Java集合-Collection
Java集合-Collection
一、Collection继承关系
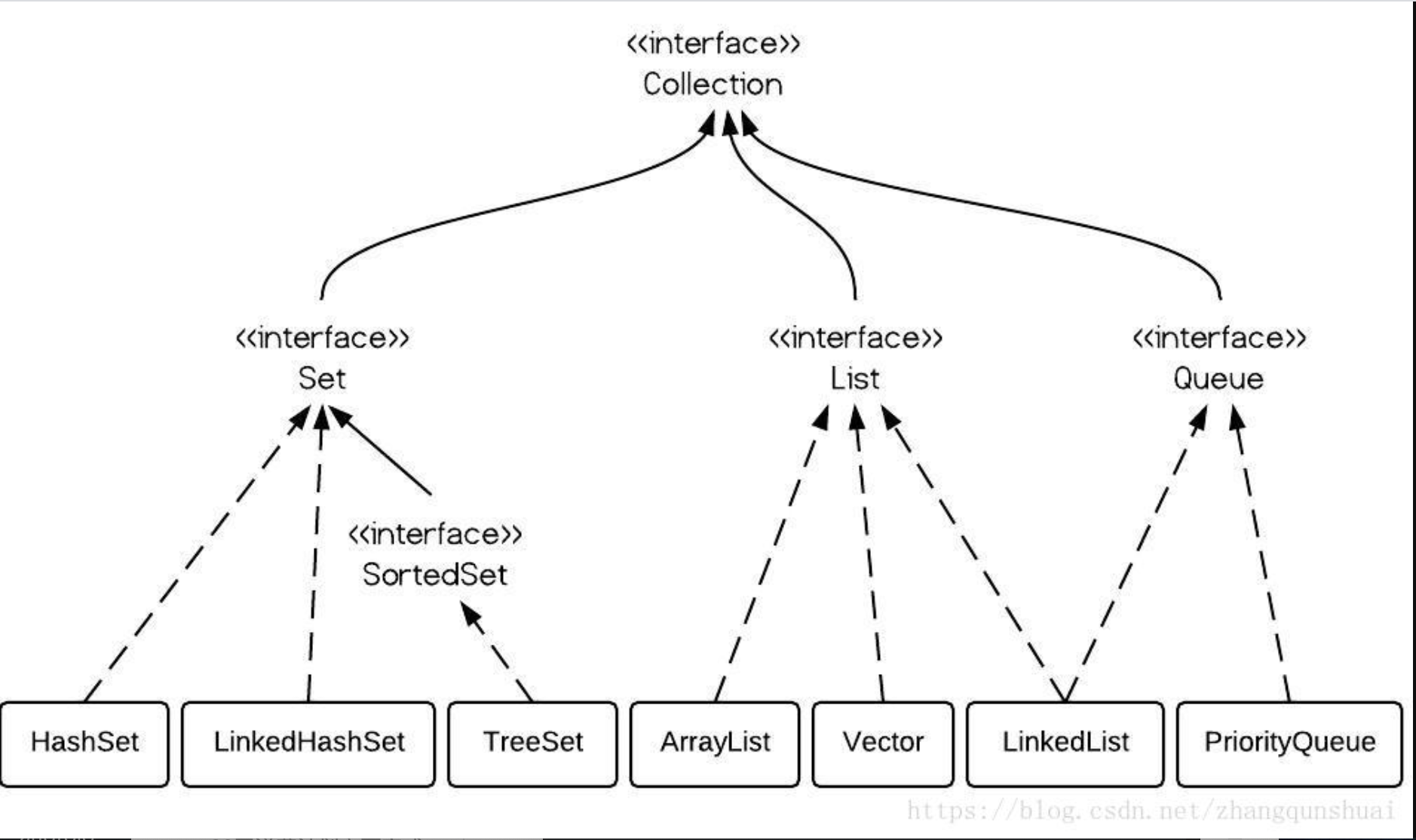
由上图可知Collection有三个子类,分别是Set、List、Queue。
特点:
Set:无序且值唯一
List:有序、值可重复
Queue:先进先出的线性表
二、Collection提供的方法
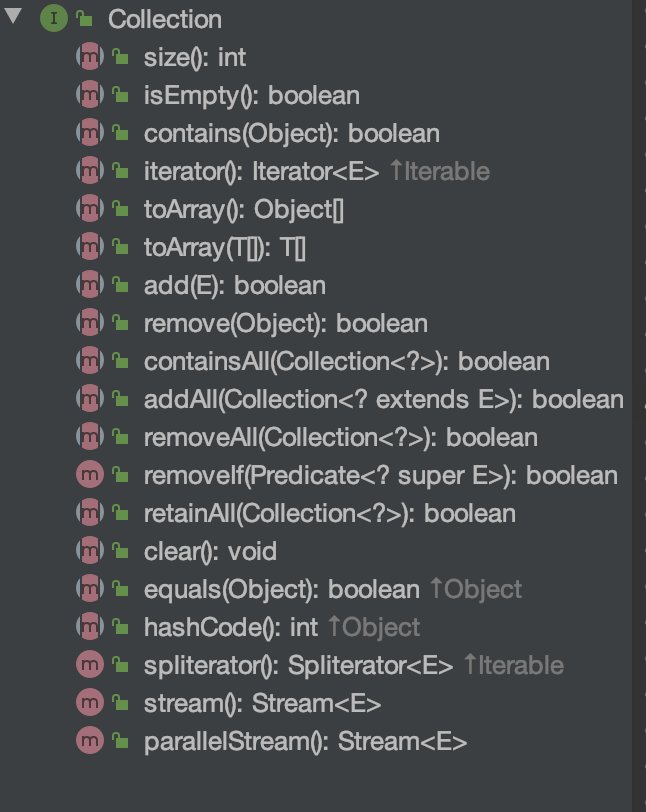
Collection提供了对集合的通用操作
三、Collection子类
1、Set
无序且值唯一。
Set子类有:
HashSet
底层数据结构是哈希表(实际是hashMap),从构造函数可以看出在创建实例时会创建一个HashMap,该HashMap就是用来实际存储元素的,除此之外在创建HashSet实例时我们可以指定其内部HashMap的容量和加载因子(默认大小为16,加载因子为0.75)
public HashSet() {
map = new HashMap<>();
}
再来看下增删查数据是如何实现的:
- add操作
public boolean add(E e) {
//add是调用HashMap的put操作
return map.put(e, PRESENT)==null;
}
- remove操作
public boolean remove(Object o) {
return map.remove(o)==PRESENT;
}
- contains操作
public boolean contains(Object o) {
return map.containsKey(o);
}
HashSet如何来保证元素唯一性? 1.依赖两个方法:hashCode()和equals()。
TreeSet
TreeSet是一个非同步的非线程安全的二叉树,底层数据结构是红黑树。(唯一,排序),其add , remove和contains操作的时间复杂度为log(n)
来看下默认构造函数:
public TreeSet() {
this(new TreeMap<E,Object>());
}
private transient NavigableMap<E,Object> m;
private static final Object PRESENT = new Object();
TreeSet(NavigableMap<E,Object> m) {
