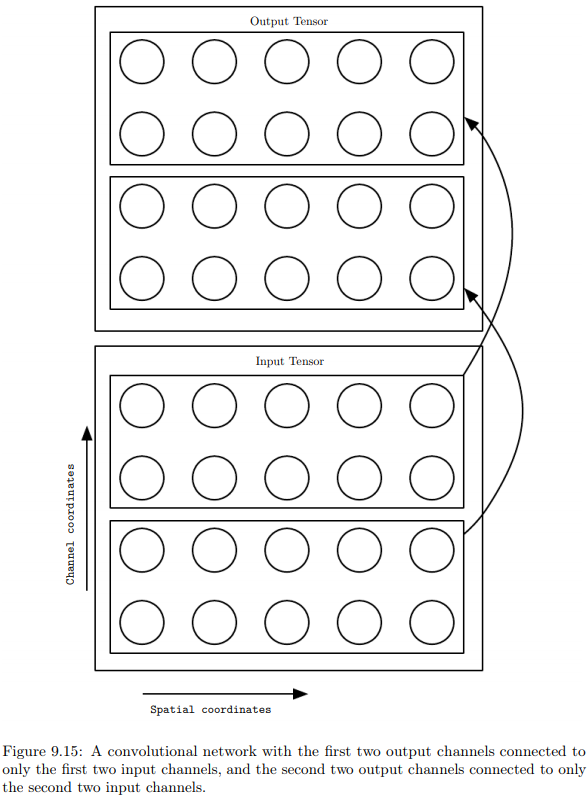
当然,这种通道限制是不会减小隐藏单元数目的(即特征数)。
平铺卷积
见P217图。所谓平铺卷积tiled convolution,折衷了卷积层和局部连接层。三者区别只在于参数共享。

-
局部连接层不存在共享参数;
-
平铺卷积层可以有\(t\)个不同的核,这里\(t=2\);遍历\(t\)个可用的核后,参数会循环;
-
传统(标准)卷积核相当于\(t=1\)的平铺。
我们应该能理解平铺卷积的好处。
如果用传统卷积,希望学习两种特征,那么我们就需要并行卷积,需要两倍于输出特征映射大小的存储和计算量。
如果用平铺卷积,就意味着相邻位置上具有两种滤波器,可以近似为在同一位置检测两种特征。因此参数增长得较少。
其代数表示为:
核需要多两个维数,是因为\(\mathbf K\)在每个方向上都有\(t\)种不同的核,即存在一个\(t×t\)的核的集合。
回忆我们之前,用最大池化引入旋转不变性的方法。
在这里,平铺卷积就可以实现3种姿态的检测,而不需要并行卷积。
卷积网络中的其他运算
参见P215~P217。P217最下面两个公式,其本质就是反向传播。
特别地,我们说一下偏置。在卷积输出以后,我们常加上一个偏置\(\boldsymbol b\),再进行非线性运算。
-
如果是局部连接,那么偏置是独立的;
-
如果是平铺卷积,那么偏置是循环的;
-
如果是标准卷积,那么偏置理论上应该是共享的,即一个通道对应一种偏置。
但是,我们也经常让偏置独立学习。尽管统计效率下降,但这样可以允许模型校正图像中不同位置的统计差异。
例如,当使用零填充时,图像边缘的探测单元可以采用较大偏置,以弥补较少的输入。
9.6 结构化输出
卷积神经网络不仅可以用来预测分类任务的类标签或回归任务的实数值,还可以用来输出高维的结构化对象。
例如,模型可以产生张量\(\mathbf S\),其中\(S_{i,j,k}\)是输入像素\((j,k)\)属于类\(i\)的概率。
一旦我们得到了这样的张量\(\mathbf S\),那么我们就可以进行图分割。
如果相邻像素对应于相同的标签,那么我们就可以将它们归为同一块区域。
进一步,我们也可以把卷积神经网络,用于最大化近似图模型,说白了就是将一整张图分类。
在分类问题中,我们可以单纯地产生一张低分辨率的标签网格,即利用维数降低这一“问题”。
9.7 数据类型
通道的内涵
卷积网络的输入通常包含多通道。例子见P219表格。
例如,彩色图像是一种二维数据,彩色视频是一种三维数据,但它们都是多通道数据,可以分为RGB三通道。
又例如,骨架动画描述人体三个关节的角度,那么其是一种一维数据(角度是标量),但分为3通道。
卷积核代表了某个输入单元和某个输出单元之间的连接强度,这两个单元可以不在同一通道上。
通道与等变性
由于参数共享,即一个模板(核)应用在同一张图片上,因此图像输入关于卷积运算,将具有两个方向上的平移等变性。
但如果三个通道的图像数据对换,由于通道间的核参数不共享,因此结果不具有等变性。
可变的输入尺度
卷积网络的一大优点是:它可以处理空间尺度可变的输入。
哪怕计算开销和过拟合都不是主要问题,卷积网络也因此大放异彩。
考虑一组图像,它们的高度和宽度都不尽相同。
如果采用固定大小的权重矩阵,我们还没有对应的建模方法。
但如果采用卷积网络:
-
核可以根据输入的大小,被使用不同的次数(即移动不同的次数)。
-
池化层的大小可以和输入成比例,使得池化输出数目是固定的。
9.8 高效的卷积算法
我们知道,两个信号的卷积的傅里叶变换,等于两个信号的傅里叶变换相乘。
因此,对于某些问题的规模,有时候频域操作再反变换会更快。
我们还可以考虑可分离性。
对于可分离卷积,标准卷积要比一维卷积的外积慢得多。
设核有\(d\)维,每一维都有\(w\)个元素,则前者复杂度是\(O(w^d)\),后者仅为\(O(w×d)\)。
9.9 随机或无监督的特征
通常,卷积网络的计算代价并不高。经过若干层池化以后,特征已经不多了。
