Paper | How transferable are features in deep neural networks?
How transferable are features in deep neural networks
1. 核心贡献
我们都知道,深度网络中的特征是逐渐特化的。如果我们将一个深度网络中的高层特征,迁移用于另一个任务,那么这个新任务的表现很有可能不理想。
这篇文章讨论的就是深度网络中特征的可迁移性,通过实验有以下3点发现:
-
越高层的特征越难以迁移。
-
迁移后网络的参数联动性被打破,导致了优化困难。
-
迁移往往会带来泛化能力上的飞跃,即使在迁移后仍长时间迭代收敛。
解释一下第二点,可能需要看完实验部分才知道是什么意思。
假设我们的源任务S和目标任务T的网络前n层是一样的。我们想把S前n层迁移。现在有两种方法:
-
方法1:前n层参数固定(frozen);
-
方法2:前n层参数只用于初始化但不固定,其参数可以在新任务上继续优化。
方法2看上去会更好。
因为方法1打破了T网络的前n层和后几层的参数联动性,优化产生了困难。这就是第三点的由来。
但是要注意,我们之所以迁移,大多情况下是因为T任务的数据量太少,而S任务训练数据充足。
如果我们继续优化前n层的特征,很可能会导致过拟合,泛化能力下降。
如果我们需要论证深度网络中特征的可迁移性,或者论证影响可迁移性的因素,那么这篇文章是有借鉴意义的。
2. 实验设置
2.1 任务设置
一个特征的可迁移性有多强,可以通过迁移实验的好坏来评价。显然,该性质与任务之间的差异有很大关系。
为了减小偶然性,作者从ImageNet中随机选择了1000个类别,再随机分为两组。从两组中随机抽出任务A和任务B,作为迁移源任务和目标任务。
为了探究任务差异与可迁移性的关系,作者还按以下方式分组:前一组全为自然物体,而后一组全为人造物体。
2.2 网络设置

对任务A和B,都配置一个8层网络。前n层(\(1{\le}n{\le}7\))用来迁移;图中为\(n=3\)。
为了进一步考察可迁移性,作者有以下设置:
-
BnB网络:B的前n层是从训练好的B网络内迁移得到的,且参数固定;后\((8-n)\)层随机初始化并进一步训练优化。
-
AnB网络:B的前n层是从训练好的A网络内迁移得到的,且参数固定;后\((8-n)\)层随机初始化并进一步训练优化。
-
BnB+网络:B的前n层是从训练好的B网络内迁移得到的,参数不固定,可以进一步训练优化。
-
AnB+网络:B的前n层是从训练好的A网络内迁移得到的,参数不固定,可以进一步训练优化。
目的:
-
探究完全迁移的优势;
-
探究第3层的特征是general的(迁移效果好)还是specific的(迁移效果差)。
-
探究限制可迁移性的因素(第3点发现)。
-
探究固定参数迁移的优势。
具体目的,继续看实验结果。
3. 实验结果
-
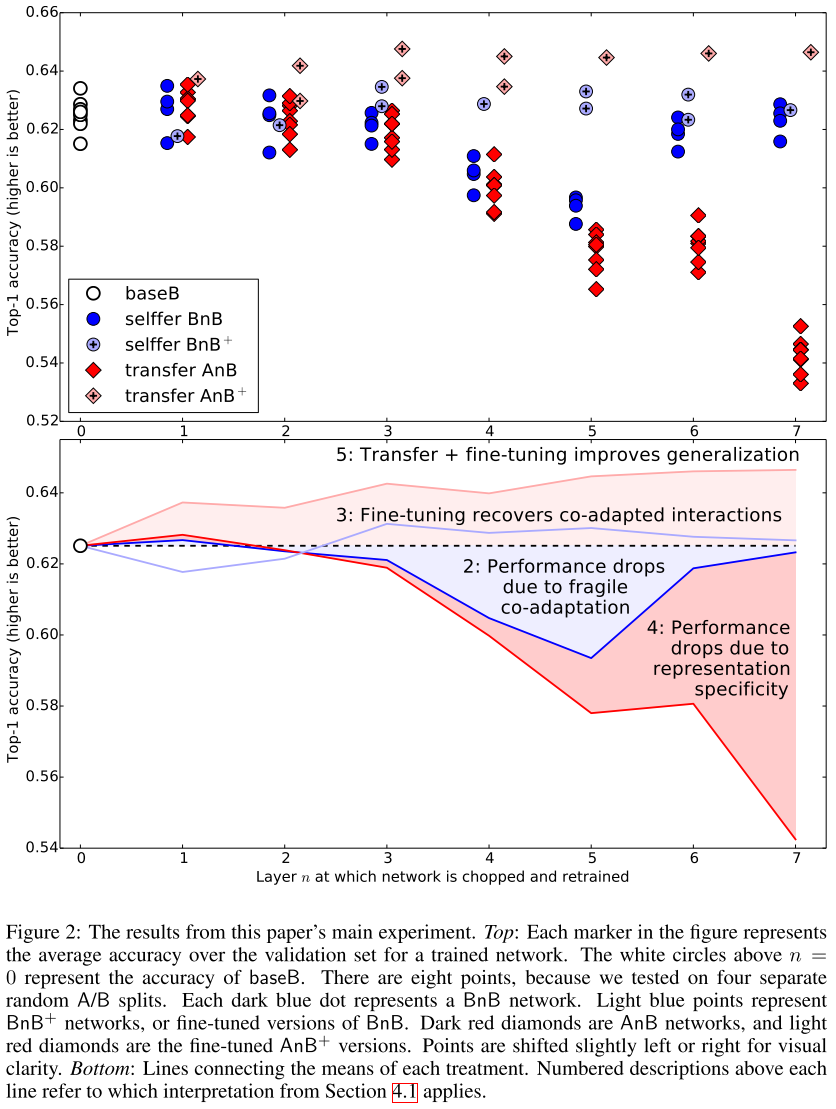
实验中尝试了4种分组,因此有8个数据集和网络参与了测试。上图中8个圈圈就是它们的测试结果,Top-1分类准确率大概是62.5%。
-
参数的联动性是很重要的。
我们看上图的深蓝色圈圈,代表的是BnB网络的测试结果。当\(n \ge 2\)时,网络的性能比原B网络更差。
换句话说,BP过程由于前n层的固定变得很不正常,因此参数训练得不好。
当然了,如果n较大,那么这个网络需要训练的参数就不多了,因此效果又提升了。如图中\(n = 6,7\)时。这也是第一篇文献发现了:优化困难最容易在中间层发生,既不是开始也不是最后。
-
BnB+网络的表现和基础网络基本一致,起码不会像BnB一样衰减。
-
底层特征泛化能力较强。
我们看AnB的表现,当\(n=1,2\)时,网络表现是不错的。虽然参数固定,但特征仍然在B任务上表现出色。
但层数较深时,特征可迁移性就很差了。当然,这与联动性的破坏也有关系(基于BnB的实验)。
-
完全自由迁移的效果真的太棒啦!
