Paper | Cross-stitch Networks for Multi-task Learning
Cross-stitch Networks for Multi-task Learning
1. 问题
假设我们有任务A和B,并且这两个任务存在一定的关联性。最常见的做法是:对相同的输入,A和B共享同一个输入特征提取网络,然后在同样的特征上,各自单独训练,得到最终结果。
至于在哪里分开(独立),我们可以做遍历实验,尝试所有可能的网络结构,如图:

显然,这种暴力穷举法非常笨拙,并且找到的最佳结构也不是通用的。尽管我们缺乏理论指导,但有没有更好的实验方法?
有的!下面介绍的这篇文章Cross-stitch Networks for Multi-task Learning,来自卡耐基梅隆机器人所,是CVPR2016高引论文。
首先,作者选择了两对关联任务:语义分割(Semantic segmentation)和曲面法线预测(Surface normal prediction),以及物体检测(Object detection)和属性预测(Attribute prediction)。根据上图的分、合模式,我们可以得到对应的实验结果:

图中的数据,是与task-specific网络(即上上图最右)比较的结果。作者总结出两点:
- 多任务相较于单任务,有一定的优势;
- 最佳分、合结构因任务而异。
接下来才是我们的重点。
2. 十字绣结构(Cross-stitch architecture)
看图秒懂:
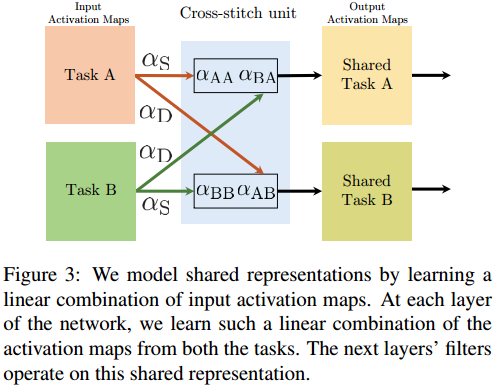
啥?不知道怎么分合?让它变成超参数!
是的,十字绣结构就这么简单。在每一层的输出后,增加这样的分、合结构,然后再接入下一层的输入。
为了保证可导(可反向传播),这里的分合不是开关结构,而是由超参数加权控制。
图中的\(\alpha_S\)意为the same-task values,\(\alpha_D\)意为the different-task values。\(\alpha_S=1\)就是task-spec结构,\(\alpha_D\)越大共享程度越高。