this.m = m;
}
可以看出其内部默认是使用TreeMap存储元素的,因为其内部元素是有序的,对于元素的排序有两种方式自然排序和比较器排序,自然排序就是当comparator为空的时候,构建无参构造函数的时候默认的一种排序方式,比较器排序就是在构造函数中传入comparator从而指定排序方式。
treeSet = new TreeSet<>(new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
return o1.length()-o2.length();
}
});
TreeSet保证元素唯一性的是通过比较的返回值是否是0来决定
LinkedHashSet
Set接口的哈希表和链接列表实现即保证插入顺序,(FIFO插入有序,唯一)由链表保证元素有序由哈希表保证元素唯一。linkedHashSet是一个非线程安全的集合。如果有多个线程同时访问当前linkedhashset集合容器,并且有一个线程对当前容器中的元素做了修改,那么必须要在外部实现同步
来看下其构造函数
public LinkedHashSet() {
super(16, .75f, true);
}
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
LinkedHashSet父类为HashSet,然后在HashSet的构造函数中创建了LinkedHashMap实例,也就是说LinkedHashSet最终是使用LinkedHashMap来存储元素。
Set小结
我们简绍了三种Set在实际使用时可以根据需求选择合适的,同时我们也看到这三种Set的实现最终都是通过Map来存储元素的。
2、List
List链表是一种线性结构,其内部元素有序(插入有序)、不唯一,可以根据索引来查找获取数据。
ArrayList
底层通过数组实现,查找快增删慢,线程不安全。来看下默认构造函数
transient Object[] elementData;
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
可以看到存储元素的是一个叫做elementData的数组。
- add操作
public boolean add(E e) {
ensureCapacityInternal(size + 1); // Increments modCount!!