但是,如果要学习特征,那么卷积网络训练将会非常耗时。
比如我们使用梯度下降执行有监督训练,每一步梯度计算,都需要完整地执行前向传播和后向传播。
不幸的是,卷积网络往往是庞大的。因此训练成本高昂。
减小卷积网络训练成本的一种方式是:利用无监督算法学习特征。
以下是3种方法,可以不通过监督训练而得到卷积核。
但值得说明的是,如今大多数卷积网络都是以纯粹的方式进行训练,即执行完整的前向、反向传播。
下述方法在2007-2013年曾经流行,因为当时标记数据很少,而且计算能力有限。
-
简单地随机初始化它们;
-
手动设计它们,比如设置每一核检测特定的方向或尺度的边缘;
-
无监督训练得到,如对小图像执行k均值聚类算法,将习得的k个中心的小图像,作为卷积核。
在得到全部训练集的特征以后(比如某个样本的一些特征被激活,另一些没有激活),再在特征和类别之间做有监督学习。
如果使用SVM或逻辑回归等方法,还有可能得到凸优化问题。
10. 序列建模:循环和递归网络
10.0 循环神经网络中的参数共享
回顾一下,卷积网络是专门用于处理网格化数据的神经网络,并且可以处理高分辨率或大小可变的图像。
而循环神经网络recurrent neural network, RNN是专门用于处理序列的神经网络,并且可以处理较长或可变长度的序列。
为了使模型拓展到不同形式的样本(这里指不同长度的序列样本)并进行泛化,参数共享是非常重要的思想。
反之,如果每个时间点的参数都不同,不仅不能处理变长序列(否则参数可能未定义),并且统计特性(强度)也不能在时间轴上共享。
提一下参数共享和池化的区别。
-
参数共享
- 参数共享主要用于单个卷积核,即针对单一统计特性,具有平移等变性。
如要检测单词apple,无论是序列'I have an apple'还是'Apple is mine',相同的卷积参数集都能奏效。 - 参数共享简化了参数数量,提高泛化能力和统计效率。
- 即使样本大小发生变化,参数由于是共享的,因此不需要额外学习。
- 参数共享主要用于单个卷积核,即针对单一统计特性,具有平移等变性。
-
池化
- 池化主要用于处理多个卷积核的输出或多个卷积的输出。
- 如果处理多个卷积的输出,可以用于处理不同尺度的样本;即输出层节点数量可以保持固定。
- 如果处理多个卷积核的输出,可以使得某种变换(如旋转)具有不变性。
循环神经网络也沿用了参数共享的思想。每一个时间步中使用相同的卷积核。
但还有所不同。
-
在卷积中,输出是相邻几个输入的函数。
-
在循环卷积网络中,输出的每一项,是其前一项的函数。
参数共享只是保证:输出的更新规则是相同的。这使得计算图可以很深。
有几点需要注意:
-
为了简单起见,本章RNN的目标是\(t\)时刻的序列\(\boldsymbol x^{(t)}\),包含时刻1到\(\tau\)。
-
实际情况中,RNN通常在序列的小batch上操作,并且batch中每一项的长度\(\tau\)可以不同。
-
\(t\)不一定指的是时间,也可以是序列中的位置。
-
RNN不仅可以用于一维(时间维),也可以用于二维的空间数据,如图像。
10.1 展开计算图
计算图在6.5.1节已经有了完整介绍。
本节,我们介绍展开unfolding计算图,其目的是得到包含重复结构的循环计算图。
实际上,展开不仅意味着结构重复,还意味着参数共享。
P229图就是一个例子,左、右两图是等价的。
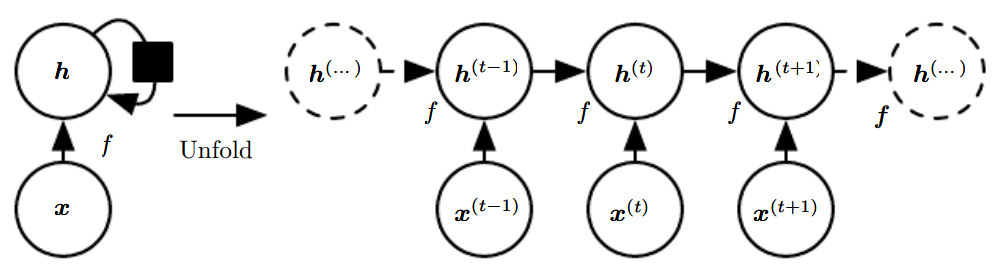
这是一个没有输出的循环网络,\(\boldsymbol h\)是隐藏单元。其典型表达式为:
典型的RNN会再加上输出层。
-
左图更强调物理结构,比如生物神经网络中的一个神经元。黑色方块代表延迟。
-
右图就是展开计算图,一个时间步就是一个变量,表示在该时间点组件的状态。
需要注意:
-
在本例中,展开图的长度取决于输入序列的长度。
因为如果序列长度为\(t_0\),也就意味着用于训练(计算最后一个时间步的梯度)的参数至少有\(t_0\)个。 -
