机器学习听课 | Pandas | 04
Pandas基本介绍
Pandas介绍

2008年才开发出来的库,专门用于数据挖掘.
基于numpy,借力于numpy计算方面性能高的优势.
基于matplotlib,能够简便的画图.
为什么使用Pandas
numpy已经能够帮我们处理数据,能够结合matplotlib解决部分数据展示问题.
那么pandas学习目的什么地方呢?
(1) 便捷的数据处理能力
(2) 读取文件方便
(3) 封装了matplotlib,numpy的画图和计算.
案例
创建一个符合正态分布的10个股票5天的涨跌幅数据

但是这样的数据形式很难看到存储的是什么样的数据,并也很难获取到相应的数据.
使用panda可以让下面的根据更有意义的展示.
要实现的效果如下:
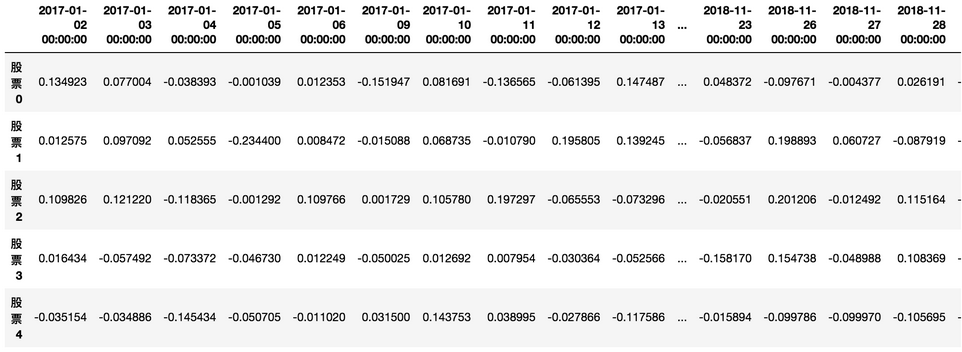
将数据转化为pd.DataFrame格式
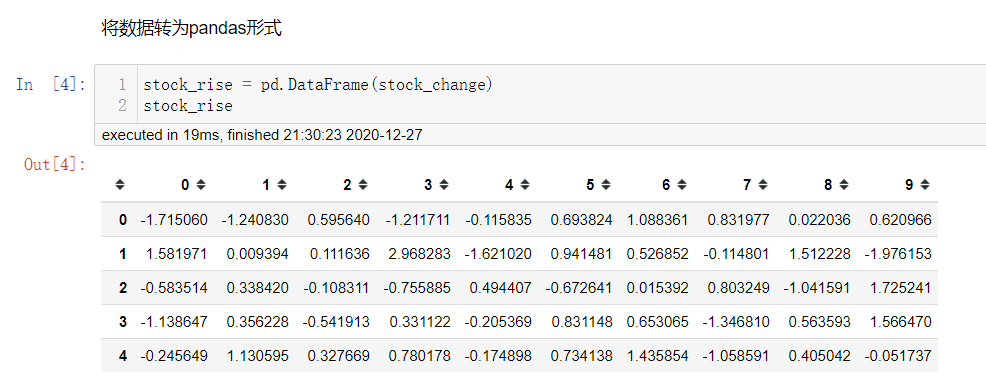
增加行索引index

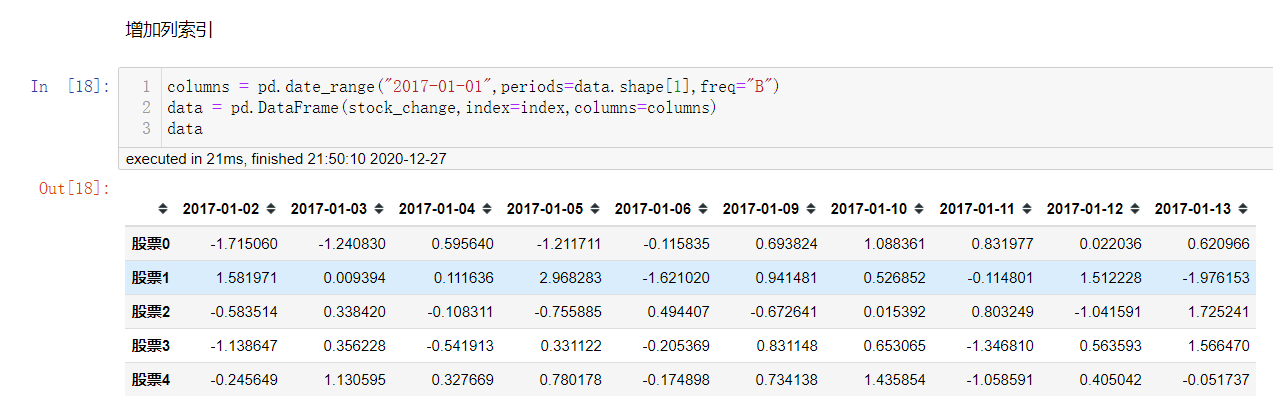
增加列索引columns
股票的日期是一个时间的序列,我们要实现从前往后的时间还要考虑每月的总天数等,不方便.
使用pd.date_range(),用于生成一组连续的时间序列.
pd.date_range(start=None,end=None,periods=None,freq="B")
# 用于生成一组连续的时间序列
# start: 开始时间
# end: 结束时间
# periods: 时间天数
# freq: 递进单位,默认1天,'B'默认略过周末
# 注意: end和periods二者取一即可
DataFrame
DataFrame结构
DataFrame对象既有行索引index,又有列索引columns
(1) 行索引: index,横向索引,0轴,axis=0
(2) 列索引: columns,纵向索引,1轴,axis=1
注意: 这里的0轴,1轴是以数值为准来看的 => 0轴上的索引,1轴上的索引.

DataFrame的属性
df.shape
# df的形状
df.index
# 返回df的行索引列表
df.columns
# 返回df的列索引列表
df.values
# 直接获取其中的df值
df.T
# 得到df的转置
df.head(5)/df.tail(5)/df.sample(5)
# 获取前/末尾/随机5行数据

DataFrame索引的设置
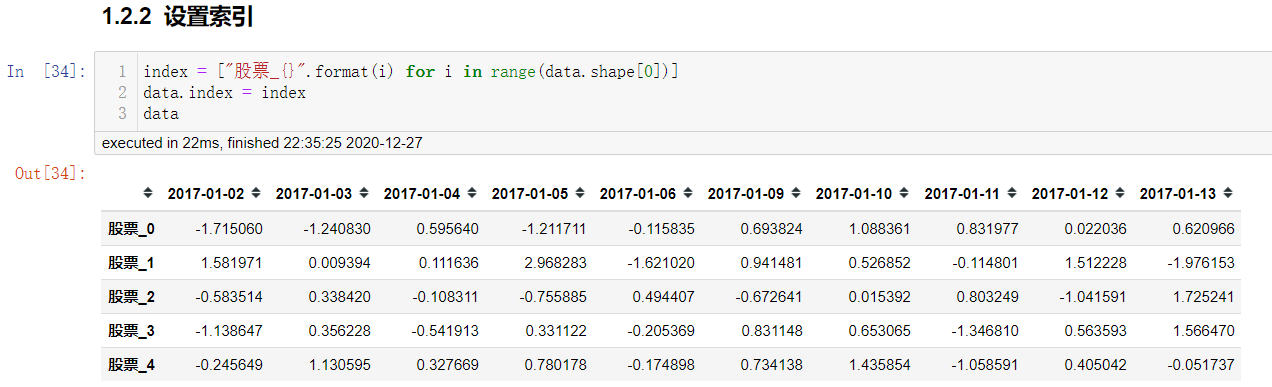
修改行列索引值
index = ["股票_" + str(i) for i in range(stock_day_rise.shape[0])]
# 必须整体全部修改
data.index = index
注意: 以下修改方式是错误的.
# 错误修改方式
data.index[3] = '股票_3'
重设索引值
df.reset_index(drop=False)
# 设置新的下标索引
# drop: 默认为False,不删除原来的索引,如果为True,删除原来的索引值
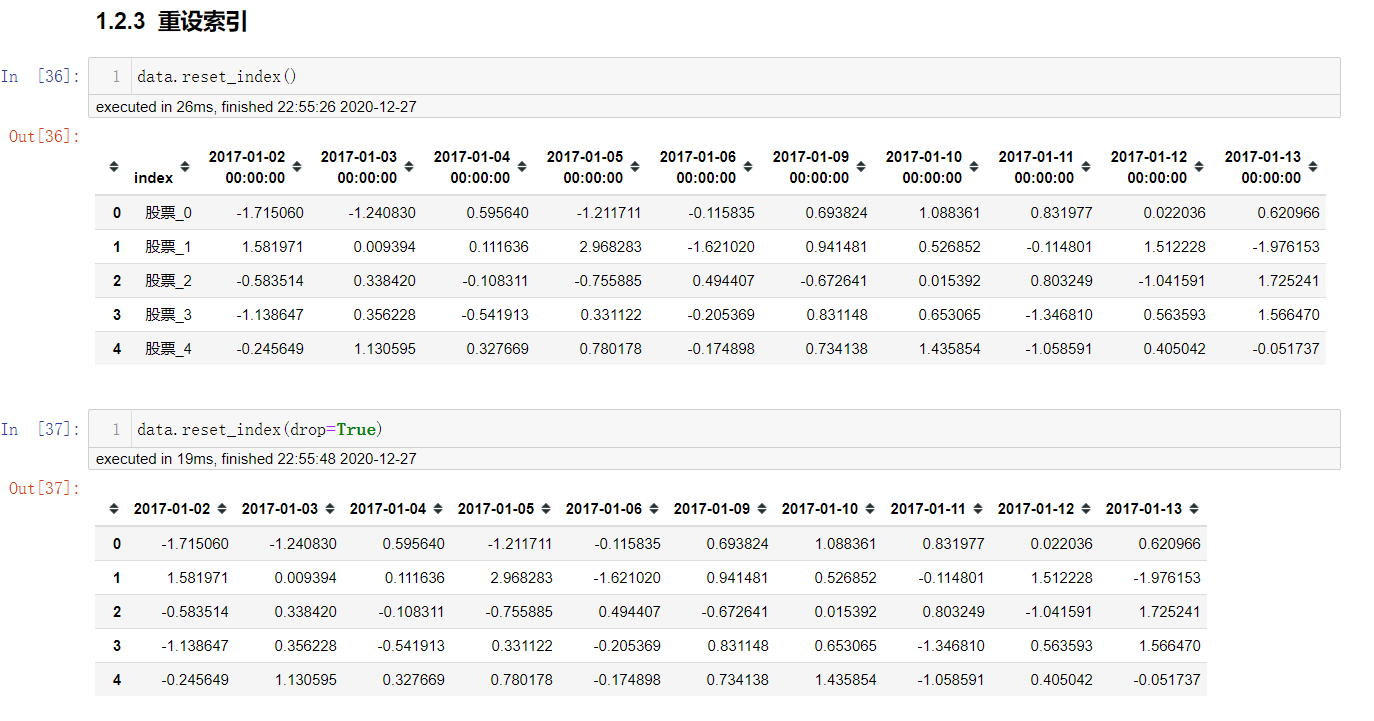
以某列值设置为新的索引
df.set_index(列索引名,drop=True)
# 序列: 列索引名
# drop: 删除原来的列
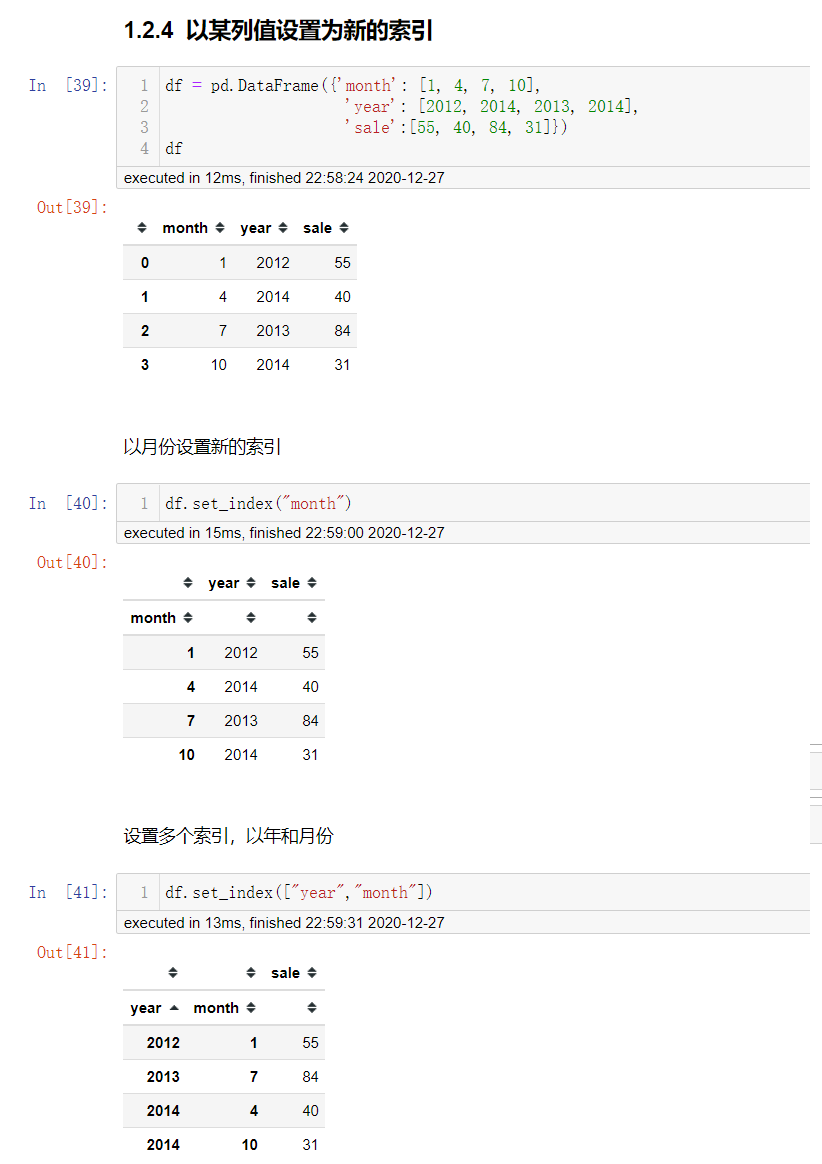
注意: 上面多个索引就是具有MultiIndex的DataFrame
MultiIndex与Panel
打印刚才的结果
MultiIndex
多级或分层索引对象
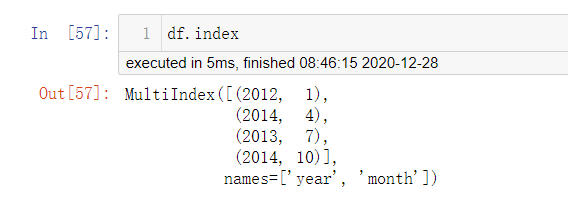
df.index.names
# levels的名称
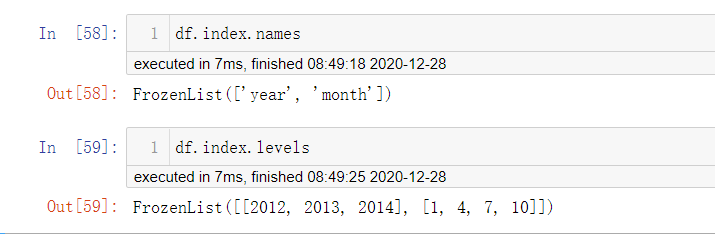
df.index.levels
# 每个level的元组值
Panel
Panel已经弃用了..
注意: Pandas从版本0.20.0开始弃用:推荐的用于表示3D数据的方法是通过DataFrame上的MultiIndex方法
Series结构
什么是Series结构呢? 我们直接看下面的的图