看AnB+的表现就知道了。无论从何时开始迁移,效果都比基础网络更好!
并且,即使我们长时间训练,迁移带来的爆炸效果仍然回荡不绝!Q:是因为解决了过拟合吗?
A:不是的,因为B任务的数据集也很大呀!Q:是因为AnB+的总迭代次数比B更长吗?
A:不是的,因为AnB+和BnB+都是450k+450k次迭代,但AnB+比BnB+效果更好!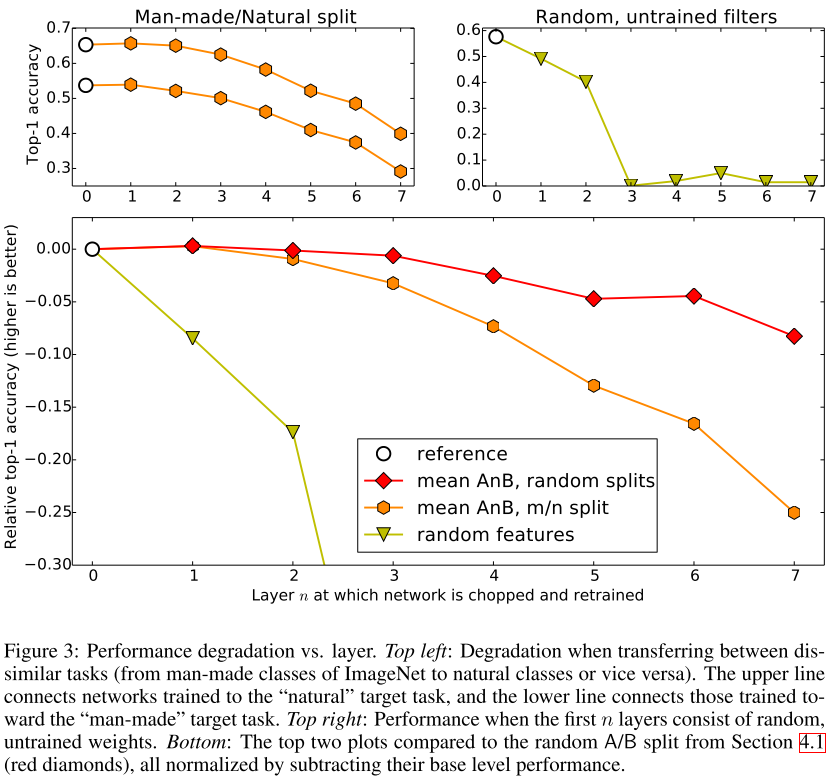
-
任务差异增大,可迁移性变差。
见上图左上小图。上曲线为自然任务预测表现,下曲线为人造任务预测表现。白圈为基准。
我们取个均值,和上面的随机分组的表现相比,见上图下小图。红色曲线始终高于橙色曲线。可见,当刻意分为自然和人造时,任务差异性增强,网络的表现变差。
-
任务差异增大,优化困难会增加。
见上图下小图,比较红色、橙色曲线。都是AnB网络,随着n增加,自然/ 人造分组的表现会降得更厉害,即优化困难增加得更剧烈。
绿色的不看了,那是随机滤波器。作者想说明,即便从差距较大的任务迁移,效果也要比随机滤波器好。现在看来这一点是很显而易见的,因为随机滤波器就是瞎猜嘛。
4. 启发
迁移学习常常用于解决数据量不足、网络易过拟合的问题。
但这篇文章告诉我们,在数据量充足的情况下,如果我们能从相似的任务中获得特征->迁移初始化,那么训练出来的网络总比随机初始化表现更好。
哪怕迁移后我们长时间迭代;无论我们迁移初始化的比例(多少是迁移初始化的)有多高。
当然,在实际应用时,我们更应该考虑数据的清洁、训练的合理性。否则迁移学习的效果是很难看到的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号