实际训练中,输入序列长度可能会做一定的有损处理,即展开图可能不会这么长。
比如统计语言建模,我们往往采用前3个以内的词用于训练和预测,而不是所有历史词汇。
但也有最苛刻的情况,如自编码器,需要足够丰富的\(\boldsymbol h\)。 -
当模型学成后,(模型的)输入长度就是固定的,与序列长度无关。
这就意味着,该模型可以泛化到任意长度的输入序列。 -
每个时间步一般使用相同的参数(相同的转移函数),以减少参数量,实现参数共享。
10.2 循环神经网络
循环神经网络有3种经典的设计模型:
方案一. 见P230图,每个时间步都有输出(因为没有黑色方块延时!),隐藏单元之间有循环网络。
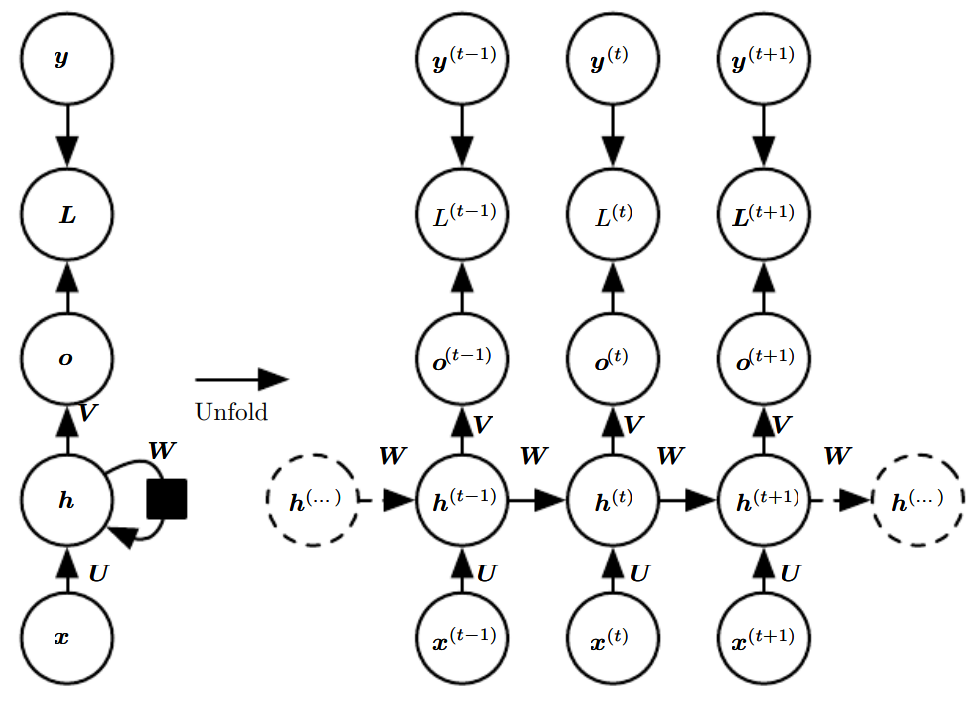
注意,我们假设每一时刻的输出\(\boldsymbol o\)是未经归一化的对数概率。
在\(L\)内部,我们才计算\(\hat {\boldsymbol y} = softmax(\boldsymbol o)\),然后与\(\boldsymbol y\)比较得到损失\(L\)。
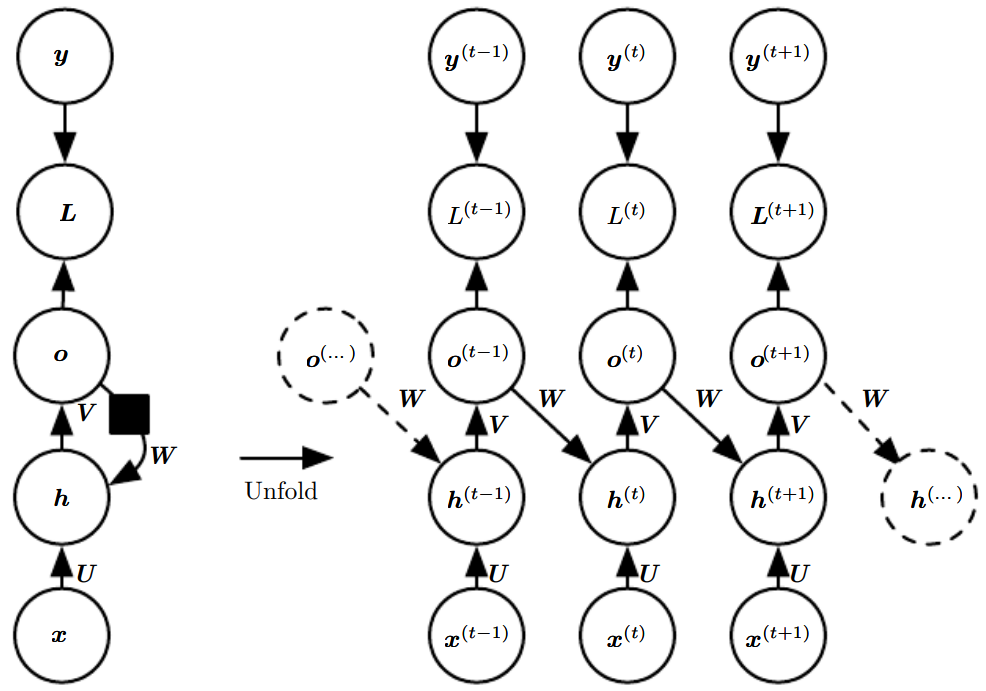
方案二. 见P231上图,每个时间步都有输出,但循环网络存在于当前时刻的输出\(o\),以及下一时刻的隐藏单元\(h\)之间,而不是隐藏单元之间。
方案三. 见P231下图。隐藏单元之间有循环网络,但只有最后一步有单个输出。
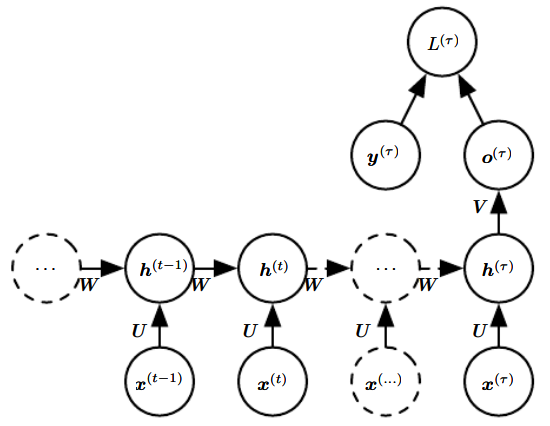
方案三将在后续小节介绍。
方案一是最典型的,贯穿本章。因此我们重点介绍方案一。
方案一:经典RNN
任何图灵可计算的函数,都可以通过这样一个有限维的循环网络计算。
因为由图灵机计算的函数是离散的,因此该网络模拟的函数是准确的,而不是近似。
因此,在这种意义上,方案一给出的循环网络是万能的。
从\(t=1\)到\(t=\tau\)的每一个时间步,其前向传播流程如下:
-
非线性激活单元的线性层(仿射变换):
\[\boldsymbol a^{(t)} = \boldsymbol b + \boldsymbol {Wh}^{(t-1)} + \boldsymbol {Ux}^{(t)} \] -
非线性激活函数,假设为tanh激活函数:
\[\boldsymbol h^{(t)} = tanh(\boldsymbol a^{(h)}) \] -
softmax输出单元的线性层(仿射变换):
\[\boldsymbol o^{(t)} = \boldsymbol c + \boldsymbol {Vh}^{(t)} \] -
softmax输出单元:
\[\hat {\boldsymbol y}^{(t)} = softmax(\boldsymbol o^{(t)}) \] -
损失函数为:
\[\begin{align}L(\{\boldsymbol x^{(1)},...,\boldsymbol x^{(\tau)}\},\{\boldsymbol y^{(1)},...,\boldsymbol y^{(\tau)}\}) &= \sum_t L^{(t)} \\ &= -\sum_t \log p_{model} (\boldsymbol y^{(t)}|\{\boldsymbol x^{(1)},...,\boldsymbol x^{(t)}\})\end{align} \]
理解:
-
给定长度为\(\tau\)的序列样本\(\boldsymbol x\)和相同长度的拟合序列\(\boldsymbol y\);
-
在当前参数下,模型会根据输入\(\boldsymbol x^{(1)},...,\boldsymbol x^{(t)}\),在每一个时间步\(t\)上,输出预测值\(\hat{\boldsymbol y}^{(t)}\),综合起来就是预测序列\(\hat {\boldsymbol y}\);
-
如果模型准确,那么该条件概率就很大;反之很小。这就是条件似然。
复习:
-