serise结构只有行索引
我们将之前的涨跌幅数据进行转置,然后获取"股票0"的所有数据
# series
type(data['2017-01-02'])
pandas.core.series.Series
# 这一步相当于是series去获取行索引的值
data['2017-01-02']['股票_0']
-0.18753158283513574
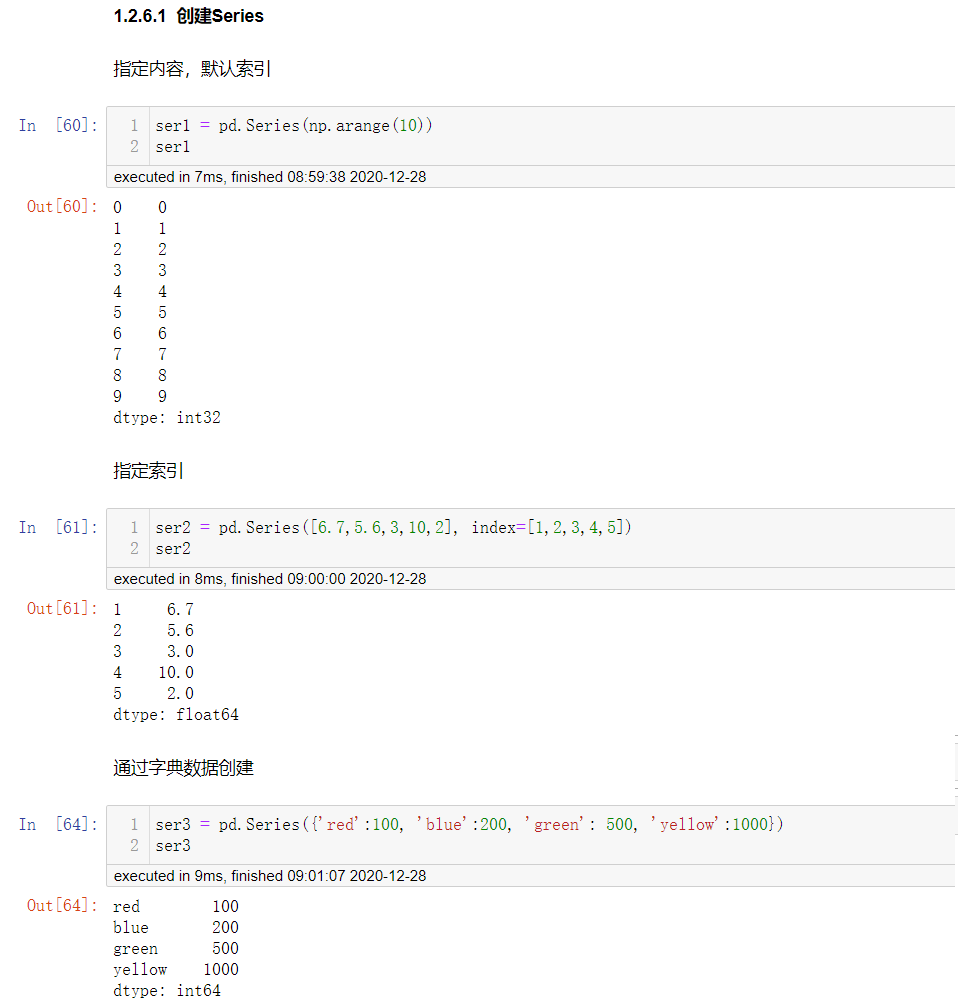
创建Series
1. 直接创建 pd.Series(序列)
2. 指定行索引 pd.Series(序列,index=...)
3. 传入字典创建 pd.Series(字典)
Series获取属性
ser.index
# 获取series的行索引
ser.values
# 获取series的值

基本数据操作
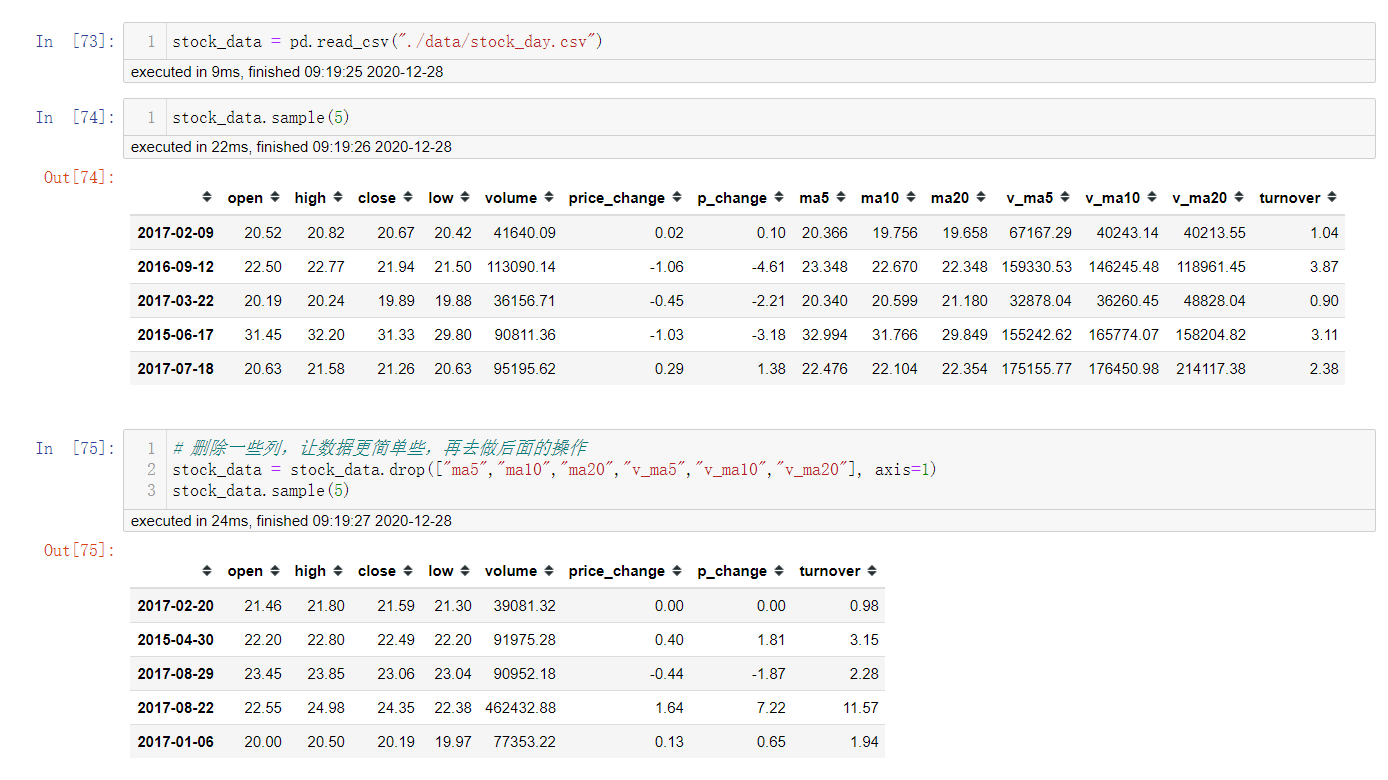
为了更好的理解这些基本操作,我们将读取一个真实的股票数据.
关于文件的操作,后面在介绍,这里只是先用一下API.
# 读取文件
data = pd.read_csv("./data/stock_day.csv")
# 删除一些列,让数据更简单些,再去做后面的操作
data = data.drop(["ma5","ma10","ma20","v_ma5","v_ma10","v_ma20"], axis=1)
索引操作
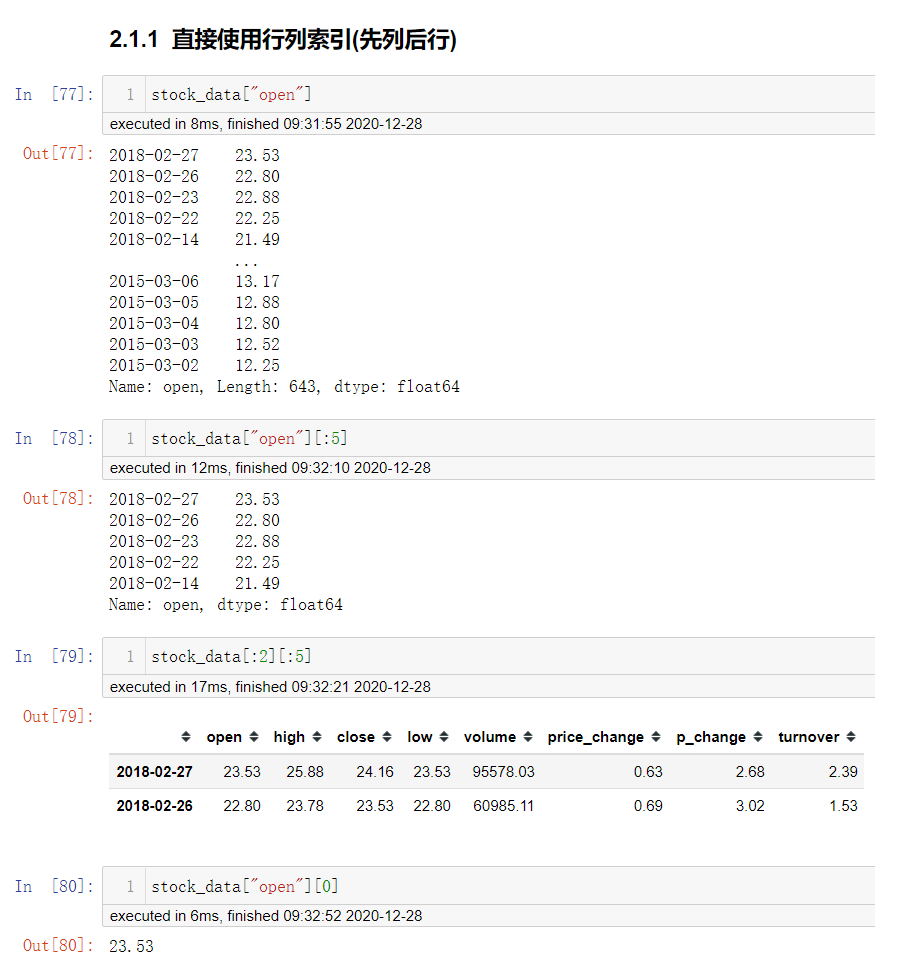
直接使用行列索引(先列后行)
获取'2018-02-27'这天的'close'的结果
# 直接使用行列索引名字的方式(先列后行)
data['open']['2018-02-27']
23.53
这里使用索引下标数组或者索引名字都是可以的.
下面是不支持的操作
# 错误
data['2018-02-27']['open']
# 错误
data[:1, :2]
结合loc或者iloc使用索引
df.loc和df.iloc的取值方式和numpy的取值方式是一致的.
但是df.loc和df.iloc不能混用.
df.loc[行名称,列名称]
# 通过行列索引的名字来获取值
df.iloc[行下标,列下标]
# 通过行列下标来获取值
获取从'2018-02-27':'2018-02-22','open'的结果