elementData[size++] = e;
return true;
}
我们看到在增加元素前会先调用 ensureCapacityInternal来确保数组elementData有足够的空间,如果空间不足会进行扩容操作。
private void ensureCapacityInternal(int minCapacity) {
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
minCapacity = Math.max(DEFAULT_CAPACITY, minCapacity);
}
//判断是否需要扩容
ensureExplicitCapacity(minCapacity);
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;
// 需要扩容
if (minCapacity - elementData.length > 0)
grow(minCapacity);
}
private void grow(int minCapacity) {
// 当前数组大小
int oldCapacity = elementData.length;
//扩容为原来的1.5倍
int newCapacity = oldCapacity + (oldCapacity >> 1); //扩容后还不满足所需最小容量则把容量设置为所需最小容量
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
//MAX_ARRAY_SIZE的值为Integer.MAX_VALUE - 8表示最大可设置的值
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// 真正扩容操作是通过Arrays.copyOf来完成的
elementData = Arrays.copyOf(elementData, newCapacity);
}
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // 溢出
throw new OutOfMemoryError();
//所需最小容量大于MAX_ARRAY_SIZE则扩容为Integer.MAX_VALUE
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}
再来看下在指定位置插入元素的操作
public void add(int index, E element) {
if (index > size || index < 0)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
//检查是否需要扩容
ensureCapacityInternal(size + 1);
//把插入位置后面所有元素后移一位
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
//插入元素
elementData[index] = element;
size++;
}
- remove操作
public boolean remove(Object o) {
if (o == null) {
for (int index = 0; index < size; index++)
if (elementData[index] == null) {
fastRemove(index);
return true;
}
} else {
for (int index = 0; index < size; index++)
if (o.equals(elementData[index])) {
fastRemove(index);
return true;
}
}
return false;
}
可以看到remove中是根据equals来判断元素是否是要删除的,具体移除操作是通过fastRemove来完成。
private void fastRemove(int index) {
modCount++;
int numMoved = size - index - 1;
if (numMoved > 0)
//把移除位置之后所有元素向前移动一位
System.arraycopy(elementData, index+1, elementData, index,
numMoved);
elementData[--size] = null; // clear to let GC do its work
}
总体来说ArrayList底层采用数组存储元素在元素增删时通过copy数组来实现元素移动,其增删操作的时间复杂度为O(n)。
Vector
底层数组实现,查找快增删慢,线程安全。构造函数
public Vector() {
this(10);
}
public Vector(int initialCapacity) {
this(initialCapacity, 0);
}
//这里的capacityIncrement是指扩容时增加的容量
public Vector(int initialCapacity, int capacityIncrement) {
super();
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
this.elementData = new Object[initialCapacity];
this.capacityIncrement = capacityIncrement;
}
因为Vector底层也是数组实现,所以在增删数据时会涉及到数组容量的变化,这跟ArrayList类似下面是Vector扩容的核心内容,可以看出其在容量不足时会增加capacityIncrement的容量,如果capacityIncrement<0则直接增加一倍的容量。
private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + ((capacityIncrement > 0) ?