对于回归问题,我们常假设输出模型为高斯模型,即\(p(\boldsymbol y | \boldsymbol x) = \mathscr N (\boldsymbol y ; \hat {\boldsymbol y}, \boldsymbol I)\);
-
对于分类问题,我们常假设输出模型为Bernoulli(二分类)或Multinoulli(多分类)输出模型。
-
最大似然原则告诉我们,代价函数可以简单地设为输出分布的负对数似然,然后予以最小化。
-
对于前者,最大似然等价于最小化MSE,因此代价函数可以设为MSE;
-
对于后者,最大似然等价于最小化KL散度,因此代价函数可以设为交叉熵。
现在我们考虑反向传播。由损失函数可以看出:
-
如果我们要计算\(\tau\)时刻的梯度,就需要考虑\(\tau\)时刻到当前时刻的所有输入,计算需求大;
-
这种前向传播图是无法用并行方式计算的,无法简化;
-
每一个状态都要保留,内存需求高。
总的来说,这种反向传播方式的运行时间和内存代价都是\(O(\tau)\)。
这种方式又称为通过时间的反向传播back-propagation through time, BPTT。
方案二:输出循环网络和导师驱动过程
方案二又称为输出循环网络,因为此RNN的唯一循环,是从输出到隐藏层的反馈连接。
这种RNN功能上不如经典RNN,但支持并行运算。
先说不足。
首先我们要清楚一点,隐藏层\(\boldsymbol h\)的维数和信息量,通常要比输出\(\boldsymbol o\)大。
换句话说,\(\boldsymbol o\)通常缺乏过去的重要信息。
然而在该网络中,\(\boldsymbol o\)是允许传播到未来的唯一信息。
因此,RNN的能力大打折扣,只能表示更小的函数集合,不能模拟通用图灵机。
再说优点。
根据网络图,我们发现,当我们需要计算\(t_0\)时刻梯度时,我们不再需要计算\(t=1\)到\(t=t_0\)时刻的所有状态!
因为:我们可以用最理想的输出:标签\(\boldsymbol y\),来代替输出\(\boldsymbol o\)。这样的好处是:
-
我们不再需要计算参数了,因为\(\boldsymbol y\)是训练集附带的;
-
时间步被解耦了。当我们计算多个时刻的梯度时,我们可以并行计算!
这种训练方法叫做导师驱动过程teacher forcing。图解:
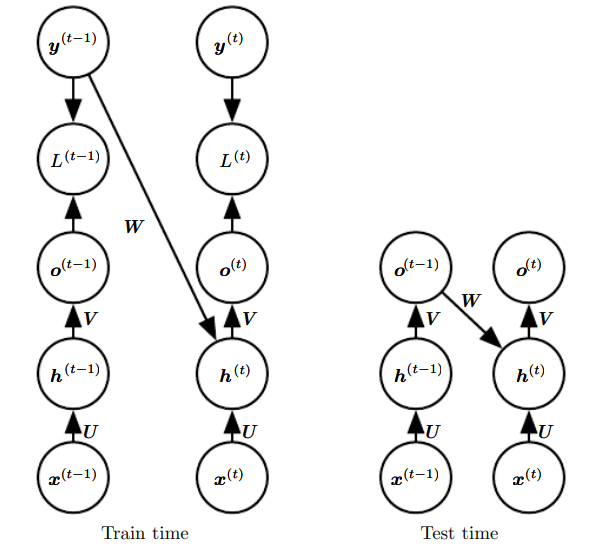
注意,这是一种训练技术,当测试时,正确反馈通常是未知的,因此需要上一时刻的输出作为反馈。
此时的损失函数不再是最大似然。我们以\(\tau =2\)为例,显然损失函数应为:
原条件似然函数将变成:
即模型的目标,应是最大化第一项:\(y^{(2)}\)的条件概率。
导师驱动是可行的,本质上是因为:RNN训练的实际上是转移函数,因此可以在真实值之间进行训练。
当然,导师驱动不仅可以用于该网络。只要上一层输出与下一层的计算相关,该方法都可以使用。
在某些网络中,BPTT必须使用,因为隐藏单元和前一个时间步有关,而不只是与输出有关。
最后,导师驱动也是有缺点的。训练期间网络看到的输入,与测试时看到的输入会很不相同。解决方法:
-
随机选择模式,要么是原始方法,要么是导师驱动模式。
-
同时使用两种模式,使网络从开环open-loop变为闭环,让网络具有预测未知输入的能力。
计算循环神经网络的梯度
我们简单地把反向传播算法推广即可。推导过程见P234。
基于上下文的升级版RNN
这一节,我们介绍最常见的两种RNN建模方式。
在最开始介绍的方案一中,循环网络仅存在于隐藏(状态)节点之间。
这样做的不足是:RNN仅能表示:在给定\(\boldsymbol x\)值的情况下,\(\boldsymbol y\)值彼此条件独立的分布。这里的\(y\)说的是label。
而我们知道,对同一个序列而言,其label往往也具有相关性。因此我们增加从真实反馈到隐藏层的连接:

优点:可以表示关于\(\boldsymbol y\)序列的任意分布。