使用ix组合索引
df.ix[]可以实现下标和名称和混用(当然直接获取索引的方式也可以).
但是df.ix[]不推荐使用,所以推荐使用
df.loc[df.index[:],[列名称]]来代替

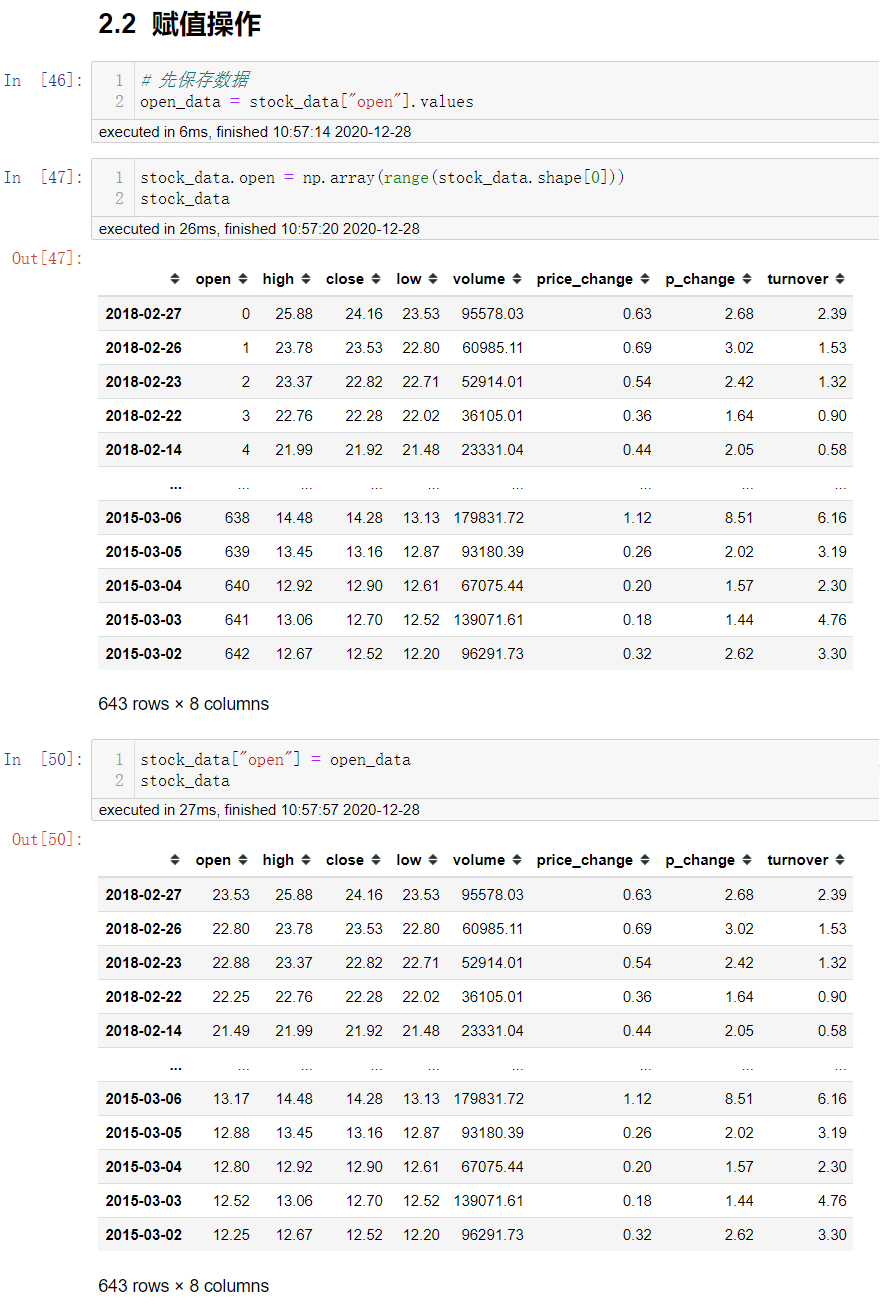
赋值操作
对df的整列进行赋值操作
# 直接修改原来的值
data['close'] = 1
# 或者
data.close = 1
排序
排序有两种形式,一种对于索引进行排序,一种对内容进行排序.
df.sort_values(by=...,ascending=...)
# 单个键或者多个键进行排序,默认升序
# ascending=False 降序
# ascending=True 升序
df.sort_index(by=...,ascending=...)
ser.sort_values(ascending=...)
# series排序时,只有一列,不需要参数
ser.sort_index()

DataFrame运算
算数运算
可以对一列Series进行加减乘除操作
ser.add() +
ser.sub() -
...
逻辑运算
逻辑运算符号 <,>,|,&
data["p_change"] > 2 # 逻辑判断
data[data["p_change"] > 2] # 使用逻辑判断来进行筛选
data[(data["p_change"] > 2) & (data['open'] > 15)] # 与的逻辑判断来筛选
data[(data["p_change"] > 2) | (data['open'] > 15)] # 或的逻辑判断来筛选
逻辑运算函数
df.query(expr)
# 通过query使得刚才的过程更加方便简单
# expr: 查询字符串
df[列名]/ser.isin(序列)
# 判断值是否存在这个序列执行
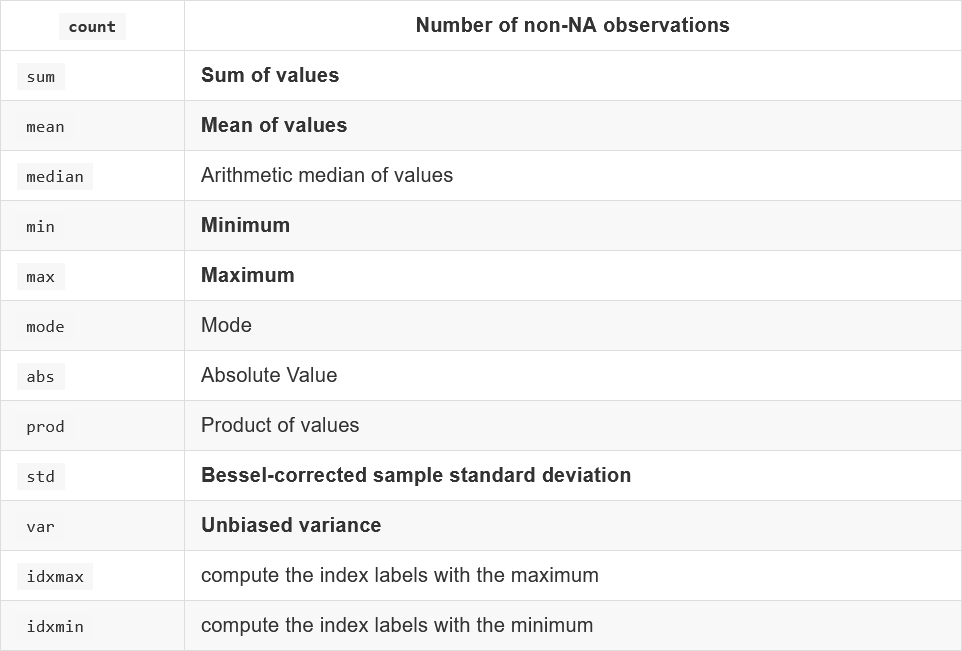
统计运算
describe()
df/ser.describe()
# 综合分析,能够直接得出很多统计结果 count,mean,std,min,max等

统计函数
numpy中已经详细介绍了,在这里我们演示min,max,mean,median,var,std,mode结果
这些统计函数默认都是统计的列columns,axis=0,如果要对行进行index,axis=1进行统计的话,需要指定axis=1.