capacityIncrement : oldCapacity);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
elementData = Arrays.copyOf(elementData, newCapacity);
}
Vector实现跟ArrayList类似最大的不同在于Vector是线程安全的。
stack
先进后出的结构,stack中peek函数是查看栈顶元素但并不移除,pop是弹出栈顶元素。
其构造函数是空实现
public Stack() {
}
- push操作
public E push(E item) {
addElement(item);
return item;
}
public synchronized void addElement(E obj) {
modCount++;
//检查是否需要扩容
ensureCapacityHelper(elementCount + 1);
//存入数据
elementData[elementCount++] = obj;
}
- pop操作
public synchronized E pop() {
E obj;
int len = size();
obj = peek();
removeElementAt(len - 1);
return obj;
}
public synchronized void removeElementAt(int index) {
modCount++;
if (index >= elementCount) {
throw new ArrayIndexOutOfBoundsException(index + " >= " +
elementCount);
}
else if (index < 0) {
throw new ArrayIndexOutOfBoundsException(index);
}
int j = elementCount - index - 1;
if (j > 0) {
//移动数据
System.arraycopy(elementData, index + 1, elementData, index, j);
}
elementCount--;
//将删除位置置空
elementData[elementCount] = null; /* to let gc do its work */
}
- peek操作
public synchronized E peek() {
int len = size();
if (len == 0)
throw new EmptyStackException();
return elementAt(len - 1);
}
public synchronized E elementAt(int index) {
if (index >= elementCount) {
throw new ArrayIndexOutOfBoundsException(index + " >= " + elementCount);
}
return elementData(index);
}
E elementData(int index) {
return (E) elementData[index];
}
LinkedList
底层双链表实现,查找慢增删快,线程不安全,LinkedList同时实现了List, Deque两个接口也就是说它既可以作为list也可作为deque使用。
既然是双链表则会有节点的概念,我们来看下它的Node,这是LinkedList的一个内部类。
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
- add操作
public boolean add(E e) {
linkLast(e);
return true;
}
//在表尾插入一个Node
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}
- add(index,obj)
public void add(int index, E element) {
//检查插入位置是否合法
checkPositionIndex(index);
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
}
//插入链表
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
final Node<E> pred = succ.prev;
final Node<E> newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
first = newNode;
else
pred.next = newNode;
size++;
modCount++;
}
-
remove操作
public boolean remove(Object o) { if (o == null) { for (Node<E> x = first; x != null; x = x.next) { if (x.item == null) { unlink(x); return true; } } } else { //先查找到要删除节点 for (Node<E> x = first; x != null; x = x.next) { if (o.equals(x.item)) { //移除节点 unlink(x); return true; } } } return false; } E unlink(Node<E> x) { // assert x != null; final E element = x.item; final Node<E> next = x.next; final Node<E> prev = x.prev; //修改前驱指针 if (prev == null) { first = next; } else { prev.next = next; x.prev = null; } //修改后继指针 if (next == null) { last = prev; } else { next.prev = prev; x.next = null; } x.item = null; size--; modCount++; return element; }可以看出LinkedList的数据操作大多都是链表的操作所以其特点是增删快查找慢,在类内部LinkedList维护了first和last两个指针,这也是其能实现deque功能的基础。在作为deque时offer表示在队尾入队一个元素,poll是出队队首一个元素,peek是查看队首元素但并不出队。在作为deque时无法调用list相关接口方法。
3、Queue
队列是一种先进先出的线性结构,不支持随机访问数据。
PriorityQueue
优先队列是基于堆实现的,对内元素是有序的,offer,poll,remove和add等方法提供了O(log(n))的时间复杂度 ,而remove(obj)和contains方法的时间复杂度是O(n),peek时间复杂度为O(1)。排序是通过自然排序和比较器排序实现的,采用哪种排序是通过构造函数确定的,其中自然排序要求元素实现compare函数,比较排序则需要在构造函数中指明排序规则。
默认构造函数
private static final int DEFAULT_INITIAL_CAPACITY = 11;
public PriorityQueue() {
this(DEFAULT_INITIAL_CAPACITY, null);
}
public PriorityQueue(int initialCapacity,
Comparator<? super E> comparator) {
//可以看出内部采用数组存储
if (initialCapacity < 1)
throw new IllegalArgumentException();
this.queue = new Object[initialCapacity];
this.comparator = comparator;
}
- offer
public boolean offer(E e) {
if (e == null)
throw new NullPointerException();
modCount++;
int i = size;
if (i >= queue.length)
//扩容
grow(i + 1);
size = i + 1;
if (i == 0)
queue[0] = e;
else
//入队
siftUp(i, e);
return true;
}
private void siftUp(int k, E x) {
if (comparator != null)
siftUpUsingComparator(k, x);
else
//这里以分析siftUpComparable为例
siftUpComparable(k, x);
}
private void siftUpComparable(int k, E x) {
Comparable<? super E> key = (Comparable<? super E>) x;
while (k > 0) {
//找k位置的父节点的index
int parent = (k - 1) >>> 1;
//k位置的父节点
Object e = queue[parent];
//调整堆,大于父节点的就不动,小于父节点的就上浮
if (key.compareTo((E) e) >= 0)
break;
queue[k] = e;
k = parent;
}
queue[k] = key;
}
- poll操作
public E poll() {
if (size == 0)
return null;
int s = --size;
modCount++;
E result = (E) queue[0];
E x = (E) queue[s];
queue[s] = null;
if (s != 0)
//调整堆
siftDown(0, x);
return result;
}
private void siftDown(int k, E x) {
if (comparator != null)
siftDownUsingComparator(k, x);
else
siftDownComparable(k, x);
}
private void siftDownComparable(int k, E x) {
Comparable<? super E> key = (Comparable<? super E>)x;
int half = size >>> 1;
while (k < half) {
int child = (k << 1) + 1; // assume left child is least
Object c = queue[child];
int right = child + 1;
if (right < size &&
((Comparable<? super E>) c).compareTo((E) queue[right]) > 0)
c = queue[child = right];
if (key.compareTo((E) c) <= 0)
break;
queue[k] = c;
k = child;
}
queue[k] = key;
}
ArrayDeque
双端队列,底层数组实现。
默认构造函数
public ArrayDeque() {
//数组大小默认16
elements = new Object[16];
}
因为可以双端操作数据所以其内部采用head和tail来存储头尾元素的index这样就可以快锁找到头尾元素。ArrayDeque还规定elements的size必须是2的整数次幂,当我们设置容量大小不是2的整数次幂时会进行调整
public ArrayDeque(int numElements) {
allocateElements(numElements);
}
private void allocateElements(int numElements) {
int initialCapacity = MIN_INITIAL_CAPACITY;
// Find the best power of two to hold elements.