缺点:输入、输出序列长度必须相同。10.4节将讨论如何打破这一限制。
之前我们讨论的都是:把向量序列:\(\boldsymbol x^{(t)}, t=1,...,\tau\)输入RNN。另一选择是:把单个向量\(\boldsymbol x\)输入RNN。
输入方法有:
-
在每个时刻,都作为一个额外输入。
-
作为初始状态,也即\(\boldsymbol h^{(0)}\)。
-
二者结合。
第一种最常用,如图:
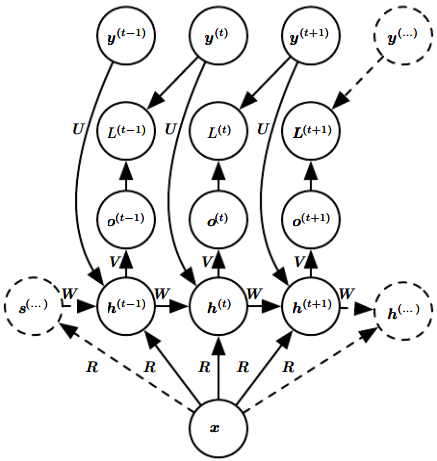
这种网络大有可为。比如,将单一图像作为输入,产生一系列描述图像的词序列。
既要保证描述准确,又要保证句法准确(词语连贯),并且是单输入,因此采用这种网络。
10.3 双向RNN
之前讨论的RNN都是单向的。但在很多应用中,我们要输出的\(\hat {\boldsymbol y}\)可能依赖于整体输入序列。
例如在语音识别中,由于存在连音等,当前发音可能和未来的序列信息有关。
如果当前词有两种及以上的合理解释,我们就需要向未来寻求帮助。
双向RNN应运而生。双向RNN发表于1997年,在之后的语音识别、手写识别和生物信息学等表现出色。
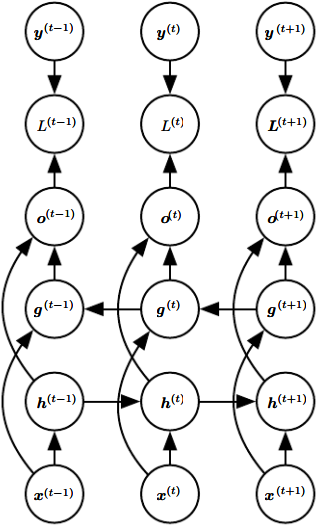
如图,双向RNN结合了从序列起点开始的RNN,以及从序列末尾开始移动的RNN。
两个RNN具有各自的状态节点:\(\boldsymbol h\)和\(\boldsymbol g\)。
输入\(\boldsymbol x\)同时作用于\(\boldsymbol h\)和\(\boldsymbol g\),而\(\boldsymbol h\)和\(\boldsymbol g\)又同时作用于输出单元\(\boldsymbol o\)。
这样,RNN就可以计算:同时依赖于过去和未来的,且对\(t\)时刻输入最敏感的表示。
还有一个优点:在前馈神经网络、CNN或典型RNN中,窗口大小往往是固定的;
而双向RNN可以自动提取\(t\)邻域内的最佳表示,因此不需要规定固定大小的窗口(如果参数关系弱,就相当于小窗口;参数关系强,就相当于大窗口)。
这个想法可以拓展至图像等。如果是二维输入(图像),那么我们可以用4个RNN,分别在4个移动方向上计算。
这样,整体RNN就能捕捉到大多数局部信息,并且依赖于长期输入的表示。
10.4 基于编码-解码的序列到序列架构
前面学的大部分RNN,都是将一个向量序列\(\boldsymbol x\),映射到等长序列\(\boldsymbol y\)。
此外,方案三是从序列到向量,10.2节给出了向量到序列的方法。
本节,我们要打破一个限制:如何令RNN输出不等长的序列。
这在许多场景中都很有意义:语音识别,机器翻译或问答等。尽管输入、输出可能长度相关,但往往不等。
解决这一问题的网络架构产生于2014年,并在翻译问题中取得了最佳效果。该构架称为编码-解码架构或序列到序列架构。如图:
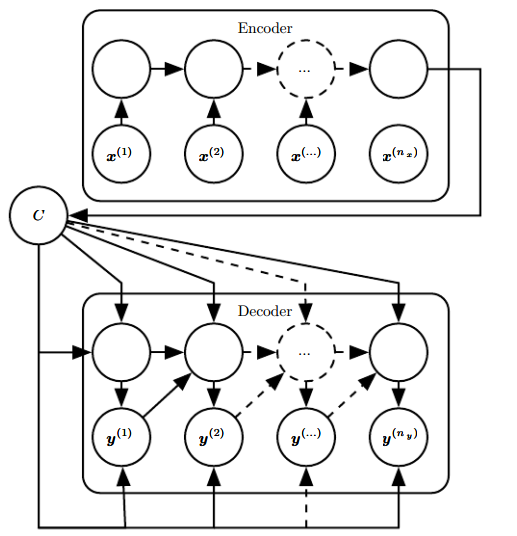
该构架的思想很简单:
-
输入input序列先输入编码器encoder或读取器reader。
-
编码器的最后一个状态\(\boldsymbol h^{(n_x)}\)是一个向量或向量序列,被称为上下文context, \(C\),一般为固定大小,作为语义概要。
-
\(C\)再输入解码器decoder或写入器writer,得到RNN的输出。
我们可以认为这是两个RNN。这两个RNN共同训练,以最大化:
其中\(n_y\)和\(n_x\)可以不同。
上下文既可以作为解码RNN的初始状态,也可以作用于所有隐藏单元,甚至还可以同时采用,如图。
该架构的明显缺点是:上下文的维度太小,可能难以概括语义,特别是长序列的。
有学者提出,让上下文的长度可变,或引入注意力机制attention mechanism,参见12.4.5.1节。
10.5 深度循环网络
我们现在讨论网络的深度。