累计统计函数

以上这些累计函数应该如何使用呢?
这里我们按照时间的从前往后来进行累计.
首先让stock_chaneg按照时间索引进行排序
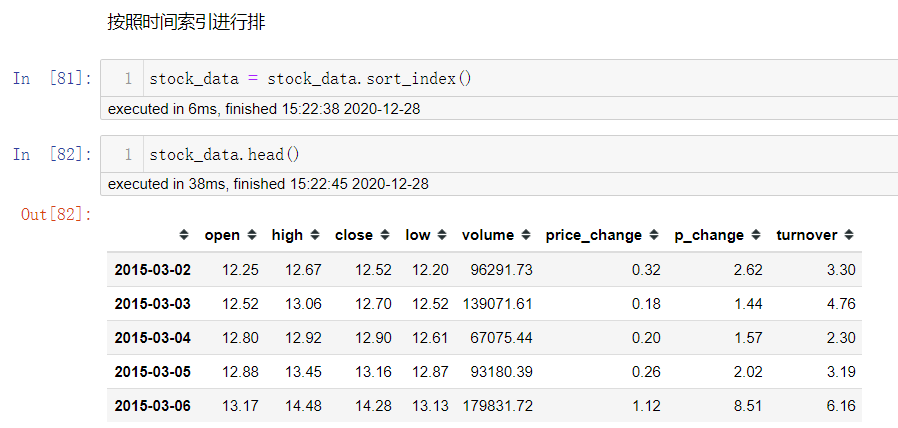
对p_change属性进行累计求和,然后画图

说明:
plot方法集成了前面直方图,条形图,饼图,折线图.
有关详细的API会在后面进行说明.
自定义运算
df.apply(func,axis=0)
# func: 自定义函数
# axis=0,默认是列,axis=1为行进行计算
自定义一个处理方法: 最大值-最小值的函数

Pandas画图
df/ser.plot(x=None,y=None,kind="line")
# plot就这一个绘图函数,封装基本的图形
# x,y: x值和y值
# kind: str
# "line" : 直线
# "bar" : 饼图
# "barh" : 水平柱状图
# "hist" : 直方图
# "pie" : 饼图
# "scatter" : 散点图
文件读取与存储
我们的数据大部分存在于文件当中,所以pandas会支持复杂的IO操作.
pandas的API支持众多的文件格式,如CSV,SQL,XLS,JSON,HDF5...
注意: 最常用的HDF5和CSV文件.
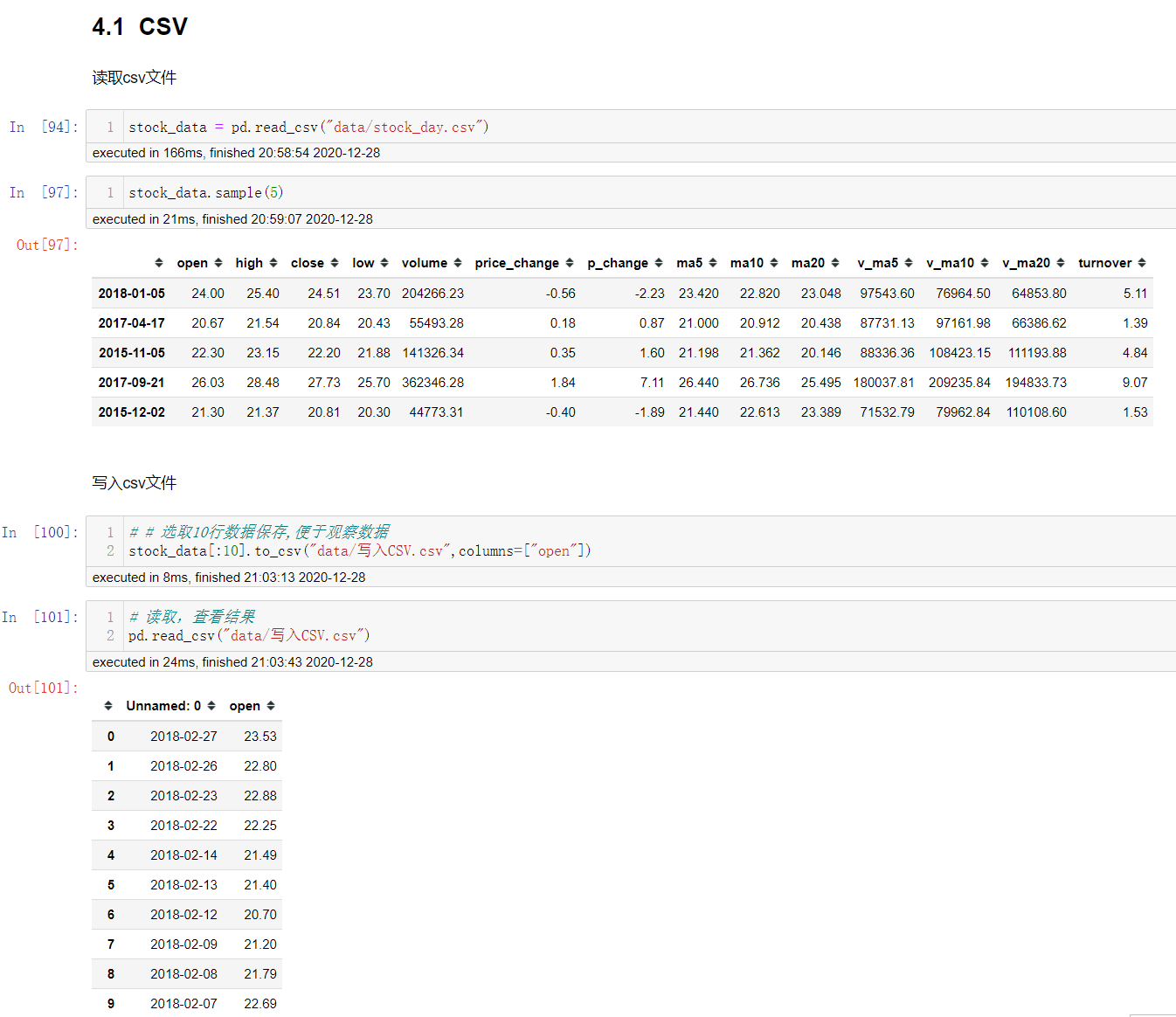
CSV
pd.read_csv(filepath_or_buffer,sep=",",usecols=...)
# filepath_or_buffer: 文件路径
# usecols: 指定读取的列名,列表形式
df.to_csv(path_or_buf=None,sep=",",colums=None,header=True,index=True,mode="w",encoding=None)
# path_or_buf: 保存的文件路径
# columns: 要写入的序列,列表形式
# mode: "w"重写,"a"追加
# index: 是否写进索引
# header: 布尔值/列表, 是否写入列索引
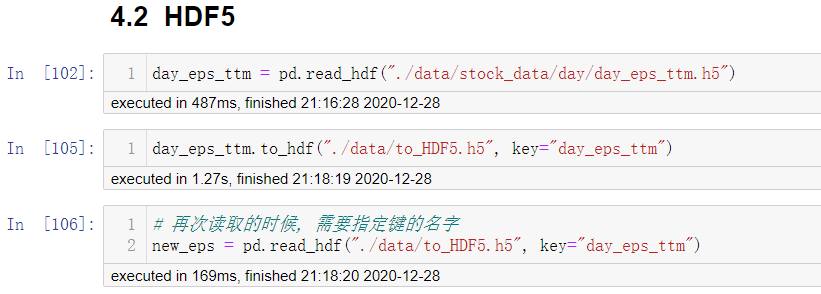
HDF5
pd.read_hdf(path_or_buf,key=None...)
# 从h5文件当中读取数据
# path_or_buffer: 文件路径
# key: 读取的键
df.to_hdf(path_or_buf,key,...)
注意: 读取hdf5文件之前需要先安装tables模块
pip install tables
h5文件是不能直接打开的,需要先读入才能查看.
JSON
JSON是我们常用的一种数据交互格式,在前后端交互的时候经常用到.
pd.read_json(path_or_buf=None,orient=None,typ="frame",lines=False)
# 将JSON标准格式换成默认的 Pandas DataFrame格式
# orinet: 字符串,表示预期的JSON字符串格式。
# lines: 按照每行读取json对象
# typ: 指定转换的对象类型 series,dataframe,默认 dataframe
df.to_json(path_or_buf=None,orient=None,lines=False)
# 将pandas对象存储为json格式
# path_or_buf=None 文件地址
# orient: 存储的json形式
# lines: 一个对象存储为一行
下面的测试案例数据集使用一个新闻标题讽刺数据集,格式为json.
is_sarcastic: 1 讽刺的,否则为0.
headline: 新闻报道的标题
article_link: 链接到原始新闻

拓展
优先选择使用HDF5文件存储
(1) HDF5在存储的时候支持压缩,使用的方式是blosc,这个是速度最快的,也是pandas支持的.
(2) 使用压缩可以提高磁盘的利用率,节省空间.
(3) HDF5还是跨平台的,可以轻松迁移到hadoop上面.
高级处理 -- 缺失值处理
如何处理nan
判断是否存在缺失值
pd.isnull(df)
# 判断是否存在缺失值
pd.notnull(df)
# 判断是否不是缺失值
处理缺失值
处理缺失值有两种方式、
(1) 删除缺失值 dropna
(2) 替换缺失值 fillna
df.dropna(axis=..)
# 删除缺失值,不修改原数据,返回一个新的df
# axis=0 列, axis=1,列
df.fillna(value,inplace=True)
# value:替换成的值
# inplace: True会修改原数据,False不替换修改原数据,生成新的df
电影数据的缺失值处理
电影数据的读取
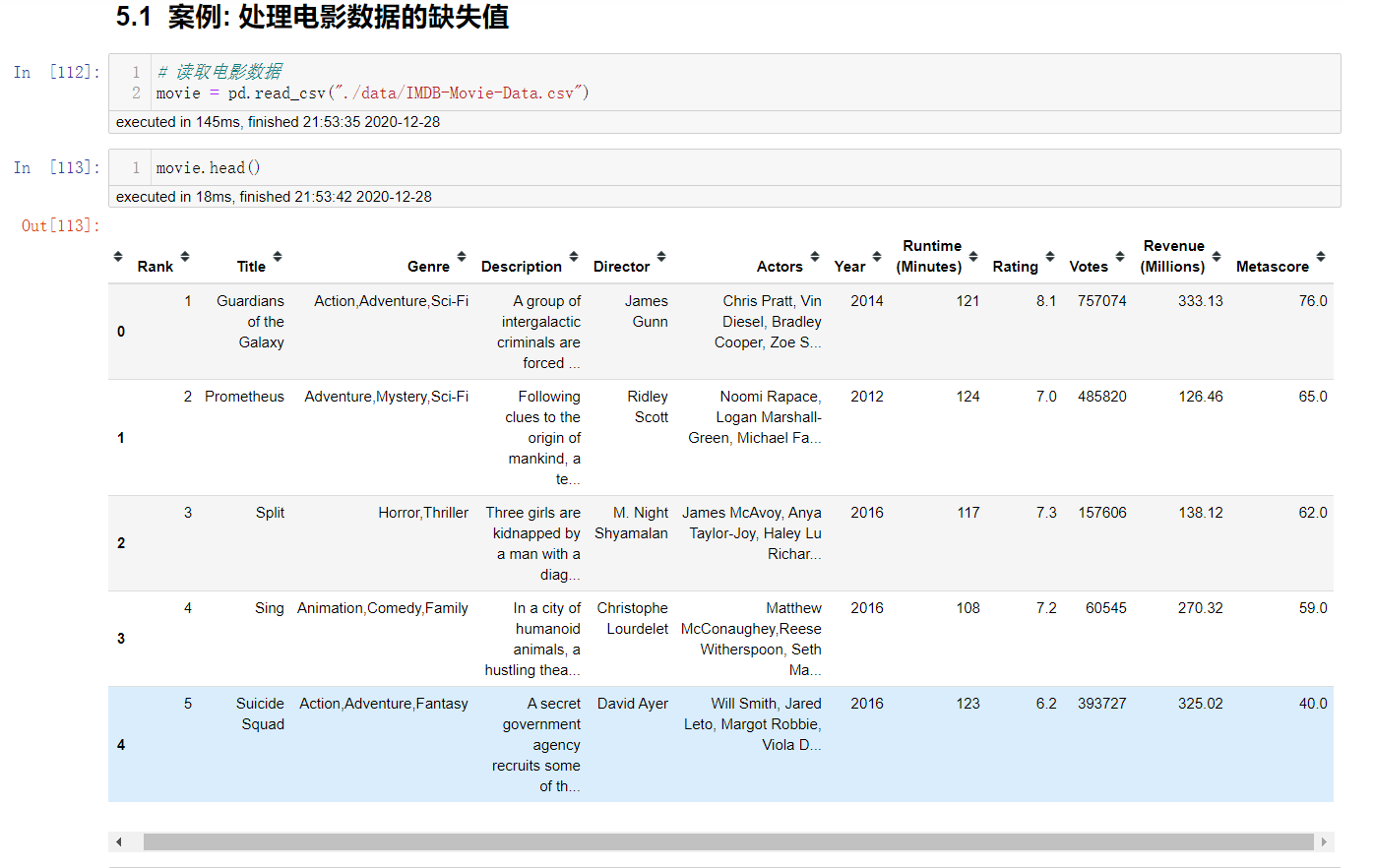
判断缺失值是否存在
处理缺失值