// Tests "<=" because arrays aren't kept full.
if (numElements >= initialCapacity) {
initialCapacity = numElements;
initialCapacity |= (initialCapacity >>> 1);
initialCapacity |= (initialCapacity >>> 2);
initialCapacity |= (initialCapacity >>> 4);
initialCapacity |= (initialCapacity >>> 8);
initialCapacity |= (initialCapacity >>> 16);
initialCapacity++;
if (initialCapacity < 0) // Too many elements, must back off
initialCapacity >>>= 1; // Good luck allocating 2^30 elements
}
elements = new Object[initialCapacity];
}
allocateElements实现思路如下:
1.要明确2整数次幂使用二进制的表现形式如下:0...010...0,中间有一个1,其它的都是0。
2.根据1的形式,计算使输入任意的X,等式成立的Y。X的二进制形式为????????,是一个未知数,这样如何求得Y呢?方法很简单,找到X最高位为1的位置:那么X就是0..001???,这种形式了。那么所求的Y就是0..010...0,其值就是比X最高位为1再高一位为1,其它位为0的值。
3.X的最高为1的那一位是未知的,如何求更高一位为1的Y呢?直接求是没有办法的,但是可以通过将X最高位为1后面所有位都变成1,再加1进位的方式办到。就是0..001???变成0.001..1,使用这个+1就会变成所要的Y:0.010...0了。
4.如何保证X最高位为1后面都是1呢?这个就是上面位运算所实现的内容了。假设X是0..01???,左移一位就是0.001??,做或运算就变成了0..011??,是不是很巧妙,出现了两位为1的就移动2位,获得四位为1的值,这样移动到16的时候就涵盖了32位整数的所有范围了。这个时候+1可能发生整数溢出,所以再左移一位保证在整数范围内。
- addFirst
public void addFirst(E e) {
if (e == null)
throw new NullPointerException();
//(head - 1) & (elements.length - 1)的作用是确定head的index
elements[head = (head - 1) & (elements.length - 1)] = e;
//首尾指向同一位置 扩容至原先两倍大小
if (head == tail)
doubleCapacity();
}
private void doubleCapacity() {
assert head == tail;
int p = head;
int n = elements.length;
int r = n - p; // number of elements to the right of p
int newCapacity = n << 1;
if (newCapacity < 0)
throw new IllegalStateException("Sorry, deque too big");
Object[] a = new Object[newCapacity];
System.arraycopy(elements, p, a, 0, r);
System.arraycopy(elements, 0, a, r, p);
elements = a;
head = 0;
tail = n;
}
- pollFirst
public E pollFirst() {
final Object[] elements = this.elements;
final int h = head;
@SuppressWarnings("unchecked")
E result = (E) elements[h];
// Element is null if deque empty
if (result != null) {
elements[h] = null; // Must null out slot
head = (h + 1) & (elements.length - 1);
}
return result;
}
在addFirst中(head - 1) & (elements.length - 1)操作主要是确定入队的队首元素的位置,该操作相当于取模操作同时还很好的处理了head-1是-1的情况(head-1是-1时该操作的结果是elements.length - 1)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号