根据前面所学,我们在输入-隐藏、隐藏-隐藏、隐藏-输出之间,都采用的浅层变换。
这些浅层变换通常由一个仿射变换和非线性表示组成。
实验表明,增加RNN的深度大有裨益。下图给出了三种方法:
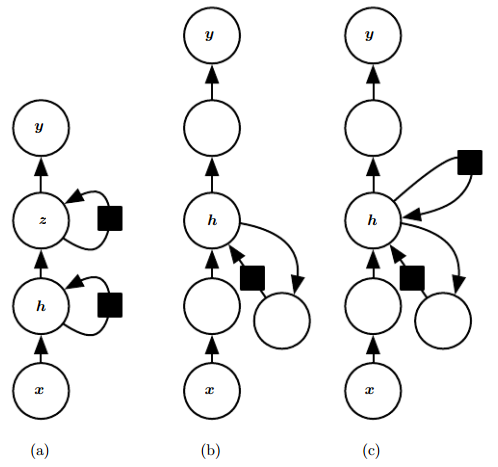
-
如图a,将一个隐藏层拓展到两个,表示能力增强。
-
如图b,在输入-隐藏、隐藏-隐藏、隐藏-输出之间,引入更深的计算(如MLP),延长最短路径。
-
如图c,引入跳跃连接,以缓解路径延长效应。
10.6 递归神经网络
递归神经网络recursive neural network是循环神经网络RNN的拓展,但二者是不同的。
它被构造成树状而不是RNN的链状,如图是监督学习的情况:
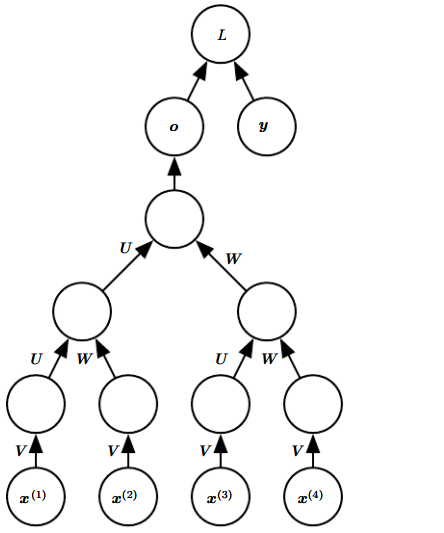
个人感觉,递归网络在结构上更像深度前馈网络,但在参数设计上更像RNN。由于没有卷积操作,因此和CNN差别较大。
递归网络的主要优点有:
-
对于长期依赖问题,RNN需要比较深;相比之下,递归网络可以将深度从\(\tau\)缩减至\(O(\log \tau)\);
-
可用于学习推论,如自然语言处理和计算机视觉。
一个悬而未决的问题是:人们希望学习器能自行推断出适合于给定输入的树结构。
10.7 长期依赖的挑战
参见8.2.5节。
当计算图变得很深时,模型会难以获取先前的信息。
即:经过多次传播后,梯度倾向于消失(大部分情况)或爆炸(少数情况,但后果很严重)。
梯度消失的根本原因是:大量的非线性函数组合,导致组合函数高度非线性。
高度非线性函数,可能会存在大量微小的导数和少量极大的导数,如P244示例。
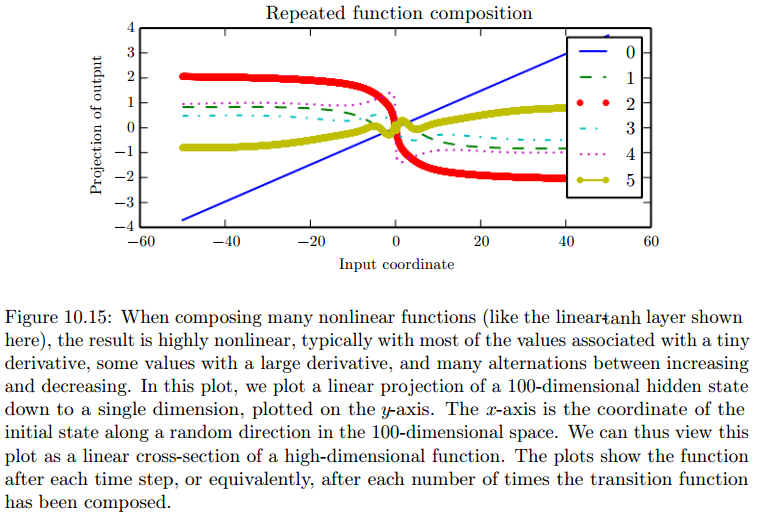
进一步的原理解释,参考这篇文章。
-
简单来说,损失函数关于大部分参数的梯度,会随着网络深度增加而越来越冗长。
-
其中出问题的是\(\prod \frac {\partial \boldsymbol h_j}{\partial \boldsymbol h_{j-1}}\)。
-
回顾方案一,\(h_j\)和\(h_{j-1}\)之间会存在一个非线性激活函数,比如tanh。因此求导会产生一个tanh的导数的乘积。
-
tanh函数是定义在无穷区间上,值域在1和-1之间的函数。其导数在0和1之间,在原点处达到最大值1,在两侧趋于0。
-
显然,绝对值小于1的数,会越乘越小。因此梯度越来越小。
教材上利用特征分解予以解释,但我在最后没有太明白,不理解为什么部分项会被丢弃。
我们把循环神经网络简化为:
假设存在特征分解,其中\(\boldsymbol Q\)正交:
那么就有:
\begin{equation}\begin{split}
\boldsymbol h^{(t)} &= (\boldsymbol Wt)T \boldsymbol h^{(0)} \
&= \boldsymbol Q^T \boldsymbol \Lambda^t \boldsymbol Q \boldsymbol h^{(0)}
\end{split}\end{equation}
这意味着:
-
对角阵中幅值大于1的特征值,会被继续放大;幅值小于1的,则会被衰减到0。
-
\(\boldsymbol h^{(0)}\)是初始状态。由矩阵乘法,\(\boldsymbol h^{(0)}\)中没能和最大特征向量对应的部分,就被丢掉了。
注意,上述挑战针对于循环网络。在非循环网络,如前馈神经网络中,我们可以通过精心设计,避免梯度消失和爆炸。
有人希望模型停留在稳定参数区域。不幸的是:
In order to store memories in a way that is robust to small perturbations, the RNN must enter a region of parameter space where gradients vanish (Bengio et al., 1993, 1994).