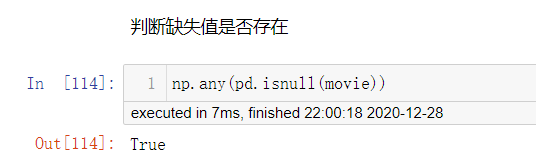
不是缺失值nan,有默认标记的
数据是这样的:
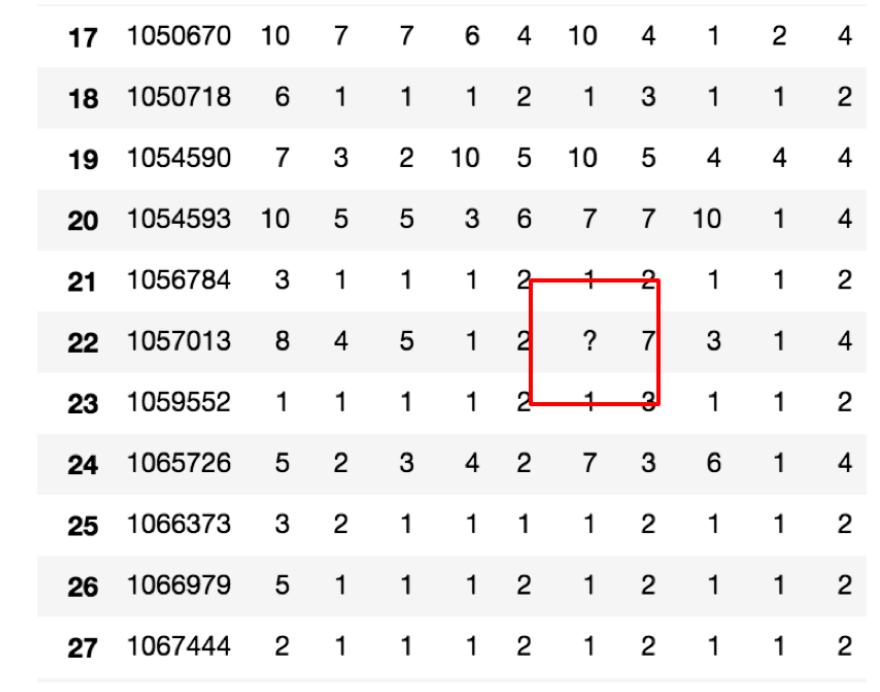
df.replace(to_replace=...,value=...)
# to_replace: 替换前的值
# value: 替换后的值
高级处理 -- 数据离散化
为什么要离散化
连续属性(或分类很多的离散属性)离散化的目的是为了简化数据结构.
数据离散化技术可以用来减少给定连续属性的个数,离散化方法经常作为数据挖掘的工具.
什么是数据的离散化
连续属性的离散化就是在连续属性的值域上,将值域划分为若干个离散的区间,最后用不同的符号或整数值,代表落在每个子区间中的属性值.
离散化有很多种方式,这使用一种最简单的方式去操作
例:
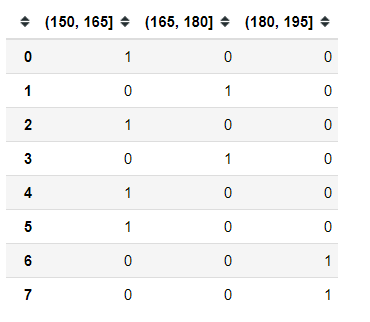
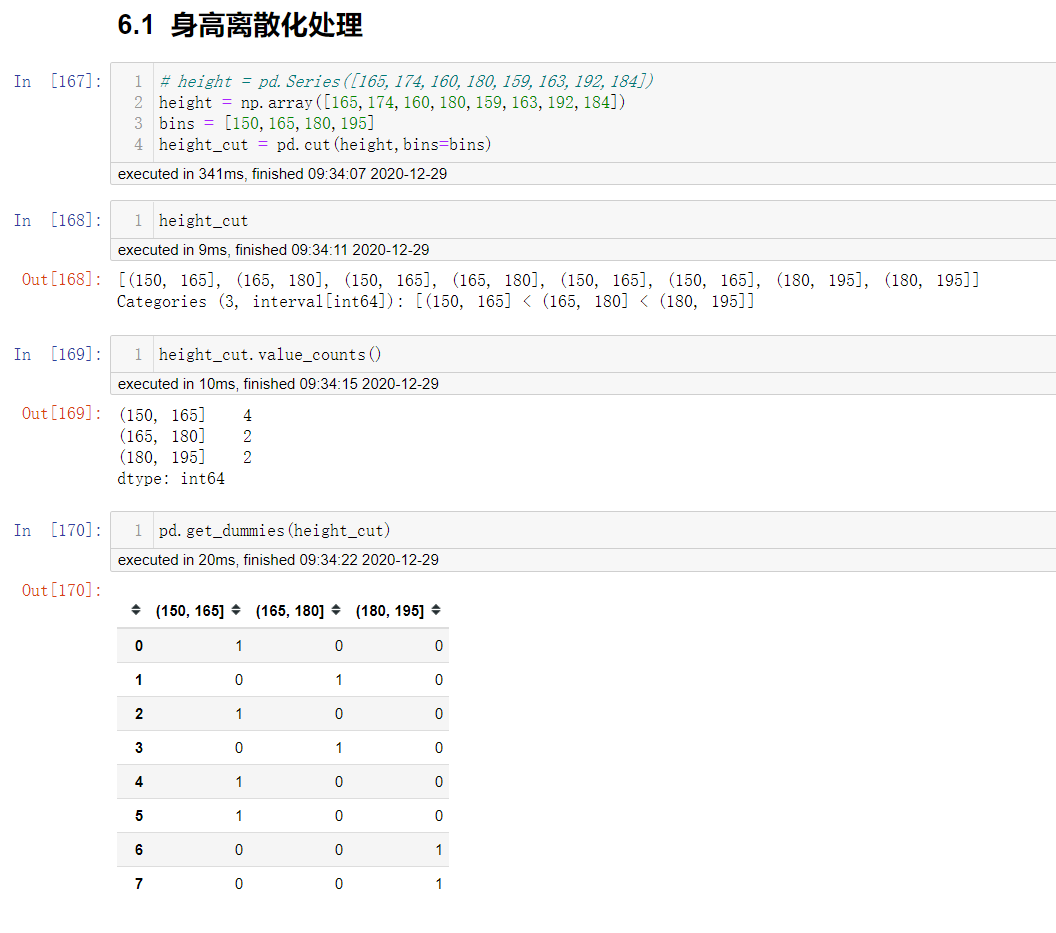
原始人的身高数据:165,174,160,180,159,163,192,184
假设按照身高分几个区间段:150~165, 165180,180195
这样我们将数据分到了三个区间段,我可以对应的标记为矮、中、高三个类别,最终要处理成一个 "哑变量"矩阵
数据离散化的api
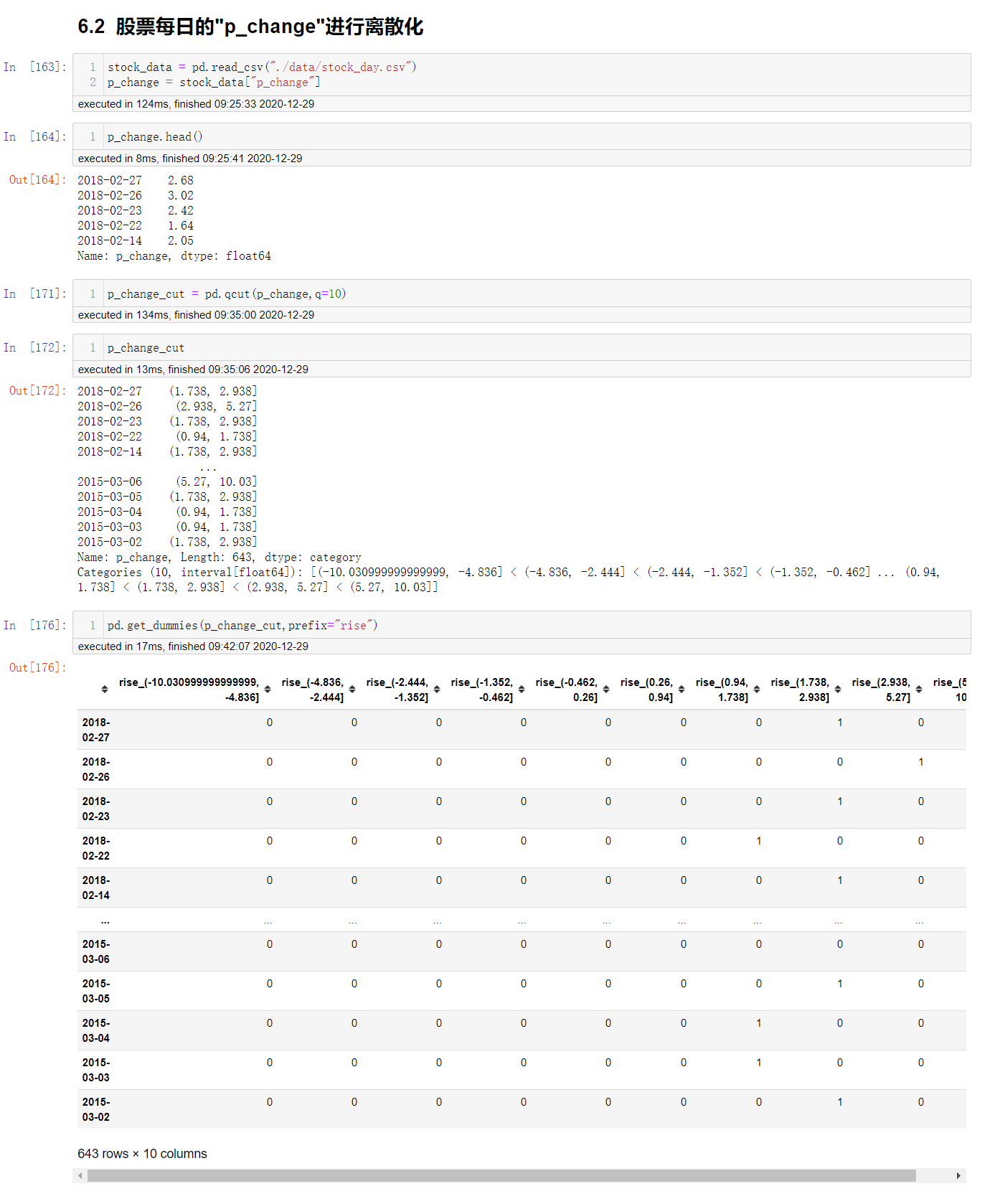
pd.qcut(data,q):
# 将数据进行分组
# data: like-array
# q: 指定分组的数量
pd.cut(data,bins):
# data: like-array
# bins: 自己指定分划分序列,例 [160,175,185,195]
df/ser.values_count()
# 统计分组次数,按照分组次数从大到小排序
pd.get_dummies(data,preifx=None)
# 得到分组的哑变量
# data: array-like
# prefix: 分组名字(前缀)
身高数据离散化
股票的涨跌幅离散化
高级处理 -- 合并
如果你的数据由多张表组成,那么有时候需要将不同的内容合并在一起分析.
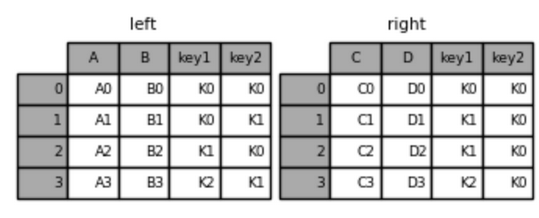
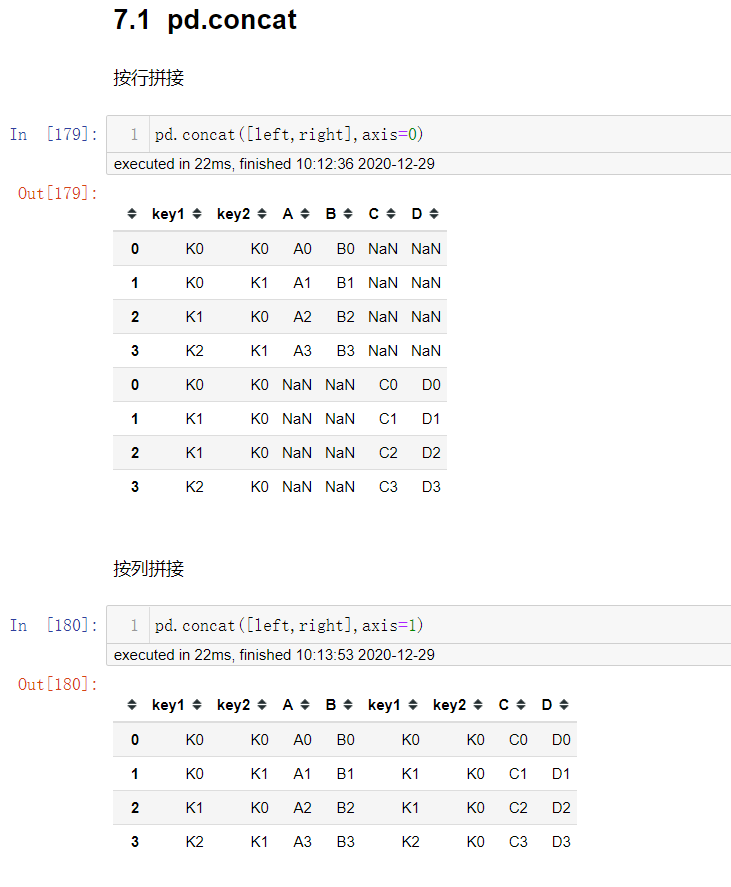
首先构造出左表和右表
left = pd.DataFrame({'key1': ['K0', 'K0', 'K1', 'K2'],
'key2': ['K0', 'K1', 'K0', 'K1'],
'A': ['A0', 'A1', 'A2', 'A3'],
'B': ['B0', 'B1', 'B2', 'B3']})
right = pd.DataFrame({'key1': ['K0', 'K1', 'K1', 'K2'],
'key2': ['K0', 'K0', 'K0', 'K0'],
'C': ['C0', 'C1', 'C2', 'C3'],
'D': ['D0', 'D1', 'D2', 'D3']})
pd.concat实现数据合并
pd.concat([data1,data2],axis=..)
# 拼接两个表 data1,data2
# axis: 0按照列方向拼接,1按照行方向拼接
pd.merge
pd.merge(left,right,how="inner",on=None,left_on=None,right_on=None)
# 可以按照数据的方式进行合并
# left/right: 左/右表
# on: 合并表一来的key
# left_on/right_on: 指定左右键
# how: left,right,inner,outer 四种合并方式

