
作业3
第三次作业爬虫实践报告
作业①:气象网站图片爬取
1.1 代码实现与运行结果
单线程图片爬取代码
import requests
from bs4 import BeautifulSoup
import os
import threading
from urllib.parse import urljoin
import time
class WeatherImageCrawler:
def __init__(self, base_url="http://www.weather.com.cn"):
self.base_url = base_url
self.images_dir = "images"
self.max_pages = 25 # 学号尾数2位控制总页数
self.max_images = 125 # 学号尾数3位控制总图片数
self.downloaded_count = 0
if not os.path.exists(self.images_dir):
os.makedirs(self.images_dir)
def get_page_images(self, url):
"""获取单个页面的所有图片URL"""
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
}
response = requests.get(url, headers=headers, timeout=10)
response.encoding = 'utf-8'
soup = BeautifulSoup(response.text, 'html.parser')
img_urls = []
for img in soup.find_all('img'):
src = img.get('src')
if src and self.is_valid_image(src):
full_url = urljoin(self.base_url, src)
img_urls.append(full_url)
return img_urls
except Exception as e:
print(f"获取页面 {url} 图片失败: {e}")
return []
def is_valid_image(self, url):
"""检查是否为有效图片URL"""
valid_extensions = ['.jpg', '.jpeg', '.png', '.gif', '.bmp']
return any(url.lower().endswith(ext) for ext in valid_extensions)
def download_image(self, img_url):
"""下载单个图片"""
if self.downloaded_count >= self.max_images:
return False
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
}
response = requests.get(img_url, headers=headers, timeout=10)
if response.status_code == 200:
# 生成文件名
filename = os.path.join(self.images_dir,
f"image_{self.downloaded_count + 1}_{hash(img_url) % 10000}.jpg")
with open(filename, 'wb') as f:
f.write(response.content)
self.downloaded_count += 1
print(f"下载成功: {img_url} -> {filename}")
return True
except Exception as e:
print(f"下载图片失败 {img_url}: {e}")
return False
def single_thread_crawl(self):
"""单线程爬取"""
print("开始单线程爬取...")
start_time = time.time()