根据第一个解释,我们能找到解决思路:尽量让tanh导数项的自变量处在原点处,使该导数趋于1。
本章其余部分将继续讨论:如何降低学习长期依赖问题的难度。因为单纯增加深度已经存在问题了,并且仍是深度学习的主要挑战。
10.8 回声状态网络
如果阅读了上面推荐的文章,那么我们就知道,在三种权重里,隐藏-隐藏和输入-隐藏是最难训练的。
相比之下,隐藏-输出的权重较好训练。
回声状态网络echo state network, ESN,就是解决这一问题的。
该网络中设定了循环隐藏单元,使其能很好地捕捉输入历史,并且只学习输出权重。
与ESN类似的还有流体状态机liquid state machines,区别在于前者的隐藏单元是连续的,后者的是二值输出。
二者都称为储层计算reservoir computing,因为隐藏单元的作用是捕获历史不同方面的临时特征池。
具体说明参见P245-247。
10.9 渗漏单元和其他多时间尺度的策略
处理长期依赖的一种思路是:让模型在多个时间尺度下工作,使模型的某些部分在细粒度时间尺度上操作以处理小的细节,而其他部分在粗时间尺度上操作以处理遥远的信息。
这种思路衍生出众多的方法,包括本节要介绍的:在时间轴增加跳跃连接。
渗漏单元正是使用了不同时间常数的整合信号,并且去除了一些细粒度时间尺度的连接。
时间维度的跳跃连接
这种思想可以追溯到1996年。Lin等人引入了\(d\)延时的循环连接,使得导数指数下降的速度与\(\frac{\tau}{d}\)相关,而不是\(\tau\)。
但这治标不治本,并且可能长期依赖无法被很好地表示。
渗漏单元和一系列不同时间尺度
批注:该思想类似于TensorFlow里的滑动平均模型和影子变量。
滑动平均值实际上包含了很长一段时间的信息。
在长期依赖问题中,我们可以用滑动平均值来代替真实参数,使得参数更迭时考虑更多的长期信息。
设\(\mu^{(t)}\)是\(v^{(t)}\)累积的一个滑动平均值。即当参数更迭时,我们总是利用\(\mu^{(t)}\)而不是\(v^{(t)}\)。
其求法为:
当\(\alpha → 1\)时,\(\mu^{(t)}\)几乎全采用上一个滑动平均值,几乎不发生变化,对历史信息沿用较大;
当\(\alpha → 0\)时,\(\mu^{(t)}\)几乎全采用算法输出值,历史信息基本被全部丢弃。
这些从\(\mu^{(t-1)}\)连接到\(\mu^{(t)}\)的方式,称为线性自连接;
而\(\alpha → 1\)的线性自连接隐藏单元,我们称之为渗漏单元leaky unit。
我们设置线性自连接单元,并且令连接权重接近1,从而使得导数乘积接近1。
这样,我们就避免了跳跃,而是采取了这种更平滑的方式,来保持更久远的长期依赖。
删除连接
和跳跃连接不同的是,跳跃连接是添加边,单元可以自我选择有利的依赖;
而删除连接直接把长度为1的连接删除了,强迫连接是较长的。
总的来说,上述两种方法都在保持深度\(\tau\)不变的情况下,尽可能迫使模型学习长期依赖。
10.10 长短期记忆和其他门控RNN
在本书撰写时,门控gated RNN是当时最有效的序列模型。
包括:基于长短期记忆long short-term memory和基于门控循环单元gated recurrent unit的网络。
和渗漏单元类似,门控RNN也是要生成通过时间的路径,使其导数既不消失也不爆炸。
不同的是,渗漏单元中的连接权重一般是手动设置或设为参量的常量,而门控RNN中的连接权重在每一个时间步都有可能改变。
回顾渗漏单元,我们会注意到一个问题:渗漏单元允许网络累积长期信息,但如果该信息已经被使用或无用,神经网络应该丢弃这些信息。但由于连接权重是常量,这一点无法做到。
一个很明显的例子是:我们的长序列由一系列子序列组成,子序列之间是无关的。
显然,我们希望在每个子序列内积累信息,但切换到另一子序列时,应该遗忘历史。
进一步,我们希望RNN自行决定何时遗忘。这就是门控RNN的设计初衷。
LSTM
先看图:
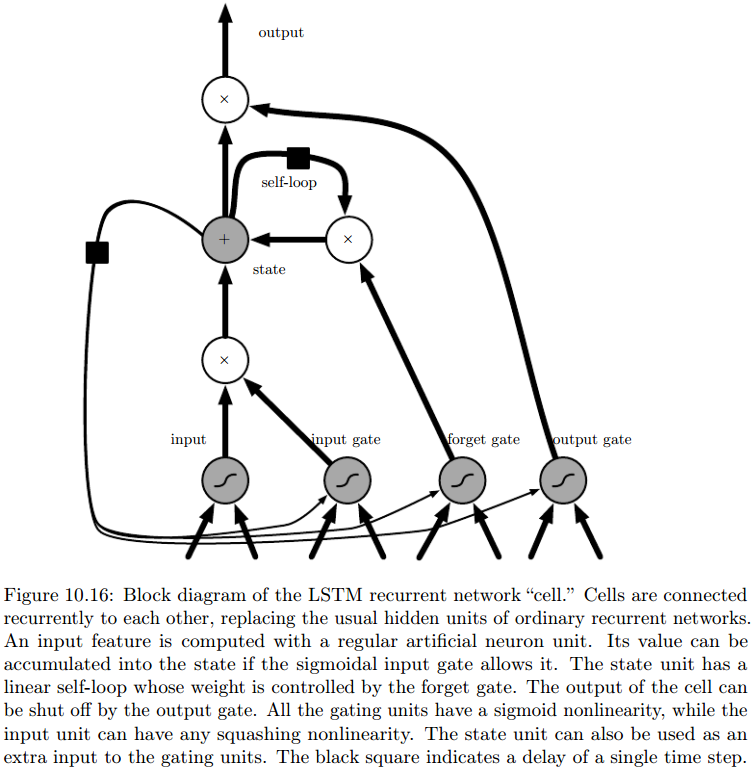
主要创新有:
-
输入、状态、输出都有门控制;
-
门控系数都是根据上下文训练得到的。
如图,输入和输出比较好理解,分别由外部输入门external input gate和输出门output gate控制:
注意:外部输入门单元\(\boldsymbol g^{(t)}\)和输出门单元\(\boldsymbol q^{(t)}\)都需要同时考虑:外部输入\(\boldsymbol x^{(t)}\)和上一时刻细胞的输出\(\boldsymbol h^{(t-1)}\)。
所以说是基于上下文的。
状态的门控稍微复杂一些。我们称以下过程为状态单元\(\boldsymbol s^{(t)}\)的自循环self-loop,与渗透单元的线性自环类似:
其中状态单元的门控单元\(\boldsymbol f^{(t)}\)称为遗忘门forget gate。
注意上式中大部分乘积为哈达玛乘积,即对整个向量的每个元素分别进行迭代。