高级处理 -- 交叉表与透视表
交叉表与透视表有什么作用?
以探究股票的涨跌与星期几有关为例进行理解.
交叉表和透视表就是用来探索两列数据之间的关系.
交叉表和透视表api
pd.crosstab(value1,value2)
# 返回具体数量
df.pivot_table([],index=[])
# 返回百分占比
案例分析
准备两列数据,星期数据已经涨跌幅是好是坏数据.
进行交叉表计算.

高级处理 -- 分组与聚合
分组与聚合通常是分析数据的一种方式,通常与一些统计函数一起使用,查看数据的分组情况.
其实交叉表与透视表也有分组的功能,所以算是分组的一种形式,只不过他们主要是计算次数或者计算比例.
什么是分组与聚合
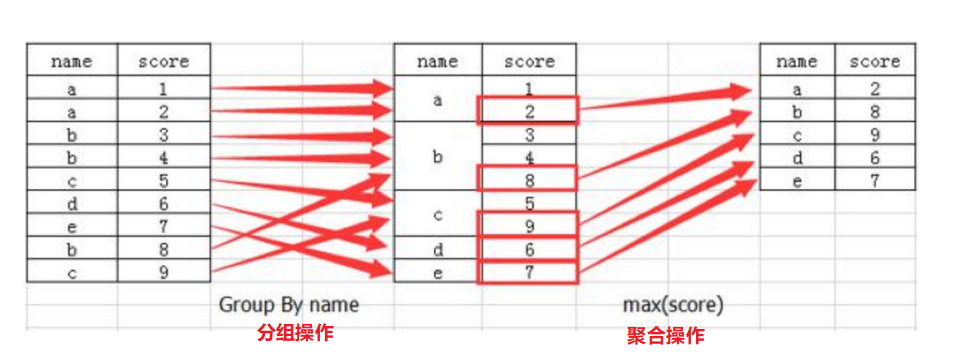
分组api
df/ser.groupby(by=...,as_index=False)
# by: 分组的键,可以是单个,可以是一个列表
# as_index: 是否将分组作为索引
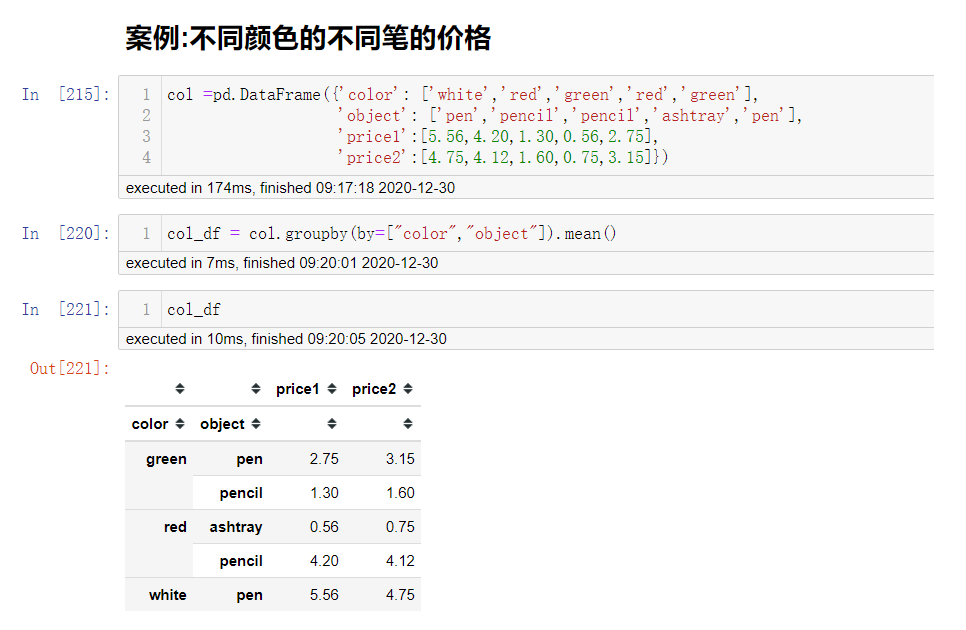
案例:不同颜色的不同笔的价格
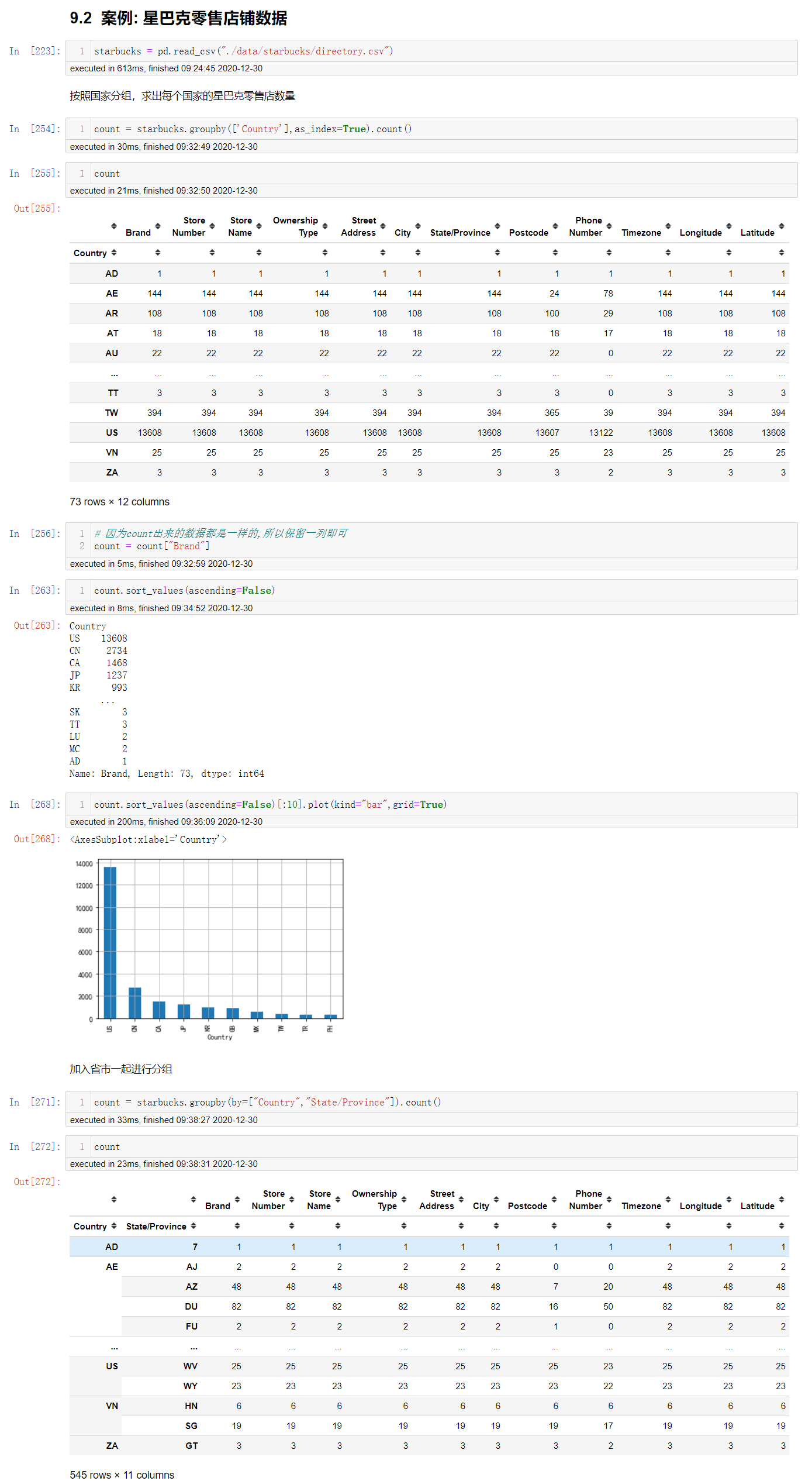
案例: 星巴克零售店铺数据
现在我们有一组关于全球星巴克店铺的统计数据,如果我想知道美国的星巴克数量和中国的哪个多,或者我想知道中国每个省份星巴克的数量的情况,那么应该怎么办?
时间序列
为什么要学习pandas中的时间序列
不管在什么行业,时间序列都是一种非常重要的数据形式.
很多统计数据以及数据的规律也都和时间序列有着非常重要的联系.
在pandas中处理时间序列是非常简单的.
时间序列api
pd.data_range(start=None,end=None,periods=None,freq="D")
# 返回一个DatetimeIndex
# start和end以及freq配合能够生成从[start,end)范围内以频率freq的一组时间索引
# start和periods以及freq配合能够生成从start开始的频率为freq的periods个时间索引

