Paper | Detail-revealing Deep Video Super-resolution
Detail-revealing Deep Video Super-resolution
发表在2017年ICCV。
核心内容:提出了亚像素运动补偿(Sub-pixel Motion Compensation, SPMC)层,服务:基于CNN的视频超分辨方法。
特点:
-
SPMC可以同时完成超分辨和运动补偿。这一点是精髓,作者claims that可以更好地保持亚像素信息。为什么这么说,最后我再解释。
-
SPMC是无参数的,因此结合到视频超分辨网络中,使得该网络可用于任意尺寸的输入,而无需重新训练。
-
使用了Conv-LSTM,输入帧数任意。这样,我们可以在效率和质量上权衡。
这篇论文实际上写得很绕。我无意间发现了作者对这篇论文的报告视频,讲得简单明了。这里做一个截图和笔记。

1. 故事
首先,视频超分辨率有以下几个挑战:
-
如何配准多帧信息。如果没有配准,那么多帧反而是有害的。
-
模型不够健壮。一个放缩系数往往对应一个模型,并且输入帧数也是固定的。
-
生成的细节有时是假的。这是因为外部数据库的影响。

鉴于此,本文的目标是:
-
任意大小输入,任意放缩系数。
-
更好地利用亚像素信息。
-
生成更真实的细节。

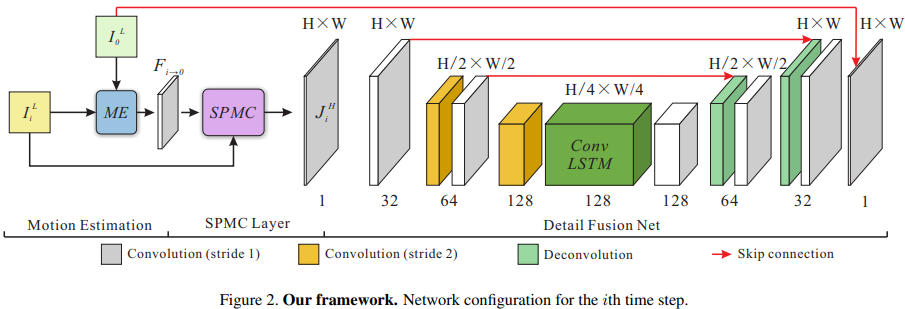
本文提出的网络架构(从论文截取的大图):
2. 步骤
-
第\(i\)时刻的LR帧\(I_i^L\)和当前\(0\)时刻的LR帧\(I_0^L\)一起输入运动预测网络,得到光流预测图\(F_{i \to 0}\)。

-
\(F_{i \to 0}\)和\(I_i^L\)一起输入SPMC层,得到升采样并且运动补偿的\(J^L\)。

-
由于\(J^L\)比较稀疏,因此输入一个有丰富降采样的编码器-解码器网络,得到残差;然后与\(I_0^L\)点点求和,即得到最终输出。注意,与传统编解码网络不同,中间的单元被换成了Conv-LSTM,从而可以对视频序列建模。

3. 实验
首先,作者尝试将三个相同帧输入网络,发现输出图像虽然更锐利了,但是没有产生额外的信息。

接着,作者换成了三张连续帧,效果就好了。这说明:SPMC的使用,使得细节伪造更少了,并且细节的生成更真实。

作者还尝试了传统方案:先运动补偿,然后升采样,结果中产生了很多虚假的细节:

换成SPMC就好了:

作者说:基于以上实验,他们认为,在亚像素级别,只有合适地运动补偿,才能恢复真实的细节。这一句,就是点睛之笔。
我的理解:前人一般都是先 运动补偿 然后 超分辨,在这个过程中,亚像素信息需要二次增强,很难保真,而更倾向于从 根据外部数据库学习的先验 中获取。
4. SPMC
看完了视频,我们再来看一下SPMC。其实很简单:
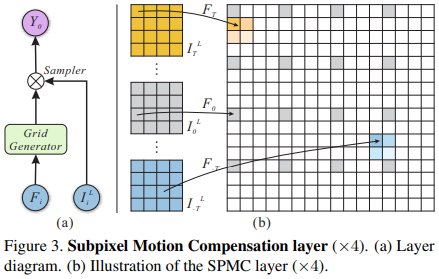
第一步是坐标变换,其中\(\alpha\)就是放缩系数:

第二步是双线性插值,将升采样的图完善。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号