其他门控RNN
Which pieces of the LSTM architecture are actually necessary? What other successful architectures could be designed that allow the network to dynamically control the time scale and forgetting behavior of different units?
Some answers to these questions are given with the recent work on gated RNNs, whose units are also known as gated recurrent units or GRUs (Cho et al., 2014b; Chung et al., 2014, 2015a; Jozefowicz et al., 2015; Chrupala et al., 2015). The main difference with the LSTM is that a single gating unit simultaneously controls the forgetting factor and the decision to update the state unit.
参见P250。
关于长期依赖的其他优化方法,以及外显记忆思想,参见本章后两节。
11. 实践方法论
前面讲的都是原理,现在终于要结合实际了。
在实践中,正确使用一个普通的算法,比草率地使用一个不清楚的算法,效果会更好。
本章许多建议来自Ng。
大致设计流程为:
-
确定目标——使用什么误差度量,并设定目标阈值。
-
尽快建立一个端到端的工作流程。
-
搭建系统,找出性能瓶颈。
-
改善性能:收集新数据,调整超参数或改进算法。
11.1 性能度量
我们最熟悉的性能指标是:准确率和错误率。
但在很多情况下,我们需要更高级的度量。
第一种情况是:错误分两种,但其中一种后果尤为严重。
比如癌症检测,无论是有病判无还是无病判有,都算误诊。但显然,前者对病人的危害更为严重。
又比如邮件检测,宁可未拦截垃圾邮件,也不要误杀正常邮件。
还有一种情况是:对一些比例极其不平衡的分类问题,准确率是一个很糟糕的指标。
比如某种罕见病在一百万人中只有一人患病。此时我们有一个很糟糕的分类器,其结果永远为“未患病”。
即便如此,分类器的准确率仍高达99.9999%。
为了解决这两种情况,我们首先把事件分为四类:
-
True Positive (TP) :“患病”,确实患病(预测正确)
-
False Positives (FP) :“患病”,但其实健康(预测错误)
-
True Negative (TN) :“健康”,确实健康(预测正确)
-
False Negative (FN) :“健康”,但其实患病(预测错误)
Positive和Negative指的是“正例”or“反例”,True和False评价预测正确与否。
精度precision:
“精度”关注预测为正例的事件,度量预测结果中的正例的预测准确性。
召回率recall:
“召回率”关注真实为正例的事件,度量真实情况中的正例的预测准确性。
回到罕见病,尽管精度完美(分子分母都为0),但召回率为0,因为患者全部被误诊。
精度和召回率是矛盾的。为了综合评价,我们有以下两种方法:
-
绘制PR curve,权衡二者。
比如计算曲线下方的总面积,取最大面积对应的情况。这样做有个好处,我们可以动态规划,随时调整判断阈值。
-
计算F-score:
\[F = \frac {2pr}{p+r} \]
在实际应用中,我们可以给机器设定一个阈值。
如果机器输出结果的置信度小于该阈值,那么该结果就是无效的,转由人工处理。比如癌症检测和物体识别等。
一般情况下,人工处理的准确率会高于机器判断,但机器效率更高。
如果我们想兼顾准确率和效率,我们可以引入一个覆盖率coverage度量。
覆盖率的意思是:机器任务占总工作量的比例。
比如在某数字识别任务中,当覆盖率为0时,即全人工处理,准确率为99.999%;
当覆盖率为95%时,准确率只下降到98%。这一般是可以接受的。
11.2 调试策略
我们通常会遇到的问题是:当测试效果不佳时,我们难以判断是算法不好,还是实现错误。
比如参数迭代实现有误:
我们忘了使用梯度,导致参数永远都在减小。但是,由于模型中存在大量的自适应模块,使得最终结果可能还算理想。
大部分调试策略都用来解决这两个问题中的一个或两个。我们可以:
-
设计一种简单情况,观察输出;
-
将网络分模块测试,或阶段性输出。
可视化输出也是一种重要的测试方法。比如观察图像检测模型的隐藏层图像。
其他内容,过拟合、欠拟合、超参数等,前面章节已叙,不再赘述。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号