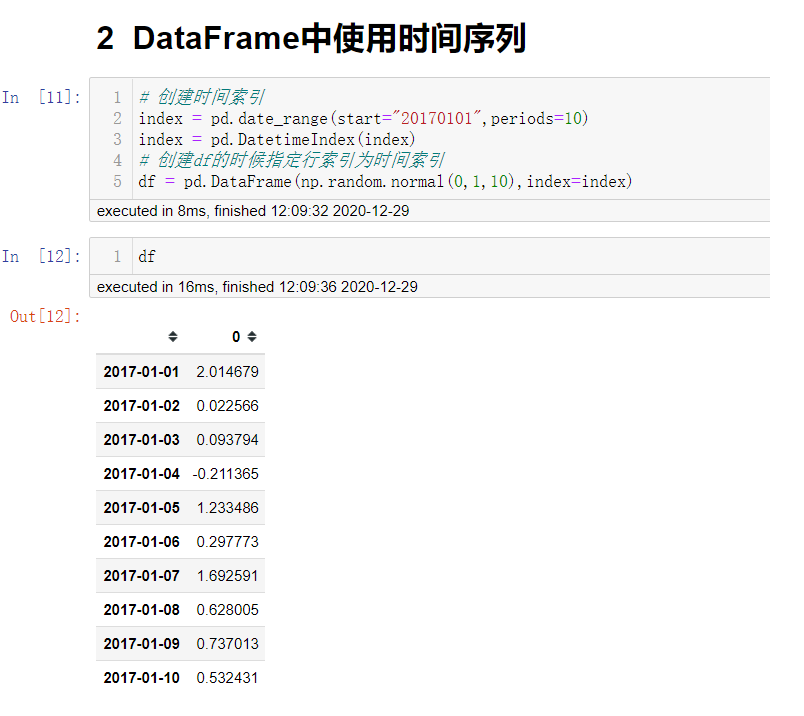
在DataFrame中使用时间序列
index = pd.date_range("20170101",periods=10) # 创建一段时间序列
df = pd.DateFrame(np.random.normal(0,1,10),index=index) # 指定行索引为时间序列
如果是在数据分析案例中,我们可以使用pandas中提供的方法把时间字符串转换为时间序列
df["timestamp"] = pd.to_datetime(df["timestamp"],format=...)
# format: 大部分时候不写,但是对于pandas无法格式化的字符串,我们可以使用该参数,比如包含中文
# 时间字符串就是python的时间格式化字符串
DatetimeIndex
DatetimeIndex的主要作用之一是用作pandas对象的索引.
DatetimeIndex还有许多可以获取时间的操作.
pd.to_datetime(时间字符串/时间字符串序列)
# 将时间字符串转为时间戳
pd.DatetimeIndex(Timestamp)
# 将Timestamp转为DatetimeIndex
DatetimeIndex属性
DatetimeIndex的属性和datetime中的属性是一致的.
time = pd.DatetimeIndex(...)
time.year # 提取年
time.month # 提取月
time.day # 提取天
time.hour
time.minute
time.second
time.weekday
...
提取出时间的子集
time = pd.DatetimeIndex(...)
time["时间字符串"]
例:
time["2015"] # 提取2015年的数据
time["201501"] # 提取2015年1月的数据
time.truncate(before=None,after=None,axis=None)
# before: 在此时间之前
# after: 在此时间之后
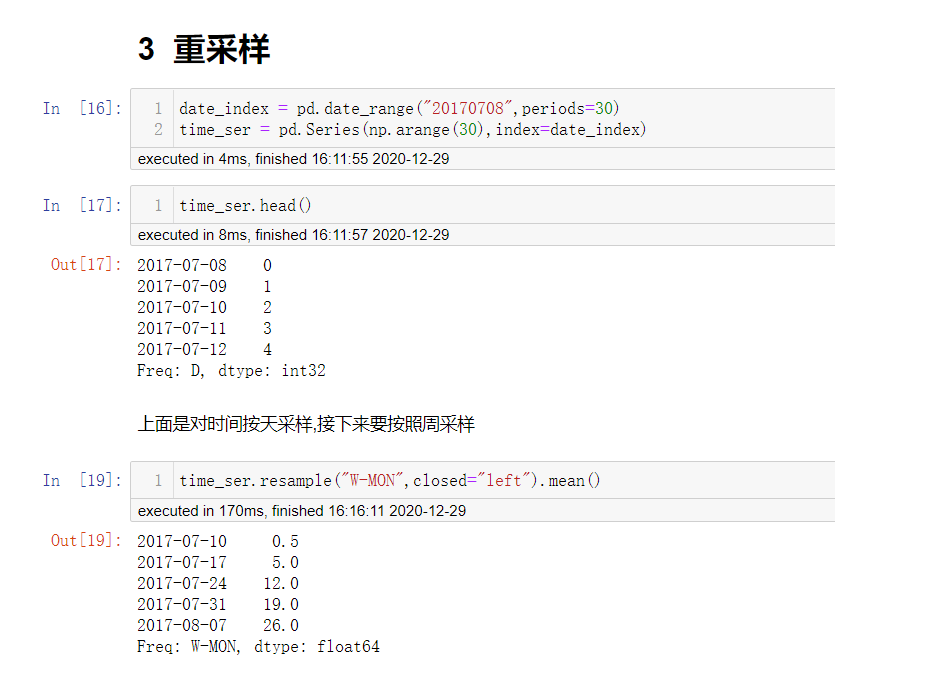
pandas重采样
重采样: 指的是将时间序列从一个频率转换为另一个频率进行处理的过程.
降采样: 降高频率数据转化为低频率数据.
升采样: 降低频率数据转化为高频率数据.
注意: 要进行重采样的对象,必须具有与时间相关的索引,比如DatetimeIndex,PeriodIndex等.