# 获取首页图片
img_urls = self.get_page_images(self.base_url)
for img_url in img_urls:
if self.downloaded_count >= self.max_images:
break
self.download_image(img_url)
end_time = time.time()
print(f"单线程爬取完成,共下载 {self.downloaded_count} 张图片,耗时: {end_time - start_time:.2f}秒")
def multi_thread_crawl(self):
"""多线程爬取"""
print("开始多线程爬取...")
start_time = time.time()
# 获取首页图片
img_urls = self.get_page_images(self.base_url)
threads = []
for img_url in img_urls:
if self.downloaded_count >= self.max_images:
break
thread = threading.Thread(target=self.download_image, args=(img_url,))
threads.append(thread)
thread.start()
for thread in threads:
thread.join()
end_time = time.time()
print(f"多线程爬取完成,共下载 {self.downloaded_count} 张图片,耗时: {end_time - start_time:.2f}秒")
if __name__ == "__main__":
crawler = WeatherImageCrawler()
# 单线程爬取
crawler.single_thread_crawl()
# 重置计数器进行多线程爬取
crawler.downloaded_count = 0
crawler.multi_thread_crawl()
运行截图将在此处展示

1.2 作业心得
单线程与多线程爬取的性能差异。单线程实现简单,代码易于理解和调试,但在下载大量图片时效率较低。多线程虽然提高了下载速度,但也带来了线程安全、资源竞争等复杂问题。
作业②:股票信息爬取
2.1 代码实现与运行结果
Scrapy项目结构
stock_crawler/
├── scrapy.cfg
├── stock_crawler/
│ ├── __init__.py
│ ├── items.py
│ ├── pipelines.py
│ ├── settings.py
│ └── spiders/
│ ├── __init__.py
│ └──eastmoney_spider.py
└── requirements.txt
数据库运行结果截图将在此处展示
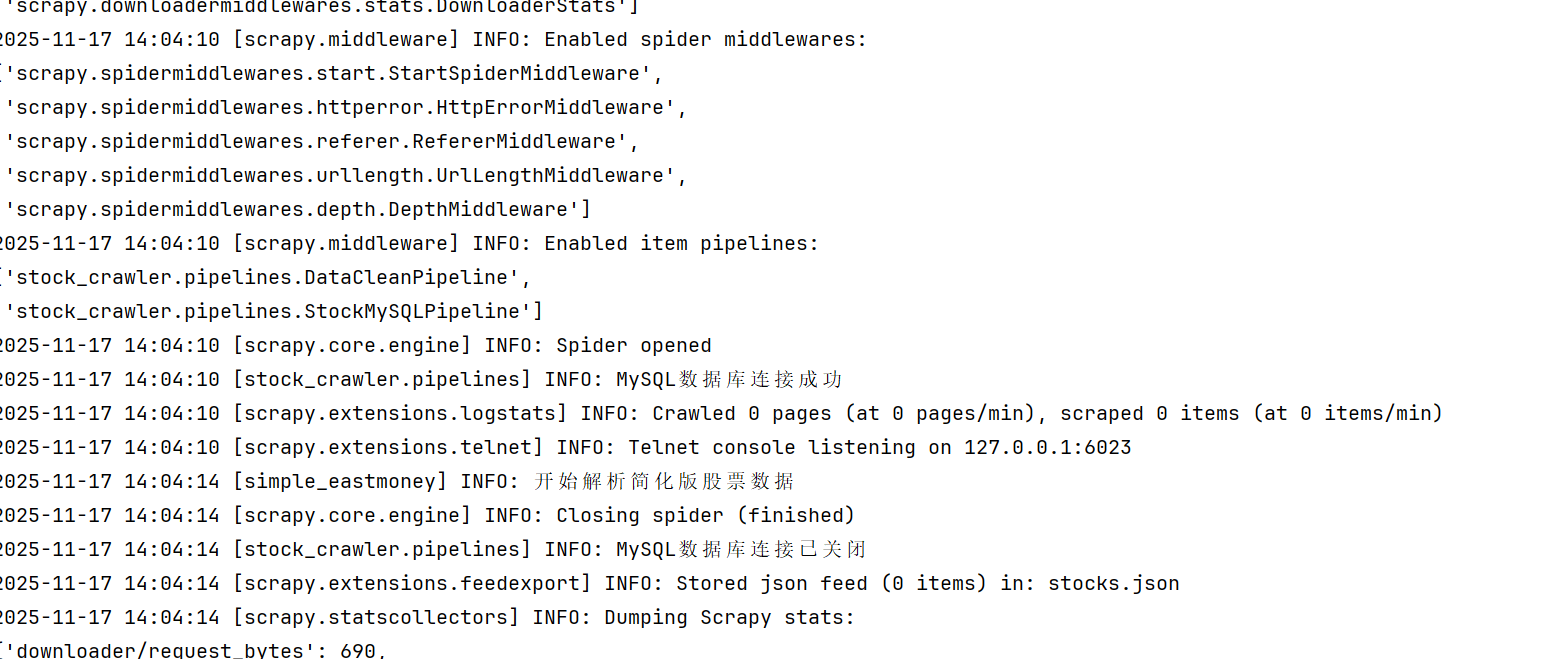
2.2 作业心得
通过本次股票信息爬取作业,我深入掌握了Scrapy框架的核心组件。Item类帮助我规范了数据结构,Pipeline实现了数据的清洗和存储,XPath选择器让数据提取变得更加精准。
在连接MySQL数据库的过程中,我学习了数据库表设计、连接池管理和异常处理。特别是在处理股票数据时,需要考虑数据类型转换和空值处理,这锻炼了我的数据清洗能力。
作业③:外汇数据爬取
3.1 代码实现与运行结果
外汇爬虫核心代码
外汇数据爬取结果截图将在此处展示
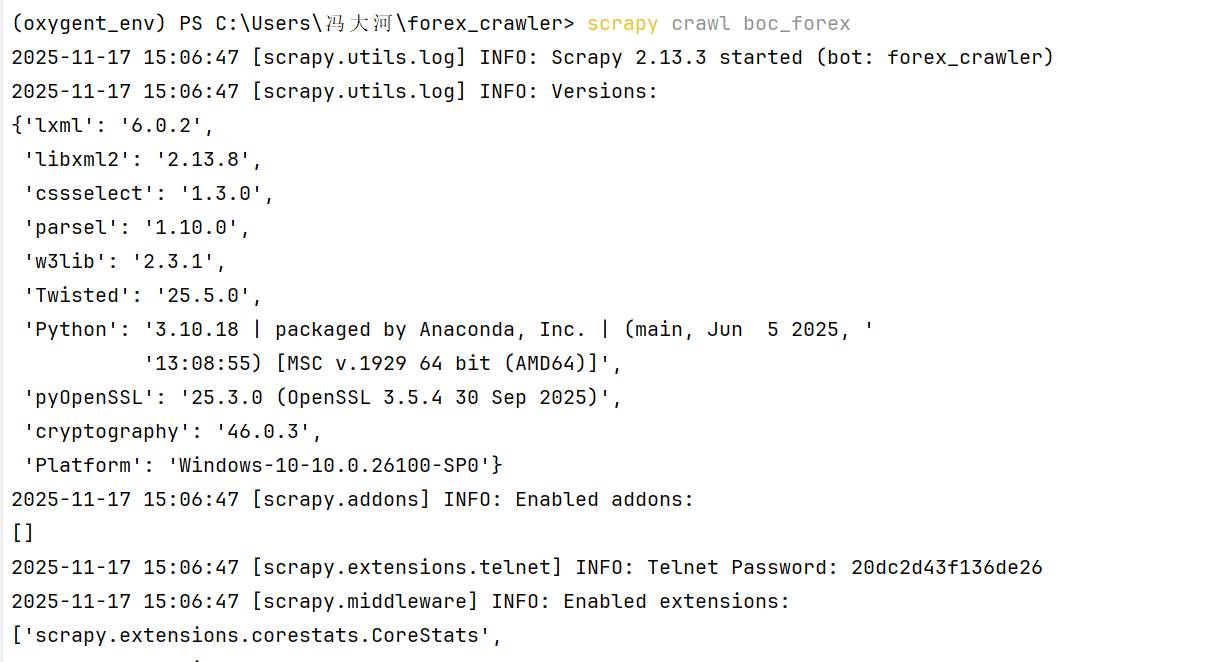
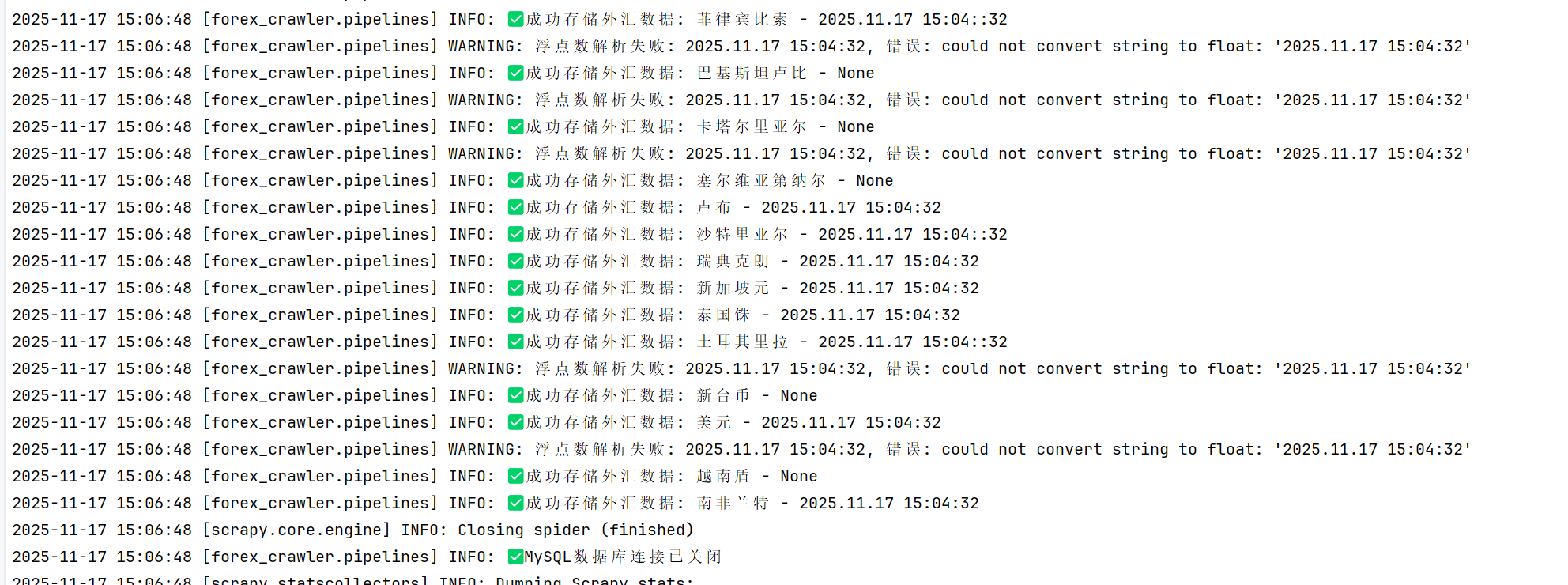
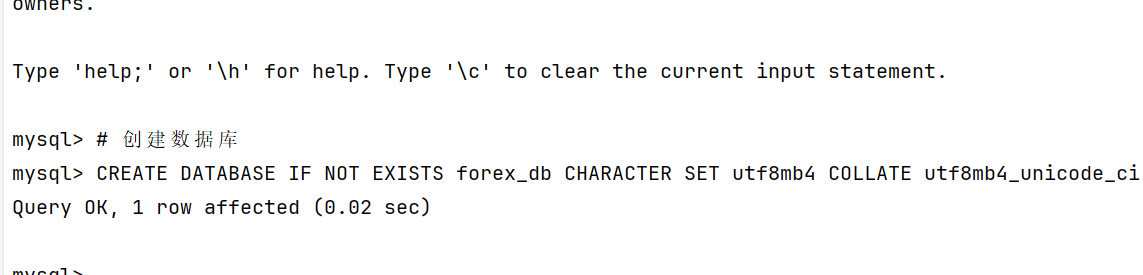
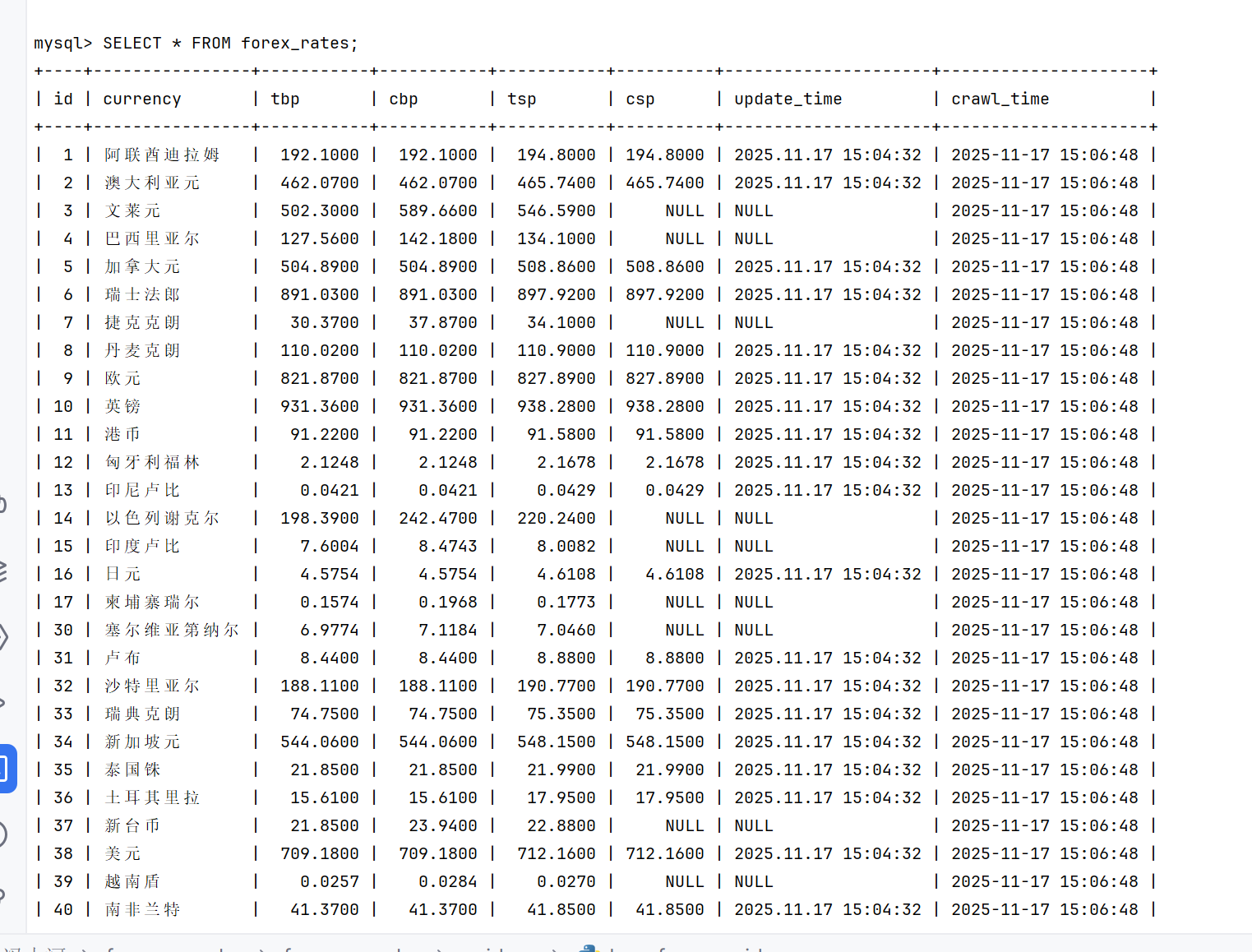

3.2 作业心得
在实现过程中,我特别注意了XPath表达式的准确性,通过浏览器开发者工具反复测试选择器,确保能够精准提取目标数据。同时,我也学习了如何在Pipeline中进行数据验证,确保入库数据的质量。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号