但在引入新结构以后,出现了以下问题:
-
这些超参数怎么初始化?
为了保证十字绣结构前后数据量级不变,很自然地,我们最好规定初始状态下超参数之和\(\alpha_S+\alpha_D=1\)。
但注意,这只是初始化的规定,在训练过程中超参数可以自由发展。其次,具体怎么设置,还得靠实验,所以是因任务而异的:
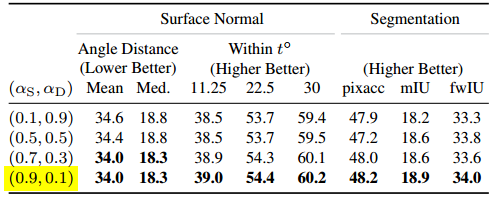
-
由于这些超参数的初始值是网络中一般参数的一到二倍大,因此在实验中发现,这些超参数调整过慢。
为了加快收敛,这些超参数的学习率被直接乘以10的若干次方。
通过实验发现,10的2到3次方最佳,此时收敛速度更快,实验结果也更好。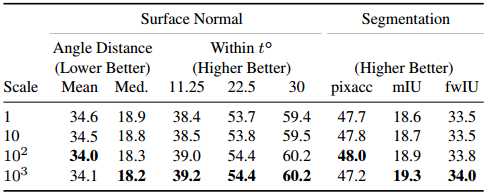
-
A和B网络如何初始化?统一还是各自初始化?还是实验解答。
-
在ImageNet特征上,分别进行20K次迭代,得到one-task initialized的两个网络;再进行10K次统一迭代。
-
直接在ImageNet特征上进行30K次迭代。
结果是前者更好:
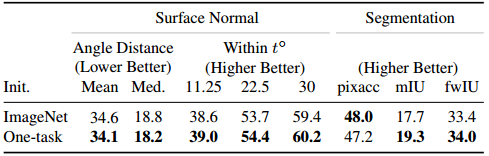
因此推荐分别各自初始化。
-
-
Det+Attr实验中发现,如果十字绣结构连接每一层的对应channel,会导致学习不稳定。
因此这一对任务的十字绣结构,在每一层之间只用一个。
3. 实验设计
实验关注以下几点:
-
在4个任务的实验中,使用cross-stitch都达到了对比算法中的最佳效果,个别除外。
-
一些对比算法的参数规模是本方法的2倍。
-
对比算法中包括当时最好的结构穷举方法。
-
在语义分割任务中,不同类别的数据量不同。实验发现,数据量越少的分类,其准确率上升大致上反而越多(十字绣帮助越大):
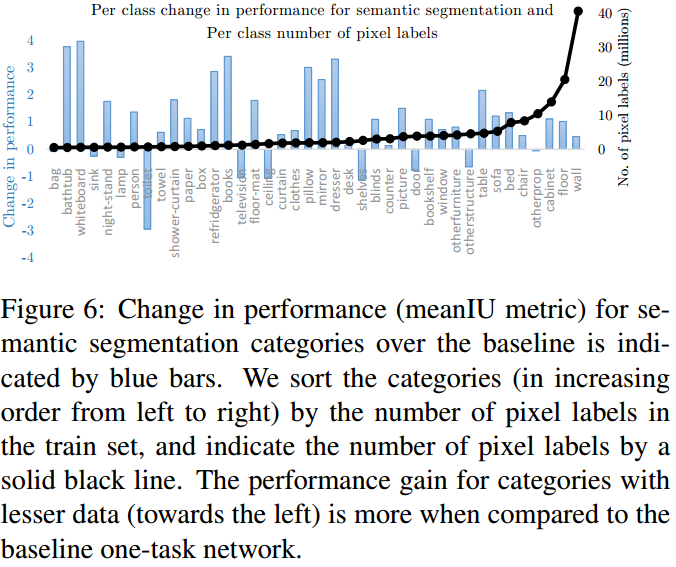
-
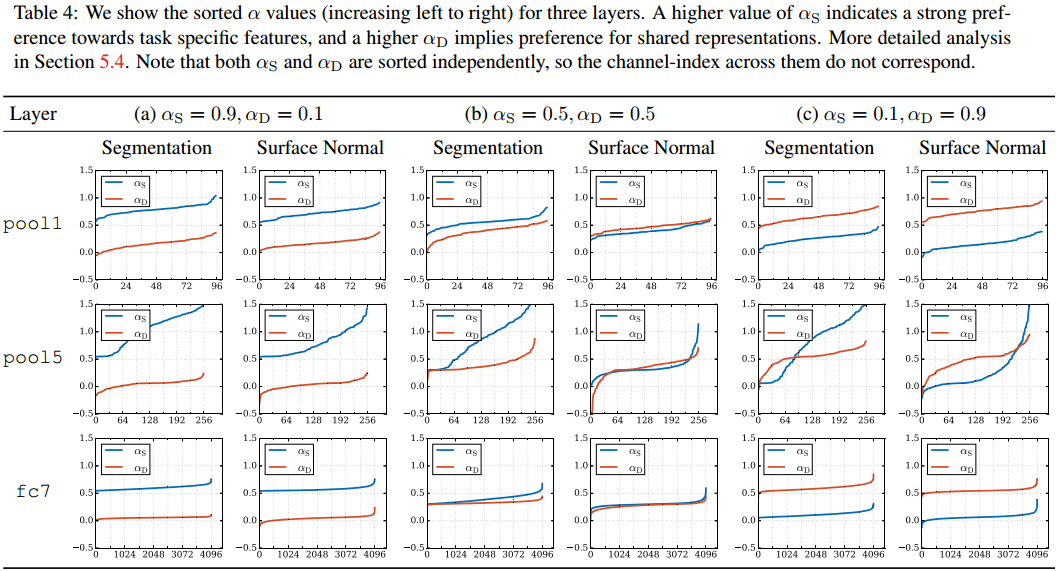
对于SS和SN组合,它们的最优分、合模式不完全一样(下图横坐标是通道index):

 浙公网安备 33010602011771号
浙公网安备 33010602011771号