ser/df.resample(rule,closed=...)
# 对时间序列进行重采样(对时间进行分组操作)
# rule: 表示重采样频率的规则,比如"M","5min"等
# closed: left表示左闭右开, right表示左开右闭
# 上面一般要与聚合函数联合使用
pd.resample().mean()/count()....
PeriodIndex
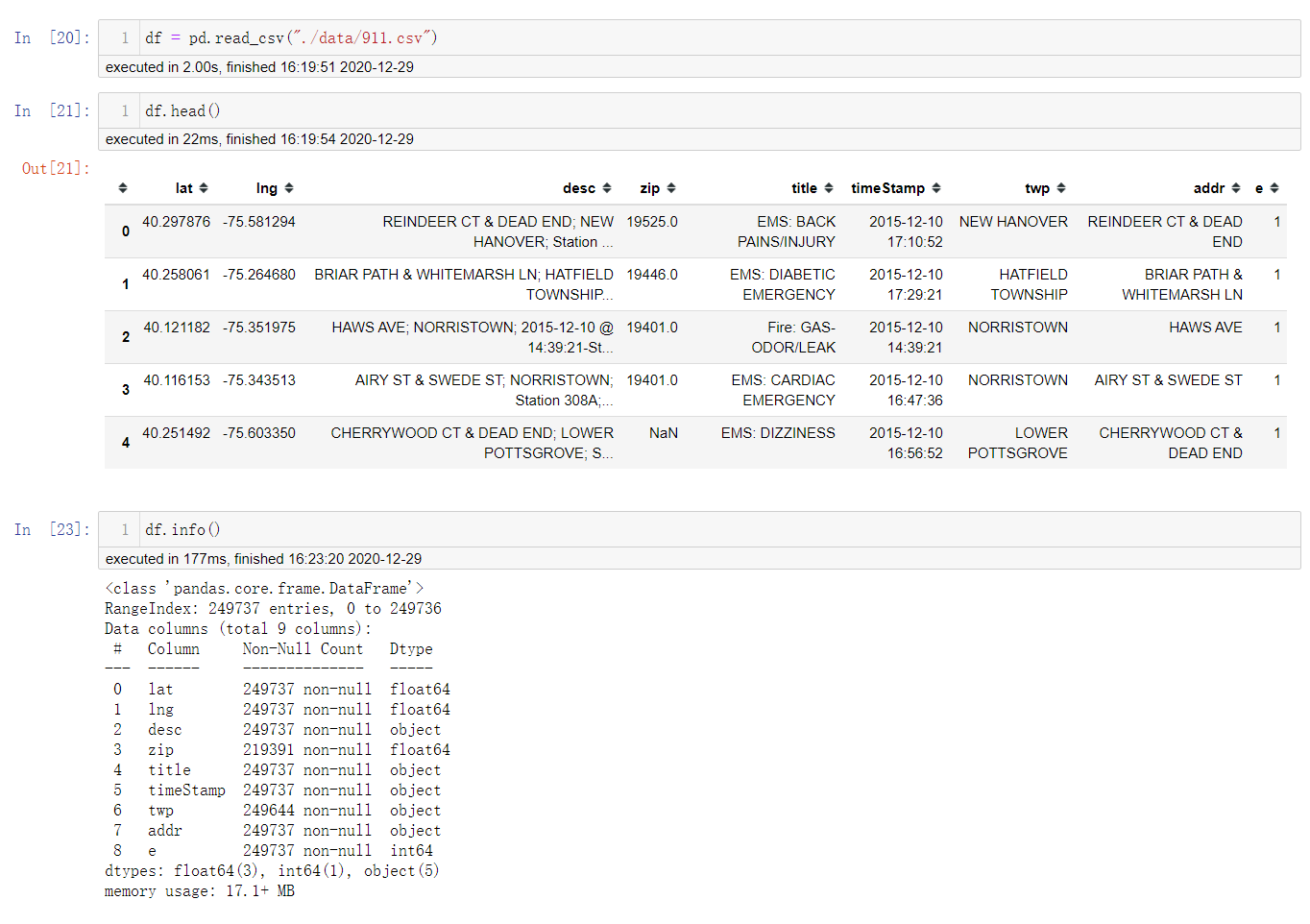
案例:911
现在我们有2015年到2017年25W条911的紧急电话的数据.
(1) 统计不同类型的紧急情况次数
(2) 统计出911数据中不同月份电话次数的变化情况
(3) 统计出911数据中不同月份不同类型的电话的次数的变化情况
数据集字段说明:
lat: 经度
lng: 维度
desc: 描述
zip:
title: 标题,也有分类信息
timeStamp: 时间戳
twp: 位置
addr: 位置
e:
导入数据,处理数据
首先导入数据,查看一下数据.
发现zip,twp两列有缺失值,但是这两列不是重点,所以不进行处理.
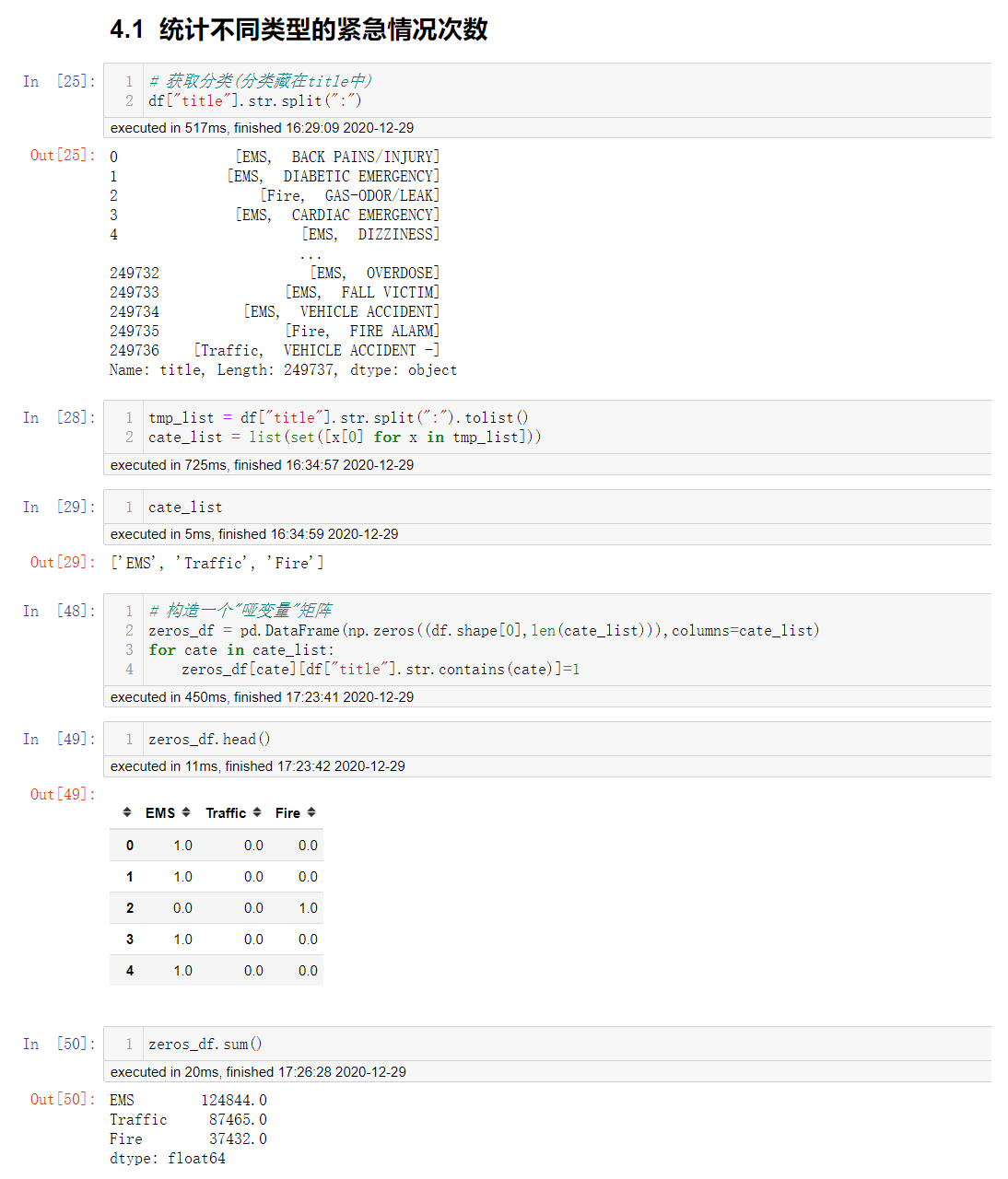
统计不同类型的紧急情况次数
首先一个问题就是类型的信息放在哪里?
观察知道,类型的信息在title字段当中,那么如何获取呢?
使用字符串分割的方式进行获取.
tmp_list = df["title"].str.split(":").tolist
cate_list = list(set([x[0] for x in tmp_list]))
还有一个问题就是如何统计次数?
有一个套路: 构建一个"哑变量"矩阵.
然后就是如何往"哑变量"矩阵中填值的问题.
列: 类型
行: 通过ser.str.xxx 来进行获取
当然还可以怎么处理呢?
新增一列cate特征,然后进行groupby统计.
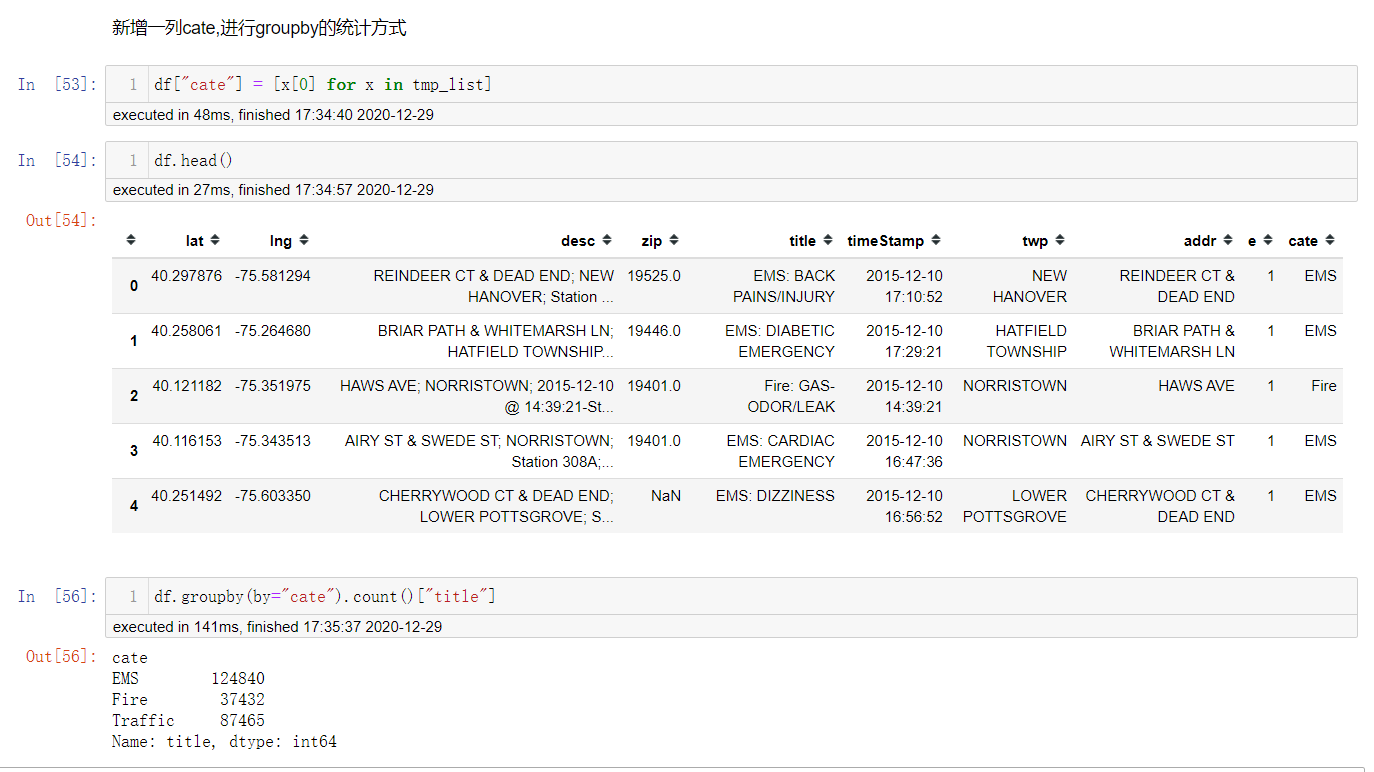
统计出911数据中不同月份电话次数的变化情况
如何按照月份统计?
很简单的道理,只要按照月份分组即可
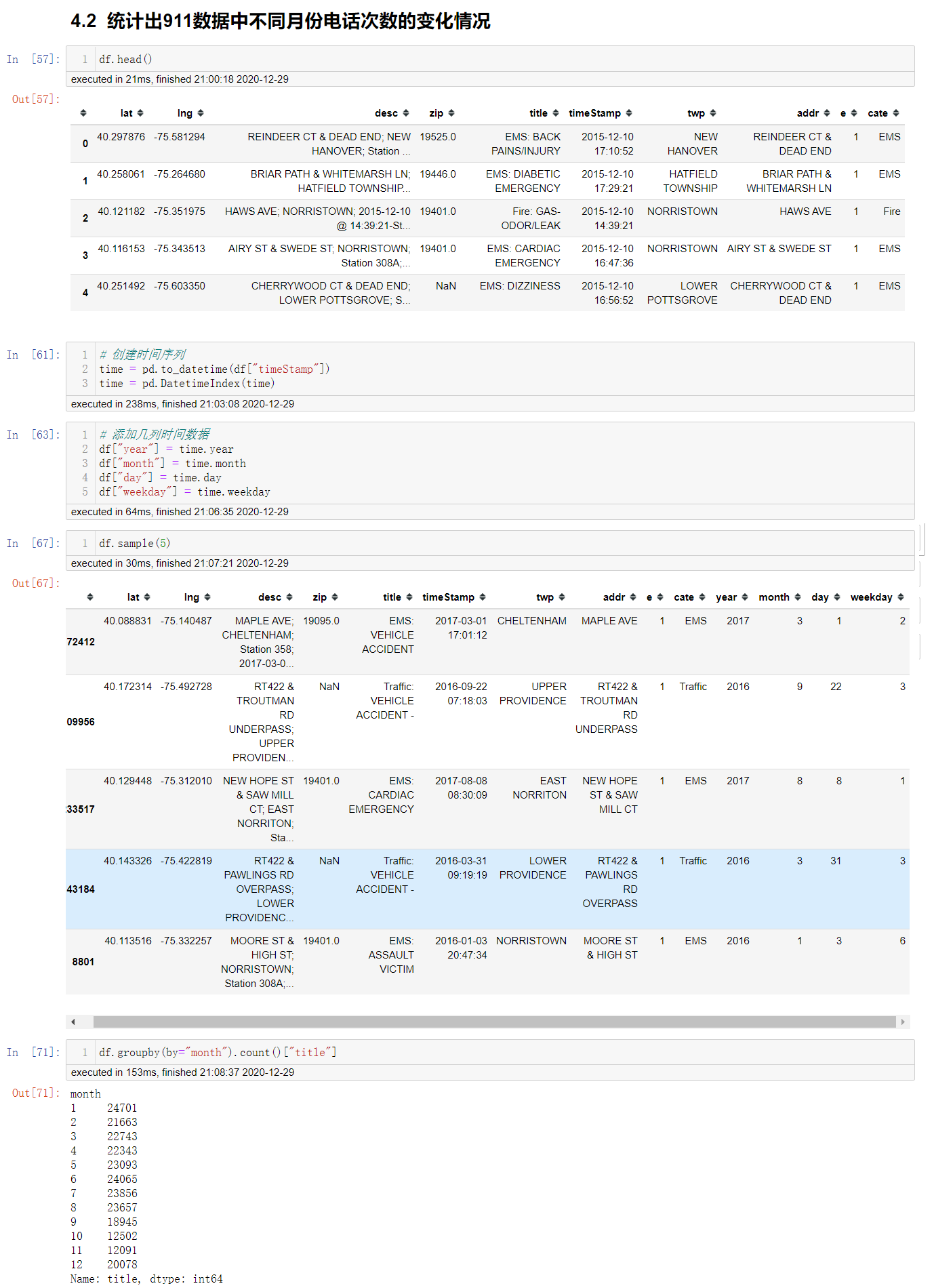
统计出911数据中不同月份不同类型的电话的次数的变化情况
也是聚合分组,首先按照月份分组统计,再按照类型进行分组统计.


 浙公网安备 33010602011771号
浙公网安备 33010602011771号